Content from Getting Started with Nextflow
Last updated on 2024-06-10 | Edit this page
Overview
Questions
- What is a workflow and what are workflow management systems?
- Why should I use a workflow management system?
- What is Nextflow?
- What are the main features of Nextflow?
- What are the main components of a Nextflow script?
- How do I run a Nextflow script?
Objectives
- Understand what a workflow management system is.
- Understand the benefits of using a workflow management system.
- Explain the benefits of using Nextflow as part of your bioinformatics workflow.
- Explain the components of a Nextflow script.
- Run a Nextflow script.
Workflows
Analysing data involves a sequence of tasks, including gathering, cleaning, and processing data. This sequence of tasks is called a workflow or a pipeline. These workflows typically require executing multiple software packages, sometimes running on different computing environments, such as a desktop or a compute cluster. Traditionally these workflows have been joined together in scripts using general purpose programming languages such as Bash or Python.
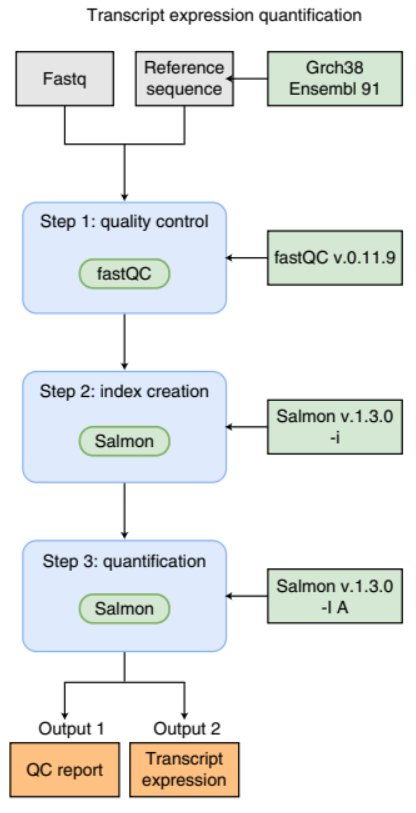
An example of a simple bioinformatics RNA-Seq pipeline.
However, as workflows become larger and more complex, the management of the programming logic and software becomes difficult.
Workflow management systems
Workflow Management Systems (WfMS) such as Snakemake, Galaxy, and Nextflow have been developed specifically to manage computational data-analysis workflows in fields such as bioinformatics, imaging, physics, and chemistry. These systems contain multiple features that simplify the development, monitoring, execution and sharing of pipelines, such as:
- Run time management
- Software management
- Portability & Interoperability
- Reproducibility
- Re-entrancy
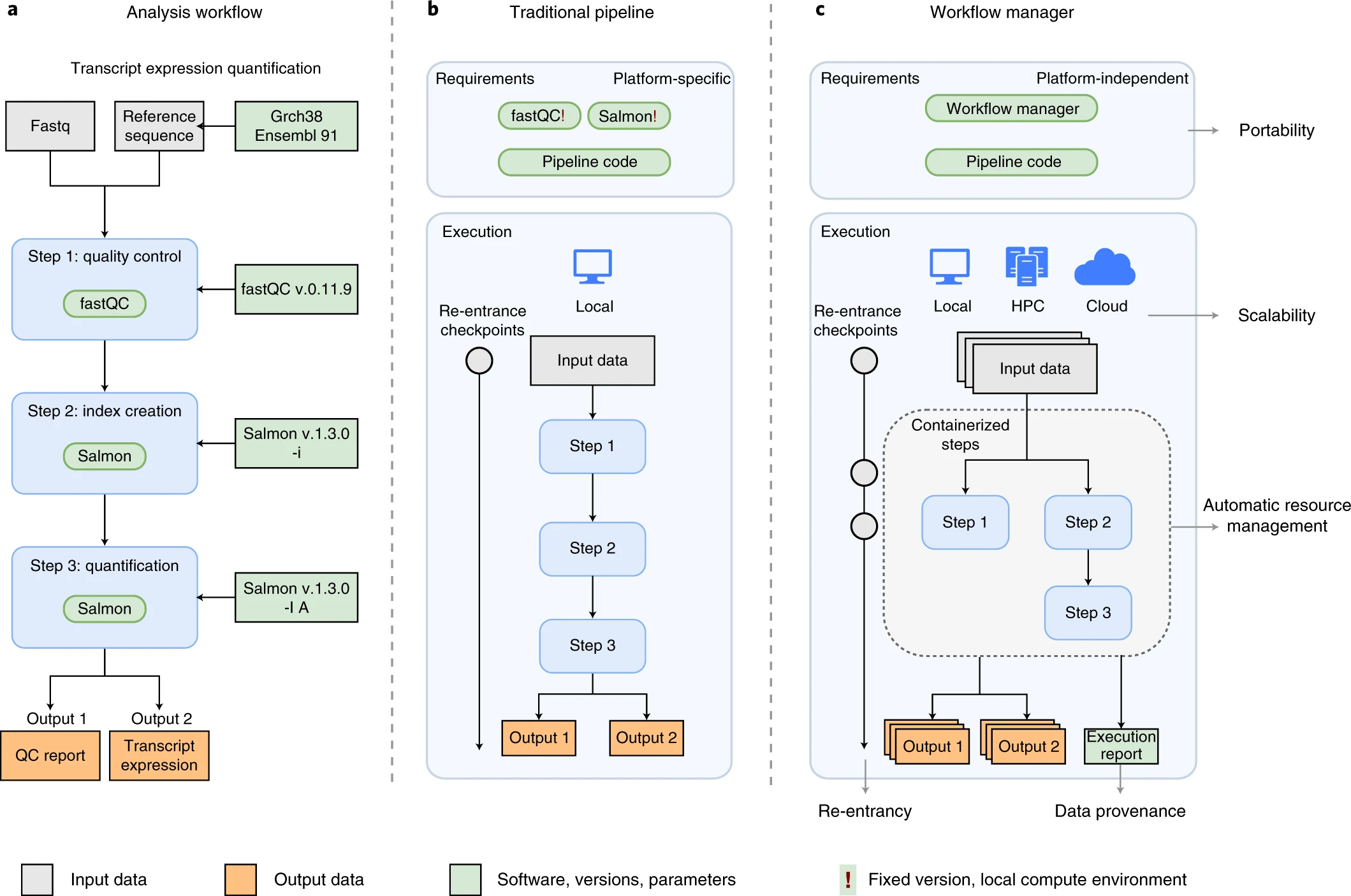
An example of differences between running a specific analysis workflow using a traditional pipeline or a WfMS-based pipeline. Source: Wratten, L., Wilm, A. & Göke, J. Reproducible, scalable, and shareable analysis pipelines with bioinformatics workflow managers. Nat Methods 18, 1161–1168 (2021). https://doi.org/10.1038/s41592-021-01254-9
Nextflow core features
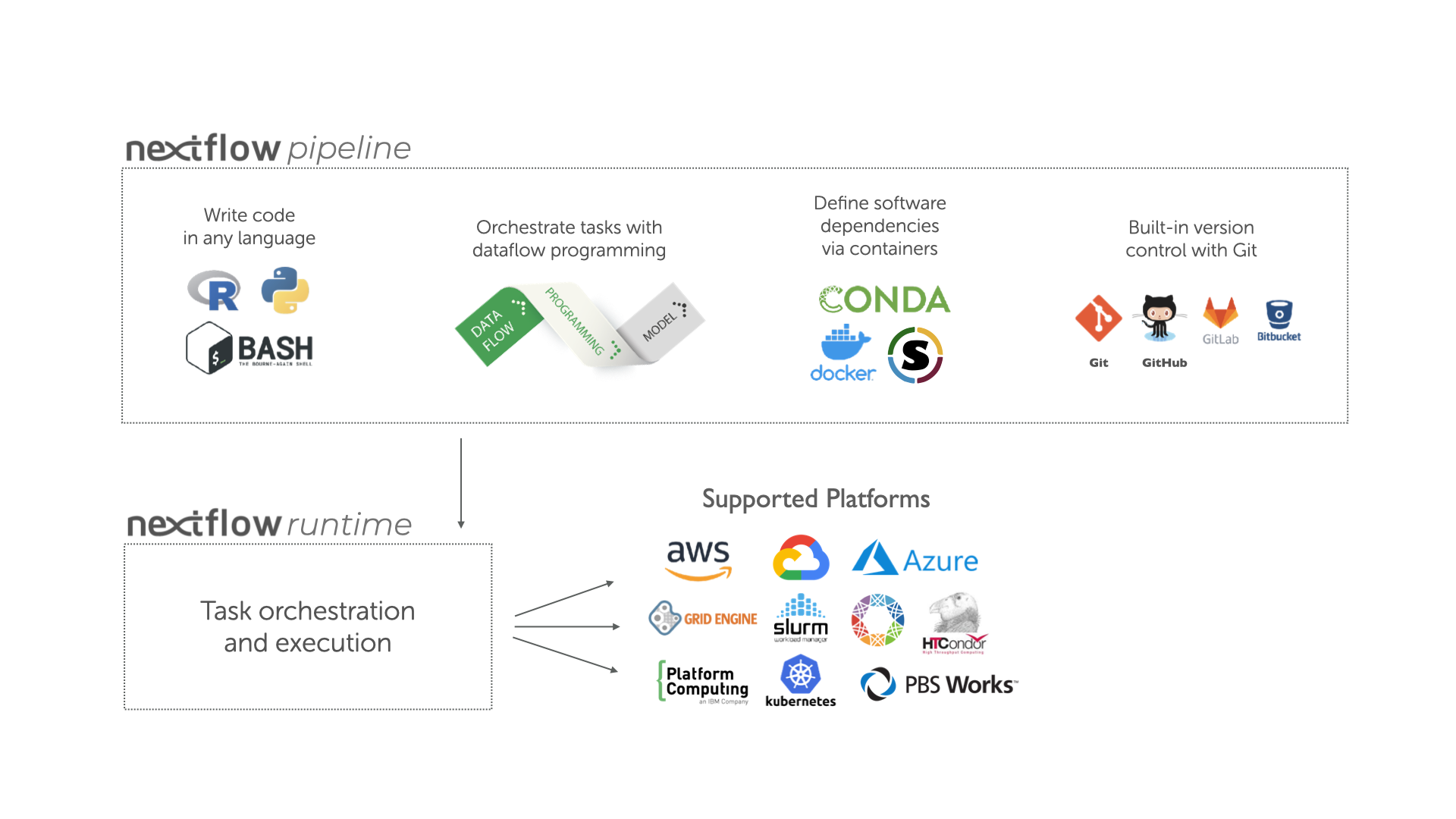
Overview of Nextflow core features.
Fast prototyping: A simple syntax for writing pipelines that enables you to reuse existing scripts and tools for fast prototyping.
Reproducibility: Nextflow supports several container technologies, such as Docker and Singularity, as well as the package manager Conda. This, along with the integration of the GitHub code sharing platform, allows you to write self-contained pipelines, manage versions and to reproduce any previous result when re-run, including on different computing platforms.
Portability & interoperability: Nextflow’s syntax separates the functional logic (the steps of the workflow) from the execution settings (how the workflow is executed). This allows the pipeline to be run on multiple platforms, e.g. local compute vs. a university compute cluster or a cloud service like AWS, without changing the steps of the workflow.
Simple parallelism: Nextflow is based on the dataflow programming model which greatly simplifies the splitting of tasks that can be run at the same time (parallelisation).
Continuous checkpoints & re-entrancy: All the intermediate results produced during the pipeline execution are automatically tracked. This allows you to resume its execution from the last successfully executed step, no matter what the reason was for it stopping.
Processes, channels, and workflows
Nextflow workflows have three main parts: processes, channels, and workflows.
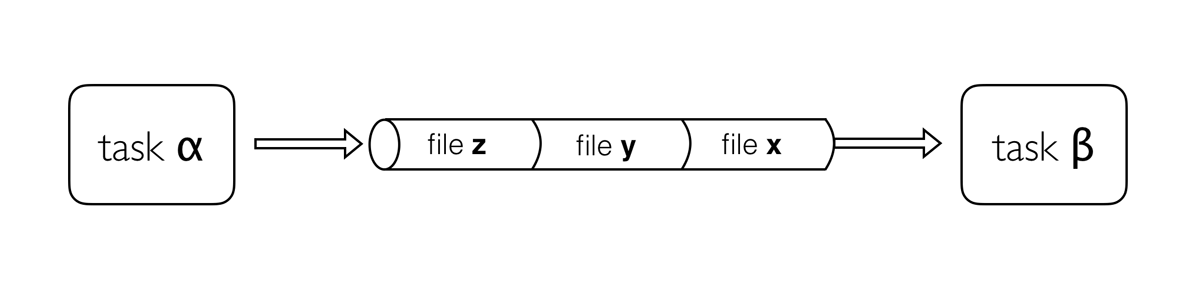
Processes describe a task to be run. A process script can be written in any scripting language that can be executed by the Linux platform (Bash, Perl, Ruby, Python, R, etc.). Processes spawn a task for each complete input set. Each task is executed independently and cannot interact with other tasks. The only way data can be passed between process tasks is via asynchronous queues, called channels.
Processes define inputs and outputs for a task. Channels are then used to manipulate the flow of data from one process to the next.
The interaction between processes, and ultimately the pipeline execution flow itself, is then explicitly defined in a workflow section.
In the following example we have a channel containing three elements, e.g., three data files. We have a process that takes the channel as input. Since the channel has three elements, three independent instances (tasks) of that process are run in parallel. Each task generates an output, which is passed to another channel and used as input for the next process.
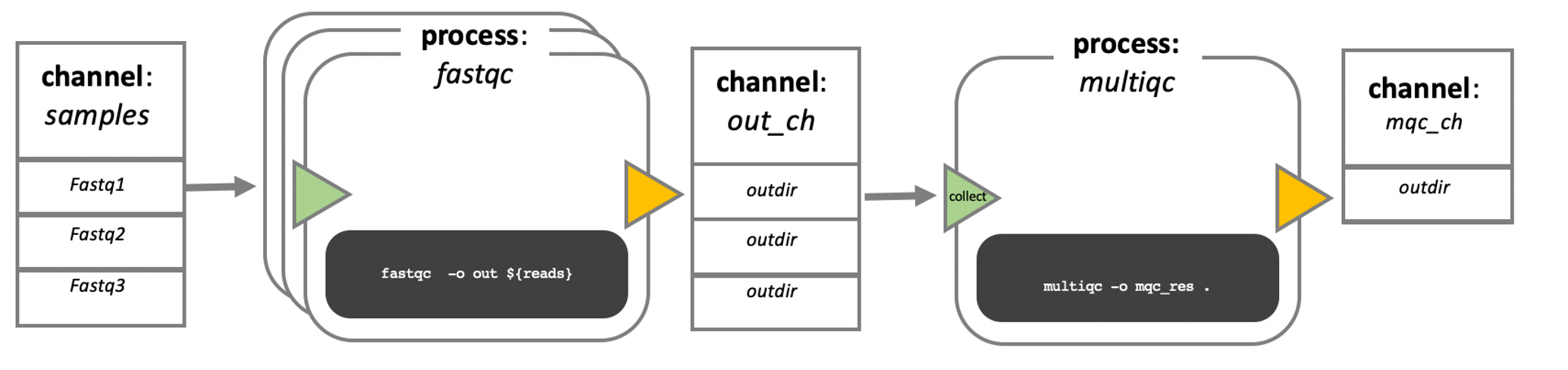
Nextflow process flow diagram.
Workflow execution
While a process defines what command or script has to be
executed, the executor determines how that script is
actually run in the target system.
If not otherwise specified, processes are executed on the local computer. The local executor is very useful for pipeline development, testing, and small-scale workflows, but for large-scale computational pipelines, a High Performance Cluster (HPC) or Cloud platform is often required.
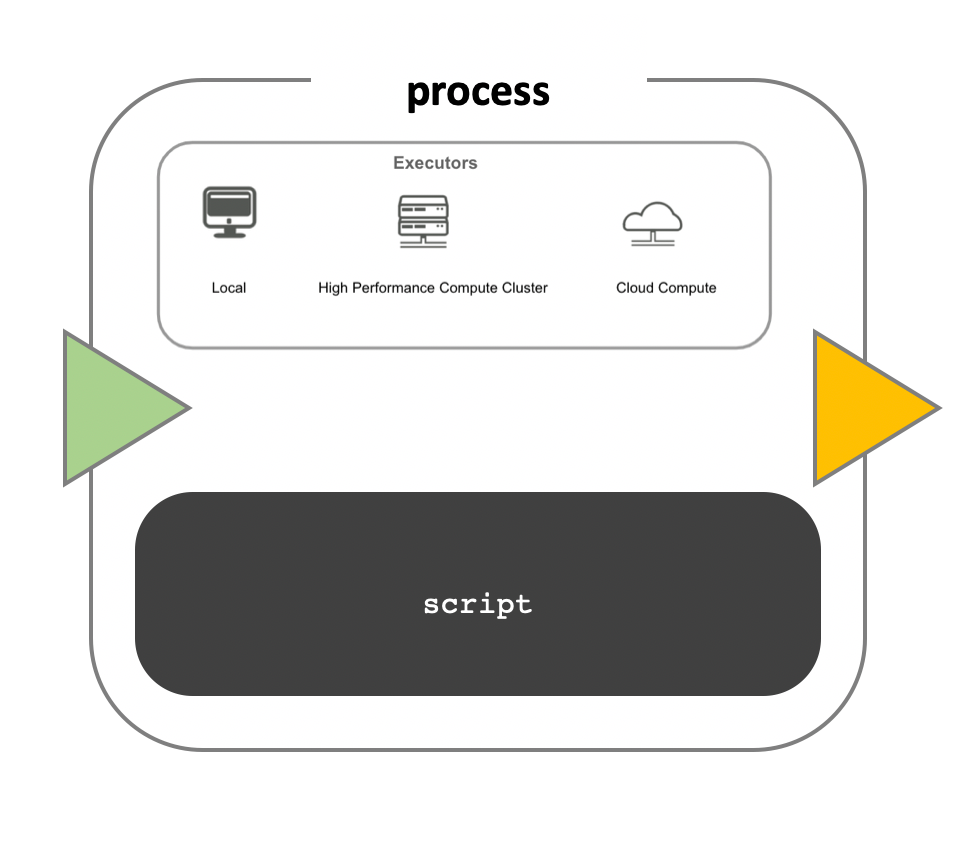
Nextflow Executors
Nextflow provides a separation between the pipeline’s functional logic and the underlying execution platform. This makes it possible to write a pipeline once, and then run it on your computer, compute cluster, or the cloud, without modifying the workflow, by defining the target execution platform in a configuration file.
Nextflow provides out-of-the-box support for major batch schedulers and cloud platforms such as Sun Grid Engine, SLURM job scheduler, AWS Batch service and Kubernetes; a full list can be found here.
Your first script
We are now going to look at a sample Nextflow script that counts the
number of lines in a file. Create the file word_count.nf in
the current directory using your favourite text editor and copy-paste
the following code:
GROOVY
#!/usr/bin/env nextflow
/*
========================================================================================
Workflow parameters are written as params.<parameter>
and can be initialised using the `=` operator.
========================================================================================
*/
params.input = "data/yeast/reads/ref1_1.fq.gz"
/*
========================================================================================
Input data is received through channels
========================================================================================
*/
input_ch = Channel.fromPath(params.input)
/*
========================================================================================
Main Workflow
========================================================================================
*/
workflow {
// The script to execute is called by it's process name, and input is provided between brackets.
NUM_LINES(input_ch)
/* Process output is accessed using the `out` channel.
The channel operator view() is used to print process output to the terminal. */
NUM_LINES.out.view()
}
/*
========================================================================================
A Nextflow process block. Process names are written, by convention, in uppercase.
This convention is used to enhance workflow readability.
========================================================================================
*/
process NUM_LINES {
input:
path read
output:
stdout
script:
"""
# Print file name
printf '${read}\\t'
# Unzip file and count number of lines
gunzip -c ${read} | wc -l
"""
}This is a Nextflow script, which contains the following:
- An optional interpreter directive (“Shebang”) line, specifying the location of the Nextflow interpreter.
- A multi-line Nextflow comment, written using C style block comments, there are more comments later in the file.
- A pipeline parameter
params.inputwhich is given a default value, of the relative path to the location of a compressed fastq file, as a string. - A Nextflow channel
input_chused to read in data to the workflow. - An unnamed
workflowexecution block, which is the default workflow to run. - A call to the process
NUM_LINES. - An operation on the process output, using the channel operator
.view(). - A Nextflow process block named
NUM_LINES, which defines what the process does. - An
inputdefinition block that assigns theinputto the variableread, and declares that it should be interpreted as a file path. - An
outputdefinition block that uses the Linux/Unix standard output streamstdoutfrom the script block. - A script block that contains the bash commands
printf '${read}'andgunzip -c ${read} | wc -l.
Running Nextflow scripts
To run a Nextflow script use the command
nextflow run <script_name>.
You should see output similar to the text shown below:
OUTPUT
N E X T F L O W ~ version 21.04.3
Launching `word_count.nf` [fervent_babbage] - revision: c54a707593
executor > local (1)
[21/b259be] process > NUM_LINES (1) [100%] 1 of 1 ✔
ref1_1.fq.gz 58708- The first line shows the Nextflow version number.
- The second line shows the run name
fervent_babbage(adjective and scientist name) and revision idc54a707593. - The third line tells you the process has been executed locally
(
executor > local). - The next line shows the process id
21/b259be, process name, number of cpus, percentage task completion, and how many instances of the process have been run. - The final line is the output of the
.view()operator.
Quick recap
- A workflow is a sequence of tasks that process a set of data, and a workflow management system (WfMS) is a computational platform that provides an infrastructure for the set-up, execution and monitoring of workflows.
- Nextflow scripts comprise of channels for controlling inputs and outputs, and processes for defining workflow tasks.
- You run a Nextflow script using the
nextflow runcommand.
Key Points
- A workflow is a sequence of tasks that process a set of data.
- A workflow management system (WfMS) is a computational platform that provides an infrastructure for the set-up, execution and monitoring of workflows.
- Nextflow is a workflow management system that comprises both a runtime environment and a domain specific language (DSL).
- Nextflow scripts comprise of channels for controlling inputs and outputs, and processes for defining workflow tasks.
- You run a Nextflow script using the
nextflow runcommand.
