Content from Getting Started
Last updated on 2023-11-16 | Edit this page
Overview
Questions
- What makes us understand the context of data?
- How do you approach an unknown dataset?
Objectives
- Getting familiar with the example dataset.
- Facing a common challenge when exploring an unknown dataset.
Challenge 0: What do you see?
Your collaborators sent you a link to one of their tabular datasets with the request to inspect and comment on the collected data.
Download the data: exampleDataObject.csv (csv file, delimiter: “,”)
Open the CSV file with your day-to-day data analysis tool (Python, MS Excel, R, Matlab, etc.)
Inspect the data
-
Ask yourself the following questions:
- Do you get information out of the data?
- Which challenges do you face?
- Do you think that something is missing?
Write down your answers and impressions. You will have the opportunity to discuss them with everyone in the lesson.
Important: There is no right or wrong in this task. Just note down whatever comes to your mind!
Content from Data and Metadata
Last updated on 2023-11-16 | Edit this page

Overview
Questions
- What is data and what is metadata?
- Which types of metadata exist?
- Where can I find (meta)data in everyday examples?
- What are bad and good enough practices of metadata handling in the scientific context?
Objectives
- Recognize and describe examples of (meta)data
- Name best and worst practice situations in research (meta)data handling
- Getting familiar with the example dataset
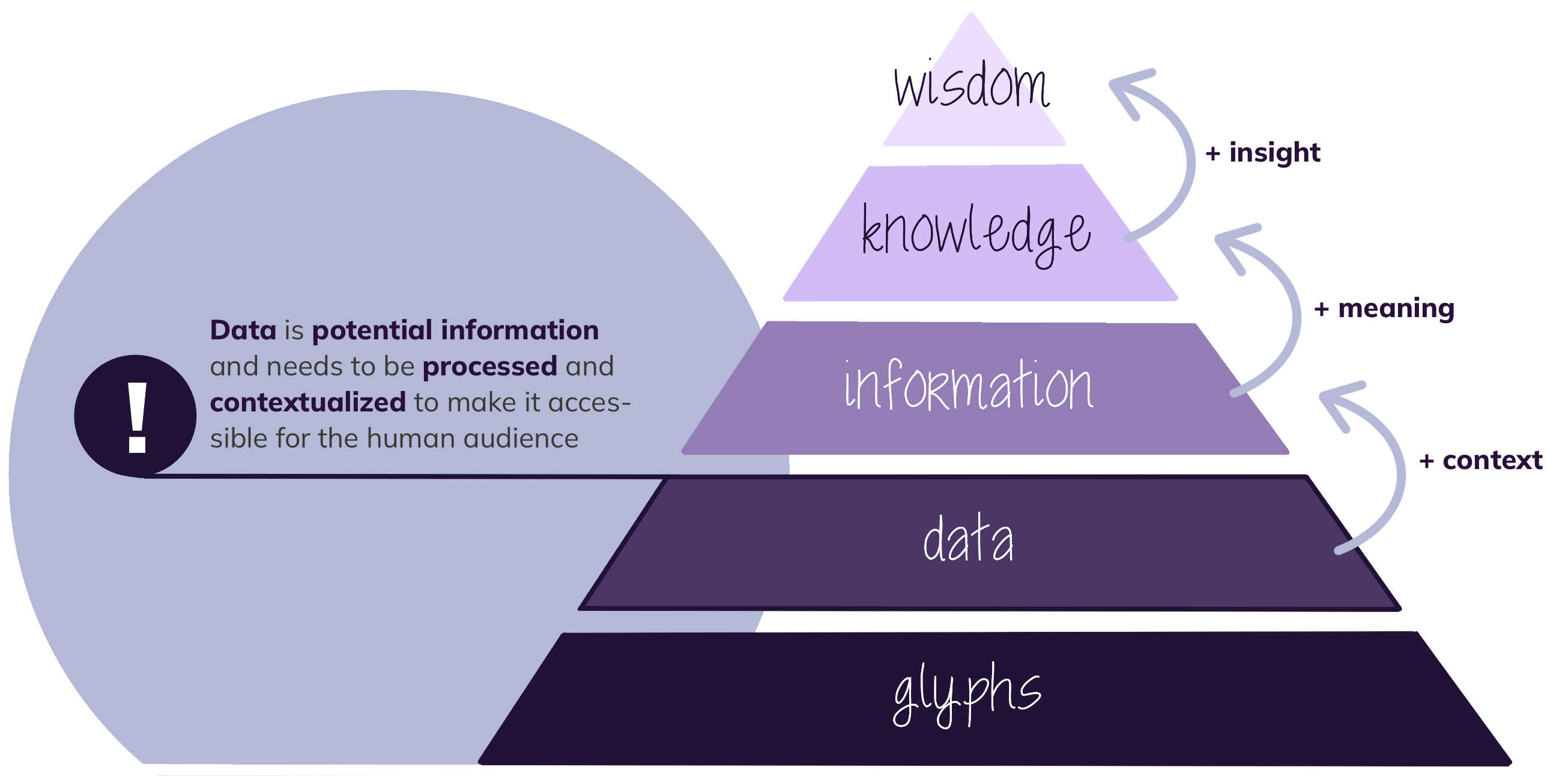
Data – Information – Knowledge – Wisdom
The question “What is data?” seems trivial at first, but if we look at the definition, it is apparent that the question is not that easy to answer. In information science, we distinguish between Glyphs (or symbols), data, information, knowledge and wisdom. GLYPHS are the smallest unit of data representation. Glyphs represent the symbols of which data can be composed.
To cite the information scientist Jeffrey Pomerantz, “DATA is stuff. It is raw, unprocessed, possibly even untouched by human hands, unviewed by human eyes, un-thought-about by human minds”1. In other words, data is potential information, that requires processing and context to extract the information held within.
