Introduction to Programming with R and RStudio
Overview
Teaching: min
Exercises: minQuestions
What is a program?
Why would do we want to use a program?
What is R and RStudio and how can we use them to read in data?
Objectives
Learn programming concepts and terms
Learn how to open up RStudio and read in our data
Programming concepts and language
Programming doesn’t have to be scary, and we have some real-world examples to help you understand what’s going on with these words we’re typing in a computer text window. The words in bold will come up in a programming context later on, but it might help to have a mental reference picture to associate with these words.
Let’s imagine that instead of a program to work with numbers and letters, we’re creating a program that cooks breakfast instead.
In order to make breakfast, you need:
- A working directory (the place where you’re doing things, such as your kitchen countertop)
- Available data (information about what you’re working with)
- Data could be an inventory of your pantry, a grocery shopping list, a map of the store, a collection of prices at the store, and so forth.
- Types of objects – a method of grouping what can be done to what types of things.
- Food is one type of thing; people are another; pets are a third.
- A specific food object can be an egg or a pancake; a particular pet object can be your cat or your dog.
- Some inputs that may be objects of appropriate types (breakfast food ingredients)
- You create breakfast by performing actions on objects of food types, and then you feed it to things of the people and pet types.
- Some functions (recipes that work with the ingredients)
- Inputs to functions are usually stored in variables – you don’t always want to make the same thing every day, so the instructions have placeholder names for things that are similar to each other but may vary. (A “todays_cheese” variable could hold Stilton for one day’s omelet and cheddar for the next.)
- You need to match your object types to your functions.
- You shouldn’t use a pet-type object as an input to a breakfast-making function. (Nobody wants to eat the goldfish for breakfast.)
- You might be able to use a dinner-type food object as an input to a breakfast-making function, but use caution.
- Some outputs (food ready to be consumed)
- A destination (where to put the food that’s ready to be consumed)
- You could put your outputs in your working directory (eat breakfast in your kitchen) or you could send it to another location (put leftovers in the refrigerator)
 “Breakfast” by viviandnguyen_ is licensed under CC BY-SA 2.0
“Breakfast” by viviandnguyen_ is licensed under CC BY-SA 2.0
Intro to R and RStudio
In this episode we’ll cover the basics of using R, which is a programming language for statistics, data analysis, and data visualization. In the past decade or so, R has become very popular in both science and business, largely because (1) it is free, and (2) thousands of people have written new code extending its functionality, and that code is also free. If you perform an analysis in R, you can share that analysis so that anyone in the world can reproduce it without having to purchase any other software.
If you’re already proficient with Excel, you will probably already know how to accomplish a lot of what we are doing in this episode using Excel instead of R. One reason why we are teaching you this material, however, is to get you comfortable with R since we will be using R for geospatial analysis (which is not so easy in Excel). In addition, R makes it easier for your processes to be automatic and repeatable, traits we find very desirable when running analyses over and over again.
In this lesson, we will be making use of another software called “RStudio” as a way to interact with the programming language R. RStudio makes writing our programs more user-friendly. Using RStudio instead of R is a little like having a toaster. You can make toast over a fire, but having a toaster makes the job easier and less scorch-prone.
We launch RStudio by double clicking on its icon, as we would with other software on our computers.
Windows Users: Click Here for more details
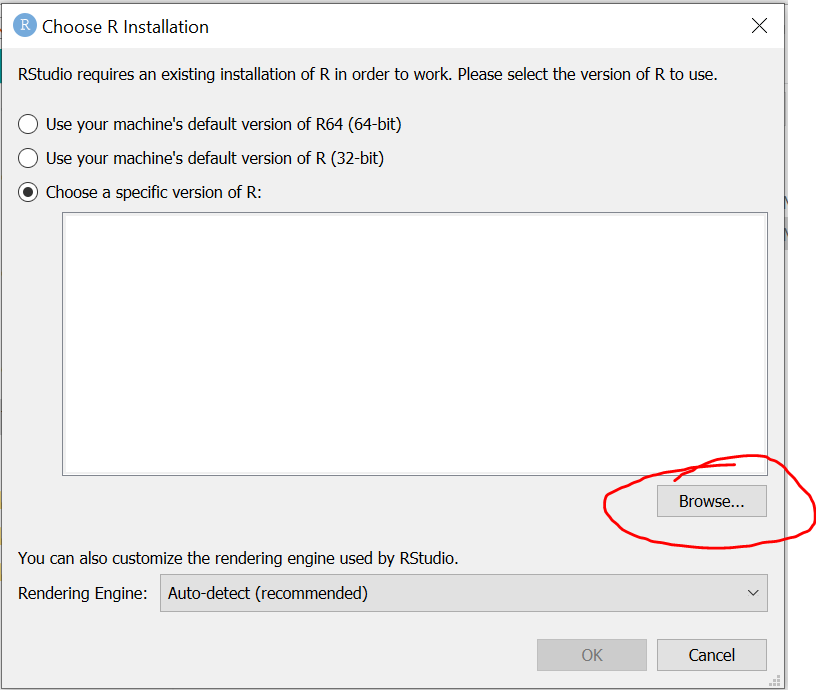
If you’re running R Studio from a copy made from the USB stick, then the first time you launch R Studio, you’ll be asked where your installation of R is located.