Content from Workflow parameterisation
Last updated on 2024-08-23 | Edit this page
Overview
Questions
- How can I change the data a workflow uses?
- How can I parameterise a workflow?
- How can I add my parameters to a file?
Objectives
- Use pipeline parameters to change the input to a workflow.
- Add a pipeline parameters to a Nextflow script.
- Understand how to create and use a parameter file.
In the first episode we ran the Nextflow script,
word_count.nf, from the command line and it counted the
number of lines in the file data/yeast/reads/ref1_1.fq.gz.
To change the input to script we can make use of pipeline
parameters.
Pipeline parameters
The Nextflow word_count.nf script defines a pipeline
parameter params.input. Pipeline parameters enable you to
change the input to the workflow at runtime, via the command line or a
configuration file, so they are not hard-coded into the script.
Pipeline parameters are declared in the workflow by prepending the
prefix params, separated by the dot character, to a
variable name e.g., params.input.
Their value can be specified on the command line by prefixing the
parameter name with a double dash character, e.g.,
--input.
In the script word_count.nf the pipeline parameter
params.input was specified with a value of
"data/yeast/reads/ref1_1.fq.gz".
To process a different file,
e.g. data/yeast/reads/ref2_2.fq.gz, in the
word_count.nf script we would run:
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `word_count.nf` [gigantic_woese] - revision: 8acb5cb9b0
executor > local (1)
[26/3cf986] process > NUM_LINES (1) [100%] 1 of 1 ✔
ref2_2.fq.gz 81720We can also use wild cards to specify multiple input files (This will
be covered in the channels episode). In the example below we use the
* to match any sequence of characters between
ref2_ and .fq.gz. Note: If
you use wild card characters on the command line you must enclose the
value in quotes.
This runs the process NUM_LINES twice, once for each file it matches.
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `word_count.nf` [tender_lumiere] - revision: 8acb5cb9b0
executor > local (2)
[cc/b6f793] process > NUM_LINES (1) [100%] 2 of 2 ✔
ref2_2.fq.gz 81720
ref2_1.fq.gz 81720Change a pipeline’s input using a parameter
Re-run the Nextflow script word_count.nf by changing the
pipeline input to all files in the directory
data/yeast/reads/ that begin with ref and end
with .fq.gz:
The string specified on the command line will override the default value of the parameter in the script. The output will look like this:
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `word_count.nf` [soggy_miescher] - revision: c54a707593
executor > local (6)
[d3/9ca185] process > NUM_LINES (2) [100%] 6 of 6 ✔
ref3_2.fq.gz 52592
ref2_2.fq.gz 81720
ref1_1.fq.gz 58708
ref1_2.fq.gz 58708
ref3_1.fq.gz 52592
ref2_1.fq.gz 81720Adding a parameter to a script
To add a pipeline parameter to a script prepend the prefix
params, separated by a dot character ., to a
variable name e.g., params.input.
Let’s make a copy of the word_count.nf script as
wc-params.nf and add a new input parameter.
To add a parameter sleep with the default value
2 to wc-params.nf we add the line:
Note: You should always add a sensible default value
to the pipeline parameter. We can use this parameter to add another step
to our NUM_LINES process.
This step, sleep ${params.sleep}, will add a delay for
the amount of time specified in the params.sleep variable,
by default 2 seconds. To access the value inside the script block we use
{variable_name} syntax
e.g. ${params.sleep}.
We can now change the sleep parameter from the command line, For Example:
Add a pipeline parameter
If you haven’t already make a copy of the word_count.nf
as wc-params.nf.
Add the param sleep with a default value of 2 below the
params.input line. Add the line
sleep ${params.sleep} in the process NUM_LINES
above the line printf ${read}.
Run the new script wc-params.nf changing the sleep input
time.
What input file would it run and why?
How would you get it to process all .fq.gz files in the
data/yeast/reads directory as well as changing the sleep
input to 1 second?
This would use 1 as a value of sleep parameter instead
of default value (which is 2) and run the pipeline. The input file would
be data/yeast/reads/ref1_1.fq.gz as this is the default. To
run all input files we could add the param
--input 'data/yeast/reads/*.fq.gz'
Parameter File
If we have many parameters to pass to a script it is best to create a
parameters file. Parameters can be stored in JSON format. JSON is a data
serialization language, that is a way of storing data objects and
structures, such as the params object in a file.
The -params-file option is used to pass the parameters
file to the script.
For example the file wc-params.json contains the
parameters sleep and input in JSON format.
Create a file called wc-params.json with the above
contents.
To run the wc-params.nf script using these parameters we
add the option -params-file and pass the file
wc-params.json:
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `wc-params.nf` [nostalgic_northcutt] - revision: 2f86c9ac7e
executor > local (2)
[b4/747eaa] process > NUM_LINES (1) [100%] 2 of 2 ✔
etoh60_1_2.fq.gz 87348
etoh60_1_1.fq.gz 87348Create and use a Parameter file.
Create a parameter file params.json for the Nextflow
file wc-params.nf, and run the Nextflow script using the
created parameter file, specifying:
- sleep as 10
- input as
data/yeast/reads/ref3_1.fq.gz
OUTPUT
N E X T F L O W
version 21.04.0 Launching `wc-params.nf` [small_wiles] - revision:
f5ef7b7a01 executor \> local (1) [f3/4fa480] process \> NUM_LINES
(1) [100%] 1 of 1 ✔ ref3_1.fq.gz 52592 Key Points
- Pipeline parameters are specified by prepending the prefix
paramsto a variable name, separated by dot character. - To specify a pipeline parameter on the command line for a Nextflow
run use
--variable_namesyntax. - You can add parameters to a JSON formatted file and pass them to the
script using option
-params-file.
Content from Channels
Last updated on 2024-08-23 | Edit this page
Overview
Questions
- How do I move data around in Nextflow?
- How do I handle different types of input, e.g. files and parameters?
- How do I create a Nextflow channel?
- How can I use pattern matching to select input files?
- How do I change the way inputs are handled?
Objectives
- Understand how Nextflow manages data using channels.
- Understand the different types of Nextflow channels.
- Create a value and queue channel using channel factory methods.
- Select files as input based on a glob pattern.
- Edit channel factory arguments to alter how data is read in.
Channels
Earlier we learnt that channels are the way in which Nextflow sends
data around a workflow. Channels connect processes via their inputs and
outputs. Channels can store multiple items, such as files (e.g., fastq
files) or values. The number of items a channel stores determines how
many times a process will run using that channel as input.
Note: When the process runs using one item from the input
channel, we will call that run a task.
Why use Channels?
Channels are how Nextflow handles file management, allowing complex tasks to be split up, run in parallel, and reduces ‘admin’ required to get the right inputs to the right parts of the pipeline.
Channels are asynchronous, which means that outputs from a set of processes will not necessarily be produced in the same order as the corresponding inputs went in. However, the first element into a channel queue is the first out of the queue (First in - First out). This allows processes to run as soon as they receive input from a channel. Channels only send data in one direction, from a producer (a process/operator), to a consumer (another process/operator).
Channel types
Nextflow distinguishes between two different kinds of channels: queue channels and value channels.
Queue channel
Queue channels are a type of channel in which data is consumed (used up) to make input for a process/operator. Queue channels can be created in two ways:
- As the outputs of a process.
- Explicitly using channel factory methods such as Channel.of or Channel.fromPath.
Value channels
The second type of Nextflow channel is a value channel.
A value channel is bound to a single
value. A value channel can be used an unlimited number times since its
content is not consumed. This is also useful for processes that need to
reuse input from a channel, for example, a reference genome sequence
file that is required by multiple steps within a process, or by more
than one process.
Queue vs Value Channel.
What type of channel would you use to store the following?
- Multiple values.
- A list with one or more values.
- A single value.
- A queue channels is used to store multiple values.
- A value channel is used to store a single value, this can be a list with multiple values.
- A value channel is used to store a single value.
Creating Channels using Channel factories
Channel factories are used to explicitly create channels. In
programming, factory methods (functions) are a programming design
pattern used to create different types of objects (in this case,
different types of channels). They are implemented for things that
represent more generalised concepts, such as a Channel.
Channel factories are called using the
Channel.<method> syntax, and return a specific
instance of a Channel.
The value Channel factory
The value factory method is used to create a value
channel. Values are put inside parentheses () to assign
them to a channel.
For example:
GROOVY
ch1 = Channel.value( 'GRCh38' )
ch2 = Channel.value( ['chr1', 'chr2', 'chr3', 'chr4', 'chr5'] )
ch3 = Channel.value( ['chr1' : 248956422, 'chr2' : 242193529, 'chr3' : 198295559] )- Creates a value channel and binds a string to it.
- Creates a value channel and binds a list object to it that will be emitted as a single item.
- Creates a value channel and binds a map object to it that will be emitted as a single item.
The value method can only take 1 argument, however, this can be a single list or map containing several elements.
Reminder:
- A List
object can be defined by placing the values in square brackets
[]separated by a comma. - A Map
object is similar, but with
key:value pairsseparated by commas.
To view the contents of a value channel, use the view
operator. We will learn more about channel operators in a later
episode.
GROOVY
ch1 = Channel.value( 'GRCh38' )
ch2 = Channel.value( ['chr1', 'chr2', 'chr3', 'chr4', 'chr5'] )
ch3 = Channel.value( ['chr1' : 248956422, 'chr2' : 242193529, 'chr3' : 198295559] )
ch1.view()
ch2.view()
ch3.view()Each item in the channel is printed on a separate line.
OUTPUT
GRCh38
[chr1, chr2, chr3, chr4, chr5]
[chr1:248956422, chr2:242193529, chr3:198295559]Queue channel factory
Queue (consumable) channels can be created using the following channel factory methods.
Channel.ofChannel.fromListChannel.fromPathChannel.fromFilePairsChannel.fromSRA
The of Channel factory
When you want to create a channel containing multiple values you can
use the channel factory Channel.of. Channel.of
allows the creation of a queue channel with the values
specified as arguments, separated by a ,.
OUTPUT
chr1
chr3
chr5
chr7The first line in this example creates a variable
chromosome_ch. chromosome_ch is a queue
channel containing the four values specified as arguments in the
of method. The view operator will print one
line per item in a list. Therefore the view operator on the
second line will print four lines, one for each element in the
channel:
You can specify a range of numbers as a single argument using the
Groovy range operator ... This creates each value in the
range (including the start and end values) as a value in the channel.
The Groovy range operator can also produce ranges of dates, letters, or
time. More information on the range operator can be found here.
Arguments passed to the of method can be of varying
types e.g., combinations of numbers, strings, or objects. In the above
examples we have examples of both string and number data types.
Channel.from
You may see the method Channel.from in older nextflow
scripts. This performs a similar function but is now deprecated (no
longer used), and so Channel.of should be used instead.
Create a value and Queue and view Channel contents
- Create a Nextflow script file called
channel.nf. - Create a Value channel
ch_vlcontaining the String'GRCh38'. - Create a Queue channel
ch_qucontaining the values 1 to 4. - Use
.view()operator on the channel objects to view the contents of the channels. - Run the code using
The fromList Channel factory
You can use the Channel.fromList method to create a
queue channel from a list object.
GROOVY
aligner_list = ['salmon', 'kallisto']
aligner_ch = Channel.fromList(aligner_list)
aligner_ch.view()This would produce two lines.
OUTPUT
salmon
kallistoChannel.fromList vs Channel.of
In the above example, the channel has two elements. If you has used
the Channel.of(aligner_list) it would have contained only 1 element
[salmon, kallisto] and any operator or process using the
channel would run once.
Creating channels from a list
Write a Nextflow script that creates both a queue and
value channel for the list
Then print the contents of the channels using the view
operator. How many lines does the queue and value channel print?
Hint: Use the fromList() and
value() Channel factory methods.
GROOVY
ids = ['ERR908507', 'ERR908506', 'ERR908505']
queue_ch = Channel.fromList(ids)
value_ch = Channel.value(ids)
queue_ch.view()
value_ch.view()OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `channel_fromList.nf` [wise_hodgkin] - revision: 22d76be151
ERR908507
ERR908506
ERR908505
[ERR908507, ERR908506, ERR908505]The queue channel queue_ch will print three lines.
The value channel value_ch will print one line.
The fromPath Channel factory
The previous channel factory methods dealt with sending general
values in a channel. A special channel factory method
fromPath is used when wanting to pass files.
The fromPath factory method creates a queue
channel containing one or more files matching a file path.
The file path (written as a quoted string) can be the location of a single file or a “glob pattern” that matches multiple files or directories.
The file path can be a relative path (path to the file from the
current directory), or an absolute path (path to the file from the
system root directory - starts with /).
The script below creates a queue channel with a single file as its content.
OUTPUT
data/yeast/reads/ref1_2.fq.gzYou can also use glob syntax to specify pattern-matching behaviour for files. A glob pattern is specified as a string and is matched against directory or file names.
- An asterisk,
*, matches any number of characters (including none). - Two asterisks,
**, works like * but will also search sub directories. This syntax is generally used for matching complete paths. - Braces
{}specify a collection of subpatterns. For example:{bam,bai}matches “bam” or “bai”
For example the script below uses the *.fq.gz pattern to
create a queue channel that contains as many items as there are files
with .fq.gz extension in the data/yeast/reads
folder.
OUTPUT
data/yeast/reads/ref1_2.fq.gz
data/yeast/reads/etoh60_3_2.fq.gz
data/yeast/reads/temp33_1_2.fq.gz
data/yeast/reads/temp33_2_1.fq.gz
data/yeast/reads/ref2_1.fq.gz
data/yeast/reads/temp33_3_1.fq.gz
[..truncated..]Note The pattern must contain at least a star wildcard character.
You can change the behaviour of Channel.fromPath method
by changing its options. A list of .fromPath options is
shown below.
Available fromPath options:
| Name | Description |
|---|---|
| glob | When true, the characters *, ?,
[] and {} are interpreted as glob wildcards,
otherwise they are treated as literal characters (default: true) |
| type | The type of file paths matched by the string, either
file, dir or any (default:
file) |
| hidden | When true, hidden files are included in the resulting paths (default: false) |
| maxDepth | Maximum number of directory levels to visit (default: no limit) |
| followLinks | When true, symbolic links are followed during directory tree traversal, otherwise they are managed as files (default: true) |
| relative | When true returned paths are relative to the top-most common directory (default: false) |
| checkIfExists | When true throws an exception if the specified path does not exist in the file system (default: false) |
We can change the default options for the fromPath
method to give an error if the file doesn’t exist using the
checkIfExists parameter. In Nextflow, method parameters are
separated by a , and parameter values specified with a
colon :.
If we execute a Nextflow script with the contents below, it will run and not produce an output, or an error message that the file does not exist. This is likely not what we want.
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `channels.nf` [scruffy_swartz] DSL2 - revision: 2c8f18ab48Add the argument checkIfExists with the value
true.
GROOVY
read_ch = Channel.fromPath( 'data/chicken/reads/*.fq.gz', checkIfExists: true )
read_ch.view()This will give an error as there is no data/chicken directory.
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `channels.nf` [intergalactic_mcclintock] - revision: d2c138894b
No files match pattern `*.fq.gz` at path: data/chicken/reads/Using Channel.fromPath
- Create a Nextflow script
channel_fromPath.nf - Use the
Channel.fromPathmethod to create a channel containing all files in thedata/yeast/directory, including the subdirectories. - Add the parameter to include any hidden files.
- Then print all file names using the
viewoperator.
Hint: You need two asterisks, i.e. **,
to search subdirectories.
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `channel_fromPath.nf` [reverent_mclean] - revision: cf02269bcb
data/yeast/samples.csv
data/yeast/reads/etoh60_3_2.fq.gz
data/yeast/reads/temp33_1_2.fq.gz
data/yeast/reads/temp33_2_1.fq.gz
[..truncated..]The fromFilePairs Channel factory
We have seen how to process files individually using
fromPath. In Bioinformatics we often want to process files
in pairs or larger groups, such as read pairs in sequencing.
For example is the data/yeast/reads directory we have
nine groups of read pairs.
| Sample group | read1 | read2 |
|---|---|---|
| ref1 | data/yeast/reads/ref1_1.fq.gz | data/yeast/reads/ref1_2.fq.gz |
| ref2 | data/yeast/reads/ref2_1.fq.gz | data/yeast/reads/ref2_2.fq.gz |
| ref3 | data/yeast/reads/ref3_1.fq.gz | data/yeast/reads/ref3_2.fq.gz |
| temp33_1 | data/yeast/reads/temp33_1_1.fq.gz | data/yeast/reads/temp33_1_2.fq.gz |
| temp33_2 | data/yeast/reads/temp33_2_1.fq.gz | data/yeast/reads/temp33_2_2.fq.gz |
| temp33_3 | data/yeast/reads/temp33_3_1.fq.gz | data/yeast/reads/temp33_3_2.fq.gz |
| etoh60_1 | data/yeast/reads/etoh60_1_1.fq.gz | data/yeast/reads/etoh60_1_2.fq.gz |
| etoh60_2 | data/yeast/reads/etoh60_2_1.fq.gz | data/yeast/reads/etoh60_2_2.fq.gz |
| etoh60_3 | data/yeast/reads/etoh60_3_1.fq.gz | data/yeast/reads/etoh60_3_2.fq.gz |
Nextflow provides a convenient Channel factory method for this common
bioinformatics use case. The fromFilePairs method creates a
queue channel containing a tuple for every set of files
matching a specific glob pattern (e.g.,
/path/to/*_{1,2}.fq.gz).
A tuple is a grouping of data, represented as a Groovy
List.
- The first element of the tuple emitted from
fromFilePairsis a string based on the shared part of the filenames (i.e., the*part of the glob pattern). - The second element is the list of files matching the remaining part
of the glob pattern (i.e., the
<string>_{1,2}.fq.gzpattern). This will include any files ending_1.fq.gzor_2.fq.gz.
OUTPUT
[etoh60_3, [data/yeast/reads/etoh60_3_1.fq.gz, data/yeast/reads/etoh60_3_2.fq.gz]]
[temp33_1, [data/yeast/reads/temp33_1_1.fq.gz, data/yeast/reads/temp33_1_2.fq.gz]]
[ref1, [data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz]]
[ref2, [data/yeast/reads/ref2_1.fq.gz, data/yeast/reads/ref2_2.fq.gz]]
[temp33_2, [data/yeast/reads/temp33_2_1.fq.gz, data/yeast/reads/temp33_2_2.fq.gz]]
[ref3, [data/yeast/reads/ref3_1.fq.gz, data/yeast/reads/ref3_2.fq.gz]]
[temp33_3, [data/yeast/reads/temp33_3_1.fq.gz, data/yeast/reads/temp33_3_2.fq.gz]]
[etoh60_1, [data/yeast/reads/etoh60_1_1.fq.gz, data/yeast/reads/etoh60_1_2.fq.gz]]
[etoh60_2, [data/yeast/reads/etoh60_2_1.fq.gz, data/yeast/reads/etoh60_2_2.fq.gz]]This will produce a queue channel, read_pair_ch ,
containing nine elements.
Each element is a tuple that has;
- string value (the file prefix matched, e.g
temp33_1) - and a list with the two files e,g.
[data/yeast/reads/temp33_1_1.fq.gz, data/yeast/reads/temp33_1_2.fq.gz].
The asterisk character *, matches any number of
characters (including none), and the {} braces specify a
collection of subpatterns. Therefore the *_{1,2}.fq.gz
pattern matches any file name ending in _1.fq.gz or
_2.fq.gz .
What if you want to capture more than a pair?
If you want to capture more than two files for a pattern you will
need to change the default size argument (the default value
is 2) to the number of expected matching files.
For example in the directory data/yeast/reads there are
six files with the prefix ref. If we want to group (create
a tuple) for all of these files we could write;
GROOVY
read_group_ch = Channel.fromFilePairs('data/yeast/reads/ref{1,2,3}*',size:6)
read_group_ch.view()The code above will create a queue channel containing one element. The element is a tuple of which contains a string value, that is the pattern ref, and a list of six files matching the pattern.
OUTPUT
[ref, [data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz, data/yeast/reads/ref2_1.fq.gz, data/yeast/reads/ref2_2.fq.gz, data/yeast/reads/ref3_1.fq.gz, data/yeast/reads/ref3_2.fq.gz]]See more information about the channel factory
fromFilePairs here
More complex patterns
If you need to match more complex patterns you should create a sample sheet specifying the files and create a channel from that. This will be covered in the operator episode.
Create a channel containing groups of files
- Create a Nextflow script file
channel_fromFilePairs.nf. - Use the
fromFilePairsmethod to create a channel containing three tuples. Each tuple will contain the pairs of fastq reads for the three temp33 samples in thedata/yeast/readsdirectory
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `channels.nf` [stupefied_lumiere] - revision: a3741edde2
[temp33_1, [data/yeast/reads/temp33_1_1.fq.gz, data/yeast/reads/temp33_1_2.fq.gz]]
[temp33_3, [data/yeast/reads/temp33_3_1.fq.gz, data/yeast/reads/temp33_3_2.fq.gz]]
[temp33_2, [data/yeast/reads/temp33_2_1.fq.gz, data/yeast/reads/temp33_2_2.fq.gz]]Key Points
- Channels must be used to import data into Nextflow.
- Nextflow has two different kinds of channels: queue channels and value channels.
- Data in value channels can be used multiple times in workflow.
- Data in queue channels are consumed when they are used by a process or an operator.
- Channel factory methods, such as
Channel.of, are used to create channels. - Channel factory methods have optional parameters e.g.,
checkIfExists, that can be used to alter the creation and behaviour of a channel.
Content from Processes
Last updated on 2024-08-23 | Edit this page
Overview
Questions
- How do I run tasks/processes in Nextflow?
- How do I get data, files and values, into a processes?
Objectives
- Understand how Nextflow uses processes to execute tasks.
- Create a Nextflow process.
- Define inputs to a process.
Processes
We now know how to create and use Channels to send data around a workflow. We will now see how to run tasks within a workflow using processes.
A process is the way Nextflow executes commands you
would run on the command line or custom scripts.
A process can be thought of as a particular step in a workflow, e.g. an alignment step in RNA-seq analysis. Processes are independent of each other (don’t require any another process to execute) and can not communicate/write to each other. Data is passed between processes via input and output Channels.
