All in One View
Content from Introduction to RNA-seq
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- What are the different choices to consider when planning an RNA-seq experiment?
- How does one process the raw fastq files to generate a table with read counts per gene and sample?
- Where does one find information about annotated genes for a given organism?
- What are the typical steps in an RNA-seq analysis?
Objectives
- Explain what RNA-seq is.
- Describe some of the most common design choices that have to be made before running an RNA-seq experiment.
- Provide an overview of the procedure to go from the raw data to the read count matrix that will be used for downstream analysis.
- Show some common types of results and visualizations generated in RNA-seq analyses.
What are we measuring in an RNA-seq experiment?
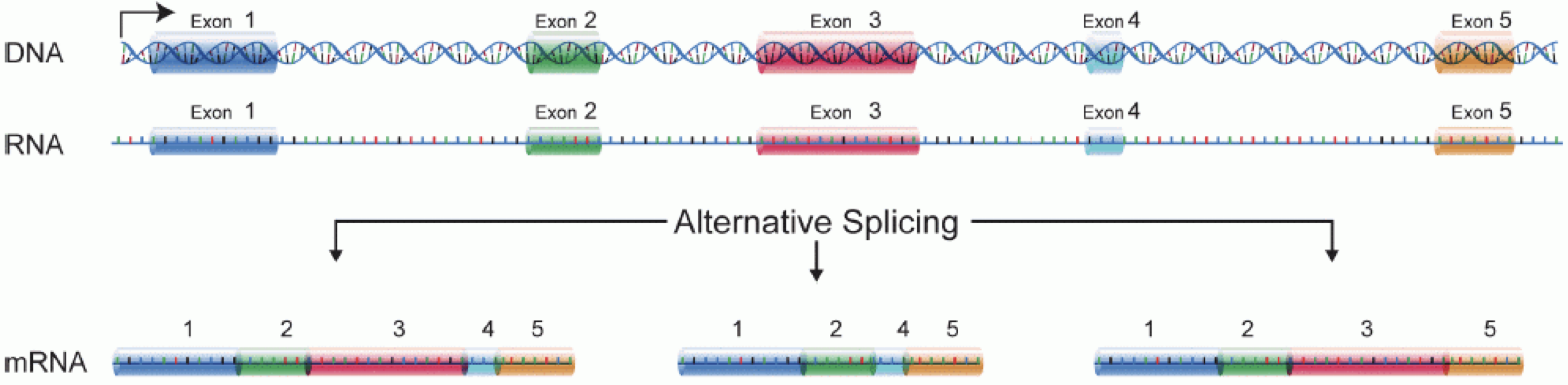
In order to produce an RNA molecule, a stretch of DNA is first transcribed into mRNA. Subsequently, intronic regions are spliced out, and exonic regions are combined into different isoforms of a gene.
(figure adapted from Martin & Wang (2011)).
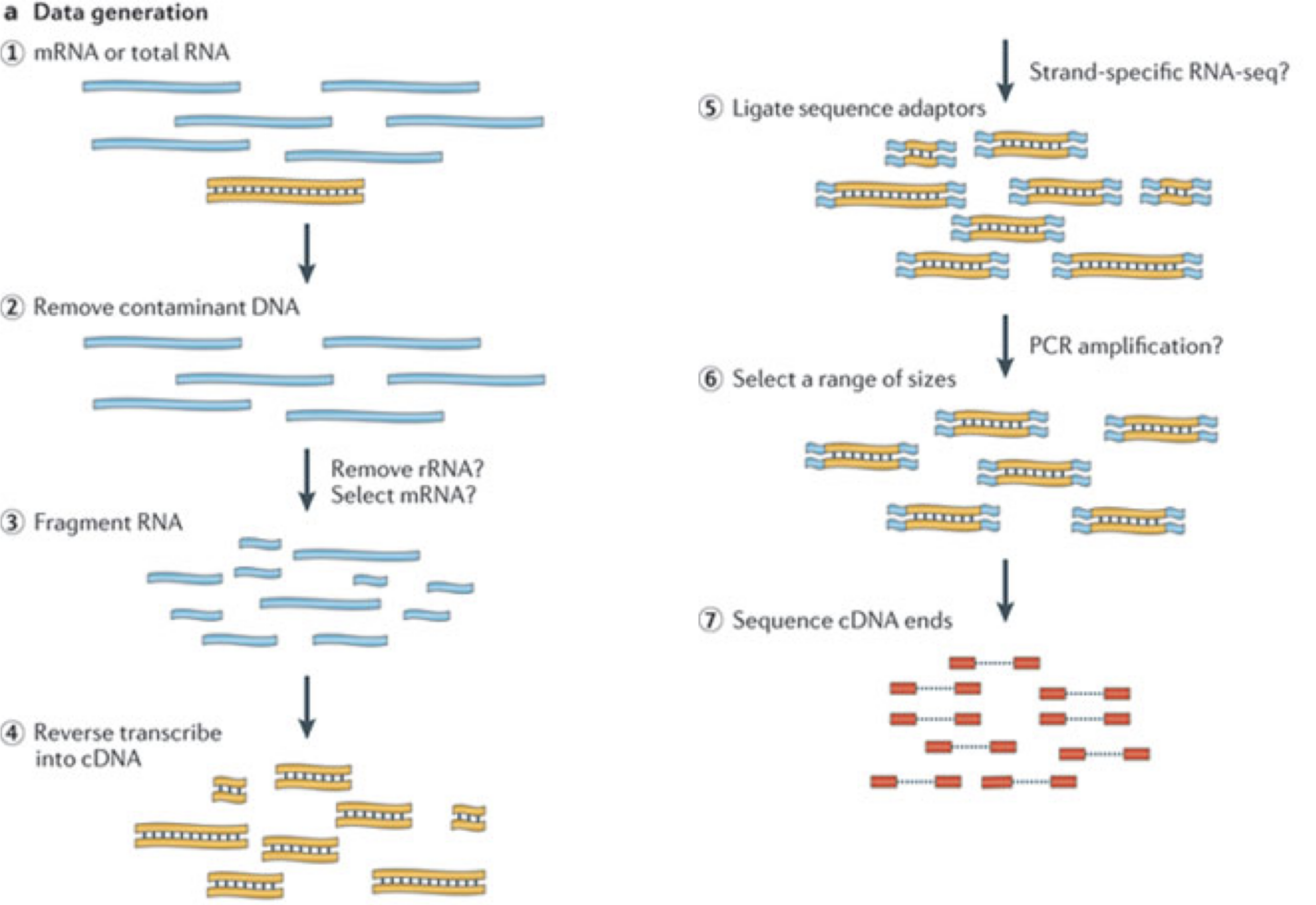
In a typical RNA-seq experiment, RNA molecules are first collected from a sample of interest. After a potential enrichment for molecules with polyA tails (predominantly mRNA), or depletion of otherwise highly abundant ribosomal RNA, the remaining molecules are fragmented into smaller pieces (there are also long-read protocols where entire molecules are considered, but those are not the focus of this lesson). It is important to keep in mind that because of the splicing excluding intronic sequences, an RNA molecule (and hence a generated fragment) may not correspond to an uninterrupted region of the genome. The RNA fragments are then reverse transcribed into cDNA, whereafter sequencing adapters are added to each end. These adapters allow the fragments to attach to the flow cell. Once attached, each fragment will be heavily amplified to generate a cluster of identical sequences on the flow cell. The sequencer then determines the sequence of the first 50-200 nucleotides of the cDNA fragments in each such cluster, starting from one end, which corresponds to a read. Many data sets are generated with so called paired-end protocols, in which the fragments are read from both ends. Millions of such reads (or pairs of reads) will be generated in an experiment, and these will be represented in a (pair of) FASTQ files. Each read is represented by four consecutive lines in such a file: first a line with a unique read identifier, next the inferred sequence of the read, then another identifier line, and finally a line containing the base quality for each inferred nucleotide, representing the probability that the nucleotide in the corresponding position has been correctly identified.
Challenge: Discuss the following points with your neighbor
- What are potential advantages and disadvantages of paired-end protocols compared to only sequencing one end of a fragment?
- What quality assessment can you think of that would be useful to perform on the FASTQ files with read sequences?
Experimental design considerations
Before starting to collect data, it is essential to take some time to think about the design of the experiment. Experimental design concerns the organization of experiments with the purpose of making sure that the right type of data, and enough of it, is available to answer the questions of interest as efficiently as possible. Aspects such as which conditions or sample groups to consider, how many replicates to collect, and how to plan the data collection in practice are important questions to consider. Many high-throughput biological experiments (including RNA-seq) are sensitive to ambient conditions, and it is often difficult to directly compare measurements that have been done on different days, by different analysts, in different centers, or using different batches of reagents. For this reason, it is very important to design experiments properly, to make it possible to disentangle different types of (primary and secondary) effects.

(figure from Lazic (2017)).
Challenge: Discuss with your neighbor
- Why is it essential to have replicates?
Importantly, not all replicates are equally useful, from a statistical point of view. One common way to classify the different types of replicates is as ‘biological’ and ‘technical’, where the latter are typically used to test the reproducibility of the measurement device, while biological replicates inform about the variability between different samples from a population of interest. Another scheme classifies replicates (or units) into ‘biological’, ‘experimental’ and ‘observational’. Here, biological units are entities we want to make inferences about (e.g., animals, persons). Replication of biological units is required to make a general statement of the effect of a treatment - we can not draw a conclusion about the effect of drug on a population of mice by studying a single mouse only. Experimental units are the smallest entities that can be independently assigned to a treatment (e.g., animal, litter, cage, well). Only replication of experimental units constitute true replication. Observational units, finally, are entities at which measurements are made.
To explore the impact of experimental design on the ability to answer questions of interest, we are going to use an interactive application, provided in the ConfoundingExplorer package.
Challenge
Launch the ConfoundingExplorer application and familiarize yourself with the interface.
Challenge
- For a balanced design (equal distribution of replicates between the two groups in each batch), what is the effect of increasing the strength of the batch effect? Does it matter whether one adjusts for the batch effect or not?
- For an increasingly unbalanced design (most or all replicates of one group coming from one batch), what is the effect of increasing the strength of the batch effect? Does it matter whether one adjusts for the batch effect or not?
RNA-seq quantification: from reads to count matrix

The read sequences contained in the FASTQ files from the sequencer are typically not directly useful as they are, since we do not have the information about which gene or transcript they originate from. Thus, the first processing step is to attempt to identify the location of origin for each read, and use this to obtain an estimate of the number of reads originating from a gene (or another features, such as an individual transcript). This can then be used as a proxy for the abundance, or expression level, of the gene. There is a plethora of RNA quantification pipelines, and the most common approaches can be categorized into three main types:
Align reads to the genome, and count the number of reads that map within the exons of each gene. This is the one of simplest methods. For species for which the transcriptome is poorly annotated, this would be the preferred approach. Example:
STARalignment to GRCm39 +RsubreadfeatureCountsAlign reads to the transcriptome, quantify transcript expression, and summarize transcript expression into gene expression. This approach can produce accurate quantification results (independent benchmarking), particularly for high-quality samples without DNA contamination. Example: RSEM quantification using
rsem-calculate-expression --staron the GENCODE GRCh38 transcriptome +tximportPseudoalign reads against the transcriptome, using the corresponding genome as a decoy, quantifying transcript expression in the process, and summarize the transcript-level expression into gene-level expression. The advantages of this approach include: computational efficiency, mitigation of the effect of DNA contamination, and GC bias correction. Example:
salmon quant --gcBias+tximport
At typical sequencing read depth, gene expression quantification is often more accurate than transcript expression quantification. However, differential gene expression analyses can be improved by having access also to transcript-level quantifications.
Other tools used in RNA-seq quantification include: TopHat2, bowtie2, kallisto, HTseq, among many others.
The choice of an appropriate RNA-seq quantification depends on the quality of the transcriptome annotation, the quality of the RNA-seq library preparation, the presence of contaminating sequences, among many factors. Often, it can be informative to compare the quantification results of multiple approaches.
Because the best quantification method is species- and experiment-dependent, and often requires large amounts of computing resources, this workshop will not cover any specifics of how to generate the counts. Instead, we recommend checking out the references above and consulting with a local bioinformatics expert if you need help.
Challenge: Discuss the following points with your neighbor
- Which of the mentioned RNA-Seq quantification tools have you heard about? Do you know other pros and cons of the methods?
- Have you done your own RNA-Seq experiment? If so, what quantification tool did you use and why did you choose it?
- Do you have access to specific tools / local bioinformatics expert / computational resources for quantification? If you don’t, how might you gain access?
Finding the reference sequences
In order to quantify abundances of known genes or transcripts from RNA-seq data, we need a reference database informing us of the sequence of these features, to which we can then compare our reads. This information can be obtained from different online repositories. It is highly recommended to choose one of these for a particular project, and not mix information from different sources. Depending on the quantification tool you have chosen, you will need different types of reference information. If you are aligning your reads to the genome and investigating the overlap with known annotated features, you will need the full genome sequence (provided in a fasta file) and a file that tells you the genomic location of each annotated feature (typically provided in a gtf file). If you are mapping your reads to the transcriptome, you will instead need a file with the sequence of each transcript (again, a fasta file).
- If you are working with mouse or human samples, the GENCODE project provides well-curated reference files.
- Ensembl provides reference files for a large set of organisms, including plants and fungi.
- UCSC also provides reference files for many organisms.
Challenge
Download the latest mouse transcriptome fasta file from GENCODE. What
do the entries look like? Tip: to read the file into R, consider the
readDNAStringSet() function from the
Biostrings package.
Where are we heading towards in this workshop?
During the coming two days, we will discuss and practice how to perform differential expression analysis with Bioconductor, and how to interpret the results. We will start from a count matrix, and thus assume that the initial quality assessment and quantification of gene expression have already been done. The outcome of a differential expression analysis is often represented using graphical representations, such as MA plots and heatmaps (see below for examples).
In the following episodes we will learn, among other things, how to generate and interpret these plots. It is also common to perform follow-up analyses to investigate whether there is a functional relationship among the top-ranked genes, so called gene set (enrichment) analysis, which will also be covered in a later episode.
- RNA-seq is a technique of measuring the amount of RNA expressed within a cell/tissue and state at a given time.
- Many choices have to be made when planning an RNA-seq experiment, such as whether to perform poly-A selection or ribosomal depletion, whether to apply a stranded or an unstranded protocol, and whether to sequence the reads in a single-end or paired-end fashion. Each of the choices have consequences for the processing and interpretation of the data.
- Many approaches exist for quantification of RNA-seq data. Some methods align reads to the genome and count the number of reads overlapping gene loci. Other methods map reads to the transcriptome and use a probabilistic approach to estimate the abundance of each gene or transcript.
- Information about annotated genes can be accessed via several sources, including Ensembl, UCSC and GENCODE.
Content from RStudio Project and Experimental Data
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- How do you use RStudio project to manage your analysis project?
- What is the most effective way to organize directories for an analysis project?
- How to download a dataset from the internet and save it as a file.
Objectives
- Create an RStudio project and the directories required for storing the files pertinent to an analysis project.
- Download the data set that will be used for the subsequent episodes.
Introduction
Typically, an analysis project begins with dataset files, a handful
of R scripts and output files in a directory. As the project advances,
complexity inevitably rises with the addition of more scripts, output
files, and possibly new datasets. The complexity is further amplified
when dealing with multiple versions of scripts and output files,
necessitating efficient organisation. If these are not well-managed from
the beginning, resuming the project after a break, or sharing the
project with someone else becomes challenging and time-consuming, as we
struggle to recall the project’s status and navigate the directory tree.
Additionally, without proper organisation, the project’s complexity
could lead to frequent use of the setwd function to switch
between different working directories, resulting in a disorganised
workspace.
In this lesson, we will first focus on an effective strategy for managing the files, both used and generated by our data analysis project, within a working directory.
What is a working directory?
A working directory in R is the default location on your computer where R looks for files to load or store any data you wish to save. More information can be found in our Introduction to data analysis with R and Bioconductor lesson.
Secondly, we will also learn how to leverage RStudio projects, a feature built-in to RStudio for managing our analysis project.
What is RStudio?
RStudio is a freely available integrated development environment (IDE), widely used by scientists and software developers for developing software or analysing datasets in R. If you require assistance with RStudio or its general usage, please refer to our Introduction to data analysis with R and Bioconductor lesson.
Finally, in this lesson, we will also learn to use the R function
download.file to download the data for the subsequent
episodes.
Structuring your working directory
For a more streamlined workflow, we suggest storing all files associated with an analysis in a specific directory, which will serve as your project’s working directory. Initially, this working directory should contain four distinct directories:
-
data: dedicated to storing raw data. This folder should ideally only house raw data and not be modified unless you receive a new dataset (even then, if you have the storage capacity, we suggest you retain the previous dataset as well in case you need it again in the future). For RNA-seq data analysis, this directory will typically contain*.fastqfiles and any related metadata files for the experiment. -
scripts: for storing the R scripts you’ve written and utilised for analysing the data. -
documents: for storing documents related to your analysis, such as a manuscript outline or meeting notes with your team. -
output: for storing intermediate or final results generated by the R scripts in thescriptsdirectory. Importantly, if you carry out data cleaning or pre-processing, the output should ideally be stored in this directory, as these no longer represent raw data.
As your project grows in complexity, you might find it necessary to create more directories or sub-directories. Nevertheless, the aforementioned four directories should serve as the foundation of your working directory.
Create the directories for subsequent episodes
Create a directory on your computer to serve as the working directory
for the rest of this episode and lesson (the workshop example uses a
directory called bio_rnaseq). Then, within this chosen
directory, create the four fundamental directories previously discussed
(data, scripts, documents, and
output).
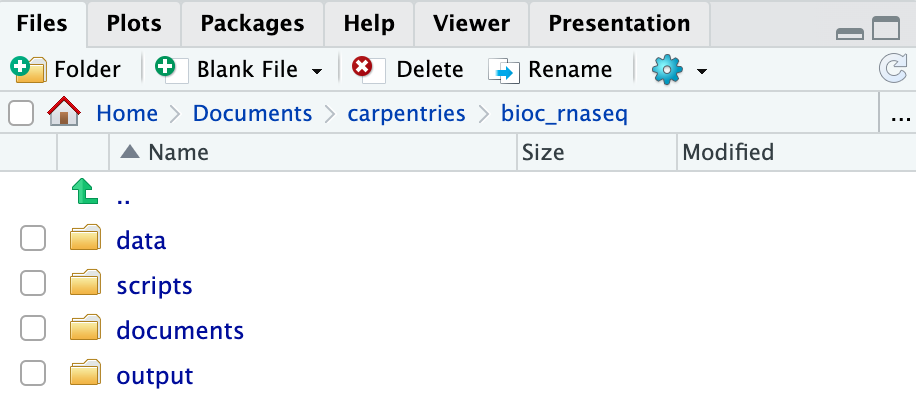
Using RStudio project to manage your working directory
As previously highlighted, RStudio project is a feature built-into
RStudio for managing your analysis project. It does so by storing
project-specific settings in an .Rproj file stored in your
project’s working directory. Loading these settings up into RStudio by
either opening the .Rproj file directly or through
RStudio’s open project option (from the menu bar, select
File > Open Project...) will automatically
set your working directory in R to the location of the
.Rproj file, essentially your project’s working
directory.
To create an RStudio project:
- Start RStudio.
- Navigate to the menu bar and select
File>New Project.... - Choose
Existing Directory. - Click
Browse...button, and select the directory you have previously chosen as the working directory for the analysis (i.e., the directory where the 4 essential directories reside). - Click
Create Projectat the bottom right of the window.
Upon completion of the steps above, you will find a
.Rproj file within your project’s working directory.
Moreover, the heading of your RStudio console should now also display
the absolute path of your project’s working directory, i.e., where the
.Rproj file resides, indicating that RStudio has set this
directory as your working directory in R.
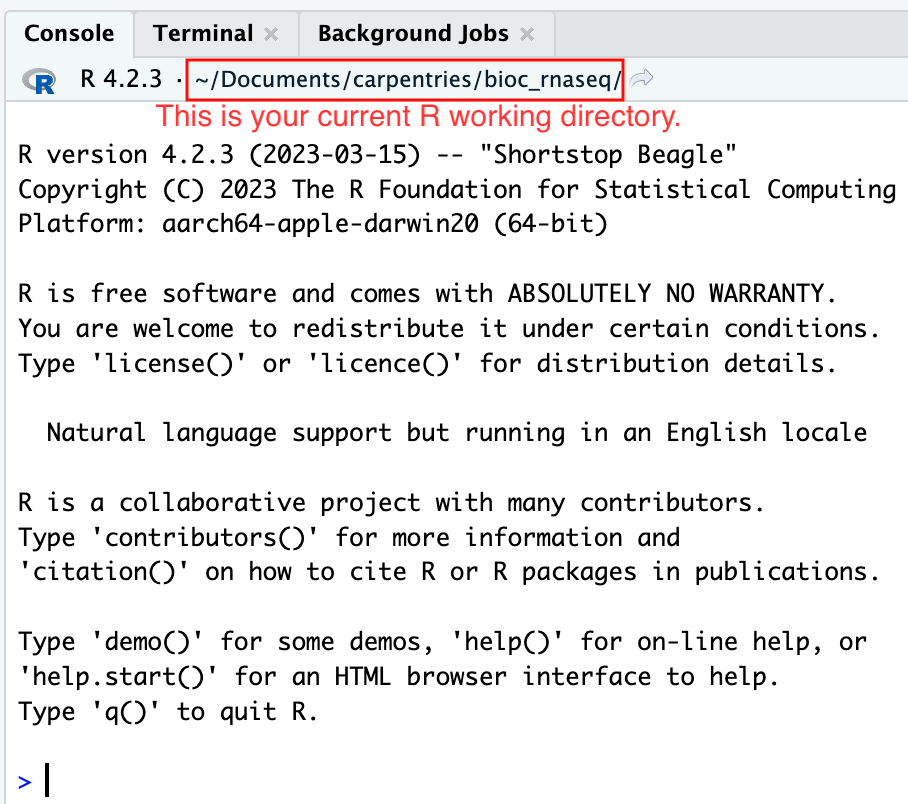
From this point forward, any R code that you execute that involves reading data from a file or saving data in a file will, by default, be directed to a path relative to your project’s working directory.
If you wish to close the project, perhaps to open another project,
create a new one, or take a break from the project, you can do so by
using to File > Close Project option
located in the menu bar. To open the project back up, either
double-click on the .Rproj file in the working directory, or open up
RStudio and using the File > Open Project
option in the menu bar.
Download the RNA-seq data for subsequent episodes
Finally, we will learn how to use R to download the RNA-seq data required for the subsequent episodes of the lesson. The dataset we will be using was generated to investigate the impact upper-respiratory infection have on changes in RNA transcription in the cerebellum and spinal cord of mice. This dataset was produced as part of the following study:
Blackmore, Stephen, et al. “Influenza infection triggers disease in a genetic model of experimental autoimmune encephalomyelitis.” Proceedings of the National Academy of Sciences 114.30 (2017): E6107-E6116.
The dataset is available at Gene Expression Omnibus (GEO), under the accession number GSE96870. Downloading data from GEO is not straightforward (and won’t be covered in this lesson). Hence, we have made the data available on our GitHub repository for easier access.
To download the files, we will use the R function
download.file, which necessitates at least two parameters:
url and destfile. The url
parameter is used to specify the address on the internet to download the
data from. The destfile parameter indicates where to save
the downloaded file and what the downloaded file should be named.
Let’s download one of the four data files needed for the remainder of
this lesson. The data file is located at https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_counts_cerebellum.csv.
We shall save the downloaded file in the data folder of our
working directory with the name
GSE96870_counts_cerebellum.csv.
R
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_counts_cerebellum.csv",
destfile = "data/GSE96870_counts_cerebellum.csv"
)
If you navigate to the data folder in your working
directory, you should now find a file named
GSE96870_counts_cerebellum.csv.
Download the remaining data set files
There are three more data set files we need to download for the remainder of this lesson.
| URL | Filename |
|---|---|
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_cerebellum.csv | GSE96870_coldata_cerebellum.csv |
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_all.csv | GSE96870_coldata_all.csv |
| https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_rowranges.tsv | GSE96870_rowranges.tsv |
Use the download.file function to download the files
into the data folder in your working directory.
R
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_cerebellum.csv",
destfile = "data/GSE96870_coldata_cerebellum.csv"
)
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_coldata_all.csv",
destfile = "data/GSE96870_coldata_all.csv"
)
download.file(
url = "https://github.com/carpentries-incubator/bioc-rnaseq/raw/main/episodes/data/GSE96870_rowranges.tsv",
destfile = "data/GSE96870_rowranges.tsv"
)
- Proper organisation of the files required for your project in a working directory is crucial for maintaining order and ensuring easy access in the future.
- RStudio project serves as a valuable tool for managing your project’s working directory and facilitating analysis.
- The
download.filefunction in R can be used for downloading datasets from the internet.
Content from Importing and annotating quantified data into R
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- How can one import quantified gene expression data into an object suitable for downstream statistical analysis in R?
- What types of gene identifiers are typically used, and how are mappings between them done?
Objectives
- Learn how to import the quantifications into a SummarizedExperiment object.
- Learn how to add additional gene annotations to the object.
Load packages
In this episode we will use some functions from add-on R packages. In
order to use them, we need to load them from our
library:
R
suppressPackageStartupMessages({
library(AnnotationDbi)
library(org.Mm.eg.db)
library(hgu95av2.db)
library(SummarizedExperiment)
})
If you get any error messages about
there is no package called 'XXXX' it means you have not
installed the package/s yet for this version of R. See the bottom of the
Summary
and Setup to install all the necessary packages for this workshop.
If you have to install, remember to re-run the library
commands above to load them.
Load data
In the last episode, we used R to download 4 files from the internet and saved them on our computer. But we do not have these files loaded into R yet so that we can work with them. The original experimental design in Blackmore et al. 2017 was fairly complex: 8 week old male and female C57BL/6 mice were collected at Day 0 (before influenza infection), Day 4 and Day 8 after influenza infection. From each mouse, cerebellum and spinal cord tissues were taken for RNA-seq. There were originally 4 mice per ‘Sex x Time x Tissue’ group, but a few were lost along the way resulting in a total of 45 samples. For this workshop, we are going to simplify the analysis by only using the 22 cerebellum samples. Expression quantification was done using STAR to align to the mouse genome and then counting reads that map to genes. In addition to the counts per gene per sample, we also need information on which sample belongs to which Sex/Time point/Replicate. And for the genes, it is helpful to have extra information called annotation. Let’s read in the data files that we downloaded in the last episode and start to explore them:
Counts
R
counts <- read.csv("data/GSE96870_counts_cerebellum.csv",
row.names = 1)
dim(counts)
OUTPUT
[1] 41786 22R
# View(counts)
Genes are in rows and samples are in columns, so we have counts for
41,786 genes and 22 samples. The View() command has been
commented out for the website, but running it will open a tab in RStudio
that lets us look at the data and even sort the table by a particular
column. However, the viewer cannot change the data inside the
counts object, so we can only look, not permanently sort
nor edit the entries. When finished, close the viewer using the X in the
tab. Looks like the rownames are gene symbols and the column names are
the GEO sample IDs, which are not very informative for telling us which
sample is what.
Sample annotations
Next read in the sample annotations. Because samples are in columns
in the count matrix, we will name the object coldata:
R
coldata <- read.csv("data/GSE96870_coldata_cerebellum.csv",
row.names = 1)
dim(coldata)
OUTPUT
[1] 22 10R
# View(coldata)
Now samples are in rows with the GEO sample IDs as the rownames, and
we have 10 columns of information. The columns that are the most useful
for this workshop are geo_accession (GEO sample IDs again),
sex and time.
Gene annotations
The counts only have gene symbols, which while short and somewhat
recognizable to the human brain, are not always good absolute
identifiers for exactly what gene was measured. For this we need
additional gene annotations that were provided by the authors. The
count and coldata files were in comma
separated value (.csv) format, but we cannot use that for our gene
annotation file because the descriptions can contain commas that would
prevent a .csv file from being read in correctly. Instead the gene
annotation file is in tab separated value (.tsv) format. Likewise, the
descriptions can contain the single quote ' (e.g., 5’),
which by default R assumes indicates a character entry. So we have to
use a more generic function read.delim() with extra
arguments to specify that we have tab-separated data
(sep = "\t") with no quotes used (quote = "").
We also put in other arguments to specify that the first row contains
our column names (header = TRUE), the gene symbols that
should be our row.names are in the 5th column
(row.names = 5), and that NCBI’s species-specific gene ID
(i.e., ENTREZID) should be read in as character data even though they
look like numbers (colClasses argument). You can look up
this details on available arguments by simply entering the function name
starting with question mark. (e.g., ?read.delim)
R
rowranges <- read.delim("data/GSE96870_rowranges.tsv",
sep = "\t",
colClasses = c(ENTREZID = "character"),
header = TRUE,
quote = "",
row.names = 5)
dim(rowranges)
OUTPUT
[1] 41786 7R
# View(rowranges)
For each of the 41,786 genes, we have the seqnames
(e.g., chromosome number), start and end
positions, strand, ENTREZID, gene product
description (product) and the feature type
(gbkey). These gene-level metadata are useful for the
downstream analysis. For example, from the gbkey column, we
can check what types of genes and how many of them are in our
dataset:
R
table(rowranges$gbkey)
OUTPUT
C_region D_segment exon J_segment misc_RNA
20 23 4008 94 1988
mRNA ncRNA precursor_RNA rRNA tRNA
21198 12285 1187 35 413
V_segment
535 Challenge: Discuss the following points with your neighbor
- How are the 3 objects
counts,coldataandrowrangesrelated to each other in terms of their rows and columns? - If you only wanted to analyse the mRNA genes, what would you have to do keep just those (generally speaking, not exact codes)?
- If you decided the first two samples were outliers, what would you have to do to remove those (generally speaking, not exact codes)?
- In
counts, the rows are genes just like the rows inrowranges. The columns incountsare the samples, but this corresponds to the rows incoldata. - I would have to remember subset both the rows of
countsand the rows ofrowrangesto just the mRNA genes. - I would have to remember to subset both the columns of
countsbut the rows ofcoldatato exclude the first two samples.
You can see how keeping related information in separate objects could
easily lead to mis-matches between our counts, gene annotations and
sample annotations. This is why Bioconductor has created a specialized
S4 class called a SummarizedExperiment. The details of a
SummarizedExperiment were covered extensively at the end of
the Introduction
to data analysis with R and Bioconductor workshop. As a reminder,
let’s take a look at the figure below representing the anatomy of the
SummarizedExperiment class:

It is designed to hold any type of quantitative ’omics data
(assays) along with linked sample annotations
(colData) and feature annotations with
(rowRanges) or without (rowData) chromosome,
start and stop positions. Once these three tables are (correctly!)
linked, subsetting either samples and/or features will correctly subset
the assay, colData and rowRanges.
Additionally, most Bioconductor packages are built around the same core
data infrastructure so they will recognize and be able to manipulate
SummarizedExperiment objects. Two of the most popular
RNA-seq statistical analysis packages have their own extended S4 classes
similar to a SummarizedExperiment with the additional slots
for statistical results: DESeq2’s
DESeqDataSet and edgeR’s
DGEList. No matter which one you end up using for
statistical analysis, you can start by putting your data in a
SummarizedExperiment.