- Choose the “Choose a specific version of R” item next to the large text box.
- Use the Browse button to navigate to:
- DataHarvestingWin/ProgramFiles/R/R-3.6.2/bin/
- and choose Select Folder.
Next, you’ll be prompted which version you want to use. You could choose either 32 bit or 64 bit; either should work, but 64 bit is likely to be what your computer is capable of.
In the image below, the 64 bit version has been chosen and you can now press OK.
You’ll be prompted to restart R Studio; double click the launch icon again. At this point, R Studio should open next.
![]()
Getting your RStudio workspace ready for the workshop
Let’s get our “countertop” ready to “cook” by:
- Setting up our working directory.
- Loading libraries and sourcing functions in order to make the tools we’ll use available to RStudio.
- Locating our data ingredients.
Setting your working directory
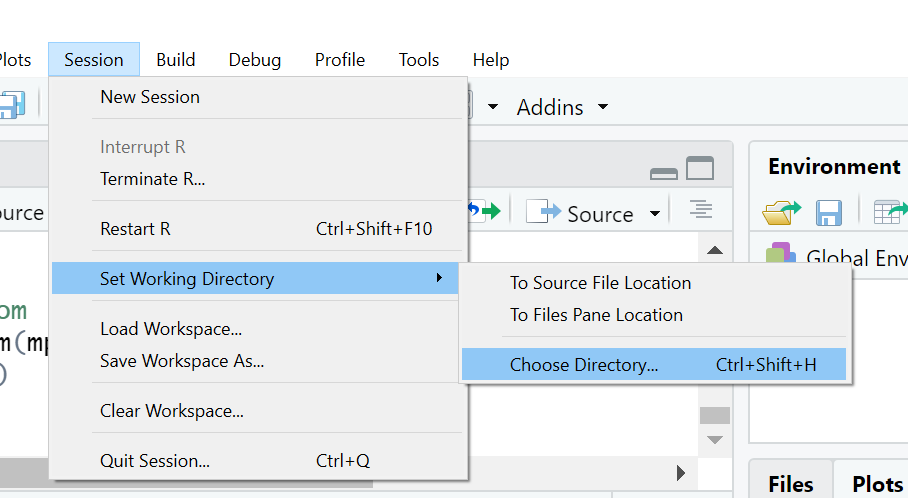
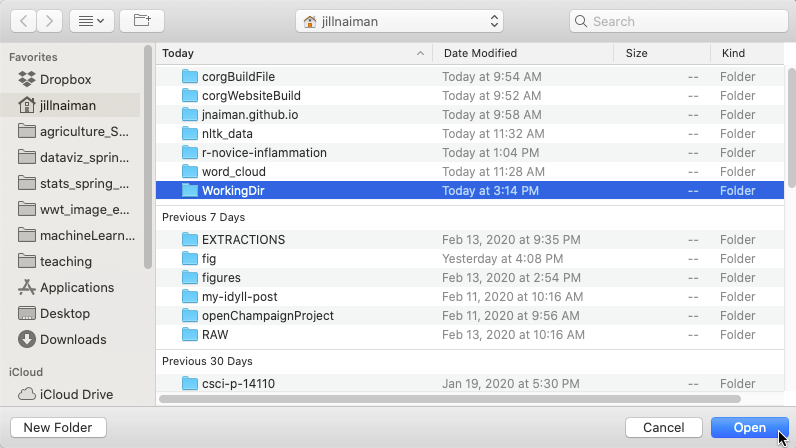
Under the Session menu, choose Set Working Directory, then Choose Directory.