For example, below is the command you would run to count the number of sequence records in a FASTA format file such as the yeast transcriptome:
FASTA format
FASTA format is a text-based format for representing either nucleotide sequences or peptide sequences. A sequence in FASTA format begins with a single-line description, followed by lines of sequence data. The description line is distinguished from the sequence data by a greater-than (“>”) symbol in the first column.
BASH
>YBR024W_mRNA cdna chromosome:R64-1-1:II:289445:290350:1 gene:YBR024W gene_biotype:protein_coding transcript_biotype:protein_coding gene_symbol:SCO2 description:Protein anchored to mitochondrial inner membrane; may have a redundant function with Sco1p in delivery of copper to cytochrome c oxidase; interacts with Cox2p; SCO2 has a paralog, SCO1, that arose from the whole genome duplication [Source:SGD;Acc:S000000228]
ATGTTGAATAGTTCAAGAAAATATGCTTGTCGTTCCCTATTCAGACAAGCGAACGTCTCA
ATAAAAGGACTCTTTTATAATGGAGGCGCATATCGAAGAGGGTTTTCAACGGGATGTTGTzgrep -c ‘^>’
The command
zgrep -c '^>' data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
is used in Unix-like systems for a specific purpose: it counts the
number of sequences in a compressed FASTA file. The tool
zgrep combines the functionalities of ‘grep’ for pattern
searching and ‘gzip’ for handling compressed files. The -c
option modifies this command to count the occurrences of lines matching
the pattern, instead of displaying them. The pattern
'^>' is designed to find lines that start with ‘>’,
which in FASTA files, denotes the beginning of a new sequence. Thus,
this command efficiently counts how many sequences are contained within
the specified compressed FASTA file.
OUTPUT
6612Now we will show how to convert this into a simple Nextflow process.
Process definition
The process definition starts with keyword process,
followed by process name, in this case NUMSEQ, and finally
the process body delimited by curly brackets
{}. The process body must contain a string which represents
the command or, more generally, a script that is executed by it.
GROOVY
process NUMSEQ {
script:
"zgrep -c '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
}This process would run once.
Implicit variables
We use the Nextflow implicit variable ${projectDir} to
specify the directory where the main script is located. This is
important as Nextflow scripts are executed in a separate working
directory. A full list of implicit variables can be found here
To add the process to a workflow add a workflow block,
and call the process like a function. We will learn more about the
workflow block in the workflow episode.
GROOVY
//process_01.nf
process NUMSEQ {
script:
"zgrep -c '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
}
workflow {
//process is called like a function in the workflow block
NUMSEQ()
}We can now run the process:
Note We need to add the Nextflow run option
-process.debug to print the output to the terminal.
OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `process_01.nf` [modest_pike] - revision: 3eaa812b17
executor > local (1)
[cd/eab1fd] process > NUMSEQ [100%] 1 of 1 ✔
6612GROOVY
process COUNT_BASES {
script:
"""
zgrep -v '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz|tr -d '\n'|wc -m
"""
}
workflow {
COUNT_BASES()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `simple_process.nf`` [prickly_gilbert] - revision: 471a79c65c
executor > local (1)
[56/5e6001] process > COUNT_BASES [100%] 1 of 1 ✔
8772368Definition blocks
The previous example was a simple process with no
defined inputs and outputs that ran only once. To control inputs,
outputs and how a command is executed a process may contain five
definition blocks:
- directives - 0, 1, or more: allow the definition of optional settings that affect the execution of the current process e.g. the number of cpus a task uses and the amount of memory allocated.
- inputs - 0, 1, or more: Define the input dependencies, usually channels, which determines the number of times a process is executed.
- outputs - 0, 1, or more: Defines the output channels used by the process to send results/data produced by the process.
- when clause - optional: Allows you to define a condition that must be verified in order to execute the process.
- script block - required: A statement within quotes that defines the commands that are executed by the process to carry out its task.
The syntax is defined as follows:
Script
At minimum a process block must contain a script
block.
The script block is a String “statement” that defines
the command that is executed by the process to carry out its task. These
are normally the commands you would run on a terminal.
A process contains only one script block, and it must be
the last statement when the process contains input and
output declarations.
The script block can be a simple one line string in
quotes e.g.
GROOVY
process NUMSEQ {
script:
"zgrep -c '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
}
workflow {
NUMSEQ()
}Or, for commands that span multiple lines you can encase the command
in triple quotes """.
For example:
GROOVY
//process_multi_line.nf
process NUMSEQ_CHR {
script:
"""
zgrep '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz > ids.txt
zgrep -c '>YA' ids.txt
"""
}
workflow {
NUMSEQ_CHR()
}OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `process_multi_line.nf` [focused_jang] - revision: e32caf0dcb
executor > local (1)
[90/6e38f4] process > NUMSEQ_CHR [100%] 1 of 1 ✔
118By default the process command is interpreted as a Bash script. However, any other scripting language can be used just simply starting the script with the corresponding Shebang declaration. For example:
GROOVY
//process_python.nf
process PROCESS_READS {
script:
"""
#!/usr/bin/env python
import gzip
reads = 0
bases = 0
with gzip.open('${projectDir}/data/yeast/reads/ref1_1.fq.gz', 'rb') as read:
for id in read:
seq = next(read)
reads += 1
bases += len(seq.strip())
next(read)
next(read)
print("reads", reads)
print("bases", bases)
"""
}
workflow {
PROCESS_READS()
}OUTPUT
N E X T F L O W ~ version 24.04.4
Launching `process_python.nf` [mad_montalcini] DSL2 - revision: ee25d49465
executor > local (1)
[b4/a100c3] PROCESS_READS [100%] 1 of 1 ✔
reads 14677
bases 1482377This allows the use of a different programming languages which may better fit a particular job. However, for large chunks of code it is suggested to save them into separate files and invoke them from the process script.
Associated scripts
Scripts such as the one in the example below,
process_reads.py, can be stored in a bin
folder at the same directory level as the Nextflow workflow script that
invokes them, and given execute permission. Nextflow will automatically
add this folder to the PATH environment variable. To invoke
the script in a Nextflow process, simply use its filename on its own
rather than invoking the interpreter e.g. process_reads.py
instead of python process_reads.py. Note
The script process_reads.py must be executable to run.
PYTHON
#!/usr/bin/env python
# process_reads.py
import gzip
import sys
reads = 0
bases = 0
with gzip.open(sys.argv[1], 'rb') as read:
for id in read:
seq = next(read)
reads += 1
bases += len(seq.strip())
next(read)
next(read)
print("reads", reads)
print("bases", bases)GROOVY
//process_python_script.nf
process PROCESS_READS {
script:
"""
process_reads.py ${projectDir}/data/yeast/reads/ref1_1.fq.gz
"""
}
workflow {
PROCESS_READS()
}OUTPUT
N E X T F L O W ~ version 23.10.1
Launching `pr.nf` [kickass_legentil] DSL2 - revision: 3b9eee1d47
executor > local (1)
[88/759311] process > PROCESS_READS [100%] 1 of 1 ✔
reads 14677
bases 1482377Associated scripts
Scripts such as the one in the example above,
process_reads.py, can be stored in a bin
folder at the same directory level as the Nextflow workflow script that
invokes them, and given execute permission. Nextflow will automatically
add this folder to the PATH environment variable. To invoke
the script in a Nextflow process, simply use its filename on its own
rather than invoking the interpreter e.g. process_reads.py
instead of python process_reads.py.
Script parameters
The command in the script block can be defined
dynamically using Nextflow variables e.g. ${projectDir}. To
reference a variable in the script block you can use the $
in front of the Nextflow variable name, and additionally you can add
{} around the variable name
e.g. ${projectDir}.
Variable substitutions
Similar to bash scripting Nextflow uses the $ character
to introduce variable substitutions. The variable name to be expanded
may be enclosed in braces {variable_name}, which are
optional but serve to protect the variable to be expanded from
characters immediately following it which could be interpreted as part
of the name. It is a good rule of thumb to always use the
{} syntax because it enhances readability and clarity,
ensures correct variable interpretation, and prevents potential syntax
errors in complex expressions.
In the example below the variable chr is set to the
value A at the top of the Nextflow script. The variable is referenced
using the $chr syntax within the multi-line string
statement in the script block. A Nextflow variable can be
used multiple times in the script block.
GROOVY
//process_script.nf
chr = "A"
process CHR_COUNT {
script:
"""
printf "Number of sequences for chromosome ${chr} :"
zgrep -c '>Y'${chr} ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
"""
}
workflow {
CHR_COUNT()
}In most cases we do not want to hard code parameter values. We saw in
the parameter episode the use of a special Nextflow variable
params that can be used to assign values from the command
line. You would do this by adding a key name to the params variable and
specifying a value, like params.keyname = value
In the example below we define the variable params.chr
with a default value of A in the Nextflow script.
GROOVY
//process_script_params.nf
params.chr = "A"
process CHR_COUNT {
script:
"""
printf 'Number of sequences for chromosome '${params.chr}':'
zgrep -c '^>Y'${params.chr} ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
"""
}
workflow {
CHR_COUNT()
}Remember, we can change the default value of chr to a
different value such as B, by running the Nextflow script
using the command below. Note: parameters to the
workflow have two hyphens --.
OUTPUT
N E X T F L O W ~ version 24.04.3
Launching `process_script_params.nf` [pedantic_mandelbrot] DSL2 - revision: 538e3c2b38
executor > local (1)
[19/6d96a0] process > CHR_COUNT [100%] 1 of 1 ✔
Number of sequences for chromosome B:456Script parameters
For the Nextflow script below.
GROOVY
//process_exercise_script_params.nf
process COUNT_BASES {
script:
"""
zgrep -v '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz|grep -o A|wc -l
"""
}
workflow {
COUNT_BASES()
}Add a parameter params.base to the script and uses the
variable ${param.base} insides the script. Run the pipeline
using a base value of C using the --base
command line option.
Note: The Nextflow option
-process.debug will print the process’ stdout to the
terminal.
GROOVY
//process_exercise_script_params.nf
params.base='A'
process COUNT_BASES {
script:
"""
zgrep -v '^>' ${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz|grep -o ${params.base}|wc -l
"""
}
workflow {
COUNT_BASES()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_script_params.nf ` [nostalgic_jones] - revision: 9feb8de4fe
executor > local (1)
[92/cdc9de] process > COUNT_BASES [100%] 1 of 1 ✔
1677188Bash variables
Nextflow uses the same Bash syntax for variable substitutions,
$variable, in strings. However, Bash variables need to be
escaped using \ character in front of
\$variable name.
In the example below we will set a bash variable NUMIDS
then echo the value of NUMIDS in our script block.
GROOVY
//process_escape_bash.nf
process NUM_IDS {
script:
"""
#set bash variable NUMIDS
NUMIDS=`zgrep -c '^>' $params.transcriptome`
echo 'Number of sequences'
printf "%'d\n" \$NUMIDS
"""
}
params.transcriptome = "${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
workflow {
NUM_IDS()
}Shell
Another alternative is to use a shell block definition
instead of script. When using the shell
statement Bash variables are referenced in the normal way
$my_bash_variable; However, the shell
statement uses a different syntax for Nextflow variable substitutions:
!{nextflow_variable}, which is needed to use both Nextflow
and Bash variables in the same script.
For example in the script below that uses the shell
statement we reference the Nextflow variables as
!{projectDir} , and the Bash variable as
${NUMCHAR} and ${NUMLINES}.
GROOVY
//process_shell.nf
process NUM_IDS {
shell:
//Shell script definition requires the use of single-quote ' delimited strings
'''
#set bash variable NUMIDS
NUMIDS=`zgrep -c '^>' !{params.transcriptome}`
echo 'Number of sequences'
printf $NUMIDS
'''
}
params.transcriptome = "${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
workflow {
NUM_IDS()
}Conditional script execution
Sometimes you want to change how a process is run depending on some
condition. In Nextflow scripts we can use conditional statements such as
the if statement or any other expression evaluating to
boolean value true or false.
If statement
The if statement uses the same syntax common to other
programming languages such Java, C, JavaScript, etc.
GROOVY
if( < boolean expression > ) {
// true branch
}
else if ( < boolean expression > ) {
// true branch
}
else {
// false branch
}For example, the Nextflow script below will use the if
statement to change what the COUNT process counts depending on the
Nextflow variable params.method.
GROOVY
//process_conditional.nf
params.method = 'ids'
params.transcriptome = "$projectDir/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process COUNT {
script:
if( params.method == 'ids' ) {
"""
echo Number of sequences in transciptome
zgrep -c "^>" $params.transcriptome
"""
}
else if( params.method == 'bases' ) {
"""
echo Number of bases in transciptome
zgrep -v "^>" $params.transcriptome|grep -o "."|wc -l
"""
}
else {
"""
echo Unknown method $params.method
"""
}
}
workflow {
COUNT()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `juggle_processes.nf` [cheeky_shirley] - revision: 588f20ae5a
[01/60b08d] process > COUNT [100%] 1 of 1 ✔
Number of sequences in transciptome
6612Inputs
Processes are isolated from each other but can communicate by sending
values and files via Nextflow channels from input and into
output blocks.
The input block defines which channels the process is
expecting to receive input from. The number of elements in input
channels determines the process dependencies and the number of times a
process executes.
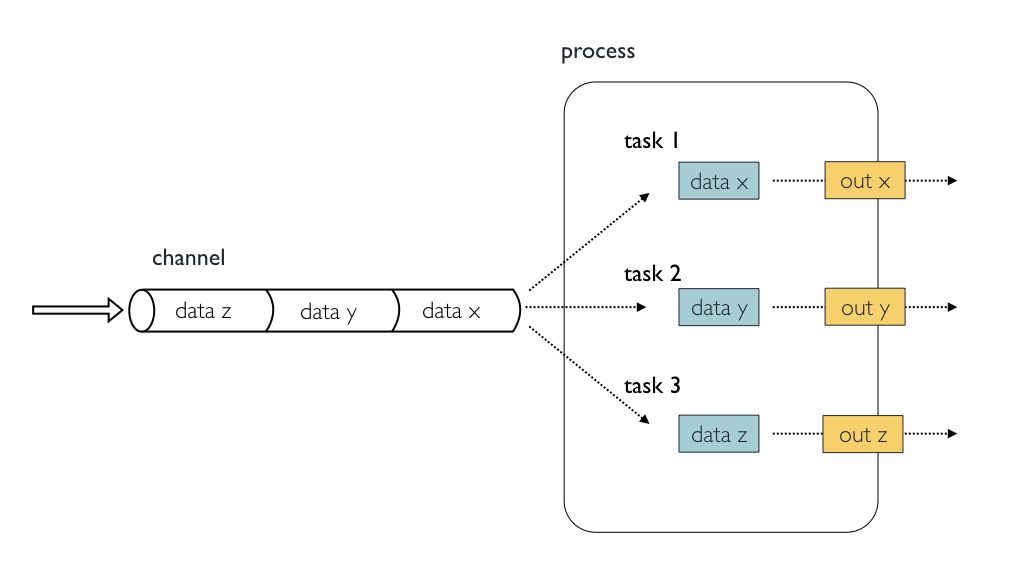
You can only define one input block at a time and it must contain one or more input declarations.
The input block follows the syntax shown below:
The input qualifier declares the type of data to be received.
Input qualifiers
-
val: Lets you access the received input value by its name as a variable in the process script. -
env: Lets you use the input value to set an environment variable named as the specified input name. -
path: Lets you handle the received value as a file, staging the file properly in the execution context. -
stdin: Lets you forward the received value to the process stdin special file. -
tuple: Lets you handle a group of input values having one of the above qualifiers. -
each: Lets you execute the process for each entry in the input collection. A complete list of inputs can be found here.
Input values
The val qualifier allows you to receive value data as
input. It can be accessed in the process script by using the specified
input name, as shown in the following example:
GROOVY
//process_input_value.nf
process PRINTCHR {
input:
val chr
script:
"""
echo processing chromosome $chr
"""
}
chr_ch = Channel.of( 'A' .. 'P' )
workflow {
PRINTCHR(chr_ch)
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_input_value.nf` [wise_kalman] - revision: 7f90e1bfc5
executor > local (24)
[b1/88df3f] process > PRINTCHR (16) [100%] 24 of 24 ✔
processing chromosome C
processing chromosome L
processing chromosome A
..truncated...In the above example the process is executed 16 times; each time a
value is received from the queue channel chr_ch it is used
to run the process.
Channel order
The channel guarantees that items are delivered in the same order as they have been sent, but since the process is executed in a parallel manner, there is no guarantee that they are processed in the same order as they are received.
Input files
When you need to handle files as input, you need the
path qualifier. Using the path qualifier means
that Nextflow will stage it in the process execution directory, and it
can be accessed in the script by using the name specified in the input
declaration.
The input file name can be defined dynamically by defining the input
name as a Nextflow variable and referenced in the script using the
$variable_name syntax.
For example, in the script below, we assign the variable name
read to the input files using the path
qualifier. The file is referenced using the variable substitution syntax
${read} in the script block:
GROOVY
//process_input_file.nf
process NUMLINES {
input:
path read
script:
"""
printf '${read} '
gunzip -c ${read} | wc -l
"""
}
reads_ch = Channel.fromPath( 'data/yeast/reads/ref*.fq.gz' )
workflow {
NUMLINES(reads_ch)
}OUTPUT
[cd/77af6d] process > NUMLINES (1) [100%] 6 of 6 ✔
ref1_1.fq.gz 58708
ref3_2.fq.gz 52592
ref2_2.fq.gz 81720
ref2_1.fq.gz 81720
ref3_1.fq.gz 52592
ref1_2.fq.gz 58708Callout
The input name can also be defined as a user-specified filename
inside quotes. For example, in the script below, the name of the file is
specified as 'sample.fq.gz' in the input definition and can
be referenced by that name in the script block.
GROOVY
//process_input_file_02.nf
process NUMLINES {
input:
path 'sample.fq.gz'
script:
"""
printf 'sample.fq.gz '
gunzip -c sample.fq.gz | wc -l
"""
}
reads_ch = Channel.fromPath( 'data/yeast/reads/ref*.fq.gz' )
workflow {
NUMLINES(reads_ch)
}OUTPUT
[d2/eb0e9d] process > NUMLINES (1) [100%] 6 of 6 ✔
sample.fq.gz 58708
sample.fq.gz 52592
sample.fq.gz 81720
sample.fq.gz 81720
sample.fq.gz 52592
sample.fq.gz 58708File Objects as inputs
When a process declares an input file, the corresponding channel
elements must be file objects, i.e. created with the path helper
function from the file specific channel factories,
e.g. Channel.fromPath or
Channel.fromFilePairs.
Add input channel
For the script process_exercise_input.nf:
- Define a Channel using
fromPathfor the transcriptomeparams.transcriptome.
- Add an input channel that takes the transcriptome channel as a file input.
- Replace
params.transcriptomein thescript:block with the input variable you defined in theinput:definition.
GROOVY
//process_exercise_input.nf
params.chr = "A"
params.transcriptome = "${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process CHR_COUNT {
script:
"""
printf 'Number of sequences for chromosome '${params.chr}':'
zgrep -c '^>Y'${params.chr} ${params.transcriptome}
"""
}
workflow {
CHR_COUNT()
}Then run your script using
GROOVY
params.chr = "A"
params.transcriptome = "${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process CHR_COUNT {
input:
path transcriptome
script:
"""
printf 'Number of sequences for chromosome '${params.chr}':'
zgrep -c '^>Y'${params.chr} ${transcriptome}
"""
}
transcriptome_ch = channel.fromPath(params.transcriptome)
workflow {
CHR_COUNT(transcriptome_ch)
}OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `process_exercise_input.nf` [focused_jang] - revision: e32caf0dcb
executor > local (1)
[00/14ce67] process > CHR_COUNT (1) [100%] 1 of 1 ✔
Number of sequences for chromosome A:118Combining input channels
A key feature of processes is the ability to handle inputs from multiple channels. However, it’s important to understand how the number of items within the multiple channels affect the execution of a process.
Consider the following example:
GROOVY
//process_combine.nf
process COMBINE {
input:
val x
val y
script:
"""
echo $x and $y
"""
}
num_ch = Channel.of(1, 2, 3)
letters_ch = Channel.of('a', 'b', 'c')
workflow {
COMBINE(num_ch, letters_ch)
}Both channels contain three elements, therefore the process is executed three times, each time with a different pair:
OUTPUT
2 and b
1 and a
3 and cWhat is happening is that the process waits until it receives an input value from all the queue channels declared as input.
When this condition is verified, it uses up the input values coming from the respective queue channels, runs the task. This logic repeats until one or more queue channels have no more content. The process then stops.
What happens when not all channels have the same number of elements?
For example:
GROOVY
//process_combine_02.nf
process COMBINE {
input:
val x
val y
script:
"""
echo $x and $y
"""
}
ch_num = Channel.of(1, 2)
ch_letters = Channel.of('a', 'b', 'c', 'd')
workflow {
COMBINE(ch_num, ch_letters)
}In the above example the process is executed only two times, because when a queue channel has no more data to be processed it stops the process execution.
OUTPUT
2 and b
1 and aValue channels and process termination
Note however that value channels,
Channel.value, do not affect the process termination.
To better understand this behaviour compare the previous example with the following one:
GROOVY
//process_combine_03.nf
process COMBINE {
input:
val x
val y
script:
"""
echo $x and $y
"""
}
ch_num = Channel.value(1)
ch_letters = Channel.of('a', 'b', 'c')
workflow {
COMBINE(ch_num, ch_letters)
}In this example the process is run three times.
OUTPUT
1 and b
1 and a
1 and cCombining input channels
GROOVY
// process_exercise_combine_answer.nf
process COMBINE {
input:
path transcriptome
val chr
script:
"""
zgrep -c ">Y${chr}" ${transcriptome}
"""
}
transcriptome_ch = channel.fromPath('data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz', checkIfExists: true)
chr_ch = channel.of("A")
workflow {
COMBINE(transcriptome_ch, chr_ch)
}OUTPUT
N E X T F L O W ~ version 24.04.4
Launching `process_exercise_combine.nf` [fabulous_kare] DSL2 - revision: 1eade0a2e9
executor > local (1)
[e0/b05fe7] COMBINE (1) [100%] 1 of 1 ✔
118Input repeaters
We saw previously that by default the number of times a process runs
is defined by the queue channel with the fewest items. However, the
each qualifier allows you to repeat the execution of a
process for each item in a list or a queue channel, every time new data
is received.
