Assessing multiple linear regression model fit and assumptions
Overview
Teaching: 15 min
Exercises: 45 minQuestions
Why is the adjusted R squared used, instead of the standard R squared, when working with multiple linear regression?
What are the six assumptions of multiple linear regression and how are they assessed?
Objectives
Use the adjusted R squared value as a measure of model fit.
Assess whether the assumptions of the multiple linear regression model have been violated.
In this episode we will check the fit and assumptions of multiple linear regression models. We will use the extension to $R^2$ for multiple linear regression models, the adjusted $R^2$ ($R^2_{adj}$). We will also learn to assess the six linear regression assumptions in the case of multiple linear regression.
Measuring fit using $R^2_{adj}$
In the simple linear regression episode
on model assumptions we learned that $R^2$ quantifies
the proportion of variation in the outcome variable explained by the
explanatory variable. In the context of multiple linear regression, a
caveat emerges to $R^2$: adding explanatory variables to our model will
always increase $R^2$, even if the explanatory variables are not related to the response variable. Therefore, when interpreting
the output from summ(), look at the $R^2_{adj}$. This is an $R^2$ corrected
for the number of variables in the model. In some cases, the adjusted and
unadjusted metrics will be (near) equal. In other cases, the differences
will be larger.
Exercise
Find the adjusted R-squared value for the
summoutput of ourHemoglobin_Age_Sexmodel from episode 2. What proportion of variation in hemoglobin is explained by age, sex and their interaction in our model? Does our model account for most of the variation inHemoglobin?Solution
Hemoglobin_Age_Sex <- dat %>% filter(Age > 17) %>% lm(formula = Hemoglobin ~ Age * Sex) summ(Hemoglobin_Age_Sex, confint = TRUE)MODEL INFO: Observations: 5995 (502 missing obs. deleted) Dependent Variable: Hemoglobin Type: OLS linear regression MODEL FIT: F(3,5991) = 1026.31, p = 0.00 R² = 0.34 Adj. R² = 0.34 Standard errors: OLS --------------------------------------------------------- Est. 2.5% 97.5% t val. p ----------------- ------- ------- ------- -------- ------ (Intercept) 13.29 13.18 13.41 219.70 0.00 Age 0.00 -0.00 0.00 0.68 0.49 Sexmale 2.76 2.59 2.93 31.85 0.00 Age:Sexmale -0.02 -0.03 -0.02 -13.94 0.00 ---------------------------------------------------------Since $R^2_{adj} = 0.34$, our model accounts for approximately 34% of the variation in
Hemoglobin. Our model explains 34% of the variation inHemoglobin, which a model that always predicts the mean would not.
Assessing the assumptions of the multiple linear regression model
We learned to assess six assumptions in the simple linear regression episode on model assumptions. These assumptions also hold in the multiple linear regression context, although in some cases their assessment is a little more extensive. Below we will practice assessing these assumptions.
Validity
Recall that the validity assumption states that the model is appropriate for the research question. Validity is assessed through three questions:
A) Does the outcome variable reflect the phenomenon of interest?
B) Does the model include all relevant explanatory variables?
C) Does the model generalise to our case of interest?
Exercise
You are asked to use the
FEV1_Age_SmokeNowmodel to answer the following research question:“Does the effect of age on FEV1 differ by smoking status in US adults?”
Using the three points above, assess the validity of this model for the research question.
Solution
A) The research question is on FEV1, which is our outcome variable. Therefore our outcome variable reflects the phenomenon of interest.
B) Our research question asks whether the effect of age differs by smoking status, which can be tested using an interaction betweenAgeandSmokeNow. Since our model does not include this interaction, our model does not include all relevant explanatory variables.
C) Since the NHANES data was collected from individuals in the US, our model should generalise to our case of interest.
Representativeness
Recall that the representativeness assumption states that the sample is representative of the population to which we are generalising our findings. This assumption is assessed in the same way as for the case of the simple linear regression model, so we will not go through another exercise at this point. Note however that when representativesness is violated, this can sometimes be solved by adding the misrepresented variable to the model as an extra explanatory variable.
Linearity and additivity
Recall that this assumption states that our outcome variable has a linear, additive relationship with the explanatory variables.