Windows Users: Click here for more details
In each software collection on the USB drive, we’ve made subdirectories called
WorkingDirwith another subdirectory called data. (Even if you’ve installed from scratch rather than copying from the USB drive, the instructions will be easier to follow if you have a folder calledWorkingDirthat contains another one calleddata.)So if you’re using our file collection after copying it to your local hard drive on Windows, choosing your working directory will look like this:
(If you’re running from the USB drive, the drive letter there will likely say
D:instead ofC:, but the rest will be the same.)
Mac Users: Click here for more details
Selecting the
WorkingDirfile where we’ve copied the scripts anddatadirectory.
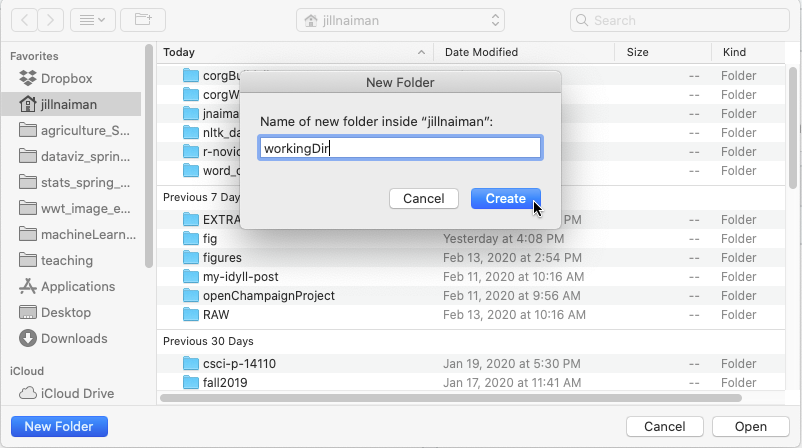
If you do not see a working directory
WorkingDir, make sure you are in the right folder. If you have not yet created a working directory, you can do so at this point:
Once selected, click
Open. Once you have your directory set you should see asetwdcommand show up in the console of RStudio:
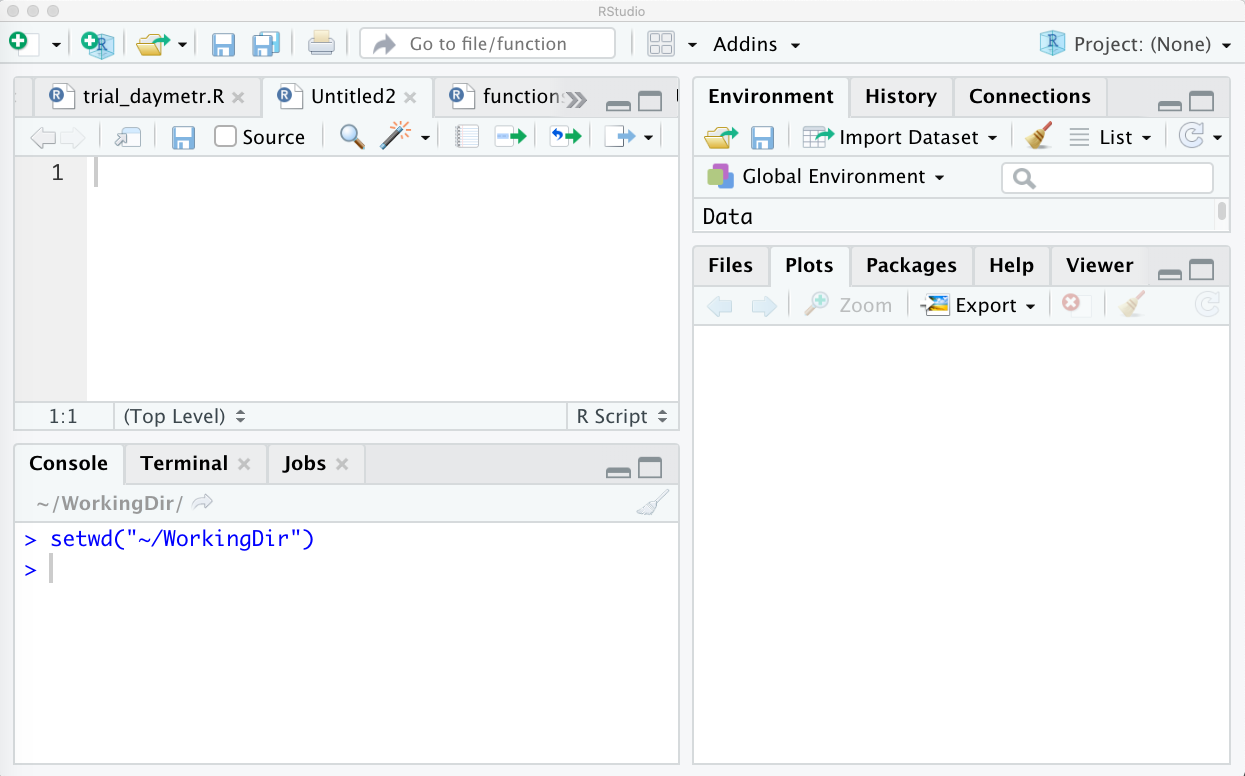
Windows
At the console, type:
setwd("C:/DataHarvestingWin/WorkingDir")
Mac
At the console, type:
setwd("~/WorkingDir")
Now we’ve identified where we want to work and can start loading libraries and data.