For example if we can fix the previous example by using the input
qualifer each for the letters queue channel:
GROOVY
//process_repeat.nf
process COMBINE {
input:
val x
each y
script:
"""
echo $x and $y
"""
}
ch_num = Channel.of(1, 2)
ch_letters = Channel.of('a', 'b', 'c', 'd')
workflow {
COMBINE(ch_num, ch_letters)
}The process will run eight times.
OUTPUT
2 and d
1 and a
1 and c
2 and b
2 and c
1 and d
1 and b
2 and aInput repeaters
Extend the script process_exercise_repeat.nf by adding
more values to the chr queue channel e.g. A to P and
running the process for each value.
GROOVY
//process_exercise_repeat.nf
process COMBINE {
input:
path transcriptome
val chr
script:
"""
printf "Number of sequences for chromosome $chr: "
zgrep -c "^>Y${chr}" ${transcriptome}
"""
}
transcriptome_ch = channel.fromPath('data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz', checkIfExists: true)
chr_ch = channel.of('A')
workflow {
COMBINE(transcriptome_ch, chr_ch)
}How many times does this process run?
GROOVY
//process_exercise_repeat_answer.nf
process COMBINE {
input:
path transcriptome
each chr
script:
"""
printf "Number of sequences for chromosome $chr: "
zgrep -c "^>Y${chr}" ${transcriptome}
"""
}
transcriptome_ch = channel.fromPath('data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz', checkIfExists: true)
chr_ch = channel.of('A'..'P')
workflow {
COMBINE(transcriptome_ch, chr_ch)
}Then run the script.
This process runs 16 times.
OUTPUT
N E X T F L O W ~ version 24.04.4
Launching `process_exercise_repeat.nf` [ecstatic_turing] DSL2 - revision: 17891a7528
executor > local (16)
[65/389033] COMBINE (13) [ 62%] 10 of 16
executor > local (16)
[6d/f803e5] COMBINE (9) [100%] 16 of 16 ✔
Number of sequences for chromosome J: 398
Number of sequences for chromosome G: 583
Number of sequences for chromosome O: 597
Number of sequences for chromosome N: 435
Number of sequences for chromosome B: 456
Number of sequences for chromosome E: 323
executor > local (16)
[6d/f803e5] COMBINE (9) [100%] 16 of 16 ✔
Number of sequences for chromosome J: 398
Number of sequences for chromosome G: 583
Number of sequences for chromosome O: 597
Number of sequences for chromosome N: 435
Number of sequences for chromosome B: 456
Number of sequences for chromosome E: 323
Number of sequences for chromosome K: 348
Number of sequences for chromosome H: 321
Number of sequences for chromosome C: 186
Number of sequences for chromosome M: 505
Number of sequences for chromosome L: 580
Number of sequences for chromosome A: 118
Number of sequences for chromosome D: 836
Number of sequences for chromosome F: 140
Number of sequences for chromosome P: 513
Number of sequences for chromosome I: 245Key Points
- A Nextflow process is an independent step in a workflow.
- Processes contain up to five definition blocks including: directives, inputs, outputs, when clause and finally a script block.
- The script block contains the commands you would like to run.
- A process should have a script but the other four blocks are optional.
- Inputs are defined in the input block with a type qualifier and a name.
Content from Processes Part 2
Last updated on 2024-06-10 | Edit this page
Overview
Questions
- How do I get data, files, and values, out of processes?
- How do I handle grouped input and output?
- How can I control when a process is executed?
- How do I control resources, such as number of CPUs and memory, available to processes?
- How do I save output/results from a process?
Objectives
- Define outputs to a process.
- Understand how to handle grouped input and output using the tuple qualifier.
- Understand how to use conditionals to control process execution.
- Use process directives to control execution of a process.
- Use the
publishDirdirective to save result files to a directory.
Outputs
We have seen how to input data into a process; now we will see how to output files and values from a process.
The output declaration block allows us to define the
channels used by the process to send out the files and values
produced.
An output block is not required, but if it is present it can contain one or more output declarations.
The output block follows the syntax shown below:
Output values
Like the input, the type of output data is defined using type qualifiers.
The val qualifier allows us to output a value defined in
the script.
Because Nextflow processes can only communicate through channels, if we want to share a value output of one process as input to another process, we would need to define that value in the output declaration block as shown in the following example:
GROOVY
//process_output_value.nf
params.transcriptome="${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process COUNT_CHR_SEQS {
input:
val chr
output:
val chr
script:
"""
zgrep -c '^>Y'$chr $params.transcriptome
"""
}
// Both 'Channel' and 'channel' keywords work to generate channels.
// However, it is a good practice to be consistent through the whole pipeline development
chr_ch = channel.of('A'..'P')
workflow {
COUNT_CHR_SEQS(chr_ch)
// use the view operator to display contents of the channel
COUNT_CHR_SEQS.out.view()
}OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `p1.nf` [jovial_lavoisier] - revision: a652ef75d4
executor > local (16)
executor > local (16)
[6a/d82669] process > COUNT_CHR_SEQS (16) [100%] 16 of 16 ✔
B
456
A
118
C
186
[..truncated..]
Output files
If we want to capture a file instead of a value as output we can use
the path qualifier that can capture one or more files
produced by the process, over the specified channel.
GROOVY
//process_output_file.nf
params.transcriptome="${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process COUNT_CHR_SEQS {
input:
val chr
output:
path "${chr}_seq_count.txt"
script:
"""
zgrep -c '^>Y'$chr $params.transcriptome > ${chr}_seq_count.txt
"""
}
// Both 'Channel' and 'channel' keywords work to generate channels.
// However, it is a good practice to be consistent through the whole pipeline development
chr_ch = channel.of('A'..'P')
workflow {
COUNT_CHR_SEQS(chr_ch)
// use the view operator to display contents of the channel
COUNT_CHR_SEQS.out.view()
}OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `process_output_file.nf` [angry_lichterman] - revision: 6a46c69413
executor > local (16)
[95/ec5d62] process > COUNT_CHR_SEQS (13) [100%] 16 of 16 ✔
/Users/ggrimes2/Documents/process_wf/work/f2/6d5c44985a15feb0555b7b71c37a9c/J_seq_count.txt
executor > local (16)
[95/ec5d62] process > COUNT_CHR_SEQS (13) [100%] 16 of 16 ✔
work/f2/6d5c44985a15feb0555b7b71c37a9c/J_seq_count.txt
work/4f/f810942341d003acc80c2603671177/B_seq_count.txt
work/23/883ccf187b5357137a9a87d98717c0/I_seq_count.txt
[..truncated..]In the above example the process COUNT_CHR_SEQS creates
a file named <chr>_seq_count.txt in the work
directory containing the number of transcripts within that
chromosome.
Since a file parameter using the same name,
<chr>_seq_count.txt, is declared in the output block,
when the task is completed that file is sent over the output
channel.
A downstream operator, such as .view or a
process declaring the same channel as input will be able to
receive it.
Multiple output files
When an output file name contains a * or ?
metacharacter it is interpreted as a pattern match. This allows us to
capture multiple files into a list and output them as a one item
channel.
For example, here we will capture the files
sequence_ids.txt and sequence.txt produced as
results from SPLIT_FASTA in the output channel.
GROOVY
//process_output_multiple.nf
params.transcriptome="${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process SPLIT_FASTA {
input:
path transcriptome
output:
path "*"
script:
"""
zgrep '^>' $transcriptome > sequence_ids.txt
zgrep -v '^>' $transcriptome > sequence.txt
"""
}
// Both 'Channel' and 'channel' keywords work to generate channels.
// However, it is a good practice to be consistent through the whole pipeline development
transcriptome_ch = channel.fromPath(params.transcriptome)
workflow {
SPLIT_FASTA(transcriptome_ch)
// use the view operator to display contents of the channel
SPLIT_FASTA.out.view()
}OUTPUT
N E X T F L O W ~ version 21.10.6
Launching `process_output_multiple.nf` [goofy_meitner] - revision: 53cbf7e5a4
executor > local (1)
[21/01e6ba] process > SPLIT_FASTA (1) [100%] 1 of 1 ✔
[/work/21/01e6baac41d2f37531f86dc7a57034/sequence.txt, work/21/01e6baac41d2f37531f86dc7a57034/sequence_ids.txt]
Note: There are some caveats on glob pattern behaviour:
- Input files are not included in the list of possible matches.
- Glob pattern matches against both files and directories path.
- When a two stars pattern
**is used to recurse through subdirectories, only file paths are matched i.e. directories are not included in the result list.
Output channels
Modify the nextflow script process_exercise_output.nf to
include an output block that captures the different output file
${chr}_seqids.txt.
GROOVY
//process_exercise_output.nf
process EXTRACT_IDS {
input:
path transcriptome
each chr
//add output block here to capture the file "${chr}_seqids.txt"
script:
"""
zgrep '^>Y'$chr $transcriptome > ${chr}_seqids.txt
"""
}
transcriptome_ch = channel.fromPath('data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz')
chr_ch = channel.of('A'..'P')
workflow {
EXTRACT_IDS(transcriptome_ch, chr_ch)
EXTRACT_IDS.out.view()
}GROOVY
//process_exercise_output_answer.nf
process EXTRACT_IDS {
input:
path transcriptome
each chr
//add output block here to capture the file "${chr}_seqids.txt"
output:
path "${chr}_seqids.txt"
script:
"""
zgrep '^>Y'$chr $transcriptome > ${chr}_seqids.txt
"""
}
transcriptome_ch = channel.fromPath('data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz')
chr_ch = channel.of('A'..'P')
workflow {
EXTRACT_IDS(transcriptome_ch, chr_ch)
EXTRACT_IDS.out.view()
}Grouped inputs and outputs
So far we have seen how to declare multiple input and output
channels, but each channel was handling only one value at time. However
Nextflow can handle groups of values using the tuple
qualifiers.
In tuples the first item is the grouping key and the second item is the list.
[group_key,[file1,file2,...]]When using channel containing a tuple, such a one created with
.filesFromPairs factory method, the corresponding input
declaration must be declared with a tuple qualifier,
followed by definition of each item in the tuple.
GROOVY
//process_tuple_input.nf
process TUPLEINPUT{
input:
tuple val(sample_id), path(reads)
script:
"""
echo $sample_id
echo $reads
"""
}
reads_ch = Channel.fromFilePairs('data/yeast/reads/ref1_{1,2}.fq.gz')
workflow {
TUPLEINPUT(reads_ch)
}outputs
OUTPUT
ref1
ref1_1.fq.gz ref1_2.fq.gzIn the same manner an output channel containing tuple of values can
be declared using the tuple qualifier following by the
definition of each tuple element in the tuple.
In the code snippet below the output channel would contain a tuple
with the grouping key value as the Nextflow variable
sample_id and a list containing the files matching the
following pattern "${sample_id}.fq.gz".
An example can be seen in this script below.
GROOVY
//process_tuple_io.nf
process COMBINE_FQ {
input:
tuple val(sample_id), path(reads)
output:
tuple val(sample_id), path("${sample_id}.fq.gz")
script:
"""
cat $reads > ${sample_id}.fq.gz
"""
}
reads_ch = Channel.fromFilePairs('data/yeast/reads/ref1_{1,2}.fq.gz')
workflow {
COMBINE_FQ(reads_ch)
COMBINE_FQ.out.view()
}The output is now a tuple containing the sample id and the combined fastq files.
OUTPUT
[ref1, work/2d/a073d34b5b3231b1f57872599bd308/ref1.fq]Composite inputs and outputs
Fill in the blank ___ input and output qualifiers for
process_exercise_tuple.nf. Note: the
output for the COMBINE_REPS process.
GROOVY
//process_exercise_tuple.nf
process COMBINE_REPS {
input:
tuple ___(sample_id), ___(reads)
output:
tuple ___(sample_id), ___("*.fq.gz")
script:
"""
cat *_1.fq.gz > ${sample_id}_R1.fq.gz
cat *_2.fq.gz > ${sample_id}_R2.fq.gz
"""
}
reads_ch = Channel.fromFilePairs('data/yeast/reads/ref{1,2,3}*.fq.gz',size:-1)
workflow{
COMBINE_REPS(reads_ch)
COMBINE_REPS.out.view()
}GROOVY
//process_exercise_tuple_answer.nf
process COMBINE_REPS {
input:
tuple val(sample_id), path(reads)
output:
tuple val(sample_id), path("*.fq.gz")
script:
"""
cat *_1.fq.gz > ${sample_id}_R1.fq.gz
cat *_2.fq.gz > ${sample_id}_R2.fq.gz
"""
}
reads_ch = Channel.fromFilePairs('data/yeast/reads/ref*_{1,2,3}.fq.gz',size:-1)
workflow{
COMBINE_REPS(reads_ch)
COMBINE_REPS.out.view()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_exercise_tuple.nf` [spontaneous_coulomb] - revision: 06ff22f1a9
executor > local (3)
[75/f4a44d] process > COMBINE_REPS (3) [100%] 3 of 3 ✔
[ref3, work/99/a7d9176e332fdc0988973dbb89df63/ref3_R1.fq.gz, work/99/a7d9176e332fdc0988973dbb89df63/ref3_R2.fq.gz]
[ref2, /work/53/e3cbd39afa9f0f84a3d9cd060d991a/ref2_R1.fq.gz, /work/53/e3cbd39afa9f0f84a3d9cd060d991a/ref2_R2.fq.gz]
[ref1, work/75/f4a44d0bc761fa4774c2f23a465766/ref1_R1.fq.gz, work/75/f4a44d0bc761fa4774c2f23a465766/ref1_R2.fq.gz]Conditional execution of a process
The when declaration allows you to define a condition
that must be verified in order to execute the process. This can be any
expression that evaluates a boolean value; true or
false.
It is useful to enable/disable the process execution depending on the state of various inputs and parameters.
In the example below the process CONDITIONAL will only
execute when the value of the chr variable is less than or
equal to 5:
GROOVY
//process_when.nf
process CONDITIONAL {
input:
val chr
when:
chr <= 5
script:
"""
echo $chr
"""
}
chr_ch = channel.of(1..22)
workflow {
CONDITIONAL(chr_ch)
}OUTPUT
4
5
2
3
1Directives
Directive declarations allow the definition of optional settings,
like the number of cpus and amount of memory,
that affect the execution of the current process without affecting the
task itself.
They must be entered at the top of the process body, before any other
declaration blocks (i.e. input, output,
etc).
Note: You do not use = when assigning a
value to a directive.
Directives are commonly used to define the amount of computing resources to be used or extra information for configuration or logging purpose.
For example:
GROOVY
//process_directive.nf
process PRINTCHR {
tag "tagging with chr$chr"
cpus 1
echo true
input:
val chr
script:
"""
echo processing chromosome: $chr
echo number of cpus $task.cpus
"""
}
chr_ch = channel.of(1..22, 'X', 'Y')
workflow {
PRINTCHR(chr_ch)
}OUTPUT
processing chromosome: 1
number of cpus 1
processing chromosome: 2
number of cpus 1
processing chromosome: 6
number of cpus 1
[..truncated..]The above process uses the three directives, tag,
cpus and echo.
The tag directive to allow you to give a custom tag to
each process execution. This tag makes it easier to identify a
particular task (executed instance of a process) in a log file or in the
execution report.
The second directive cpus allows you to define the
number of CPUs required for each task.
The third directive echo true prints the stdout to the
terminal.
We use the Nextflow task.cpus variable to capture the
number of cpus assigned to a task. This is frequently used to specify
the number of threads in a multi-threaded command in the script
block.
Another commonly used directive is memory specification:
memory.
A complete list of directives is available at this link.
Adding directives
Many software tools allow users to configure the number of CPU threads used, optimizing performance for faster and more efficient data processing in high-throughput sequencing tasks.
In this exercise, we will use the bioinformatics tool FastQC to assess the quality of high-throughput sequencing read data. FastQC generates an HTML report along with a directory containing detailed analysis results. We can specify the number of CPU threads for FastQC to use with the -t option, followed by the desired number of threads.
Modify the Nextflow script
process_exercise_directives.nf
- Add a
tagdirective logging the sample_id in the execution output. - Add a
cpusdirective to specify the number of cpus as 2. - Change the fastqc
-toption value to$task.cpusin the script directive.
GROOVY
//process_exercise_directives.nf
process FASTQC {
//add tag directive
//add cpu directive
input:
tuple val(sample_id), path(reads)
output:
tuple val(sample_id), path("fastqc_out")
script:
"""
mkdir fastqc_out
fastqc $reads -o fastqc_out -t 1
"""
}
read_pairs_ch = Channel.fromFilePairs('data/yeast/reads/ref*_{1,2}.fq.gz')
workflow {
FASTQC(read_pairs_ch)
FASTQC.out.view()
}GROOVY
//process_directives_answer.nf
process FASTQC {
tag "$sample_id"
cpus 2
input:
tuple val(sample_id), path(reads)
output:
tuple val(sample_id), path("fastqc_out")
script:
"""
mkdir fastqc_out
fastqc $reads -o fastqc_out -t $task.cpus
"""
}
read_pairs_ch = Channel.fromFilePairs('data/yeast/reads/ref*_{1,2}.fq.gz')
workflow {
FASTQC(read_pairs_ch)
FASTQC.out.view()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_exercise_directives.nf` [sad_rosalind] - revision: 2ccbfa4937
executor > local (3)
[90/de1125] process > FASTQC (ref1) [100%] 3 of 3 ✔
[ref2, work/ea/9e6a341b88caf8879e8d18b77049c8/fastqc_out]
[ref3, work/94/d059b816a9ec3d868f2924c26813e7/fastqc_out]
[ref1, work/90/de11251d362f494d6650789d9f8c1d/fastqc_out]Organising outputs
PublishDir directive
Nextflow manages intermediate results from the pipeline’s expected outputs independently.
Files created by a process are stored in a task specific
working directory which is considered as temporary. Normally this is
under the work directory, which can be deleted upon
completion.
The files you want the workflow to return as results need to be
defined in the process output block and then
the output directory specified using the directive
publishDir. More information here.
Note: A common mistake is to specify an output
directory in the publishDir directive while forgetting to
specify the files you want to include in the output
block.
publishDir <directory>, parameter: value, parameter2: value ...For example if we want to capture the results of the
COMBINE_READS process in a
results/merged_reads output directory we need to define the
files in the output and specify the location of the results
directory in the publishDir directive:
GROOVY
//process_publishDir.nf
process COMBINE_READS {
publishDir "results/merged_reads"
input:
tuple val(sample_id), path(reads)
output:
path("${sample_id}.merged.fq.gz")
script:
"""
cat ${reads} > ${sample_id}.merged.fq.gz
"""
}
reads_ch = Channel.fromFilePairs('data/yeast/reads/ref1_{1,2}.fq.gz')
workflow {
COMBINE_READS(reads_ch)
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_publishDir.nf` [friendly_pauling] - revision: 9b5c315893
executor > local (1)
[a1/5956bd] process > COMBINE_READS (1) [100%] 1 of 1 ✔We can use the UNIX command ls -l to examine the
contents of the results directory.
OUTPUT
results/merged_reads/ref1.merged.fq.gz -> /Users/nf-user/nf-training/work/a1/5956bd9a92f13694b3ada1941f0d2d/ref1.merged.fq.gzIn the above example, the
publishDir "results/merged_reads", creates a symbolic link
-> to the output files specified by the process
merged_reads to the directory path
results/merged_reads.
A symbolic link, often referred to as a symlink, is a type of file that serves as a reference or pointer to another file or directory, allowing multiple access paths to the same resource without duplicating its actual data
publishDir
The publishDir output is relative to the path the pipeline run has
been launched. Hence, it is a good practice to use implicit
variables like projectDir to specify publishDir
value.
publishDir parameters
The publishDir directive can take optional parameters,
for example the mode parameter can take the value
"copy" to specify that you wish to copy the file to output
directory rather than just a symbolic link to the files in the working
directory. Since the working directory is generally deleted on
completion of a pipeline, it is safest to use mode: "copy"
for results files. The default mode (symlink) is helpful for checking
intermediate files which are not needed in the long term.
Full list here.
Manage semantic sub-directories
You can use more than one publishDir to keep different
outputs in separate directories. To specify which files to put in which
output directory use the parameter pattern with the a glob
pattern that selects which files to publish from the overall set of
output files.
In the example below we will create an output folder structure in the
directory results, which contains a separate sub-directory for sequence
id file, pattern:"*_ids.txt" , and a sequence directory,
results/sequence" for the sequence.txt file.
Remember, we need to specify the files we want to copy as outputs.
GROOVY
//process_publishDir_semantic.nf
params.transcriptome="${projectDir}/data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
process SPLIT_FASTA {
publishDir "results/ids", pattern: "*_ids.txt", mode: "copy"
publishDir "results/sequence", pattern: "sequence.txt", mode: "copy"
input:
path transcriptome
output:
path "*"
script:
"""
zgrep '^>' $transcriptome > sequence_ids.txt
zgrep -v '^>' $transcriptome > sequence.txt
"""
}
// Both 'Channel' and 'channel' keywords work to generate channels.
// However, it is a good practice to be consistent through the whole pipeline development
transcriptome_ch = channel.fromPath(params.transcriptome)
workflow {
SPLIT_FASTA(transcriptome_ch)
// use the view operator to display contents of the channel
SPLIT_FASTA.out.view()
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_publishDir_semantic.nf` [golden_poisson] - revision: 421a604840
executor > local (1)
[be/950786] process > SPLIT_FASTA (1) [100%] 1 of 1 ✔We can now use the ls results/* command to examine the
results directory.
OUTPUT
results/ids:
sequence_ids.txt
results/sequence:
sequence.txtPublishing results
Add a publishDir directive to the nextflow script
process_exercise_publishDir.nf that copies the merged reads
to the results folder merged_reps.