Assemble SummarizedExperiment
We will create a SummarizedExperiment from these
objects:
- The
countobject will be saved inassaysslot
- The
coldataobject with sample information will be stored incolDataslot (sample metadata)
- The
rowrangesobject describing the genes will be stored inrowRangesslot (features metadata)
Before we put them together, you ABSOLUTELY MUST MAKE SURE THE
SAMPLES AND GENES ARE IN THE SAME ORDER! Even though we saw that
count and coldata had the same number of
samples and count and rowranges had the same
number of genes, we never explicitly checked to see if they were in the
same order. One quick way to check:
R
all.equal(colnames(counts), rownames(coldata)) # samples
OUTPUT
[1] TRUER
all.equal(rownames(counts), rownames(rowranges)) # genes
OUTPUT
[1] TRUER
# If the first is not TRUE, you can match up the samples/columns in
# counts with the samples/rows in coldata like this (which is fine
# to run even if the first was TRUE):
tempindex <- match(colnames(counts), rownames(coldata))
coldata <- coldata[tempindex, ]
# Check again:
all.equal(colnames(counts), rownames(coldata))
OUTPUT
[1] TRUEChallenge
If the features (i.e., genes) in the assay (e.g.,
counts) and the gene annotation table (e.g.,
rowranges) are different, how can we fix them? Write the
codes.
R
tempindex <- match(rownames(counts), rownames(rowranges))
rowranges <- rowranges[tempindex, ]
all.equal(rownames(counts), rownames(rowranges))
Once we have verified that samples and genes are in the same order,
we can then create our SummarizedExperiment object.
R
# One final check:
stopifnot(rownames(rowranges) == rownames(counts), # features
rownames(coldata) == colnames(counts)) # samples
se <- SummarizedExperiment(
assays = list(counts = as.matrix(counts)),
rowRanges = as(rowranges, "GRanges"),
colData = coldata
)
Because matching the genes and samples is so important, the
SummarizedExperiment() constructor does some internal check
to make sure they contain the same number of genes/samples and the
sample/row names match. If not, you will get some error messages:
R
# wrong number of samples:
bad1 <- SummarizedExperiment(
assays = list(counts = as.matrix(counts)),
rowRanges = as(rowranges, "GRanges"),
colData = coldata[1:3,]
)
ERROR
Error in `validObject()`:
! invalid class "SummarizedExperiment" object:
nb of cols in 'assay' (22) must equal nb of rows in 'colData' (3)R
# same number of genes but in different order:
bad2 <- SummarizedExperiment(
assays = list(counts = as.matrix(counts)),
rowRanges = as(rowranges[c(2:nrow(rowranges), 1),], "GRanges"),
colData = coldata
)
ERROR
Error in `SummarizedExperiment()`:
! the rownames and colnames of the supplied assay(s) must be NULL or identical
to those of the RangedSummarizedExperiment object (or derivative) to
constructA brief recap of how to access the various data slots in a
SummarizedExperiment and how to make some
manipulations:
R
# Access the counts
head(assay(se))
OUTPUT
GSM2545336 GSM2545337 GSM2545338 GSM2545339 GSM2545340 GSM2545341
Xkr4 1891 2410 2159 1980 1977 1945
LOC105243853 0 0 1 4 0 0
LOC105242387 204 121 110 120 172 173
LOC105242467 12 5 5 5 2 6
Rp1 2 2 0 3 2 1
Sox17 251 239 218 220 261 232
GSM2545342 GSM2545343 GSM2545344 GSM2545345 GSM2545346 GSM2545347
Xkr4 1757 2235 1779 1528 1644 1585
LOC105243853 1 3 3 0 1 3
LOC105242387 177 130 131 160 180 176
LOC105242467 3 2 2 2 1 2
Rp1 3 1 1 2 2 2
Sox17 179 296 233 271 205 230
GSM2545348 GSM2545349 GSM2545350 GSM2545351 GSM2545352 GSM2545353
Xkr4 2275 1881 2584 1837 1890 1910
LOC105243853 1 0 0 1 1 0
LOC105242387 161 154 124 221 272 214
LOC105242467 2 4 7 1 3 1
Rp1 3 6 5 3 5 1
Sox17 302 286 325 201 267 322
GSM2545354 GSM2545362 GSM2545363 GSM2545380
Xkr4 1771 2315 1645 1723
LOC105243853 0 1 0 1
LOC105242387 124 189 223 251
LOC105242467 4 2 1 4
Rp1 3 3 1 0
Sox17 273 197 310 246R
dim(assay(se))
OUTPUT
[1] 41786 22R
# The above works now because we only have one assay, "counts"
# But if there were more than one assay, we would have to specify
# which one like so:
head(assay(se, "counts"))
OUTPUT
GSM2545336 GSM2545337 GSM2545338 GSM2545339 GSM2545340 GSM2545341
Xkr4 1891 2410 2159 1980 1977 1945
LOC105243853 0 0 1 4 0 0
LOC105242387 204 121 110 120 172 173
LOC105242467 12 5 5 5 2 6
Rp1 2 2 0 3 2 1
Sox17 251 239 218 220 261 232
GSM2545342 GSM2545343 GSM2545344 GSM2545345 GSM2545346 GSM2545347
Xkr4 1757 2235 1779 1528 1644 1585
LOC105243853 1 3 3 0 1 3
LOC105242387 177 130 131 160 180 176
LOC105242467 3 2 2 2 1 2
Rp1 3 1 1 2 2 2
Sox17 179 296 233 271 205 230
GSM2545348 GSM2545349 GSM2545350 GSM2545351 GSM2545352 GSM2545353
Xkr4 2275 1881 2584 1837 1890 1910
LOC105243853 1 0 0 1 1 0
LOC105242387 161 154 124 221 272 214
LOC105242467 2 4 7 1 3 1
Rp1 3 6 5 3 5 1
Sox17 302 286 325 201 267 322
GSM2545354 GSM2545362 GSM2545363 GSM2545380
Xkr4 1771 2315 1645 1723
LOC105243853 0 1 0 1
LOC105242387 124 189 223 251
LOC105242467 4 2 1 4
Rp1 3 3 1 0
Sox17 273 197 310 246R
# Access the sample annotations
colData(se)
OUTPUT
DataFrame with 22 rows and 10 columns
title geo_accession organism age sex
<character> <character> <character> <character> <character>
GSM2545336 CNS_RNA-seq_10C GSM2545336 Mus musculus 8 weeks Female
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545339 CNS_RNA-seq_13C GSM2545339 Mus musculus 8 weeks Female
GSM2545340 CNS_RNA-seq_14C GSM2545340 Mus musculus 8 weeks Male
... ... ... ... ... ...
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545354 CNS_RNA-seq_4C GSM2545354 Mus musculus 8 weeks Male
GSM2545362 CNS_RNA-seq_5C GSM2545362 Mus musculus 8 weeks Female
GSM2545363 CNS_RNA-seq_6C GSM2545363 Mus musculus 8 weeks Male
GSM2545380 CNS_RNA-seq_9C GSM2545380 Mus musculus 8 weeks Female
infection strain time tissue mouse
<character> <character> <character> <character> <integer>
GSM2545336 InfluenzaA C57BL/6 Day8 Cerebellum 14
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545339 InfluenzaA C57BL/6 Day4 Cerebellum 15
GSM2545340 InfluenzaA C57BL/6 Day4 Cerebellum 18
... ... ... ... ... ...
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4
GSM2545354 NonInfected C57BL/6 Day0 Cerebellum 2
GSM2545362 InfluenzaA C57BL/6 Day4 Cerebellum 20
GSM2545363 InfluenzaA C57BL/6 Day4 Cerebellum 12
GSM2545380 InfluenzaA C57BL/6 Day8 Cerebellum 19R
dim(colData(se))
OUTPUT
[1] 22 10R
# Access the gene annotations
head(rowData(se))
OUTPUT
DataFrame with 6 rows and 3 columns
ENTREZID product gbkey
<character> <character> <character>
Xkr4 497097 X Kell blood group p.. mRNA
LOC105243853 105243853 uncharacterized LOC1.. ncRNA
LOC105242387 105242387 uncharacterized LOC1.. ncRNA
LOC105242467 105242467 lipoxygenase homolog.. mRNA
Rp1 19888 retinitis pigmentosa.. mRNA
Sox17 20671 SRY (sex determining.. mRNAR
dim(rowData(se))
OUTPUT
[1] 41786 3R
# Make better sample IDs that show sex, time and mouse ID:
se$Label <- paste(se$sex, se$time, se$mouse, sep = "_")
se$Label
OUTPUT
[1] "Female_Day8_14" "Female_Day0_9" "Female_Day0_10" "Female_Day4_15"
[5] "Male_Day4_18" "Male_Day8_6" "Female_Day8_5" "Male_Day0_11"
[9] "Female_Day4_22" "Male_Day4_13" "Male_Day8_23" "Male_Day8_24"
[13] "Female_Day0_8" "Male_Day0_7" "Male_Day4_1" "Female_Day8_16"
[17] "Female_Day4_21" "Female_Day0_4" "Male_Day0_2" "Female_Day4_20"
[21] "Male_Day4_12" "Female_Day8_19"R
colnames(se) <- se$Label
# Our samples are not in order based on sex and time
se$Group <- paste(se$sex, se$time, sep = "_")
se$Group
OUTPUT
[1] "Female_Day8" "Female_Day0" "Female_Day0" "Female_Day4" "Male_Day4"
[6] "Male_Day8" "Female_Day8" "Male_Day0" "Female_Day4" "Male_Day4"
[11] "Male_Day8" "Male_Day8" "Female_Day0" "Male_Day0" "Male_Day4"
[16] "Female_Day8" "Female_Day4" "Female_Day0" "Male_Day0" "Female_Day4"
[21] "Male_Day4" "Female_Day8"R
# change this to factor data with the levels in order
# that we want, then rearrange the se object:
se$Group <- factor(se$Group, levels = c("Female_Day0","Male_Day0",
"Female_Day4","Male_Day4",
"Female_Day8","Male_Day8"))
se <- se[, order(se$Group)]
colData(se)
OUTPUT
DataFrame with 22 rows and 12 columns
title geo_accession organism age
<character> <character> <character> <character>
Female_Day0_9 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks
Female_Day0_10 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks
Female_Day0_8 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks
Female_Day0_4 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks
Male_Day0_11 CNS_RNA-seq_20C GSM2545343 Mus musculus 8 weeks
... ... ... ... ...
Female_Day8_16 CNS_RNA-seq_2C GSM2545351 Mus musculus 8 weeks
Female_Day8_19 CNS_RNA-seq_9C GSM2545380 Mus musculus 8 weeks
Male_Day8_6 CNS_RNA-seq_17C GSM2545341 Mus musculus 8 weeks
Male_Day8_23 CNS_RNA-seq_25C GSM2545346 Mus musculus 8 weeks
Male_Day8_24 CNS_RNA-seq_26C GSM2545347 Mus musculus 8 weeks
sex infection strain time tissue
<character> <character> <character> <character> <character>
Female_Day0_9 Female NonInfected C57BL/6 Day0 Cerebellum
Female_Day0_10 Female NonInfected C57BL/6 Day0 Cerebellum
Female_Day0_8 Female NonInfected C57BL/6 Day0 Cerebellum
Female_Day0_4 Female NonInfected C57BL/6 Day0 Cerebellum
Male_Day0_11 Male NonInfected C57BL/6 Day0 Cerebellum
... ... ... ... ... ...
Female_Day8_16 Female InfluenzaA C57BL/6 Day8 Cerebellum
Female_Day8_19 Female InfluenzaA C57BL/6 Day8 Cerebellum
Male_Day8_6 Male InfluenzaA C57BL/6 Day8 Cerebellum
Male_Day8_23 Male InfluenzaA C57BL/6 Day8 Cerebellum
Male_Day8_24 Male InfluenzaA C57BL/6 Day8 Cerebellum
mouse Label Group
<integer> <character> <factor>
Female_Day0_9 9 Female_Day0_9 Female_Day0
Female_Day0_10 10 Female_Day0_10 Female_Day0
Female_Day0_8 8 Female_Day0_8 Female_Day0
Female_Day0_4 4 Female_Day0_4 Female_Day0
Male_Day0_11 11 Male_Day0_11 Male_Day0
... ... ... ...
Female_Day8_16 16 Female_Day8_16 Female_Day8
Female_Day8_19 19 Female_Day8_19 Female_Day8
Male_Day8_6 6 Male_Day8_6 Male_Day8
Male_Day8_23 23 Male_Day8_23 Male_Day8
Male_Day8_24 24 Male_Day8_24 Male_Day8 R
# Finally, also factor the Label column to keep in order in plots:
se$Label <- factor(se$Label, levels = se$Label)
Challenge
- How many samples are there for each level of the
Infectionvariable? - Create 2 objects named
se_infectedandse_noninfectedcontaining a subset ofsewith only infected and non-infected samples, respectively. Then, calculate the mean expression levels of the first 500 genes for each object, and use thesummary()function to explore the distribution of expression levels for infected and non-infected samples based on these genes. - How many samples represent female mice infected with Influenza A on day 8?
R
# 1
table(se$infection)
OUTPUT
InfluenzaA NonInfected
15 7 R
# 2
se_infected <- se[, se$infection == "InfluenzaA"]
se_noninfected <- se[, se$infection == "NonInfected"]
means_infected <- rowMeans(assay(se_infected)[1:500, ])
means_noninfected <- rowMeans(assay(se_noninfected)[1:500, ])
summary(means_infected)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000e+00 1.333e-01 2.867e+00 7.641e+02 3.374e+02 1.890e+04 R
summary(means_noninfected)
OUTPUT
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000e+00 1.429e-01 3.143e+00 7.710e+02 3.666e+02 2.001e+04 R
# 3
ncol(se[, se$sex == "Female" & se$infection == "InfluenzaA" & se$time == "Day8"])
OUTPUT
[1] 4Save SummarizedExperiment
This was a bit of code and time to create our
SummarizedExperiment object. We will need to keep using it
throughout the workshop, so it can be useful to save it as an actual
single file on our computer to read it back in to R’s memory if we have
to shut down RStudio. To save an R-specific file we can use the
saveRDS() function and later read it back into R using the
readRDS() function.
R
saveRDS(se, "data/GSE96870_se.rds")
rm(se) # remove the object!
se <- readRDS("data/GSE96870_se.rds")
Data provenance and reproducibility
We have now created an external .rds file that represents our RNA-Seq data in a format that can be read into R and used by various packages for our analyses. But we should still keep a record of the codes that created the .rds file from the 3 files we downloaded from the internet. But what is the provenance of those files - i.e, where did they come from and how were they made? The original counts and gene information were deposited in the GEO public database, accession number GSE96870. But these counts were generated by running alignment/quantification programs on the also-deposited fastq files that hold the sequence base calls and quality scores, which in turn were generated by a specific sequencing machine using some library preparation method on RNA extracted from samples collected in a particular experiment. Whew!
If you conducted the original experiment ideally you would have the
complete record of where and how the data were generated. But you might
use publicly-available data sets so the best you can do is to keep track
of what original files you got from where and what manipulations you
have done to them. Using R codes to keep track of everything is an
excellent way to be able to reproduce the entire analysis from the
original input files. The exact results you get can differ depending on
the R version, add-on package versions and even what operating system
you use, so make sure to keep track of all this information as well by
running sessionInfo() and recording the output (see example
at end of lesson).
Challenge: How to subset to mRNA genes
Before, we conceptually discussed subsetting to only the mRNA genes.
Now that we have our SummarizedExperiment object, it
becomes much easier to write the codes to subset se to a
new object called se_mRNA that contains only the genes/rows
where the rowData(se)$gbkey is equal to mRNA. Write the
codes and then check you correctly got the 21,198 mRNA genes:
R
se_mRNA <- se[rowData(se)$gbkey == "mRNA" , ]
dim(se_mRNA)
OUTPUT
[1] 21198 22Gene Annotations
Depending on who generates your count data, you might not have a nice file of additional gene annotations. There may only be the count row names, which could be gene symbols or ENTREZIDs or another database’s ID. Characteristics of gene annotations differ based on their annotation strategies and information sources. For example, RefSeq human gene models (i.e., Entrez from NCBI) are well supported and broadly used in various studies. The UCSC Known Genes dataset is based on protein data from Swiss-Prot/TrEMBL (UniProt) and the associated mRNA data from GenBank, and serves as a foundation for the UCSC Genome Browser. Ensembl genes contain both automated genome annotation and manual curation.
You can find more information in Bioconductor Annotation Workshop material.
Bioconductor has many packages and functions that can help you to get additional annotation information for your genes. The available resources are covered in more detail in Episode 7 Gene set enrichment analysis.
Here, we will introduce one of the gene ID mapping functions,
mapIds:
mapIds(annopkg, keys, column, keytype, ..., multiVals)Where
-
annopkg is the annotation package
-
keys are the IDs that we know
-
column is the value we want
- keytype is the type of key used
R
mapIds(org.Mm.eg.db, keys = "497097", column = "SYMBOL", keytype = "ENTREZID")
OUTPUT
'select()' returned 1:1 mapping between keys and columnsOUTPUT
497097
"Xkr4" Different from the select() function,
mapIds() function handles 1:many mapping between keys and
columns through an additional argument, multiVals. The
below example demonstrate this functionality using the
hgu95av2.db package, an Affymetrix Human Genome U95 Set
annotation data.
R
keys <- head(keys(hgu95av2.db, "ENTREZID"))
last <- function(x){x[[length(x)]]}
mapIds(hgu95av2.db, keys = keys, column = "ALIAS", keytype = "ENTREZID")
OUTPUT
'select()' returned 1:many mapping between keys and columnsOUTPUT
10 100 1000 10000 100008586 10001
"AAC2" "ADA1" "ACOGS" "MPPH" "GAGE-12F" "ARC33" R
# When there is 1:many mapping, the default behavior was
# to output the first match. This can be changed to a function,
# which we defined above to give us the last match:
mapIds(hgu95av2.db, keys = keys, column = "ALIAS", keytype = "ENTREZID", multiVals = last)
OUTPUT
'select()' returned 1:many mapping between keys and columnsOUTPUT
10 100 1000 10000 100008586 10001
"NAT2" "ADA" "CDH2" "AKT3" "GAGE12F" "MED6" R
# Or we can get back all the many mappings:
mapIds(hgu95av2.db, keys = keys, column = "ALIAS", keytype = "ENTREZID", multiVals = "list")
OUTPUT
'select()' returned 1:many mapping between keys and columnsOUTPUT
$`10`
[1] "AAC2" "NAT-2" "PNAT" "NAT2"
$`100`
[1] "ADA1" "ADA"
$`1000`
[1] "ACOGS" "ADHD8" "ARVD14" "CD325" "CDHN" "CDw325" "NCAD" "CDH2"
$`10000`
[1] "MPPH" "MPPH2" "PKB-GAMMA" "PKBG" "PRKBG"
[6] "RAC-PK-gamma" "RAC-gamma" "STK-2" "AKT3"
$`100008586`
[1] "GAGE-12F" "GAGE12F"
$`10001`
[1] "ARC33" "NY-REN-28" "MED6" Session info
R
sessionInfo()
OUTPUT
R version 4.6.0 (2026-04-24)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] hgu95av2.db_3.13.0 org.Hs.eg.db_3.23.1
[3] org.Mm.eg.db_3.23.0 AnnotationDbi_1.74.0
[5] SummarizedExperiment_1.42.0 Biobase_2.72.0
[7] MatrixGenerics_1.24.0 matrixStats_1.5.0
[9] GenomicRanges_1.64.0 Seqinfo_1.2.0
[11] IRanges_2.46.0 S4Vectors_0.50.1
[13] BiocGenerics_0.58.1 generics_0.1.4
[15] knitr_1.51
loaded via a namespace (and not attached):
[1] Matrix_1.7-5 bit_4.6.0 crayon_1.5.3
[4] compiler_4.6.0 BiocManager_1.30.27 renv_1.2.3
[7] blob_1.3.0 Biostrings_2.80.1 png_0.1-9
[10] yaml_2.3.12 fastmap_1.2.0 lattice_0.22-9
[13] R6_2.6.1 XVector_0.52.0 S4Arrays_1.12.0
[16] DelayedArray_0.38.2 DBI_1.3.0 pillar_1.11.1
[19] rlang_1.3.0 KEGGREST_1.52.2 cachem_1.1.0
[22] xfun_0.60 bit64_4.8.2 otel_0.2.0
[25] SparseArray_1.12.2 RSQLite_3.53.3 memoise_2.0.1
[28] cli_3.6.6 grid_4.6.0 lifecycle_1.0.5
[31] vctrs_0.7.3 glue_1.8.1 evaluate_1.0.5
[34] abind_1.4-8 httr_1.4.8 pkgconfig_2.0.3
[37] tools_4.6.0 - Depending on the gene expression quantification tool used, there are
different ways (often distributed in Bioconductor packages) to read the
output into a
SummarizedExperimentorDGEListobject for further processing in R. - Stable gene identifiers such as Ensembl or Entrez IDs should preferably be used as the main identifiers throughout an RNA-seq analysis, with gene symbols added for easier interpretation.
Content from Exploratory analysis and quality control
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- Why is exploratory analysis an essential part of an RNA-seq analysis?
- How should one preprocess the raw count matrix for exploratory
analysis?
- Are two dimensions sufficient to represent your data?
Objectives
- Learn how to explore the gene expression matrix and perform common quality control steps.
- Learn how to set up an interactive application for exploratory analysis.
Load packages
Assuming you just started RStudio again, load some packages we will
use in this lesson along with the SummarizedExperiment
object we created in the last lesson.
R
suppressPackageStartupMessages({
library(SummarizedExperiment)
library(DESeq2)
library(vsn)
library(ggplot2)
library(ComplexHeatmap)
library(RColorBrewer)
library(hexbin)
library(iSEE)
})
R
se <- readRDS("data/GSE96870_se.rds")
Remove unexpressed genes
Exploratory analysis is crucial for quality control and to get to know our data. It can help us detect quality problems, sample swaps and contamination, as well as give us a sense of the most salient patterns present in the data. In this episode, we will learn about two common ways of performing exploratory analysis for RNA-seq data; namely clustering and principal component analysis (PCA). These tools are in no way limited to (or developed for) analysis of RNA-seq data. However, there are certain characteristics of count assays that need to be taken into account when they are applied to this type of data. First of all, not all mouse genes in the genome will be expressed in our Cerebellum samples. There are many different threshold you could use to say whether a gene’s expression was detectable or not; here we are going to use a very minimal one that if a gene does not have more than 5 counts total across all samples, there is simply not enough data to be able to do anything with it anyway.
R
nrow(se)
OUTPUT
[1] 41786R
# Remove genes/rows that do not have > 5 total counts
se <- se[rowSums(assay(se, "counts")) > 5, ]
nrow(se)
OUTPUT
[1] 27430Challenge: What kind of genes survived this filtering?
Last episode we discussed subsetting down to only mRNA genes. Here we subsetted based on a minimal expression level.
- How many of each type of gene survived the filtering?
- Compare the number of genes that survived filtering using different thresholds.
- What are pros and cons of more aggressive filtering? What are important considerations?
R
table(rowData(se)$gbkey)
OUTPUT
C_region exon J_segment misc_RNA mRNA
14 1765 14 1539 16859
ncRNA precursor_RNA rRNA tRNA V_segment
6789 362 2 64 22 R
nrow(se) # represents the number of genes using 5 as filtering threshold
OUTPUT
[1] 27430R
length(which(rowSums(assay(se, "counts")) > 10))
OUTPUT
[1] 25736R
length(which(rowSums(assay(se, "counts")) > 20))
OUTPUT
[1] 23860- Cons: Risk of removing interesting information Pros:
- Not or lowly expressed genes are unlikely to be biological meaningful.
- Reduces number of statistical tests (multiple testing).
- More reliable estimation of mean-variance relationship
Potential considerations: - Is a gene expressed in both groups? - How many samples of each group express a gene?
Library size differences
Differences in the total number of reads assigned to genes between samples typically occur for technical reasons. In practice, it means that we can not simply compare a gene’s raw read count directly between samples and conclude that a sample with a higher read count also expresses the gene more strongly - the higher count may be caused by an overall higher number of reads in that sample. In the rest of this section, we will use the term library size to refer to the total number of reads assigned to genes for a sample. First we should compare the library sizes of all samples.
R
# Add in the sum of all counts
se$libSize <- colSums(assay(se))
# Plot the libSize by using R's native pipe |>
# to extract the colData, turn it into a regular
# data frame then send to ggplot:
colData(se) |>
as.data.frame() |>
ggplot(aes(x = Label, y = libSize / 1e6, fill = Group)) +
geom_bar(stat = "identity") + theme_bw() +
labs(x = "Sample", y = "Total count in millions") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1))
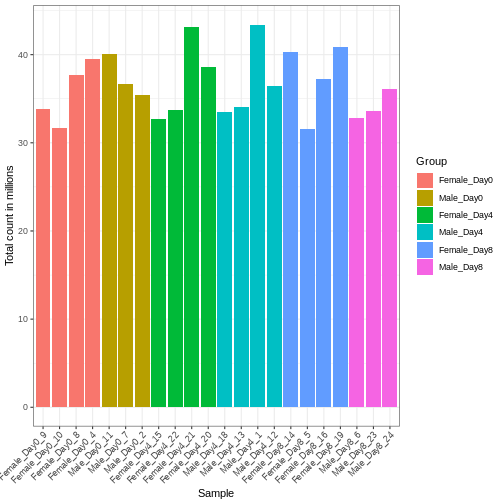
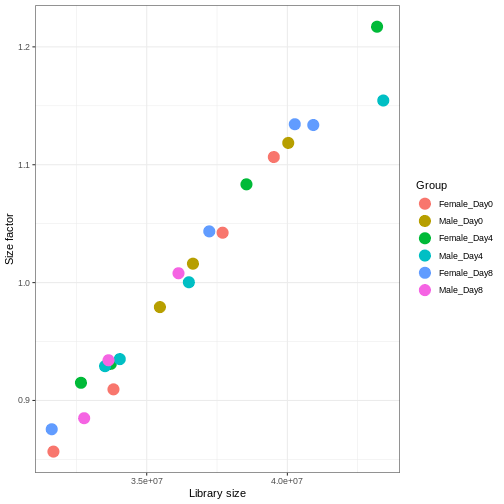
We need to adjust for the differences in library size between samples, to avoid drawing incorrect conclusions. The way this is typically done for RNA-seq data can be described as a two-step procedure. First, we estimate size factors - sample-specific correction factors such that if the raw counts were to be divided by these factors, the resulting values would be more comparable across samples. Next, these size factors are incorporated into the statistical analysis of the data. It is important to pay close attention to how this is done in practice for a given analysis method. Sometimes the division of the counts by the size factors needs to be done explicitly by the analyst. Other times (as we will see for the differential expression analysis) it is important that they are provided separately to the analysis tool, which will then use them appropriately in the statistical model.
With DESeq2, size factors are calculated using the
estimateSizeFactors() function. The size factors estimated
by this function combines an adjustment for differences in library sizes
with an adjustment for differences in the RNA composition of the
samples. The latter is important due to the compositional nature of
RNA-seq data. There is a fixed number of reads to distribute between the
genes, and if a single (or a few) very highly expressed gene consume a
large part of the reads, all other genes will consequently receive very
low counts. We now switch our SummarizedExperiment object
over to a DESeqDataSet as it has the internal structure to
store these size factors. We also need to tell it our main experiment
design, which is sex and time:
R
dds <- DESeq2::DESeqDataSet(se, design = ~ sex + time)
WARNING
Warning in DESeq2::DESeqDataSet(se, design = ~sex + time): some variables in
design formula are characters, converting to factorsR
dds <- estimateSizeFactors(dds)
# Plot the size factors against library size
# and look for any patterns by group:
ggplot(data.frame(libSize = colSums(assay(dds)),
sizeFactor = sizeFactors(dds),
Group = dds$Group),
aes(x = libSize, y = sizeFactor, col = Group)) +
geom_point(size = 5) + theme_bw() +
labs(x = "Library size", y = "Size factor")
Transform data
There is a rich literature on methods for exploratory analysis. Most of these work best in situations where the variance of the input data (here, each gene) is relatively independent of the average value. For read count data such as RNA-seq, this is not the case. In fact, the variance increases with the average read count.
R
meanSdPlot(assay(dds), ranks = FALSE)
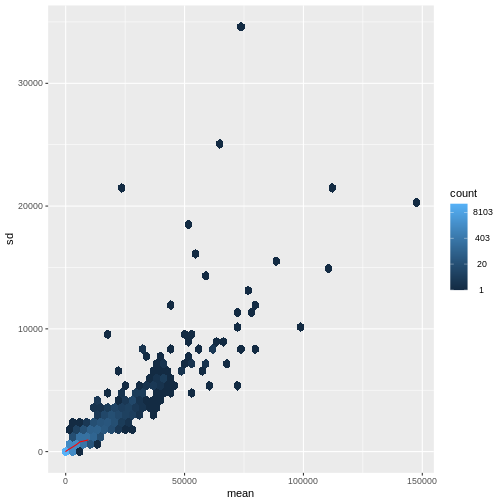
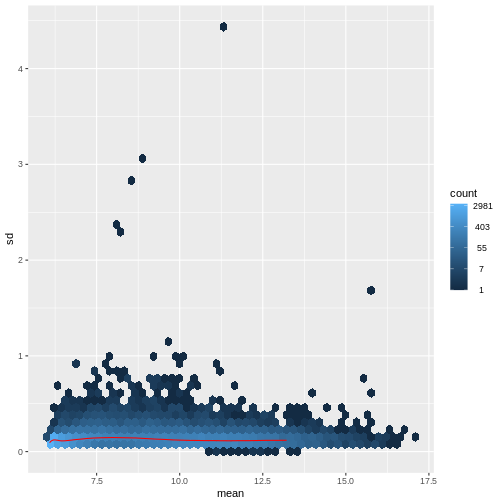
There are two ways around this: either we develop methods specifically adapted to count data, or we adapt (transform) the count data so that the existing methods are applicable. Both ways have been explored; however, at the moment the second approach is arguably more widely applied in practice. We can transform our data using DESeq2’s variance stabilizing transformation and then verify that it has removed the correlation between average read count and variance.
R
vsd <- DESeq2::vst(dds, blind = TRUE)
meanSdPlot(assay(vsd), ranks = FALSE)
Heatmaps and clustering
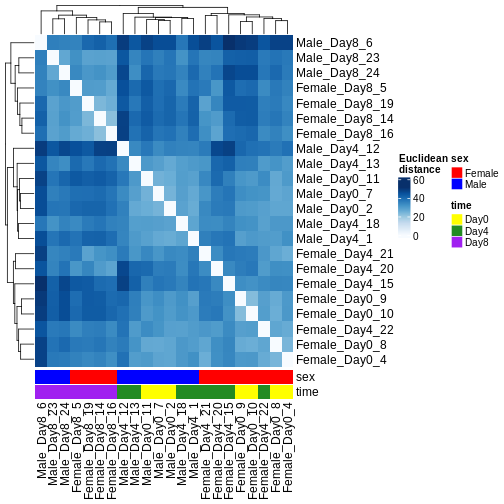
There are many ways to cluster samples based on their similarity of expression patterns. One simple way is to calculate Euclidean distances between all pairs of samples (longer distance = more different) and then display the results with both a branching dendrogram and a heatmap to visualize the distances in color. From this, we infer that the Day 8 samples are more similar to each other than the rest of the samples, although Day 4 and Day 0 do not separate distinctly. Instead, males and females reliably separate.