Accordingly, INFORMATION is processed, human-consumable data. If this information is internalized by a human being, it is called KNOWLEDGE. This knowledge can be applied in a broader context by the human being. Applied knowledge is called WISDOM. The key to reaching wisdom from data is processing and contextualizing data to extract information. To achieve this goal we often need to add a description to the data: metadata.
Information pyramid
Metadata
Metadata is (semi-)structured data that provides information about characteristics of other (more complex) data objects (e.g. files or documents). Regarding research data, metadata gives the observer the necessary context to interpret the data and derive information from it. Although metadata is data itself, it only is meaningful in connection with a data object that is described by the metadata record (e.g. the meta-information in a book about said book). Metadata can be found inside of a data object (e.g. in a book, in a data record) or as a separate object (e.g. library catalogue, separate file).
National Information Standards Organization (NISO, 2004, from “Big Data, Little Data, No Data”, Christine L. Borgman, 2015): “Metadata is structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use or manage an information resource”.
Types of Metadata
Descriptive metadata provides information about the intellectual content of a (digital) object (e.g. title, author, date of publication, subject, description, unique identifier). 2
Administrative metadata provides information to support the management of a resource (e.g. technical information regarding the file’s creation and format, version, information about copyright, licence and intellectual property rights). 2
Structural metadata specifies the relationships between components of a (digital) object and between different (digital) objects (e.g. chapters in a book). 2
Challenge 1: Real-world metadata
- Open one of these web pages in your preferred browser:
- Open one of the articles linked on the main page.
- Inspect the web page source code.
| Browser | Shortcut to Source Code |
|---|---|
| Firefox | Ctrl + u |
| Chrome | Ctrl + u |
| Safari | Option + Command + u |
| Opera | Ctrl + u |
| Edge | Ctrl + u |
| Internet Explorer | Ctrl + u |
- Look for meta
tags in the HTML source code
<head>element. - Assign some
<meta>tags to one of the categories descriptive, administrative, structural
Metadata records
Handwritten (lab) notes Handwritten (lab) notes are still a common practice in many scientific disciplines. These notes are easy to take during data generation. The greatest disadvantage, however, is the physical separation from the data itself and the difficulty to find, store and share this information. Often, handwritten lab notes do not follow a predictable structure and, hence, are hard to interpret and sometimes even hard to read.
Readme style text documents Recording your metadata
(additionally) in a digital README-style text document
comes with one great advantage: the metadata can be associated and
stored directly with the experimental data. README-style
metadata best practices include:3
- creating one
READMEfile for each data file, whenever possible. - naming the
READMEin a way that it is easily associated with the data file(s) it describes. - writing the
READMEdocument as a plain text file avoids proprietary data formats. - structuring multiple
READMEfiles identically. - where possible follow established conventions for scientific vocabulary (i.e. from glossaries or resources such as the IUPAC Gold book)
We strongly recommend to use this
template for README-style metadata
documents.4
Key Points
- Data is potential information.
- The boundaries between data and metadata are blurred and depend on the context.
-
Scientific meta information is often recorded in
handwritten (lab) notes. A better - though still limited - solution, is
the documentation of scientific metadata in accompanying
READMEfiles
Pomerantz, J. (2015). Metadata. The MIT Press. https://doi.org/10.7551/mitpress/10237.001.0001↩︎
Zhang, A. B., Gourley, D. (2008). Metadata strategy in Creating Digital Collections: a practical Guide. Sawston, UK: Woodhead Publishing.↩︎
Chadwick, I. (2016). Research Data Management: guide to writing ”readme” type metadata. The Open University. https://www.open.ac.uk/library-research-support/sites/www.open.ac.uk.library-research-support/files/files/RDM-Guidelines-for-creating-readme-style-metadata.pdf↩︎
Guide to writing “readme” style metadata – Cornell Data Services. (n.d.). https://data.research.cornell.edu/data-management/sharing/readme/↩︎
Content from Structured Metadata: From Markup to JSON
Last updated on 2023-11-16 | Edit this page

Overview
Questions
- What is semi-structured metadata?
- How do you extract semi-structured metadata from natural language.
- What is the JSON syntax?
Objectives
- Explain the importance of semi-structured metadata for machine readability.
- Understand, read and write basic Markdown / HTML / XML / JSON.
Markup?
Markup is not part of the natural language or content of the text but tells something about it 1, 2. By “marking up” a text document additional information on the structure, formatting and relationships within the document can be given. A familiar example are the annotations left by a teacher in a student’s assay with a red pen.2 In order to make Markup work, it is essential, that it follows determined rules, that are understood by the entity marking up the document and the interpreter alike. Markup languages in the digital context establish sets of rules that allow the machine to interpret the building blocks of the document. Some categories of markup are:
Punctuational markup is placing periods, question marks, or similar punctuations at the end of sentences. It gives clues about intonations.
This is a question?Presentational markup is mainly about style.
Descriptive or declarative markup declares what an element is; e. g. a member of a particular type or class like a:
If design rules for headlines change, the document structure remains intact and is still in line with the authors’ original intention.
Referential markup refers to entities external to
the document and may be replaced by those entities during processing.
The World Wide Web markup language HTML
(HyperText Markup
Language) e.g. uses the anchor <a>
tag for hypertext references (hyperlinks) or <img>
for images.
Callout
Rigorous markup can make text (character strings) more accessible for computer analysis.
SGML (Standard Generalized Markup Language) was one of the first industry standards for electronic publishing – a meta-language for generalized, descriptive markup languages – first accepted as an ISO standard in 1986. Both, HTML (1989) and XML (1998) are based on SGML.3
HTML (HyperText Markup Language) is the standard markup language for web pages.
XML
The main purpose of XML (eXtensible
Markup Language) is the
transfer and storage of arbitrary data on the World Wide Web.
XML is software- and hardware-independent. It is considered
human-readable and allows for hierarchical (tree-like) structures. Data
elements are wrapped in start <...> and end
</...> “tags”. XML tags can be customized by the
author of the document, its markup is therefore not limited to a set of
rules but extensible.4
JSON
JSON (JavaScript Object Notation) is not a markup language. It is a lightweight, human-readable, hierarchical format to store and transport data.5 JSON syntax is inspired by JavaScript object notation.6 Like XML, JSON is software- and hardware-independent.