GROOVY
//process_exercise_publishDir.nf
params.reads= "data/yeast/reads/ref{1,2,3}*{1,2}.fq.gz"
process MERGE_REPS {
input:
tuple val(sample_id), path(reads)
output:
path("*fq.gz")
script:
"""
cat *1.fq.gz > ${sample_id}.merged.R1.fq.gz
cat *2.fq.gz > ${sample_id}.merged.R2.fq.gz
"""
}
reads_ch = Channel.fromFilePairs(params.reads,checkIfExists:true,size:6)
workflow {
MERGE_REPS(reads_ch)
}GROOVY
//process_exercise_publishDir_answer.nf
params.reads= "data/yeast/reads/ref{1,2,3}*{1,2}.fq.gz"
process MERGE_REPS {
publishDir "results/merged_reps"
input:
tuple val(sample_id), path(reads)
output:
path("*fq.gz")
script:
"""
cat *1.fq.gz > ${sample_id}.merged.R1.fq.gz
cat *2.fq.gz > ${sample_id}.merged.R2.fq.gz
"""
}
reads_ch = Channel.fromFilePairs(params.reads,checkIfExists:true,size:6)
workflow {
MERGE_REPS(reads_ch)
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process_exercise_publishDir.nf` [infallible_becquerel] - revision: 4d865241a8
executor > local (1)
[22/88aa22] process > MERGE_REPS (1) [100%] 1 of 1 ✔Nextflow Patterns
If you want to find out common structures of Nextflow processes, the Nextflow Patterns page collects some recurrent implementation patterns used in Nextflow applications.
Key Points
- Outputs to a process are defined using the output blocks.
- You can group input and output data from a process using the tuple qualifier.
- The execution of a process can be controlled using the
whendeclaration and conditional statements. - Files produced within a process and defined as
outputcan be saved to a directory using thepublishDirdirective.
Content from Workflow
Last updated on 2024-06-10 | Edit this page
Overview
Questions
- How do I connect channels and processes to create a workflow?
- How do I invoke a process inside a workflow?
Objectives
- Create a Nextflow workflow joining multiple processes.
- Understand how to to connect processes via their inputs and outputs within a workflow.
Workflow
Our previous episodes have shown us how to parameterise workflows
using params, move data around a workflow using
channels and define individual tasks using
processes. In this episode we will cover how connect
multiple processes to create a workflow.
Workflow definition
We can connect processes to create our pipeline inside a
workflow scope. The workflow scope starts with the keyword
workflow, followed by an optional name and finally the
workflow body delimited by curly brackets {}.
Implicit workflow
In contrast to processes, the workflow definition in Nextflow does not require a name. In Nextflow, if you don’t give a name to a workflow, it’s considered the main/implicit starting point of your workflow program.
A named workflow is a subworkflow that can be invoked
from other workflows, subworkflows are not covered in this lesson, more
information can be found in the official documentation here.
Invoking processes with a workflow
As seen previously, a process is invoked as a function
in the workflow scope, passing the expected input channels
as arguments as it if were.
<process_name>(<input_ch1>,<input_ch2>,...)To combined multiple processes invoke them in the order they would
appear in a workflow. When invoking a process with multiple inputs,
provide them in the same order in which they are declared in the
input block of the process.
For example:
GROOVY
//workflow_01.nf
process FASTQC {
input:
tuple(val(sample_id), path(reads))
output:
path "fastqc_${sample_id}_logs"
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs -f fastq -q ${reads}
"""
}
process MULTIQC {
publishDir "results/mqc"
input:
path transcriptome
output:
path "*"
script:
"""
multiqc .
"""
}
workflow {
read_pairs_ch = channel.fromFilePairs('data/yeast/reads/*_{1,2}.fq.gz',checkIfExists: true)
//index process takes 1 input channel as a argument
//assign process output to Nextflow variable fastqc_obj
fastqc_obj = FASTQC(read_pairs_ch)
//quant channel takes 1 input channel as an argument
//We use the collect operator to gather multiple channel items into a single item
MULTIQC(fastqc_obj.collect()).view()
}Process outputs
In the previous example we assigned the process output to a Nextflow
variable fastqc_obj.
A process output can also be accessed directly using the
out attribute for the respective
process object.
For example:
GROOVY
[..truncated..]
workflow {
read_pairs_ch = channel.fromFilePairs('data/yeast/reads/*_{1,2}.fq.gz',checkIfExists: true)
FASTQC(read_pairs_ch)
// process output accessed using the `out` attribute of the process object
MULTIQC(FASTQC.out.collect()).view()
MULTIQC.out.view()
}When a process defines two or more output channels, each of them can
be accessed using the list element operator e.g. out[0],
out[1], or using named outputs.
Process named output
It can be useful to name the output of a process, especially if there are multiple outputs.
The process output definition allows the use of the
emit: option to define a named identifier that can be used
to reference the channel in the external scope.
For example in the script below we name the output from the
FASTQC process as fastqc_results using the
emit: option. We can then reference the output as
FASTQC.out.fastqc_results in the workflow scope.
GROOVY
//workflow_02.nf
process FASTQC {
input:
tuple val(sample_id), path(reads)
output:
path "fastqc_${sample_id}_logs", emit: fastqc_results
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs ${reads}
"""
}
process MULTIQC {
publishDir "results/mqc"
input:
path fastqc_results
output:
path "*"
script:
"""
multiqc .
"""
}
workflow {
read_pairs_ch = channel.fromFilePairs('data/yeast/reads/ref*_{1,2}.fq.gz',checkIfExists: true)
//FASTQC process takes 1 input channel as a argument
FASTQC(read_pairs_ch)
//MULTIQC channel takes 1 input channels as arguments
MULTIQC(FASTQC.out.fastqc_results.collect()).view()
}Accessing script parameters
A workflow component can access any variable and parameter defined in the outer scope:
For example:
GROOVY
//workflow_03.nf
[..truncated..]
params.reads = 'data/yeast/reads/*_{1,2}.fq.gz'
workflow {
reads_ch_ = channel.fromFilePairs(params.reads)
FASTQC(reads_ch_)
MULTIQC(FASTQC.out.fastqc_results.collect()).view()
}In this example params.reads, defined outside the
workflow scope, can be accessed inside the workflow
scope.
Workflow
Connect the output of the process FASTQC to
PARSEZIP in the Nextflow script
workflow_exercise.nf.
Note: You will need to pass the
read_pairs_ch as an argument to FASTQC and you will need to
use the collect operator to gather the items in the FASTQC
channel output to a single List item.
GROOVY
//workflow_exercise.nf
params.reads = 'data/yeast/reads/*_{1,2}.fq.gz'
process FASTQC {
input:
tuple val(sample_id), path(reads)
output:
path "fastqc_${sample_id}_logs/*.zip"
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs ${reads}
"""
}
process PARSEZIP {
publishDir "results/fqpass", mode:"copy"
input:
path fastqc_logs
output:
path 'pass_basic.txt'
script:
"""
for zip in *.zip; do zipgrep 'Basic Statistics' \$zip|grep 'summary.txt'; done > pass_basic.txt
"""
}
read_pairs_ch = channel.fromFilePairs(params.reads,checkIfExists: true)
workflow {
//connect process FASTQC and PARSEZIP
// remember to use the collect operator on the FASTQC output
}GROOVY
//workflow_exercise.nf
params.reads = 'data/yeast/reads/*_{1,2}.fq.gz'
process FASTQC {
input:
tuple val(sample_id), path(reads)
output:
path "fastqc_${sample_id}_logs/*.zip"
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs ${reads}
"""
}
process PARSEZIP {
publishDir "results/fqpass", mode:"copy"
input:
path fastqc_logs
output:
path 'pass_basic.txt'
script:
"""
for zip in *.zip; do zipgrep 'Basic Statistics' \$zip|grep 'summary.txt'; done > pass_basic.txt
"""
}
read_pairs_ch = channel.fromFilePairs(params.reads,checkIfExists: true)
workflow {
PARSEZIP(FASTQC(read_pairs_ch).collect())
}OUTPUT
18The file results/fqpass/pass_basic.txt should have 18
lines. If you only have two lines it might mean that you did not use
collect() operator on the FASTC output channel.
Key Points
- A Nextflow workflow is defined by invoking
processesinside theworkflowscope. - A process is invoked like a function inside the
workflowscope passing any required input parameters as arguments. e.g.FASTQC(reads_ch). - Process outputs can be accessed using the
outattribute for the respectiveprocessobject or assigning the output to a Nextflow variable. - Multiple outputs from a single process can be accessed using the
list syntax
[]and it’s index or by referencing the a named process output .
Content from Operators
Last updated on 2024-04-23 | Edit this page
Overview
Questions
- How do I perform operations, such as filtering, on channels?
- What are the different kinds of operations I can perform on channels?
- How do I combine operations?
- How can I use a CSV file to process data into a Channel?
Objectives
- Understand what Nextflow operators are.
- Modify the contents/elements of a channel using operators.
- Perform filtering and combining operations on a channel object.
- Use the
splitCsvoperator to parse the contents of CSV file into a channel .
Operators
In the Channels episode we learnt how to create Nextflow channels to
enable us to pass data and values around our workflow. If we want to
modify the contents or behaviour of a channel, Nextflow provides methods
called operators. We have previously used the
view operator to view the contents of a channel. There are
many more operator methods that can be applied to Nextflow channels that
can be usefully separated into several groups:
- Filtering operators: reduce the number of elements in a channel.
- Transforming operators: transform the value/data in a channel.
- Splitting operators: split items in a channel into smaller chunks.
- Combining operators: join channels together.
- Maths operators: apply simple math functions on channels.
- Other: such as the view operator.
In this episode you will see examples, and get to use different types of operators.
Using Operators
To use an operator, the syntax is the channel name, followed by a dot
. , followed by the operator name and brackets
().
view
The view operator prints the items emitted by a channel
to the console appending a new line character to each item in
the channel.
We can also chain together the channel factory method
.of and the operator .view() using the dot
notation.
To make code more readable we can split the operators over several lines. The blank space between the operators is ignored and is solely for readability.
prints:
Closures
An optional closure {} parameter can be
specified to customise how items are printed.
Briefly, a closure is a block of code that can be passed as an
argument to a function. In this way you can define a chunk of code and
then pass it around as if it were a string or an integer. By default the
parameters for a closure are specified with the groovy keyword
$it (‘it’ is for ‘item’).
For example here we use the the view operator and apply
a closure to it, to add a chr prefix to each element of the
channel using string interpolation.
It prints:
OUTPUT
chr1
chr2
chr3Note: the view() operator doesn’t
change the contents of the channel object.
OUTPUT
chr1
chr2
chr3
1
2
3Filtering operators
We can reduce the number of items in a channel by using filtering operators.
The filter operator allows you to get only the items
emitted by a channel that satisfy a condition and discard all the
others. The filtering condition can be specified by using either:
- a regular expression
- a literal value
- a data type qualifier, e.g. Number (any integer,float …), String, Boolean
- or any boolean statement.
Data type qualifier
Here we use the filter operator on the
chr_ch channel specifying the data type qualifier
Number so that only numeric items are returned. The Number
data type includes both integers and floating point numbers. We will
then use the view operator to print the contents.
GROOVY
chr_ch = channel.of( 1..22, 'X', 'Y' )
autosomes_ch =chr_ch.filter( Number )
autosomes_ch.view()To simplify the code we can chain multiple operators together, such
as filter and view using a .
.
The previous example could be rewritten like: The blank space between the operators is ignored and is used for readability.
OUTPUT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22Regular expression
To filter by a regular expression you have to do is to put
~ right in front of the string literal regular expression
(e.g. ~"(^[Nn]extflow)" or use slashy strings which replace
the quotes with /. ~/^[Nn]extflow/).
The following example shows how to filter a channel by using a
regular expression ~/^1.*/ inside a slashy string, that
returns only strings that begin with 1:
OUTPUT
1
10
11
12
13
14
15
16
17
18
19Boolean statement
A filtering condition can be defined by using a Boolean expression
described by a closure {} and returning a boolean value.
For example the following fragment shows how to combine a filter for a
type qualifier Number with another filter operator using a
Boolean expression to emit numbers less than 5:
OUTPUT
1
2
3
4Closures
In the above example we have removed the brackets around the filter
condition e.g. filter{ it<5}, since it specifies a
closure as the operator’s argument. This is language short for
filter({ it<5})
Modifying the contents of a channel
If we want to modify the items in a channel, we can use transforming operators.
Applying a function to items in a channel
The map operator applies a function of your choosing to
every item in a channel, and returns the items so obtained as a new
channel. The function applied is called the mapping function and is
expressed with a closure {} as shown in the example
below:
Here the map function uses the groovy string function
replaceAll to remove the chr prefix from each element.
OUTPUT
1
2We can also use the map operator to transform each
element into a tuple.
In the example below we use the map operator to
transform a channel containing fastq files to a new channel containing a
tuple with the fastq file and the number of reads in the fastq file. We
use the built in countFastq file method to count the number
of records in a FASTQ formatted file.
We can change the default name of the closure parameter keyword from
it to a more meaningful name file using
->. When we have multiple parameters we can specify the
keywords at the start of the closure,
e.g. file, numreads ->.
GROOVY
fq_ch = channel
.fromPath( 'data/yeast/reads/*.fq.gz' )
.map ({ file -> [file, file.countFastq()] })
.view ({ file, numreads -> "file $file contains $numreads reads" })This would produce.
OUTPUT
file data/yeast/reads/ref1_2.fq.gz contains 14677 reads
file data/yeast/reads/etoh60_3_2.fq.gz contains 26254 reads
file data/yeast/reads/temp33_1_2.fq.gz contains 20593 reads
file data/yeast/reads/temp33_2_1.fq.gz contains 15779 reads
file data/yeast/reads/ref2_1.fq.gz contains 20430 reads
[..truncated..]We can then add a filter operator to only retain those
fastq files with more than 25000 reads.
GROOVY
channel
.fromPath( 'data/yeast/reads/*.fq.gz' )
.map ({ file -> [file, file.countFastq()] })
.filter({ file, numreads -> numreads > 25000})
.view ({ file, numreads -> "file $file contains $numreads reads" })OUTPUT
file data/yeast/reads/etoh60_3_2.fq.gz contains 26254 reads
file data/yeast/reads/etoh60_3_1.fq.gz contains 26254 readsConverting a list into multiple items
The flatten operator transforms a channel in such a way
that every item in a list or tuple is
flattened so that each single entry is emitted as a sole element by the
resulting channel.
OUTPUT
[1, 2, 3]The above snippet prints:
OUTPUT
1
2
3This is similar to the channel factory
Channel.fromList.
Converting the contents of a channel to a single list item.
The reverse of the flatten operator is
collect. The collect operator collects all the
items emitted by a channel to a list and return the resulting object as
a sole emission. This can be extremely useful when combining the results
from the output of multiple processes, or a single process run multiple
times.
It prints a single value:
OUTPUT
[1,2,3,4]The result of the collect operator is a value channel
and can be used multiple times.
Grouping contents of a channel by a key.
The groupTuple operator collects tuples or
lists of values by grouping together the channel elements
that share the same key. Finally it emits a new tuple object for each
distinct key collected.
For example.
GROOVY
ch = channel
.of( ['wt','wt_1.fq'], ['wt','wt_2.fq'], ["mut",'mut_1.fq'], ['mut', 'mut_2.fq'] )
.groupTuple()
.view()OUTPUT
[wt, [wt_1.fq, wt_1.fq]]
[mut, [mut_1.fq, mut_2.fq]]If we know the number of items to be grouped we can use the
groupTuple size parameter. When the specified
size is reached, the tuple is emitted. By default incomplete tuples
(i.e. with less than size grouped items) are discarded (default).
For example.
GROOVY
ch = channel
.of( ['wt','wt_1.fq'], ['wt','wt_1.fq'], ["mut",'mut_1.fq'])
.groupTuple(size:2)
.view()outputs,
OUTPUT
[wt, [wt_1.fq, wt_1.fq]]This operator is useful to process altogether all elements for which there’s a common property or a grouping key.
Group Tuple
Modify the Nextflow script above to add the map operator
to create a tuple with the name prefix as the key and the file as the
value using the closure below.
Finally group together all files having the same common prefix using
the groupTuple operator and view the contents
of the channel.
Merging Channels
Combining operators allows you to merge channels together. This can be useful when you want to combine the output channels from multiple processes to perform another task such as joint QC.
mix
The mix operator combines the items emitted by two (or
more) channels into a single channel.
GROOVY
ch1 = channel.of( 1,2,3 )
ch2 = channel.of( 'X','Y' )
ch3 = channel.of( 'mt' )
ch4 = ch1.mix(ch2,ch3).view()OUTPUT
1
2
3
X
Y
mtThe items emitted by the resulting mixed channel may appear in any order, regardless of which source channel they came from. Thus, the following example it could be a possible result of the above example as well.
OUTPUT
1
2
X
3
mt
Yjoin
The join operator creates a channel that joins together
the items emitted by two channels for which exists a matching key. The
key is defined, by default, as the first element in each item
emitted.
GROOVY
reads1_ch = channel
.of(['wt', 'wt_1.fq'], ['mut','mut_1.fq'])
reads2_ch= channel
.of(['wt', 'wt_2.fq'], ['mut','mut_2.fq'])
reads_ch = reads1_ch
.join(reads2_ch)
.view()The resulting channel emits:
OUTPUT
[wt, wt_1.fq, wt_2.fq]
[mut, mut_1.fq, mut_2.fq]Maths operators
The maths operators allows you to apply simple math function on channels.
The maths operators are:
- count
- min
- max
- sum
- toInteger
Splitting items in a channel
Sometimes you want to split the content of a individual item in a channel, like a file or string, into smaller chunks that can be processed by downstream operators or processes e.g. items stored in a CSV file.
Nextflow has a number of splitting operators that can achieve this:
- splitCsv: The splitCsv operator allows you to parse text items emitted by a channel, that are formatted using the CSV format, and split them into records or group them into list of records with a specified length.
- splitFasta: The splitFasta operator allows you to split the entries emitted by a channel, that are formatted using the FASTA format. It returns a channel which emits a text item for each sequence in the received FASTA content.
- splitFastq: The splitFastq operator allows you to split the entries emitted by a channel, that are formatted using the FASTQ format. It returns a channel which emits a text chunk for each sequence in the received item.
- splitText: The splitText operator allows you to split multi-line strings or text file items, emitted by a source channel into chunks containing n lines, which will be emitted by the resulting channel.
splitCsv
The splitCsv operator allows you to parse text items
emitted by a channel, that are formatted using the CSV format, and split
them into records or group them into list of records with a specified
length. This is useful when you want to use a sample sheet.
In the simplest case just apply the splitCsv operator to
a channel emitting a CSV formatted text files or text entries. For
example:
For the CSV file samples.csv.
OUTPUT
sample_id,fastq_1,fastq_2
ref1,data/yeast/reads/ref1_1.fq.gz,data/yeast/reads/ref1_2.fq.gz
ref2,data/yeast/reads/ref2_1.fq.gz,data/yeast/reads/ref2_2.fq.gzWe can use the splitCsv() operator to split the channel
contaning a CSV file into three elements.
OUTPUT
[sample_id, fastq_1, fastq_2]
[ref1, data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz]
[ref2, data/yeast/reads/ref2_1.fq.gz, data/yeast/reads/ref2_2.fq.gz]The above example shows hows the CSV file samples.csv is
parsed and is split into three elements.
Accessing values
Values can be accessed by their positional indexes using the square
brackets syntax[index]. So to access the first column you
would use [0] as shown in the following example:
OUTPUT
sample_id
ref1
ref2Column headers
When the CSV begins with a header line defining the column names, you
can specify the parameter header: true which allows you to
reference each value by its name, as shown in the following example:
GROOVY
csv_ch=channel
.fromPath('data/yeast/samples.csv')
.splitCsv(header:true)
csv_ch.view({it.fastq_1})OUTPUT
data/yeast/reads/ref1_1.fq.gz
data/yeast/reads/ref2_1.fq.gzMore resources
See the operators documentation on the Nextflow web site.
Key Points
- Nextflow operators are methods that allow you to modify, set or view channels.
- Operators can be separated in to several groups; filtering , transforming , splitting , combining , forking and Maths operators
- To use an operator use the dot notation after the Channel object
e.g.
my_ch.view(). - You can parse text items emitted by a channel, that are formatted
using the CSV format, using the
splitCsvoperator.
Content from Reporting
Last updated on 2024-04-23 | Edit this page
Overview
Questions
- How do I get information about my pipeline run?
- How can I see what commands I ran?
- How can I create a report from my run?
Objectives
- View Nextflow pipeline run logs.
- Use
nextflow logto view more information about a specific run. - Create an HTML report from a pipeline run.
Nextflow log
Once a script has run, Nextflow stores a log of all the workflows executed in the current folder. Similar to an electronic lab book, this means you have a record of all processing steps and commands run.
You can print Nextflow’s execution history and log information using
the nextflow log command.
OUTPUT
TIMESTAMP DURATION RUN NAME STATUS REVISION ID SESSION ID COMMANDThis will print a summary of the executions log and runtime information for all pipelines run. By default, included in the summary, are the date and time it ran, how long it ran for, the run name, run status, a revision ID, the session id and the command run on the command line.
The output will look similar to this:
OUTPUT
TIMESTAMP DURATION RUN NAME STATUS REVISION ID SESSION ID COMMAND
2021-03-19 13:45:53 6.5s fervent_babbage OK c54a707593 15487395-443a-4835-9198-229f6ad7a7fd nextflow run wc.nf
2021-03-19 13:46:53 6.6s soggy_miescher OK c54a707593 58da0ccf-63f9-42e4-ba4b-1c349348ece5 nextflow run wc.nf --samples 'data/yeast/reads/*.fq.gz'Pipeline execution report
If we want to get more information about an individual run we can add
the run name or session ID to the log command.
For example:
BASH
/data/.../work/7b/3753ff13b1fa5348d2d9b6f512153a
/data/.../work/c1/56a36d8f498c99ac6cba31e85b3e0c
/data/.../work/f7/659c65ef60582d9713252bcfbcc310
/data/.../work/82/ba67e3175bd9e6479d4310e5a92f99
/data/.../work/e5/2816b9d4e7b402bfdd6597c2c2403d
/data/.../work/3b/3485d00b0115f89e4c202eacf82ebaThis will list the work directory for each process.
Task ID
The task ID is a a 32 hexadecimal
digit,e.g. 3b3485d00b0115f89e4c202eacf82eba. A task’s
unique ID is generated as a 128-bit hash number obtained from a
composition of the task’s:
- Inputs values
- Input files
- Command line string
- Container ID
- Conda environment
- Environment modules
- Any executed scripts in the bin directory
Fields
If we want to print more metadata we can use the log
command and the option -f (fields) followed by a comma
delimited list of fields. This can be composed to track the provenance
of a workflow result.
For example:
Will output the process name, exit status, hash and duration of the
process for the tiny_fermat run to the terminal.