The linearity component is assessed in the same way as in the simple
linear regression case. For example, recall that the relationship between
combined diastolic blood pressure (BPDiaAve) and age in months (AgeMonths)
was curved (see this episode from the simple linear regression lesson). Adding a squared term to the model helped us to model this
non-linear relationship. We can add a Sex term to fit separate
non-linear curves to this data:
BPDiaAve_AgeMonthsSQ_Sex <- lm(BPDiaAve ~ AgeMonths + I(AgeMonths^2) + Sex, data = dat)
interact_plot(BPDiaAve_AgeMonthsSQ_Sex, pred = AgeMonths, modx = Sex,
plot.points = TRUE, interval = TRUE,
point.size = 0.7) +
ylab("Combined diastolic blood pressure") +
xlab("Age in Months")
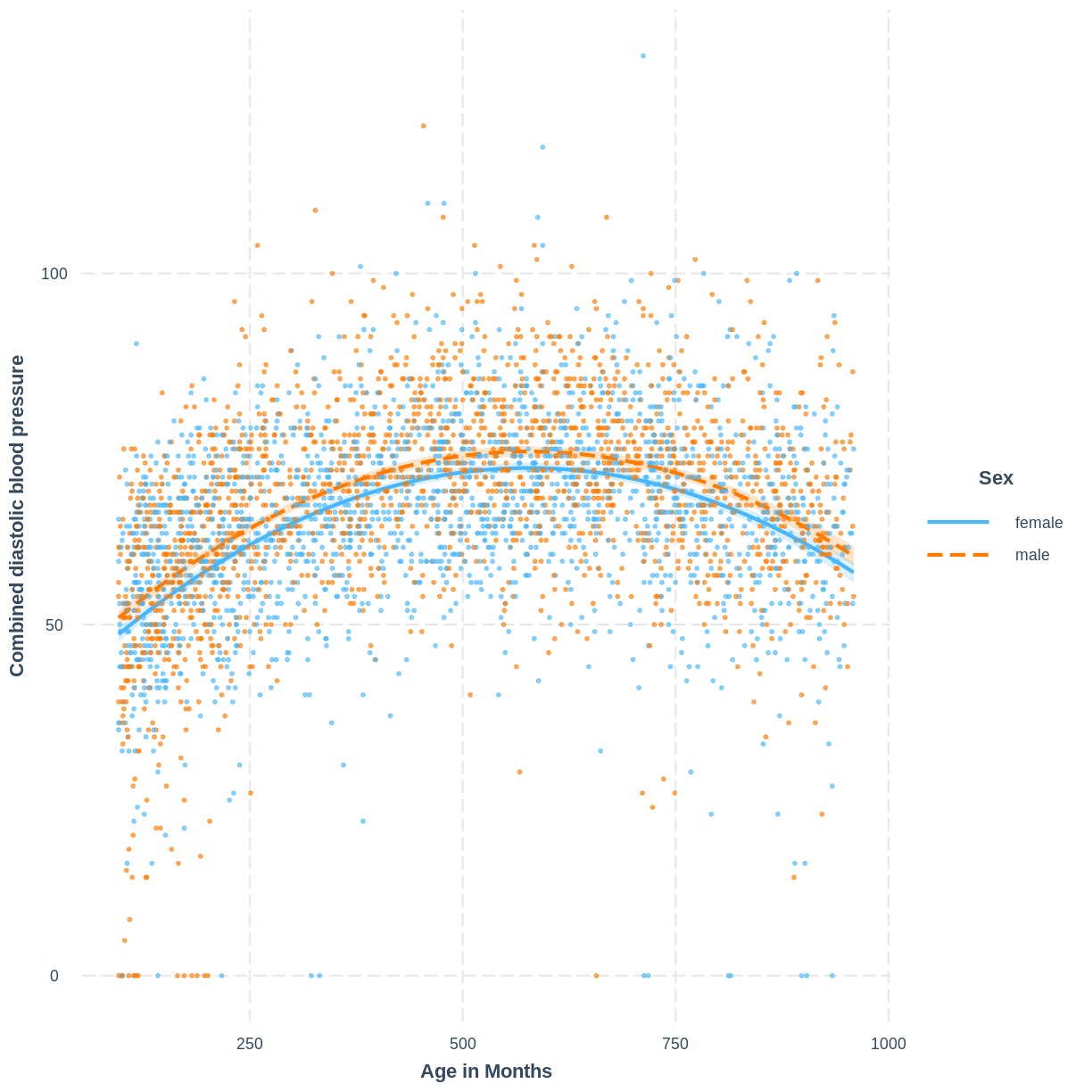
The non-linear relationship has now been modeled separately for levels of a categorical variable.
