Introduction to Natural Language Processing
Overview
Teaching: 15 minutes min
Exercises: 20 minutes minQuestions
What is Natural Language Processing?
What tasks can be done by Natural Language Processing?
What does a workflow for an NLP project look?
Objectives
Learn the tasks that NLP can do
Use a pretrained chatbot in python
Discuss our workflow for performing NLP tasks
Introduction
What is Natural Language Processing?
Text Analysis, also known as Natural Language Processing or NLP, is a subdiscipline of the larger disciplines of machine learning and artificial intelligence.
AI and machine learning both use complex mathematical constructs called models to take data as an input and produce a desired output.
What distinguishes NLP from other types of machine learning is that text and human language is the main input for NLP tasks.
Context for Digital Humanists
Before we get started, we would like to also provide a disclaimer. The humanities involves a wide variety of fields. Each of those fields brings a variety of research interests and methods to focus on a wide variety of questions.
AI is not infallible or without bias. NLP is simply another tool you can use to analyze texts and should be critically considered in the same way any other tool would be. The goal of this workshop is not to replace or discredit existing humanist methods, but to help humanists learn new tools to help them accomplish their research.
The Interpretive Loop
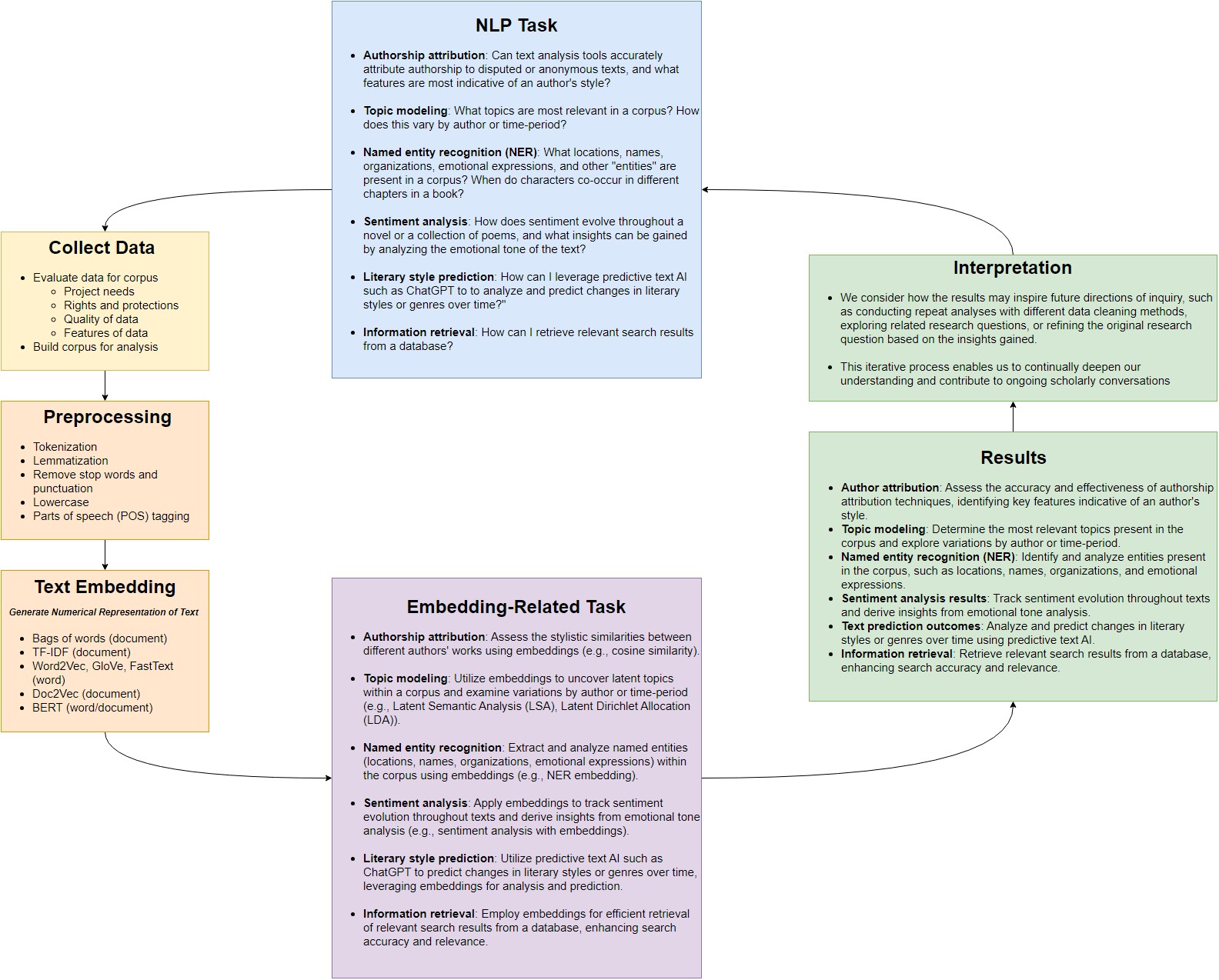
Despite the array of tasks encompassed within text analysis, many share common underlying processes and methodologies. Throughout our exploration, we’ll navigate an ‘interpretive loop’ that connects our research inquiries with the tools and techniques of natural language processing (NLP). This loop comprises several recurring stages:
- Formulating a research question or NLP task: Each journey begins with defining a task or problem within the domain of the digital humanities. This might involve authorship attribution, topic modeling, named entity recognition (NER), sentiment analysis, text prediction, or search, among others.
- Data collection and corpus building: With a clear objective in mind, the next step involves gathering relevant data and constructing a corpus (a set of documents). This corpus serves as the foundation for our analysis and model training. It may include texts, documents, articles, social media posts, or any other textual data pertinent to the research task.
- Data preprocessing: Before our data can be fed into NLP models, it undergoes preprocessing steps to clean, tokenize, and format the text. This ensures compatibility with our chosen model and facilitates efficient computation.
- Generating embeddings: Our processed data is then transformed into mathematical representations known as embeddings. These embeddings capture semantic and contextual information in the corpus, bridging the gap between human intuition and machine algorithms.
- Embedding-related tasks: Leveraging embeddings, we perform various tasks such as measuring similarity between documents, summarizing texts, or extracting key insights.
- Results: Results are generated from specific embedding-related tasks, such as measuring document similarity, document summarization, or topic modeling to uncover latent themes within a corpus.
- Interpreting results: Finally, we interpret the outputs in the context of our research objectives, stakeholder interests, and broader scholarly discourse. This critical analysis allows us to draw conclusions, identify patterns, and refine our approach as needed.
Additionally, we consider how the results may inspire future directions of inquiry, such as conducting repeat analyses with different data cleaning methods, exploring related research questions, or refining the original research question based on the insights gained. This iterative process enables us to continually deepen our understanding and contribute to ongoing scholarly conversations.
NLP Tasks
We’ll start by trying to understand what tasks NLP can do. Some of the many functions of NLP include topic modelling and categorization, named entity recognition, search, summarization and more.
We’re going to explore some of these tasks in this lesson using the popular “HuggingFace” library.
Launch a web browser and navigate to https://huggingface.co/tasks. Here we can see examples of many of the tasks achievable using NLP.
What do these different tasks mean? Let’s take a look at an example. A user engages in conversation with a bot. The bot generates a response based on the user’s prompt. This is called text generation. Let’s click on this task now: https://huggingface.co/tasks/text-generation
HuggingFace usefully provides an online demo as well as a description of the task. On the right, we can see there is a demo of a particular model that does this task. Give conversing with the chatbot a try.
If we scroll down, much more information is available. There is a link to sample models and datasets HuggingFace has made available that can do variations of this task. Documentation on how to use the model is available by scrolling down the page. Model specific information is available by clicking on the model.
Worked Example: Chatbot in Python
We’ve got an overview of what different tasks we can accomplish. Now let’s try getting started with doing these tasks in Python. We won’t worry too much about how this model works for the time being, but will instead just focusing trying it out. We’ll start by running a chatbot, just like the one we used online.
NLP tasks often need to be broken down into simpler subtasks to be executed in a particular order. These are called pipelines since the output from one subtask is used as the input to the next subtask. We will now define a “pipeline” in Python.
Launch either colab or our Anaconda environment, depending on your setup. Try following the example below.
from transformers import pipeline
from transformers.utils import logging
#disable warning about optional authentication
logging.set_verbosity_error()
text2text_generator = pipeline("text2text-generation")
print(text2text_generator("question: What is 42 ? context: 42 is the answer to life, the universe and everything"))
[{'generated_text': 'the answer to life, the universe and everything'}]
Feel free to prompt the chatbot with a few prompts of your own.
Group Activity and Discussion
With some experience with a task, let’s get a broader overview of the types of tasks we can do. Relaunch a web browser and go back to https://huggingface.co/tasks. Break out into groups and look at a couple of tasks for HuggingFace. The groups will be based on general categories for each task. Discuss possible applications of this type of model to your field of research. Try to brainstorm possible applications for now, don’t worry about technical implementation.
- Tasks that seek to convert non-text into text
- Searching and classifying documents as a whole
- Classifying individual words- Sequence based tasks
- Interactive and generative tasks such as conversation and question answering
Briefly present a summary of some of the tasks you explored. What types of applications could you see this type of task used in? How might this be relevant to a research question you have? Summarize these tasks and present your findings to the group.
What tasks can NLP do?
There are many models for representing language. The model we chose for our task will depend on what we want the output of our model to do. In other words, our model will vary based on the task we want it to accomplish.
We can think of the various tasks NLP can do as different types of desired outputs, which may require different models depending on the task.
Let’s discuss tasks you may find interesting in more detail. These are not the only tasks NLP can accomplish, but they are frequently of interest for Humanities scholars.
Search
Search attempts to retrieve documents that are similar to a query. In order to do this, there must be some way to compute the similarity between documents. A search query can be thought of as a small input document, and the outputs could be a score of relevant documents stored in the corpus. While we may not be building a search engine, we will find that similarity metrics such as those used in search are important to understanding NLP.
Topic Modeling
Topic modeling is a type of analysis that attempts to categorize documents into categories. These categories could be human generated labels, or we could ask our model to group together similar texts and create its own labels. For example, the Federalist Papers are a set of 85 essays written by three American Founding Fathers- Alexander Hamilton, James Madison and John Jay. These papers were written under pseudonyms, but many of the papers authors were later identified. One use for topic modelling might be to present a set of papers from each author that are known, and ask our model to label the federalist papers whose authorship is in dispute.