R
dst <- dist(t(assay(vsd)))
colors <- colorRampPalette(brewer.pal(9, "Blues"))(255)
ComplexHeatmap::Heatmap(
as.matrix(dst),
col = colors,
name = "Euclidean\ndistance",
cluster_rows = hclust(dst),
cluster_columns = hclust(dst),
bottom_annotation = columnAnnotation(
sex = vsd$sex,
time = vsd$time,
col = list(sex = c(Female = "red", Male = "blue"),
time = c(Day0 = "yellow", Day4 = "forestgreen", Day8 = "purple")))
)
PCA
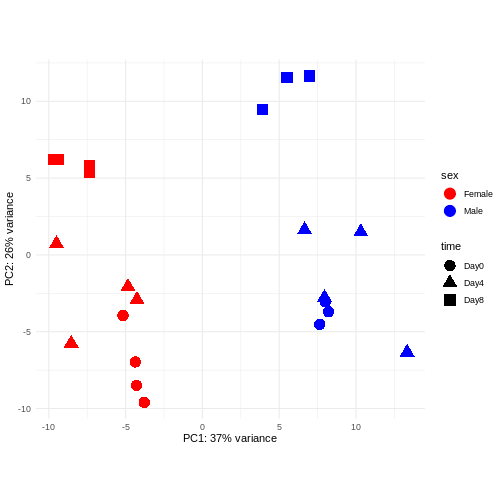
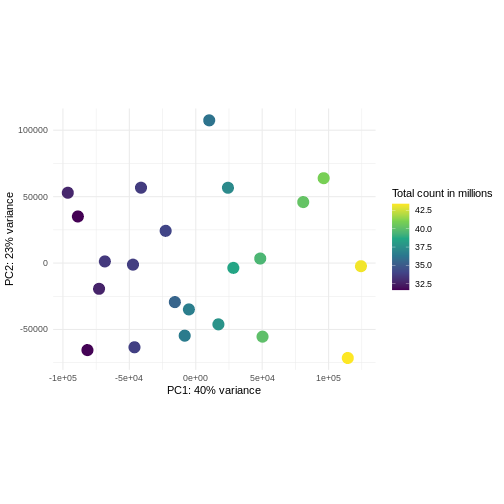
Principal component analysis is a dimensionality reduction method, which projects the samples into a lower-dimensional space. This lower-dimensional representation can be used for visualization, or as the input for other analysis methods. The principal components are defined in such a way that they are orthogonal, and that the projection of the samples into the space they span contains as much variance as possible. It is an unsupervised method in the sense that no external information about the samples (e.g., the treatment condition) is taken into account. In the plot below we represent the samples in a two-dimensional principal component space. For each of the two dimensions, we indicate the fraction of the total variance that is represented by that component. By definition, the first principal component will always represent more of the variance than the subsequent ones. The fraction of explained variance is a measure of how much of the ‘signal’ in the data that is retained when we project the samples from the original, high-dimensional space to the low-dimensional space for visualization.
R
pcaData <- DESeq2::plotPCA(vsd, intgroup = c("sex", "time"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaData, "percentVar"))
ggplot(pcaData, aes(x = PC1, y = PC2)) +
geom_point(aes(color = sex, shape = time), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_manual(values = c(Male = "blue", Female = "red"))
Challenge: Discuss the following points with your neighbour
Assume you are mainly interested in expression changes associated with the time after infection (Reminder Day0 -> before infection). What do you need to consider in downstream analysis?
Consider an experimental design where you have multiple samples from the same donor. You are still interested in differences by time and observe the following PCA plot. What does this PCA plot suggest?
OUTPUT
using ntop=500 top features by variance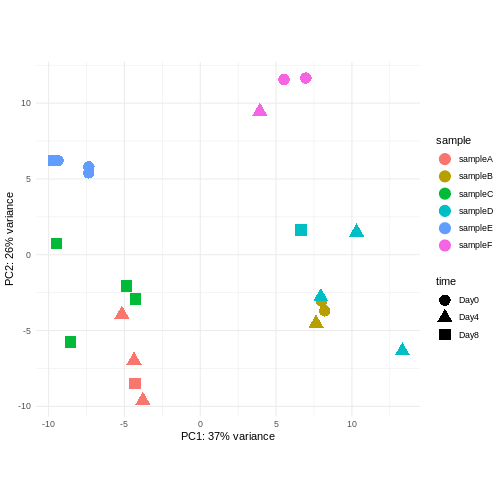
The major signal in this data (37% variance) is associated with sex. As we are not interested in sex-specific changes over time, we need to adjust for this in downstream analysis (see next episodes) and keep it in mind for further exploratory downstream analysis. A possible way to do so is to remove genes on sex chromosomes.
- A strong donor effect, that needs to be accounted for.
- What does PC1 (37% variance) represent? Looks like 2 donor groups?
- No association of PC1 and PC2 with time –> no or weak transcriptional effect of time –> Check association with higher PCs (e.g., PC3,PC4, ..)
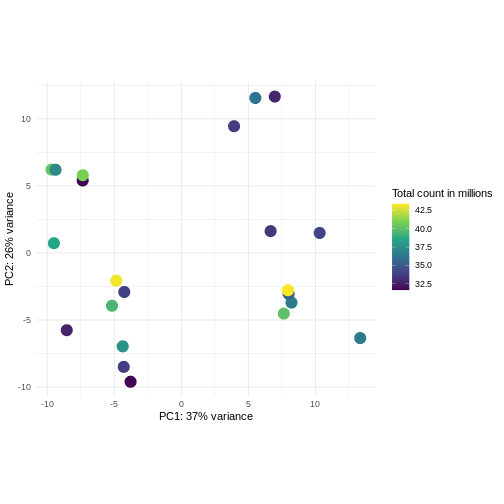
Challenge: Plot the PCA colored by library sizes.
Compare before and after variance stabilizing transformation.
Hint: The DESeq2::plotPCA expect an object of the
class DESeqTransform as input. You can transform a
SummarizedExperiment object using
plotPCA(DESeqTransform(se))
R
pcaDataVst <- DESeq2::plotPCA(vsd, intgroup = c("libSize"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaDataVst, "percentVar"))
ggplot(pcaDataVst, aes(x = PC1, y = PC2)) +
geom_point(aes(color = libSize / 1e6), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_continuous("Total count in millions", type = "viridis")
R
pcaDataCts <- DESeq2::plotPCA(DESeqTransform(se), intgroup = c("libSize"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaDataCts, "percentVar"))
ggplot(pcaDataCts, aes(x = PC1, y = PC2)) +
geom_point(aes(color = libSize / 1e6), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_continuous("Total count in millions", type = "viridis")
Interactive exploratory data analysis
Often it is useful to look at QC plots in an interactive way to directly explore different experimental factors or get insides from someone without coding experience. Useful tools for interactive exploratory data analysis for RNA-seq are Glimma and iSEE
Challenge: Interactively explore our data using iSEE
R
## Convert DESeqDataSet object to a SingleCellExperiment object, in order to
## be able to store the PCA representation
sce <- as(dds, "SingleCellExperiment")
## Add PCA to the 'reducedDim' slot
stopifnot(rownames(pcaData) == colnames(sce))
reducedDim(sce, "PCA") <- as.matrix(pcaData[, c("PC1", "PC2")])
## Add variance-stabilized data as a new assay
stopifnot(colnames(vsd) == colnames(sce))
assay(sce, "vsd") <- assay(vsd)
app <- iSEE(sce)
shiny::runApp(app)
Session info
R
sessionInfo()
OUTPUT
R version 4.6.0 (2026-04-24)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] iSEE_2.24.0 SingleCellExperiment_1.34.0
[3] hexbin_1.28.5 RColorBrewer_1.1-3
[5] ComplexHeatmap_2.28.0 ggplot2_4.0.3
[7] vsn_3.80.0 DESeq2_1.52.0
[9] SummarizedExperiment_1.42.0 Biobase_2.72.0
[11] MatrixGenerics_1.24.0 matrixStats_1.5.0
[13] GenomicRanges_1.64.0 Seqinfo_1.2.0
[15] IRanges_2.46.0 S4Vectors_0.50.1
[17] BiocGenerics_0.58.1 generics_0.1.4
loaded via a namespace (and not attached):
[1] rlang_1.3.0 magrittr_2.0.5 shinydashboard_0.7.3
[4] clue_0.3-68 GetoptLong_1.1.1 otel_0.2.0
[7] compiler_4.6.0 mgcv_1.9-4 png_0.1-9
[10] vctrs_0.7.3 pkgconfig_2.0.3 shape_1.4.6.1
[13] crayon_1.5.3 fastmap_1.2.0 XVector_0.52.0
[16] labeling_0.4.3 promises_1.5.0 preprocessCore_1.74.0
[19] shinyAce_0.4.4 xfun_0.60 cachem_1.1.0
[22] jsonlite_2.0.0 listviewer_4.0.0 later_1.4.8
[25] DelayedArray_0.38.2 BiocParallel_1.46.0 parallel_4.6.0
[28] cluster_2.1.8.2 R6_2.6.1 bslib_0.11.0
[31] limma_3.68.4 jquerylib_0.1.4 Rcpp_1.1.2
[34] iterators_1.0.14 knitr_1.51 httpuv_1.6.17
[37] Matrix_1.7-5 splines_4.6.0 igraph_2.3.3
[40] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
[43] doParallel_1.0.17 codetools_0.2-20 affy_1.90.0
[46] miniUI_0.1.2 lattice_0.22-9 tibble_3.3.1
[49] shiny_1.14.0 withr_3.0.3 S7_0.2.2
[52] evaluate_1.0.5 circlize_0.4.18 pillar_1.11.1
[55] affyio_1.82.0 BiocManager_1.30.27 renv_1.2.3
[58] DT_0.34.0 foreach_1.5.2 shinyjs_2.1.1
[61] scales_1.4.0 xtable_1.8-8 glue_1.8.1
[64] tools_4.6.0 colourpicker_1.3.0 locfit_1.5-9.12
[67] colorspace_2.1-3 nlme_3.1-169 vipor_0.4.7
[70] cli_3.6.6 viridisLite_0.4.3 S4Arrays_1.12.0
[73] dplyr_1.2.1 gtable_0.3.6 rintrojs_0.3.4
[76] sass_0.4.10 digest_0.6.39 SparseArray_1.12.2
[79] ggrepel_0.9.8 rjson_0.2.23 htmlwidgets_1.6.4
[82] farver_2.1.2 htmltools_0.5.9 lifecycle_1.0.5
[85] shinyWidgets_0.9.1 GlobalOptions_0.1.4 statmod_1.5.2
[88] mime_0.13 - Exploratory analysis is essential for quality control and to detect potential problems with a data set.
- Different classes of exploratory analysis methods expect differently preprocessed data. The most commonly used methods expect counts to be normalized and log-transformed (or similar- more sensitive/sophisticated), to be closer to homoskedastic. Other methods work directly on the raw counts.
Content from Differential expression analysis
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- What are the steps performed in a typical differential expression analysis?
- How does one interpret the output of DESeq2?
Objectives
- Explain the steps involved in a differential expression analysis.
- Explain how to perform these steps in R, using DESeq2.
Differential expression inference
A major goal of RNA-seq data analysis is the quantification and statistical inference of systematic changes between experimental groups or conditions (e.g., treatment vs. control, timepoints, tissues). This is typically performed by identifying genes with differential expression pattern using between- and within-condition variability and thus requires biological replicates (multiple sample of the same condition). Multiple software packages exist to perform differential expression analysis. Comparative studies have shown some concordance of differentially expressed (DE) genes, but also variability between tools with no tool consistently outperforming all others (see Soneson and Delorenzi, 2013). In the following we will explain and conduct differential expression analysis using the DESeq2 software package. The edgeR package implements similar methods following the same main assumptions about count data. Both packages show a general good and stable performance with comparable results.
The DESeqDataSet
To run DESeq2 we need to represent our count data as
object of the DESeqDataSet class. The
DESeqDataSet is an extension of the
SummarizedExperiment class (see section Importing and annotating quantified data
into R ) that stores a design formula in addition to the
count assay(s) and feature (here gene) and sample metadata. The
design formula expresses the variables which will be used in
modeling. These are typically the variable of interest (group variable)
and other variables you want to account for (e.g., batch effect
variables). A detailed explanation of design formulas and
related design matrices will follow in the section about extra exploration of design matrices.
Objects of the DESeqDataSet class can be build from count
matrices, SummarizedExperiment
objects, transcript
abundance files or htseq
count files.
Load packages
R
suppressPackageStartupMessages({
library(SummarizedExperiment)
library(DESeq2)
library(ggplot2)
library(ExploreModelMatrix)
library(cowplot)
library(ComplexHeatmap)
library(apeglm)
})
Load data
Let’s load in our SummarizedExperiment object again. In
the last episode for quality control exploration, we removed ~35% genes
that had 5 or fewer counts because they had too little information in
them. For DESeq2 statistical analysis, we do not technically have to
remove these genes because by default it will do some independent
filtering, but it can reduce the memory size of the
DESeqDataSet object resulting in faster computation. Plus,
we do not want these genes cluttering up some of the visualizations.
R
se <- readRDS("data/GSE96870_se.rds")
se <- se[rowSums(assay(se, "counts")) > 5, ]
Create DESeqDataSet
The design matrix we will use in this example is
~ sex + time. This will allow us test the difference
between males and females (averaged over time point) and the difference
between day 0, 4 and 8 (averaged over males and females). If we wanted
to test other comparisons (e.g., Female.Day8 vs. Female.Day0 and also
Male.Day8 vs. Male.Day0) we could use a different design matrix to more
easily extract those pairwise comparisons.
R
dds <- DESeq2::DESeqDataSet(se,
design = ~ sex + time)
WARNING
Warning in DESeq2::DESeqDataSet(se, design = ~sex + time): some variables in
design formula are characters, converting to factorsNormalization
DESeq2 and edgeR make the following
assumptions:
- most genes are not differentially expressed
- the probability of a read mapping to a specific gene is the same for all samples within the same group
As shown in the previous section
on exploratory data analysis the total counts of a sample (even from the
same condition) depends on the library size (total number of reads
sequenced). To compare the variability of counts from a specific gene
between and within groups we first need to account for library sizes and
compositional effects. Recall the estimateSizeFactors()
function from the previous section:
R
dds <- estimateSizeFactors(dds)
Statistical modeling
DESeq2 and edgeR model RNA-seq counts as
negative binomial distribution to account for a limited
number of replicates per group, a mean-variance dependency (see exploratory data analysis) and a
skewed count distribution.
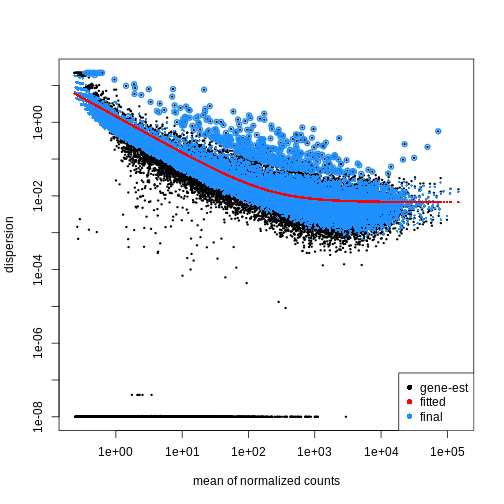
Dispersion
The within-group variance of the counts for a gene following a negative binomial distribution with mean \(\mu\) can be modeled as:
\(var = \mu + \theta \mu^2\)
\(\theta\) represents the
gene-specific dispersion, a measure of variability or
spread in the data. As a second step, we need to estimate gene-wise
dispersions to get the expected within-group variance and test for group
differences. Good dispersion estimates are challenging with a few
samples per group only. Thus, information from genes with similar
expression pattern are “borrowed”. Gene-wise dispersion estimates are
shrinked towards center values of the observed distribution of
dispersions. With DESeq2 we can get dispersion estimates
using the estimateDispersions() function. We can visualize
the effect of shrinkage using plotDispEsts():
R
dds <- estimateDispersions(dds)
OUTPUT
gene-wise dispersion estimatesOUTPUT
mean-dispersion relationshipOUTPUT
final dispersion estimatesR
plotDispEsts(dds)
Testing
We can use the nbinomWaldTest()function of
DESeq2 to fit a generalized linear model (GLM) and
compute log2 fold changes (synonymous with “GLM coefficients”,
“beta coefficients” or “effect size”) corresponding to the variables of
the design matrix. The design matrix is directly
related to the design formula and automatically derived from
it. Assume a design formula with one variable (~ treatment)
and two factor levels (treatment and control). The mean expression \(\mu_{j}\) of a specific gene in sample
\(j\) will be modeled as following:
\(log(μ_j) = β_0 + x_j β_T\),
with \(β_T\) corresponding to the log2 fold change of the treatment groups, \(x_j\) = 1, if \(j\) belongs to the treatment group and \(x_j\) = 0, if \(j\) belongs to the control group.
Finally, the estimated log2 fold changes are scaled by their standard error and tested for being significantly different from 0 using the Wald test.
R
dds <- nbinomWaldTest(dds)
Note
Standard differential expression analysis as performed above is
wrapped into a single function, DESeq(). Running the first
code chunk is equivalent to running the second one:
R
dds <- DESeq(dds)
R
dds <- estimateSizeFactors(dds)
dds <- estimateDispersions(dds)
dds <- nbinomWaldTest(dds)
Explore results for specific contrasts
The results() function can be used to extract gene-wise
test statistics, such as log2 fold changes and (adjusted) p-values. The
comparison of interest can be defined using contrasts, which are linear
combinations of the model coefficients (equivalent to combinations of
columns within the design matrix) and thus directly related to
the design formula. A detailed explanation of design matrices and how to
use them to specify different contrasts of interest can be found in the
section on the exploration of design
matrices. In the results() function a contrast can be
represented by the variable of interest (reference variable) and the
related level to compare using the contrast argument. By
default the reference variable will be the last
variable of the design formula, the reference level
will be the first factor level and the last level will be used
for comparison. You can also explicitly specify a contrast by the
name argument of the results() function. Names
of all available contrasts can be accessed using
resultsNames().
Challenge
What will be the default contrast, reference
level and “last level” for comparisons when
running results(dds) for the example used in this
lesson?
Hint: Check the design formula used to build the object.
In the lesson example the last variable of the design formula is
time. The reference level (first in
alphabetical order) is Day0 and the last
level is Day8
R
levels(dds$time)
OUTPUT
[1] "Day0" "Day4" "Day8"No worries, if you had difficulties to identify the default contrast
the output of the results() function explicitly states the
contrast it is referring to (see below)!
To explore the output of the results() function we can
use the summary() function and order results by
significance (p-value). Here we assume that we are interested in changes
over time (“variable of interest”), more specifically genes
with differential expression between Day0 (“reference
level”) and Day8 (“level to compare”). The model we used
included the sex variable (see above). Thus our results
will be “corrected” for sex-related differences.
R
## Day 8 vs Day 0
resTime <- results(dds, contrast = c("time", "Day8", "Day0"))
summary(resTime)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 4472, 16%
LFC < 0 (down) : 4282, 16%
outliers [1] : 10, 0.036%
low counts [2] : 3723, 14%
(mean count < 1)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
# View(resTime)
head(resTime[order(resTime$pvalue), ])
OUTPUT
log2 fold change (MLE): time Day8 vs Day0
Wald test p-value: time Day8 vs Day0
DataFrame with 6 rows and 6 columns
baseMean log2FoldChange lfcSE stat pvalue
<numeric> <numeric> <numeric> <numeric> <numeric>
Asl 701.343 1.117332 0.0594128 18.8062 6.71212e-79
Apod 18765.146 1.446981 0.0805056 17.9737 3.13229e-72
Cyp2d22 2550.480 0.910202 0.0556002 16.3705 3.10712e-60
Klk6 546.503 -1.671897 0.1057395 -15.8115 2.59339e-56
Fcrls 184.235 -1.947016 0.1277235 -15.2440 1.80488e-52
A330076C08Rik 107.250 -1.749957 0.1155125 -15.1495 7.63434e-52
padj
<numeric>
Asl 1.59057e-74
Apod 3.71130e-68
Cyp2d22 2.45431e-56
Klk6 1.53639e-52
Fcrls 8.55406e-49
A330076C08Rik 3.01518e-48Challenge
Explore the DE genes between males and females independent of time.
Hint: You don’t need to fit the GLM again. Use
resultsNames() to get the correct contrast.
R
## Male vs Female
resSex <- results(dds, contrast = c("sex", "Male", "Female"))
summary(resSex)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 51, 0.19%
LFC < 0 (down) : 70, 0.26%
outliers [1] : 10, 0.036%
low counts [2] : 8504, 31%
(mean count < 6)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
head(resSex[order(resSex$pvalue), ])
OUTPUT
log2 fold change (MLE): sex Male vs Female
Wald test p-value: sex Male vs Female
DataFrame with 6 rows and 6 columns
baseMean log2FoldChange lfcSE stat pvalue
<numeric> <numeric> <numeric> <numeric> <numeric>
Xist 22603.0359 -11.60429 0.336282 -34.5076 6.16852e-261
Ddx3y 2072.9436 11.87241 0.397493 29.8683 5.08722e-196
Eif2s3y 1410.8750 12.62513 0.565194 22.3377 1.58997e-110
Kdm5d 692.1672 12.55386 0.593607 21.1484 2.85293e-99
Uty 667.4375 12.01728 0.593573 20.2457 3.87772e-91
LOC105243748 52.9669 9.08325 0.597575 15.2002 3.52699e-52
padj
<numeric>
Xist 1.16684e-256
Ddx3y 4.81149e-192
Eif2s3y 1.00253e-106
Kdm5d 1.34915e-95
Uty 1.46702e-87
LOC105243748 1.11194e-48Multiple testing correction
Due to the high number of tests (one per gene) our DE results will contain a substantial number of false positives. For example, if we tested 20,000 genes at a threshold of \(\alpha = 0.05\) we would expect 1,000 significant DE genes with no differential expression.
To account for this expected high number of false positives, we can
correct our results for multiple testing. By default
DESeq2 uses the Benjamini-Hochberg
procedure to calculate adjusted p-values (padj) for
DE results.
Independent Filtering and log-fold shrinkage
We can visualize the results in many ways. A good check is to explore
the relationship between log2fold changes, significant DE
genes and the genes mean count. DESeq2
provides a useful function to do so, plotMA().
R
plotMA(resTime)
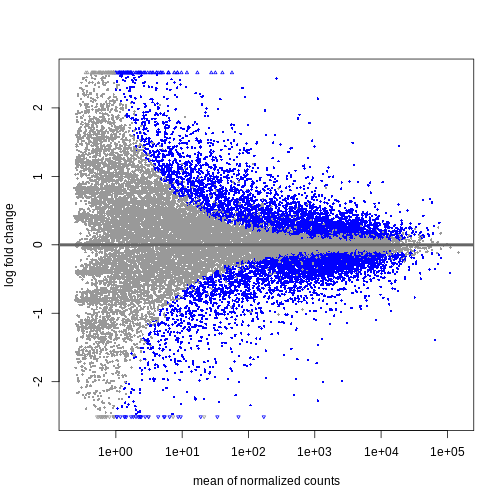
We can see that genes with a low mean count tend to have larger log fold changes. This is caused by counts from lowly expressed genes tending to be very noisy. We can shrink the log fold changes of these genes with low mean and high dispersion, as they contain little information.
R
resTimeLfc <- lfcShrink(dds, coef = "time_Day8_vs_Day0", res = resTime)
OUTPUT
using 'apeglm' for LFC shrinkage. If used in published research, please cite:
Zhu, A., Ibrahim, J.G., Love, M.I. (2018) Heavy-tailed prior distributions for
sequence count data: removing the noise and preserving large differences.
Bioinformatics. https://doi.org/10.1093/bioinformatics/bty895R
plotMA(resTimeLfc)
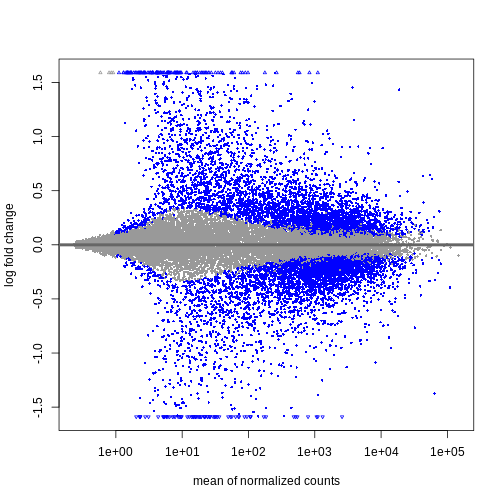 Shrinkage of log fold changes is useful for visualization and ranking of
genes, but for result exploration typically the
Shrinkage of log fold changes is useful for visualization and ranking of
genes, but for result exploration typically the
independentFiltering argument is used to remove lowly
expressed genes.
Challenge
By default independentFiltering is set to
TRUE. What happens without filtering lowly expressed genes?
Use the summary() function to compare the results. Most of
the lowly expressed genes are not significantly differential expressed
(blue in the above MA plots). What could cause the difference in the
results then?
R
resTimeNotFiltered <- results(dds,
contrast = c("time", "Day8", "Day0"),
independentFiltering = FALSE)
summary(resTime)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 4472, 16%
LFC < 0 (down) : 4282, 16%
outliers [1] : 10, 0.036%
low counts [2] : 3723, 14%
(mean count < 1)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
summary(resTimeNotFiltered)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 4324, 16%
LFC < 0 (down) : 4129, 15%
outliers [1] : 10, 0.036%
low counts [2] : 0, 0%
(mean count < 0)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsGenes with very low counts are not likely to see significant differences typically due to high dispersion. Filtering of lowly expressed genes thus increased detection power at the same experiment-wide false positive rate.
Visualize selected set of genes
The amount of DE genes can be overwhelming and a ranked list of genes can still be hard to interpret with regards to an experimental question. Visualizing gene expression can help to detect expression pattern or group of genes with related functions. We will perform systematic detection of over represented groups of genes in a later section. Before this visualization can already help us to get a good intuition about what to expect.
We will use transformed data (see exploratory data analysis) and the top differentially expressed genes for visualization. A heatmap can reveal expression pattern across sample groups (columns) and automatically orders genes (rows) according to their similarity.
R
# Transform counts
vsd <- vst(dds, blind = TRUE)
# Get top DE genes
genes <- resTime[order(resTime$pvalue), ] |>
head(10) |>
rownames()
heatmapData <- assay(vsd)[genes, ]
# Scale counts for visualization
heatmapData <- t(scale(t(heatmapData)))
# Add annotation
heatmapColAnnot <- data.frame(colData(vsd)[, c("time", "sex")])
heatmapColAnnot <- HeatmapAnnotation(df = heatmapColAnnot)
# Plot as heatmap
ComplexHeatmap::Heatmap(heatmapData,
top_annotation = heatmapColAnnot,
cluster_rows = TRUE, cluster_columns = FALSE)
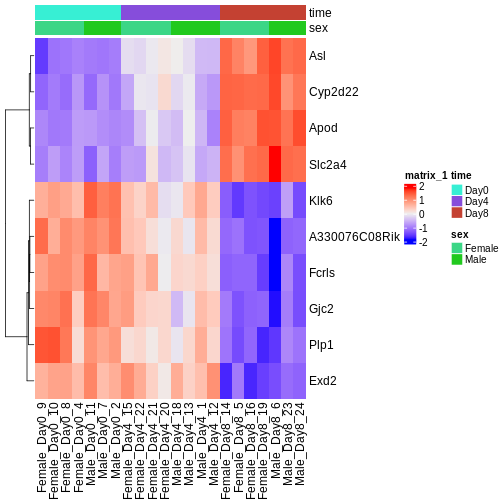
Challenge
Check the heatmap and top DE genes. Do you find something expected/unexpected in terms of change across all 3 time points?
Output results
We may want to to output our results out of R to have a stand-alone
file. The format of resTime only has the gene symbols as
rownames, so let us join the gene annotation information, and then write
out as .csv file:
R
head(as.data.frame(resTime))
head(as.data.frame(rowRanges(se)))
temp <- cbind(as.data.frame(rowRanges(se)),
as.data.frame(resTime))
write.csv(temp, file = "output/Day8vsDay0.csv")
- With DESeq2, the main steps of a differential expression analysis (size factor estimation, dispersion estimation, calculation of test statistics) are wrapped in a single function: DESeq().
- Independent filtering of lowly expressed genes is often beneficial.
Content from Extra exploration of design matrices
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- How can one translate biological questions and comparisons to statistical terms suitable for use with RNA-seq analysis packages?
Objectives
- Explain the formula notation and design matrices.
- Explore different designs and learn how to interpret coefficients.
Loading required packages and reading data
We start by loading a few packages that will be needed in this episode. In particular, the ExploreModelMatrix package provides resources for exploring design matrices in a graphical fashion, for easier interpretation.
R
suppressPackageStartupMessages({
library(SummarizedExperiment)
library(ExploreModelMatrix)
library(dplyr)
library(DESeq2)
})
Next, we read the metadata table for our data set. Because we want to explore many different design matrices, we will read in the 4th file we downloaded but haven’t used yet: that for both Cerebellum and Spinal Cord samples (45 samples total). As seen in previous episodes, the metadata contains information about the age, sex, infection status, time of measurement and tissue of the collected samples. Note that Day0 always corresponds to non-infected samples, and that infected samples are collected on days 4 and 8. Moreover, all mice have the same age (8 weeks). Hence, in the first part of this episode we consider only the sex, tissue and time variables further.
R
meta <- read.csv("data/GSE96870_coldata_all.csv", row.names = 1)
# Here, for brevity we only print the first rows of the data.frame
head(meta)
OUTPUT
title geo_accession organism age sex
GSM2545336 CNS_RNA-seq_10C GSM2545336 Mus musculus 8 weeks Female
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545339 CNS_RNA-seq_13C GSM2545339 Mus musculus 8 weeks Female
GSM2545340 CNS_RNA-seq_14C GSM2545340 Mus musculus 8 weeks Male
GSM2545341 CNS_RNA-seq_17C GSM2545341 Mus musculus 8 weeks Male
infection strain time tissue mouse
GSM2545336 InfluenzaA C57BL/6 Day8 Cerebellum 14
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545339 InfluenzaA C57BL/6 Day4 Cerebellum 15
GSM2545340 InfluenzaA C57BL/6 Day4 Cerebellum 18
GSM2545341 InfluenzaA C57BL/6 Day8 Cerebellum 6R
table(meta$time, meta$infection)
OUTPUT
InfluenzaA NonInfected
Day0 0 15
Day4 16 0
Day8 14 0R
table(meta$age)
OUTPUT
8 weeks
45 We can start by visualizing the number of observations for each combination of the three predictor variables.
R
vd <- VisualizeDesign(sampleData = meta,
designFormula = ~ tissue + time + sex)
vd$cooccurrenceplots
OUTPUT
$`tissue = Cerebellum`
OUTPUT
$`tissue = Spinalcord`
Challenge
Based on this visualization, would you say that the data set is balanced, or are there combinations of predictor variables that are severely over- or underrepresented?
Compare males and females, non-infected spinal cord
Next, we will set up our first design matrix. Here, we will focus on
the uninfected (Day0) spinal cord samples, and our aim is to compare the
male and female mice. Thus, we first subset the metadata to only the
samples of interest, and next set up and visualize the design matrix
with a single predictor variable (sex). By defining the design formula
as ~ sex, we tell R to include an intercept in the design.
This intercept will represent the ‘baseline’ level of the predictor
variable, which in this case is selected to be the Female mice. If not
explicitly specified, R will order the values of the predictor in
alphabetical order and select the first one as the reference or baseline
level.
