Exploratory analysis and quality control
Last updated on 2026-07-14 | Edit this page
Overview
Questions
- Why is exploratory analysis an essential part of an RNA-seq analysis?
- How should one preprocess the raw count matrix for exploratory
analysis?
- Are two dimensions sufficient to represent your data?
Objectives
- Learn how to explore the gene expression matrix and perform common quality control steps.
- Learn how to set up an interactive application for exploratory analysis.
Load packages
Assuming you just started RStudio again, load some packages we will
use in this lesson along with the SummarizedExperiment
object we created in the last lesson.
R
suppressPackageStartupMessages({
library(SummarizedExperiment)
library(DESeq2)
library(vsn)
library(ggplot2)
library(ComplexHeatmap)
library(RColorBrewer)
library(hexbin)
library(iSEE)
})
R
se <- readRDS("data/GSE96870_se.rds")
Remove unexpressed genes
Exploratory analysis is crucial for quality control and to get to know our data. It can help us detect quality problems, sample swaps and contamination, as well as give us a sense of the most salient patterns present in the data. In this episode, we will learn about two common ways of performing exploratory analysis for RNA-seq data; namely clustering and principal component analysis (PCA). These tools are in no way limited to (or developed for) analysis of RNA-seq data. However, there are certain characteristics of count assays that need to be taken into account when they are applied to this type of data. First of all, not all mouse genes in the genome will be expressed in our Cerebellum samples. There are many different threshold you could use to say whether a gene’s expression was detectable or not; here we are going to use a very minimal one that if a gene does not have more than 5 counts total across all samples, there is simply not enough data to be able to do anything with it anyway.
R
nrow(se)
OUTPUT
[1] 41786R
# Remove genes/rows that do not have > 5 total counts
se <- se[rowSums(assay(se, "counts")) > 5, ]
nrow(se)
OUTPUT
[1] 27430Challenge: What kind of genes survived this filtering?
Last episode we discussed subsetting down to only mRNA genes. Here we subsetted based on a minimal expression level.
- How many of each type of gene survived the filtering?
- Compare the number of genes that survived filtering using different thresholds.
- What are pros and cons of more aggressive filtering? What are important considerations?
R
table(rowData(se)$gbkey)
OUTPUT
C_region exon J_segment misc_RNA mRNA
14 1765 14 1539 16859
ncRNA precursor_RNA rRNA tRNA V_segment
6789 362 2 64 22 R
nrow(se) # represents the number of genes using 5 as filtering threshold
OUTPUT
[1] 27430R
length(which(rowSums(assay(se, "counts")) > 10))
OUTPUT
[1] 25736R
length(which(rowSums(assay(se, "counts")) > 20))
OUTPUT
[1] 23860- Cons: Risk of removing interesting information Pros:
- Not or lowly expressed genes are unlikely to be biological meaningful.
- Reduces number of statistical tests (multiple testing).
- More reliable estimation of mean-variance relationship
Potential considerations: - Is a gene expressed in both groups? - How many samples of each group express a gene?
Library size differences
Differences in the total number of reads assigned to genes between samples typically occur for technical reasons. In practice, it means that we can not simply compare a gene’s raw read count directly between samples and conclude that a sample with a higher read count also expresses the gene more strongly - the higher count may be caused by an overall higher number of reads in that sample. In the rest of this section, we will use the term library size to refer to the total number of reads assigned to genes for a sample. First we should compare the library sizes of all samples.
R
# Add in the sum of all counts
se$libSize <- colSums(assay(se))
# Plot the libSize by using R's native pipe |>
# to extract the colData, turn it into a regular
# data frame then send to ggplot:
colData(se) |>
as.data.frame() |>
ggplot(aes(x = Label, y = libSize / 1e6, fill = Group)) +
geom_bar(stat = "identity") + theme_bw() +
labs(x = "Sample", y = "Total count in millions") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1))
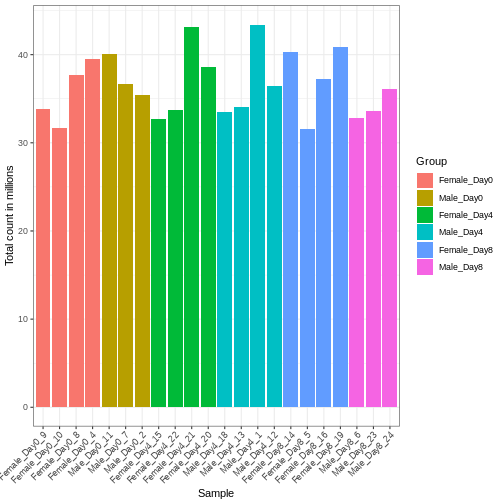
We need to adjust for the differences in library size between samples, to avoid drawing incorrect conclusions. The way this is typically done for RNA-seq data can be described as a two-step procedure. First, we estimate size factors - sample-specific correction factors such that if the raw counts were to be divided by these factors, the resulting values would be more comparable across samples. Next, these size factors are incorporated into the statistical analysis of the data. It is important to pay close attention to how this is done in practice for a given analysis method. Sometimes the division of the counts by the size factors needs to be done explicitly by the analyst. Other times (as we will see for the differential expression analysis) it is important that they are provided separately to the analysis tool, which will then use them appropriately in the statistical model.