Loading libraries and sourcing functions
R and RStudio are used in many different fields, including biology, genomics, and geospatial data. If we loaded everything that R was capable of handling at once, though, it would take even more space than it already does!
So with this set of instructions, we’re telling R that we want a set of published tools that are appropriate for working with geospatial data and public data sources, and also some custom-written scripts specifically for this workshop.
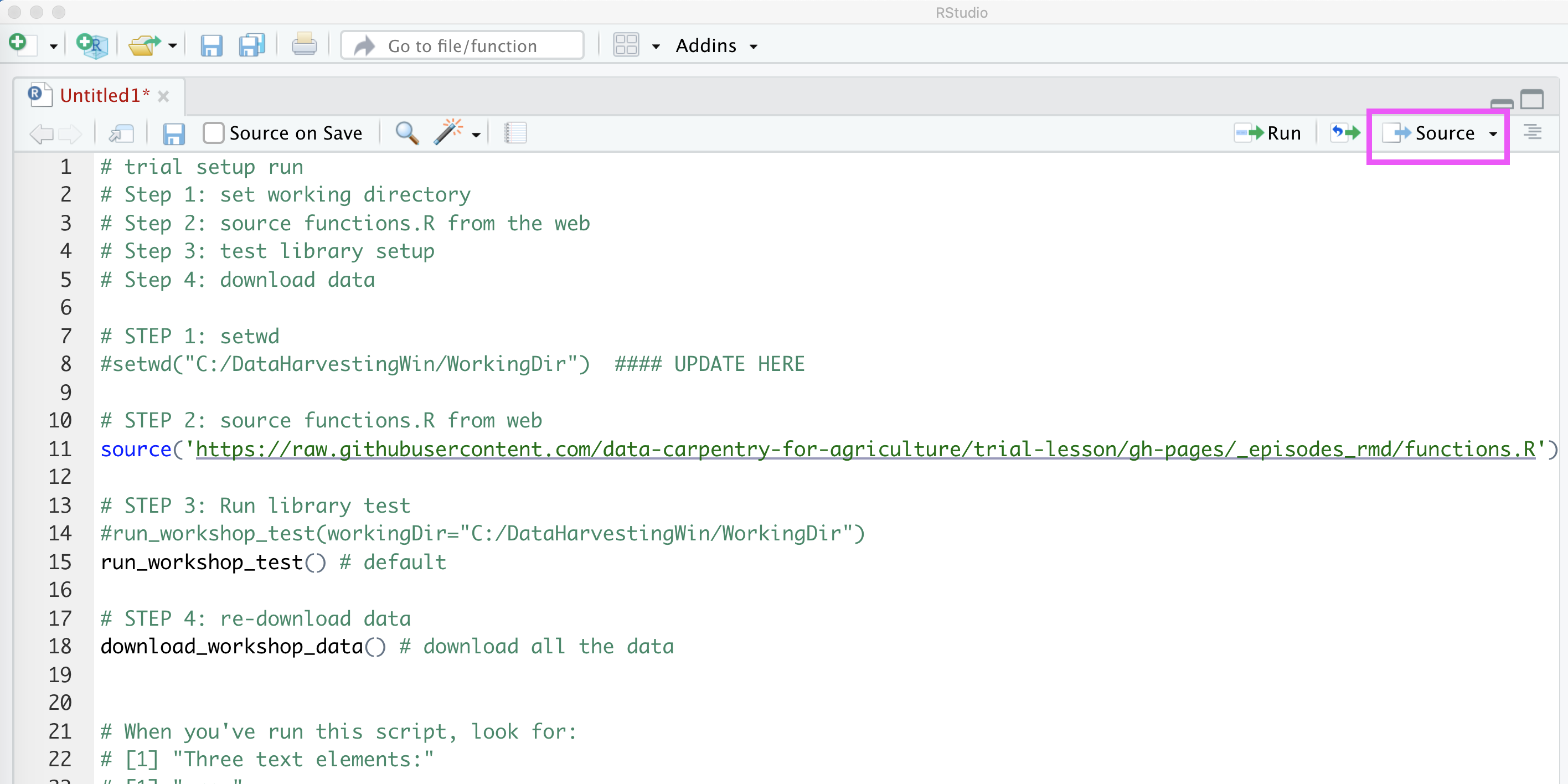
- Right-click to open the code for the
package_load_and_test.Rscript in a new browser window. This file will tell R which tools should be loaded into its memory and make sure they’re all working. - Create a new R script file for yourself in R Studio by clicking on
File→New File→R Script. - Copy and paste the test script from the browser window into your new script file.