Alternatively, the computer might be asked to come up with a set number of topics, and create categories without precoded documents, in a process called unsupervised learning. Supervised learning requires human labelling and intervention, where unsupervised learning does not. Scholars may then look at the categories created by the NLP model and try to interpret them. One example of this is Mining the Dispatch, which tries to categorize articles based on unsupervised learning topics.
Token Classification
The task of token classification is trying to apply labels on a more granular level- labelling words as belonging to a certain group. The entities we are looking to recognize may be common. Parts of Speech (POS) Tagging looks to give labels to entities such as verbs, nouns, and so on. Named Entity Recognition (NER) seeks to label things such as places, names of individuals, or countries might not be easily enumerated. A possible application of this would be to track co-occurrence of characters in different chapters in a book.

Document Summarization
Document summarization takes documents which are longer, and attempts to output a document with the same meaning by finding relevant snippets or by generating a smaller document that conveys the meaning of the first document. Think of this as taking a large set of input data of words and outputting a smaller output of words that describe our original text.
Text Prediction
Text prediction attempts to predict future text inputs from a user based on previous text inputs. Predictive text is used in search engines and also on smartphones to help correct inputs and speed up the process of text input. It is also used in popular models such as ChatGPT.
Summary and Outro
We’ve looked at a general process or ‘interpretive loop’ for NLP. We’ve also seen a variety of different tasks you can accomplish with NLP. We used Python to generate text based on one of the models available through HuggingFace. Hopefully this gives some ideas about how you might use NLP in your area of research.
In the lessons that follow, we will be working on better understanding what is happening in these models. Before we can use a model though, we need to make sure we have data to build our model on. Our next lesson will be looking at one tool to build a dataset called APIs.
Key Points
NLP is comprised of models that perform different tasks.
Our workflow for an NLP project consists of designing, preprocessing, representation, running, creating output, and interpreting that output.
NLP tasks can be adapted to suit different research interests.
Corpus Development- Text Data Collection
Overview
Teaching: 20 min
Exercises: 20 minQuestions
How do I evaluate what kind of data to use for my project?
What do I need to consider when building my corpus?
Objectives
Become familiar with technical and legal/ethical considerations for data collection.
Practice evaluating text data files created through different processes.
Corpus Development- Text Data Collection
Building Your Corpus
The best sources to build a corpus, or dataset, for text analysis will ultimately depend on the needs of your project. Datasets and sources are not usually prepared to be used in specific kinds of projects, therefore the burden is on the researcher to select materials that will be suitable for their corpus.
Evaluating Data
It can be tempting to find a source and grab its data in bulk, trusting that it will be a fit for your analyses because it meets certain criteria. However, it is important to think critically about the data you are gathering, its context, and the corpus you are assembling. Doing so will allow you to create a corpus that can both meet your project’s needs and possibly serve as its own contribution to your field. As you collect your data and assemble your corpus, you will need to think critically about the content, file types, reduction of bias, rights and permissions, quality, and features needed for your analysis. You may find that no one source fits all of these needs and it may be best to put together a corpus from a variety of sources.
Content type
Materials used in projects can be either born digital, meaning that they originated in a digital format, or digitized, meaning that they were converted to a digital format. Common sources of text data for text analysis projects include digitized archival or primary source materials, newspapers, books, social media, and research articles. Depending on your project, you may even need to digitize some materials yourself. If you are accessing born digital materials, you will want to document the dates you accessed the resources as sources that are born digital may change over time and diverge from those in your corpus. If you are digitizing materials, you will want to document your process for digitization and make sure you are considering the rights and restrictions that apply to your materials.
The nature of your research question will inform the content type and your potential data sources. A question like “How are women represented in 19th century texts?” is very broad. A corpus that explores this question might quickly exceed your computing power as it is large enough to include all content types. Instead, it would be helpful to narrow the scope of the question and this will also narrow down the content type and potential sources. Which women? Where? What kind of texts - newspapers, novels, magazines, legal documents? A question like “How are women represented in classic 19th century American novels?” narrows the scope and content type to 19th century classic American novels.
Once you know the type of materials you need, you can begin exploring data sources for your project. Sources of text data can include government documents, cultural institutions such as archives, libraries, and museums, online projects, and commercial sources. Many sources make their data easily available for download or through an API. Depending on the source, you may also be able to reach out and ask for a copy of data. Other sources, such as commercial vendors, including vendors that work with libraries, can restrict access to their full text data or not allow for download outside of their platform. Although researchers tend to prefer full text data for text analysis, metadata from a source can also be useful for analysis.
File types
Text data can come in different forms, including unstructured text in a plain text file, or in a structured file such as json, html, or xml. As you collect files for potential use in your corpus, creating an inventory of the file types will be helpful as you decide whether to include files, which files to convert, and what kind of analyses you may want to explore.
You may find that the documents you want to analyze may not be in the format you want them to be. They may not even be in text form. A common source of data for text analysis in the digital humanities includes digitized sources. Digitized documents result in jpeg images, which aren’t very useful for text analysis. Some sources also provide a text file for the digitized image which is generated by either Optical Character Recognition (ORC) or, if the document was handwritten, by Handwritten Text Recognition (HTR), which converts images to text. A source may have audio files that are important to your corpus and may or may not contain a transcript generated by speech transcription software. The process of converting files is out of scope for this lesson, but it is worth mentioning that you can also use an OCR tool such as Tesseract, an HTR tool like eScriptorium, or a speech to text tool like DeepSpeech, which are all open source, to convert your files from image or audio to text.
Rights and Restrictions
One of the most important criteria for inclusion in your corpus is whether or not you have the right to use the data in the way your project requires. When evaluating data sources for your project, you may need to navigate a variety of legal and ethical issues. We’ll briefly mention some of them below, but to learn more about these issues, we recommend the open access book Building Legal Literacies for Text and Data Mining. If you are working with foreign-held or licensed content or your project involves international research collaborations, we recommend reviewing resources from the Legal Literacies for Text Data Mining- Cross Border Project (LLTDMX).
- Copyright - Copyright law in the United States protects original works of authorship and grants the right to reproduce the work, to create derivative works, distribute copies, perform the work publicly, and to share the work publicly. Fair use may create exceptions for some TDM activities, but if you are analyzing the full text of copyrighted material, publicly sharing that corpus would most likely not be allowed.
- Licensing - Licenses grant permission to use materials in certain ways while usually restricting others. If you are working with databases or other licensed collections of materials, make sure that you understand the license and how it applies to text and data mining.
- Terms of Use - If you are collecting text data from other sources, such as websites or applications, make sure that you understand any retrictions on how the data can be used.
- Technology Protection Measures - Some publishers and content hosts protect their copyrighted/licensed materials through encryption. While commercial versions of ebooks, for example, would make for easy content to analyze, circumventing these protections would be illegal in the United States under the Digital Millennium Copyright Act.
- Privacy - Before sharing a corpus publicly, consider whether doing so would constitute any legal or ethical violations, especially with regards to privacy. Consulting with digital scholarship librarians at your university or professional organizations in your field would be a good place to learn about privacy issues that might arise with the type of data you are working with.
- Research Protections - Depending on the type of corpus you are creating, you might need to consider human subject research protections such as informed consent. Your institution’s Institutional Review Board may be able to help you navigate emerging issues surrounding text data that is publicly available but could be sensitive, such as social media data.
Assessing Data Sources for Bias
Thinking critically about sources of data and the bias they may introduce to your project is important. It can be tempting to think that datasets are objective and that computational analysis can give you objective answers, however, the strength of the humanities is being able to interpret and understand subjectivity. Who created the data you are considering and for what purpose? What biases might they have held and how might that impact what is included or excluded from your data?
It is also important to think about the bias you may create as you choose your sources and assemble your corpus. If you are creating a corpus to explore how immigrant women are represented in 19th century American novels, you should consider who you are representing in your own corpus. Are any of the authors you are including women? Are any of them immigrants? Including different perspectives can give you a richer corpus that could lead to multiple insights that wouldn’t have been possible with a more limited corpus.
Another source of bias that you should consider is the bias in datasets used to train models you might use in your research and what impact they might have on your analysis. Research the models you are considering. What data were they trained on? Are there known issues with those datasets? If there are known bias issues with the model or you discover some, you will need to consider your options. Is it possible to remediate the model by either removing the biased dataset or adding new training data? Is there an alternative model trained on different data?
Data Quality and Features
Sources of text data each have their own characteristics depending on content type and whether the source was digitized, born digital, or converted from another medium. This may impact the quality of the data or give it certain characteristics. As you assemble your corpus, you should think critically about how the quality of the data and its features might impact your analysis or your decision to include it.
Text data sources that are born digital, meaning that they are created in digital formats rather than being converted or digitized, tend to have better quality data. However, this does not mean that they will necessarily be the best for your project or easier to work with. You should become familiar with your data sources, the way the data source impacts the text data, and options for improving the data quality if necessary.
Let’s look at two different content types, a novel and a newspaper, and how they are formatted. We’ll be working with novels from Project Gutenberg in the next lesson, including the novel “Emma” by Jane Austen. In this lesson we’ll compare the data from that ebook with OCR text data from a digitized newspaper of an article about Jane Austen.
Let’s explore the Project Gutenberg file for “Emma.” Project Gutenberg offers public domain ebooks in HTML or plain text. Uploaded versions must be proofread and often have had page numbers, headers, and footers removed. This makes for good quality plain text data that is easy to work with. However, it includes language about the project and the rights associated with the ebook at the beginning of each file that may need to be removed for cleaner text.
This novel is formatted to include a table of contents at the beginning that outlines its structure. Depending on your analysis, you could use these features to either divide the text data into its volumes and chapters or if you don’t need it, you can decide to remove the capitalized words volume and chapters from the corpus.
Now let’s look at a digitized image of an article about Jane Austen from the Library of Congress’s Chronicling America: Historic American Newspapers collection and its accompanying OCR text.
You can see that the text in the image is in columns. Because of the way the OCR process works, the OCR text data will be in columns as well and will preserve all the instances of words being broken up by this feature. When you look at the OCR text file, you can see that it also includes the text of all the other articles in the same image.
When you look at the quality of the text data, you can see that it is full of misspelled and broken up words. If you wanted to include it in a corpus, you might want to improve the quality of the text data by increasing the contrast or sharpening the image of the text you want and running it through OCR tools. An advanced technique involves running the image through three OCR programs and comparing the outputs against each other.