With DESeq2, size factors are calculated using the
estimateSizeFactors() function. The size factors estimated
by this function combines an adjustment for differences in library sizes
with an adjustment for differences in the RNA composition of the
samples. The latter is important due to the compositional nature of
RNA-seq data. There is a fixed number of reads to distribute between the
genes, and if a single (or a few) very highly expressed gene consume a
large part of the reads, all other genes will consequently receive very
low counts. We now switch our SummarizedExperiment object
over to a DESeqDataSet as it has the internal structure to
store these size factors. We also need to tell it our main experiment
design, which is sex and time:
R
dds <- DESeq2::DESeqDataSet(se, design = ~ sex + time)
WARNING
Warning in DESeq2::DESeqDataSet(se, design = ~sex + time): some variables in
design formula are characters, converting to factorsR
dds <- estimateSizeFactors(dds)
# Plot the size factors against library size
# and look for any patterns by group:
ggplot(data.frame(libSize = colSums(assay(dds)),
sizeFactor = sizeFactors(dds),
Group = dds$Group),
aes(x = libSize, y = sizeFactor, col = Group)) +
geom_point(size = 5) + theme_bw() +
labs(x = "Library size", y = "Size factor")
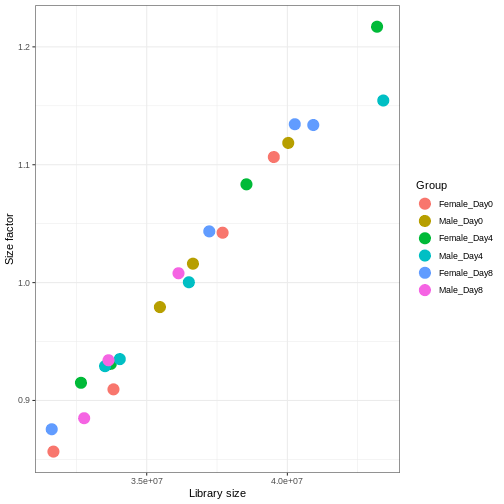
Transform data
There is a rich literature on methods for exploratory analysis. Most of these work best in situations where the variance of the input data (here, each gene) is relatively independent of the average value. For read count data such as RNA-seq, this is not the case. In fact, the variance increases with the average read count.
R
meanSdPlot(assay(dds), ranks = FALSE)
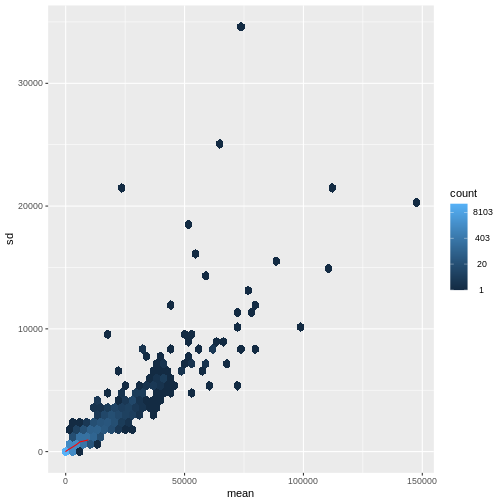
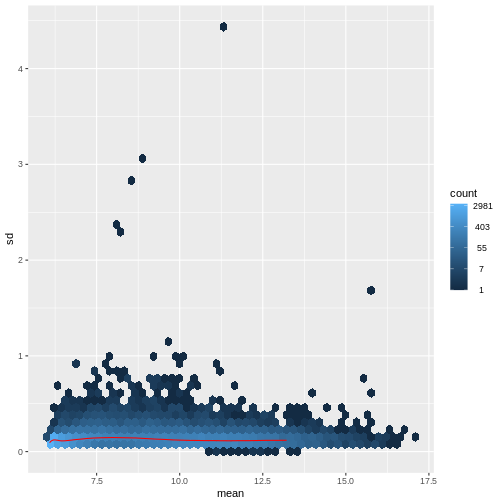
There are two ways around this: either we develop methods specifically adapted to count data, or we adapt (transform) the count data so that the existing methods are applicable. Both ways have been explored; however, at the moment the second approach is arguably more widely applied in practice. We can transform our data using DESeq2’s variance stabilizing transformation and then verify that it has removed the correlation between average read count and variance.