- Save the file as
package_load_and_test.Rin your working directory so that you’ll be able to use it again. - Click the
Sourcebutton near the top right of your script window to load these functions as well.
Updating your startup script and saving your R Studio environment
You can save your R Studio environment so that the next time it loads, it will remember what libraries and functions you’ve been working with.
You’ll be prompted to do this when you quit R Studio:
q()
Save workspace image to C:/DataHarvestingWin/WorkingDir/.RData? [y/n]:
If you choose Y, you’ll save your working environment and R Studio will load it at the next launch.
However, it’s not a bad idea to modify the download and test script a little bit so that you could reuse it in case you’re working on other projects as well.
To find out what your current working directory is, run this command in the console:
getwd()
Ideally, this should say C:/DataHarvestingWin/WorkingDir on Windows. (Macs will see a different variation involving DataHarvestingMac.)
If the directory you see here isn’t the one you want to use, scroll up to the “Set Working Directory” section above and use those instructions to choose your working directory. Then run getwd() again to make sure you have the directory you want.
Once you have the directory you want (shown by getwd()):
- Remove the
#before setwd in the line belowSTEP 1. - If your
getwd()results don’t matchC:/DataHarvestingWin/WorkingDir, you’ll need to change what’s in the quotations on that line. - With your cursor on that line of the script, click the
Runbutton. - The
setwd()command will run from the script. - Click
File→Savein order to save the changes to your script so you won’t need to do this again in the future.
Additionally, you probably won’t want to re-download the data files every time you run the startup script. To prevent that from happening, we add a # at the start of the line after STEP 3.
With these modifications, if you start R Studio and don’t see what you expect to see, you can re-open package_load_and_test.R and click the Source button to get your environment re-loaded.
Locating data ingredients
The instructions from here on out assume that you’ve set your working directory to be a folder named “WorkingDir” and that you have a folder inside it called “data” which contains several files of information.
We’ve automated bringing data sets in from our lesson as part of the setup script, but when you want to work with your own data, it’ll help to know which directory you’ve stored it in.
Tip for Testing
When you’re testing things out, it’s a good idea to work with copies of your files rather than with the originals. Make copies in a different working directory to give yourself the freedom to experiment and make mistakes without damaging your original data.
The stuff in your “kitchen”: Getting oriented with R Studio
So far, we’ve seen some things happen in the four quadrants of R Studio:
- New R script files are made in the top left quadrant, and if you have more than one of them open at a time, you’ll see more than one tab with the file names on them.
- If you want to save the commands you’re working on, this is where you’ll put your work. There’s no real downside to keeping your notes in a script file; you can easily come back to your work later.
- The console is in the lower left quadrant, and that’s where the “action items” happen. When you clicked through the test script elements, text-based responses came up in the console whether or not a graphic was rendered with that test.
- In R Studio, it’s helpful to get in the habit of typing your work in a script window, selecting your section, and hitting Run instead of typing directly in the console. You can’t easily get back what you typed in the console in a previous session. (Script files are like recipe cards that you save; entries on the console are like scribbling on the back of a napkin.)
- Information about your environment is in the top right quadrant. This includes libraries that are loaded, variables that have had information put into them, and so forth. Several of the tests caused changes in this area.