Recall that the additivity component of the linearity and additivity assumption means that the effect of any explanatory variable on the outcome variable does not depend on another explanatory variable in the model. In other words, that our model includes all necessary interactions between explanatory variables. In the above example, the additivity component does not appear to be violated: it does not look like the data requires an interaction between age and sex. However, to be sure of this we may compare the model fit of models with and without the interaction using the tools discussed in this episode.
Exercise
In the example above we saw that a model with a squared explanatory variable can also include separate intercepts for levels of a categorical variable.
Recall our
child_logWeight_Height_lmmodel from the previous lesson, which modeled the relationship between the log of child weight and child height:child_logWeight_Height_lm <- dat %>% filter(Age < 18) %>% lm(formula = log(Weight) ~ Height) effect_plot(child_logWeight_Height_lm, pred = Height, plot.points = TRUE, interval = TRUE, line.colors = c("magenta"))
Extend this model by adding separate intercepts for the levels of the
Sexvariable. Visualise the model usinginteract_plot(). Do you think that including the interaction betweenHeightandSexis necessary?Solution
child_logWeight_Height_Sex <- dat %>% filter(Age < 18) %>% lm(formula = log(Weight) ~ Height + Sex) interact_plot(child_logWeight_Height_Sex, pred = Height, modx = Sex, plot.points = TRUE, interval = TRUE, point.size = 0.7)
There is little evidence from the plot that the effect of height on weight is different between sexes meaning that an interaction term is not needed. But we could assess the model fit with and without the interaction to check.
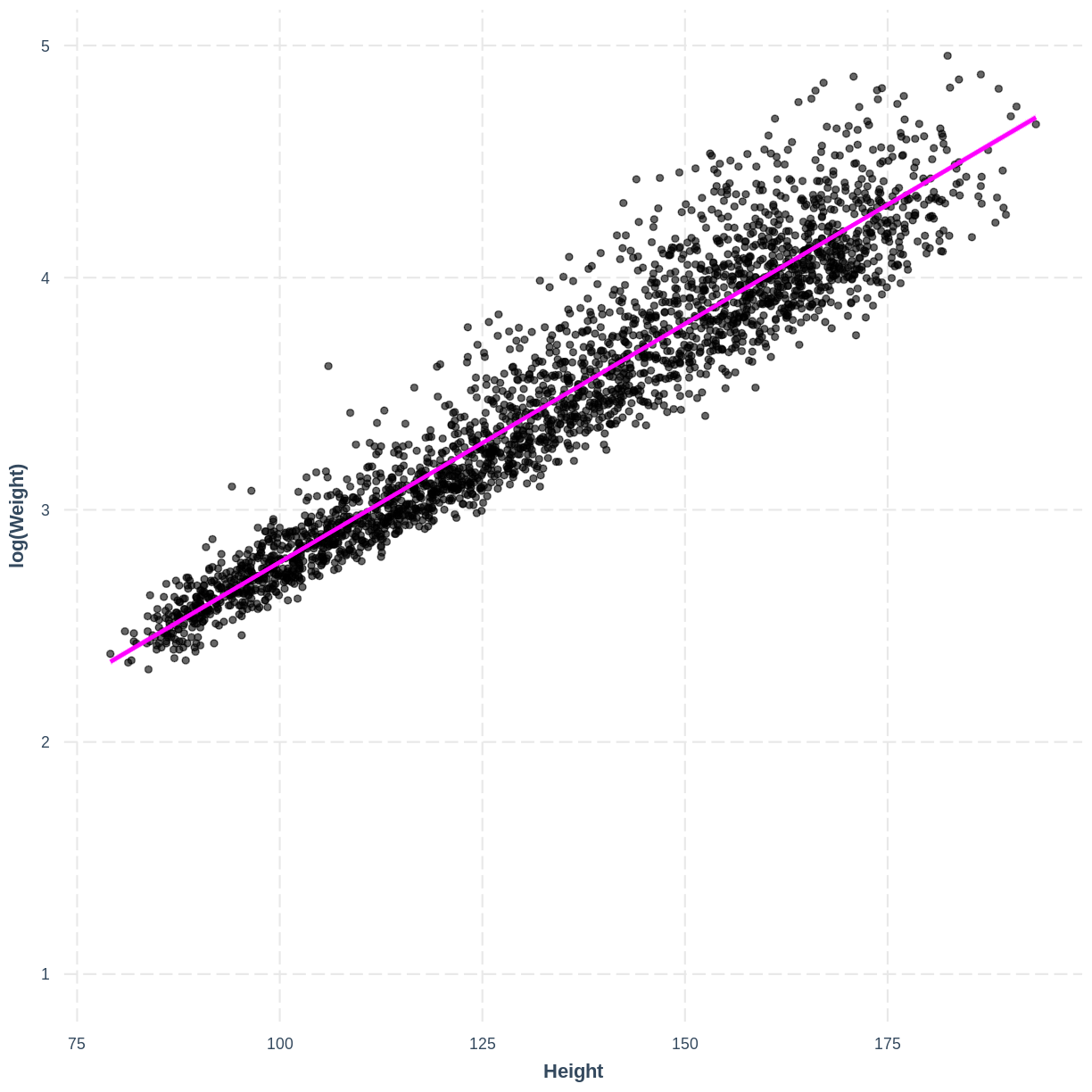
Independent errors
Recall that when observations in our data are grouped, this can result in a violation of the independent errors assumption. If there are a few levels in our grouping variable (say, less than 6) then we may overcome the violation by including the grouping variable as an explanatory variable in our model. If the grouping variable has many more levels, we may opt for a modelling approach more complex than multiple linear regression.
Exercise
In which of the following scenarios are we at risk of violating the independent errors assumption? In those cases, should we be working with an extra explanatory variable?