Assembling Your Corpus
Now that you have an understanding of what you need to consider when collecting data for a corpus, it can be useful to create a list with the requirements of your specific project to help you evaluate your data. Your corpus might be made up from different sources that you are bringing together. It is important for you to document the sources for your data, including the date accessed, search terms you used, and any decisions you made about what to include or exclude. Whether you are able to make your corpus public later on will depend on the rights and restrictions of the sources used, so make sure to document that information as well.
Although it sounds impressive, Big Data doesn’t always make for a better project. The size of your corpus should depend on your project’s needs, your storage capacity, and your computing power. A smaller dataset with more targeted documents might actually be better at helping you arrive at the insights that you need, depending on your use case. Whether your corpus consists of hundreds of documents or millions, the important thing is to create the corpus that works best for your project.
Key Points
You will need to evaluate the suitability of data for inclusion in your corpus and will need to take into consideration issues such as legal/ethical restrictions and data quality among others.
It is important to think critically about data sources and the context of how they were created or assembled.
Becoming familiar with your data and its characteristics can help you prepare your data for analysis.
Preparing and Preprocessing Your Data
Overview
Teaching: 10 min
Exercises: 10 minQuestions
How can I prepare data for NLP?
What are tokenization, casing and lemmatization?
Objectives
Load a test document into Spacy.
Learn preprocessing tasks.
Preparing and Preprocessing Your Data
Collection
The first step to preparing your data is to collect it. Whether you use API’s to gather your material or some other method depends on your research interests. For this workshop, we’ll use pre-gathered data.
During the setup instructions, we asked you to download a number of files. These included about forty texts downloaded from Project Gutenberg, which will make up our corpus of texts for our hands on lessons in this course.
Take a moment to orient and familiarize yourself with them:
- Austen
- Chesteron
- Dickens
- Dumas
- Melville
- Shakespeare
While a full-sized corpus can include thousands of texts, these forty-odd texts will be enough for our illustrative purposes.
Loading Data into Python
We’ll start by mounting our Google Drive so that Colab can read the helper functions. We’ll also go through how many of these functions are written in this lesson.
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
# Show existing colab notebooks and helpers.py file
from os import listdir
wksp_dir = '/content/drive/My Drive/Colab Notebooks/text-analysis'
listdir(wksp_dir)
# Add folder to colab's path so we can import the helper functions
import sys
sys.path.insert(0, wksp_dir)
Next, we have a corpus of text files we want to analyze. Let’s create a method to list those files. To make this method more flexible, we will also use glob to allow us to put in regular expressions so we can filter the files if so desired. glob is a tool for listing files in a directory whose file names match some pattern, like all files ending in *.txt.
!pip install pathlib parse
import glob
import os
from pathlib import Path
def create_file_list(directory, filter_str='*'):
files = Path(directory).glob(filter_str)
files_to_analyze = list(map(str, files))
return files_to_analyze
Alternatively, we can load this function from the helpers.py file we provided for learners in this course:
from helpers import create_file_list
Either way, now we can use that function to list the books in our corpus:
corpus_dir = '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books'
corpus_file_list = create_file_list(corpus_dir)
print(corpus_file_list)
['/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-olivertwist.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-knewtoomuch.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-tenyearslater.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-twentyyearsafter.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-pride.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-taleoftwocities.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-whitehorse.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-hardtimes.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-emma.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-thursday.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-threemusketeers.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-ball.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-ladysusan.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-persuasion.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-conman.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-napoleon.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-brown.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-maninironmask.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-blacktulip.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-greatexpectations.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-ourmutualfriend.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-sense.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-christmascarol.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-davidcopperfield.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-pickwickpapers.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-bartleby.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-bleakhouse.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-montecristo.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-northanger.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-moby_dick.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-twelfthnight.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-typee.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-romeo.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-omoo.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-piazzatales.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-muchado.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-midsummer.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-lear.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-pierre.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-caesar.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-othello.txt']
We will use the full corpus later, but it might be useful to filter to just a few specific files. For example, if I want just documents written by Austen, I can filter on part of the file path name:
austen_list = create_file_list(corpus_dir, 'austen*')
print(austen_list)
['/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-pride.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-emma.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-ladysusan.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-persuasion.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-sense.txt', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-northanger.txt']
Let’s take a closer look at Emma. We are looking at the first full sentence, which begins with character 50 and ends at character 290.
preview_len = 290
emmapath = create_file_list(corpus_dir, 'austen-emma*')[0]
print(emmapath)
sentence = ""
with open(emmapath, 'r') as f:
sentence = f.read(preview_len)[50:preview_len]
print(sentence)
/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-emma.txt
Emma Woodhouse, handsome, clever, and rich, with a comfortable home
and happy disposition, seemed to unite some of the best blessings
of existence; and had lived nearly twenty-one years in the world
with very little to distress or vex her.
Preprocessing
Currently, our data is still in a format that is best for humans to read. Humans, without having to think too consciously about it, understand how words and sentences group up and divide into discrete units of meaning. We also understand that the words run, ran, and running are just different grammatical forms of the same underlying concept. Finally, not only do we understand how punctuation affects the meaning of a text, we also can make sense of texts that have odd amounts or odd placements of punctuation.
For example, Darcie Wilder’s literally show me a healthy person has very little capitalization or punctuation:
in the unauthorized biography of britney spears she says her advice is to lift 1 lb weights and always sing in elevators every time i left to skateboard in the schoolyard i would sing in the elevator i would sing britney spears really loud and once the door opened and there were so many people they heard everything so i never sang again
Across the texts in our corpus, our authors write with different styles, preferring different dictions, punctuation, and so on.
To prepare our data to be more uniformly understood by our NLP models, we need to (a) break it into smaller units, (b) replace words with their roots, and (c) remove unwanted common or unhelpful words and punctuation. These steps encompass the preprocessing stage of the interpretive loop.
Tokenization
Tokenization is the process of breaking down texts (strings of characters) into words, groups of words, and sentences. A string of characters needs to be understood by a program as smaller units so that it can be embedded. These are called tokens.
While our tokens will be single words for now, this will not always be the case. Different models have different ways of tokenizing strings. The strings may be broken down into multiple word tokens, single word tokens, or even components of words like letters or morphology. Punctuation may or may not be included.
We will be using a tokenizer that breaks documents into single words for this lesson.
Let’s load our tokenizer and test it with the first sentence of Emma:
import spacy
import en_core_web_sm
spacyt = spacy.load("en_core_web_sm")
We will define a tokenizer method with the text editor. Keep this open so we can add to it throughout the lesson.
class Our_Tokenizer:
def __init__(self):
#import spacy tokenizer/language model
self.nlp = en_core_web_sm.load()
self.nlp.max_length = 4500000 # increase max number of characters that spacy can process (default = 1,000,000)
def __call__(self, document):
tokens = self.nlp(document)
return tokens
This will load spacy and its preprocessing pipeline for English. Pipelines are a series of interrelated tasks, where the output of one task is used as an input for another. Different languages may have different rulesets, and therefore require different preprocessing pipelines. Running the document we created through the NLP model we loaded performs a variety of tasks for us. Let’s look at these in greater detail.
tokens = spacyt(sentence)
for t in tokens:
print(t.text)
Emma
Woodhouse
,
handsome
,
clever
,
and
rich
,
with
a
comfortable
home
and
happy
disposition
,
seemed
to
unite
some
of
the
best
blessings
of
existence
;
and
had
lived
nearly
twenty
-
one
years
in
the
world
with
very
little
to
distress
or
vex
her
.
The single sentence has been broken down into a set of tokens. Tokens in spacy aren’t just strings: They’re python objects with a variety of attributes. Full documentation for these attributes can be found at: https://spacy.io/api/token
Stems and Lemmas
Think about similar words, such as running, ran, and runs. All of these words have a similar root, but a computer does not know this. Without preprocessing, each of these words would be a new token.
Stemming and Lemmatization are used to group together words that are similar or forms of the same word.
Stemming is removing the conjugation and pluralized endings for words. For example, words like digitization, and digitizing might chopped down to digitiz.
Lemmatization is the more sophisticated of the two, and looks for the linguistic base of a word. Lemmatization can group words that mean the same thing but may not be grouped through simple stemming, such as irregular verbs like bring and brought.
Similarly, in naive tokenization, capital letters are considered different from non-capital letters, meaning that capitalized versions of words are considered different from non-capitalized versions. Converting all words to lower case ensures that capitalized and non-capitalized versions of words are considered the same.
These steps are taken to reduce the complexities of our NLP models and to allow us to train them from less data.
When we tokenized the first sentence of Emma above, Spacy also created a lemmatized version of itt. Let’s try accessing this by typing the following:
for t in tokens:
print(t.lemma)
14931068470291635495
17859265536816163747
2593208677638477497
7792995567492812500
2593208677638477497
5763234570816168059
2593208677638477497
2283656566040971221
10580761479554314246
2593208677638477497
12510949447758279278
11901859001352538922
2973437733319511985
12006852138382633966
962983613142996970
2283656566040971221
244022080605231780
3083117615156646091
2593208677638477497
15203660437495798636
3791531372978436496
1872149278863210280
7000492816108906599
886050111519832510
7425985699627899538
5711639017775284443
451024245859800093
962983613142996970
886050111519832510
4708766880135230039
631425121691394544
2283656566040971221
14692702688101715474
13874798850131827181
16179521462386381682
8304598090389628520
9153284864653046197
17454115351911680600
14889849580704678361
3002984154512732771
7425985699627899538
1703489418272052182
962983613142996970
12510949447758279278
9548244504980166557
9778055143417507723
3791531372978436496
14526277127440575953
3740602843040177340
14980716871601793913
6740321247510922449
12646065887601541794
962983613142996970
Spacy stores words by an ID number, and not as a full string, to save space in memory. Many spacy functions will return numbers and not words as you might expect. Fortunately, adding an underscore for spacy will return text representations instead. We will also add in the lower case function so that all words are lower case.
for t in tokens:
print(str.lower(t.lemma_))
emma
woodhouse
,
handsome
,
clever
,
and
rich
,
with
a
comfortable
home
and
happy
disposition
,
seem
to
unite
some
of
the
good
blessing
of
existence
;
and
have
live
nearly
twenty
-
one
year
in
the
world
with
very
little
to
distress
or
vex
she
.