- The lower right quadrant holds several tabs, but the two you’ll use most often are the Plots tab and the Packages tab.
- The map-drawing tests produced images in the Plots tab.
- When you ran the library-loading lines, checkmarks appeared by those libraries’ names in the Packages tab.
- That’s a handy way to know what your current environment includes. If you’ve just reopened RStudio after a time away, and you’re not sure what RStudio remembers from your last session, look at the Packages tab to see if your libraries are loaded or not. In our case, dplyr is an easy one to find near the start of the alphabet; if it’s not checked when you open RStudio, you’ll want to re-run the package_load_and_test.R script.
- Check it out: Click from tab to tab to see what’s in each of them.
Let’s crack some eggs: Getting started with functions and variables
From our breakfast example earlier, here are some of the programming terms and analogies for what they mean.
What is a function?
A function is a bit of code that we want to be able to reuse again and again. For example, let’s say you want to make omelets every morning, wouldn’t it be great if you had some sort of machine that would do it for you?
Let’s imagine an omelet-making scenario. You start with some eggs, some cheese, and some other ingredients, use utensils and heat, and end up with something cooked and edible on a plate—or more than one plate, if several people want omelets that morning.
The number of eggs and amount of cheese you use can vary depending on how many you want, so we call the bit of space that stores that information a variable.
Sometimes the recipe you received is dependent on other things that you want to leave yourself notes about as well. Just like scribbling on a recipe card, you can leave comments in your code by beginning a commented section with a # character.
Here’s what that omelet process might look like in terms a step closer to programming:
Making an Omelet
Instructors: Build a process like this step-by-step on the board or screen if possible, incorporating student input.
~~~
Note: This doesn’t actually do anything; it’s just a thought-example.
You don’t need to copy this into RStudio.
function make_omelet(how_many, todays_cheese, cheese_quantity, other_ingredients) {
# Multiply number of omelets wanted by 2 eggs each eggs <- how_many * 2
# Multiply cheese per omelet by number of omelets to decide how much cheese is needed total_cheese <- how_many * cheese_quantity
# Mix ingredients for each bowl crack eggs discard shells add total_cheese if other_ingredients bowl <- bowl + other_ingredients else ready to cook
# When ready to cook pour bowl into hot pan # if more than 3 eggs, get more hot pans cook serve wash_dishes } ~~~
In this example, we’re telling the system these things:
- A function (repeatable sequence of commands) named make_omelet takes several inputs (the ingredients list in parentheses)
- The part in the curly braces {} tells the function what to do with the inputs (also called arguments or parameters – you can think of this as an ingredients list if it helps)
To use a function we have to call it in a specific way. (To call a function is to use it for a specific case with specific data.) Let’s call an R function named print which will just echo back what we give it as an input parameter:
todays_cheese <- "Stilton" # assign the value of Stilton to a variable called "todays_cheese" -- we don’t want to use apostrophes in variable names, so today’s_cheese wouldn’t work.
print(todays_cheese) # print out the value of the variable to the screen
From now on, whenever we use todays_cheese, R will substitute the value we assigned to it. In layman’s terms, a variable is a placeholder name for something that can be changed regularly.
In R, variable names:
- can include letters, digits, and underscores
- cannot start with a digit
- are case sensitive, meaning that “ABC” is considered different than “abc”.
This means that, for example:
cheese1is a valid variable name, whereas1cheeseis noteggsandEggsare different variables
Variable Naming Conventions
Historically, R programmers have used a variety of conventions for naming variables. The
.character in R can be a valid part of a variable name; thus the above assignment could have easily beentodays.cheese <- "Stilton".This is often confusing to R newcomers who have programmed in languages where
.has a more significant meaning, or to people who are used to file names likeresume.docwhere the component after.identifies the type of a file.Today, most R programmers prefer these standards:
- Start variable names with lower case letters
- Separate words in variable names with underscores
- Use only lowercase letters, underscores, and numbers in variable names. (The book R Packages includes a chapter on this and other style considerations.)