- (meta)data elements are defined in key/value pairs
- keys are of data type
string(in quotes) - values must be of data type
string,number,boolean,arrayorobject - elements are separated by commas
- curly braces hold
objects - square brackets hold
arrays - in-line commenting is not supported
JSON
{
"key":"value",
"aString":"string",
"anInteger":5,
"aFloat":0.5,
"aBoolean":true,
"anArray": ["item1", "item2", "item3"],
"anObject": {
"key1":"value1",
"key2":"value2",
"key3":"value3"
}
}Callout
Data exchange formats such as XML or JSON can be read and processed not only by humans but also by computers. Structured (meta)data is key to enable machine-readability.
Challenge 2: Identify metadata in README.txt
You cannot make sense of the data you got from your collaborators. You ask them for supplemental information and they send you the following README file (see below).
- Read the README carefully.
- In the group, discuss, decide and prioritize which information in the text are relevant experimental metadata.
-
Mark up the relevant information. In markdown you
can mark up the respective words with “==”.
Example:==This text will be highlighted==
You can download the README as TXT file here: README_exampleDataObject.txt
README_exampleDataObject.txt
This README file describes the data in trainingObject.csv
The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster "Flight of the Bat" in Gotham City.
The data was collected by Bruce Wayne and Selina Kyle (Institute for Vigilance and Nightly Motion -- Justice League) on 2022-02-28 in Gotham City, New Jersey.
The test person (male) is 5'11 tall and weighs 187 lbs.
The test person strapped the recording device (iPhone X) with a running armband to their left upper arm and activated the biomechanical acceleration and scream detection of the application "Physics Toolbox Suite" by Vieyra Software.
- "t" describes the ride time at which measurements were taken upon activating the recording in seconds.
- "ax" describes the biomechanical acceleration of the test person on the x axis in m/s².
- "ay" describes the biomechanical acceleration of the test person on the y axis in m/s².
- "az" describes the biomechanical acceleration of the test person on the z axis in m/s².
- "scr" is a boolean indicating a detected scream of the test person.This README describes the data in trainingObject.csv
The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster “Flight of the Bat” in Gotham City.
The data was collected by Bruce Wayne and Selina Kyle (Institute for Vigilance and Nightly Motion - Justice League) on 2022-02-28 in Gotham City, New Jersey.
The test person (male) is 5’11’’ tall and weighs 187 lbs.
The test person strapped the recording device (iPhone X) with a running armband to the left upper arm and activated the biomechanical acceleration and scream detection of the application Physics Toolbox Suite by Vieyra Software. During the ride, the test person was instructed to firmly hold on to the safety handles in order to avoid excessive movement of the arm. The test person was seated in row 10 on the outer left (seat 37).
“t” describes the ride time at which measurements were taken upon activating the recording in seconds. “ax” describes the biomechanical acceleration of the test person on the x axis in m/s². “ay” describes the biomechanical acceleration of the test person on the y axis in m/s². “az” describes the biomechanical acceleration of the test person on the z axis in m/s². “scr” is a boolean indicating a detected scream of the test person.
Challenge 3: Write JSON metadata record
You have manually marked up the relevant information in the README. However, your project requires you to provide metadata in the form of a machine-readable JSON metadata record. The project provides you with a simple example JSON object (remember, that curly braces hold objects):
- Based on the information identified in the README, write a structured, descriptive JSON object.
- Collaboratively, find suitable keys to your values.
- You may want to use some JSON formatter web service to check and beautify (lint) your output.
Keep in mind, that values in JSON must be one of the following data types:
- a string
"" - a number
42 - a boolean
True - null
null - an array
[] - an object
{}
Example:
This is just one (of many) valid solutions.
JSON
{
"fileName": "trainingObject.csv",
"abstract": "The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster \"Flight of the Bat\" in Gotham City.",
"format": "text/csv",
"date": "2022-02-28",
"creator": [
{
"creatorName": "Bruce Wayne",
"creatorAffiliation": "Institute for Vigilance and Nightly Motion - Justice League"
},
{
"creatorName": "Selina Kyle",
"creatorAffiliation": "Institute for Vigilance and Nightly Motion - Justice League"
}
],
"experimentalParameters": {
"testRide": {
"rideName": "Flight of the Bat",
"location": "Gotham City, New Jersey",
"rideType": "roller coaster"
},
"testPerson": {
"sex": "male",
"height": 180
},
"recording": {
"testDevice": "iPhone X",
"testDeviceFixture": "left upper arm",
"testApp": "Physics Toolbox Suite by Vieyra Software"
}
},
"columns": [
{
"columnName": "t",
"columnDescription": "ride time at which measurements were taken upon activating the recording in seconds",
"dataType": "number",
"columnUnit": "sec"
},
{
"columnName": "ax",
"columnDescription": "biomechanical acceleration of the test person on the x axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "ay",
"columnDescription": "biomechanical acceleration of the test person on the y axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "az",
"columnDescription": "biomechanical acceleration of the test person on the z axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "scr",
"columnDescription": "boolean indicating a detected scream of the test person",
"dataType": "boolean",
"columnUnit": "1"
}
]
}Plenary result discussion
- What was easy while generating the structured metadata record?
- What was hard? Which points were intensely discussed in the group?
- Which differences do you see between the different JSON metadata records?
- How do you feel after comparing the results?
Key Points
- Markup languages add information to a text that is separated from the content.