Notice how words like best and her have been changed to their root words like good and she. Let’s change our tokenizer to save the lower cased, lemmatized versions of words instead of the original words.
class Our_Tokenizer:
def __init__(self):
# import spacy tokenizer/language model
self.nlp = en_core_web_sm.load()
self.nlp.max_length = 4500000 # increase max number of characters that spacy can process (default = 1,000,000)
def __call__(self, document):
tokens = self.nlp(document)
simplified_tokens = [str.lower(token.lemma_) for token in tokens]
return simplified_tokens
Stop-Words and Punctuation
Stop-words are common words that are often filtered out for more efficient natural language data processing. Words such as the and and don’t necessarily tell us a lot about a document’s content and are often removed in simpler models. Stop lists (groups of stop words) are curated by sorting terms by their collection frequency, or the total number of times that they appear in a document or corpus. Punctuation also is something we are not interested in, at least not until we get to more complex models. Many open-source software packages for language processing, such as Spacy, include stop lists. Let’s look at Spacy’s stopword list.
from spacy.lang.en.stop_words import STOP_WORDS
print(STOP_WORDS)
{''s', 'must', 'again', 'had', 'much', 'a', 'becomes', 'mostly', 'once', 'should', 'anyway', 'call', 'front', 'whence', ''ll', 'whereas', 'therein', 'himself', 'within', 'ourselves', 'than', 'they', 'toward', 'latterly', 'may', 'what', 'her', 'nowhere', 'so', 'whenever', 'herself', 'other', 'get', 'become', 'namely', 'done', 'could', 'although', 'which', 'fifteen', 'seems', 'hereafter', 'whereafter', 'two', "'ve", 'to', 'his', 'one', ''d', 'forty', 'being', 'i', 'four', 'whoever', 'somehow', 'indeed', 'that', 'afterwards', 'us', 'she', "'d", 'herein', ''ll', 'keep', 'latter', 'onto', 'just', 'too', "'m", ''re', 'you', 'no', 'thereby', 'various', 'enough', 'go', 'myself', 'first', 'seemed', 'up', 'until', 'yourselves', 'while', 'ours', 'can', 'am', 'throughout', 'hereupon', 'whereupon', 'somewhere', 'fifty', 'those', 'quite', 'together', 'wherein', 'because', 'itself', 'hundred', 'neither', 'give', 'alone', 'them', 'nor', 'as', 'hers', 'into', 'is', 'several', 'thus', 'whom', 'why', 'over', 'thence', 'doing', 'own', 'amongst', 'thereupon', 'otherwise', 'sometime', 'for', 'full', 'anyhow', 'nine', 'even', 'never', 'your', 'who', 'others', 'whole', 'hereby', 'ever', 'or', 'and', 'side', 'though', 'except', 'him', 'now', 'mine', 'none', 'sixty', "n't", 'nobody', ''m', 'well', "'s", 'then', 'part', 'someone', 'me', 'six', 'less', 'however', 'make', 'upon', ''s', ''re', 'back', 'did', 'during', 'when', ''d', 'perhaps', "'re", 'we', 'hence', 'any', 'our', 'cannot', 'moreover', 'along', 'whither', 'by', 'such', 'via', 'against', 'the', 'most', 'but', 'often', 'where', 'each', 'further', 'whereby', 'ca', 'here', 'he', 'regarding', 'every', 'always', 'are', 'anywhere', 'wherever', 'using', 'there', 'anyone', 'been', 'would', 'with', 'name', 'some', 'might', 'yours', 'becoming', 'seeming', 'former', 'only', 'it', 'became', 'since', 'also', 'beside', 'their', 'else', 'around', 're', 'five', 'an', 'anything', 'please', 'elsewhere', 'themselves', 'everyone', 'next', 'will', 'yourself', 'twelve', 'few', 'behind', 'nothing', 'seem', 'bottom', 'both', 'say', 'out', 'take', 'all', 'used', 'therefore', 'below', 'almost', 'towards', 'many', 'sometimes', 'put', 'were', 'ten', 'of', 'last', 'its', 'under', 'nevertheless', 'whatever', 'something', 'off', 'does', 'top', 'meanwhile', 'how', 'already', 'per', 'beyond', 'everything', 'not', 'thereafter', 'eleven', 'n't', 'above', 'eight', 'before', 'noone', 'besides', 'twenty', 'do', 'everywhere', 'due', 'empty', 'least', 'between', 'down', 'either', 'across', 'see', 'three', 'on', 'formerly', 'be', 'very', 'rather', 'made', 'has', 'this', 'move', 'beforehand', 'if', 'my', 'n't', "'ll", 'third', 'without', ''m', 'yet', 'after', 'still', 'same', 'show', 'in', 'more', 'unless', 'from', 'really', 'whether', ''ve', 'serious', 'these', 'was', 'amount', 'whose', 'have', 'through', 'thru', ''ve', 'about', 'among', 'another', 'at'}
It’s possible to add and remove words as well, for example, zebra:
# remember, we need to tokenize things in order for our model to analyze them.
z = spacyt("zebra")[0]
print(z.is_stop) # False
# add zebra to our stopword list
STOP_WORDS.add("zebra")
spacyt = spacy.load("en_core_web_sm")
z = spacyt("zebra")[0]
print(z.is_stop) # True
# remove zebra from our list.
STOP_WORDS.remove("zebra")
spacyt = spacy.load("en_core_web_sm")
z = spacyt("zebra")[0]
print(z.is_stop) # False
Let’s add “Emma” to our list of stopwords, since knowing that the name “Emma” is often in Jane Austin does not tell us anything interesting.
This will only adjust the stopwords for the current session, but it is possible to save them if desired. More information about how to do this can be found in the Spacy documentation. You might use this stopword list to filter words from documents using spacy, or just by manually iterating through it like a list.
Let’s see what our example looks like without stopwords and punctuation:
# add emma to our stopword list
STOP_WORDS.add("emma")
spacyt = spacy.load("en_core_web_sm")
# retokenize our sentence
tokens = spacyt(sentence)
for token in tokens:
if not token.is_stop and not token.is_punct:
print(str.lower(token.lemma_))
woodhouse
handsome
clever
rich
comfortable
home
happy
disposition
unite
good
blessing
existence
live
nearly
year
world
little
distress
vex
Notice that because we added emma to our stopwords, she is not in our preprocessed sentence any more. Other stopwords are also missing such as numbers.
Let’s filter out stopwords and punctuation from our custom tokenizer now as well:
class Our_Tokenizer:
def __init__(self):
# import spacy tokenizer/language model
self.nlp = en_core_web_sm.load()
self.nlp.max_length = 4500000 # increase max number of characters that spacy can process (default = 1,000,000)
def __call__(self, document):
tokens = self.nlp(document)
simplified_tokens = []
for token in tokens:
if not token.is_stop and not token.is_punct:
simplified_tokens.append(str.lower(token.lemma_))
return simplified_tokens
Parts of Speech
While we can manually add Emma to our stopword list, it may occur to you that novels are filled with characters with unique and unpredictable names. We’ve already missed the word “Woodhouse” from our list. Creating an enumerated list of all of the possible character names seems impossible.
One way we might address this problem is by using Parts of speech (POS) tagging. POS are things such as nouns, verbs, and adjectives. POS tags often prove useful, so some tokenizers also have built in POS tagging done. Spacy is one such library. These tags are not 100% accurate, but they are a great place to start. Spacy’s POS tags can be used by accessing the pos_ method for each token.
for token in tokens:
if token.is_stop == False and token.is_punct == False:
print(str.lower(token.lemma_)+" "+token.pos_)
woodhouse PROPN
handsome ADJ
clever ADJ
rich ADJ
comfortable ADJ
home NOUN
SPACE
happy ADJ
disposition NOUN
unite VERB
good ADJ
blessing NOUN
SPACE
existence NOUN
live VERB
nearly ADV
year NOUN
world NOUN
SPACE
little ADJ
distress VERB
vex VERB
SPACE
Because our dataset is relatively small, we may find that character names and places weigh very heavily in our early models. We also have a number of blank or white space tokens, which we will also want to remove.
We will finish our special tokenizer by removing punctuation and proper nouns from our documents:
class Our_Tokenizer:
def __init__(self):
# import spacy tokenizer/language model
self.nlp = en_core_web_sm.load()
self.nlp.max_length = 4500000 # increase max number of characters that spacy can process (default = 1,000,000)
def __call__(self, document):
tokens = self.nlp(document)
simplified_tokens = [
#our helper function expects spacy tokens. It will take care of making them lowercase lemmas.
token for token in tokens
if not token.is_stop
and not token.is_punct
and token.pos_ != "PROPN"
]
return simplified_tokens
Alternative, instead of “blacklisting” all of the parts of speech we don’t want to include, we can “whitelist” just the few that we want, based on what they information they might contribute to the meaning of a text:
class Our_Tokenizer:
def __init__(self):
# import spacy tokenizer/language model
self.nlp = en_core_web_sm.load()
self.nlp.max_length = 4500000 # increase max number of characters that spacy can process (default = 1,000,000)
def __call__(self, document):
tokens = self.nlp(document)
simplified_tokens = [
#our helper function expects spacy tokens. It will take care of making them lowercase lemmas.
token for token in tokens
if not token.is_stop
and not token.is_punct
and token.pos_ in {"ADJ", "ADV", "INTJ", "NOUN", "VERB"}
]
return simplified_tokens
Either way, let’s test our custom tokenizer on this selection of text to see how it works.
tokenizer = Our_Tokenizer()
tokens = tokenizer(sentence)
print(tokens)
['handsome', 'clever', 'rich', 'comfortable', 'home', 'happy', 'disposition', 'unite', 'good', 'blessing', 'existence', 'live', 'nearly', 'year', 'world', 'little', 'distress', 'vex']
Putting it All Together
Now that we’ve built a tokenizer we’re happy with, lets use it to create lemmatized versions of all the books in our corpus.