R
vsd <- DESeq2::vst(dds, blind = TRUE)
meanSdPlot(assay(vsd), ranks = FALSE)
Heatmaps and clustering
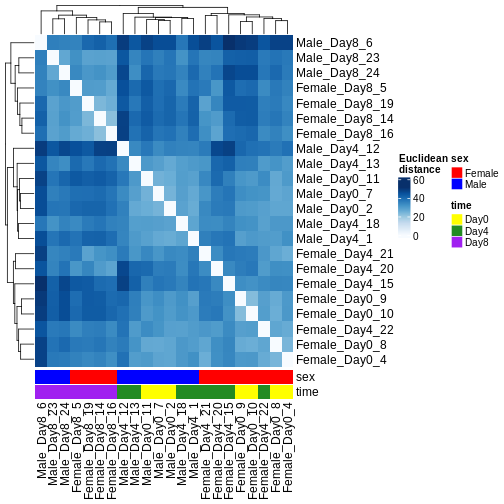
There are many ways to cluster samples based on their similarity of expression patterns. One simple way is to calculate Euclidean distances between all pairs of samples (longer distance = more different) and then display the results with both a branching dendrogram and a heatmap to visualize the distances in color. From this, we infer that the Day 8 samples are more similar to each other than the rest of the samples, although Day 4 and Day 0 do not separate distinctly. Instead, males and females reliably separate.
R
dst <- dist(t(assay(vsd)))
colors <- colorRampPalette(brewer.pal(9, "Blues"))(255)
ComplexHeatmap::Heatmap(
as.matrix(dst),
col = colors,
name = "Euclidean\ndistance",
cluster_rows = hclust(dst),
cluster_columns = hclust(dst),
bottom_annotation = columnAnnotation(
sex = vsd$sex,
time = vsd$time,
col = list(sex = c(Female = "red", Male = "blue"),
time = c(Day0 = "yellow", Day4 = "forestgreen", Day8 = "purple")))
)
PCA
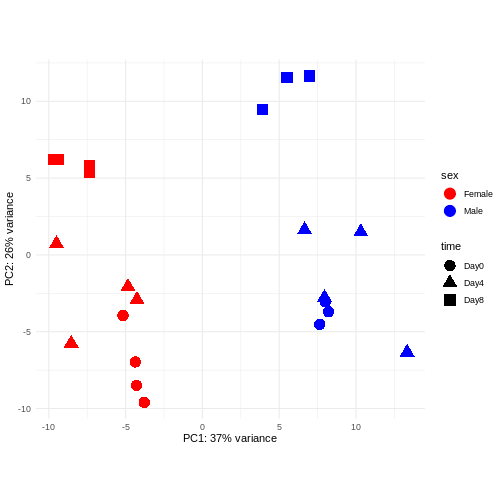
Principal component analysis is a dimensionality reduction method, which projects the samples into a lower-dimensional space. This lower-dimensional representation can be used for visualization, or as the input for other analysis methods. The principal components are defined in such a way that they are orthogonal, and that the projection of the samples into the space they span contains as much variance as possible. It is an unsupervised method in the sense that no external information about the samples (e.g., the treatment condition) is taken into account. In the plot below we represent the samples in a two-dimensional principal component space. For each of the two dimensions, we indicate the fraction of the total variance that is represented by that component. By definition, the first principal component will always represent more of the variance than the subsequent ones. The fraction of explained variance is a measure of how much of the ‘signal’ in the data that is retained when we project the samples from the original, high-dimensional space to the low-dimensional space for visualization.
R
pcaData <- DESeq2::plotPCA(vsd, intgroup = c("sex", "time"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaData, "percentVar"))
ggplot(pcaData, aes(x = PC1, y = PC2)) +
geom_point(aes(color = sex, shape = time), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_manual(values = c(Male = "blue", Female = "red"))
Challenge: Discuss the following points with your neighbour
Assume you are mainly interested in expression changes associated with the time after infection (Reminder Day0 -> before infection). What do you need to consider in downstream analysis?