A) We are modelling the effect of average daily calorie intake on BMI in the adult UK population. We have one observation per participant and participants are known to belong to one of five income brackets.
B) We are modelling the effect of age on grip strength in adult females in the UK. Whether participants are physically active is known.
C) We are asking whether people’s sprinting speed is increased after partaking in an athletics course. Our data includes measurements of 100 participant’s sprinting speed before and after the course.Solution
A) Since we have multiple observations per income bracket, our observations are not independent. There are five levels in the income bracket variable, so we may chose to include income bracket as an explanatory variable.
B) Since we have multiple observations per level of physical activity, our observations are not independent. Since there are two levels in our physical activity variable, we could use physical activity as an explanatory variable in our model.
C) This data has two levels of grouping: within individuals (two measurements per individual) and timing (before/after the course). While timing can be included as an explanatory variable (two levels), it would not be appropriate to include individuals as an explanatory variable (100 levels). In this scenario we would opt for a more complex modelling approach (a mixed effect model).
Equal variance of errors (homoscedasticity)
This assumption states that the magnitude of variation in the residuals is not different across the fitted values or any explanatory variable. Importantly, when interactions are included in the model, the scale of the residuals should be checked at the interaction level. In the case of an interaction between continuous and categorical explanatory variables, this means colouring the points in the residuals vs explanatory variable plot by the levels of a categorical variable.
For example, below we create the diagnostic plots for our Hemoglobin_Age_Sex
model. We create plots of residuals vs. fitted (p1), residuals vs. age (p2)
and residuals vs. sex (p3). Notice that in the residuals vs. age plot, we colour
points by sex using colour = sex. This allows us to assess whether the residuals
are homogenously scattered across age, grouped by sex (i.e. at the interaction
level). Note that the / in p1 / p2 / p3 relies on the patchwork package
being loaded and results in the three graphs being plotted in vertical sequence.