R
## Subset metadata
meta_noninf_spc <- meta %>% filter(time == "Day0" &
tissue == "Spinalcord")
meta_noninf_spc
OUTPUT
title geo_accession organism age sex
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male
infection strain time tissue mouse
GSM2545356 NonInfected C57BL/6 Day0 Spinalcord 2
GSM2545357 NonInfected C57BL/6 Day0 Spinalcord 3
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545361 NonInfected C57BL/6 Day0 Spinalcord 7
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10
GSM2545367 NonInfected C57BL/6 Day0 Spinalcord 11R
## Use ExploreModelMatrix to create a design matrix and visualizations, given
## the desired design formula.
vd <- VisualizeDesign(sampleData = meta_noninf_spc,
designFormula = ~ sex)
vd$designmatrix
OUTPUT
(Intercept) sexMale
GSM2545356 1 1
GSM2545357 1 1
GSM2545358 1 0
GSM2545361 1 1
GSM2545364 1 0
GSM2545365 1 0
GSM2545366 1 0
GSM2545367 1 1R
vd$plotlist
OUTPUT
[[1]]
R
## Note that we can also generate the design matrix like this
model.matrix(~ sex, data = meta_noninf_spc)
OUTPUT
(Intercept) sexMale
GSM2545356 1 1
GSM2545357 1 1
GSM2545358 1 0
GSM2545361 1 1
GSM2545364 1 0
GSM2545365 1 0
GSM2545366 1 0
GSM2545367 1 1
attr(,"assign")
[1] 0 1
attr(,"contrasts")
attr(,"contrasts")$sex
[1] "contr.treatment"Challenge
With this design, what is the interpretation of the
sexMale coefficient?
Challenge
Set up the design formula to compare male and female spinal cord samples from Day0 as above, but instruct R to not include an intercept in the model. How does this change the interpretation of the coefficients? What contrast would have to be specified to compare the mean expression of a gene between male and female mice?
R
meta_noninf_spc <- meta %>% filter(time == "Day0" &
tissue == "Spinalcord")
meta_noninf_spc
OUTPUT
title geo_accession organism age sex
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male
infection strain time tissue mouse
GSM2545356 NonInfected C57BL/6 Day0 Spinalcord 2
GSM2545357 NonInfected C57BL/6 Day0 Spinalcord 3
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545361 NonInfected C57BL/6 Day0 Spinalcord 7
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10
GSM2545367 NonInfected C57BL/6 Day0 Spinalcord 11R
vd <- VisualizeDesign(sampleData = meta_noninf_spc,
designFormula = ~ 0 + sex)
vd$designmatrix
OUTPUT
sexFemale sexMale
GSM2545356 0 1
GSM2545357 0 1
GSM2545358 1 0
GSM2545361 0 1
GSM2545364 1 0
GSM2545365 1 0
GSM2545366 1 0
GSM2545367 0 1R
vd$plotlist
OUTPUT
[[1]]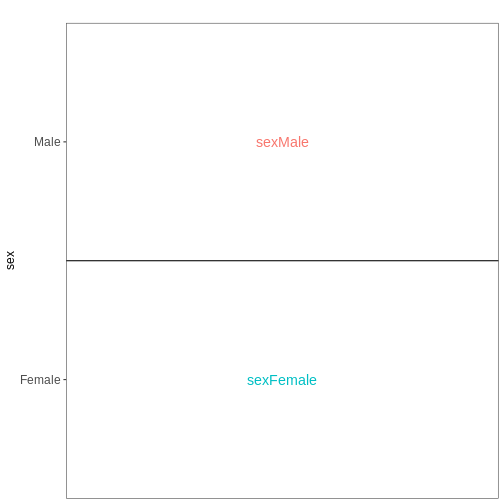
Challenge
Set up the design formula to compare the three time points (Day0,
Day4, Day8) in the male spinal cord samples, and visualize it using
ExploreModelMatrix.
R
meta_male_spc <- meta %>% filter(sex == "Male" & tissue == "Spinalcord")
meta_male_spc
OUTPUT
title geo_accession organism age sex infection
GSM2545355 CNS_RNA-seq_571 GSM2545355 Mus musculus 8 weeks Male InfluenzaA
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male NonInfected
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male NonInfected
GSM2545360 CNS_RNA-seq_589 GSM2545360 Mus musculus 8 weeks Male InfluenzaA
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male NonInfected
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male NonInfected
GSM2545368 CNS_RNA-seq_728 GSM2545368 Mus musculus 8 weeks Male InfluenzaA
GSM2545369 CNS_RNA-seq_729 GSM2545369 Mus musculus 8 weeks Male InfluenzaA
GSM2545372 CNS_RNA-seq_733 GSM2545372 Mus musculus 8 weeks Male InfluenzaA
GSM2545373 CNS_RNA-seq_735 GSM2545373 Mus musculus 8 weeks Male InfluenzaA
GSM2545378 CNS_RNA-seq_742 GSM2545378 Mus musculus 8 weeks Male InfluenzaA
GSM2545379 CNS_RNA-seq_743 GSM2545379 Mus musculus 8 weeks Male InfluenzaA
strain time tissue mouse
GSM2545355 C57BL/6 Day4 Spinalcord 1
GSM2545356 C57BL/6 Day0 Spinalcord 2
GSM2545357 C57BL/6 Day0 Spinalcord 3
GSM2545360 C57BL/6 Day8 Spinalcord 6
GSM2545361 C57BL/6 Day0 Spinalcord 7
GSM2545367 C57BL/6 Day0 Spinalcord 11
GSM2545368 C57BL/6 Day4 Spinalcord 12
GSM2545369 C57BL/6 Day4 Spinalcord 13
GSM2545372 C57BL/6 Day8 Spinalcord 17
GSM2545373 C57BL/6 Day4 Spinalcord 18
GSM2545378 C57BL/6 Day8 Spinalcord 23
GSM2545379 C57BL/6 Day8 Spinalcord 24R
vd <- VisualizeDesign(sampleData = meta_male_spc, designFormula = ~ time)
vd$designmatrix
OUTPUT
(Intercept) timeDay4 timeDay8
GSM2545355 1 1 0
GSM2545356 1 0 0
GSM2545357 1 0 0
GSM2545360 1 0 1
GSM2545361 1 0 0
GSM2545367 1 0 0
GSM2545368 1 1 0
GSM2545369 1 1 0
GSM2545372 1 0 1
GSM2545373 1 1 0
GSM2545378 1 0 1
GSM2545379 1 0 1R
vd$plotlist
OUTPUT
[[1]]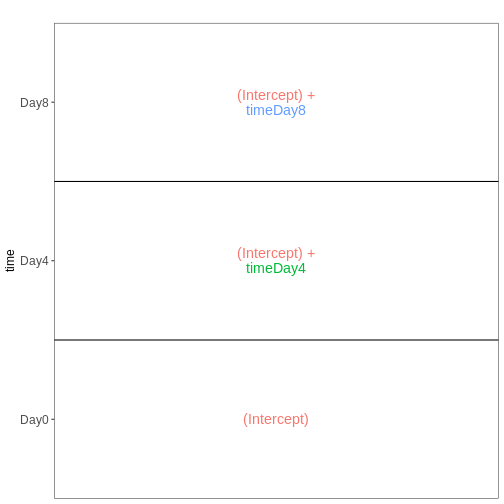
Factorial design without interactions
Next, we again consider only non-infected mice, but fit a model incorporating both sex and tissue as predictors. We assume that the tissue differences are the same for both male and female mice, and consequently fit an additive model, without interaction terms.
R
meta_noninf <- meta %>% filter(time == "Day0")
meta_noninf
OUTPUT
title geo_accession organism age sex
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545343 CNS_RNA-seq_20C GSM2545343 Mus musculus 8 weeks Male
GSM2545348 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks Female
GSM2545349 CNS_RNA-seq_28C GSM2545349 Mus musculus 8 weeks Male
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545354 CNS_RNA-seq_4C GSM2545354 Mus musculus 8 weeks Male
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male
infection strain time tissue mouse
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545343 NonInfected C57BL/6 Day0 Cerebellum 11
GSM2545348 NonInfected C57BL/6 Day0 Cerebellum 8
GSM2545349 NonInfected C57BL/6 Day0 Cerebellum 7
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4
GSM2545354 NonInfected C57BL/6 Day0 Cerebellum 2
GSM2545356 NonInfected C57BL/6 Day0 Spinalcord 2
GSM2545357 NonInfected C57BL/6 Day0 Spinalcord 3
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545361 NonInfected C57BL/6 Day0 Spinalcord 7
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10
GSM2545367 NonInfected C57BL/6 Day0 Spinalcord 11R
vd <- VisualizeDesign(sampleData = meta_noninf,
designFormula = ~ sex + tissue)
vd$designmatrix
OUTPUT
(Intercept) sexMale tissueSpinalcord
GSM2545337 1 0 0
GSM2545338 1 0 0
GSM2545343 1 1 0
GSM2545348 1 0 0
GSM2545349 1 1 0
GSM2545353 1 0 0
GSM2545354 1 1 0
GSM2545356 1 1 1
GSM2545357 1 1 1
GSM2545358 1 0 1
GSM2545361 1 1 1
GSM2545364 1 0 1
GSM2545365 1 0 1
GSM2545366 1 0 1
GSM2545367 1 1 1R
vd$plotlist
OUTPUT
[[1]]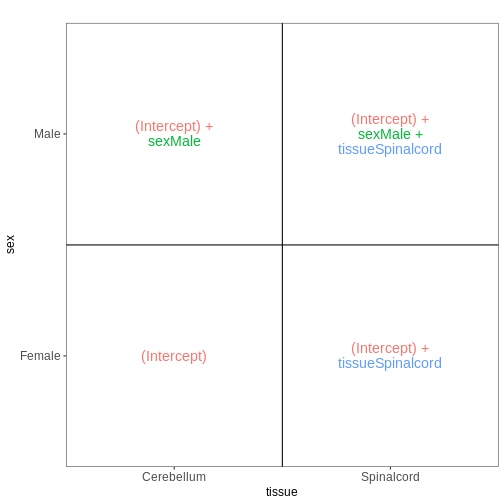
Factorial design with interactions
In the previous model, we assumed that the tissue differences were the same for both male and female mice. To allow for the estimation of sex-specific tissue differences (at the expense of having one additional coefficient to estimate from the data), we can include an interaction term in the model.
R
meta_noninf <- meta %>% filter(time == "Day0")
meta_noninf
OUTPUT
title geo_accession organism age sex
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545343 CNS_RNA-seq_20C GSM2545343 Mus musculus 8 weeks Male
GSM2545348 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks Female
GSM2545349 CNS_RNA-seq_28C GSM2545349 Mus musculus 8 weeks Male
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545354 CNS_RNA-seq_4C GSM2545354 Mus musculus 8 weeks Male
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male
infection strain time tissue mouse
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545343 NonInfected C57BL/6 Day0 Cerebellum 11
GSM2545348 NonInfected C57BL/6 Day0 Cerebellum 8
GSM2545349 NonInfected C57BL/6 Day0 Cerebellum 7
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4
GSM2545354 NonInfected C57BL/6 Day0 Cerebellum 2
GSM2545356 NonInfected C57BL/6 Day0 Spinalcord 2
GSM2545357 NonInfected C57BL/6 Day0 Spinalcord 3
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545361 NonInfected C57BL/6 Day0 Spinalcord 7
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10
GSM2545367 NonInfected C57BL/6 Day0 Spinalcord 11R
## Define a design including an interaction term
## Note that ~ sex * tissue is equivalent to
## ~ sex + tissue + sex:tissue
vd <- VisualizeDesign(sampleData = meta_noninf,
designFormula = ~ sex * tissue)
vd$designmatrix
OUTPUT
(Intercept) sexMale tissueSpinalcord sexMale:tissueSpinalcord
GSM2545337 1 0 0 0
GSM2545338 1 0 0 0
GSM2545343 1 1 0 0
GSM2545348 1 0 0 0
GSM2545349 1 1 0 0
GSM2545353 1 0 0 0
GSM2545354 1 1 0 0
GSM2545356 1 1 1 1
GSM2545357 1 1 1 1
GSM2545358 1 0 1 0
GSM2545361 1 1 1 1
GSM2545364 1 0 1 0
GSM2545365 1 0 1 0
GSM2545366 1 0 1 0
GSM2545367 1 1 1 1R
vd$plotlist
OUTPUT
[[1]]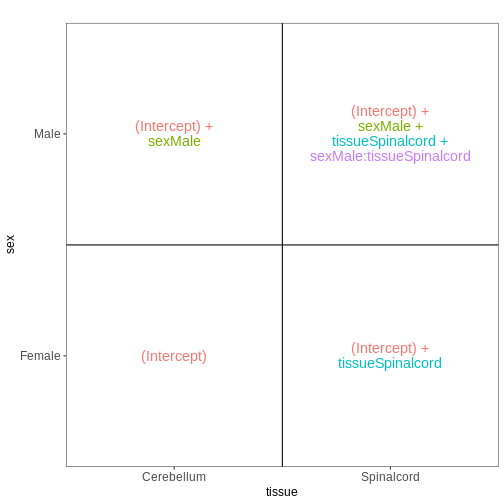
Combining multiple factors into one
Sometimes, for experiments with multiple factors, it is easier to interpret coefficients and set up contrasts of interest if the factors are combined into one. Let’s consider the previous example again, using this approach:
R
meta_noninf <- meta %>% filter(time == "Day0")
meta_noninf$sex_tissue <- paste0(meta_noninf$sex, "_", meta_noninf$tissue)
meta_noninf
OUTPUT
title geo_accession organism age sex
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545343 CNS_RNA-seq_20C GSM2545343 Mus musculus 8 weeks Male
GSM2545348 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks Female
GSM2545349 CNS_RNA-seq_28C GSM2545349 Mus musculus 8 weeks Male
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545354 CNS_RNA-seq_4C GSM2545354 Mus musculus 8 weeks Male
GSM2545356 CNS_RNA-seq_574 GSM2545356 Mus musculus 8 weeks Male
GSM2545357 CNS_RNA-seq_575 GSM2545357 Mus musculus 8 weeks Male
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545361 CNS_RNA-seq_590 GSM2545361 Mus musculus 8 weeks Male
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545367 CNS_RNA-seq_713 GSM2545367 Mus musculus 8 weeks Male
infection strain time tissue mouse sex_tissue
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9 Female_Cerebellum
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10 Female_Cerebellum
GSM2545343 NonInfected C57BL/6 Day0 Cerebellum 11 Male_Cerebellum
GSM2545348 NonInfected C57BL/6 Day0 Cerebellum 8 Female_Cerebellum
GSM2545349 NonInfected C57BL/6 Day0 Cerebellum 7 Male_Cerebellum
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4 Female_Cerebellum
GSM2545354 NonInfected C57BL/6 Day0 Cerebellum 2 Male_Cerebellum
GSM2545356 NonInfected C57BL/6 Day0 Spinalcord 2 Male_Spinalcord
GSM2545357 NonInfected C57BL/6 Day0 Spinalcord 3 Male_Spinalcord
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4 Female_Spinalcord
GSM2545361 NonInfected C57BL/6 Day0 Spinalcord 7 Male_Spinalcord
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8 Female_Spinalcord
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9 Female_Spinalcord
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10 Female_Spinalcord
GSM2545367 NonInfected C57BL/6 Day0 Spinalcord 11 Male_SpinalcordR
vd <- VisualizeDesign(sampleData = meta_noninf,
designFormula = ~ 0 + sex_tissue)
vd$designmatrix
OUTPUT
sex_tissueFemale_Cerebellum sex_tissueFemale_Spinalcord
GSM2545337 1 0
GSM2545338 1 0
GSM2545343 0 0
GSM2545348 1 0
GSM2545349 0 0
GSM2545353 1 0
GSM2545354 0 0
GSM2545356 0 0
GSM2545357 0 0
GSM2545358 0 1
GSM2545361 0 0
GSM2545364 0 1
GSM2545365 0 1
GSM2545366 0 1
GSM2545367 0 0
sex_tissueMale_Cerebellum sex_tissueMale_Spinalcord
GSM2545337 0 0
GSM2545338 0 0
GSM2545343 1 0
GSM2545348 0 0
GSM2545349 1 0
GSM2545353 0 0
GSM2545354 1 0
GSM2545356 0 1
GSM2545357 0 1
GSM2545358 0 0
GSM2545361 0 1
GSM2545364 0 0
GSM2545365 0 0
GSM2545366 0 0
GSM2545367 0 1R
vd$plotlist
OUTPUT
[[1]]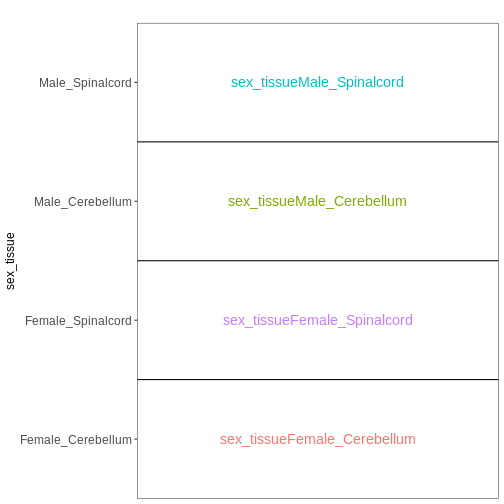
Paired design
In this particular data set the samples are paired - the same mice have contributed both the cerebellum and spinal cord samples. This information was not included in the previous models. However, accounting for it can increase power to detect tissue differences by eliminating variability in baseline expression levels between mice. Here, we define a paired design for the female non-infected mice, aimed at testing for differences between tissues after accounting for baseline differences between mice.
R
meta_fem_day0 <- meta %>% filter(sex == "Female" &
time == "Day0")
# ensure that mouse is treated as a categorical variable
meta_fem_day0$mouse <- factor(meta_fem_day0$mouse)
meta_fem_day0
OUTPUT
title geo_accession organism age sex
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545348 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks Female
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
infection strain time tissue mouse
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545348 NonInfected C57BL/6 Day0 Cerebellum 8
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10R
vd <- VisualizeDesign(sampleData = meta_fem_day0,
designFormula = ~ mouse + tissue)
vd$designmatrix
OUTPUT
(Intercept) mouse8 mouse9 mouse10 tissueSpinalcord
GSM2545337 1 0 1 0 0
GSM2545338 1 0 0 1 0
GSM2545348 1 1 0 0 0
GSM2545353 1 0 0 0 0
GSM2545358 1 0 0 0 1
GSM2545364 1 1 0 0 1
GSM2545365 1 0 1 0 1
GSM2545366 1 0 0 1 1R
vd$plotlist
OUTPUT
[[1]]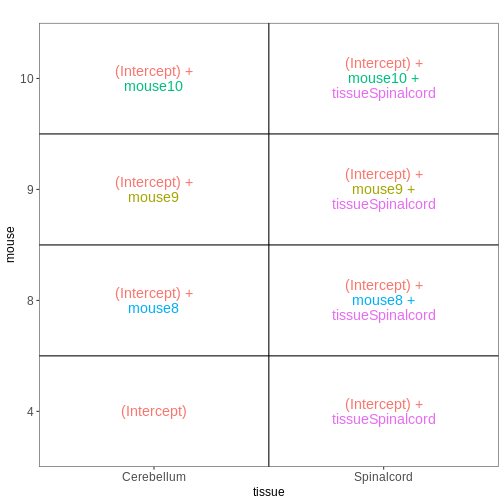
Within- and between-subject comparisons
In some situations, we need to combine the types of models considered above. For example, let’s say that we want to investigate if the tissue differences are different for infected and non-infected female mice. In this case, each mice only contributes to one of the infection groups (each mice is either infected or non-infected), but contributes both a cerebellum and a spinal cord sample. One way to view this type of design is as two paired experiments, one for each infection group (see the edgeR user guide section 3.5). We can then easily compare the two tissues in each infection group, and contrast the tissue differences between the infection groups.
R
meta_fem_day04 <- meta %>%
filter(sex == "Female" &
time %in% c("Day0", "Day4")) %>%
droplevels()
# ensure that mouse is treated as a categorical variable
meta_fem_day04$mouse <- factor(meta_fem_day04$mouse)
meta_fem_day04
OUTPUT
title geo_accession organism age sex
GSM2545337 CNS_RNA-seq_11C GSM2545337 Mus musculus 8 weeks Female
GSM2545338 CNS_RNA-seq_12C GSM2545338 Mus musculus 8 weeks Female
GSM2545339 CNS_RNA-seq_13C GSM2545339 Mus musculus 8 weeks Female
GSM2545344 CNS_RNA-seq_21C GSM2545344 Mus musculus 8 weeks Female
GSM2545348 CNS_RNA-seq_27C GSM2545348 Mus musculus 8 weeks Female
GSM2545352 CNS_RNA-seq_30C GSM2545352 Mus musculus 8 weeks Female
GSM2545353 CNS_RNA-seq_3C GSM2545353 Mus musculus 8 weeks Female
GSM2545358 CNS_RNA-seq_583 GSM2545358 Mus musculus 8 weeks Female
GSM2545362 CNS_RNA-seq_5C GSM2545362 Mus musculus 8 weeks Female
GSM2545364 CNS_RNA-seq_709 GSM2545364 Mus musculus 8 weeks Female
GSM2545365 CNS_RNA-seq_710 GSM2545365 Mus musculus 8 weeks Female
GSM2545366 CNS_RNA-seq_711 GSM2545366 Mus musculus 8 weeks Female
GSM2545371 CNS_RNA-seq_731 GSM2545371 Mus musculus 8 weeks Female
GSM2545375 CNS_RNA-seq_738 GSM2545375 Mus musculus 8 weeks Female
GSM2545376 CNS_RNA-seq_740 GSM2545376 Mus musculus 8 weeks Female
GSM2545377 CNS_RNA-seq_741 GSM2545377 Mus musculus 8 weeks Female
infection strain time tissue mouse
GSM2545337 NonInfected C57BL/6 Day0 Cerebellum 9
GSM2545338 NonInfected C57BL/6 Day0 Cerebellum 10
GSM2545339 InfluenzaA C57BL/6 Day4 Cerebellum 15
GSM2545344 InfluenzaA C57BL/6 Day4 Cerebellum 22
GSM2545348 NonInfected C57BL/6 Day0 Cerebellum 8
GSM2545352 InfluenzaA C57BL/6 Day4 Cerebellum 21
GSM2545353 NonInfected C57BL/6 Day0 Cerebellum 4
GSM2545358 NonInfected C57BL/6 Day0 Spinalcord 4
GSM2545362 InfluenzaA C57BL/6 Day4 Cerebellum 20
GSM2545364 NonInfected C57BL/6 Day0 Spinalcord 8
GSM2545365 NonInfected C57BL/6 Day0 Spinalcord 9
GSM2545366 NonInfected C57BL/6 Day0 Spinalcord 10
GSM2545371 InfluenzaA C57BL/6 Day4 Spinalcord 15
GSM2545375 InfluenzaA C57BL/6 Day4 Spinalcord 20
GSM2545376 InfluenzaA C57BL/6 Day4 Spinalcord 21
GSM2545377 InfluenzaA C57BL/6 Day4 Spinalcord 22R
design <- model.matrix(~ mouse, data = meta_fem_day04)
design <- cbind(design,
Spc.Day0 = meta_fem_day04$tissue == "Spinalcord" &
meta_fem_day04$time == "Day0",
Spc.Day4 = meta_fem_day04$tissue == "Spinalcord" &
meta_fem_day04$time == "Day4")
rownames(design) <- rownames(meta_fem_day04)
design
OUTPUT
(Intercept) mouse8 mouse9 mouse10 mouse15 mouse20 mouse21 mouse22
GSM2545337 1 0 1 0 0 0 0 0
GSM2545338 1 0 0 1 0 0 0 0
GSM2545339 1 0 0 0 1 0 0 0
GSM2545344 1 0 0 0 0 0 0 1
GSM2545348 1 1 0 0 0 0 0 0
GSM2545352 1 0 0 0 0 0 1 0
GSM2545353 1 0 0 0 0 0 0 0
GSM2545358 1 0 0 0 0 0 0 0
GSM2545362 1 0 0 0 0 1 0 0
GSM2545364 1 1 0 0 0 0 0 0
GSM2545365 1 0 1 0 0 0 0 0
GSM2545366 1 0 0 1 0 0 0 0
GSM2545371 1 0 0 0 1 0 0 0
GSM2545375 1 0 0 0 0 1 0 0
GSM2545376 1 0 0 0 0 0 1 0
GSM2545377 1 0 0 0 0 0 0 1
Spc.Day0 Spc.Day4
GSM2545337 0 0
GSM2545338 0 0
GSM2545339 0 0
GSM2545344 0 0
GSM2545348 0 0
GSM2545352 0 0
GSM2545353 0 0
GSM2545358 1 0
GSM2545362 0 0
GSM2545364 1 0
GSM2545365 1 0
GSM2545366 1 0
GSM2545371 0 1
GSM2545375 0 1
GSM2545376 0 1
GSM2545377 0 1R
vd <- VisualizeDesign(sampleData = meta_fem_day04 %>%
select(time, tissue, mouse),
designFormula = NULL,
designMatrix = design, flipCoordFitted = FALSE)
vd$designmatrix
OUTPUT
(Intercept) mouse8 mouse9 mouse10 mouse15 mouse20 mouse21 mouse22
GSM2545337 1 0 1 0 0 0 0 0
GSM2545338 1 0 0 1 0 0 0 0
GSM2545339 1 0 0 0 1 0 0 0
GSM2545344 1 0 0 0 0 0 0 1
GSM2545348 1 1 0 0 0 0 0 0
GSM2545352 1 0 0 0 0 0 1 0
GSM2545353 1 0 0 0 0 0 0 0
GSM2545358 1 0 0 0 0 0 0 0
GSM2545362 1 0 0 0 0 1 0 0
GSM2545364 1 1 0 0 0 0 0 0
GSM2545365 1 0 1 0 0 0 0 0
GSM2545366 1 0 0 1 0 0 0 0
GSM2545371 1 0 0 0 1 0 0 0
GSM2545375 1 0 0 0 0 1 0 0
GSM2545376 1 0 0 0 0 0 1 0
GSM2545377 1 0 0 0 0 0 0 1
Spc.Day0 Spc.Day4
GSM2545337 0 0
GSM2545338 0 0
GSM2545339 0 0
GSM2545344 0 0
GSM2545348 0 0
GSM2545352 0 0
GSM2545353 0 0
GSM2545358 1 0
GSM2545362 0 0
GSM2545364 1 0
GSM2545365 1 0
GSM2545366 1 0
GSM2545371 0 1
GSM2545375 0 1
GSM2545376 0 1
GSM2545377 0 1R
vd$plotlist
OUTPUT
$`time = Day0`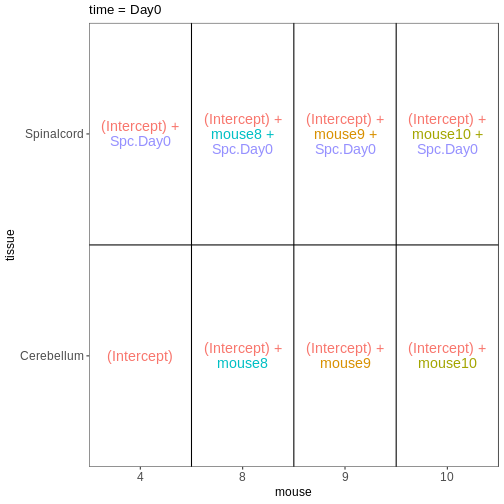
OUTPUT
$`time = Day4`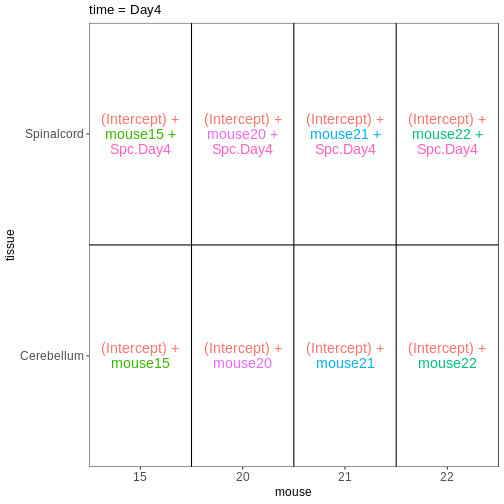
How does this relate to the DESeq2 analysis we did in the previous episode?
Now that we have learnt more about interpreting design matrices, let’s look back to the differential expression analysis we performed in the previous episode. We will repeat the main lines of code here.
R
se <- readRDS("data/GSE96870_se.rds")
se <- se[rowSums(assay(se, "counts")) > 5, ]
dds <- DESeq2::DESeqDataSet(se, design = ~ sex + time)
dds <- DESeq(dds)
OUTPUT
estimating size factorsOUTPUT
estimating dispersionsOUTPUT
gene-wise dispersion estimatesOUTPUT
mean-dispersion relationshipOUTPUT
final dispersion estimatesOUTPUT
fitting model and testingDESeq2 stores the design matrix in the object:
R
attr(dds, "modelMatrix")
OUTPUT
Intercept sex_Male_vs_Female time_Day4_vs_Day0 time_Day8_vs_Day0
Female_Day0_9 1 0 0 0
Female_Day0_10 1 0 0 0
Female_Day0_8 1 0 0 0
Female_Day0_4 1 0 0 0
Male_Day0_11 1 1 0 0
Male_Day0_7 1 1 0 0
Male_Day0_2 1 1 0 0
Female_Day4_15 1 0 1 0
Female_Day4_22 1 0 1 0
Female_Day4_21 1 0 1 0
Female_Day4_20 1 0 1 0
Male_Day4_18 1 1 1 0
Male_Day4_13 1 1 1 0
Male_Day4_1 1 1 1 0
Male_Day4_12 1 1 1 0
Female_Day8_14 1 0 0 1
Female_Day8_5 1 0 0 1
Female_Day8_16 1 0 0 1
Female_Day8_19 1 0 0 1
Male_Day8_6 1 1 0 1
Male_Day8_23 1 1 0 1
Male_Day8_24 1 1 0 1
attr(,"assign")
[1] 0 1 2 2
attr(,"contrasts")
attr(,"contrasts")$sex
[1] "contr.treatment"
attr(,"contrasts")$time
[1] "contr.treatment"The column names can be obtained via the resultsNames
function:
R
resultsNames(dds)
OUTPUT
[1] "Intercept" "sex_Male_vs_Female" "time_Day4_vs_Day0"
[4] "time_Day8_vs_Day0" Let’s visualize this design:
R
vd <- VisualizeDesign(sampleData = colData(dds)[, c("sex", "time")],
designMatrix = attr(dds, "modelMatrix"),
flipCoordFitted = TRUE)
vd$plotlist
OUTPUT
[[1]]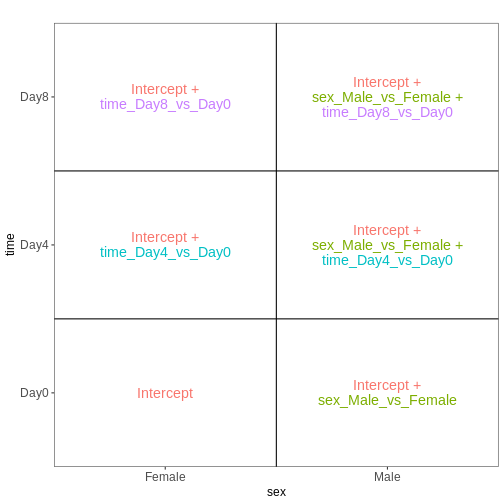
In the previous episode, we performed a test comparing Day8 samples to Day0 samples:
R
resTime <- results(dds, contrast = c("time", "Day8", "Day0"))
From the figure above, we see that this comparison is represented by
the time_Day8_vs_Day0 coefficient, which corresponds to the
fourth column in the design matrix. Thus, an alternative way of
specifying the contrast for the test would be:
R
resTimeNum <- results(dds, contrast = c(0, 0, 0, 1))
Let’s check if the results are comparable:
R
summary(resTime)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 4472, 16%
LFC < 0 (down) : 4282, 16%
outliers [1] : 10, 0.036%
low counts [2] : 3723, 14%
(mean count < 1)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
summary(resTimeNum)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 4472, 16%
LFC < 0 (down) : 4282, 16%
outliers [1] : 10, 0.036%
low counts [2] : 3723, 14%
(mean count < 1)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
## logFC
plot(resTime$log2FoldChange, resTimeNum$log2FoldChange)
abline(0, 1)
R
## -log10(p-value)
plot(-log10(resTime$pvalue), -log10(resTimeNum$pvalue))
abline(0, 1)
Redo DESeq2 analysis with interaction
Next, let’s look at a different setup. We still consider the sex and time predictors, but now we allow an interaction between them. In other words, we allow the time effect to be different for males and females.