That is, we want to turn this:
Emma Woodhouse, handsome, clever, and rich, with a comfortable home
and happy disposition, seemed to unite some of the best blessings
of existence; and had lived nearly twenty-one years in the world
with very little to distress or vex her.
into this:
handsome
clever
rich
comfortable
home
happy
disposition
seem
unite
good
blessing
existence
live
nearly
year
world
very
little
distress
vex
To help make this quick for all the text in all our books, we’ll use a helper function we prepared for learners to use our tokenizer, do the casing and lemmatization we discussed earlier, and write the results to a file:
from helpers import lemmatize_files
lemma_file_list = lemmatize_files(tokenizer, corpus_file_list)
['/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-olivertwist.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-knewtoomuch.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-tenyearslater.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-twentyyearsafter.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-pride.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-taleoftwocities.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-whitehorse.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-hardtimes.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-emma.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-thursday.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-threemusketeers.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-ball.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-ladysusan.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-persuasion.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-conman.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-napoleon.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/chesterton-brown.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-maninironmask.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-blacktulip.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-greatexpectations.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-ourmutualfriend.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-sense.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-christmascarol.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-davidcopperfield.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-pickwickpapers.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-bartleby.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dickens-bleakhouse.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/dumas-montecristo.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/austen-northanger.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-moby_dick.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-twelfthnight.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-typee.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-romeo.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-omoo.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-piazzatales.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-muchado.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-midsummer.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-lear.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/melville-pierre.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-caesar.txt.lemmas', '/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/shakespeare-othello.txt.lemmas']
This process may take several minutes to run. Doing this preprocessing now however will save us much, much time later.
Saving Our Progress
Let’s save our progress by storing a spreadsheet (*.csv or *.xlsx file) that lists all our authors, books, and associated filenames, both the original and lemmatized copies.
We’ll use another helper we prepared to make this easy:
from helpers import parse_into_dataframe
pattern = "/content/drive/My Drive/Colab Notebooks/text-analysis/data/books/{author}-{title}.txt"
data = parse_into_dataframe(pattern, corpus_file_list)
data["Lemma_File"] = lemma_file_list
Finally, we’ll save this table to a file:
data.to_csv("/content/drive/My Drive/Colab Notebooks/text-analysis/data/data.csv", index=False)
Outro and Conclusion
This lesson has covered a number of preprocessing steps. We created a list of our files in our corpus, which we can use in future lessons. We customized a tokenizer from Spacy, to better suit the needs of our corpus, which we can also use moving forward.
Next lesson, we will start talking about the concepts behind our model.
Key Points
Tokenization breaks strings into smaller parts for analysis.
Casing removes capital letters.
Stopwords are common words that do not contain much useful information.
Lemmatization reduces words to their root form.
Vector Space and Distance
Overview
Teaching: 20 min
Exercises: 20 minQuestions
How can we model documents effectively?
How can we measure similarity between documents?
What’s the difference between cosine similarity and distance?
Objectives
Visualize vector space in a 2D model.
Learn about embeddings.
Learn about cosine similarity and distance.
Vector Space
Now that we’ve preprocessed our data, let’s move to the next step of the interpretative loop: generating a text embedding.
Many NLP models make use of a concept called Vector Space. The concept works like this:
- We create embeddings, or mathematical surrogates, of words and documents in vector space. These embeddings can be represented as sets of coordinates in multidimensional space, or as multi-dimensional matrices.
- These embeddings should be based on some sort of feature extraction, meaning that meaningful features from our original documents are somehow represented in our embedding. This will make it so that relationships between embeddings in this vector space will correspond to relationships in the actual documents.
Bags of Words
In the models we’ll look at today, we have a “bag of words” assumption as well. We will not consider the placement of words in sentences, their context, or their conjugation into different forms (run vs ran), not until later in this course.
A “bag of words” model is like putting all words from a sentence in a bag and just being concerned with how many of each word you have, not their order or context.
Worked Example: Bag of Words
Let’s suppose we want to model a small, simple set of toy documents. Our entire corpus of documents will only have two words, to and be. We have four documents, A, B, C and D:
- A: be be be be be be be be be be to
- B: to be to be to be to be to be to be to be to be
- C: to to be be
- D: to be to be
We will start by embedding words using a “one hot” embedding algorithm. Each document is a new row in our table. Every time word ‘to’ shows up in a document, we add one to our value for the ‘to’ dimension for that row, and zero to every other dimension. Every time ‘be’ shows up in our document, we will add one to our value for the ‘be’ dimension for that row, and zero to every other dimension.
How does this corpus look in vector space? We can display our model using a document-term matrix, which looks like the following:
| Document | to | be |
|---|---|---|
| Document A | 1 | 10 |
| Document B | 8 | 8 |
| Document C | 2 | 2 |
| Document D | 2 | 2 |
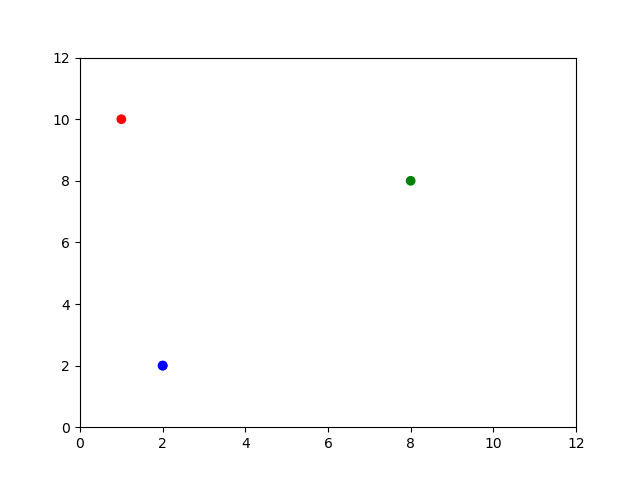
Notice that documents C and D are represented exactly the same. This is unavoidable right now because of our “bag of words” assumption, but much later on we will try to represent positions of words in our models as well. Let’s visualize this using Python.
import numpy as np
import matplotlib.pyplot as plt
corpus = np.array([[1,10],[8,8],[2,2],[2,2]])
print(corpus)
[[ 1 10]
[ 8 8]
[ 2 2]
[ 2 2]]
Graphing our model
We don’t just have to think of our words as columns. We can also think of them as dimensions, and the values as coordinates for each document.
# matplotlib expects a list of values by column, not by row.
# We can simply turn our table on its edge so rows become columns and vice versa.
corpusT = np.transpose(corpus)
print(corpusT)
[[ 1 8 2 2]
[10 8 2 2]]
X = corpusT[0]
Y = corpusT[1]
# define some colors for each point. Since points A and B are the same, we'll have them as the same color.
mycolors = ['r','g','b','b']
# display our visualization
plt.scatter(X,Y, c=mycolors)
plt.xlim(0, 12)
plt.ylim(0, 12)
plt.show()
Distance and Similarity
What can we do with this simple model? At the heart of many research tasks is distance or similarity, in some sense. When we classify or search for documents, we are asking for documents that are “close to” some known examples or search terms. When we explore the topics in our documents, we are asking for a small set of concepts that capture and help explain as much as the ways our documents might differ from one another. And so on.
There are two measures of distance/similarity we’ll consider here: Euclidean distance and cosine similarity.
Euclidean Distance
The Euclidian distance formula makes use of the Pythagorean theorem, where $a^2 + b^2 = c^2$. We can draw a triangle between two points, and calculate the hypotenuse to find the distance. This distance formula works in two dimensions, but can also be generalized over as many dimensions as we want. Let’s use distance to compare A to B, C and D. We’ll say the closer two points are, the smaller their distance, so the more similar they are.
from sklearn.metrics.pairwise import euclidean_distances as dist
#What is closest to document D?
D = [corpus[3]]
print(D)
[array([2, 2])]
dist(corpus, D)
array([[8.06225775],
[8.48528137],
[0. ],
[0. ]])
Distance may seem like a decent metric at first. Certainly, it makes sense that document D has zero distance from itself. C and D are also similar, which makes sense given our bag of words assumption. But take a closer look at documents B and D. Document B is just document D copy and pasted 4 times! How can it be less similar to document D than document B?
Distance is highly sensitive to document length. Because document A is shorter than document B, it is closer to document D. While distance may be an intuitive measure of similarity, it is actually highly dependent on document length.
We need a different metric that will better represent similarity. This is where vectors come in. Vectors are geometric objects with both length and direction. They can be thought of as a ray or an arrow pointing from one point to another.
Vectors can be added, subtracted, or multiplied together, just like regular numbers can. Our model will consider documents as vectors instead of points, going from the origin at $(0,0)$ to each document. Let’s visualize this.
# we need the point of origin in order to draw a vector. Numpy has a function to create an array full of zeroes.
origin = np.zeros([1,4])
print(origin)
[[0. 0. 0. 0.]]
# draw our vectors
plt.quiver(origin, origin, X, Y, color=mycolors, angles='xy', scale_units='xy', scale=1)
plt.xlim(0, 12)
plt.ylim(0, 12)
plt.show()
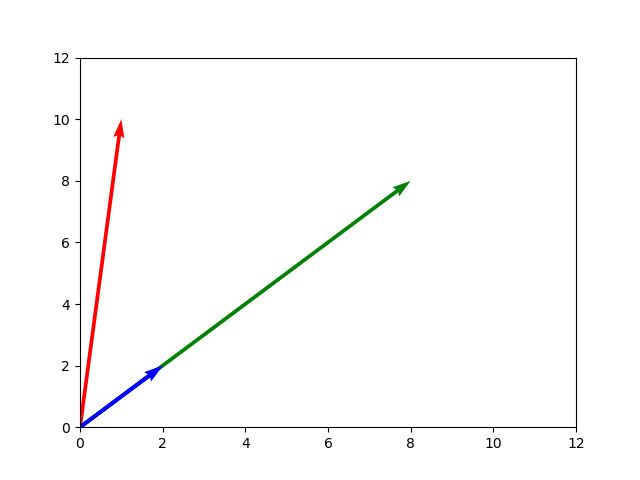
Document A and document D are headed in exactly the same direction, which matches our intution that both documents are in some way similar to each other, even though they differ in length.
Cosine Similarity
Cosine Similarity is a metric which is only concerned with the direction of the vector, not its length. This means the length of a document will no longer factor into our similarity metric. The more similar two vectors are in direction, the closer the cosine similarity score gets to 1. The more orthogonal two vectors get (the more at a right angle they are), the closer it gets to 0. And as the more they point in opposite directions, the closer it gets to -1.
You can think of cosine similarity between vectors as signposts aimed out into multidimensional space. Two similar documents going in the same direction have a high cosine similarity, even if one of them is much further away in that direction.
Now that we know what cosine similarity is, how does this metric compare our documents?
from sklearn.metrics.pairwise import cosine_similarity as cs
cs(corpus, D)
array([[0.7739573],
[1. ],
[1. ],
[1. ]])
Both A and D are considered similar by this metric. Cosine similarity is used by many models as a measure of similarity between documents and words.