-
XMLandJSONare lightweight, hierarchical file formats to store and transfer data. -
XMLandJSONare human readable, software- and hardware-independent
James H. Coombs et al. (November 1987). Markup Systems and the Future of Scholarly Text Processing. Communications of the ACM 30. http://xml.coverpages.org/coombs.html#Note1↩︎
Cynthia Zender (2005). Markup 101: Markup Basics. SAS Institute. https://www.lexjansen.com/pharmasug/2005/Tutorials/tu12.pdf↩︎
XML Tutorial. (C) 1999-2022. Refsnes Data, W3Schools. https://www.w3schools.com/xml/↩︎
ECMA-404 - ECMA International. (2021, February 4). Ecma International. https://www.ecma-international.org/publications-and-standards/standards/ecma-404/↩︎
JSON Introduction. (C) 1999-2022. Refsnes Data, W3Schools. https://www.w3schools.com/js/js_json_intro.asp↩︎
Content from Enabling Technologies and Standards
Last updated on 2023-11-16 | Edit this page

Overview
Questions
- What are the benefits of creating or using standards and metadata schemas?
- How do you find a suitable metadata standard or terminology for your research field online?
Objectives
- Understand, read and write XML / JSON Schema.
- Find metadata standards and terminologies relevant to your scientific domain.
A Brief History of the World Wide Web
In 1989 researchers Tim Berners-Lee and Robert Cailliau started their HyperText project called the WWW (World-Wide Web, short Web) at the CERN research center in Geneva, Switzerland. The Web was developed to “meet the demand for automated information-sharing between scientists in universities and institutes around the world”.1
The main building blocks of the World Wide Web are:
- HTML (HyperText Markup Language) with “hyperlinks”
- HTTP (HyperText Transfer Protocol)
- URI (Uniform Resource Identifier)
HTML is the standard markup language to create Web pages. It describes the Web page’s structure and tells the browser how to display the content.2
“a combination of natural language text with the computer’s capacity for interactive branching, or dynamic display …”
- Ted Nelson
HTTP is a simple protocol for communication between devices that store and provide resources (“server”) and devices that want to access and update them (“clients”). It is still the main protocol used on the World Wide Web.
For URI see chapter (Web) Location & Identifiers.
In 1992 Deutsches Elektronen-Synchrotron DESY in Hamburg connected a web server to the WWW. One of the first adopters worldwide was the arXiv preprint repository. They switched from email to HTTP for manuscript dissemination in 1991.3
So-called web repositories store and publish (scholarly) digital objects – like paper publications and research data – and their metadata records. This way, they aim to improve the persistent findability and accessibility of research output. Repositories in turn are indexed for findability in registry services like re3data and OpenDOAR.
Metadata Schemas
Callout
A metadata schema is a template which precisely spicifies the metadata elements expected and how they should be structured.
XML Schemas (.xsd) are written in XML and used to
specify & syntactically validate the structure of XML documents or
(meta)data records.4 You might encounter XML Schemas while
looking for certain standards relevant to your field of research.
However, xsd is less frequently used for modern
standards.
The JSON Schema Vocabulary is used to specify & syntactically validate the structure of JSON (meta)data records. We will focus on JSON Schema in our next hands-on task. Each JSON schema is a JSON object literal by itself.5
A simple JSON schema could look like the one below. It declares:
- JSON Schema version with
$schema - a list (an array) of required (i. e. mandatory) properties with one
required property (i.e.
"superhero") - one optional property (i.e.
"power") - data type constraints for record values
(e.g.
"type": "integer")
There are also some descriptions added for the human
reader.
JSON
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"description": "In real life you would add a meaningful description here.",
"type": "object",
"required": [
"superhero"
],
"properties": {
"superhero": {
"description": "A mandatory string property.",
"type": "string"
},
"power": {
"description": "An optional numeric property.",
"type": "integer"
}
}
}A JSON entity is syntactically valid and is called
instance of a schema, if it conforms to the definition
specified by the JSON schema. Note, that the JSON Schema
required keyword holds a list of keys that must be present
for a JSON object to be considered a valid instance of this schema.
Callout
The most challenging part of schema development can be to have everyone agree on the same expectations.
Challenge 4: JSON Schema
After a couple of researchers upload their JSON metadata records to the project repository, it becomes obvious that well-formed JSON metadata describing similar experiments can still be expressed in a myriad of ways.
Your collaboration decides to develop a metadata schema to standardize metadata records across the project. Consensus is encoded in a JSON Schema.
Now it is your task to help with the subschema for experimental conditions!
In the following code block you see valid JSON metadata that specifies experimental conditions as agreed on in the project.
JSON
{
"experimentalConditions": {
"ride": {
"rideType": "roller coaster",
"rideName": "Flight of the Bat",
"location": "Gotham City, New Jersey"
},
"testPerson": {
"sex": "male",
"height": 180
},
"recording": {
"testDevice": "iPhone X",
"testDeviceFixture": "left upper arm",
"testApp": "Physics Toolbox Suite by Vieyra Software"
}
}
}In the following code block you see the JSON schema draft for the
experimental conditions. Your collaborators already modelled constraints
and valid values for ride and testPerson.
Discuss and add constraints to the recording
property.