R
se <- readRDS("data/GSE96870_se.rds")
se <- se[rowSums(assay(se, "counts")) > 5, ]
dds <- DESeq2::DESeqDataSet(se, design = ~ sex * time)
dds <- DESeq(dds)
OUTPUT
estimating size factorsOUTPUT
estimating dispersionsOUTPUT
gene-wise dispersion estimatesOUTPUT
mean-dispersion relationshipOUTPUT
final dispersion estimatesOUTPUT
fitting model and testingR
attr(dds, "modelMatrix")
OUTPUT
Intercept sex_Male_vs_Female time_Day4_vs_Day0 time_Day8_vs_Day0
Female_Day0_9 1 0 0 0
Female_Day0_10 1 0 0 0
Female_Day0_8 1 0 0 0
Female_Day0_4 1 0 0 0
Male_Day0_11 1 1 0 0
Male_Day0_7 1 1 0 0
Male_Day0_2 1 1 0 0
Female_Day4_15 1 0 1 0
Female_Day4_22 1 0 1 0
Female_Day4_21 1 0 1 0
Female_Day4_20 1 0 1 0
Male_Day4_18 1 1 1 0
Male_Day4_13 1 1 1 0
Male_Day4_1 1 1 1 0
Male_Day4_12 1 1 1 0
Female_Day8_14 1 0 0 1
Female_Day8_5 1 0 0 1
Female_Day8_16 1 0 0 1
Female_Day8_19 1 0 0 1
Male_Day8_6 1 1 0 1
Male_Day8_23 1 1 0 1
Male_Day8_24 1 1 0 1
sexMale.timeDay4 sexMale.timeDay8
Female_Day0_9 0 0
Female_Day0_10 0 0
Female_Day0_8 0 0
Female_Day0_4 0 0
Male_Day0_11 0 0
Male_Day0_7 0 0
Male_Day0_2 0 0
Female_Day4_15 0 0
Female_Day4_22 0 0
Female_Day4_21 0 0
Female_Day4_20 0 0
Male_Day4_18 1 0
Male_Day4_13 1 0
Male_Day4_1 1 0
Male_Day4_12 1 0
Female_Day8_14 0 0
Female_Day8_5 0 0
Female_Day8_16 0 0
Female_Day8_19 0 0
Male_Day8_6 0 1
Male_Day8_23 0 1
Male_Day8_24 0 1
attr(,"assign")
[1] 0 1 2 2 3 3
attr(,"contrasts")
attr(,"contrasts")$sex
[1] "contr.treatment"
attr(,"contrasts")$time
[1] "contr.treatment"Let’s visualize this design:
R
vd <- VisualizeDesign(sampleData = colData(dds)[, c("sex", "time")],
designMatrix = attr(dds, "modelMatrix"),
flipCoordFitted = TRUE)
vd$plotlist
OUTPUT
[[1]]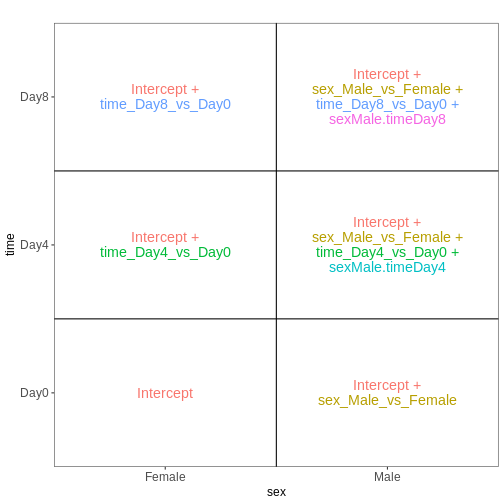
Note that now, the time_Day8_vs_Day0 coefficient
represents the difference between Day8 and Day0 for the Female
samples. To get the corresponding difference for the male
samples, we need to also add the interaction effect
(sexMale.timeDay8).
R
## Day8 vs Day0, female
resTimeFemale <- results(dds, contrast = c("time", "Day8", "Day0"))
## Interaction effect (difference in Day8-Day0 effect between Male and Female)
resTimeInt <- results(dds, name = "sexMale.timeDay8")
Let’s try to fit this model with the second approach mentioned above, namely to create a single factor.
R
se <- readRDS("data/GSE96870_se.rds")
se <- se[rowSums(assay(se, "counts")) > 5, ]
se$sex_time <- paste0(se$sex, "_", se$time)
dds <- DESeq2::DESeqDataSet(se, design = ~ 0 + sex_time)
dds <- DESeq(dds)
OUTPUT
estimating size factorsOUTPUT
estimating dispersionsOUTPUT
gene-wise dispersion estimatesOUTPUT
mean-dispersion relationshipOUTPUT
final dispersion estimatesOUTPUT
fitting model and testingR
attr(dds, "modelMatrix")
OUTPUT
sex_timeFemale_Day0 sex_timeFemale_Day4 sex_timeFemale_Day8
Female_Day0_9 1 0 0
Female_Day0_10 1 0 0
Female_Day0_8 1 0 0
Female_Day0_4 1 0 0
Male_Day0_11 0 0 0
Male_Day0_7 0 0 0
Male_Day0_2 0 0 0
Female_Day4_15 0 1 0
Female_Day4_22 0 1 0
Female_Day4_21 0 1 0
Female_Day4_20 0 1 0
Male_Day4_18 0 0 0
Male_Day4_13 0 0 0
Male_Day4_1 0 0 0
Male_Day4_12 0 0 0
Female_Day8_14 0 0 1
Female_Day8_5 0 0 1
Female_Day8_16 0 0 1
Female_Day8_19 0 0 1
Male_Day8_6 0 0 0
Male_Day8_23 0 0 0
Male_Day8_24 0 0 0
sex_timeMale_Day0 sex_timeMale_Day4 sex_timeMale_Day8
Female_Day0_9 0 0 0
Female_Day0_10 0 0 0
Female_Day0_8 0 0 0
Female_Day0_4 0 0 0
Male_Day0_11 1 0 0
Male_Day0_7 1 0 0
Male_Day0_2 1 0 0
Female_Day4_15 0 0 0
Female_Day4_22 0 0 0
Female_Day4_21 0 0 0
Female_Day4_20 0 0 0
Male_Day4_18 0 1 0
Male_Day4_13 0 1 0
Male_Day4_1 0 1 0
Male_Day4_12 0 1 0
Female_Day8_14 0 0 0
Female_Day8_5 0 0 0
Female_Day8_16 0 0 0
Female_Day8_19 0 0 0
Male_Day8_6 0 0 1
Male_Day8_23 0 0 1
Male_Day8_24 0 0 1
attr(,"assign")
[1] 1 1 1 1 1 1
attr(,"contrasts")
attr(,"contrasts")$sex_time
[1] "contr.treatment"We again visualize this design:
R
vd <- VisualizeDesign(sampleData = colData(dds)[, c("sex", "time")],
designMatrix = attr(dds, "modelMatrix"),
flipCoordFitted = TRUE)
vd$plotlist
OUTPUT
[[1]]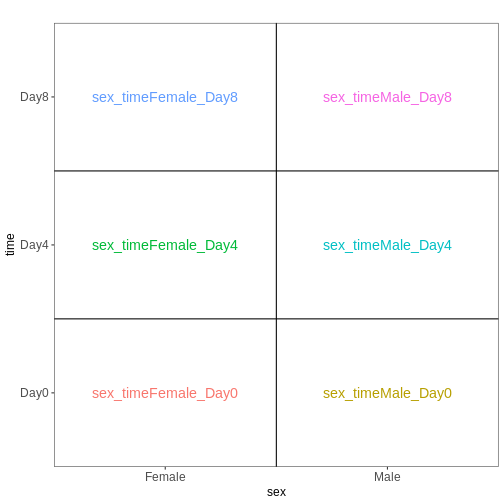
We then set up the same contrasts as above
R
## Day8 vs Day0, female
resTimeFemaleSingle <- results(dds, contrast = c("sex_time", "Female_Day8", "Female_Day0"))
## Interaction effect (difference in Day8-Day0 effect between Male and Female)
resultsNames(dds)
OUTPUT
[1] "sex_timeFemale_Day0" "sex_timeFemale_Day4" "sex_timeFemale_Day8"
[4] "sex_timeMale_Day0" "sex_timeMale_Day4" "sex_timeMale_Day8" R
resTimeIntSingle <- results(dds, contrast = c(1, 0, -1, -1, 0, 1))
Check that these results agree with the ones obtained by fitting the model with the two factors and the interaction term.
R
summary(resTimeFemale)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 2969, 11%
LFC < 0 (down) : 3218, 12%
outliers [1] : 6, 0.022%
low counts [2] : 6382, 23%
(mean count < 3)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
summary(resTimeFemaleSingle)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 2969, 11%
LFC < 0 (down) : 3218, 12%
outliers [1] : 6, 0.022%
low counts [2] : 6382, 23%
(mean count < 3)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
plot(-log10(resTimeFemale$pvalue), -log10(resTimeFemaleSingle$pvalue))
abline(0, 1)
R
summary(resTimeInt)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 0, 0%
LFC < 0 (down) : 0, 0%
outliers [1] : 6, 0.022%
low counts [2] : 0, 0%
(mean count < 0)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
summary(resTimeIntSingle)
OUTPUT
out of 27430 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 0, 0%
LFC < 0 (down) : 0, 0%
outliers [1] : 6, 0.022%
low counts [2] : 0, 0%
(mean count < 0)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsR
plot(-log10(resTimeInt$pvalue), -log10(resTimeIntSingle$pvalue))
abline(0, 1)
- The formula framework in R allows creation of design matrices, which details the variables expected to be associated with systematic differences in gene expression levels.
- Comparisons of interest can be defined using contrasts, which are linear combinations of the model coefficients.
Content from Gene set enrichment analysis
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- What is the aim of performing gene set enrichment analysis?
- What is the method of over-representation analysis?
- What are the commonly-used gene set databases?
Objectives
- Learn the method of gene set enrichment analysis.
- Learn how to obtain gene sets from various resources in R.
- Learn how to perform gene set enrichment analysis and how to visualize enrichment results.
After we have obtained a list of differentially expressed (DE) genes, the next question naturally to ask is what biological functions these DE genes may affect. Gene set enrichment analysis (GSEA) evaluates the associations of a list of DE genes to a collection of pre-defined gene sets, where each gene set has a specific biological meaning. Once DE genes are significantly enriched in a gene set, the conclusion is made that the corresponding biological meaning (e.g. a biological process or a pathway) is significantly affected.
The definition of a gene set is very flexible and the construction of gene sets is straightforward. In most cases, gene sets are from public databases where huge efforts from scientific curators have already been made to carefully categorize genes into gene sets with clear biological meanings. Nevertheless, gene sets can also be self-defined from individual studies, such as a set of genes in a network module from a co-expression network analysis, or a set of genes that are up-regulated in a certain disease.
There are a huge amount of methods available for GSEA analysis. In this episode, we will learn the simplest but the mostly used one: the over-representation analysis (ORA). ORA is directly applied to the list of DE genes and it evaluates the association of the DE genes and the gene set by the numbers of genes in different categories.
Please note, ORA is a universal method that it can not only be applied to the DE gene list, but also any type of gene list of interest to look for their statistically associated biological meanings.
In this episode, we will start with a tiny example to illustrate the statistical method of ORA. Next we will go through several commonly-used gene set databases and how to access them in R. Then, we will learn how to perform ORA analysis with the Bioconductor package clusterProfiler. And in the end, we will learn several visualization methods on the GSEA results.
Following is a list of packages that will be used in this episode:
R
library(SummarizedExperiment)
library(DESeq2)
library(gplots)
library(microbenchmark)
library(org.Hs.eg.db)
library(org.Mm.eg.db)
library(msigdb)
library(clusterProfiler)
library(enrichplot)
library(ggplot2)
library(simplifyEnrichment)
The statistical method
To demonstrate the ORA analysis, we use a list of DE genes from a
comparison between genders. The following code performs
DESeq2 analysis which you should have already learnt in
the previous episode. In the end, we have a list of DE genes filtered by
FDR < 0.05, and save it in the object sexDEgenes.
The file data/GSE96870_se.rds contains a
RangedSummarizedExperiment that contains RNA-Seq counts
that were downloaded in Episode 2 and
constructed in Episode 3 (minimal
codes for downloading and constructing in the script download_data.R.
In the following code, there are also comments that explain every step
of the analysis.
R
library(SummarizedExperiment)
library(DESeq2)
# read the example dataset which is a `RangedSummarizedExperiment` object
se <- readRDS("data/GSE96870_se.rds")
# only restrict to mRNA (protein-coding genes)
se <- se[rowData(se)$gbkey == "mRNA"]
# construct a `DESeqDataSet` object where we also specify the experimental design
dds <- DESeqDataSet(se, design = ~ sex + time)
# perform DESeq2 analysis
dds <- DESeq(dds)
# obtain DESeq2 results, here we only want Male vs Female in the "sex" variable
resSex <- results(dds, contrast = c("sex", "Male", "Female"))
# extract DE genes with padj < 0.05
sexDE <- as.data.frame(subset(resSex, padj < 0.05))
# the list of DE genes
sexDEgenes <- rownames(sexDE)
Let’s check the number of DE genes and how they look like. It seems the number of DE genes is very small, but it is OK for this example.
R
length(sexDEgenes)
OUTPUT
[1] 54R
head(sexDEgenes)
OUTPUT
[1] "Lgr6" "Myoc" "Fibcd1" "Kcna4" "Ctxn2" "S100a9"Next we construct a gene set which contains genes on sex chromosomes
(let’s call it the “XY gene set”). Recall the
RangedSummarizedExperiment object also includes genomic
locations of genes, thus we can simply obtain sex genes by filtering the
chromosome names.
In the following code, geneGR is a GRanges
object on which seqnames() is applied to extract chromosome
names. seqnames() returns a special data format and we need
to explicitly convert it to a normal vector by
as.vector().
R
geneGR <- rowRanges(se)
totalGenes <- rownames(se)
XYGeneSet <- totalGenes[as.vector(seqnames(geneGR)) %in% c("X", "Y")]
head(XYGeneSet)
OUTPUT
[1] "Gm21950" "Gm14346" "Gm14345" "Gm14351" "Spin2-ps1" "Gm3701" R
length(XYGeneSet)
OUTPUT
[1] 1134The format of a single gene set is very straightforward, which is simply a vector. The ORA analysis is applied on the DE gene vector and gene set vector.
Before we move on, one thing worth to mention is that ORA deals with
two gene vectors. To correctly map between them, gene ID types must be
consistent in the two vectors. In this tiny example, since both DE genes
and the XY gene set are from the same object se,
they are ensured to be in the same gene ID types (the gene symbol). But
in general, DE genes and gene sets are from two different sources
(e.g. DE genes are from researcher’s experiment and gene sets are from
public databases), it is very possible that gene IDs are not consistent
in the two. Later in this episode, we will learn how to perform gene ID
conversion in the ORA analysis.
Since the DE genes and the gene set can be mathematically thought of as two sets, a natural way is to first visualize them with a Venn diagram.
R
library(gplots)
plot(venn(list("sexDEgenes" = sexDEgenes,
"XY gene set" = XYGeneSet)))
title(paste0("|universe| = ", length(totalGenes)))
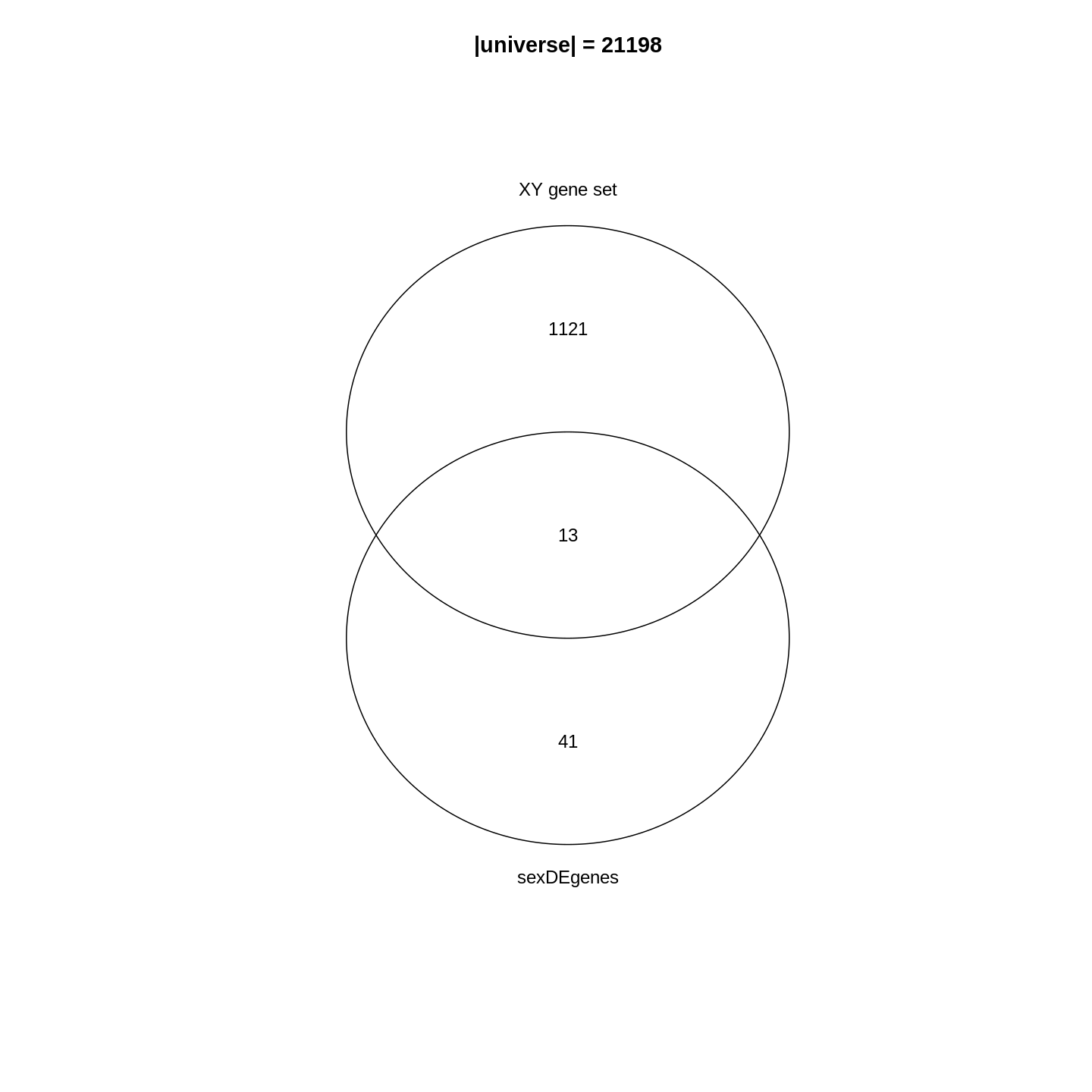
In the Venn diagram, we can observe that around 1.1% (13/1134) of genes in the XY gene set are DE. Compared to the global fraction of DE genes (54/21198 = 0.25%), it seems there is a strong relations between DE genes and the gene set. We can also compare the fraction of DE genes that belong to the gene set (13/54 = 24.1%) and the global fraction of XY gene set in the genome (1134/21198 = 5.3%). On the other hand, it is quite expected because the two events are actually biologically relevant where one is from a comparison between genders and the other is the set of gender-related genes.
Then, how to statistically measure the enrichment or over-representation? Let’s go to the next section.
Fisher’s exact test
To statistically measure the enrichment, the relationship of DE genes and the gene set is normally formatted into the following 2x2 contingency table, where in the table are the numbers of genes in different categories. \(n_{+1}\) is the size of the XY gene set (i.e. the number of member genes), \(n_{1+}\) is the number of DE genes, \(n\) is the number of total genes.
| In the gene set | Not in the gene set | Total | |
|---|---|---|---|
| DE | \(n_{11}\) | \(n_{12}\) | \(n_{1+}\) |
| Not DE | \(n_{21}\) | \(n_{22}\) | \(n_{2+}\) |
| Total | \(n_{+1}\) | \(n_{+2}\) | \(n\) |
These numbers can be obtained as in the following code1. Note we replace
+ with 0 in the R variable names.
R
n <- nrow(se)
n_01 <- length(XYGeneSet)
n_10 <- length(sexDEgenes)
n_11 <- length(intersect(sexDEgenes, XYGeneSet))
Other values can be obtained by:
R
n_12 <- n_10 - n_11
n_21 <- n_01 - n_11
n_20 <- n - n_10
n_02 <- n - n_01
n_22 <- n_02 - n_12
All the values are:
R
matrix(c(n_11, n_12, n_10, n_21, n_22, n_20, n_01, n_02, n),
nrow = 3, byrow = TRUE)
OUTPUT
[,1] [,2] [,3]
[1,] 13 41 54
[2,] 1121 20023 21144
[3,] 1134 20064 21198And we fill these numbers into the 2x2 contingency table:
| In the gene set | Not in the gene set | Total | |
|---|---|---|---|
| DE | 13 | 41 | 54 |
| Not DE | 1121 | 20023 | 21144 |
| Total | 1134 | 20064 | 21198 |
Fisher’s exact test can be used to test the associations of the two
marginal attributes, i.e. is there a dependency of a gene to be a DE
gene and to be in the XY gene set? In R, we can use the
function fisher.test() to perform the test. The input is
the top-left 2x2 sub-matrix. We specify
alternative = "greater" in the function because we are only
interested in over-representation.
R
fisher.test(matrix(c(n_11, n_12, n_21, n_22), nrow = 2, byrow = TRUE),
alternative = "greater")
OUTPUT
Fisher's Exact Test for Count Data
data: matrix(c(n_11, n_12, n_21, n_22), nrow = 2, byrow = TRUE)
p-value = 3.906e-06
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
3.110607 Inf
sample estimates:
odds ratio
5.662486 In the output, we can see the p-value is very small
(3.906e-06), then we can conclude DE genes have a very
strong enrichment in the XY gene set.
Results of the Fisher’s Exact test can be saved into an object
t, which is a simple list, and the p-value can be
obtained by t$p.value.
R
t <- fisher.test(matrix(c(n_11, n_12, n_21, n_22), nrow = 2, byrow = TRUE),
alternative = "greater")
t$p.value
OUTPUT
[1] 3.9059e-06Odds ratio from the Fisher’s exact test is defined as follows:
\[ \mathrm{Odds\_ratio} = \frac{n_{11}/n_{21}}{n_{12}/n_{22}} = \frac{n_{11}/n_{12}}{n_{21}/n_{22}} = \frac{n_{11} * n_{22}}{n_{12} * n_{21}} \]
If there is no association between DE genes and the gene set, odds ratio is expected to be 1. And it is larger than 1 if there is an over-representation of DE genes on the gene set.
Further reading
The 2x2 contingency table can be transposed and it does not affect the Fisher’s exact test. E.g. let’s put whether genes are in the gene sets on rows, and put whether genes are DE on columns.
| DE | Not DE | Total | |
|---|---|---|---|
| In the gene set | 13 | 1121 | 1134 |
| Not in the gene set | 41 | 20023 | 20064 |
| Total | 54 | 21144 | 21198 |
And the corresponding fisher.test() is:
R
fisher.test(matrix(c(13, 1121, 41, 20023), nrow = 2, byrow = TRUE),
alternative = "greater")
OUTPUT
Fisher's Exact Test for Count Data
data: matrix(c(13, 1121, 41, 20023), nrow = 2, byrow = TRUE)
p-value = 3.906e-06
alternative hypothesis: true odds ratio is greater than 1
95 percent confidence interval:
3.110607 Inf
sample estimates:
odds ratio
5.662486 The hypergeometric distribution
We can look at the problem from another aspect. This time we treat all genes as balls in a big box where all the genes have the same probability to be picked up. Some genes are marked as DE genes (in red in the figure) and other genes are marked as non-DE genes (in blue). We grab \(n_{+1}\) genes (the size of the gene set) from the box and we want to ask what is the probability of having \(n_{11}\) DE genes in our hand?
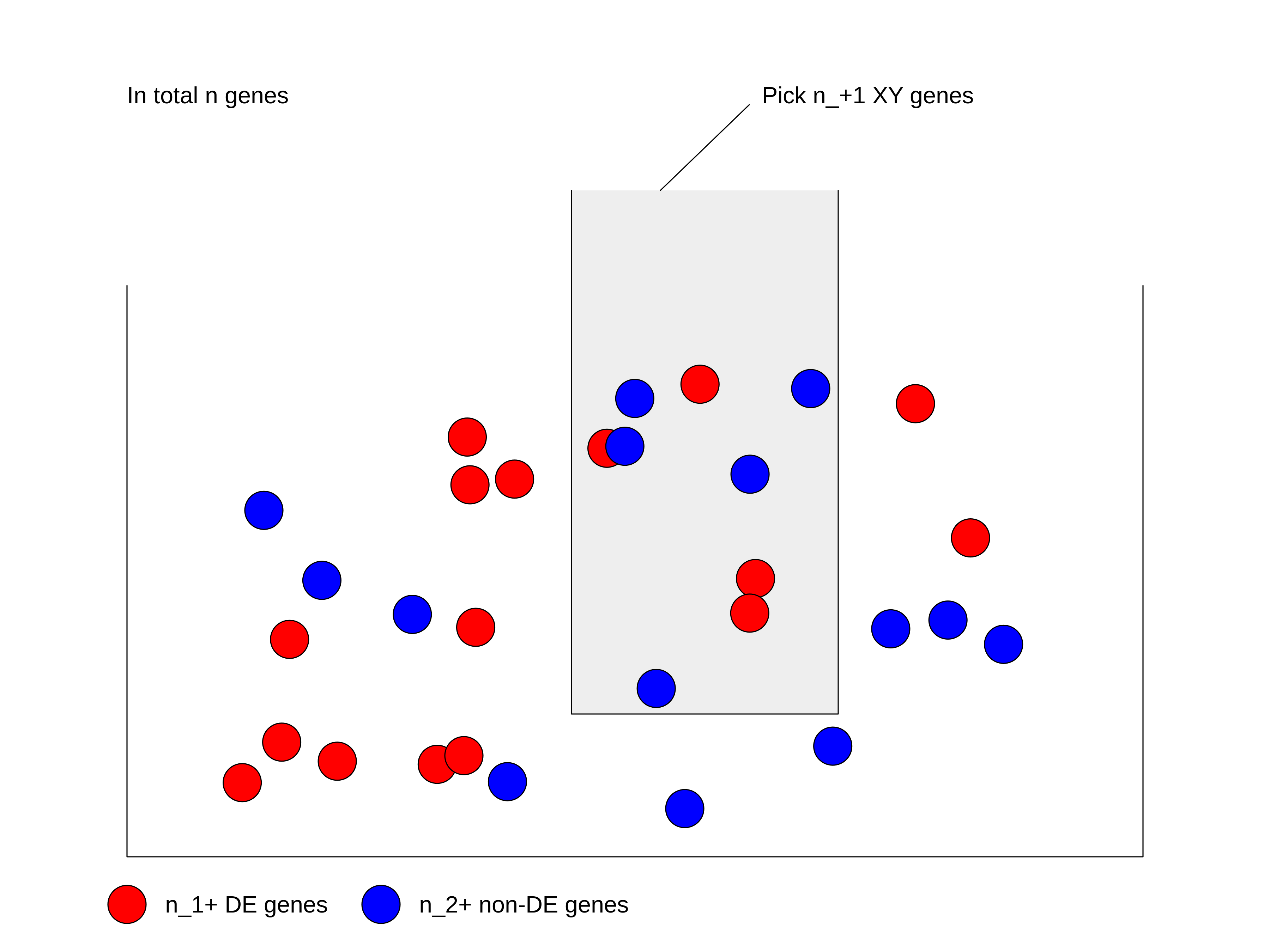
We first calculate the total number of ways of picking \(n_{+1}\) genes from total \(n\) genes, without distinguishing whether they are DE or not: \(\binom{n}{n_{+1}}\).
Next, in the \(n_{+1}\) genes that have been picked, there are \(n_{11}\) DE genes which can only be from the total \(n_{1+}\) DE genes. Then the number of ways of picking \(n_{11}\) DE genes from \(n_{1+}\) total DE genes is \(\binom{n_{1+}}{n_{11}}\).
Similarly, there are still \(n_{21}\) non-DE genes in our hand, which can only be from the total \(n_{2+}\) non-DE genes. Then the number of ways of picking \(n_{21}\) non-DE genes from \(n_{2+}\) total non-DE genes: \(\binom{n_{2+}}{n_{21}}\).
Since picking DE genes and picking non-DE genes are independent, the number of ways of picking \(n_{+1}\) genes which contain \(n_{11}\) DE genes and \(n_{21}\) non-DE genes is their multiplication: \(\binom{n_{1+}}{n_{11}} \binom{n_{2+}}{n_{21}}\).
And the probability \(P\) is:
\[P = \frac{\binom{n_{1+}}{n_{11}} \binom{n_{2+}}{n_{21}}}{\binom{n}{n_{+1}}} = \frac{\binom{n_{1+}}{n_{11}} \binom{n - n_{1+}}{n_{+1} -n_{11}}}{\binom{n}{n_{+1}}} \]
where in the denominator is the number of ways of picking \(n_{+1}\) genes without distinguishing whether they are DE or not.
If \(n\) (number of total genes), \(n_{1+}\) (number of DE genes) and \(n_{+1}\) (size of gene set) are all fixed values, the number of DE genes that are picked can be denoted as a random variable \(X\). Then \(X\) follows the hypergeometric distribution with parameters \(n\), \(n_{1+}\) and \(n_{+1}\), written as:
\[ X \sim \mathrm{Hyper}(n, n_{1+}, n_{+1})\]
The p-value of the enrichment is calculated as the probability of having an observation equal to or larger than \(n_{11}\) under the assumption of independence:
\[ \mathrm{Pr}( X \geqslant n_{11} ) = \sum_{x \in \{ {n_{11}, n_{11}+1, ..., \min\{n_{1+}, n_{+1}\} \}}} \mathrm{Pr}(X = x) \]
In R, the function phyper() calculates p-values
from the hypergeometric distribution. There are four arguments:
R
phyper(q, m, n, k)
which are:
-
q: the observation, -
m: number of DE genes, -
n: number of non-DE genes, -
k: size of the gene set.
phyper() calculates \(\mathrm{Pr}(X \leqslant q)\). To calculate
\(\mathrm{Pr}(X \geqslant q)\), we need
to transform it a little bit:
\[ \mathrm{Pr}(X \geqslant q) = 1 - \mathrm{Pr}(X < q) = 1 - \mathrm{Pr}(X \leqslant q-1)\]
Then, the correct use of phyper() is:
R
1 - phyper(q - 1, m, n, k)
Let’s plugin our variables:
R
1 - phyper(n_11 - 1, n_10, n_20, n_01)
OUTPUT
[1] 3.9059e-06Optionally, lower.tail argument can be specified which
directly calculates p-values from the upper tail of the
distribution.