Generalizing over more dimensions
If we want to add another word to our model, we can add another dimension, which we can represent as another column in our table. Let’s add more documents with new words in them.
- E: be or not be
- F: to be or not to be
| Document | to | be | or | not |
|---|---|---|---|---|
| Document A | 1 | 10 | 0 | 0 |
| Document B | 8 | 8 | 0 | 0 |
| Document C | 2 | 2 | 0 | 0 |
| Document D | 2 | 2 | 0 | 0 |
| Document E | 0 | 2 | 1 | 1 |
| Document F | 2 | 2 | 1 | 1 |
We can keep adding dimensions for however many words we want to add. It’s easy to imagine vector space with two or three dimensions, but visualizing this mentally will rapidly become downright impossible as we add more and more words. Vocabularies for natural languages can easily reach tens of thousands of words.
Keep in mind, it’s not necessary to visualize how a high dimensional vector space looks. These relationships and formulae work over an arbitrary number of dimensions. Our methods for how to measure similarity will carry over, even if drawing a graph is no longer possible.
# add two new dimensions to our corpus
corpus = np.hstack((corpus, np.zeros((4,2))))
print(corpus)
[[ 1. 10. 0. 0.]
[ 8. 8. 0. 0.]
[ 2. 2. 0. 0.]
[ 2. 2. 0. 0.]]
E = np.array([[0,2,1,1]])
F = np.array([[2,2,1,1]])
#add document E to our corpus
corpus = np.vstack((corpus, E))
print(corpus)
[[ 1. 10. 0. 0.]
[ 8. 8. 0. 0.]
[ 2. 2. 0. 0.]
[ 2. 2. 0. 0.]
[ 0. 2. 1. 1.]]
What do you think the most similar document is to document F?
cs(corpus, F)
array([[0.69224845],
[0.89442719],
[0.89442719],
[0.89442719],
[0.77459667]])
This new document seems most similar to the documents B,C and D.
This principle of using vector space will hold up over an arbitrary number of dimensions, and therefore over a vocabulary of arbitrary size.
This is the essence of vector space modeling: documents are embedded as vectors in very high dimensional space.
How we define these dimensions and the methods for feature extraction may change and become more complex, but the essential idea remains the same.
Next, we will discuss TF-IDF, which balances the above “bag of words” approach against the fact that some words are more or less interesting: whale conveys more useful information than the, for example.
Key Points
We model documents by plotting them in high dimensional space.
Distance is highly dependent on document length.
Documents are modeled as vectors so cosine similarity can be used as a similarity metric.
Document Embeddings and TF-IDF
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is a document embedding?
What is TF-IDF?
Objectives
Produce TF-IDF matrix on a corpus
Understand how TF-IDF relates to rare/common words
The method of using word counts is just one way we might embed a document in vector space.
Let’s talk about more complex and representational ways of constructing document embeddings.
To start, imagine we want to represent each word in our model individually, instead of considering an entire document.
How individual words are represented in vector space is something called “word embeddings” and they are an important concept in NLP.
One hot encoding: Limitations
How would we make word embeddings for a simple document such as “Feed the duck”?
Let’s imagine we have a vector space with a million different words in our corpus, and we are just looking at part of the vector space below.
| dodge | duck | … | farm | feather | feed | … | tan | the | |
|---|---|---|---|---|---|---|---|---|---|
| feed | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ||
| the | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ||
| duck | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ||
| Document | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
Similar to what we did in the previous lesson, we can see that each word embedding gives a 1 for a dimension corresponding to the word, and a zero for every other dimension. This kind of encoding is known as “one hot” encoding, where a single value is 1 and all others are 0.
Once we have all the word embeddings for each word in the document, we sum them all up to get the document embedding. This is the simplest and most intuitive way to construct a document embedding from a set of word embeddings.
But does it accurately represent the importance of each word?
Our next model, TF-IDF, will embed words with different values rather than just 0 or 1.
TF-IDF Basics
Currently our model assumes all words are created equal and are all equally important. However, in the real world we know that certain words are more important than others.
For example, in a set of novels, knowing one novel contains the word the 100 times does not tell us much about it. However, if the novel contains a rarer word such as whale 100 times, that may tell us quite a bit about its content.
A more accurate model would weigh these rarer words more heavily, and more common words less heavily, so that their relative importance is part of our model.
However, rare is a relative term. In a corpus of documents about blue whales, the term whale may be present in nearly every document. In that case, other words may be rarer and more informative. How do we determine how these weights are done?
One method for constructing more advanced word embeddings is a model called TF-IDF.
TF-IDF stands for term frequency-inverse document frequency and can be calculated for each document, d, and term, t, in a corpus. The calculation consists of two parts: term frequency and inverse document frequency. We multiply the two terms to get the TF-IDF value.
Term frequency(t,d) is a measure for how frequently a term, t, occurs in a document, d. The simplest way to calculate term frequency is by simply adding up the number of times a term occurs in a document, and dividing by the total word count in the document.
Inverse document frequency measures a term’s importance. Document frequency is the number of documents, N, a term occurs in, so inverse document frequency gives higher scores to words that occur in fewer documents. This is represented by the equation:
IDF(t) = ln[(N+1) / (DF(t)+1)]
where…
- N represents the total number of documents in the corpus
- DF(t) represents document frequency for a particular term/word, t. This is the number of documents a term occurs in.
The key thing to understand is that words that occur in many documents produce smaller IDF values since the denominator grows with DF(t).
We can also embed documents in vector space using TF-IDF scores rather than simple word counts. This also weakens the impact of stop-words, since due to their common nature, they have very low scores.
Now that we’ve seen how TF-IDF works, let’s put it into practice.
Worked Example: TD-IDF
Earlier, we preprocessed our data to lemmatize each file in our corpus, then saved our results for later.
Let’s load our data back in to continue where we left off:
from pandas import read_csv
data = read_csv("/content/drive/My Drive/Colab Notebooks/text-analysis/data/data.csv")
TD-IDF Vectorizer
Next, let’s load a vectorizer from sklearn that will help represent our corpus in TF-IDF vector space for us.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(input='filename', max_df=.6, min_df=.1)
Here, max_df=.6 removes terms that appear in more than 60% of our documents (overly common words like the, a, an) and min_df=.1 removes terms that appear in less than 10% of our documents (overly rare words like specific character names, typos, or punctuation the tokenizer doesn’t understand). We’re looking for that sweet spot where terms are frequent enough for us to build theoretical understanding of what they mean for our corpus, but not so frequent that they can’t help us tell our documents apart.
Now that we have our vectorizer loaded, let’s used it to represent our data.
tfidf = vectorizer.fit_transform(list(data["Lemma_File"]))
print(tfidf.shape)
(41, 9879)
Here, tfidf.shape shows us the number of rows (books) and columns (words) are in our model.
Check Your Understanding:
max_dfandmin_dfTry different values for
max_dfandmin_df. How does increasing/decreasing each value affect the number of columns (words) that get included in the model?Solution
Increasing
max_dfresults in more words being included in the more, since a highermax_dfcorresponds to accepting more common words in the model. A highermax_dfaccepts more words likely to be stopwords.Inversely, increasing
min_dfreduces the number of words in the more, since a highermin_dfcorresponds to removing more rare words from the model. A highermin_dfremoves more words likely to be typos, names of characters, and so on.
Inspecting Results
We have a huge number of dimensions in the columns of our matrix (just shy of 10,000), where each one of which represents a word. We also have a number of documents (about forty), each represented as a row.
Let’s take a look at some of the words in our documents. Each of these represents a dimension in our model.
vectorizer.get_feature_names_out()[0:5]
array(['15th', '1st', 'aback', 'abandonment', 'abase'], dtype=object)
What is the weight of those words?
print(vectorizer.idf_[0:5]) # weights for each token
[2.79175947 2.94591015 2.25276297 2.25276297 2.43508453]
Let’s show the weight for all the words:
from pandas import DataFrame
tfidf_data = DataFrame(vectorizer.idf_, index=vectorizer.get_feature_names_out(), columns=["Weight"])
tfidf_data
Weight
15th 2.791759
1st 2.945910
aback 2.252763
abandonment 2.252763
abase 2.435085
... ...
zealously 2.945910
zenith 2.791759
zest 2.791759
zigzag 2.945910
zone 2.791759
tfidf_data.sort_values(by="Weight")
That was ordered alphabetically. Let’s try from lowest to heighest weight:
Weight
unaccountable 1.518794
nest 1.518794
needless 1.518794
hundred 1.518794
hunger 1.518794
... ...
incurably 2.945910
indecent 2.945910
indeed 2.945910
incantation 2.945910
gentlest 2.945910
Your Mileage May Vary
The results above will differ based on how you configured your tokenizer and vectorizer earlier.
Values are no longer just whole numbers such as 0, 1 or 2. Instead, they are weighted according to how often they occur. More common words have lower weights, and less common words have higher weights.
TF-IDF Summary
In this lesson, we learned about document embeddings and how they could be done in multiple ways. While one hot encoding is a simple way of doing embeddings, it may not be the best representation. TF-IDF is another way of performing these embeddings that improves the representation of words in our model by weighting them. TF-IDF is often used as an intermediate step in some of the more advanced models we will construct later.
Key Points
Some words convey more information about a corpus than others
One-hot encodings treat all words equally
TF-IDF encodings weigh overly common words lower
Latent Semantic Analysis
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is topic modeling?
What is Latent Semantic Analysis (LSA)?
Objectives
Use LSA to explore topics in a corpus
Produce and interpret an LSA plot
So far, we’ve learned the kinds of task NLP can be used for, preprocessed our data, and represented it as a TF-IDF vector space.
Now, we begin to close the loop with Topic Modeling — one of many embedding-related tasks possible with NLP.
Topic Modeling is a frequent goal of text analysis. Topics are the things that a document is about, by some sense of “about.” We could think of topics as:
- discrete categories that your documents belong to, such as fiction vs. non-fiction
- or spectra of subject matter that your documents contain in differing amounts, such as being about politics, cooking, racing, dragons, …
In the first case, we could use machine learning to predict discrete categories, such as trying to determine the author of the Federalist Papers.
In the second case, we could try to determine the least number of topics that provides the most information about how our documents differ from one another, then use those concepts to gain insight about the “stuff” or “story” of our corpus as a whole.