-
testDevice,testDeviceFixtureandtestAppare mandatory properties for therecordingobject -
testDevicevalue must be one of:iPhone XiPhone 6iPhone 6sother
-
testAppvalue must be one of:Physics Toolbox Suite by Vieyra SoftwareBunny Rollercoaster Physics App
-
testDeviceFixturevalue must be one of:left upper armright upper armmouth fixture deviceother
JSON
{
"experimentalConditions": {
"description": "A summary of the experimental conditions. Include sufficient detail to facilitate search and discovery.",
"type": "object",
"required": [
"recording",
"ride",
"testPerson"
],
"properties": {
"recording": {
/* Insert your schema here and delete this comment */
},
"ride": {
"description": "Properties of the ride.",
"type": "object",
"required": [
"rideType",
"rideName"
],
"properties": {
"rideType": {
"description": "Ride type.",
"type": "string",
"enum": [
"roller coaster",
"water slide",
"bob sled"
]
},
"rideName": {
"description": "Official name of the ride.",
"type": "string",
"minLength": 3
},
"location": {
"description": "City and State in which ride is located.",
"type": "string",
"minLength": 10
}
}
}
},
"testPerson": {
"description": "Properties of person carrying the test device.",
"type": "object",
"required": [
"height",
"sex"
],
"properties": {
"height": {
"description": "Height of test person in cm (SI unit of length).",
"type": "number",
"minimum": 120,
"exclusiveMaximum": 220
},
"sex": {
"description": "Sex of test person.",
"type": "string",
"enum": [
"female",
"male",
"non-binary",
"not disclosed"
]
}
}
}
}
}JSON
{
"experimentalConditions": {
"description": "A summary of the resource. Include sufficient detail to facilitate search and discovery.",
"type": "object",
"required": [
"recording",
"testObject"
"testPerson"
],
"properties": {
*/ add your schema here /*
"recording": {
"description": "",
"type": "object",
"required":[
"testApp",
"testDevice",
"testDeviceFixture"
],
"properties": {
"testApp": {
"description": "Test app used.",
"type": "string",
"enum": [
"Physics Toolbox Suite by Vieyra Software",
"Bunny Rollercoaster Physics App"
]
},
"testAppVersion": {
"description": "Version of test app (free text input). Full semantic versioning input preferred: Major.minor.bugfix",
"type": "string",
"minLength": 1
},
"testDevice": {
"description": "Test device used.",
"type": "string",
"enum": [
"iPhone X",
"iPhone 6",
"iPhone 6s",
"other"
]
},
"testDeviceFixture": {
"description": "Test device fixture.",
"type": "string",
"enum": [
"left upper arm",
"right upper arm",
"mouth fixture device",
"other"
]
}
}
},
*/ this part was prepared by your collaborators /*
"testObject": {
"description": "A free text abstract of the experimental setup.",
"type": "object",
"required": [
"rideType",
"rideName"
],
"properties": {
"rideType": {
"description": "Specification of ride type of the tested object",
"type":"string",
"enum": [
"roller coaster",
"water slide",
"bob sled"
]
},
"rideName": {
"description": "Official name of the ride.",
"type": "string",
"minLength": 1
},
"location": {
"description": "City and State in which the ride is located",
"type": "string"
}
},
"testPerson": {
"description": "Information about the subject carrying the test device.",
"type": "object",
"required": [
"height",
"sex"
],
"properties": {
"height": {
"description": "The height of the test person in cm (SI unit of length).",
"type": "number",
"minimum": 120,
"exclusiveMaximum": 220
},
"sex": {
"description": "The sex of the test person.",
"type": "string",
"enum": [
"female",
"male",
"not disclosed"
]
}
}
}
}TASK 5: Form input and validation with JSON schema
Congratulations, you finished your metadata schema! Now, collecting interoperable metadata will be a lot easier in your collaboration.
We must admit: writing a valid JSON metadata record for each and every experiment that you perform is tedious and time consuming. But now that you have a JSON Schema at hand, things will get a lot easier! The project sets up a user-friendly HTML form interface for the input of JSON metadata.
Let’s try this:
- Download the full JSON schema here: exampleDataObject_Schema.json
- Inspect the JSON schema briefly.
- In your browser, go to the react-jsonschema-form playground.
- Delete the sample content in
JSONschemaandformData - Copy and paste the full schema into the
JSONschemabox - Check again if Chuck Norris properties reappeared in
formDataresults; he can be tough 😄 - Inspect the form interface thoroughly.
-
Optional: Copy the final JSON object literal in
formDatain a separate text document and save the file asexampleDataObject.json
Note that the JSON Schema used for this demo lacks the
recommended $schema keyword: this is because the
playground will unfortunately reject the keyword. You should always
follow the best practices when writing a schema, but sometimes some
adaptations are needed to make them work in different situations.
Plenary result discussion
- How does the browser display lists of pre-defined values (specified
as
enumin the schema)? - How are
arraysandobjectsinterpreted in the form interface? - What happens if you enter an invalid value (e.g. try to enter a
string for the test persons
height) - What happens if you enter a nonsense value (e.g. try to enter a
nonsense string for
rideName) - How does the web service respond if you click on submit without filling all the “required” fields?
Metadata Standards
Callout
A metadata schema can become a standard by governance authority or common adoption.