Consider an experimental design where you have multiple samples from the same donor. You are still interested in differences by time and observe the following PCA plot. What does this PCA plot suggest?
OUTPUT
using ntop=500 top features by variance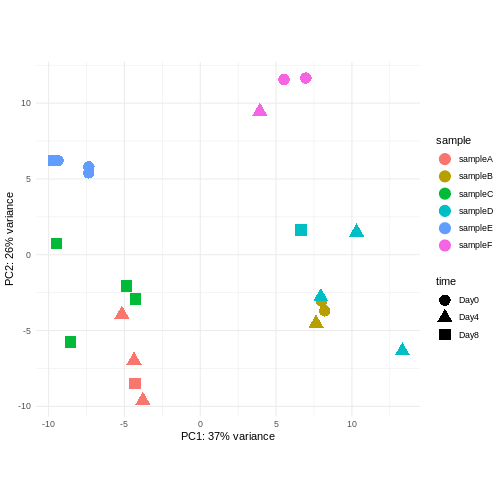
The major signal in this data (37% variance) is associated with sex. As we are not interested in sex-specific changes over time, we need to adjust for this in downstream analysis (see next episodes) and keep it in mind for further exploratory downstream analysis. A possible way to do so is to remove genes on sex chromosomes.
- A strong donor effect, that needs to be accounted for.
- What does PC1 (37% variance) represent? Looks like 2 donor groups?
- No association of PC1 and PC2 with time –> no or weak transcriptional effect of time –> Check association with higher PCs (e.g., PC3,PC4, ..)
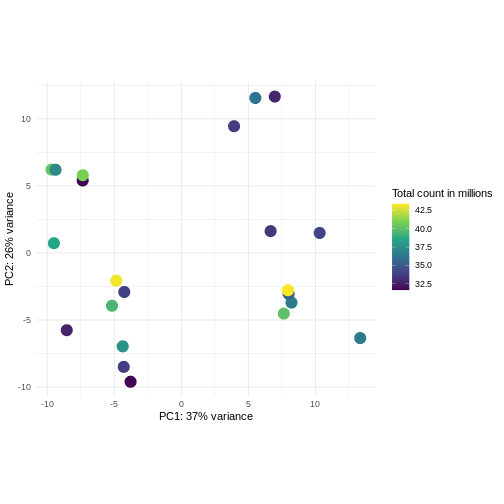
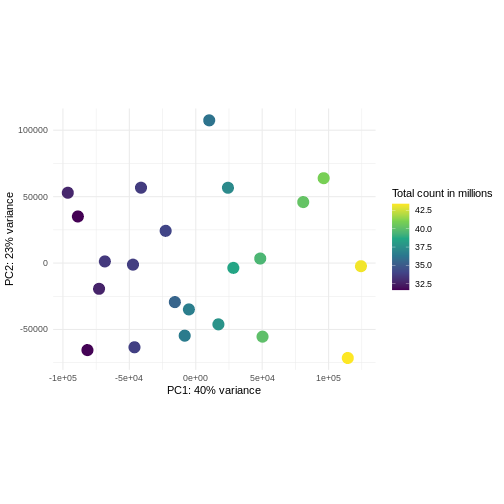
Challenge: Plot the PCA colored by library sizes.
Compare before and after variance stabilizing transformation.