In this lesson we’ll focus on this second case, where topics are treated as spectra of subject matter. There are a variety of ways of doing this, and not all of them use the vector space model we have learned. For example:
- Vector-space models:
- Principle Component Analysis (PCA)
- Epistemic Network Analysis (ENA)
- Latent Semantic Analysis (LSA)
- Probability models:
- Latent Dirichlet Allocation (LDA)
Specifically, we will be discussing Latent Semantic Analysis (LSA). We’re narrowing our focus to LSA because it introduces us to concepts and workflows that we will use in the future, in particular that of dimensional reduction.
What is dimensional reduction?
Think of a map of the Earth. The Earth is a three dimensional sphere, but we often represent it as a two dimensional shape such as a square or circle. We are performing dimensional reduction- taking a three dimensional object and trying to represent it in two dimensions.
Why do we create maps? It can often be helpful to have a two dimensional representation of the Earth. It may be used to get an approximate idea of the sizes and shapes of various countries next to each other, or to determine at a glance what things are roughly in the same direction.
How do we create maps? There’s many ways to do it, depending on what properties are important to us. We cannot perfectly capture area, shape, direction, bearing and distance all in the same model- we must make tradeoffs. Different projections will better preserve different properties we find desirable. But not all the relationships will be preserved- some projections will distort area in certain regions, others will distort directions or proximity. Our technique will likely depend on what our application is and what we determine is valuable.
Dimensional reduction for our data is the same principle. Why do we do dimensional reduction? When we perform dimensional reduction we hope to take our highly dimensional language data and get a useful ‘map’ of our data with fewer dimensions. We have various tasks we may want our map to help us with. We can determine what words and documents are semantically “close” to each other, or create easy to visualise clusters of points.
How do we do dimensional reduction? There are many ways to do dimensional reduction, in the same way that we have many projections for maps. Like maps, different dimensional reduction techniques have different properties we have to choose between- high performance in tasks, ease of human interpretation, and making the model easily trainable are a few. They are all desirable but not always compatible. When we lose a dimension, we inevitably lose data from our original representation. This problem is multiplied when we are reducing so many dimensions. We try to bear in mind the tradeoffs and find useful models that don’t lose properties and relationships we find important. But “importance” depends on your moral theoretical stances. Because of this, it is important to carefully inspect the results of your model, carefully interpret the “topics” it identifies, and check all that against your qualitative and theoretical understanding of your documents.
This will likely be an iterative process where you refine your model several times. Keep in mind the adage: all models are wrong, some are useful, and a less accurate model may be easier to explain to your stakeholders.
LSA
The assumption behind LSA is that underlying the thousands of words in our vocabulary are a smaller number of hidden (“latent”) topics, and that those topics help explain the distribution of the words we see across our documents. In all our models so far, each dimension has corresponded to a single word. But in LSA, each dimension now corresponds to a hidden topic, and each of those in turn corresponds to the words that are most strongly associated with it.
For example, a hidden topic might be the lasting influence of the Battle of Hastings on the English language, with some documents using more words with Anglo-Saxon roots and other documents using more words with Latin roots. This dimension is “hidden” because authors don’t usually stamp a label on their books with a summary of the linguistic histories of their words. Still, we can imagine a spectrum between words that are strongly indicative of authors with more Anglo-Saxon diction vs. words strongly indicative of authors with more Latin diction. Once we have that spectrum, we can place our documents along it, then move on to the next hidden topic, then the next, and so on, until we’ve discussed the fewest, strongest hidden topics that capture the most “story” about our corpus.
LSA requires two steps- first we must create a TF-IDF matrix, which we have already covered in our previous lesson.
Next, we will perform dimensional reduction using a technique called SVD.
Worked Example: LSA
In case you are starting from a fresh notebook, you will need to (1), mount Google drive (2) add the helper code to your path, (3) load the data.csv file, and (4) pip install parse which is used in the helper function code.
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
# Show existing colab notebooks and helpers.py file
from os import listdir
wksp_dir = '/content/drive/My Drive/Colab Notebooks/text-analysis/code'
print(listdir(wksp_dir))
# Add folder to colab's path so we can import the helper functions
import sys
sys.path.insert(0, wksp_dir)
# Read the data back in.
from pandas import read_csv
data = read_csv("/content/drive/My Drive/Colab Notebooks/text-analysis/data/data.csv")
data.head()
!pip install pathlib parse # parse is used by helper functions
Mathematically, these “latent semantic” dimensions are derived from our TF-IDF matrix, so let’s begin there. From the previous lesson:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(input='filename', max_df=.6, min_df=.1) # Here, max_df=.6 removes terms that appear in more than 60% of our documents (overly common words like the, a, an) and min_df=.1 removes terms that appear in less than 10% of our documents (overly rare words like specific character names, typos, or punctuation the tokenizer doesn’t understand)
tfidf = vectorizer.fit_transform(list(data["Lemma_File"]))
print(tfidf.shape)
(41, 9879)
What do these dimensions mean? We have 41 documents, which we can think of as rows. And we have several thousands of tokens, which is like a dictionary of all the types of words we have in our documents, and which we represent as columns.
Dimension Reduction Via Singular Value Decomposition (SVD)
Now we want to reduce the number of dimensions used to represent our documents. We will use a technique called Singular Value Decomposition (SVD) to do so. SVD is a powerful linear algebra tool that works by capturing the underlying patterns and relationships within a given matrix. When applied to a TF-IDF matrix, it identifies the most significant patterns of word co-occurrence across documents and condenses this information into a smaller set of “topics,” which are abstract representations of semantic themes present in the corpus. By reducing the number of dimensions, we gradually distill the essence of our corpus into a concise set of topics that capture the key themes and concepts across our documents. This streamlined representation not only simplifies further analysis but also uncovers the latent structure inherent in our text data, enabling us to gain deeper insights into its content and meaning.
To see this, let’s begin to reduce the dimensionality of our TF-IDF matrix using SVD, starting with the greatest number of dimensions (min(#rows, #cols)). In this case the maxiumum number of ‘topics’ corresponds to the number of documents- 41.
from sklearn.decomposition import TruncatedSVD
maxDimensions = min(tfidf.shape)-1
svdmodel = TruncatedSVD(n_components=maxDimensions, algorithm="arpack") # The "arpack" algorithm is typically more efficient for large sparse matrices compared to the default "randomized" algorithm. This is particularly important when dealing with high-dimensional data, such as TF-IDF matrices, where the number of features (terms) may be large. SVD is typically computed as an approximation when working with large matrices.
lsa = svdmodel.fit_transform(tfidf)
print(lsa)
[[ 3.91364432e-01 -3.38256707e-01 -1.10255485e-01 ... -3.30703329e-04
2.26445596e-03 -1.29373990e-02]
[ 2.83139301e-01 -2.03163967e-01 1.72761316e-01 ... 1.98594965e-04
-4.41931701e-03 -1.84732254e-02]
[ 3.32869588e-01 -2.67008449e-01 -2.43271177e-01 ... 4.50149502e-03
1.99200352e-03 2.32871393e-03]
...
[ 1.91400319e-01 -1.25861226e-01 4.36682522e-02 ... -8.51158743e-04
4.48451964e-03 1.67944132e-03]
[ 2.33925324e-01 -8.46322843e-03 1.35493523e-01 ... 5.46406784e-03
-1.11972177e-03 3.86332162e-03]
[ 4.09480701e-01 -1.78620470e-01 -1.61670733e-01 ... -6.72035999e-02
9.27745251e-03 -7.60191949e-05]]
Unlike with a globe, we must make a choice of how many dimensions to cut out. We could have anywhere between 41 topics to 2.
How should we pick a number of topics to keep? Fortunately, the dimension reducing technique we used produces something to help us understand how much data each topic explains. Let’s take a look and see how much data each topic explains. We will visualize it on a graph.
import matplotlib.pyplot as plt
import numpy as np
#this shows us the amount of dropoff in explanation we have in our sigma matrix.
print(svdmodel.explained_variance_ratio_)
# Calculate cumulative sum of explained variance ratio
cumulative_variance_ratio = np.cumsum(svdmodel.explained_variance_ratio_)
plt.plot(range(1, maxDimensions + 1), cumulative_variance_ratio * 100)
plt.xlabel("Number of Topics")
plt.ylabel("Cumulative % of Information Retained")
plt.ylim(0, 100) # Adjust y-axis limit to 0-100
plt.grid(True) # Add grid lines
[0.02053967 0.12553786 0.08088013 0.06750632 0.05095583 0.04413301
0.03236406 0.02954683 0.02837433 0.02664072 0.02596086 0.02538922
0.02499496 0.0240097 0.02356043 0.02203859 0.02162737 0.0210681
0.02004 0.01955728 0.01944726 0.01830292 0.01822243 0.01737443
0.01664451 0.0160519 0.01494616 0.01461527 0.01455848 0.01374971
0.01308112 0.01255502 0.01201655 0.0112603 0.01089138 0.0096127
0.00830014 0.00771224 0.00622448 0.00499762]
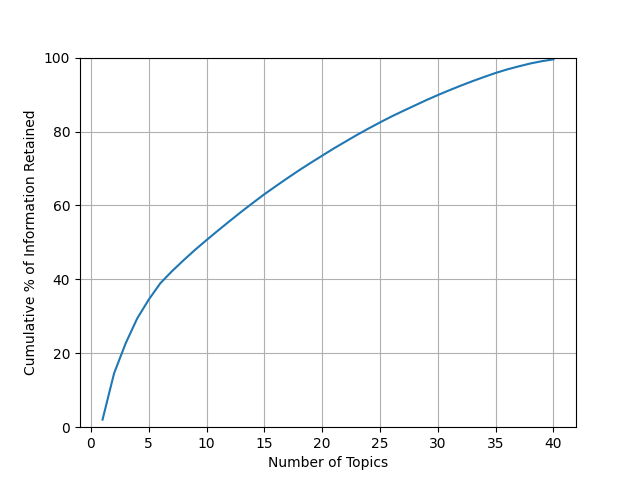
Often a heuristic used by researchers to determine a topic count is to look at the dropoff in percentage of data explained by each topic.
Typically the rate of data explained will be high at first, dropoff quickly, then start to level out. We can pick a point on the “elbow” where it goes from a high level of explanation to where it starts leveling out and not explaining as much per topic. Past this point, we begin to see diminishing returns on the amount of the “stuff” of our documents we can cover quickly. This is also often a good sweet spot between overfitting our model and not having enough topics.