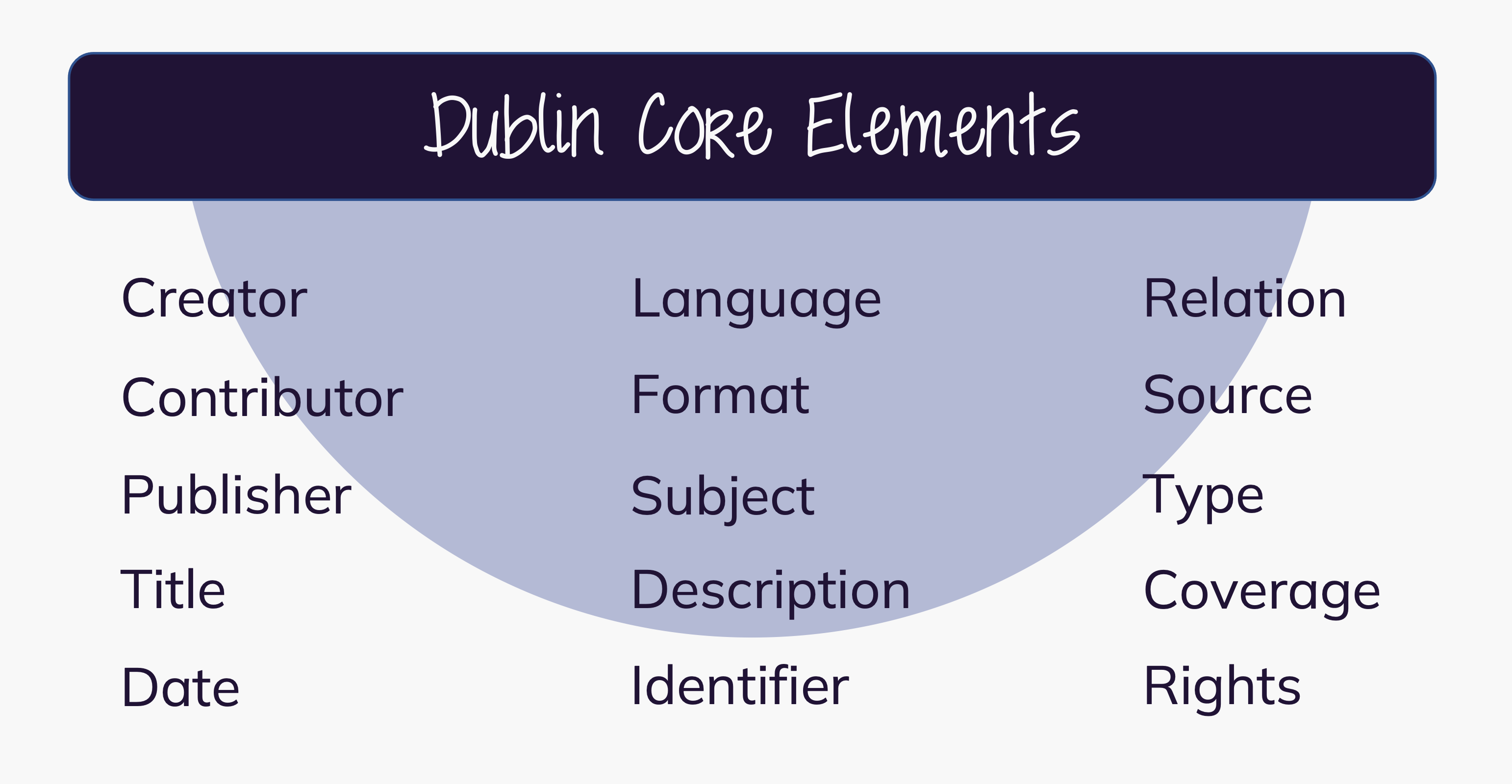
Researchers, librarians and web technologists drafted the Dublin Core – a set of 15 library-card-catalog-like metadata elements for the web – in 1995 at a meeting in Dublin, Ohio (USA).6
Dublin Core and its extensions are widely used and referenced today. The Dublin Core Metadata Initiative (DCMI) states to work openly, with a paid-membership model.
The 15 generic Dublin Core metadata elements have been formally standardized for cross-domain resource description in e.g. ISO 15836-1:20177
Many scholarly repositories expose a standardized application programming interface (API) for the harvesting of Dublin Core metadata as specified in the OAI 2.0 specification
Challenge 6: Domain specific metadata standards
- Open one of these metadata standard registries in your preferred browser:
- Search for a metadata schema, standard or vocabulary relevant to your research domain.
- Inspect the information provided.
Key Points
- The WWW was developed in from and for the scientific community to connect researchers worldwide and enable sharing information
- Metadata schemas serve as template and validation matrix for metadata records
- JSON Schemas are special JSON object literals describing how other JSON must look like
- Well-established metadata schemas have the potential to become a (community) standard
The birth of the Web | CERN. (2023, August 11). https://home.cern/science/computing/birth-web↩︎
XML Schema Tutorial. (C) 1999-2022. Refsnes Data, W3Schools. https: //www.w3schools.com/xml/schema_intro.asp↩︎
The arXiv of the future will not look like the arXiv. (n.d.). Ar5iv. https://ar5iv.labs.arxiv.org/html/1709.07020↩︎
XML Schema Tutorial. (C) 1999-2022. Refsnes Data, W3Schools. https: //www.w3schools.com/xml/schema_intro.asp↩︎
Understanding JSON Schema. The basics. © Copyright 2013-2016 Michael Droettboom, Space Telescope Science Institute; Last updated on Feb 07, 2022. https://json-schema.org/understanding-json-schema/basics.html↩︎
Metadata Basics. (2018, December 15). https://www.dublincore.org/resources/metadata-basics/↩︎
ISO 15836-1:2017. (n.d.). ISO. https://www.iso.org/standard/71339.html↩︎
Content from (Web) Location and Identifiers
Last updated on 2023-11-16 | Edit this page

Overview
Questions
- What are PIDs?
- What are the differences between URL, URI and PID?
- Which PIDs are connected to the research context?
- How are PIDs used in metadata records?
Objectives
- Explain basic concept of client-server communication.
- Explain differences between URL, URI and PID(s).
- Name examples of PIDs relevant for the research context.
- Familiarize with usage of URLs and PIDs in metadata records.
The Web of Today
The Web today is build for human understanding and has taken over a large part of our personal and professional lives. As scientists the World Wide Web has become an essential tool for us to conduct research.
The World Wide Web is a hypermedia system. It contains:
- Resources: A web resource is any entity (digital, physical or abstract), that is represented on the Web.
- Links: (Web identifiers) between these resources.
Web Identifiers
Unique Identifiers
Unique identifiers enable globally unique identification of a resource. The structure of these identifiers is standardized and are registered centrally.