Variables and data types
Something that it’s important to keep track of is what type of data you’ve stored in a particular variable. Words are treated differently than numbers, and numbers with decimals are treated differently than numbers without decimals. So, for example:
cheese_varietycould be “Stilton” or “cheddar”, but you probably don’t want a number here. This variable type is called a text string.
cheese_variety <- "Stilton" # quotes help your text variables get assigned correctly, especially if it's a multi-word unit like "Double Gloucester cheese"
cheese_amountcould be “a quarter cup”. Numbers are much easier to calculate on computers than words, so we represent that as “0.25”. This variable type is called a floating point number and would be assigned similarly to thecheese_varietyvariable:
cheese_amount <- 0.25 # in cups
-
eggscould possibly be 2.5, but it’s much easier to use either 2 whole eggs or 3 whole eggs. When you want to make sure you’re working with whole units, this variable type is called an integer.- The first time you use a number-type variable, if you want it to always be an integer, don’t include a decimal point when you assign it (
eggs <- 2). On the other hand, if you do want to have the ability to have decimal points in that value in the future, make sure to include the decimal point even if it’s.0(cheese_quantity <- 2.0):
- The first time you use a number-type variable, if you want it to always be an integer, don’t include a decimal point when you assign it (
eggs <- 2 # this will be stored as an integer
cheese_quantity <- 2.0 # this will be stored as a float
- Another variable type we’ll be introducing in a few minutes is a dataframe, which lets you hold a whole spreadsheet’s worth of information in one variable. This will be very useful for working with things more complicated than omelets, such as agricultural data!
Notice that they can all be named in similar ways; you don’t have to tell the system what type of variable you’ve just created, but it might be handy to leave #comments for yourself.
How many eggs? Passing variables and data to functions
Your breakfast function make_omelet() may default to “make omelets for two people,” but maybe one day you’re the only person who wants an omelet and another day you’re having a party. Being able to tell the function how many omelets you want to make without rewriting your code saves a bunch of time.
So when you look at the arguments list requested in make_omelet():
function make_omelet(how_many, todays_cheese, cheese_quantity, other_ingredients)
The list of items it’s asking for includes the things that are likely to change based on the day, and then the mathematical transformations from “how many omelets” to “how many eggs and how much cheese is needed” are handled inside the function.
The thing that you pass in to a function or assign to a variable can also be a data set. Let’s take a look at how to do that next.
Working with some real data
As an example of a dataset in spreadsheet form that we can use to demonstrate the R language, we are using the USDA Economic Research Service dataset on fertilizer use and price. Of all of the various tables of data on this website, we are interested now at Table 2 called “Estimated U.S. plant nutrient use by selected crops” which shows 1,000 nutrient short tons of nitrogen, phosphorus, and potash used on corn, soy, cotton, wheat, and other crops in the US from 1964–2016.
This table has been reformatted into a CSV file for ease of import into R.
- If you copied your data folder from the USB drive, it’s available in the data folder as fertilizer_use.csv.
- If not, you can download the CSV here.
What’s a CSV file and why are they helpful?
CSV stands for “common separator of values.” What’s stored in a CSV file is spreadsheet-type data, and it can be opened in Microsoft Excel (among many other things).
You might be used to seeing spreadsheet-type files saved with the
.xlsor.xlsxformat types. However, while the Excel format is complicated to take apart, a CSV is really easy for many programs to read, including text viewers and R Studio.
Getting your data into RStudio
The top few lines of the file look like:
Year,Crop,Nitrogen,Phosphate,Potash
1964,Corn,1623,1053,829
1965,Corn,2151,1336,1204
1966,Corn,2596,1626,1513
1967,Corn,3044,1857,1750
It can be opened in Excel if you want to get a quick look at it that way, or we can dive straight into looking at it in R.
Next, we’ll use the function called read.csv to import data from a CSV (comma-separated value) file. (In this case the csv is part of the name of the function, not the name of a separate file. We didn’t choose the name, which is admittedly a bit confusing here.)
To do this, put this line in your script area (upper left hand quadrant) and click Run.
fert_use <- read.csv("data/fertilizer_use.csv")
Take a moment and identify:
- the name of the function (
read.csv) - the input parameter (
"data/fertilizer_use.csv") - the variable containing the data after the code is executed (
fert_use)
The name of the file we want to read includes the data folder we created earlier. The / after data indicates to R that it should look inside this folder for the file named fertilizer_use.csv.
fert_use now shows up in the Global Environment window at the upper left of RStudio.
Explore your data in R
Now that you have your data imported into R, it would be nice to take a look at it! One quick way to do this is using the head function like so:
head(fert_use)
This lets us look at our table of data, but it formats things in a nice way, with the name of each column at the top and the row numbered on the left side.
We can furthermore control how many rows print out by including an optional parameter in our function call:
head(fert_use, n=4)
Note that we can call the head function without this parameter and it will run just fine with some default value. If we want to specify the number of rows, we include this as parameter name = parameter value. In this case, our parameter name for the head function is n and the parameter value is 4.