residualData <- tibble(resid = resid(Hemoglobin_Age_Sex),
fitted = fitted(Hemoglobin_Age_Sex),
age = Hemoglobin_Age_Sex$model$Age,
sex = Hemoglobin_Age_Sex$model$Sex)
p1 <- ggplot(residualData, aes(x = fitted, y = resid)) +
geom_point(alpha = 0.3) +
geom_smooth() +
ylab("Residual") +
xlab("Fitted values")
p2 <- ggplot(residualData, aes(x = age, y = resid, colour = sex)) +
geom_point(alpha = 0.3) +
geom_smooth() +
ylab("Residual") +
xlab("Age")
p3 <- ggplot(residualData, aes(x = sex, y = resid)) +
geom_violin() +
geom_jitter(alpha = 0.3, width = 0.2) +
ylab("Residual") +
xlab("Sex")
p1 / p2 / p3
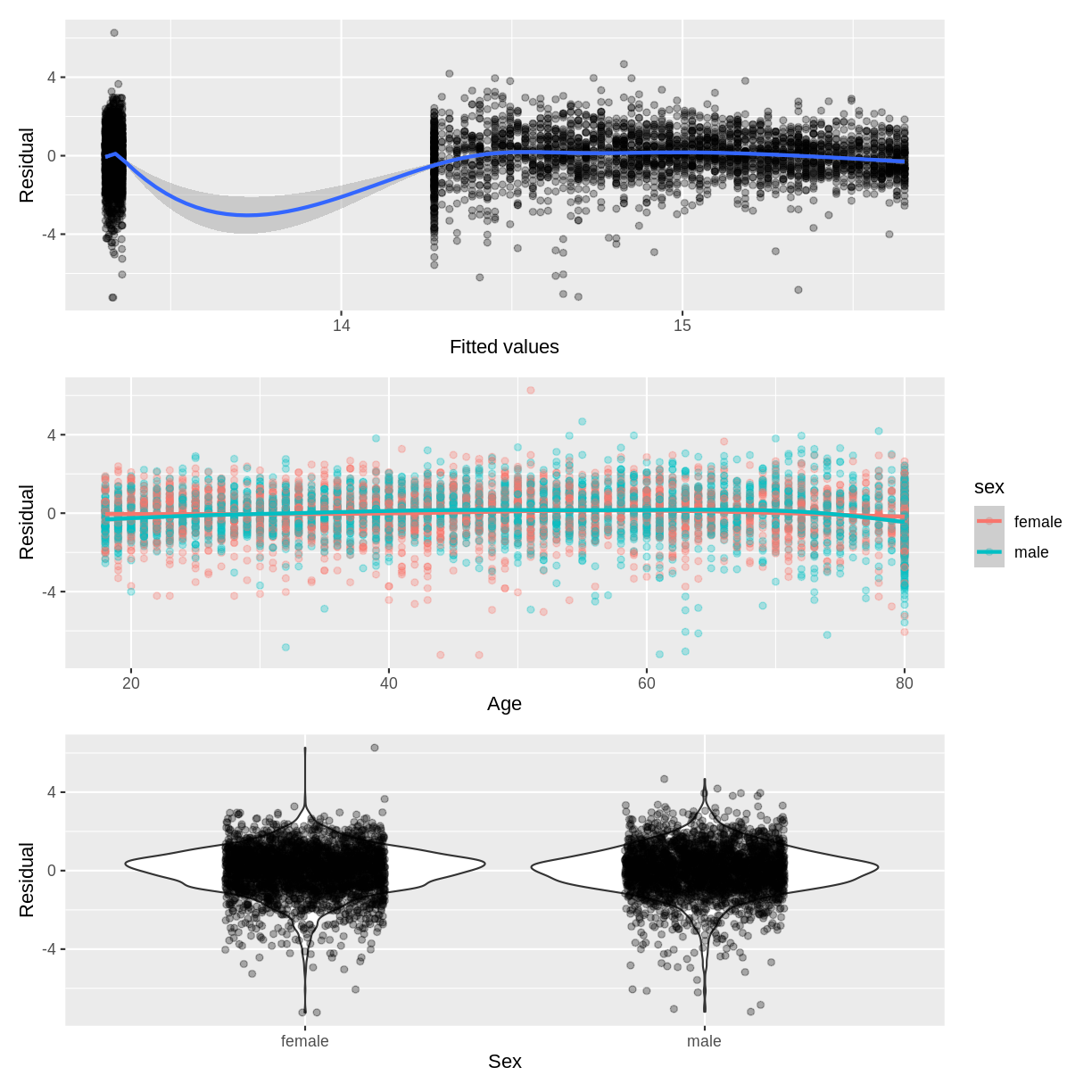
Exercise
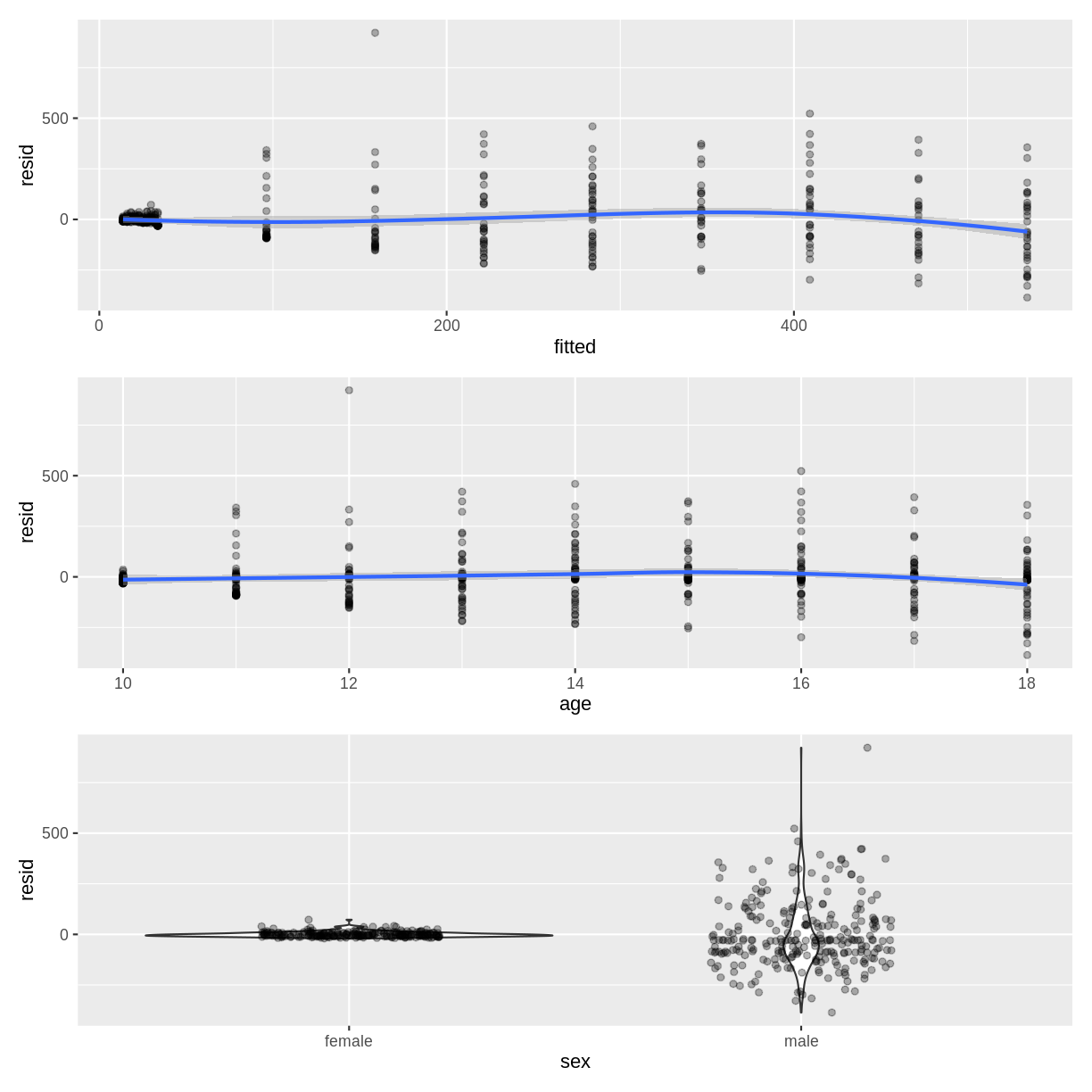
A colleague is studying testosterone levels in children. They have fit a multiple linear regression model of testosterone as a function of age, sex and their interaction. The data and their model look as shown below:
This colleague approaches you for your thoughts on the following diagnostic plots, used to assess the homoscedasticity assumption.
A) What issues can you identify in the diagnostic plots?