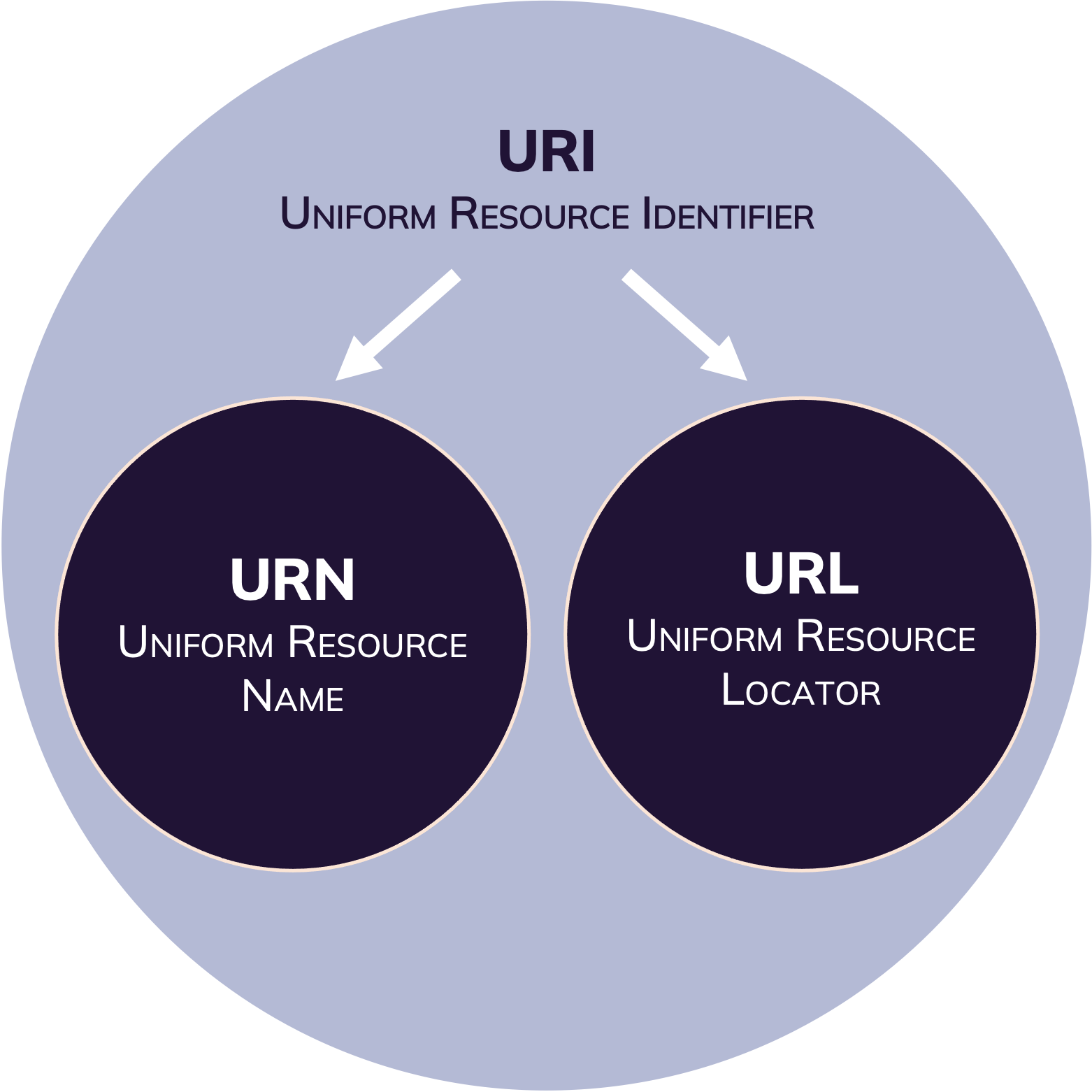
The Uniform Resource Identifier (URI) is a string of characters used to uniquely identify and locate a resource, (most commonly on the Web) and enable interaction with it via common protocols such as HTTP.
A Uniform Resource Name (URN) is a type of URI. It is a standard and unique identifier for digital resources on the Internet. To link to the resource from the URN, a resolver service is required.
The Uniform Resource Locator (URL) is a string of characters used to direct the client to requested resource by using the address of the resource location via communication protocols such as HTTP.
How links rot
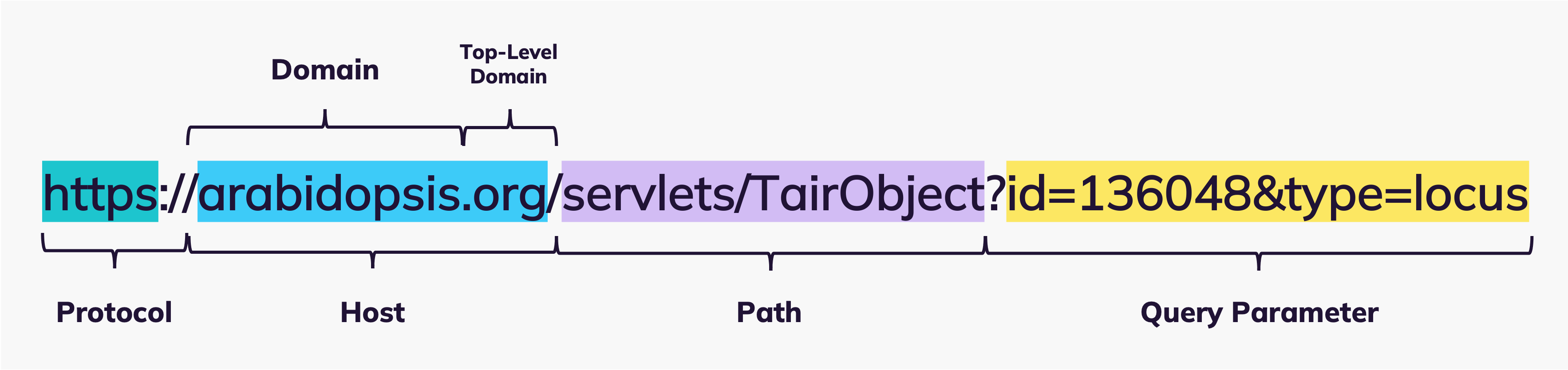
The URL specifies the exact location of a retrievable resource on the web (host & path) as well as the communication protocol (e.g. HTTP) necessary for the local browser to address the host server. If you open a link on the web operated under the HTTP protocol, the browser sends a GET request to the host server, specifying the path to the requested resource. The host server then follows this path and responds with the resource information, if retrievable.
A resource might not be retrievable by the host server, if:
- the location was misspelled.
- the file path on the host server changed.
- the resource was deleted.