R
phyper(n_11 - 1, n_10, n_20, n_01, lower.tail = FALSE)
OUTPUT
[1] 3.9059e-06If we switch n_01 and n_10, the
p-values are identical:
R
1 - phyper(n_11 - 1, n_01, n_02, n_10)
OUTPUT
[1] 3.9059e-06fisher.test() and phyper() give the same
p-value. Actually the two methods are identical because in
Fisher’s exact test, hypergeometric distribution is the exact
distribution of its statistic.
Let’s test the runtime of the two functions:
R
library(microbenchmark)
microbenchmark(
fisher = fisher.test(matrix(c(n_11, n_12, n_21, n_22), nrow = 2, byrow = TRUE),
alternative = "greater"),
hyper = 1 - phyper(n_11 - 1, n_10, n_20, n_01)
)
OUTPUT
Unit: microseconds
expr min lq mean median uq max neval
fisher 261.349 265.3810 277.03629 270.6155 286.1945 493.071 100
hyper 1.693 1.8985 3.05905 3.2060 3.5315 21.220 100It is very astonishing that phyper() is hundreds of
times faster than fisher.test(). Main reason is in
fisher.test(), there are many additional calculations
besides calculating the p-value. So if you want to implement
ORA analysis by yourself, always consider to use phyper()2.
Further reading
Current tools also use Binomial distribution or chi-square test for ORA analysis. These two are just approximations. Please refer to Rivals et al., Enrichment or depletion of a GO category within a class of genes: which test? Bioinformatics 2007 which gives an overview of statistical methods used in ORA analysis.
Gene set resources
We have learnt the basic methods of ORA analysis. Now we go to the second component of the analysis: the gene sets.
Gene sets represent prior knowledge of what is the general shared biological attribute of genes in the gene set. For example, in a “cell cycle” gene set, all the genes are involved in the cell cycle process. Thus, if DE genes are significantly enriched in the “cell cycle” gene set, which means there are significantly more cell cycle genes differentially expressed than expected, we can conclude that the normal function of cell cycle process may be affected.
As we have mentioned, genes in the gene set share the same “biological attribute” where “the attribute” will be used for making conclusions. The definition of “biological attribute” is very flexible. It can be a biological process such as “cell cycle”. It can also be from a wide range of other definitions, to name a few:
- Locations in the cell, e.g. cell membrane or cell nucleus.
- Positions on chromosomes, e.g. sex chromosomes or the cytogenetic band p13 on chromome 10.
- Target genes of a transcription factor or a microRNA, e.g. all genes that are transcriptionally regulationed by NF-κB.
- Signature genes in a certain tumor type, i.e. genes that are uniquely highly expressed in a tumor type.
The MSigDB database contains gene sets in many topics. We will introduce it later in this section.
You may have encountered many different ways to name gene sets: “gene sets”, “biological terms”, “GO terms”, “GO gene sets”, “pathways”, and so on. They basically refer to the same thing, but from different aspects. As shown in the following figure, “gene set” corresponds to a vector of genes and it is the representation of the data for computation. “Biological term” is a textual entity that contains description of its biological meaning; It corresponds to the knowledge of the gene set and is for the inference of the analysis. “GO gene sets” and “pathways” specifically refer to the enrichment analysis using GO gene sets and pahtway gene sets.

Before we touch the gene set databases, we first summarize the general formats of gene sets in R. In most analysis, a gene set is simply treated as a vector of genes. Thus, naturally, a collection of gene sets can be represented as a list of vectors. In the following example, there are three gene sets with 3, 5 and 2 genes. Some genes exist in multiple gene sets.
R
lt <- list(gene_set_1 = c("gene_1", "gene_2", "gene_3"),
gene_set_2 = c("gene_1", "gene_3", "gene_4", "gene_5", "gene_6"),
gene_set_3 = c("gene_4", "gene_7")
)
lt
OUTPUT
$gene_set_1
[1] "gene_1" "gene_2" "gene_3"
$gene_set_2
[1] "gene_1" "gene_3" "gene_4" "gene_5" "gene_6"
$gene_set_3
[1] "gene_4" "gene_7"It is also very common to store the relations of gene sets and genes as a two-column data frame. The order of the gene set column and the gene column, i.e. which column locates as the first column, are quite arbitrary. Different tools may require differently.
R
data.frame(gene_set = rep(names(lt), times = sapply(lt, length)),
gene = unname(unlist(lt)))
OUTPUT
gene_set gene
1 gene_set_1 gene_1
2 gene_set_1 gene_2
3 gene_set_1 gene_3
4 gene_set_2 gene_1
5 gene_set_2 gene_3
6 gene_set_2 gene_4
7 gene_set_2 gene_5
8 gene_set_2 gene_6
9 gene_set_3 gene_4
10 gene_set_3 gene_7Or genes be in the first column:
OUTPUT
gene gene_set
1 gene_1 gene_set_1
2 gene_2 gene_set_1
3 gene_3 gene_set_1
4 gene_1 gene_set_2
5 gene_3 gene_set_2
6 gene_4 gene_set_2
7 gene_5 gene_set_2
8 gene_6 gene_set_2
9 gene_4 gene_set_3
10 gene_7 gene_set_3Not very often, gene sets are represented as a matrix where one dimension corresponds to gene sets and the other dimension corresponds to genes. The values in the matix are binary where a value of 1 represents the gene is a member of the corresponding gene sets. In some methods, 1 is replaced by \(w_{ij}\) to weight the effect of the genes in the gene set.
# gene_1 gene_2 gene_3 gene_4
# gene_set_1 1 1 0 0
# gene_set_2 1 0 1 1Challenge
Can you convert between different gene set representations? E.g. convert a list to a two-column data frame?
R
lt <- list(gene_set_1 = c("gene_1", "gene_2", "gene_3"),
gene_set_2 = c("gene_1", "gene_3", "gene_4", "gene_5", "gene_6"),
gene_set_3 = c("gene_4", "gene_7")
)
To convert lt to a data frame (e.g. let’s put gene sets
in the first column):
R
df = data.frame(gene_set = rep(names(lt), times = sapply(lt, length)),
gene = unname(unlist(lt)))
df
OUTPUT
gene_set gene
1 gene_set_1 gene_1
2 gene_set_1 gene_2
3 gene_set_1 gene_3
4 gene_set_2 gene_1
5 gene_set_2 gene_3
6 gene_set_2 gene_4
7 gene_set_2 gene_5
8 gene_set_2 gene_6
9 gene_set_3 gene_4
10 gene_set_3 gene_7To convert df back to the list:
R
split(df$gene, df$gene_set)
OUTPUT
$gene_set_1
[1] "gene_1" "gene_2" "gene_3"
$gene_set_2
[1] "gene_1" "gene_3" "gene_4" "gene_5" "gene_6"
$gene_set_3
[1] "gene_4" "gene_7"Next, let’s go through gene sets from several major databases: the GO, KEGG and MSigDB databases.
Gene Ontology gene sets
Gene Ontology (GO) is the standard source for gene set enrichment analysis. GO contains three namespaces of biological process (BP), cellular components (CC) and molecular function (MF) which describe a biological entity from different aspect. The associations between GO terms and genes are integrated in the Bioconductor standard packages: the organism annotation packages. In the current Bioconductor release, there are the following organism packages:
| Package | Organism | Package | Organism |
|---|---|---|---|
| org.Hs.eg.db | Human | org.Mm.eg.db | Mouse |
| org.Rn.eg.db | Rat | org.Dm.eg.db | Fly |
| org.At.tair.db | Arabidopsis | org.Dr.eg.db | Zebrafish |
| org.Sc.sgd.db | Yeast | org.Ce.eg.db | Worm |
| org.Bt.eg.db | Bovine | org.Gg.eg.db | Chicken |
| org.Ss.eg.db | Pig | org.Mmu.eg.db | Rhesus |
| org.Cf.eg.db | Canine | org.EcK12.eg.db | E coli strain K12 |
| org.Xl.eg.db | Xenopus | org.Pt.eg.db | Chimp |
| org.Ag.eg.db | Anopheles | org.EcSakai.eg.db | E coli strain Sakai |
There are four sections in the name of an organism package. The
naming convention is: org simply means “organism”. The
second section corresponds to a specific organism, e.g. Hs
for human and Mm for mouse. The third section corresponds
to the primary gene ID type used in the package, where normally
eg is used which means “Entrez genes” because data is
mostly retrieved from the NCBI database. However, for some organisms,
the primary ID can be from its own primary database,
e.g. sgd for Yeast which corresponds to the Saccharomyces Genome Database,
the primary database for yeast. The last section is always “db”, which
simply implies it is a database package.
Taking the org.Hs.eg.db package as an example, all
the data is stored in a database object org.Hs.eg.db in the
OrgDb class. The object contains a connection to a local
SQLite database. Users can simply think org.Hs.eg.db as a
huge table that contains ID mappings between various databases. GO gene
sets are essentially mappings between GO terms and genes. Let’s try to
extract it from the org.Hs.eg.db object.
All the columns (the key column or the source column) can be obtained
by keytypes():
R
library(org.Hs.eg.db)
keytypes(org.Hs.eg.db)
OUTPUT
[1] "ACCNUM" "ALIAS" "ENSEMBL" "ENSEMBLPROT" "ENSEMBLTRANS"
[6] "ENTREZID" "ENZYME" "EVIDENCE" "EVIDENCEALL" "GENENAME"
[11] "GENETYPE" "GO" "GOALL" "IPI" "MAP"
[16] "OMIM" "ONTOLOGY" "ONTOLOGYALL" "PATH" "PFAM"
[21] "PMID" "PROSITE" "REFSEQ" "SYMBOL" "UCSCKG"
[26] "UNIPROT" To get the GO gene sets, we first obtain all GO IDs under the BP
(biological process) namespace. As shown in the output from
keytype(), "ONTOLOGY" is also a valid “key
column”, thus we can query “select all GO IDs where the
corresponding ONTOLOGY is BP”, which is translated into the
following code:
R
BP_Id = mapIds(org.Hs.eg.db, keys = "BP", keytype = "ONTOLOGY",
column = "GO", multiVals = "list")[[1]]
head(BP_Id)
OUTPUT
[1] "GO:0060396" "GO:0001869" "GO:0006805" "GO:0006953" "GO:0006954"
[6] "GO:0019216"mapIds() maps IDs between two sources. Since a GO
namespace have more than one GO terms, we have to set
multiVals = "list" to obtain all GO terms under that
namespace. And since we only query for one GO “ONTOLOGY”, we directly
take the first element from the list returned by
mapIds().
Next we do mapping from GO IDs to gene Entrez IDs. Now the query becomes “providing a vector of GO IDs, select ENTREZIDs which correspond to every one of them”.
R
BPGeneSets = mapIds(org.Hs.eg.db, keys = BP_Id, keytype = "GOALL",
column = "ENTREZID", multiVals = "list")
You may have noticed there is a “GO” key column as well a “GOALL”
column in the database. As GO has a hierarchical structure where a child
term is a sub-class of a parent term. All the genes annotated to a child
term are also annotated to its parent terms. To reduce the duplicated
information when annotating genes to GO terms, genes are normally
annotated to the most specific offspring terms in the GO hierarchy.
Upstream merging of gene annotations should be done by the tools which
perform analysis. In this way, the mapping between "GO" and
"ENTREZID" only contains “primary” annotations which is not
complete, and mapping between "GOALL" and
"ENTREZID" is the correct one to use.
We filter out GO gene sets with no gene annotated.
R
BPGeneSets = BPGeneSets[sapply(BPGeneSets, length) > 0]
BPGeneSets[2:3] # BPGeneSets[[1]] is too long
OUTPUT
$`GO:0001869`
[1] "2" "710"
$`GO:0006805`
[1] "9" "10" "13" "30" "100" "196" "196" "217"
[9] "218" "314" "316" "405" "590" "670" "670" "790"
[17] "873" "874" "1244" "1244" "1429" "1543" "1543" "1543"
[25] "1544" "1544" "1544" "1544" "1545" "1545" "1545" "1548"
[33] "1548" "1548" "1549" "1551" "1553" "1555" "1555" "1555"
[41] "1555" "1557" "1557" "1557" "1558" "1558" "1558" "1559"
[49] "1559" "1559" "1559" "1562" "1562" "1564" "1564" "1565"
[57] "1565" "1565" "1565" "1571" "1571" "1571" "1571" "1572"
[65] "1572" "1573" "1573" "1576" "1576" "1576" "1576" "1577"
[73] "1577" "1577" "1592" "1645" "1645" "1728" "1806" "2030"
[81] "2052" "2180" "2327" "2327" "2327" "2329" "2330" "2330"
[89] "2902" "2938" "2939" "2940" "2941" "2941" "2944" "2946"
[97] "2947" "2948" "2948" "2950" "2987" "2987" "3172" "4025"
[105] "4363" "4363" "4842" "5243" "5581" "6095" "6095" "6097"
[113] "6283" "6579" "6580" "6799" "6817" "6818" "6822" "7172"
[121] "7172" "7363" "7364" "7364" "7366" "7366" "7367" "8529"
[129] "8647" "8647" "8714" "8714" "8824" "8856" "9153" "9446"
[137] "9915" "10057" "10249" "10257" "10599" "10720" "10741" "10858"
[145] "10864" "10941" "11309" "23491" "27233" "27284" "28234" "29104"
[153] "29785" "54498" "54575" "54575" "54575" "54576" "54576" "54577"
[161] "54577" "54577" "54578" "54578" "54578" "54600" "54600" "54600"
[169] "54658" "54658" "54658" "54659" "54659" "54905" "54905" "55270"
[177] "55315" "55347" "56603" "57412" "57412" "57491" "57491" "64078"
[185] "66002" "79001" "79799" "80777" "113612" "116285" "119391" "120227"
[193] "134147" "151531" "221357" "348158" "407019" "442038" "445329" "494327"
[201] "574537"In most cases, because OrgDb is a standard Bioconductor
data structure, most tools can automatically construct GO gene sets
internally. There is no need for users to touch such low-level
processings.
Further reading
Mapping between various databases can also be done with the general
select() interface. If the OrgDb object is
provided by a package such as org.Hs.eg.db, there is
also a separated object that specifically contains mapping between GO
terms and genes. Readers can check the documentation of
org.Hs.egGO2ALLEGS. Additional information on GO terms such
as GO names and long descriptions are available in the package
GO.db.
Bioconductor has already provided a large number of organism
packages. However, if the organism you are working on is not supported
there, you may consider to look for it with the
AnnotationHub package, which additionally provide
OrgDb objects for approximately 2000 organisms. The
OrgDb object can be directly used in the ORA analysis
introduced in the next section.
KEGG gene sets
A biological pathway is a series of interactions among molecules in a cell that leads to a certain product or a change in a cell3. A pathway involves a list of genes playing different roles which constructs the “pathway gene set”. KEGG pathway is the mostly used database for pathways. It provides its data via a REST API (https://rest.kegg.jp/). There are several commands to retrieve specific types of data. To retrieve the pathway gene sets, we can use the “link” command as shown in the following URL (“link” means to link genes to pathways). When you enter the URL in the web browser:
https://rest.kegg.jp/link/pathway/hsathere will be a text table which contains a column of genes and a column of pathway IDs.
hsa:10327 path:hsa00010
hsa:124 path:hsa00010
hsa:125 path:hsa00010
hsa:126 path:hsa00010We can directly read the text output with read.table().
Wrapping the URL with the function url(), you can pretend
to directly read data from the remote web server.
R
keggGeneSets = read.table(url("https://rest.kegg.jp/link/pathway/hsa"), sep = "\t")
head(keggGeneSets)
OUTPUT
V1 V2
1 hsa:10327 path:hsa00010
2 hsa:124 path:hsa00010
3 hsa:125 path:hsa00010
4 hsa:126 path:hsa00010
5 hsa:127 path:hsa00010
6 hsa:128 path:hsa00010In this two-column table, the first column contains genes in the
Entrez ID type. Let’s remove the "hsa:" prefix, also we
remove the "path:" prefix for pathway IDs in the second
column.
R
keggGeneSets[, 1] = gsub("hsa:", "", keggGeneSets[, 1])
keggGeneSets[, 2] = gsub("path:", "", keggGeneSets[, 2])
head(keggGeneSets)
OUTPUT
V1 V2
1 10327 hsa00010
2 124 hsa00010
3 125 hsa00010
4 126 hsa00010
5 127 hsa00010
6 128 hsa00010The full pathway names can be obtained via the “list” command.
R
keggNames = read.table(url("https://rest.kegg.jp/list/pathway/hsa"), sep = "\t")
head(keggNames)
OUTPUT
V1 V2
1 hsa01100 Metabolic pathways - Homo sapiens (human)
2 hsa01200 Carbon metabolism - Homo sapiens (human)
3 hsa01210 2-Oxocarboxylic acid metabolism - Homo sapiens (human)
4 hsa01212 Fatty acid metabolism - Homo sapiens (human)
5 hsa01230 Biosynthesis of amino acids - Homo sapiens (human)
6 hsa01232 Nucleotide metabolism - Homo sapiens (human)In both commands, we obtained data for human where the corresponding
KEGG code is "hsa". The code for other organisms can be
found from the KEGG website
(e.g. "mmu" for mouse), or via https://rest.kegg.jp/list/organism.
Keep in mind, KEGG pathways are only free for academic users. If you use it for commercial purposes, please contact the KEGG team to get a licence.
Further reading
Instead directly reading from the URLs, there are also R packages
which help to obtain data from the KEGG database, such as the
KEGGREST package or the download_KEGG()
function from the clusterProfiler package. But
essentially, they all obtain KEGG data with the REST API.
MSigDB gene sets
Molecular signature database (MSigDB) is a manually curated gene set database. Initially, it was proposed as a supplementary dataset for the original GSEA paper. Later it has been separated out and developed independently. In the first version in 2005, there were only two gene sets collections and in total 843 gene sets. Now in the newest version of MSigDB (v2023.1.Hs), it has grown into nine gene sets collections, covering > 30K gene sets. It provides gene sets on a variety of topics.
MSigDB categorizes gene sets into nine collections where each collection focuses on a specific topic. For some collections, they are additionally split into sub-collections. There are several ways to obtain gene sets from MSigDB. One convenient way is to use the msigdb package. Another option is to use the msigdbr CRAN package, which supports organisms other than human and mouse by mapping to orthologs.
msigdb provides mouse and human gene sets, defined using either gene symbols or Entrez IDs. Let’s get the mouse collection.
R
library(msigdb)
library(ExperimentHub)
library(GSEABase)
MSigDBGeneSets <- getMsigdb(org = "mm", id = "SYM", version = "7.4")
The msigdb object above is a
GeneSetCollection, storing all gene sets from MSigDB. The
GeneSetCollection object class is defined in the
GSEABase package, and it is a linear data structure similar
to a base list object, but with additional metadata such as the type of
gene identifier or provenance information about the gene sets.
R
MSigDBGeneSets
OUTPUT
GeneSetCollection
names: 10qA1, 10qA2, ..., ZZZ3_TARGET_GENES (44688 total)
unique identifiers: Epm2a, Esr1, ..., Gm52481 (53805 total)
types in collection:
geneIdType: SymbolIdentifier (1 total)
collectionType: BroadCollection (1 total)R
length(MSigDBGeneSets)
OUTPUT
[1] 44688Each signature is stored in a GeneSet object, also
defined in the GSEABase package.
R
gs <- MSigDBGeneSets[[2000]]
gs
OUTPUT
setName: DESCARTES_MAIN_FETAL_CHROMAFFIN_CELLS
geneIds: Asic5, Cntfr, ..., Slc22a22 (total: 28)
geneIdType: Symbol
collectionType: Broad
bcCategory: c8 (Cell Type Signatures)mh (Mouse-Ortholog Hallmark)
bcSubCategory: NA
details: use 'details(object)'R
collectionType(gs)
OUTPUT
collectionType: Broad
bcCategory: c8 (Cell Type Signatures)mh (Mouse-Ortholog Hallmark)
bcSubCategory: NAR
geneIds(gs)
OUTPUT
[1] "Asic5" "Cntfr" "Galnt16" "Galnt14" "Gip" "Hmx1"
[7] "Il7" "Insl5" "Insm2" "Insm1" "Mab21l1" "Mab21l2"
[13] "Npy" "Pyy" "Ntrk1" "Ntrk2" "Ntrk3" "Phox2a"
[19] "Ptchd1" "Ptchd4" "Reg4" "Slc22a26" "Slc22a30" "Slc22a19"
[25] "Slc22a27" "Slc22a29" "Slc22a28" "Slc22a22"We can also subset the collection. First, let’s list the available collections and subcollections.
R
listCollections(MSigDBGeneSets)
OUTPUT
[1] "c1" "c3" "c2" "c8" "c6" "c7" "c4" "c5" "h" R
listSubCollections(MSigDBGeneSets)
OUTPUT
[1] "MIR:MIR_Legacy" "TFT:TFT_Legacy" "CGP" "TFT:GTRD"
[5] "VAX" "CP:BIOCARTA" "CGN" "GO:BP"
[9] "GO:CC" "IMMUNESIGDB" "GO:MF" "HPO"
[13] "MIR:MIRDB" "CM" "CP" "CP:PID"
[17] "CP:REACTOME" "CP:WIKIPATHWAYS"Then, we retrieve only the ‘hallmarks’ collection.
R
(hm <- subsetCollection(MSigDBGeneSets, collection = "h"))
OUTPUT
GeneSetCollection
names: HALLMARK_ADIPOGENESIS, HALLMARK_ALLOGRAFT_REJECTION, ..., HALLMARK_XENOBIOTIC_METABOLISM (50 total)
unique identifiers: Abca1, Abca4, ..., Upb1 (5435 total)
types in collection:
geneIdType: SymbolIdentifier (1 total)
collectionType: BroadCollection (1 total)If you only want to use a sub-category, specify both the
collection and subcollection arguments to
subsetCollection.
ORA with clusterProfiler
The ORA method itself is quite simple and it has been implemented in a large number of R packages. Among them, the clusterProfiler package especially does a good job in that it has a seamless integration to the Bioconductor annotation resources which allows extending GSEA analysis to other organisms easily; it has pre-defined functions for common analysis tasks, e.g. GO enrichment, KEGG enrichment; and it implements a variety of different visualization methods on the GSEA results. In this section, we will learn how to perform ORA analysis with clusterProfiler.
Here we will use a list of DE genes from a different comparison. As you may still remember, there are only 54 DE genes between genders, which may not be a good case for GSEA analysis, since after overlapping to a collection of gene sets, the majority of the gene sets will have few or even no gene overlapped. In this example we use the list of DE genes from the comparison between different time points.
Another thing worth to mention is, in the following code where we filter DE genes, we additionally add a filtering on the log2 fold change. This is recommended when the number of DE genes is too large. The filtering on log2 fold change can be thought as a filtering from the biology aspect.
R
resTime <- DESeq2::results(dds, contrast = c("time", "Day8", "Day0"))
timeDE <- as.data.frame(subset(resTime,
padj < 0.05 & abs(log2FoldChange) > log2(1.5)
))
timeDEgenes <- rownames(timeDE)
head(timeDEgenes)
OUTPUT
[1] "3110035E14Rik" "Sgk3" "Kcnb2" "Sbspon"
[5] "Gsta3" "Lman2l" R
length(timeDEgenes)
OUTPUT
[1] 1134Let’s confirm that there are around one thousand DE genes, and the DE genes are in gene symbols.
GO enrichment
In clusterProfiler, there is an
enrichGO() function which performs ORA on GO gene sets. To
use it, we need to provide the DE genes, the organism OrgDb
object which is from the organism package org.Mm.eg.db
(because our data is from mouse), also the GO namespace (one of
"BP", "CC" and "MF"). The GO gene
sets are automatically retrieved and processed from
org.Mm.eg.db in enrichGO().
R
library(clusterProfiler)
library(org.Mm.eg.db)
resTimeGO = enrichGO(gene = timeDEgenes,
ont = "BP",
OrgDb = org.Mm.eg.db)
WARNING
Warning in packageDescription(pkgname, fields = "Version"): no package '--> No
gene can be mapped....' was foundWARNING
Warning in packageDescription(pkgname, fields = "Version"): no package '-->
Expected input gene ID: ' was foundWARNING
Warning in packageDescription(pkgname, fields = "Version"): no package '-->
return NULL...' was foundOops, something seems wrong. Well, this is a common mistake where the gene ID types do not match between DE genes and the gene sets. Thankfully, the message clearly explains the reason. The ID type for gene sets is Entrez ID and it cannot match any DE gene.
There are two ways to solve this problem. 1. Convert gene IDs in
timeDEgenes to Entrez IDs in advance; or 2. Simply specify
the ID type of DE genes and let enrichGO() do the
conversion job (recall various gene ID types are also stored in the
OrgDb object). Let’s choose the second way.
In the next code, we additionally specify
keyType = "SYMBOL" to explicitly tell the function that DE
genes are in gene symbols. Recall that all valid values for
keyType are in keytypes(org.Mm.eg.db).
R
resTimeGO = enrichGO(gene = timeDEgenes,
keyType = "SYMBOL",
ont = "BP",
OrgDb = org.Mm.eg.db)
OUTPUT
'select()' returned 1:1 mapping between keys and columnsWARNING
Warning in bitr(gene, fromType = fromType, toType = "ENTREZID", OrgDb = OrgDb):
10.93% of input gene IDs are fail to map...R
resTimeGOTable = as.data.frame(resTimeGO)
head(resTimeGOTable)
OUTPUT
ID Description GeneRatio BgRatio RichFactor
GO:0050900 GO:0050900 leukocyte migration 54/946 412/25615 0.1310680
GO:0006935 GO:0006935 chemotaxis 56/946 476/25615 0.1176471
GO:0042330 GO:0042330 taxis 56/946 478/25615 0.1171548
GO:0030595 GO:0030595 leukocyte chemotaxis 37/946 233/25615 0.1587983
GO:0060326 GO:0060326 cell chemotaxis 43/946 330/25615 0.1303030
GO:0071674 GO:0071674 mononuclear cell migration 34/946 229/25615 0.1484716
FoldEnrichment zScore pvalue p.adjust qvalue
GO:0050900 3.548949 10.213913 6.488865e-16 3.281419e-12 9.099632e-13
GO:0006935 3.185549 9.425373 2.121016e-14 4.276849e-11 1.186004e-11
GO:0042330 3.172220 9.387925 2.537186e-14 4.276849e-11 1.186004e-11
GO:0030595 4.299808 9.908597 6.859406e-14 8.672004e-11 2.404815e-11
GO:0060326 3.528237 9.052150 7.528704e-13 7.614531e-10 2.111569e-10
GO:0071674 4.020191 8.990078 4.993702e-12 3.786134e-09 1.049925e-09
geneID
GO:0050900 Ccr7/Ccl2/Ptn/Prex1/Edn3/Itga4/Padi2/Emp2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Cd209a/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Il33/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Aire/Alox5/Fut7/Ada/Aoc3/Calr/Pf4/Slamf9/Plg/Adam8/Bst1/Il12a/P2ry12/Grem1/Ascl2/AI182371/Cxcl5/Ch25h/Apod/Gdf15/Ager/Enpp1/Axdnd1
GO:0006935 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0042330 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0030595 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Calr/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h
GO:0060326 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Ccl6/Lpar1/Calr/Nox1/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h/Ccl17
GO:0071674 Ccr7/Ccl2/Itga4/Padi2/Fpr2/Ccl5/Cd209a/Mdk/Hsd3b7/Ptk2b/Lgals3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Ccl7/Aire/Alox5/Fut7/Calr/Slamf9/Plg/Adam8/Il12a/P2ry12/Grem1/Ascl2/AI182371/Ch25h/Apod/Ager/Enpp1
Count
GO:0050900 54
GO:0006935 56
GO:0042330 56
GO:0030595 37
GO:0060326 43
GO:0071674 34Now enrichGO() went through! The returned object
resTimeGO is in a special format which looks like a table
but actually is not! To get rid of the confusion, in the code it is
converted to a real data frame resTimeGOTable.
In the output data frame, there are the following columns:
-
ID: ID of the gene set. In this example analysis, it is the GO ID. -
Description: Readable description. Here it is the name of the GO term. -
GeneRatio: Number of DE genes in the gene set / total number of DE genes. -
BgRatio: Size of the gene set / total number of genes. -
pvalue: p-value calculated from the hypergeometric distribution. -
p.adjust: Adjusted p-value by the BH method. -
qvalue: q-value which is another way for controlling false positives in multiple testings. -
geneID: A list of DE genes in the gene set. -
Count: Number of DE genes in the gene set.
You may have found the total number of DE genes changes. There are
1134 in timeDEgenes, but only 983 DE genes are included in
the enrichment result table (in the GeneRatio column). The
main reason is by default DE genes not annotated to any GO gene set are
filtered out. This relates to the “universe” of all genes in ORA, which
we will touch in the end of this section.
There are several additional arguments in
enrichGO():
-
universe: the universe set of genes, i.e. total genes to use. By default it uses the union of the genes in all gene sets. If it is set, DE genes and all gene sets will take intersections with it. We will discuss it in the end of this section. -
minGSSize: Minimal size of gene sets. Normally gene sets with very small size have very specific biological meanings which are not helpful too much for the interpretation. Gene sets with size smaller than it will be removed from the analysis. By default it is 10. -
maxGSSize: Maximal size of gene sets. Normally gene sets with huge size provide too general biological meanings and are not helpful either. By default is 500. -
pvalueCutoff: Cutoff for both p-values and adjusted p-values. By default is 0.05. -
qvalueCutoff: Cutoff for q-values. by default is 0.2.
Note, enrichGO() only returns significant gene sets that
pass the cutoffs4. This function design might not be proper
because a function should return all the results no matter they are
significant or not. Later users may need to use the complete enrichment
table for downstream anlaysis. Second, the meaning of
pvalueCutoff is not precise and there is redundancy between
pvalueCutoff and qvalueCutoff (adjusted
p-values and q-values are always non-smaller than raw
p-values). Thus it is suggested to set both
pvalueCutoff and qvalueCutoff to 1 in
enrichGO().
R
resTimeGO = enrichGO(gene = timeDEgenes,
keyType = "SYMBOL",
ont = "BP",
OrgDb = org.Mm.eg.db,
pvalueCutoff = 1,
qvalueCutoff = 1)
OUTPUT
'select()' returned 1:1 mapping between keys and columnsWARNING
Warning in bitr(gene, fromType = fromType, toType = "ENTREZID", OrgDb = OrgDb):
10.93% of input gene IDs are fail to map...R
resTimeGOTable = as.data.frame(resTimeGO)
head(resTimeGOTable)
OUTPUT
ID Description GeneRatio BgRatio RichFactor
GO:0050900 GO:0050900 leukocyte migration 54/946 412/25615 0.1310680
GO:0006935 GO:0006935 chemotaxis 56/946 476/25615 0.1176471
GO:0042330 GO:0042330 taxis 56/946 478/25615 0.1171548
GO:0030595 GO:0030595 leukocyte chemotaxis 37/946 233/25615 0.1587983
GO:0060326 GO:0060326 cell chemotaxis 43/946 330/25615 0.1303030
GO:0071674 GO:0071674 mononuclear cell migration 34/946 229/25615 0.1484716
FoldEnrichment zScore pvalue p.adjust qvalue
GO:0050900 3.548949 10.213913 6.488865e-16 3.281419e-12 9.099632e-13
GO:0006935 3.185549 9.425373 2.121016e-14 4.276849e-11 1.186004e-11
GO:0042330 3.172220 9.387925 2.537186e-14 4.276849e-11 1.186004e-11
GO:0030595 4.299808 9.908597 6.859406e-14 8.672004e-11 2.404815e-11
GO:0060326 3.528237 9.052150 7.528704e-13 7.614531e-10 2.111569e-10
GO:0071674 4.020191 8.990078 4.993702e-12 3.786134e-09 1.049925e-09
geneID
GO:0050900 Ccr7/Ccl2/Ptn/Prex1/Edn3/Itga4/Padi2/Emp2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Cd209a/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Il33/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Aire/Alox5/Fut7/Ada/Aoc3/Calr/Pf4/Slamf9/Plg/Adam8/Bst1/Il12a/P2ry12/Grem1/Ascl2/AI182371/Cxcl5/Ch25h/Apod/Gdf15/Ager/Enpp1/Axdnd1
GO:0006935 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0042330 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0030595 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Calr/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h
GO:0060326 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Ccl6/Lpar1/Calr/Nox1/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h/Ccl17
GO:0071674 Ccr7/Ccl2/Itga4/Padi2/Fpr2/Ccl5/Cd209a/Mdk/Hsd3b7/Ptk2b/Lgals3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Ccl7/Aire/Alox5/Fut7/Calr/Slamf9/Plg/Adam8/Il12a/P2ry12/Grem1/Ascl2/AI182371/Ch25h/Apod/Ager/Enpp1
Count
GO:0050900 54
GO:0006935 56
GO:0042330 56
GO:0030595 37
GO:0060326 43
GO:0071674 34Perform GO enrichment on other organisms
Gene sets are provided as an OrgDb object in
enrichGO(), thus you can perform ORA analysis on any
organism as long as there is a corresponding OrgDb
object.