OUTPUT
index 0 7b/3753ff 2s
fastqc 0 c1/56a36d 9.3s
fastqc 0 f7/659c65 9.1s
quant 0 82/ba67e3 2.7s
quant 0 e5/2816b9 3.2s
multiqc 0 3b/3485d0 6.3sThe complete list of available fields can be retrieved with the command:
OUTPUT
attempt
complete
container
cpus
disk
duration
env
error_action
exit
hash
inv_ctxt
log
memory
module
name
native_id
pcpu
peak_rss
peak_vmem
pmem
process
queue
rchar
read_bytes
realtime
rss
scratch
script
start
status
stderr
stdout
submit
syscr
syscw
tag
task_id
time
vmem
vol_ctxt
wchar
workdir
write_bytesScript
If we want a log of all the commands executed in the pipeline we can
use the script field. It is important to note that the
resultant output can not be used to run the pipeline steps.
Filtering
The output from the log command can be very long. We can
subset the output using the option -F (filter) specifying
the filtering criteria. This will print only those tasks matching a
pattern using the syntax =~/<pattern>/.
For example to filter for process with the name fastqc
we would run:
OUTPUT
/data/.../work/c1/56a36d8f498c99ac6cba31e85b3e0c
/data/.../work/f7/659c65ef60582d9713252bcfbcc310This can be useful to locate specific tasks work directories.
View run log
Use the Nextflow log command specifying a
run name and the fields. name, hash, process and status
Filter pipeline run log
Use the -F option and a regular expression to filter the
for a specific process e.g. multiqc.
Templates
The -t option allows a template (string or file) to be
specified. This makes it possible to create a custom report in any text
based format.
For example you could save this markdown snippet to a file
e.g. my-template.md:
Then, the following log command will output a markdown
file containing the script, exit status and
folder of all executed tasks:
Or, the template file can also be written in HTML.
For example:
HTML
<div>
<h2>${name}</h2>
<div>
Script:
<pre>${script}</pre>
</div>
<ul>
<li>Exit: ${exit}</li>
<li>Status: ${status}</li>
<li>Work dir: ${workdir}</li>
<li>Container: ${container}</li>
</ul>
</div>By saving the above snippet in a file named
template.html, you can run the following command:
To view the report open it in a browser.
Generate an HTML run report
Generate an HTML report for a run using the -t option
and the template.html file.
Key Points
- Nextflow can produce a custom execution report with run information
using the
logcommand. - You can generate a report using the
-toption specifying a template file.
Content from Nextflow configuration
Last updated on 2024-06-10 | Edit this page
Overview
Questions
- What is the difference between the workflow implementation and the workflow configuration?
- How do I configure a Nextflow workflow?
- How do I assign different resources to different processes?
- How do I separate and provide configuration for different computational systems?
- How do I change configuration settings from the default settings provided by the workflow?
Objectives
- Understand the difference between workflow implementation and configuration.
- Understand the difference between configuring Nextflow and a Nextflow script.
- Create a Nextflow configuration file.
- Understand what a configuration scope is.
- Be able to assign resources to a process.
- Be able to refine configuration settings using process selectors.
- Be able to group configurations into profiles for use with different computer infrastructures.
- Be able to override existing settings.
- Be able to inspect configuration settings before running a workflow.
Nextflow configuration
A key Nextflow feature is the ability to decouple the workflow implementation, which describes the flow of data and operations to perform on that data, from the configuration settings required by the underlying execution platform. This enables the workflow to be portable, allowing it to run on different computational platforms such as an institutional HPC or cloud infrastructure, without needing to modify the workflow implementation.
We have seen earlier that it is possible to provide a
process with directives. These directives are process
specific configuration settings. Similarly, we have also provided
parameters to our workflow which are parameter configuration settings.
These configuration settings can be separated from the workflow
implementation, into a configuration file.
Configuration files
Settings in a configuration file are sets of name-value pairs
(name = value). The name is a specific
property to set, while the value can be anything you can
assign to a variable (see nextflow
scripting), for example, strings, booleans, or other variables. It
is also possible to access any variable defined in the host environment
such as $PATH, $HOME, $PWD,
etc.
Accessing variables in your configuration file
Settings are also partitioned into scopes, which govern the behaviour
of different elements of the workflow. For example, workflow parameters
are governed from the params scope, while process
directives are governed from the process scope. A full list
of the available scopes can be found in the documentation.
It is also possible to define your own scope.
Configuration settings for a workflow are often stored in the file
nextflow.config which is in the same directory as the
workflow script. Configuration can be written in either of two ways. The
first is using dot notation, and the second is using brace notation.
Both forms of notation can be used in the same configuration file.
An example of dot notation:
GROOVY
params.input = '' // The workflow parameter "input" is assigned an empty string to use as a default value
params.outdir = './results' // The workflow parameter "outdir" is assigned the value './results' to use by default.An example of brace notation:
Configuration files can also be separated into multiple files and
included into another using the includeConfig
statement.
How configuration files are combined
Configuration settings can be spread across several files. This also allows settings to be overridden by other configuration files. The priority of a setting is determined by the following order, ranked from highest to lowest.
- Parameters specified on the command line
(
--param_name value). - Parameters provided using the
-params-fileoption. - Config file specified using the
-cmy_config option. - The config file named
nextflow.configin the current directory. - The config file named
nextflow.configin the workflow project directory ($projectDir: the directory where the script to be run is located). - The config file
$HOME/.nextflow/config. - Values defined within the workflow script itself (e.g.,
main.nf).
If configuration is provided by more than one of these methods, configuration is merged giving higher priority to configuration provided higher in the list.
Existing configuration can be completely ignored by using
-C <custom.config> to use only configuration provided
in the custom.config file.
Configuring Nextflow vs Configuring a Nextflow workflow
Parameters starting with a single dash - (e.g.,
-c my_config.config) are configuration options for
nextflow, while parameters starting with a double dash
-- (e.g., --outdir) are workflow parameters
defined in the params scope.
The majority of Nextflow configuration settings must be provided on
the command-line, however a handful of settings can also be provided
within a configuration file, such as
workdir = '/path/to/work/dir'
(-w /path/to/work/dir) or resume = true
(-resume), and do not belong to a configuration scope.
Determine script output
Determine the outcome of the following script executions. Given the
script print_message.nf:
GROOVY
nextflow.enable.dsl = 2
params.message = 'hello'
workflow {
PRINT_MESSAGE(params.message)
}
process PRINT_MESSAGE {
echo true
input:
val my_message
script:
"""
echo $my_message
"""
}and configuration (print_message.config):
params.message = 'Are you tired?'What is the outcome of the following commands?
nextflow run print_message.nfnextflow run print_message.nf --message '¿Que tal?'nextflow run print_message.nf -c print_message.confignextflow run print_message.nf -c print_message.config --message '¿Que tal?'
- ‘hello’ - Workflow script uses the value in
print_message.nf - ‘¿Que tal?’ - The command-line parameter overrides the script setting.
- ‘Are you tired?’ - The configuration overrides the script setting
- ‘¿Que tal?’ - The command-line parameter overrides both the script and configuration settings.
Configuring process behaviour
Earlier we saw that process directives allow the
specification of settings for the task execution such as
cpus, memory, conda and other
resources in the pipeline script. This is useful when prototyping a
small workflow script, however this ties the configuration to the
workflow, making it less portable. A good practice is to separate the
process configuration settings into another file.
The process configuration scope allows the setting of
any process directives in the Nextflow configuration file.
For example:
GROOVY
// nextflow.config
process {
cpus = 2
memory = 8.GB
time = '1 hour'
publishDir = [ path: params.outdir, mode: 'copy' ]
}Unit values
Memory and time duration units can be specified either using a string based notation in which the digit(s) and the unit can be separated by a space character, or by using the numeric notation in which the digit(s) and the unit are separated by a dot character and not enclosed by quote characters.
| String syntax | Numeric syntax | Value |
|---|---|---|
| ‘10 KB’ | 10.KB | 10240 bytes |
| ‘500 MB’ | 500.MB | 524288000 bytes |
| ‘1 min’ | 1.min | 60 seconds |
| ‘1 hour 25 sec’ | - | 1 hour and 25 seconds |
These settings are applied to all processes in the workflow. A process selector can be used to apply the configuration to a specific process or group of processes.
Process selectors
The resources for a specific process can be defined using
withName: followed by the process name e.g.,
'FASTQC', and the directives within curly braces. For
example, we can specify different cpus and
memory resources for the processes INDEX and
FASTQC as follows:
GROOVY
// process_resources.config
process {
withName: INDEX {
cpus = 4
memory = 8.GB
}
withName: FASTQC {
cpus = 2
memory = 4.GB
}
}When a workflow has many processes, it is inconvenient to specify
directives for all processes individually, especially if directives are
repeated for groups of processes. A helpful strategy is to annotate the
processes using the label directive (processes can have
multiple labels). The withLabel selector then allows the
configuration of all processes annotated with a specific label, as shown
below:
GROOVY
// configuration_process_labels.nf
process P1 {
label "big_mem"
script:
"""
echo P1: Using $task.cpus cpus and $task.memory memory.
"""
}
process P2 {
label "big_mem"
script:
"""
echo P2: Using $task.cpus cpus and $task.memory memory.
"""
}
workflow {
P1()
P2()
}GROOVY
// configuration_process-labels.config
process {
withLabel: big_mem {
cpus = 16
memory = 64.GB
}
}Another strategy is to use process selector expressions. Both
withName: and withLabel: allow the use of
regular expressions to apply the same configuration to all processes
matching a pattern. Regular expressions must be quoted, unlike simple
process names or labels.
- The
|matches either-or, e.g.,withName: 'INDEX|FASTQC'applies the configuration to any process matching the nameINDEXorFASTQC. - The
!inverts a selector, e.g.,withLabel: '!small_mem'applies the configuration to any process without thesmall_memlabel. - The
.*matches any number of characters, e.g.,withName: 'NFCORE_RNASEQ:RNA_SEQ:BAM_SORT:.*'matches all processes of the workflowNFCORE_RNASEQ:RNA_SEQ:BAM_SORT.
A regular expression cheat-sheet can be found here if you would like to write more expressive expressions.
Selector priority
When mixing generic process configuration and selectors, the following priority rules are applied (from highest to lowest):
-
withNameselector definition. -
withLabelselector definition. - Process specific directive defined in the workflow script.
- Process generic
processconfiguration.
Process selectors
Create a Nextflow config, process-selector.config,
specifying different cpus and memory resources
for the two processes P1 (cpus 1 and memory 2.GB) and
P2 (cpus 2 and memory 1.GB), where P1 and
P2 are defined as follows:
GROOVY
// process-selector.config
process {
withName: P1 {
cpus = 1
memory = 2.GB
}
withName: P2 {
cpus = 2
memory = 1.GB
}
}OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `process-selector.nf` [clever_borg] -
revision: e765b9e62d
executor > local (2)
[de/86cef0] process > P1 [100%] 1 of 1 ✔
[bf/8b332e] process > P2 [100%] 1 of 1 ✔
P2: Using 2 cpus and 1 GB memory.
P1: Using 1 cpus and 2 GB memory.Dynamic expressions
A common scenario is that configuration settings may depend on the
data being processed. Such settings can be dynamically expressed using a
closure. For example, we can specify the memory required as
a multiple of the number of cpus. Similarly, we can publish
results to a subfolder based on the sample name.
Configuring execution platforms
Nextflow supports a wide range of execution platforms, from running locally, to running on HPC clusters or cloud infrastructures. See https://www.nextflow.io/docs/latest/executor.html for the full list of supported executors.

The default executor configuration is defined within the
executor scope (https://www.nextflow.io/docs/latest/config.html#scope-executor).
For example, in the config below we specify the executor as Sun Grid
Engine, sge and the number of tasks the executor will
handle in a parallel manner (queueSize) to 10.
The process.executor directive allows you to override
the executor to be used by a specific process. This can be useful, for
example, when there are short running tasks that can be run locally, and
are unsuitable for submission to HPC executors (check for guidelines on
best practice use of your execution system). Other process directives
such as process.clusterOptions, process.queue,
and process.machineType can be also be used to further
configure processes depending on the executor used.
Configuring software requirements
An important feature of Nextflow is the ability to manage software
using different technologies. It supports the Conda package management
system, and container engines such as Docker, Singularity, Podman,
Charliecloud, and Shifter. These technologies allow one to package tools
and their dependencies into a software environment such that the tools
will always work as long as the environment can be loaded. This
facilitates portable and reproducible workflows. Software environment
specification is managed from the process scope, allowing
the use of process selectors to manage which processes load which
software environment. Each technology also has its own scope to provide
further technology specific configuration settings.
Software configuration using Conda
Conda is a software package and environment management system that runs on Linux, Windows, and Mac OS. Software packages are bundled into Conda environments along with their dependencies for a particular operating system (Not all software is supported on all operating systems). Software packages are tied to conda channels, for example, bioinformatic software packages are found and installed from the BioConda channel.
A Conda environment can be configured in several ways:
- Provide a path to an existing Conda environment.
- Provide a path to a Conda environment specification file (written in YAML).
- Specify the software package(s) using the
<channel>::<package_name>=<version>syntax (separated by spaces), which then builds the Conda environment when the process is run.
GROOVY
process {
conda = "/home/user/miniconda3/envs/my_conda_env"
withName: FASTQC {
conda = "environment.yml"
}
withName: SALMON {
conda = "bioconda::salmon=1.5.2"
}
}There is an optional conda scope which allows you to
control the creation of a Conda environment by the Conda package
manager. For example, conda.cacheDir specifies the path
where the Conda environments are stored. By default this is in
conda folder of the work directory.
Define a software requirement in the configuration file using conda
We are going to define a software requirement using the “conda” directive.
The software we are going to uses is fastp, a tool used
for fast processing of next-generation sequencing data (like RNA or DNA
sequences).
Each time the process is called we are going to run
fastp -A -i ${read} -o out.fq 2>&1
-
fastpis the main command that invokes the fastp program. - -A: option tells fastp to automatically detect and trim adapters. Adapters are short, artificially added sequences used in sequencing that are not part of the target DNA or RNA. -i ${read}:
- The
-iflag specifies the input file.${read}represents a nextflow variable that contains the path to the sequencing reads. -
-o: The-oflag specifies the output file. In this case, the processed sequencing data will be written to a file namedout.fq. -
2>&1: This is a shell redirection command, it means that both the regular output and error messages will be sent to the console.
Create a config file for the Nextflow script
configuration_fastp.nf.Add a conda directive for the process name
FASTPthat includes the bioconda packagefastp, version 0.12.4-0.
Hint You can specify the conda packages using the
syntax
<channel>::<package_name>=<version>
e.g. bioconda::salmon=1.5.2
- Run the Nextflow script
configure_fastp.nfwith the configuration file using the-coption.
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `configuration_fastp.nf` [berserk_jepsen] - revision: 28fadd2486
executor > local (1)
[c1/c207d5] process > FASTP (1) [100%] 1 of 1 ✔
Creating Conda env: bioconda::fastp=0.12.4-0 [cache /home/training/work/conda/env-a7a3a0d820eb46bc41ebf4f72d955e5f]
ref1_1.fq.gz 58708
Read1 before filtering:
total reads: 14677
total bases: 1482377
Q20 bases: 1466210(98.9094%)
Q30 bases: 1415997(95.5221%)
Read1 after filtering:
total reads: 14671
total bases: 1481771
Q20 bases: 1465900(98.9289%)
Q30 bases: 1415769(95.5457%)
Filtering result:
reads passed filter: 14671
reads failed due to low quality: 6
reads failed due to too many N: 0
reads failed due to too short: 0
JSON report: fastp.json
HTML report: fastp.htmlSoftware configuration using Docker
Docker is a container technology. Container images are lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. Containerized software is intended to run the same regardless of the underlying infrastructure, unlike other package management technologies which are operating system dependant (See the published article on Nextflow). For each container image used, Nextflow uses Docker to spawn an independent and isolated container instance for each process task.
To use Docker, we must provide a container image path using the
process.container directive, and also enable docker in the
docker scope, docker.enabled = true. A container image path
takes the form
(protocol://)registry/repository/image:version--build. By
default, Docker containers run software using a privileged user. This
can cause issues, and so it is also a good idea to supply your user and
group via the docker.runOptions.
The Docker run option -u $(id -u):$(id -g) is used to
specify the user and group IDs (UID and GID) that the container should
use when running. This option ensures that the processes inside the
container run with the same UID and GID as the user executing the Docker
command on the host system.
Software configuration using Singularity
Singularity is another container technology, commonly used on HPC
clusters. It is different to Docker in several ways. The primary
differences are that processes are run as the user, and certain
directories are automatically “mounted” (made available) in the
container instance. Singularity also supports building Singularity
images from Docker images, allowing Docker image paths to be used as
values for process.container.
Singularity is enabled in a similar manner to Docker. A container
image path must be provided using process.container and
singularity enabled using singularity.enabled = true.
GROOVY
process.container = 'https://depot.galaxyproject.org/singularity/salmon:1.5.2--h84f40af_0'
singularity.enabled = trueContainer protocols
The following protocols are supported:
-
docker://: download the container image from the Docker Hub and convert it to the Singularity format (default). -
library://: download the container image from the Singularity Library service. -
shub://: download the container image from the Singularity Hub. -
docker-daemon://: pull the container image from a local Docker installation and convert it to a Singularity image file. -
https://: download the singularity image from the given URL. -
file://: use a singularity image on local computer storage.
Configuration profiles
One of the most powerful features of Nextflow configuration is to
predefine multiple configurations or profiles for different
execution platforms. This allows a group of predefined settings to be
called with a short invocation,
-profile <profile name>.
Configuration profiles are defined in the profiles
scope, which group the attributes that belong to the same profile using
a common prefix.
GROOVY
//configuration_profiles.config
profiles {
standard {
params.genome = '/local/path/ref.fasta'
process.executor = 'local'
}
cluster {
params.genome = '/data/stared/ref.fasta'
process.executor = 'sge'
process.queue = 'long'
process.memory = '10GB'
process.conda = '/some/path/env.yml'
}
cloud {
params.genome = '/data/stared/ref.fasta'
process.executor = 'awsbatch'
process.container = 'cbcrg/imagex'
docker.enabled = true
}
}This configuration defines three different profiles:
standard, cluster and cloud that
set different process configuration strategies depending on the target
execution platform. By convention the standard profile is implicitly
used when no other profile is specified by the user. To enable a
specific profile use -profile option followed by the
profile name:
Configuration order
Settings from profiles will override general settings in the
configuration file. However, it is also important to remember that
configuration is evaluated in the order it is read in. For example, in
the following example, the publishDir directive will always
take the value ‘results’ even when the profile hpc is used.
This is because the setting is evaluated before Nextflow knows about the
hpc profile. If the publishDir directive is
moved to after the profiles scope, then
publishDir will use the correct value of
params.results.
Key Points
- Nextflow configuration can be managed using a Nextflow configuration file.
- Nextflow configuration files are plain text files containing a set of properties.
- You can define process specific settings, such as cpus and memory,
within the
processscope. - You can assign different resources to different processes using the
process selectors
withNameorwithLabel. - You can define a profile for different configurations using the
profilesscope. These profiles can be selected when launching a pipeline execution by using the-profilecommand-line option - Nextflow configuration settings are evaluated in the order they are read-in.
Content from Workflow caching and checkpointing
Last updated on 2024-08-21 | Edit this page
Overview
Questions
- How can I restart a Nextflow workflow after an error?
- How can I add new data to a workflow without starting from the beginning?
- Where can I find intermediate data and results?
Objectives
- Resume a Nextflow workflow using the
-resumeoption. - Restart a Nextflow workflow using new data.
A key feature of workflow management systems, like Nextflow, is re-entrancy, which is the ability to restart a pipeline after an error from the last successfully executed process. Re-entrancy enables time consuming successfully completed steps, such as index creation, to be skipped when adding more data to a pipeline. This in turn leads to faster prototyping and development of workflows, and faster analyses of additional data. Nextflow achieves re-entrancy by automatically keeping track of all the processes executed in your pipeline via caching and checkpointing.
Resume
To restart from the last successfully executed process we add the
command line option -resume to the Nextflow command.
For example, the command below would resume the
word_count.nf script from the last successful process.
We can see in the output that the results from the process
NUM_LINES has been retrieved from the cache.
OUTPUT
Launching `word_count.nf` [condescending_dalembert] - revision: fede04a544
[c9/2597d5] process > NUM_LINES (1) [100%] 2 of 2, cached: 2 ✔
ref1_1.fq.gz 58708
ref1_2.fq.gz 58708Resume a pipeline
Resume the Nextflow script word_count.nf by re-running
the command and adding the parameter -resume and the
parameter --input 'data/yeast/reads/temp33*':
If your previous run was successful the output will look similar to this:
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `word_count.nf` [nauseous_leavitt] - revision: fede04a544
[21/6116de] process > NUM_LINES (4) [100%] 6 of 6, cached: 6 ✔
temp33_3_2.fq.gz 88956
temp33_3_1.fq.gz 88956
temp33_1_1.fq.gz 82372
temp33_2_2.fq.gz 63116
temp33_1_2.fq.gz 82372
temp33_2_1.fq.gz 63116You will see that the execution of the process NUMLINES
is actually skipped (cached text appears), and the results are retrieved
from the cache.
How does resume work?
Nextflow stores all intermediate files and task results during the
execution of a workflow is work directory. It acts as a
scratch space where all the temporary data required for the workflow’s
execution is kept. Within the work directory, Nextflow creates
subdirectories named with unique hashes (e.g., work/ab/cd1234…). Each of
these subdirectories corresponds to a specific process or task in the
pipeline. The hashed directory names ensure that each task’s outputs are
isolated and uniquely identified.
The mechanism works by assigning a unique ID to each task. This
unique ID is used to create a separate execution directory, within the
work directory, where the tasks are executed and the
results stored. A task’s unique ID is generated as a 128-bit hash number
obtained from a composition of the task’s:
- Inputs values
- Input files
- Command line string
- Container ID
- Conda environment
- Environment modules
- Any executed scripts in the bin directory
When we resume a workflow Nextflow uses this unique ID to check if:
- The working directory exists
- It contains a valid command exit status
- It contains the expected output files.
If these conditions are satisfied, the task execution is skipped and the previously computed outputs are applied. When a task requires recomputation, ie. the conditions above are not fulfilled, the downstream tasks are automatically invalidated.