Getting help: How do you know what parameters a function wants?
Different functions will have different parameter names. For most professionally published software, you can get more information by appending a
?to the front of a function call:?headOther ways to get help
Oftentimes the Web provides a good resource for learning about R functions. Googling “head function r” will return many pages about the
headfunction, including the R-documentation pages.
Now let’s say we want to look at only the first few entries of the Years column of our dataset? We can do this by making use of the fact that our variable fert_use is a special type of variable called a dataframe. A dataframe is like a spreadsheet without a view. It allows us to print out individual columns by saying dataframe name $ dataframe column:
head(fert_use$Year, n=4)
Here the label of the column, Year is used to access this column alone and print out its first 4 entries. Let’s try another one:
head(fert_use$Crop, n=4)
We get a bit of extra information when we look at the Crop column. With the column Years, R stored the data as pure numbers (integers, or whole numbers without decimal places). With Crop, R has stored this column as something called a factor. A factor stores information by category instead of by number. (We call this a categorical variable while Years is called a numerical variable.) R also tells us how many levels this categorical column has, which is just R’s way of counting up the number of categories that Crop can be. In this case, we see there are 5 categories of crops in this dataset, Corn, Cotton, Other, Soybeans and Wheat. By default, R orders them alphetetically.
Using str to get column types
As with the function head, the str function is helpful for getting a quick look at your data and summarizing what kinds of columns you have:
str(fert_use)
Here str is the function name that we called with the input parameter of fert_use which is the variable that is storing our table of data.
The str function prints out the first few entries of each row, the ... just means that it has truncated its output for the sake of clarity.
Again, as with the function head, we see that the str function is also telling us something about how our data is formatted:
- There are 5 columns in our dataset -
Year,Crop,Nitrogen,Phosphate, andPotash. - There are 265
observations, or rows, in our dataset - The
Year,Nitrogen,Phosphate, andPotashcolumns areinttypes, meaning they are comprised of whole numbers (numbers without decimals) - The
Cropcolumn is a factor with 5levels. The trailing 1’s are just R’s way of tagging which row entry in this column is in what category - a 1 means a row that is tagged as “Corn”, a 2 would be a row that is taked as “Cotton”.
The str function also tells us that our variable fert_use is a dataframe by printing 'data.frame' at the top of its output.
Working with your data in R
Now that we have read in some data and have some idea of what our dataset contains, let’s actually think about manipulating our dataset! One thing we might want to know is find out the time span overwhich this data was taken. We can find out the minimum time in our dataset by applying the the min function on our Year column:
min(fert_use$Year)
And we can find the maximum year in our dataset in a similar fashion:
max(fert_use$Year)
Now we know our dataset is taken from 1964-2016! This is of course something we could have known by reading the description of this table, so let’s try something more interesting: the minimum measurement of Nitrogen:
min(fert_use$Nitrogen)
Wait a minute! What just happened?
In R, NA means missing data. Let’s take a look at a the first 50 entries of our Nitrogen column:
head(fert_use$Nitrogen, n=50)
You can see from these first 50 entries, that we ended up with a lot of NA values. By default, if we apply the min function and it encounters any NA values, it returns NA. To figure out what to do, let’s look at the help page. To find the help page for any function, type a question mark and then the name of the function.
?min
So there is an optional parameter called na.rm, and the description of it says that it controls whether or not NA values are stripped out before calculating the mean. We can make R take out NA’s before calculating the minimum by setting the optional parameter to TRUE. (In R, TRUE and FALSE should always be in all caps.)
min(fert_use$Nitrogen, na.rm = TRUE)
This worked! Let’s try a few more examples.
Finding the Maximum Nitrogen Measurement
Use the
maxfunction to calculate the maximum nitrogen measurement in your dataset.Solution
max(fert_use$Nitrogen, na.rm=TRUE)
Maximum Crop
What happens when you try to apply the max function to the
Cropcolumn? Why do you think that is?Solution
max(fert_use$Crop, na.rm=TRUE)The
maxfunction only is meaningful for numerical data, in this case you are trying to apply it to a column that is made up of categories and R got confused and printing out an error message.
Key Points
In programming there is certain terminology we need to learn: variables, variable types, functions
Use
variable <- valueto assign a value to a variable in order to record it in memory.Use
read.csvto read data in to R