B) How could the diagnostic plots be improved to be more informative?Solution
A) The residuals appear to fan out as the fitted values or age increase. The residuals also do not appear to be homogenous across sex, as the violin plot for males is much longer than for females.
B) The points in the scatterplot of age could be coloured by sex to assess the homoscedasticity assumption at the interaction level:
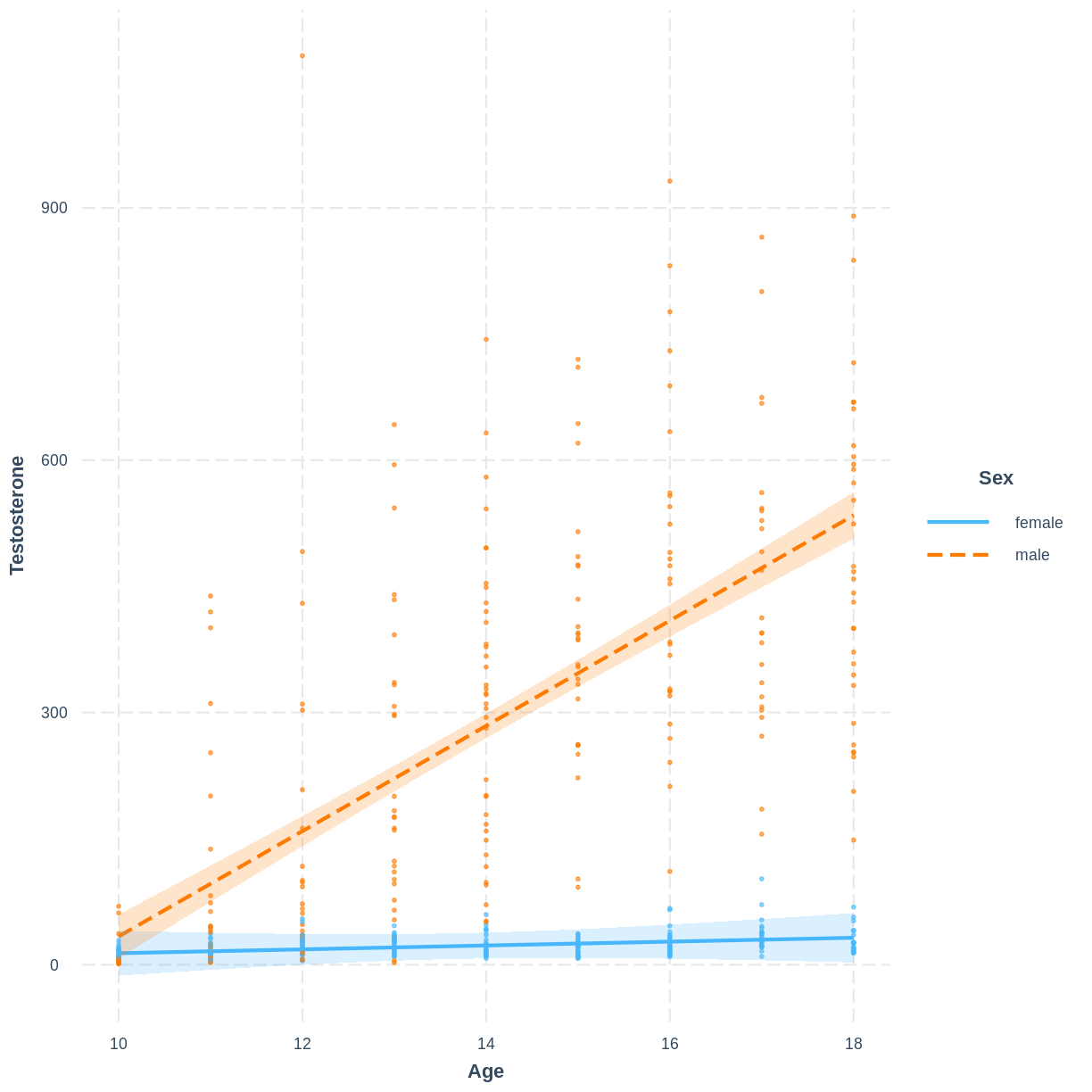
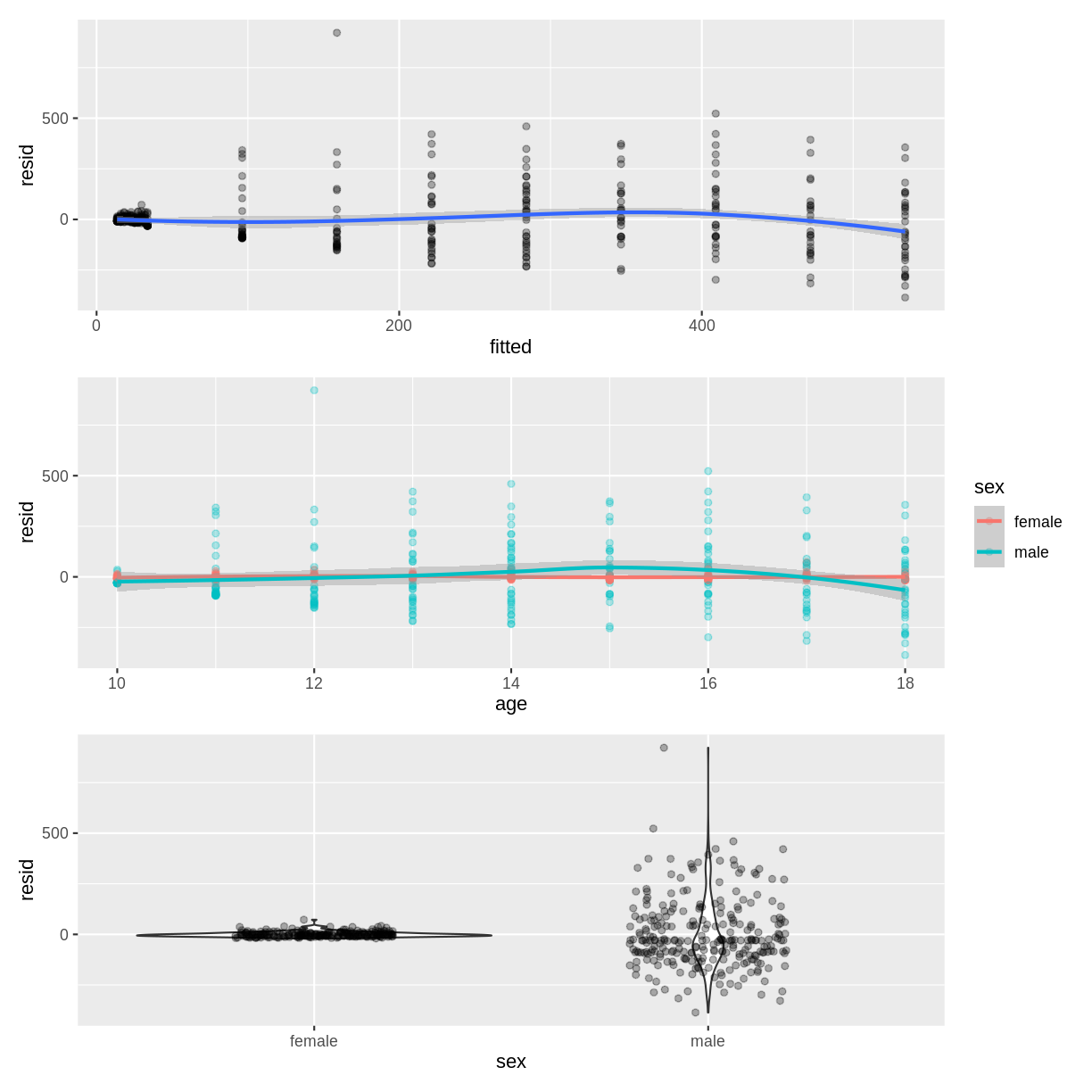
Normality of errors
Recall that this assumption states that the errors follow a normal distribution. When this assumption is strongly violated, predictions from the model are less reliable. Small deviations from normality may pose less of an issue. This assumption is assessed in the same way as for the case of the simple linear regression model, so we will not go through another exercise at this point.
Key Points
The adjusted R squared measure ensures that the metric does not increase simply due to the addition of a variable. The variable needs to improve model fit for the adjusted R squared to increase.
The same assumptions hold for simple and multiple linear regression, however more steps are involved in the assessment of the assumptions in the context of multiple linear regression.