- For model organisms, the
OrgDbobject can be obtained from the corresponding org.*.db package. - For other organisms, the
OrgDbobject can be found with the AnnotationHub package.
KEGG pathway enrichment
To perform KEGG pathway enrichment analysis, there is also a function
enrichKEGG() for that. Unfortunately, it cannot perform
gene ID conversion automatically. Thus, if the ID type is not Entrez ID,
we have to convert it by hand.
Note if you have also set universe, it should be
converted to Entrez IDs as well.
We use the mapIds() function to convert genes from
symbols to Entrez IDs. Since the ID mapping is not always one-to-one. We
only take the first one if there are multiple hits by setting
multiVals = "first"(but of course you can choose other
options for multiVals, check the documentation). We also
remove genes with no mapping available (with NA after the
mapping)5.
R
EntrezIDs = mapIds(org.Mm.eg.db, keys = timeDEgenes,
keytype = "SYMBOL", column = "ENTREZID", multiVals = "first")
OUTPUT
'select()' returned 1:1 mapping between keys and columnsR
EntrezIDs = EntrezIDs[!is.na(EntrezIDs)]
head(EntrezIDs)
OUTPUT
Sgk3 Kcnb2 Sbspon Gsta3 Lman2l Ankrd39
"170755" "98741" "226866" "14859" "214895" "109346" We have to set the KEGG organism code if it is not human. Similarly
it is suggested to set pvalueCutoff and
qvalueCutoff both to 1 and convert the result to a data
frame.
R
resTimeKEGG = enrichKEGG(gene = EntrezIDs,
organism = "mmu",
pvalueCutoff = 1,
qvalueCutoff = 1)
resTimeKEGGTable = as.data.frame(resTimeKEGG)
head(resTimeKEGGTable)
OUTPUT
category
mmu00590 Metabolism
mmu00591 Metabolism
mmu00565 Metabolism
mmu00592 Metabolism
mmu04913 Organismal Systems
mmu04061 Environmental Information Processing
subcategory ID
mmu00590 Lipid metabolism mmu00590
mmu00591 Lipid metabolism mmu00591
mmu00565 Lipid metabolism mmu00565
mmu00592 Lipid metabolism mmu00592
mmu04913 Endocrine system mmu04913
mmu04061 Signaling molecules and interaction mmu04061
Description
mmu00590 Arachidonic acid metabolism
mmu00591 Linoleic acid metabolism
mmu00565 Ether lipid metabolism
mmu00592 alpha-Linolenic acid metabolism
mmu04913 Ovarian steroidogenesis
mmu04061 Viral protein interaction with cytokine and cytokine receptor
GeneRatio BgRatio RichFactor FoldEnrichment zScore pvalue
mmu00590 16/463 89/11188 0.1797753 4.344116 6.580867 6.207040e-07
mmu00591 12/463 55/11188 0.2181818 5.272177 6.598925 1.896062e-06
mmu00565 11/463 49/11188 0.2244898 5.424604 6.449084 3.790563e-06
mmu00592 8/463 25/11188 0.3200000 7.732527 7.001745 4.701377e-06
mmu04913 12/463 64/11188 0.1875000 4.530778 5.885434 1.011509e-05
mmu04061 14/463 95/11188 0.1473684 3.561032 5.208360 3.349647e-05
p.adjust qvalue
mmu00590 0.0001980046 0.0001537159
mmu00591 0.0003024219 0.0002347777
mmu00565 0.0003749348 0.0002910713
mmu00592 0.0003749348 0.0002910713
mmu04913 0.0006453426 0.0005009956
mmu04061 0.0017808954 0.0013825537
geneID
mmu00590 18781/18784/15446/242546/11687/232889/237625/11689/18783/78390/67103/19223/211429/13118/329502/19215
mmu00591 18781/18784/13113/242546/11687/232889/237625/18783/78390/211429/622127/329502
mmu00565 53897/18781/18784/22239/320981/232889/237625/18783/78390/211429/329502
mmu00592 18781/18784/232889/237625/18783/78390/211429/329502
mmu04913 16867/242546/15485/232889/13076/11689/18783/13070/78390/211429/329502/13078
mmu04061 12775/20296/16186/20304/14825/56838/16185/57349/20306/20305/56744/20311/20295/16174
Count
mmu00590 16
mmu00591 12
mmu00565 11
mmu00592 8
mmu04913 12
mmu04061 14Perform KEGG pathway enrichment on other organisms
Extending ORA to other organisms is rather simple.
- Make sure the DE genes are Entrez IDs.
- Choose the corresponding KEGG organism code.
MSigDB enrichment
For MSigDB gene sets, there is no pre-defined enrichment function. We
need to directly use the low-level enrichment function
enricher() which accepts self-defined gene sets. The gene
sets should be in a format of a two-column data frame of genes and gene
sets (or a class that can be converted to a data frame). Let’s use the
hallmark collection (hm) that we generated above.
R
gene_sets <- stack(geneIds(hm)) |>
as.data.frame() |>
dplyr::select(ind, values) |>
dplyr::rename(gs_name = ind, gene_symbol = values)
head(gene_sets)
OUTPUT
gs_name gene_symbol
1 HALLMARK_ADIPOGENESIS Abca1
2 HALLMARK_ADIPOGENESIS Abca4
3 HALLMARK_ADIPOGENESIS Abca7
4 HALLMARK_ADIPOGENESIS Abca13
5 HALLMARK_ADIPOGENESIS Abca12
6 HALLMARK_ADIPOGENESIS Abca17As mentioned before, it is important the gene ID type in the gene
sets should be the same as in the DE genes, so here we choose the
"gene_symbol" column.
R
resTimeHallmark = enricher(gene = timeDEgenes,
TERM2GENE = gene_sets,
pvalueCutoff = 1,
qvalueCutoff = 1)
resTimeHallmarkTable = as.data.frame(resTimeHallmark)
head(resTimeHallmarkTable)
OUTPUT
ID
HALLMARK_MYOGENESIS HALLMARK_MYOGENESIS
HALLMARK_INTERFERON_GAMMA_RESPONSE HALLMARK_INTERFERON_GAMMA_RESPONSE
HALLMARK_COAGULATION HALLMARK_COAGULATION
HALLMARK_ALLOGRAFT_REJECTION HALLMARK_ALLOGRAFT_REJECTION
HALLMARK_INTERFERON_ALPHA_RESPONSE HALLMARK_INTERFERON_ALPHA_RESPONSE
HALLMARK_IL2_STAT5_SIGNALING HALLMARK_IL2_STAT5_SIGNALING
Description GeneRatio
HALLMARK_MYOGENESIS HALLMARK_MYOGENESIS 39/333
HALLMARK_INTERFERON_GAMMA_RESPONSE HALLMARK_INTERFERON_GAMMA_RESPONSE 35/333
HALLMARK_COAGULATION HALLMARK_COAGULATION 27/333
HALLMARK_ALLOGRAFT_REJECTION HALLMARK_ALLOGRAFT_REJECTION 33/333
HALLMARK_INTERFERON_ALPHA_RESPONSE HALLMARK_INTERFERON_ALPHA_RESPONSE 21/333
HALLMARK_IL2_STAT5_SIGNALING HALLMARK_IL2_STAT5_SIGNALING 30/333
BgRatio RichFactor FoldEnrichment zScore
HALLMARK_MYOGENESIS 307/5435 0.1270358 2.073393 4.946130
HALLMARK_INTERFERON_GAMMA_RESPONSE 298/5435 0.1174497 1.916934 4.159135
HALLMARK_COAGULATION 211/5435 0.1279621 2.088510 4.119874
HALLMARK_ALLOGRAFT_REJECTION 285/5435 0.1157895 1.889837 3.942222
HALLMARK_INTERFERON_ALPHA_RESPONSE 171/5435 0.1228070 2.004373 3.409155
HALLMARK_IL2_STAT5_SIGNALING 280/5435 0.1071429 1.748713 3.286183
pvalue p.adjust qvalue
HALLMARK_MYOGENESIS 7.558671e-06 0.0003779335 0.0003779335
HALLMARK_INTERFERON_GAMMA_RESPONSE 1.194293e-04 0.0029857318 0.0029857318
HALLMARK_COAGULATION 1.819948e-04 0.0030332474 0.0030332474
HALLMARK_ALLOGRAFT_REJECTION 2.467925e-04 0.0030849069 0.0030849069
HALLMARK_INTERFERON_ALPHA_RESPONSE 1.614367e-03 0.0141933353 0.0141933353
HALLMARK_IL2_STAT5_SIGNALING 1.703200e-03 0.0141933353 0.0141933353
geneID
HALLMARK_MYOGENESIS Itgb4/Cacng1/Col1a1/Itgb3/Slc6a12/Col15a1/Nos2/Ptgis/Smtnl2/Myl1/Cryab/Myh3/Vil1/Avil/Hspb2/Spdef/Erbb3/Myo1a/Actn3/Ryr1/Bdkrb2/Tnnt1/Aplnr/Casq1/Myh13/Gja5/Plxnb3/Tnnc2/Myh1/Mapk13/Cdkn1a/Tnni2/Myh15/Bche/Mybpc2/Myo1d/Lsp1/Fabp7/Mapk12
HALLMARK_INTERFERON_GAMMA_RESPONSE H2-Q6/Fpr2/Ifi27l2a/Tap1/H2-Q2/Zbp1/Itgb3/Ccl7/Irf7/H2-T23/Bst2/Bst1/Pla2g4a/Cd274/Apol6/Ccl5/Csf2rb/H2-K1/Psmb9/Lgals3bp/Mettl7a3/Psmb8/Gbp6/Gbp4/Mthfd2/Cdkn1a/Ccl2/Gbp5/Oas2/Il2rb/Ifitm7/H2-Q1/Gbp9/Ifit1/Ifitm6
HALLMARK_COAGULATION Hmgcs1/Tmprss6/Serpinb2/Apoc1/Sh2b2/Vwf/C4b/Itgb3/Tll2/Plg/Gnb4/C3/Crip3/Pcsk4/Fbn2/Vil1/Mmp8/Avil/Ctse/Ctsk/Mmp15/Klkb1/Dct/Pf4/Masp2/Maff/C8g
HALLMARK_ALLOGRAFT_REJECTION H2-Q6/Cd247/Tap1/H2-Q2/Itgb3/Il12rb1/Gm21104/Ccl7/Cfp/Irf7/Nos2/H2-T23/Il2rg/Ccl5/Capg/Icosl/Erbb3/H2-K1/Ctsk/Gpr65/Ccnd2/Il18rap/Gzmb/Pf4/Gbp6/Tap2/Gbp4/Ccl2/Gbp5/Il2rb/Bche/H2-Q1/Gbp9
HALLMARK_INTERFERON_ALPHA_RESPONSE H2-Q6/Ifi27l2a/Tap1/H2-Q2/Irf7/H2-T23/Bst2/Oas1c/H2-K1/Psmb9/Lgals3bp/Psmb8/Gbp6/Gbp4/Gbp5/Ifitm7/Sell/H2-Q1/Gbp9/Trim5/Ifitm6
HALLMARK_IL2_STAT5_SIGNALING Enpp3/Phlda1/Xbp1/Pcsk4/Ttc39a/Capg/Il1r2/Myo1a/Gpr65/Ccnd2/Gsto2/Traf1/Scn11a/Maff/Gbp6/Gbp4/Enpp1/Etv4/Hkdc1/Hopx/P4ha1/Scn7a/Gbp5/Il2rb/Myo1d/Ifitm7/Sell/Gbp9/Ager/Ifitm6
Count
HALLMARK_MYOGENESIS 39
HALLMARK_INTERFERON_GAMMA_RESPONSE 35
HALLMARK_COAGULATION 27
HALLMARK_ALLOGRAFT_REJECTION 33
HALLMARK_INTERFERON_ALPHA_RESPONSE 21
HALLMARK_IL2_STAT5_SIGNALING 30Further reading
Implementing ORA is rather simple. The following function
ora() performs ORA on a list of gene sets. Try to read and
understand the code.
R
ora = function(genes, gene_sets, universe = NULL) {
if(is.null(universe)) {
universe = unique(unlist(gene_sets))
} else {
universe = unique(universe)
}
# make sure genes are unique
genes = intersect(genes, universe)
gene_sets = lapply(gene_sets, intersect, universe)
# calculate different numbers
n_11 = sapply(gene_sets, function(x) length(intersect(genes, x)))
n_10 = length(genes)
n_01 = sapply(gene_sets, length)
n = length(universe)
# calculate p-values
p = 1 - phyper(n_11 - 1, n_10, n - n_10, n_01)
df = data.frame(
gene_set = names(gene_sets),
hits = n_11,
n_genes = n_10,
gene_set_size = n_01,
n_total = n,
p_value = p,
p_adjust = p.adjust(p, "BH")
)
}
Test on the MSigDB hallmark gene sets:
R
HallmarkGeneSets = split(gene_sets$gene_symbol, gene_sets$gs_name)
df = ora(timeDEgenes, HallmarkGeneSets, rownames(se))
head(df)
OUTPUT
gene_set hits n_genes
HALLMARK_ADIPOGENESIS HALLMARK_ADIPOGENESIS 13 1134
HALLMARK_ALLOGRAFT_REJECTION HALLMARK_ALLOGRAFT_REJECTION 33 1134
HALLMARK_ANDROGEN_RESPONSE HALLMARK_ANDROGEN_RESPONSE 7 1134
HALLMARK_ANGIOGENESIS HALLMARK_ANGIOGENESIS 6 1134
HALLMARK_APICAL_JUNCTION HALLMARK_APICAL_JUNCTION 28 1134
HALLMARK_APICAL_SURFACE HALLMARK_APICAL_SURFACE 4 1134
gene_set_size n_total p_value p_adjust
HALLMARK_ADIPOGENESIS 247 21198 5.645290e-01 8.301897e-01
HALLMARK_ALLOGRAFT_REJECTION 264 21198 5.248132e-06 8.746887e-05
HALLMARK_ANDROGEN_RESPONSE 155 21198 7.290317e-01 9.424457e-01
HALLMARK_ANGIOGENESIS 51 21198 5.368200e-02 1.118375e-01
HALLMARK_APICAL_JUNCTION 304 21198 3.728233e-03 1.331512e-02
HALLMARK_APICAL_SURFACE 84 21198 6.640741e-01 8.973974e-01Choose a proper universe
Finally, it is time to talk about the “universe” of ORA analysis which is normally ignored in many analyses. In current tools, there are mainly following different universe settings:
- Using all genes in the genome, this also includes non-protein coding genes. For human, the size of universe is 60k ~ 70k.
- Using all protein-coding genes. For human, the size of universe is ~ 20k.
- In the era of microarray, total genes that are measured on the chip is taken as the universe. For RNASeq, since reads are aligned to all genes, we can set a cutoff and only use those “expressed” genes as the universe.
- Using all genes in a gene sets collection. Then the size of the universe depends on the size of the gene sets collection. For example GO gene sets collection is much larger than the KEGG pathway gene sets collection.
If the universe is set, DE genes as well as genes in the gene sets are first intersected to the universe. However, in general the universe affects three values of \(n_{22}\), \(n_{02}\) and \(n_{20}\) more, which correspond to the non-DE genes or non-gene-set genes.
| In the gene set | Not in the gene set | Total | |
|---|---|---|---|
| DE | \(n_{11}\) | \(n_{12}\) | \(n_{1+}\) |
| Not DE | \(n_{21}\) | \(\color{red}{n_{22}}\) | \(\color{red}{n_{2+}}\) |
| Total | \(n_{+1}\) | \(\color{red}{n_{+2}}\) | \(\color{red}{n}\) |
In the contingency table, we are testing the dependency of whether genes being DE and whether genes being in the gene set. In the model, each gene has a definite attribute of being either DE or non-DE and each gene has a second definite attribute of either belonging to the gene set or not. If a larger universe is used, such as total genes where there are genes not measured nor will never annotated to gene sets (let’s call them non-informative genes, e.g. non-protein coding genes or not-expressed genes), all the non-informative genes are implicitly assigned with an attribute of being non-DE or not in the gene set. This implicit assignment is not proper because these genes provide no information and they should not be included in the analysis. Adding them to the analysis increases \(n_{22}\), \(n_{02}\) or \(n_{20}\), makes the observation \(n_{11}\) getting further away from the null distribution, eventually generates a smaller p-value. For the similar reason, small universes tend to generate large p-values.
In
enrichGO()/enrichKEGG()/enricher(),
universe genes can be set via the universe argument. By
default the universe is the total genes in the gene sets collection.
When a self-defined universe is provided, this might be different from
what you may think, the universe is the
intersection of user-provided universe and total genes in the gene set
collection. Thus the universe setting in
clusterProfiler is very conservative.
Check the more discusstions at https://twitter.com/mdziemann/status/1626407797939384320.
We can do a simple experiment on the small MSigDB hallmark gene sets.
We use the ora() function which we have implemented in
previous “Further reading” section and we compare three different
universe settings.
R
# all genes in the gene sets collection ~ 4k genes
df1 = ora(timeDEgenes, HallmarkGeneSets)
# all protein-coding genes, ~ 20k genes
df2 = ora(timeDEgenes, HallmarkGeneSets, rownames(se))
# all genes in org.Mm.eg.db ~ 70k genes
df3 = ora(timeDEgenes, HallmarkGeneSets,
keys(org.Mm.eg.db, keytype = "SYMBOL"))
# df1, df2, and df3 are in the same row order,
# so we can directly compare them
plot(df1$p_value, df2$p_value, col = 2, pch = 16,
xlim = c(0, 1), ylim = c(0, 1),
xlab = "all hallmark genes as universe (p-values)", ylab = "p-values",
main = "compare universes")
points(df1$p_value, df3$p_value, col = 4, pch = 16)
abline(a = 0, b = 1, lty = 2)
legend("topleft", legend = c("all protein-coding genes as universe", "all genes as universe"),
pch = 16, col = c(2, 4))
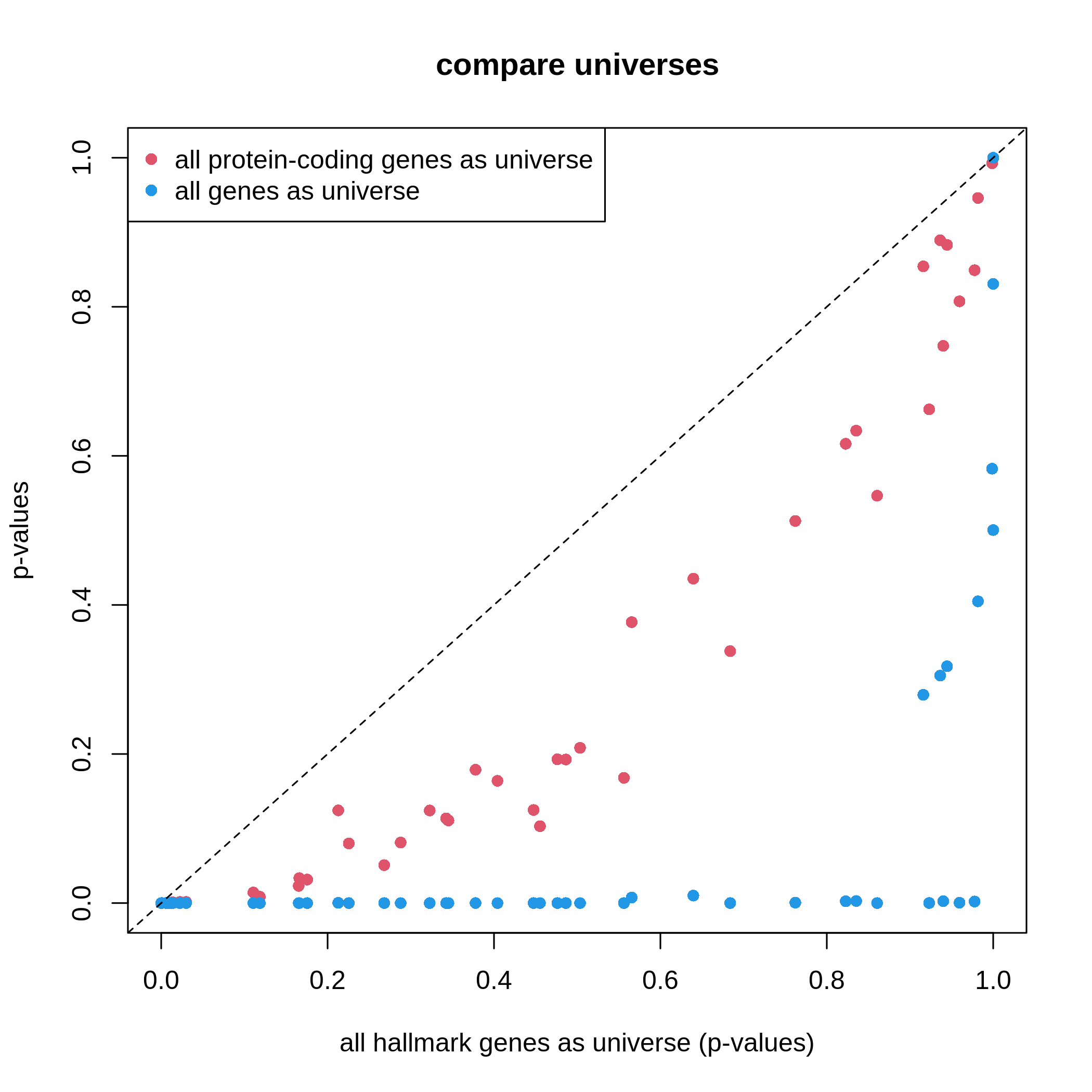
It is very straightforward to see, with a larger universe, there are more significant gene sets, which may produce potentially more false positives. This is definitely worse when using all genes in the genome as universe.
Based on the discussion in this section, the recommendation of using universe is:
- using protein-coding genes,
- using measured genes,
- or using a conservative way with clusterProfiler.
Visualization
clusterProfiler provides a rich set of visualization methods on the GSEA results, from simple visualization to complex ones. Complex visualizations are normally visually fancy but do not transfer too much useful information, and they should only be applied in very specific scenarios under very specific settings; while simple graphs normally do better jobs. Recently the visualization code in clusterProfiler has been moved to a new package enrichplot. Let’s first load the enrichplot package. The full sets of visualizations that enrichplot supports can be found from https://yulab-smu.top/biomedical-knowledge-mining-book/enrichplot.html.
We first re-generate the enrichment table.
R
library(enrichplot)
resTimeGO = enrichGO(gene = timeDEgenes,
keyType = "SYMBOL",
ont = "BP",
OrgDb = org.Mm.eg.db,
pvalueCutoff = 1,
qvalueCutoff = 1)
resTimeGOTable = as.data.frame(resTimeGO)
head(resTimeGOTable)
OUTPUT
ID Description GeneRatio BgRatio RichFactor
GO:0050900 GO:0050900 leukocyte migration 54/946 412/25615 0.1310680
GO:0006935 GO:0006935 chemotaxis 56/946 476/25615 0.1176471
GO:0042330 GO:0042330 taxis 56/946 478/25615 0.1171548
GO:0030595 GO:0030595 leukocyte chemotaxis 37/946 233/25615 0.1587983
GO:0060326 GO:0060326 cell chemotaxis 43/946 330/25615 0.1303030
GO:0071674 GO:0071674 mononuclear cell migration 34/946 229/25615 0.1484716
FoldEnrichment zScore pvalue p.adjust qvalue
GO:0050900 3.548949 10.213913 6.488865e-16 3.281419e-12 9.099632e-13
GO:0006935 3.185549 9.425373 2.121016e-14 4.276849e-11 1.186004e-11
GO:0042330 3.172220 9.387925 2.537186e-14 4.276849e-11 1.186004e-11
GO:0030595 4.299808 9.908597 6.859406e-14 8.672004e-11 2.404815e-11
GO:0060326 3.528237 9.052150 7.528704e-13 7.614531e-10 2.111569e-10
GO:0071674 4.020191 8.990078 4.993702e-12 3.786134e-09 1.049925e-09
geneID
GO:0050900 Ccr7/Ccl2/Ptn/Prex1/Edn3/Itga4/Padi2/Emp2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Cd209a/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Il33/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Aire/Alox5/Fut7/Ada/Aoc3/Calr/Pf4/Slamf9/Plg/Adam8/Bst1/Il12a/P2ry12/Grem1/Ascl2/AI182371/Cxcl5/Ch25h/Apod/Gdf15/Ager/Enpp1/Axdnd1
GO:0006935 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0042330 Ccr7/Ccl2/Ptn/S100a7a/Prex1/Edn3/Padi2/Lsp1/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Cmtm5/Ccl28/Hsd3b7/Ptk2b/S100a9/Cmtm7/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/Casr/Tubb2b/C3/Robo3/Alox5/Stx3/Ccl6/Lpar1/Calr/Nox1/Ptgr1/Pf4/Slamf9/Ntf3/Adam8/Bst1/Il12a/P2ry12/Grem1/AI182371/Cxcl5/Ch25h/Ccl17/Ager
GO:0030595 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Calr/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h
GO:0060326 Ccr7/Ccl2/Ptn/Prex1/Edn3/Padi2/Nr4a1/Fpr2/Ccl5/S100a8/Sell/Cxcl1/Mdk/Ccl28/Hsd3b7/Ptk2b/S100a9/Lgals3/Plxnb3/Tnfsf18/Dusp1/Nbl1/Trpm4/Retnlg/Itgam/Ppbp/Ccl7/C3/Alox5/Ccl6/Lpar1/Calr/Nox1/Pf4/Slamf9/Adam8/Bst1/Il12a/Grem1/AI182371/Cxcl5/Ch25h/Ccl17
GO:0071674 Ccr7/Ccl2/Itga4/Padi2/Fpr2/Ccl5/Cd209a/Mdk/Hsd3b7/Ptk2b/Lgals3/Tnfsf18/Dusp1/Nbl1/Itgb3/Trpm4/Retnlg/Ccl7/Aire/Alox5/Fut7/Calr/Slamf9/Plg/Adam8/Il12a/P2ry12/Grem1/Ascl2/AI182371/Ch25h/Apod/Ager/Enpp1
Count
GO:0050900 54
GO:0006935 56
GO:0042330 56
GO:0030595 37
GO:0060326 43
GO:0071674 34barplot() and dotplot() generate plots for
a small number of significant gene sets. Note the two functions are
directly applied on resTimeGO returned by
enrichGO().