- the resource was migrated to a different server.
Each of these events will result in the 404 error response. To avoid these broken or rotten links, assigning a Persistent Identifier (PID) to the resource resolves the issue.
Persistent Identifier
A Persistent Identifier (PID) is a long-lasting reference to digital objects such as websites, articles, datasets, persons or organizations. PIDs are globally unique and persistent over time. Assigning a PID to a digital resource ensures its permanent indentifiability, accessibility, and dereferenciability.1
PID Services
A PID service operates as a persistent look-up service that redirects GET requests for digital resources to the latest URL of this resource.
The host of the digital resource is responsible for updating the resource’s location wiith the PID service after the location changed.
Frequently used PIDs in the scientific context are: - Digital Object Identifier (DOI) - Open Researcher and Contributor ID (ORCID) - Research Organization Registry (ROR)
Web Locations and (Scientific) Metadata
Assigning your Web publications (journal articles, datasets, code, etc.) with a PID holds more advantages than persistent retrievability of the resource. Many PID providers ask you to provide metadata for the published resource and store the metadata record alongside the resource. This metadata in return is accessible by machines via the PID.
PIDs can be used in metadata records as an identifier for an associated resource (e.g. a dataset, a person). In case of the researcher’s ORCiD ID, the ORCiD record stores all the metadata about a person that this person has provided and can be retrieved by the ORCiD API. In the metadata record, that is associated with this researcher, the ORCiD can be specified in the description.
JSON
{
"fileName": "exampleData.csv",
"date": "2022-02-28",
"type": "dataset",
"creator": {
"creatorName": "Bruce Wayne",
"ORCID": "https://orcid.org/0000-0002-1201-3114"
}
}The metadata stored in the ORCID record would resolve to:
JSON
{
"given-names": "Bruce",
"family-name": "Wayne",
"credit-name": "Bruce Wayne",
"other-names": "Batman",
"researcher-urls": [{
"type": "researcher-url",
"url": "https://www.dc.com/characters/batman",
"url-name": "Justice League"
},
{
"type": "researcher-url",
"url": "https://twitter.com/Batman",
"url-name": "Twitter"
}
],
"email": [
"b.wayne@ivnm-gotham.com",
"batman@justic-league.org"
],
"address": {
"country": "USA",
"state": "New Jersey",
"city": "Gotham City",
"zip-code": "08302",
"street": "Wayne Rd 1"
},
"employment": [{
"department-name": "Institute for Vigilance and Nightly Motion",
"start-date": {
"year": 1955,
"month": 8,
"day": 15
},
"organization": {
"name": "Justice League",
"address": {
"city": "Gotham City",
"region": "New Jersey",
"country": "USA",
"disambiguated-organization-identifier": "https://ror.org/05jl9bm63"
}
}
},
{
"department-name": "Board of leaders",
"start-date": {
"year": 1939,
"month": 3,
"day": 30
},
"organization": {
"name": "Wayne Enterprises",
"address": {
"city": "Gotham City",
"region": "New Jersey",
"country": "USA",
"disambiguated-organization-identifier": "https://ror.org/04we5bw33"
}
}
},
{
"department-name": "Executive Office",
"start-date": {
"year": 1945,
"month": 4,
"day": 1
},
"organization": {
"name": "Wayne Foundation",
"address": {
"city": "Gotham City",
"region": "New Jersey",
"country": "USA",
"disambiguated-organization-identifier": "https://ror.org/02eo4wf52"
}
}
}
]
}Machine-Actionability and Interoperability
As discussed previously, most resources on the Web are optimized for the human audience. In order to make the information accessible for machines, elaborate computations would be necessary to process and contextualize the data. By attaching PID (metadata) Records to data objects that are located by PIDs, the machine-actionability and interoperability of the resource is significantly enhanced. PID Records are stored with the PID resolver service and conform to a well-defined PID Record Schema (or Kernel Information Profile).23
Outlook: The Semantic Web
PIDs can be used as identifiers for (meta)data terms
(or entities) and relationships in
schemas, vocabularies, and ontologies. With this technology, machines
are provided with a blueprint of concepts, categories and relationships
associated with data entries. In other words, meaning and references are
added to the data.
The Semantic Web was proposed
by Tim Berners-Lee and his colleagues in 2001.4 The World Wide Web Consortium (W3C) envisions
in the Semantic Web a “Web of linked Data” and has issued a set of
standards, which “enables people to create data stores […], build
vocabularies, and write rules for handling data.5
Key Points
- URLs can unambiguously identify a Web resource.
- DOI, ORCiD, and ROR are relevant PIDs in the scientific context.
- PIDs can be used to persistently identify and a resource on the Web.
- Some PIDs come with associated metadata records which are specified by Kernel Information Profiles (PID Record Schemas).
- Identifying entities (terms) of vocabularies, schemas, and ontologies is essential for Semantic Web technologies.
Kunze, J. (2018, August 24). Ten persistent myths about persistent identifiers. https://escholarship.org/uc/item/73m910w8↩︎
Weigel, T., Plale, B., Parsons, M., Zhou, G., Luo, Y., Schwardmann, U., Quick, R., Hellström, M., & Kurakawa, K. (2018). RDA Recommendation on PID Kernel Information. Research Data Alliance. https://doi.org/10.15497/RDA00031↩︎
Curdt, C., Günther, G., Jejkal, T., Koch, C., Krebs, F., Pfeil, A., Pirogov, A., Schweikert, J., Videgain Barranco, P., Weinelt, M., HMC Cross-cutting Topic Working Group “From Development to Deployment” (2022). Helmholtz Kernel Infomation Profile. Helmholtz Metadata Collaboration. DOI 10.3289/HMC_publ_03.↩︎
Berners-Lee, T., Hendler, J., Lassila, O. (2001). The Semantic Web. Scientific American↩︎
World Wide Web Consortium. (n.d.) Semantic Web Standards. https://www.w3.org/2001/sw/wiki/Main_Page↩︎