Therefore, if you modify some parts of your script, or alter the
input data using -resume, will only execute the processes
that are actually changed.
The execution of the processes that are not changed will be skipped and the cached result used instead.
This helps a lot when testing or modifying part of your pipeline without having to re-execute it from scratch.
Modify Nextflow script and re-run.
The output will look similar to this:
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `word_count.nf` [gigantic_minsky] - revision: fede04a544
executor > local (1)
[20/cda0d5] process > NUM_LINES (5) [100%] 6 of 6, cached: 5 ✔
temp33_1_2.fq.gz 82372
temp33_3_1.fq.gz 88956
temp33_2_1.fq.gz 63116
temp33_1_1.fq.gz 82372
temp33_2_2.fq.gz 63116
temp33_3_2.fq.gz 88956As you changed the timestamp on one file it will only re-run that process. The results for the other 5 processes are retrieved from the cache.
The Work directory
By default the pipeline results are cached in the directory
work where the pipeline is launched.
We can use the Bash tree command to list the contents of
the work directory. Note: By default tree does not
print hidden files (those beginning with a dot .). Use the
-a to view all files.
Example output
OUTPUT
work/
├── 12
│ └── 5489f3c7dbd521c0e43f43b4c1f352
│ ├── .command.begin
│ ├── .command.err
│ ├── .command.log
│ ├── .command.out
│ ├── .command.run
│ ├── .command.sh
│ ├── .exitcode
│ └── temp33_1_2.fq.gz -> /home/training/data/yeast/reads/temp33_1_2.fq.gz
├── 3b
│ └── a3fb24ad3242e4cc8e5aa0c24d174b
│ ├── .command.begin
│ ├── .command.err
│ ├── .command.log
│ ├── .command.out
│ ├── .command.run
│ ├── .command.sh
│ ├── .exitcode
│ └── temp33_2_1.fq.gz -> /home/training/data/yeast/reads/temp33_2_1.fq.gz
├── 4c
│ └── 125b5e5a5ee144fa25dd9bccd467e9
│ ├── .command.begin
│ ├── .command.err
│ ├── .command.log
│ ├── .command.out
│ ├── .command.run
│ ├── .command.sh
│ ├── .exitcode
│ └── temp33_3_1.fq.gz -> /home/training/data/yeast/reads/temp33_3_1.fq.gz
├── 54
│ └── eb9d72e9ac24af8183de569ab0b977
│ ├── .command.begin
│ ├── .command.err
│ ├── .command.log
│ ├── .command.out
│ ├── .command.run
│ ├── .command.sh
│ ├── .exitcode
│ └── temp33_2_2.fq.gz -> /home/training/data/yeast/reads/temp33_2_2.fq.gz
├── e9
│ └── 31f28c291481342cc45d4e176a200a
│ ├── .command.begin
│ ├── .command.err
│ ├── .command.log
│ ├── .command.out
│ ├── .command.run
│ ├── .command.sh
│ ├── .exitcode
│ └── temp33_1_1.fq.gz -> /home/training/data/yeast/reads/temp33_1_1.fq.gz
└── fa
└── cd3e49b63eadd6248aa357083763c1
├── .command.begin
├── .command.err
├── .command.log
├── .command.out
├── .command.run
├── .command.sh
├── .exitcode
└── temp33_3_2.fq.gz -> /home/training/data/yeast/reads/temp33_3_2.fq.gzTask execution directory
Within the work directory there are multiple task
execution directories. There is one directory for each time a process is
executed. These task directories are identified by the process execution
hash. For example the task directory
fa/cd3e49b63eadd6248aa357083763c1 would be location for the
process identified by the hash fa/cd3e49 .
The task execution directory contains:
.command.sh: The command script. The.command.shfile includes the specific instructions you’ve written to process your data or perform computations..command.run: A Bash script generated by Nextflow to manage the execution environment of the.command.shscript. This script acts as a wrapper around .command.sh. It performs several tasks like setting up the task’s environment variables, handling the task’s pre and post execution (like moving inputs and outputs to correct locations, logging start and end times, handling errors, and ensuring resource limits are respected.command.out: The complete job standard output..command.err: The complete job standard error..command.log: The wrapper execution output..command.begin: A file created as soon as the job is launched..exitcode: A file containing the task exit code. This file is used to capture and store the exit status of the process that was run by the .command.sh script.Any task input files (symlinks)
Any task output files
Specifying another work directory
Depending on your script, this work folder can take a lot of disk
space. You can specify another work directory using the command line
option -w. Note Using a different work
directory will mean that any jobs will need to re-run from the
beginning.
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `word_count.nf` [deadly_easley] - revision: fede04a544
executor > local (6)
[9d/0f5e89] process > NUM_LINES (5) [100%] 6 of 6 ✔
temp33_3_2.fq.gz 88956
temp33_1_1.fq.gz 82372
temp33_3_1.fq.gz 88956
temp33_1_2.fq.gz 82372
temp33_2_2.fq.gz 63116
temp33_2_1.fq.gz 63116Clean the work directory
If you are sure you won’t resume your pipeline execution, clean this
folder periodically using the command nextflow clean.
Supply the option -n to print names of files to be
removed without deleting them, or -f to force the removal
of the files. If you only want to remove files from a run but retain
execution log entries and metadata, add the option -k.
Multiple runs can be cleaned with the options, -before,
-after or -but before the run name. For
example, the command below would remove all the temporary files and log
entries for runs before the run gigantic_minsky.
Remove a Nextflow run.
Remove the last Nextflow run using the command
nextflow clean. First use the option -dry-run
to see which files would be deleted and then re-run removing the run and
associated files.
Key Points
- Nextflow automatically keeps track of all the processes executed in your pipeline via checkpointing.
- Nextflow caches intermediate data in task directories within the work directory.
- Nextflow caching and checkpointing allows re-entrancy into a workflow after a pipeline error or using new data, skipping steps that have been successfully executed.
- Re-entrancy is enabled using the
-resumeoption.
Content from Simple RNA-Seq pipeline
Last updated on 2024-09-27 | Edit this page
Overview
Questions
- How can I create a Nextflow pipeline from a series of unix commands and input data?
- How do I log my pipelines parameters?
- How can I manage my pipeline software requirements?
- How do I know when my pipeline has finished?
- How do I see how much resources my pipeline has used?
Objectives
- Create a simple RNA-Seq pipeline.
- Use the
log.infofunction to print all the pipeline parameters. - Print a confirmation message when the pipeline completes.
- Use a conda
environment.ymlfile to install the pipeline’s software requirement. - Produce an execution report and generate run metrics from a pipeline run.
We’re now set to develop a multi-step pipeline using Nextflow, for analyzing and performing quality control on our yeast RNA-Seq experiment.
In this RNA-Seq pipeline, we’ll undertake the following steps to thoroughly analyze gene expression data:
- Quality Control with FastQC: FastQC assesses the quality of the data by generating reports that highlight any potential issues, such as low-quality sequences or contamination. FastQC’s output includes an HTML report and a directory containing detailed analyses, which are essential for evaluating the integrity of the sequencing data.
- Transcriptome Indexing with Salmon: Salmon is a tool to quantify transcript expression in RNA-seq data. The first step in the process is for Salmon to create an index of the transcriptome. This step involves processing a reference transcriptome, which allows for efficient and accurate mapping and quantification of RNA-Seq reads.
- Quantification with Salmon: After indexing, Salmon is used for the quantification step. In this step, Salmon maps the reads to the transcriptome index and quantifies the transcript abundances. This process is crucial for determining the expression levels of genes in the sample.
- Aggregating Reports with MultiQC: Finally, the pipeline employs MultiQC to aggregate logs and outputs from the FastQC and Salmon. MultiQC scans the outputs and compiles a summary report, which provides an overview of the results and highlights any areas that may need further investigation.
This pipeline provides an overview of RNA-Seq data, from quality control to expression quantification, culminating in an aggregated report for easy interpretation of the results.
To start move the episode’s nextflow scripts in the
scripts/rnaseq_pipeline folder to your home directory.
This folder contains files we will be modifying in this episode.
Define the pipeline parameters
The first thing we want to do when writing a pipeline is define the
pipeline parameters. The script script1.nf defines the
pipeline input parameters.
GROOVY
//script1.nf
params.reads = "data/yeast/reads/*_{1,2}.fq.gz"
params.transcriptome = "data/yeast/transcriptome/*.fa.gz"
println "reads: $params.reads"Run it by using the following command:
We can specify a different input parameter using the
--<params> option, for example :
OUTPUT
reads: data/yeast/reads/ref1*_{1,2}.fq.gzAdd a parameter
Modify the script1.nf adding a third parameter named
outdir and set it to results. This parameter
will be used as the pipeline output directory.
It can be useful to print the pipeline parameters to the screen. This
can be done using the the log.info command and a multiline
string statement. The string method .stripIndent() command
is used to remove the indentation on multi-line strings.
log.info also saves the output to the log execution file
.nextflow.log.
log.info
Modify the script1.nf to print all the pipeline
parameters by using a single log.info command and a
multiline string statement. See an example here.
Look at the output log .nextflow.log.
Create a transcriptome index file
Nextflow allows the execution of any command or user script by using
a process definition.
For example,
A process is defined by providing three main declarations:
The second example, script2.nf adds,
- The process
INDEXwhich generate a directory with the index of the transcriptome. This process takes one input, a transcriptome file, and emits one output a salmon index directory. - A queue Channel
transcriptome_chtaking the transcriptome file defined in params variableparams.transcriptome. - Finally the script adds a
workflowdefinition block which calls theINDEXprocess.
GROOVY
//script2.nf
/*
* pipeline input parameters
*/
params.reads = "data/yeast/reads/*_{1,2}.fq.gz"
params.transcriptome = "data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
params.outdir = "results"
println """\
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: ${params.transcriptome}
reads : ${params.reads}
outdir : ${params.outdir}
"""
.stripIndent()
/*
* define the `INDEX` process that create a binary index
* given the transcriptome file
*/
process INDEX {
input:
path transcriptome
output:
path 'index'
script:
"""
salmon index --threads $task.cpus -t $transcriptome -i index
"""
}
transcriptome_ch = channel.fromPath(params.transcriptome)
workflow {
INDEX()
}Try to run it by using the command:
OUTPUT
N E X T F L O W ~ version 22.04.0
Launching `script2.nf` [happy_brown] DSL2 - revision: 90e932bb8d
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
reads : data/yeast/reads/*_{1,2}.fq.gz
outdir : results
Process `INDEX` declares 1 input channel but 0 were specified
-- Check script 'script2.nf' at line: 41 or see '.nextflow.log' file for more detailsThe execution will fail because the program the process,
INDEX , has not been passed any input channel.
Add the transcriptome_ch channel to the
INDEX process call.
Now try to run it again by using the command:
Now the workflow will run successfully.
OUTPUT
N E X T F L O W ~ version 22.04.0
Launching `script2.nf` [mad_aryabhata] DSL2 - revision: 811396b67b
R N A S E Q - N F P I P E L I N E
===================================
transcriptome:data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
reads : data/yeast/reads/*_{1,2}.fq.gz
outdir : results
executor > local (1)
[c0/418d78] process > INDEX (1) [100%] 1 of 1 ✔
The INDEX process also defines one output
channel. This channel will be populated with index
directory created during process. To view the contents of the channel we
can use the view operator.
View the contents of the index_ch
- Assign the output of the
INDEXprocess to the variableindex_ch. - View the contents of the
index_chchannel by using theviewoperator.
Collect read files by pairs
This step shows how to match read files into pairs, so they can be mapped by salmon.
The script script3.nf adds a line to create a channel,
read_pairs_ch, containing fastq read pair files using the
fromFilePairs channel factory.
GROOVY
//script3.nf
nextflow.enable.dsl = 2
/*
* pipeline input parameters
*/
params.reads = "data/yeast/reads/ref1_{1,2}.fq.gz"
params.transcriptome = "data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz"
params.outdir = "results"
log.info """\
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: ${params.transcriptome}
reads : ${params.reads}
outdir : ${params.outdir}
"""
.stripIndent()
read_pairs_ch = Channel.fromFilePairs( params.reads )We can view the contents of the read_pairs_ch by adding
the following statement as the last line:
Now if we execute it with the following command:
It will print an output similar to the one shown below that shows how
the read_pairs_ch channel emits a tuple. The tuple is
composed of two elements, where the first is the pattern matched by the
glob pattern data/yeast/reads/ref1_{1,2}.fq.g, defined by
the variable params.reads , and the second is a list
representing the actual files.
OUTPUT
[..truncated..]
[ref1, [data/yeast/reads/ref1_1.fq.gz,data/yeast/reads/ref1_2.fq.gz]]To read in other read pairs we can specify a different glob pattern
in the params.reads variable by using --reads
options on the command line. For example, the following command would
read in add the ref samples:
OUTPUT
[..truncated..]
[ref2, [data/yeast/reads/ref2_1.fq.gz, data/yeast/reads/ref2_2.fq.gz]]
[ref3, [data/yeast/reads/ref3_1.fq.gz, data/yeast/reads/ref3_2.fq.gz]]
[ref1, [data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz]]Note File paths including one or more wildcards ie.
*, ?, etc. MUST be wrapped in single-quoted
characters to avoid Bash expanding the glob pattern on the command
line.
We can also add a argument, checkIfExists: true , to the
fromFilePairs channel factory to return an message if the
file doesn’t exist.
GROOVY
//script3.nf
[..truncated..]
read_pairs_ch = Channel.fromFilePairs( params.reads, checkIfExists: true )If we now run the script with the --reads parameter
data/yeast/reads/*_1,2}.fq.gz
it will return the message .
OUTPUT
[..truncated..]
No such file: data/yeast/reads/*_1,2}.fq.gzRead in all read pairs
- Add the
checkIfExists: trueargument to thefromFilePairschannel factory inscript3.nf. - Using the command line parameter
--reads, add a glob pattern to read in all the read pairs files from thedata/yeast/readsdirectory.
OUTPUT
[..truncated..]
[temp33_1, [data/yeast/reads/temp33_1_1.fq.gz, data/yeast/reads/temp33_1_2.fq.gz]]
[ref2, [data/yeast/reads/ref2_1.fq.gz, data/yeast/reads/ref2_2.fq.gz]]
[temp33_3, [data/yeast/reads/temp33_3_1.fq.gz, data/yeast/reads/temp33_3_2.fq.gz]]
[ref3, [data/yeast/reads/ref3_1.fq.gz, data/yeast/reads/ref3_2.fq.gz]]
[temp33_2, [data/yeast/reads/temp33_2_1.fq.gz,data/yeast/reads/temp33_2_2.fq.gz]]
[etoh60_2, [data/yeast/reads/etoh60_2_1.fq.gz,data/yeast/reads/etoh60_2_2.fq.gz]]
[ref1, [data/yeast/reads/ref1_1.fq.gz, data/yeast/reads/ref1_2.fq.gz]]
[etoh60_3, [data/yeast/reads/etoh60_3_1.fq.gz, data/yeast/reads/etoh60_3_2.fq.gz]]
[etoh60_1, [data/yeast/reads/etoh60_1_1.fq.gz, data/yeast/reads/etoh60_1_2.fq.gz]]Perform expression quantification
The script script4.nf;
- Adds the quantification process,
QUANT. - Calls the
QUANTprocess in the workflow block.
GROOVY
//script4.nf
..truncated..
/*
* Run Salmon to perform the quantification of expression using
* the index and the matched read files
*/
process QUANT {
input:
each index
tuple val(pair_id), path(reads)
output:
path(pair_id)
script:
"""
salmon quant --threads $task.cpus --libType=U -i $index -1 ${reads[0]} -2 ${reads[1]} -o $pair_id
"""
}
..truncated..
workflow {
read_pairs_ch = Channel.fromFilePairs( params.reads, checkIfExists:true )
transcriptome_ch = Channel.fromPath( params.transcriptome, checkIfExists:true )
index_ch=INDEX(transcriptome_ch)
quant_ch=QUANT(index_ch,read_pairs_ch)
}The index_ch channel, declared as output in the
INDEX process, is used as the first input argument to the
QUANT process.
The second input argument of the QUANT process, the
read_pairs_ch channel, is a tuple composed of two elements:
the pair_id and the reads.
Execute it by using the following command:
You will see the execution of the index and quantification process.
Re run the command using the -resume option
The -resume option cause the execution of any step that
has been already processed to be skipped.
Try to execute it with more read files as shown below:
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `script4.nf` [shrivelled_brenner] - revision: c21df6839e
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: data/yeast/transcriptome/Saccharomyces_c
erevisiae.R64-1-1.cdna.all.fa.gz
reads : data/yeast/reads/ref*_{1,2}.fq.gz
outdir : results
executor > local (8)
[02/3742cf] process > INDEX [100%] 1 of 1, cached: 1 ✔
[9a/be3483] process > QUANT (9) [100%] 3 of 3, cached: 1 ✔You will notice that the INDEX step and one of the
QUANT steps has been cached, and the quantification process
is executed more than one time.
When your input channel contains multiple data items Nextflow, where possible, parallelises the execution of your pipeline.
In these situations it is useful to add a tag directive
to add some descriptive text to instance of the process being run.
Add a tag directive
Add a tag directive to the QUANT process of
script4.nf to provide a more readable execution log.
Data produced by the workflow during a process will be saved in the
working directory, by default a directory named work. The
working directory should be considered a temporary storage space and any
data you wish to save at the end of the workflow should be specified in
the process output with the final storage location defined in the
publishDir directive.
Note: by default the publishDir
directive creates a symbolic link to the files in the working this
behaviour can be changed using the mode parameter.
Add a publishDir directive
Add a publishDir directive to the quantification process
of script4.nf to store the process results into folder
specified by the params.outdir Nextflow variable. Include
the publishDir mode option to copy the
output.
Challenge
Recap
In this step you have learned:
How to connect two processes by using the channel declarations.
How to resume the script execution skipping already already computed steps.
How to use the
tagdirective to provide a more readable execution output.How to use the
publishDirto store a process results in a path of your choice.
Quality control
This step implements a quality control step for your input reads. The
input to the FASTQC process is the same
read_pairs_ch that is provided as input to the
quantification process QUANT .
GROOVY
//script5.nf
[..truncated..]
/*
* Run fastQC to check quality of reads files
*/
process FASTQC {
tag "FASTQC on $sample_id"
cpus 1
input:
tuple val(sample_id), path(reads)
output:
path("fastqc_${sample_id}_logs")
script:
"""
mkdir fastqc_${sample_id}_logs
fastqc -o fastqc_${sample_id}_logs -f fastq -q ${reads} -t ${task.cpus}
"""
}
[..truncated..]
workflow {
read_pairs_ch = Channel.fromFilePairs( params.reads, checkIfExists:true )
transcriptome_ch = Channel.fromPath( params.transcriptome, checkIfExists:true )
index_ch=INDEX(transcriptome_ch)
quant_ch=QUANT(index_ch,read_pairs_ch)
}Run the script script5.nf by using the following
command:
The FASTQC process will not run as the process has not
been declared in the workflow scope.
MultiQC report
This step collect the outputs from the quantification and fastqc steps to create a final report by using the MultiQC tool.
The input for the MULTIQC process requires all data in a
single channel element. Therefore, we will need to combine the
FASTQC and QUANT outputs using:
- The combining operator
mix: combines the items in the two channels into a single channel
GROOVY
//example of the mix operator
ch1 = Channel.of(1,2)
ch2 = Channel.of('a')
ch1.mix(ch2).view()OUTPUT
1
2
a- The transformation operator
collectcollects all the items in the new combined channel into a single item.
OUTPUT
[1, 2, 3]Combining operators
Which is the correct way to combined mix and
collect operators so that you have a single channel with
one List item?
quant_ch.mix(fastqc_ch).collect()quant_ch.collect(fastqc_ch).mix()fastqc_ch.mix(quant_ch).collect()fastqc_ch.collect(quant_ch).mix()
You need to use the mix operator first to combine the
channels followed by the collect operator to collect all
the items in a single item.
In script6.nf we use the statement
quant_ch.mix(fastqc_ch).collect() to combine and collect
the outputs of the QUANT and FASTQC process to
create the required input for the MULTIQC process.
GROOVY
[..truncated..]
//script6.nf
/*
* Create a report using multiQC for the quantification
* and fastqc processes
*/
process MULTIQC {
publishDir "${params.outdir}/multiqc", mode:'copy'
input:
path('*')
output:
path('multiqc_report.html')
script:
"""
multiqc .
"""
}
workflow {
read_pairs_ch = Channel.fromFilePairs( params.reads, checkIfExists:true )
transcriptome_ch = Channel.fromPath( params.transcriptome, checkIfExists:true )
index_ch=INDEX(transcriptome_ch)
quant_ch=QUANT(index_ch,read_pairs_ch)
fastqc_ch=FASTQC(read_pairs_ch)
MULTIQC(quant_ch.mix(fastqc_ch).collect())
}Execute the script with the following command:
OUTPUT
N E X T F L O W ~ version 21.04.0
Launching `script6.nf` [small_franklin] - revision: 9062818659
R N A S E Q - N F P I P E L I N E
===================================
transcriptome: data/yeast/transcriptome/Saccharomyces_cerevisiae.R64-1-1.cdna.all.fa.gz
reads : data/yeast/reads/*_{1,2}.fq.gz
outdir : results
executor > local (9)
[02/3742cf] process > INDEX [100%] 1 of 1, cached: 1 ✔
[9a/be3483] process > QUANT (quantification on etoh60_1) [100%] 9 of 9, cached: 9 ✔
[1f/b7b30a] process > FASTQC (FASTQC on etoh60_1) [100%] 9 of 9, cached: 1 ✔
[2c/206fef] process > MULTIQC [100%] 1 of 1 ✔It creates the final report in the results folder in the
${params.outdir}/multiqc directory.
Handle completion event
This step shows how to execute an action when the pipeline completes the execution.
Note: that Nextflow processes define the execution of asynchronous tasks i.e. they are not executed one after another as they are written in the pipeline script as it would happen in a common imperative programming language.
The script script7..nf uses the
workflow.onComplete event handler to print a confirmation
message when the script completes.
GROOVY
workflow.onComplete {
log.info ( workflow.success ? "\nDone! Open the following report in your browser --> $params.outdir/multiqc/multiqc_report.html\n" : "Oops .. something went wrong" )
}This code uses the ternary operator that is a shortcut expression that is equivalent to an if/else branch assigning some value to a variable.