R
barplot(resTimeGO, showCategory = 20)
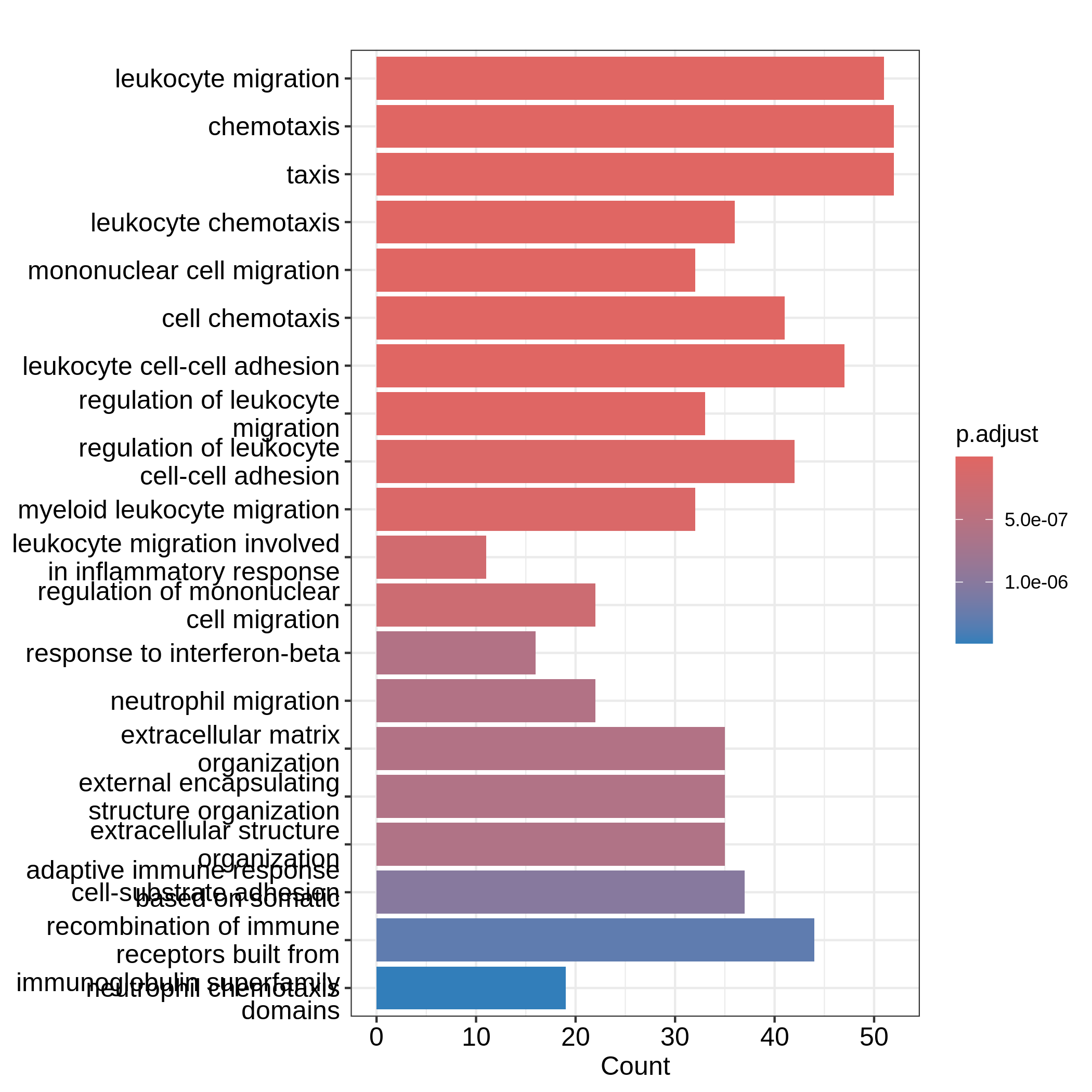
R
dotplot(resTimeGO, showCategory = 20)
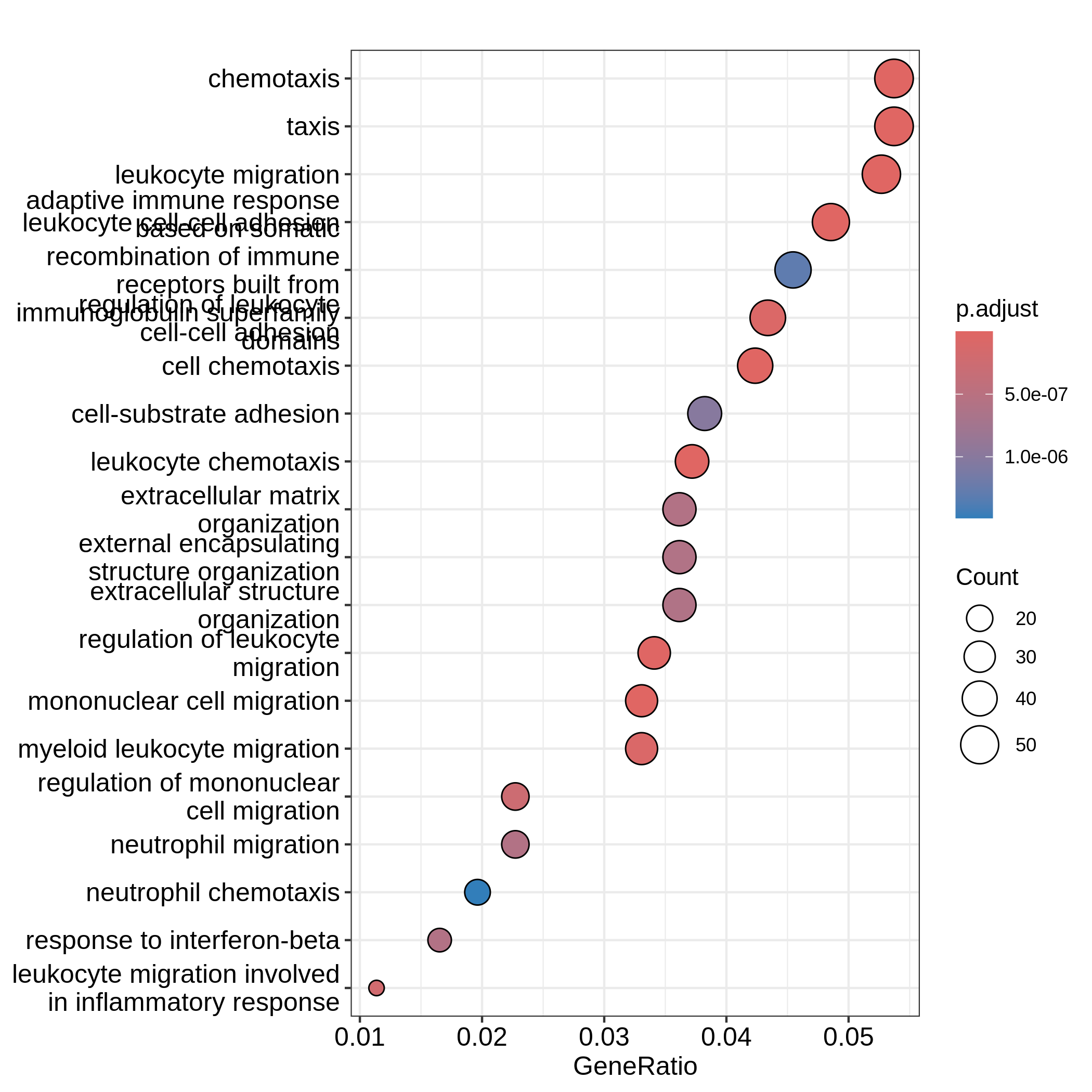
Barplots can map two variables to the plot, one to the height of bars
and the other to the colors of bars; while for dotplot, sizes of dots
can be mapped to a third variable. The variable names are in the colum
names of the result table. Both plots include the top 20 most
significant terms. On dotplot, terms are ordered by the values on x-axis
(the GeneRatio).
Now we need to talk about “what is a good visualization?”. The
essential two questions are “what is the key message a plot
transfers to readers?” and “what is the major graphical element
in the plot?”. In the barplot or dotplot, the major graphical
element which readers may notice the easiest is the height of bars or
the offset of dots to the origin. The most important message of the ORA
analysis is of course “the enrichment”. The two examples from
barplot() and dotplot() actually fail to
transfer such information to readers. In the first barplot where
"Count" is used as values on x-axis, the numer of DE genes
in gene sets is not a good measure of the enrichment because it has a
positive relation to the size of gene sets. A high value of
"Count" does not mean the gene set is more enriched.
It is the same reason for dotplot where "GeneRatio" is
used as values on x-axis. Gene ratio is calculated as the fraction of DE
genes from a certain gene set (GeneRatio = Count/Total_DE_Genes). The
dotplot puts multiple gene sets in the same plot and the aim is to
compare between gene sets, thus gene sets should be “scaled” to make
them comparable. "GeneRatio" is not scaled for different
gene sets and it still has a positive relation to the gene set size,
which can be observed in the dotplot where higher the gene ratio, larger
the dot size. Actually “GeneRatio” has the same effect as “Count”
(GeneRatio = Count/Total_DE_Genes), so as has been explained in the
previous paragraph, "GeneRatio" is not a good measure for
enrichment either.
Now let’s try to make a more reasonable barplot and dotplot to show the enrichment of ORA.
First, let’s define some metrics which measure the “enrichment” of DE genes on gene sets. Recall the denotations in the 2x2 contingency table (we are too far from that!). Let’s take these numbers from the enrichment table.
R
n_11 = resTimeGOTable$Count
n_10 = 983 # length(intersect(resTimeGO@gene, resTimeGO@universe))
n_01 = as.numeric(gsub("/.*$", "", resTimeGOTable$BgRatio))
n = 28943 # length(resTimeGO@universe)
Instead of using GeneRatio, we use the fraction of DE
genes in the gene sets which are kind of like a “scaled” value for all
gene sets. Let’s calculate it:
R
resTimeGOTable$DE_Ratio = n_11/n_01
resTimeGOTable$GS_size = n_01 # size of gene sets
Then intuitively, if a gene set has a higher DE_Ratio
value, we could say DE genes have a higher enrichment6 in it.
We can measure the enrichment in two other ways. First, the log2 fold enrichment, defined as:
\[ \log_2(\mathrm{Fold\_enrichment}) = \frac{n_{11}/n_{10}}{n_{01}/n} = \frac{n_{11}/n_{01}}{n_{10}/n} = \frac{n_{11}n}{n_{10}n_{01}} \]
which is the log2 of the ratio of DE% in the gene set and DE% in the universe or the log2 of the ratio of gene_set% in the DE genes and gene_set% in the universe. The two are identical.
R
resTimeGOTable$log2_Enrichment = log( (n_11/n_10)/(n_01/n) )
Second, it is also common to use z-score which is
\[ z = \frac{n_{11} - \mu}{\sigma} \]
where \(\mu\) and \(\sigma\) are the mean and standard deviation of the hypergeometric distribution. They can be calculated as:
R
hyper_mean = n_01*n_10/n
n_02 = n - n_01
n_20 = n - n_10
hyper_var = n_01*n_10/n * n_20*n_02/n/(n-1)
resTimeGOTable$zScore = (n_11 - hyper_mean)/sqrt(hyper_var)
We will use log2 fold change as the primary variable to map to bar
heights and DE_Ratio as the secondary variable to map to
colors. This can be done directly with the ggplot2
package. We also add the adjusted p-values as labels on the
bars.
In resTimeGOTable, gene sets are already ordered by the
significance, so we take the first 10 gene sets which are the 10 most
significant gene sets.
R
library(ggplot2)
ggplot(resTimeGOTable[1:10, ],
aes(x = log2_Enrichment, y = factor(Description, levels = rev(Description)),
fill = DE_Ratio)) +
geom_bar(stat = "identity") +
geom_text(aes(x = log2_Enrichment,
label = sprintf("%.2e", p.adjust)), hjust = 1, col = "white") +
ylab("")
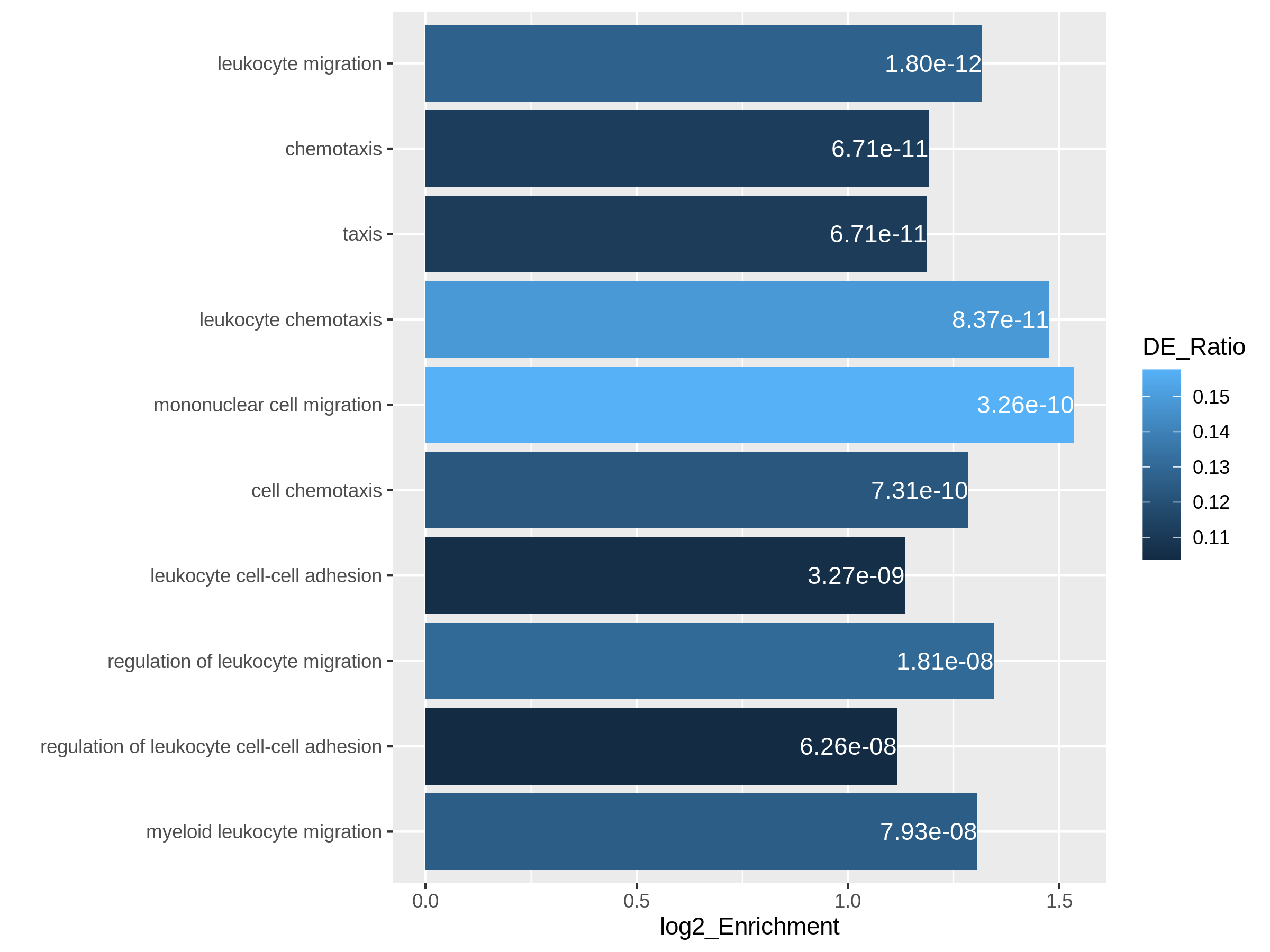
In the next example, we use z-score as the primary variable
to map to the offset to origin, DE_Ratio and
Count to map to dot colors and sizes.
R
ggplot(resTimeGOTable[1:10, ],
aes(x = zScore, y = factor(Description, levels = rev(Description)),
col = DE_Ratio, size = Count)) +
geom_point() +
ylab("")
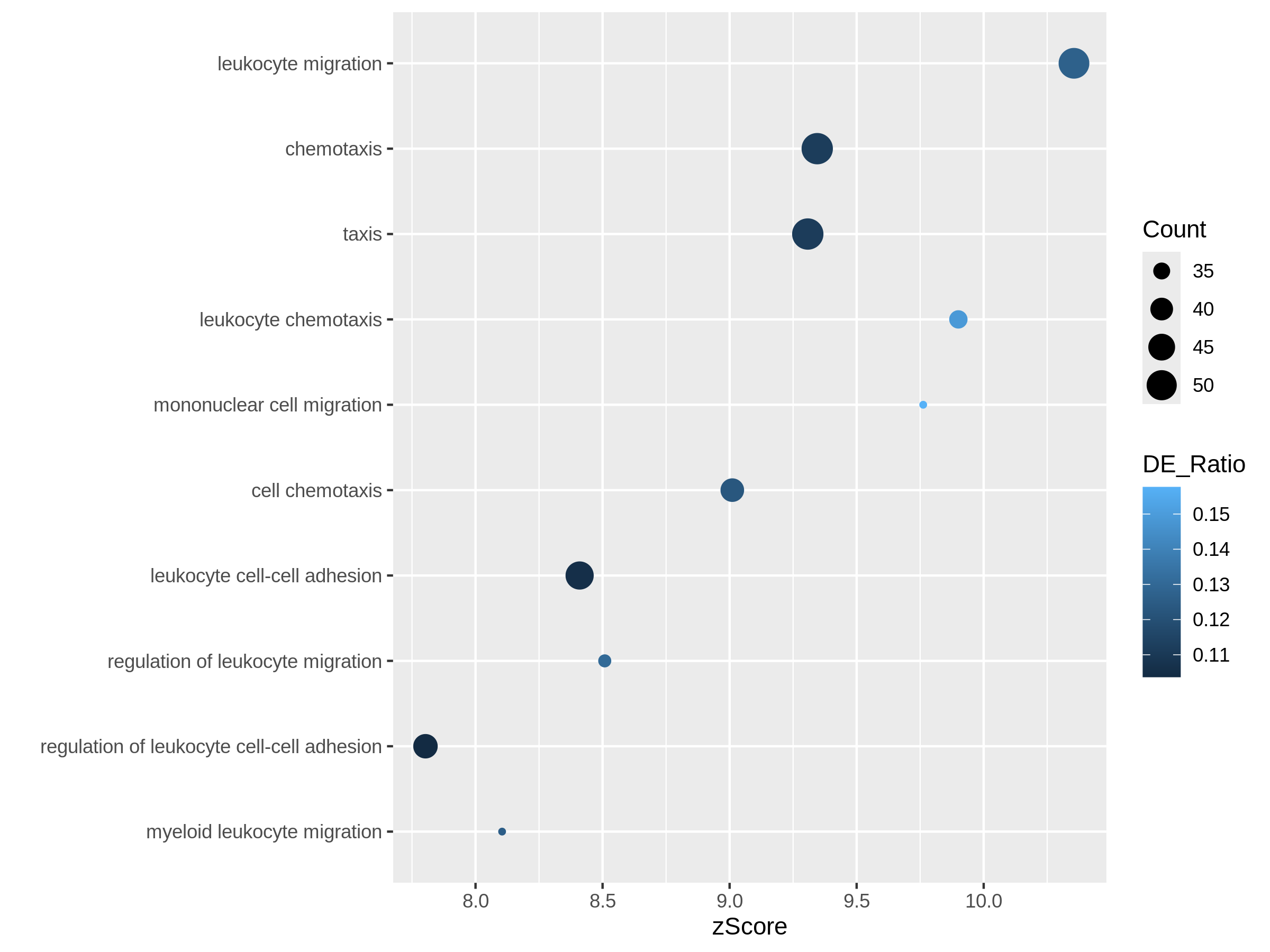
Both plots can highlight the gene set “leukocyte migration involved in inflammatory response” is relatively small but highly enriched.
Another useful visualization is the volcano plot. You may be aware of in differential expression analysis, in the volcano plot, x-axis corresponds to log2 fold changes of the differential expression, and y-axis corresponds to the adjusted p-values. It is actually similar here where we use log2 fold enrichment on x-axis.
Since we only look at the over-representation, the volcano plot is one-sided. We can set two cutoffs on the log2 fold enrichment and adjusted p-values, then the gene sets on the top right region can be thought as being both statistically significant and also biologically sensible.
R
ggplot(resTimeGOTable,
aes(x = log2_Enrichment, y = -log10(p.adjust),
color = DE_Ratio, size = GS_size)) +
geom_point() +
geom_hline(yintercept = -log10(0.01), lty = 2, col = "#444444") +
geom_vline(xintercept = 1.5, lty = 2, col = "#444444")
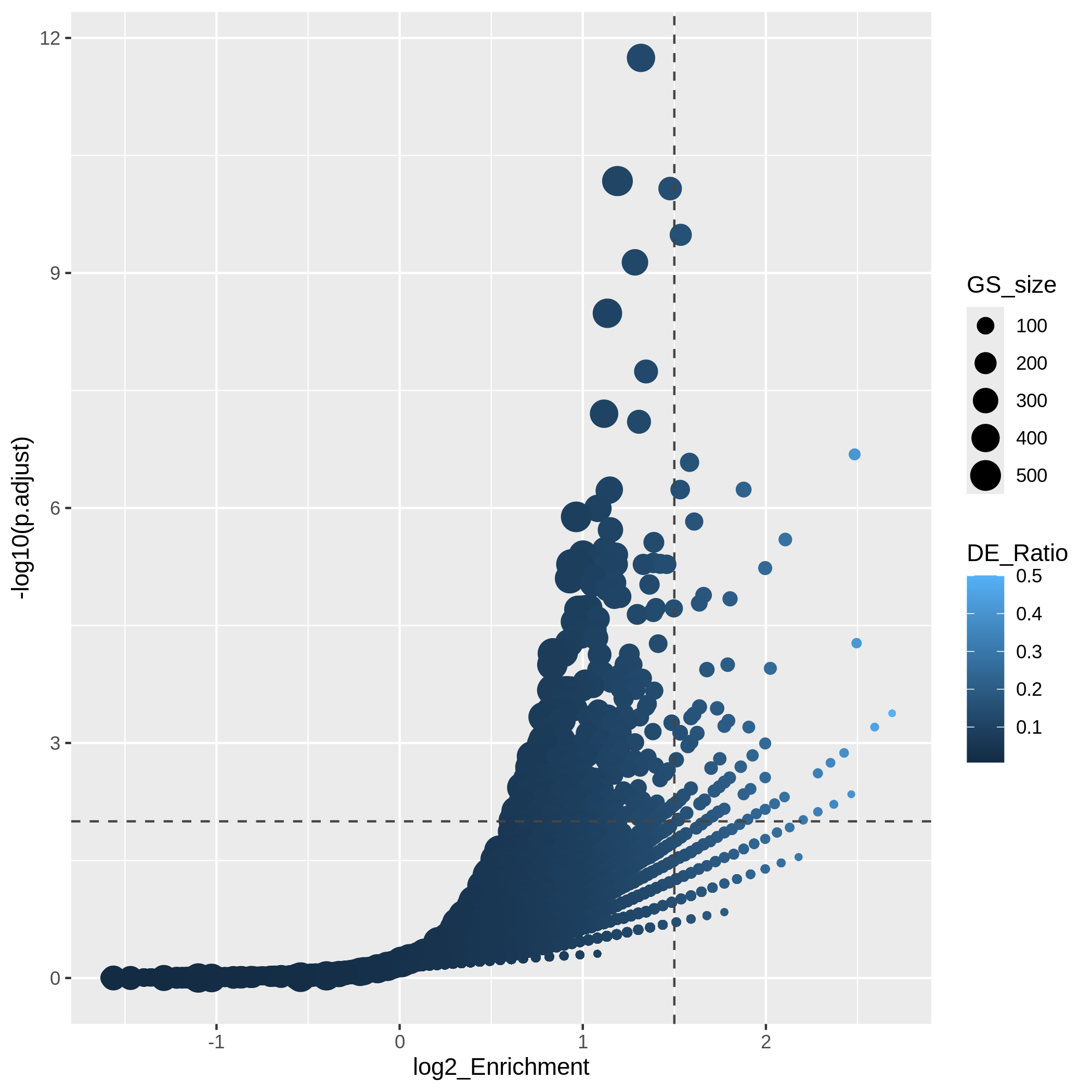
In the “volcano plot”, we can observe the plot is composed by a list
of curves. The trends are especially clear in the right bottom of the
plot. Actually each “curve” corresponds to a same "Count"
value (number of DE genes in a gene set). The volcano plot shows very
clearly that the enrichment has a positive relation to the gene set size
where a large gene set can easily reach a small p-value with a
small DE_ratio and a small log2 fold enrichment, while a small gene set
needs to have a large DE ratio to be significant.
It is also common that we perform ORA analysis on up-regulated genes and down-regulated separately. And we want to combine the significant gene sets from the two ORA analysis in one plot. In the following code, we first generate two enrichment tables for up-regulated genes and down-regulated separately.
R
# up-regulated genes
timeDEup <- as.data.frame(subset(resTime, padj < 0.05 & log2FoldChange > log2(1.5)))
timeDEupGenes <- rownames(timeDEup)
resTimeGOup = enrichGO(gene = timeDEupGenes,
keyType = "SYMBOL",
ont = "BP",
OrgDb = org.Mm.eg.db,
universe = rownames(se),
pvalueCutoff = 1,
qvalueCutoff = 1)
resTimeGOupTable = as.data.frame(resTimeGOup)
n_11 = resTimeGOupTable$Count
n_10 = length(intersect(resTimeGOup@gene, resTimeGOup@universe))
n_01 = as.numeric(gsub("/.*$", "", resTimeGOupTable$BgRatio))
n = length(resTimeGOup@universe)
resTimeGOupTable$log2_Enrichment = log( (n_11/n_10)/(n_01/n) )
# down-regulated genes
timeDEdown <- as.data.frame(subset(resTime, padj < 0.05 & log2FoldChange < -log2(1.5)))
timeDEdownGenes <- rownames(timeDEdown)
resTimeGOdown = enrichGO(gene = timeDEdownGenes,
keyType = "SYMBOL",
ont = "BP",
OrgDb = org.Mm.eg.db,
universe = rownames(se),
pvalueCutoff = 1,
qvalueCutoff = 1)
resTimeGOdownTable = as.data.frame(resTimeGOdown)
n_11 = resTimeGOdownTable$Count
n_10 = length(intersect(resTimeGOdown@gene, resTimeGOdown@universe))
n_01 = as.numeric(gsub("/.*$", "", resTimeGOdownTable$BgRatio))
n = length(resTimeGOdown@universe)
resTimeGOdownTable$log2_Enrichment = log( (n_11/n_10)/(n_01/n) )
As an example, let’s simply take the first 5 most significant terms for up-regulated genes and the first 5 most significant terms for down-regulated genes. The following ggplot2 code should be easy to read.
R
# The name of the 3rd term is too long, we wrap it into two lines.
resTimeGOupTable[3, "Description"] = paste(strwrap(resTimeGOupTable[3, "Description"]), collapse = "\n")
direction = c(rep("up", 5), rep("down", 5))
ggplot(rbind(resTimeGOupTable[1:5, ],
resTimeGOdownTable[1:5, ]),
aes(x = log2_Enrichment, y = factor(Description, levels = rev(Description)),
fill = direction)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("up" = "red", "down" = "darkgreen")) +
geom_text(aes(x = log2_Enrichment,
label = sprintf("%.2e", p.adjust)), hjust = 1, col = "white") +
ylab("")
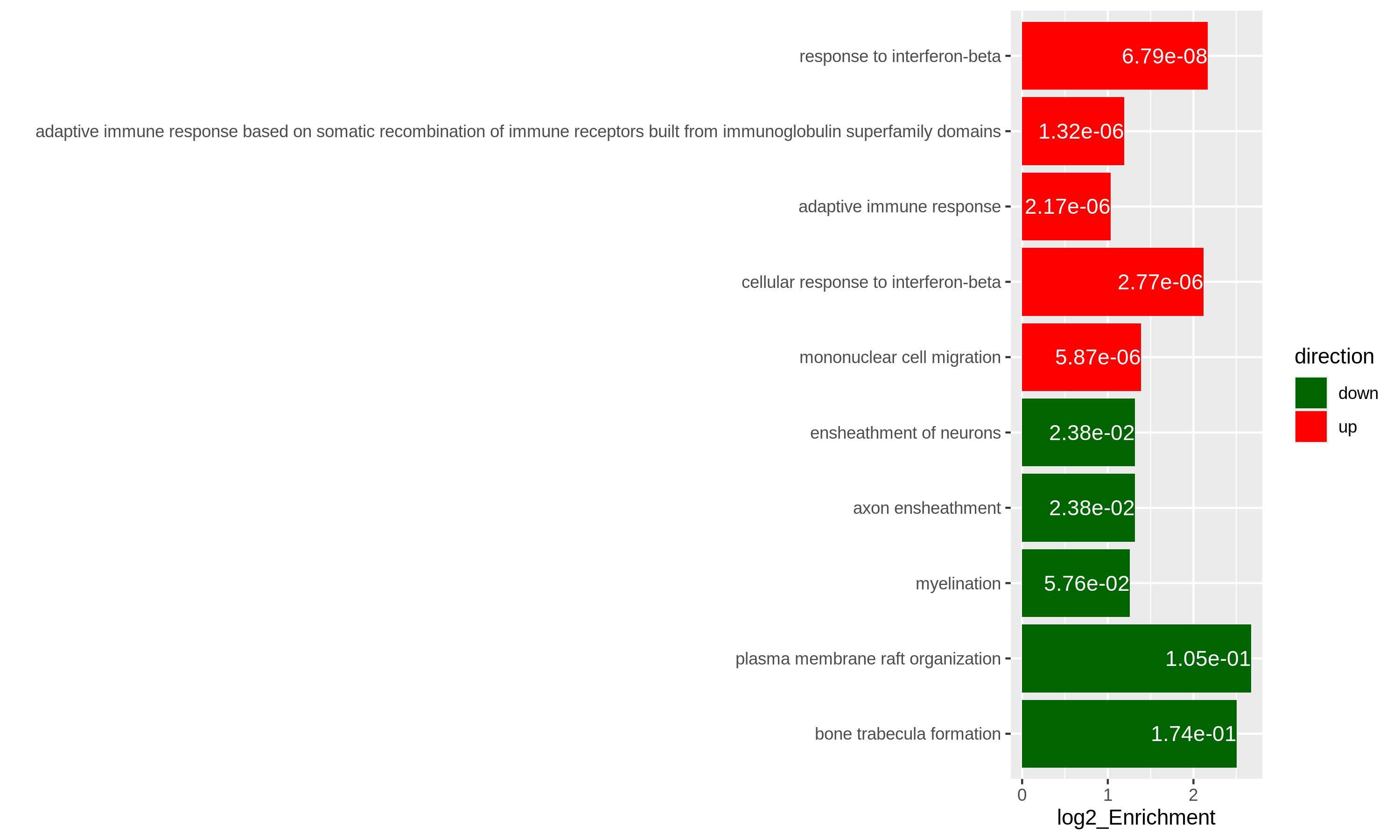
Specifically for GO enrichment, it is often that GO enrichment returns a long list of significant GO terms (e.g. several hundreds). This makes it difficult to summarize the common functions from the long list. The last package we will introduce is the simplifyEnrichment package which partitions GO terms into clusters based on their semantic similarity7 and summarizes their common functions via word clouds.
The input of the simplifyGO() function is a vector of GO
IDs. It is recommended to have at least 100 GO IDs for summarization and
visualization.
R
GO_ID = resTimeGOTable$ID[resTimeGOTable$p.adjust < 0.1]
library(simplifyEnrichment)
simplifyGO(GO_ID)
Further reading
ORA analysis actually applies a binary conversion on genes where genes pass the cutoff are set as 1 (DE gene) and others are set as 0 (non-DE gene). This binary transformation over-simplifies the problem and a lot of information are lost. There is second class of gene set enrichment analysis methods which takes the continuous gene-level score as input and weights the importance of a gene in the gene set. Please refer to Subramanian et. al. Gene set enrichment analysis: A knowledge-based approach for interpreting genome-wide expression profiles, PNAS 2005 for more information.
- ORA analysis is based on the gene counts and it is based on Fisher’s exact test or the hypergeometric distribution.
- In R, it is easy to obtain gene sets from a large number of sources.
Genes must be unique in each vector.↩︎
Also note
phyper()can be vectorized.↩︎The definition is from Wikipedia: https://en.wikipedia.org/wiki/Biological_pathway.↩︎
This is actually not true. Indeed
as.data.frame(resTimeGO)only returns the significant GO terms, but the complete enrichment table is still stored inresTimeGO@result. However, directly retrieving the slot of an S4 object is highly unrecommended.↩︎You can also use
select()function:select(org.Mm.eg.db, keys = timeDEgenes, keytype = "SYMBOL", column = "ENTREZID")↩︎If here the term “enrichment” does mean statistically.↩︎
The semantic similarity between GO terms considers the topological relations in the GO hierarchy.↩︎
Content from Next steps
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- How to go further from here?
- What other types of analyses can be done with RNA-seq data?
Objectives
- Get an overview of usages of RNA-seq data that are not covered in this workshop.
Transcript-level analyses
The analyses covered in this workshop all assumed that we have generated a matrix with read counts for each gene. Some questions, however, require expression estimates on a more fine-grained level, typically individual transcript isoforms. This is the case, for example, if we would like to look for differences in expression of individual isoforms, or changes in splicing patterns induced by a specific treatment. As already mentioned in episode 1, some quantification tools (such as Salmon, kallisto and RSEM) do in fact estimate abundances on the transcript level. To perform transcript-level differential expression analysis, these estimates would be used directly, without aggregating them on the gene level. Some caution is warranted, however, as expression estimates for individual transcripts are often more noisy than after aggregation to the gene level. This is due to the high similarity often observed between different isoforms of a gene, which leads to higher uncertainty when mapping reads to transcripts. For this reason, several approaches have been developed specifically for performing differential expression analysis on the transcript level [@Zhu2019-swish, @Baldoni2023-catchsalmon].
Analysis of differential splicing, or differential transcript usage, differs from the differential expression analyses mentioned so far as it is concerned with changes in the relative abundances of the transcripts of a gene. Hence, considering the transcripts in isolation is no longer sufficient. A good resource for learning more about differential transcript usage with Bioconductor is provided by @Love2018-swimming.
De novo transcript assembly
In this lesson, we have assumed that we are working with a well-annotated transcriptome, that is, that we know the sequence of all expressed isoforms and how they are grouped together into genes. Depending on the organism or disease type we are interested in, this may or may not be a reasonable assumption. In situations where we do not believe that the annotated transcriptome is complete enough, we can use the RNA-seq data to assemble transcripts and create a custom annotation. This assembly can be performed either guided by a genome sequence (if one is available), or completely de novo. It should be noted that transcript assembly is a challenging task, which requires a deeply sequenced library to get the best results. In addition, data from more recent long-read sequencing technologies can be very helpful, as they are in principle able to sequence entire transcript molecules, thus circumventing the need for assembly. Methods for transcript assembly represent an active area of research. Recent review are provided e.g. by @Raghavan2022-denovo and @Amarasinghe2020-longread.
- RNA-seq data is very versatile and can be used for a number of different purposes. It is important, however, to carefully plan one’s analyses, to make sure that enough data is available and that abundances for appropriate features (e.g., genes, transcripts, or exons) are quantified.