Hint: The DESeq2::plotPCA expect an object of the
class DESeqTransform as input. You can transform a
SummarizedExperiment object using
plotPCA(DESeqTransform(se))
R
pcaDataVst <- DESeq2::plotPCA(vsd, intgroup = c("libSize"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaDataVst, "percentVar"))
ggplot(pcaDataVst, aes(x = PC1, y = PC2)) +
geom_point(aes(color = libSize / 1e6), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_continuous("Total count in millions", type = "viridis")
R
pcaDataCts <- DESeq2::plotPCA(DESeqTransform(se), intgroup = c("libSize"),
returnData = TRUE)
OUTPUT
using ntop=500 top features by varianceR
percentVar <- round(100 * attr(pcaDataCts, "percentVar"))
ggplot(pcaDataCts, aes(x = PC1, y = PC2)) +
geom_point(aes(color = libSize / 1e6), size = 5) +
theme_minimal() +
xlab(paste0("PC1: ", percentVar[1], "% variance")) +
ylab(paste0("PC2: ", percentVar[2], "% variance")) +
coord_fixed() +
scale_color_continuous("Total count in millions", type = "viridis")
Interactive exploratory data analysis
Often it is useful to look at QC plots in an interactive way to directly explore different experimental factors or get insides from someone without coding experience. Useful tools for interactive exploratory data analysis for RNA-seq are Glimma and iSEE
Challenge: Interactively explore our data using iSEE
R
## Convert DESeqDataSet object to a SingleCellExperiment object, in order to
## be able to store the PCA representation
sce <- as(dds, "SingleCellExperiment")
## Add PCA to the 'reducedDim' slot
stopifnot(rownames(pcaData) == colnames(sce))
reducedDim(sce, "PCA") <- as.matrix(pcaData[, c("PC1", "PC2")])
## Add variance-stabilized data as a new assay
stopifnot(colnames(vsd) == colnames(sce))
assay(sce, "vsd") <- assay(vsd)
app <- iSEE(sce)
shiny::runApp(app)
Session info
R
sessionInfo()
OUTPUT
R version 4.6.0 (2026-04-24)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] iSEE_2.24.0 SingleCellExperiment_1.34.0
[3] hexbin_1.28.5 RColorBrewer_1.1-3
[5] ComplexHeatmap_2.28.0 ggplot2_4.0.3
[7] vsn_3.80.0 DESeq2_1.52.0
[9] SummarizedExperiment_1.42.0 Biobase_2.72.0
[11] MatrixGenerics_1.24.0 matrixStats_1.5.0
[13] GenomicRanges_1.64.0 Seqinfo_1.2.0
[15] IRanges_2.46.0 S4Vectors_0.50.1
[17] BiocGenerics_0.58.1 generics_0.1.4
loaded via a namespace (and not attached):
[1] rlang_1.3.0 magrittr_2.0.5 shinydashboard_0.7.3
[4] clue_0.3-68 GetoptLong_1.1.1 otel_0.2.0
[7] compiler_4.6.0 mgcv_1.9-4 png_0.1-9
[10] vctrs_0.7.3 pkgconfig_2.0.3 shape_1.4.6.1
[13] crayon_1.5.3 fastmap_1.2.0 XVector_0.52.0
[16] labeling_0.4.3 promises_1.5.0 preprocessCore_1.74.0
[19] shinyAce_0.4.4 xfun_0.60 cachem_1.1.0
[22] jsonlite_2.0.0 listviewer_4.0.0 later_1.4.8
[25] DelayedArray_0.38.2 BiocParallel_1.46.0 parallel_4.6.0
[28] cluster_2.1.8.2 R6_2.6.1 bslib_0.11.0
[31] limma_3.68.4 jquerylib_0.1.4 Rcpp_1.1.2
[34] iterators_1.0.14 knitr_1.51 httpuv_1.6.17
[37] Matrix_1.7-5 splines_4.6.0 igraph_2.3.3
[40] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
[43] doParallel_1.0.17 codetools_0.2-20 affy_1.90.0
[46] miniUI_0.1.2 lattice_0.22-9 tibble_3.3.1
[49] shiny_1.14.0 withr_3.0.3 S7_0.2.2
[52] evaluate_1.0.5 circlize_0.4.18 pillar_1.11.1
[55] affyio_1.82.0 BiocManager_1.30.27 renv_1.2.3
[58] DT_0.34.0 foreach_1.5.2 shinyjs_2.1.1
[61] scales_1.4.0 xtable_1.8-8 glue_1.8.1
[64] tools_4.6.0 colourpicker_1.3.0 locfit_1.5-9.12
[67] colorspace_2.1-3 nlme_3.1-169 vipor_0.4.7
[70] cli_3.6.6 viridisLite_0.4.3 S4Arrays_1.12.0
[73] dplyr_1.2.1 gtable_0.3.6 rintrojs_0.3.4
[76] sass_0.4.10 digest_0.6.39 SparseArray_1.12.2
[79] ggrepel_0.9.8 rjson_0.2.23 htmlwidgets_1.6.4
[82] farver_2.1.2 htmltools_0.5.9 lifecycle_1.0.5
[85] shinyWidgets_0.9.1 GlobalOptions_0.1.4 statmod_1.5.2
[88] mime_0.13 - Exploratory analysis is essential for quality control and to detect potential problems with a data set.
- Different classes of exploratory analysis methods expect differently preprocessed data. The most commonly used methods expect counts to be normalized and log-transformed (or similar- more sensitive/sophisticated), to be closer to homoskedastic. Other methods work directly on the raw counts.