If expression is true? "set value to a" : "else set value to b"Try to run it by using the following command:
OUTPUT
[..truncated..]
Done! Open the following report in your browser --> results/multiqc/multiqc_report.htmlMetrics and reports
Nextflow is able to produce multiple reports and charts providing several runtime metrics and execution information.
The
-with-reportoption enables the creation of the workflow execution report.The
-with-traceoption enables the create of a tab separated file containing runtime information for each executed task, including: submission time, start time, completion time, cpu and memory used..The
-with-timelineoption enables the creation of the workflow timeline report showing how processes where executed along time. This may be useful to identify most time consuming tasks and bottlenecks. See an example at this link.The
-with-dagoption enables to rendering of the workflow execution direct acyclic graph representation. Note: this feature requires the installation of Graphviz, an open source graph visualization software, in your system.
More information can be found here.
Metrics and reports
Run the script7.nf with the reporting options as shown below:
- Open the file
report.htmlwith a browser to see the report created with the above command. - Check the content of the file
trace.txtor viewtimeline.htmlto find the longest running process. - View the dag.png
The INDEX process should be the longest running process.
dag.png  The vertices in the graph
represent the pipeline’s processes and operators, while the edges
represent the data connections (i.e. channels) between them.
The vertices in the graph
represent the pipeline’s processes and operators, while the edges
represent the data connections (i.e. channels) between them.
short running tasks
Note: runtime metrics may be incomplete for run short running tasks..
Key Points
- Nextflow can combined tasks (processes) and manage data flows using channels into a single pipeline/workflow.
- A Workflow can be parameterise using
params. These value of the parameters can be captured in a log file usinglog.info - Nextflow can handle a workflow’s software requirements using several
technologies including the
condapackage and enviroment manager. - Workflow steps are connected via their
inputsandoutputsusingChannels. - Intermediate pipeline results can be transformed using Channel
operatorssuch ascombine. - Nextflow can execute an action when the pipeline completes the
execution using the
workflow.onCompleteevent handler to print a confirmation message. - Nextflow is able to produce multiple reports and charts providing
several runtime metrics and execution information using the command line
options
-with-report,-with-trace,-with-timelineand produce a graph using-with-dag.
Content from Deploying nf-core pipelines
Last updated on 2024-07-22 | Edit this page
Overview
Questions
- Where can I find best-practice Nextflow bioinformatic pipelines?
- How do I run nf-core pipelines?
- How do I configure nf-core pipelines to use my data?
- How do I reference nf-core pipelines?
Objectives
- Understand what nf-core is and how it relates to Nextflow.
- Use the nf-core helper tool to find nf-core pipelines.
- Understand how to configuration nf-core pipelines.
- Run a small demo nf-core pipeline using a test dataset.
What is nf-core?
nf-core is a community-led project to develop a set of best-practice pipelines built using Nextflow workflow management system. Pipelines are governed by a set of guidelines, enforced by community code reviews and automatic code testing.

In this episode we will covering finding, deploying and configuring nf-core pipelines.
What are nf-core pipelines?
nf-core pipelines are an organised collection of Nextflow scripts, other non-nextflow scripts (written in any language), configuration files, software specifications, and documentation hosted on GitHub. There is generally a single pipeline for a given data and analysis type e.g. There is a single pipeline for bulk RNA-Seq. All nf-core pipelines are distributed under the, permissive free software, MIT licences.
What is nf-core tools?
nf-core provides a suite of helper tools aim to help people run and develop pipelines. The nf-core tools package is written in Python and can run from the command line or imported and used within other packages.
nf-core tools sub-commands
You can use the --help option to see the range of
nf-core tools sub-commands. In this episode we will be covering the
list, launch and download
sub-commands which aid in the finding and deployment of the nf-core
pipelines.
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
Usage: nf-core [OPTIONS] COMMAND [ARGS]...
nf-core/tools provides a set of helper tools for use with nf-core Nextflow pipelines.
It is designed for both end-users running pipelines and also developers creating new pipelines.
╭─ Options ────────────────────────────────────────────────────────────────────────────────────────╮
│ --version Show the version and exit. │
│ --verbose -v Print verbose output to the console. │
│ --hide-progress Don't show progress bars. │
│ --log-file -l <filename> Save a verbose log to a file. │
│ --help -h Show this message and exit. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Commands for users ─────────────────────────────────────────────────────────────────────────────╮
│ list List available nf-core pipelines with local info. │
│ launch Launch a pipeline using a web GUI or command line prompts. │
│ create-params-file Build a parameter file for a pipeline. │
│ download Download a pipeline, nf-core/configs and pipeline singularity images. │
│ licences List software licences for a given workflow (DSL1 only). │
│ tui Open Textual TUI. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Commands for developers ────────────────────────────────────────────────────────────────────────╮
│ create Create a new pipeline using the nf-core template. │
│ lint Check pipeline code against nf-core guidelines. │
│ modules Commands to manage Nextflow DSL2 modules (tool wrappers). │
│ subworkflows Commands to manage Nextflow DSL2 subworkflows (tool wrappers). │
│ schema Suite of tools for developers to manage pipeline schema. │
│ create-logo Generate a logo with the nf-core logo template. │
│ bump-version Update nf-core pipeline version number. │
│ sync Sync a pipeline TEMPLATE branch with the nf-core template. │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯Listing available nf-core pipelines
The simplest sub-command is nf-core list, which lists
all available nf-core pipelines in the nf-core Github repository.
The output shows the latest version number and when that was released. If the pipeline has been pulled locally using Nextflow, it tells you when that was and whether you have the latest version.
Run the command below.
An example of the output from the command is as follows:
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Pipeline Name ┃ Stars ┃ Latest Release ┃ Released ┃ Last Pulled ┃ Have latest release? ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ mcmicro │ 4 │ dev │ 2 days ago │ - │ - │
│ fastquorum │ 13 │ 1.0.0 │ 2 months ago │ - │ - │
│ rnaseq │ 821 │ 3.14.0 │ 6 months ago │ - │ - │
│ crisprseq │ 22 │ 2.2.0 │ 1 months ago │ - │ - │
│ funcscan │ 62 │ 1.1.6 │ 2 weeks ago │ - │ - │
│ pairgenomealign │ 0 │ dev │ 3 days ago │ - │ - │
│ multiplesequencealign │ 11 │ dev │ 3 days ago │ - │ - │
│ denovotranscript │ 0 │ dev │ 3 days ago │ - │ - │
│ demo │ 1 │ 1.0.0 │ 1 months ago │ - │ - │
│ demultiplex │ 37 │ 1.4.1 │ 5 months ago │ - │ - │
[..truncated..]Filtering available nf-core pipelines
If you supply additional keywords after the list
sub-command, the listed pipeline will be filtered.
Note: that this searches more than just the displayed
output, including keywords and description text.
Here we filter on the keywords rna and rna-seq .
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Pipeline Name ┃ Stars ┃ Latest Release ┃ Released ┃ Last Pulled ┃ Have latest release? ┃
┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ rnaseq │ 821 │ 3.14.0 │ 6 months ago │ - │ - │
│ denovotranscript │ 0 │ dev │ 3 days ago │ - │ - │
│ scnanoseq │ 5 │ dev │ 4 days ago │ - │ - │
│ circrna │ 43 │ dev │ 6 days ago │ - │ - │
│ smrnaseq │ 70 │ 2.3.1 │ 3 months ago │ - │ - │
│ scrnaseq │ 185 │ 2.7.0 │ 4 weeks ago │ - │ - │
│ differentialabundance │ 47 │ 1.5.0 │ 2 months ago │ - │ - │
│ rnafusion │ 132 │ 3.0.2 │ 3 months ago │ - │ - │
│ spatialvi │ 45 │ dev │ 2 months ago │ - │ - │
│ rnasplice │ 35 │ 1.0.4 │ 2 months ago │ - │ - │
│ dualrnaseq │ 16 │ 1.0.0 │ 3 years ago │ - │ - │
│ marsseq │ 4 │ 1.0.3 │ 1 years ago │ - │ - │
│ lncpipe │ 30 │ dev │ 2 years ago │ - │ - │
└───────────────────────┴───────┴────────────────┴──────────────┴─────────────┴──────────────────────┘Sorting available nf-core pipelines
You can sort the results by adding the option --sort
followed by a keyword. For example, latest release
(--sort release), when you last pulled a local copy
(--sort pulled), alphabetically (--sort name),
or number of GitHub stars (--sort stars).
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Pipeline Name ┃ Stars ┃ Latest Release ┃ Released ┃ Last Pulled ┃ Have latest release? ┃
┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ rnaseq │ 821 │ 3.14.0 │ 6 months ago │ - │ - │
│ scrnaseq │ 185 │ 2.7.0 │ 4 weeks ago │ - │ - │
│ rnafusion │ 132 │ 3.0.2 │ 3 months ago │ - │ - │
│ smrnaseq │ 70 │ 2.3.1 │ 3 months ago │ - │ - │
│ differentialabundance │ 47 │ 1.5.0 │ 2 months ago │ - │ - │
│ spatialvi │ 45 │ dev │ 2 months ago │ - │ - │
│ circrna │ 43 │ dev │ 6 days ago │ - │ - │
│ rnasplice │ 35 │ 1.0.4 │ 2 months ago │ - │ - │
│ lncpipe │ 30 │ dev │ 2 years ago │ - │ - │
│ dualrnaseq │ 16 │ 1.0.0 │ 3 years ago │ - │ - │
│ scnanoseq │ 5 │ dev │ 4 days ago │ - │ - │
│ marsseq │ 4 │ 1.0.3 │ 1 years ago │ - │ - │
│ denovotranscript │ 0 │ dev │ 3 days ago │ - │ - │
└───────────────────────┴───────┴────────────────┴──────────────┴─────────────┴──────────────────────┘Archived pipelines
Archived pipelines are not returned by default. To include them, use
the --show_archived flag.
Exercise: listing nf-core pipelines
- Use the
--helpflag to print the list command usage. - Sort all pipelines by popularity (stars) and find out which is the most popular?.
- Filter pipelines for those that work with RNA and find out how many there are?
Running nf-core pipelines
Software requirements for nf-core pipelines
nf-core pipeline software dependencies are specified using either Docker, Singularity or Conda. It is Nextflow that handles the downloading of containers and creation of conda environments. In theory it is possible to run the pipelines with software installed by other methods (e.g. environment modules, or manual installation), but this is not recommended.
Fetching pipeline code
Unless you are actively developing pipeline code, you should use Nextflow’s built-in functionality to fetch nf-core pipelines. You can use the following command to pull the latest version of a remote workflow from the nf-core github site.;
Note Nextflow will also automatically fetch the
pipeline code when use
nextflow run nf-core/<PIPELINE> command.
For the best reproducibility, it is good to explicitly reference the
pipeline version number that you wish to use with the
-revision/-r flag.
In the example below we are pulling the rnaseq pipeline version 3.0
We can check the pipeline has been pulled using the
nf-core list command.
We can see from the output we have the latest release.
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Pipeline Name ┃ Stars ┃ Latest Release ┃ Released ┃ Last Pulled ┃ Have latest release? ┃
┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ rnaseq │ 821 │ 3.14.0 │ 6 months ago │ 59 seconds ago │ Yes (v3.14.0) │
[..truncated..]Development Releases
If not specified, Nextflow will fetch the default git branch. For
pipelines with a stable release this the default branch is
master - this branch contains code from the latest release.
For pipelines in early development that don’t have any releases, the
default branch is dev.
Exercise: Fetch the latest RNA-Seq pipeline
Use the
nextflow pullcommand to download the latestnf-core/rnaseqpipelineUse the
nf-core listcommand to see if you have the latest version of the pipeline
Usage instructions and documentation
You can find general documentation and instructions for Nextflow and nf-core on the nf-core website . Pipeline-specific documentation is bundled with each pipeline in the /docs folder. This can be read either locally, on GitHub, or on the nf-core website.
Each pipeline has its own webpage at https://nf-co.re/<pipeline_name> e.g. nf-co.re/rnaseq
In addition to this documentation, each pipeline comes with basic
command line reference. This can be seen by running the pipeline with
the parameter --help , for example:
OUTPUT
N E X T F L O W ~ version 20.10.0
Launching `nf-core/rnaseq` [silly_miescher] - revision: 964425e3fd [3.4]
------------------------------------------------------
,--./,-.
___ __ __ __ ___ /,-._.--~'
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/rnaseq v3.14.0-gb89fac3
------------------------------------------------------
Typical pipeline command:
nextflow run nf-core/rnaseq --input samplesheet.csv --genome GRCh37 -profile docker
Input/output options
--input [string] Path to comma-separated file containing information about the samples in the experiment.
--outdir [string] The output directory where the results will be saved. You have to use absolute paths to storage on Cloud
infrastructure.
--email [string] Email address for completion summary.
--multiqc_title [string] MultiQC report title. Printed as page header, used for filename if not otherwise specified.
..truncated..The nf-core launch command
As can be seen from the output of the help option nf-core pipelines have a number of flags that need to be passed on the command line: some mandatory, some optional.
To make it easier to launch pipelines, these parameters are described
in a JSON file, nextflow_schema.json bundled with the
pipeline.
The nf-core launch command uses this to build an
interactive command-line wizard which walks through the different
options with descriptions of each, showing the default value and
prompting for values.
Once all prompts have been answered, non-default values are saved to
a params.json file which can be supplied to Nextflow using
the -params-file option. Optionally, the Nextflow command
can be launched there and then.
To use the launch feature, just specify the pipeline name:
Exercise : Create nf-core params file
Use the nf-core launch command to create a params file
named nf-params.json.
- Use the
nf-core launchcommand to launch the interactive command-line wizard. - Add an input file name
samples.csv - Add a genome
GRCh38** Note ** : Do not run the command now.
Config files
nf-core pipelines make use of Nextflow’s configuration files to specify how the pipelines runs, define custom parameters and what software management system to use e.g. docker, singularity or conda.
Nextflow can load pipeline configurations from multiple locations. nf-core pipelines load configuration in the following order:

- Pipeline: Default ‘base’ config
- Always loaded. Contains pipeline-specific parameters and “sensible defaults” for things like computational requirements
- Does not specify any method for software packaging. If nothing else is specified, Nextflow will expect all software to be available on the command line.
- Core config profiles
- All nf-core pipelines come with some generic config profiles. The most commonly used ones are for software packaging: docker, singularity and conda
- Other core profiles are debug and two test profiles. There two test profile, a small test profile (nf-core/test-datasets) for quick test and a full test profile which provides the path to full sized data from public repositories.
- Server profiles
- At run time, nf-core pipelines fetch configuration profiles from the configs remote repository. The profiles here are specific to clusters at different institutions.
- Because this is loaded at run time, anyone can add a profile here for their system and it will be immediately available for all nf-core pipelines.
- Local config files given to Nextflow with the
-cflag
5. Command line configuration: pipeline parameters can be passed on
the command line using the --<parameter> syntax.
Config Profiles
nf-core makes use of Nextflow configuration profiles to
make it easy to apply a group of options on the command line.
Configuration files can contain the definition of one or more
profiles. A profile is a set of configuration attributes that can be
activated/chosen when launching a pipeline execution by using the
-profile command line option. Common profiles are
conda, singularity and docker
that specify which software manager to use.
Multiple profiles are comma-separated. When there are differing configuration settings provided by different profiles, the right-most profile takes priority.
BASH
nextflow run nf-core/rnaseq -r 3.14.0 -profile test,conda
nextflow run nf-core/rnaseq -r 3.14.0 -profile <institutional_config_profile>, test, condaNote The order in which config profiles are specified matters. Their priority increases from left to right.
Multiple Nextflow configuration locations
Be clever with multiple Nextflow configuration locations. For
example, use -profile for your cluster configuration, the
file $HOME/.nextflow/config for your personal config such
as params.email and a working directory
>nextflow.config file for reproducible run-specific
configuration.
Exercise create a custom config
Add the params.email to a file called
nfcore-custom.config
A line similar to one below in the file custom.config
params.email = "myemail@address.com"Running pipelines with test data
The nf-core config profile test is special profile,
which defines a minimal data set and configuration, that runs quickly
and tests the workflow from beginning to end. Since the data is minimal,
the output is often nonsense. Real world example output are instead
linked on the nf-core pipeline web page, where the workflow has been run
with a full size data set:
Software configuration profile
Note that you will typically still need to combine this with a
software configuration profile for your system - e.g.
-profile test,conda. Running with the test profile is a
great way to confirm that you have Nextflow configured properly for your
system before attempting to run with real data
Using nf-core pipelines offline
Many of the techniques and resources described above require an active internet connection at run time - pipeline files, configuration profiles and software containers are all dynamically fetched when the pipeline is launched. This can be a problem for people using secure computing resources that do not have connections to the internet.
To help with this, the nf-core download command
automates the fetching of required files for running nf-core pipelines
offline. The command can download a specific release of a pipeline with
-r/--release .
By default, the pipeline will download the pipeline code and the
institutional nf-core/configs files.
If you specify the flag --singularity, it will also
download any singularity image files that are required (this needs
Singularity to be installed). All files are saved to a single directory,
ready to be transferred to the cluster where the pipeline will be
executed.
OUTPUT
,--./,-.
___ __ __ __ ___ /,-._.--~\
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/tools version 2.14.1 - https://nf-co.re
WARNING Could not find GitHub authentication token. Some API requests may fail.
? Include the nf-core's default institutional configuration files into the download? No
In addition to the pipeline code, this tool can download software containers.
? Download software container images: none
If transferring the downloaded files to another system, it can be convenient to have everything compressed in a single file.
? Choose compression type: none
INFO Saving 'nf-core/rnaseq'
Pipeline revision: '3.14.0'
Use containers: 'none'
Container library: 'quay.io'
Output directory: 'nf-core-rnaseq_3.14.0'
Include default institutional configuration: 'False'
INFO Downloading workflow files from GitHubExercise Run a demo nf-core pipeline
Run the nf-core/demo pipeline release 1.0.0 with the
provided test data using the profile test. Add the
parameters --max_memory 3G, --skip_trim, and
–outdir “nfcore-demo-out” on the command line. Include the config file,
nfcore-custom.config, from the previous exercise using the
option -c, to send an email when your pipeline
finishes.
BASH
$ nextflow run nf-core/demo -r 1.0.0 -profile test --skip_trim --max_memory 3.GB -c nfcore-custom.configThe nf-core/demo pipleine is a simple nf-core style
bioinformatics pipeline for workshops and demonstrations that runs
FASTQC and multiqc.
OUTPUT
N E X T F L O W ~ version 24.04.3
Launching `https://github.com/nf-core/demo` [silly_bohr] DSL2 - revision: 705f18e4b1 [master]
WARN: Access to undefined parameter `monochromeLogs` -- Initialise it to a default value eg. `params.monochromeLogs = some_value`
------------------------------------------------------
,--./,-.
___ __ __ __ ___ /,-._.--~'
|\ | |__ __ / ` / \ |__) |__ } {
| \| | \__, \__/ | \ |___ \`-._,-`-,
`._,._,'
nf-core/demo v1.0.0-g705f18e
------------------------------------------------------
Core Nextflow options
revision : master
runName : silly_bohr
launchDir : /home/nf-training
workDir : /home/nf-training/work
projectDir : /home/nf-training/.nextflow/assets/nf-core/demo
userName : nf-training
profile : test
configFiles :
Input/output options
input : https://raw.githubusercontent.com/nf-core/test-datasets/viralrecon/samplesheet/samplesheet_test_illumina_amplicon.csv
outdir : out
email : myemail@address.com
Process skipping options
skip_trim : true
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Max job request options
max_cpus : 2
max_memory : 3.GB
max_time : 6.h
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
If you use nf-core/demo for your analysis please cite:
* The pipeline
* The nf-core framework
https://doi.org/10.1038/s41587-020-0439-x
* Software dependencies
https://github.com/nf-core/demo/blob/master/CITATIONS.md
------------------------------------------------------
executor > local (4)
[08/94286a] process > NFCORE_DEMO:DEMO:FASTQC (SAMPLE2_PE) [100%] 3 of 3 ✔
[df/45c5c7] process > NFCORE_DEMO:DEMO:MULTIQC [100%] 1 of 1 ✔
-[nf-core/demo] Sent summary e-mail to graeme.grimes@ed.ac.uk (sendmail)-
-[nf-core/demo] Pipeline completed successfully-Troubleshooting
If you run into issues running your pipeline you can you the nf-core website to troubleshoot common mistakes and issues https://nf-co.re/usage/troubleshooting .
Extra resources and getting help
If you still have an issue with running the pipeline then feel free
to contact the nf-core community via the Slack channel . The nf-core
Slack organisation has channels dedicated for each pipeline, as well as
specific topics (eg. #help, #pipelines,
#tools, #configs and much more). The nf-core
Slack can be found at https://nfcore.slack.com (NB: no
hyphen in nfcore!). To join you will need an invite, which you can get
at https://nf-co.re/join/slack.
You can also get help by opening an issue in the respective pipeline repository on GitHub asking for help.
If you have problems that are directly related to Nextflow and not our pipelines or the nf-core framework tools then check out the Nextflow gitter channel or the google group.
Referencing a Pipeline
Publications
If you use an nf-core pipeline in your work you should cite the main publication for the main nf-core paper, describing the community and framework, as follows:
The nf-core framework for community-curated bioinformatics pipelines. Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen. Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x. ReadCube: Full Access Link
Many of the pipelines have a publication listed on the nf-core website that can be found here.
DOIs
In addition, each release of an nf-core pipeline has a digital object identifiers (DOIs) for easy referencing in literature The DOIs are generated by Zenodo from the pipeline’s github repository.
Key Points
- nf-core is a community-led project to develop a set of best-practice pipelines built using the Nextflow workflow management system.
- The nf-core tool (
nf-core) is a suite of helper tools that aims to help people run and develop nf-core pipelines. - nf-core pipelines can be found using
nf-core list, or by checking the nf-core website. -
nf-core launch nf-core/<pipeline>can be used to write a parameter file for an nf-core pipeline. This can be supplied to the pipeline using the-params-fileoption. - An nf-core workflow is run using
nextflow run nf-core/<pipeline>syntax. - nf-core pipelines can be reconfigured by using custom config files and/or adding command line parameters.