Alternatively, we could set some target sum for how much of our data we want our topics to explain, something like 90% or 95%. However, with a small dataset like this, that would result in a large number of topics, so we’ll pick an elbow instead.
Looking at our results so far, a good number in the middle of the “elbow” appears to be around 5-7 topics. So, let’s fit a model using only 6 topics and then take a look at what each topic looks like.
Why is the first topic, “Topic 0,” so low?
It has to do with how our SVD was setup. Truncated SVD does not mean center the data beforehand, which takes advantage of sparse matrix algorithms by leaving most of the data at zero. Otherwise, our matrix will me mostly filled with the negative of the mean for each column or row, which takes much more memory to store. The math is outside the scope for this lesson, but it’s expected in this scenario that topic 0 will be less informative than the ones that come after it, so we’ll skip it.
numDimensions = 7
svdmodel = TruncatedSVD(n_components=numDimensions, algorithm="arpack")
lsa = svdmodel.fit_transform(tfidf)
print(lsa)
[[ 3.91364432e-01 -3.38256707e-01 -1.10255485e-01 -1.57263147e-01
4.46988327e-01 4.19701195e-02 -1.60554169e-01]
...
And put all our results together in one DataFrame so we can save it to a spreadsheet to save all the work we’ve done so far. This will also make plotting easier in a moment.
Since we don’t know what these topics correspond to yet, for now I’ll call the first topic X, the second Y, the third Z, and so on.
data[["X", "Y", "Z", "W", "P", "Q"]] = lsa[:, [1, 2, 3, 4, 5, 6]]
data.head()
Let’s also mean-center the data, so that the “average” value per topic (across all our documents) lies at the origin when we plot things in a moment. By mean-centering, you are ensuring that the “average” value for each topic becomes the reference point (0,0) in the plot, which can provide more informative insights into the relative distribution and relationships between topics.
data[["X", "Y", "Z", "W", "P", "Q"]] = lsa[:, [1, 2, 3, 4, 5, 6]]-lsa[:, [1, 2, 3, 4, 5, 6]].mean(0)
data[["X", "Y", "Z", "W", "P", "Q"]].mean()
X -7.446618e-18
Y -2.707861e-18
Z -1.353931e-18
W -1.184689e-17
P 3.046344e-18
Q 2.200137e-18
dtype: float64
Finally, let’s save our progress so far.
data.to_csv("/content/drive/My Drive/Colab Notebooks/text-analysis/data/data.csv", index=False)
Inspecting LSA Results
Plotting
Let’s plot the results, using a helper we prepared for learners. We’ll focus on the X and Y topics for now to illustrate the workflow. We’ll return to the other topics in our model as a further exercise.
from helpers import lsa_plot
lsa_plot(data, svdmodel)
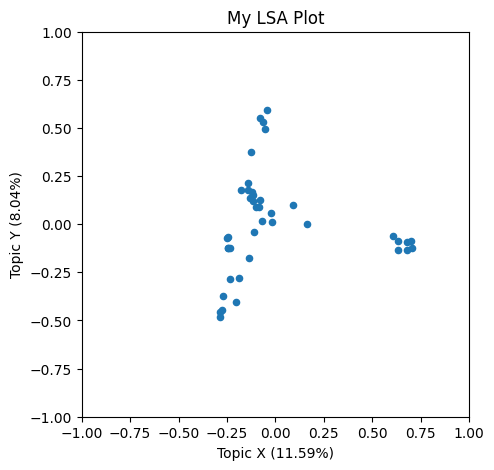
What do you think these X and Y axes are capturing, conceptually?
To help figure that out, lets color-code by author to see if any patterns are immediately apparent.
colormap = {
"austen": "red",
"chesterton": "blue",
"dickens": "green",
"dumas": "orange",
"melville": "cyan",
"shakespeare": "magenta"
}
lsa_plot(data, svdmodel, groupby="author", colors=colormap)
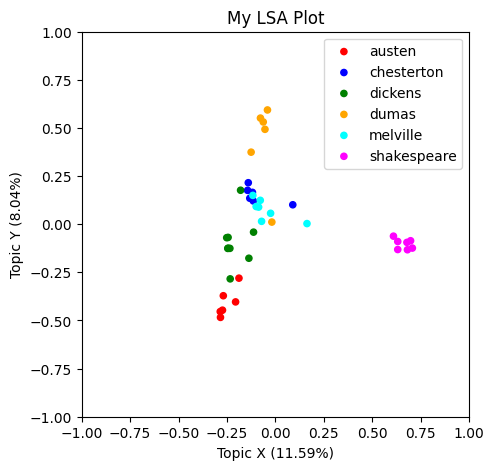
It seems that some of the books by the same author are clumping up together in our plot.
We don’t know why they are getting arranged this way, since we don’t know what more concepts X and Y correspond to. But we can work do some work to figure that out.
Topics
Let’s write a helper to get the strongest words for each topic. This will show the terms with the highest and lowest association with a topic. In LSA, each topic is a spectra of subject matter, from the kinds of terms on the low end to the kinds of terms on the high end. So, inspecting the contrast between these high and low terms (and checking that against our domain knowledge) can help us interpret what our model is identifying.
import pandas as pd
def show_topics(vectorizer, svdmodel, topic_number, n):
# Get the feature names (terms) from the TF-IDF vectorizer
terms = vectorizer.get_feature_names_out()
# Get the weights of the terms for the specified topic from the SVD model
weights = svdmodel.components_[topic_number]
# Create a DataFrame with terms and their corresponding weights
df = pd.DataFrame({"Term": terms, "Weight": weights})
# Sort the DataFrame by weights in descending order to get top n terms (largest positive weights)
highs = df.sort_values(by=["Weight"], ascending=False)[0:n]
# Sort the DataFrame by weights in ascending order to get bottom n terms (largest negative weights)
lows = df.sort_values(by=["Weight"], ascending=False)[-n:]
# Concatenate top and bottom terms into a single DataFrame and return
return pd.concat([highs, lows])
# Get the top 5 and bottom 5 terms for each specified topic
topic_words_x = show_topics(vectorizer, svdmodel, 1, 5) # Topic 1
topic_words_y = show_topics(vectorizer, svdmodel, 2, 5) # Topic 2
You can also use a helper we prepared for learners:
from helpers import show_topics
topic_words_x = show_topics(vectorizer, svdmodel, topic_number=1, n=5)
topic_words_y = show_topics(vectorizer, svdmodel, topic_number=2, n=5)
Either way, let’s look at the terms for the X topic.
What does this topic seem to represent to you? What’s the contrast between the top and bottom terms?
print(topic_words_x)
Term Weight
8718 thou 0.369606
4026 hath 0.368384
3104 exit 0.219252
8673 thee 0.194711
8783 tis 0.184968
9435 ve -0.083406
555 attachment -0.090431
294 am -0.103122
5312 ma -0.117927
581 aunt -0.139385
And the Y topic.
What does this topic seem to represent to you? What’s the contrast between the top and bottom terms?
print(topic_words_y)
Term Weight
1221 cardinal 0.269191
5318 madame 0.258087
6946 queen 0.229547
4189 honor 0.211801
5746 musketeer 0.203572
294 am -0.112988
5312 ma -0.124932
555 attachment -0.150380
783 behaviour -0.158139
581 aunt -0.216180
Now that we have names for our first two topics, let’s redo the plot with better axis labels.
lsa_plot(data, svdmodel, groupby="author", colors=colormap, xlabel="Victorian vs. Elizabethan", ylabel="English vs. French")
Check Your Understanding: Intrepreting LSA Results
Let’s repeat this process with the other 4 topics, which we tentatively called Z, W, P, and Q.
In the first two topics (X and Y), some authors were clearly separated, but others overlapped. If we hadn’t color coded them, we wouldn’t be easily able to tell them apart.
But in remaining topics, different combinations of authors get pulled apart or together. This is because these topics (Z, W, P, and Q) highlight different features of the data, independent of the features we’ve already captured above.
Take a few moments to work through the steps above for the remaining dimensions Z, W, P, and Q, and chat with one another about what you think the topics being represented are.
Key Points
Topic modeling helps explore and describe the content of a corpus
LSA defines topics as spectra that the corpus is distributed over
Each dimension (topic) in LSA corresponds to a contrast between positively and negatively weighted words
Intro to Word Embeddings
Overview
Teaching: 40 min
Exercises: 5 minQuestions
How can we extract vector representations of individual words rather than documents?
What sort of research questions can be answered with word embedding models?
Objectives
Understand the difference between document embeddings and word embeddings
Introduce the Gensim python library and its word embedding functionality
Explore vector math with word embeddings using pretrained models
Visualize word embeddings with the help of principal component analysis (PCA)
Discuss word embedding use-cases
Load pre-trained model via Gensim
First, load the Word2Vec embedding model. The Word2Vec model takes 3-10 minutes to load.
We’ll be using the Gensim library. The Gensim library comes with several word embedding models including Word2Vec, GloVe, and fastText. We’ll start by exploring one of the pre-trained Word2Vec models. We’ll discuss the other options later in this lesson.
If you can’t get the below word2vec model to load quickly enough, you can use the GloVe model, instead. The GloVe model produces word embeddings that are often very similar to Word2Vec. GloVe can be loaded with:wv = api.load('glove-wiki-gigaword-50')
# RUN BEFORE INTRO LECTURE :)
# api to load word2vec models
import gensim.downloader as api
# takes 3-10 minutes to load
wv = api.load('word2vec-google-news-300') # takes 3-10 minutes to load
Document/Corpus Embeddings Recap
So far, we’ve seen how word counts (bag of words), TF-IDF, and LSA can help us embed a document or set of documents into useful vector spaces that allow us to gain insights from text data. Let’s review the embeddings covered thus far…
-
Word count embeddings: Word count embeddings are a simple yet powerful method that represent text data as a sparse vector where each dimension corresponds to a unique word in the vocabulary, and the value in each dimension indicates the frequency of that word in the document. This approach disregards word order and context, treating each document as an unordered collection of words or tokens.
-
TF-IDF embeddings: Term Frequency Inverse Document Frequency (TF-IDF) is a fancier word-count method. It emphasizes words that are both frequent within a specific document and rare across the entire corpus.
-
LSA embeddings: Latent Semantic Analysis (LSA) is used to find the hidden topics represented by a group of documents. It involves running singular-value decomposition (SVD) on a document-term matrix (typically the TF-IDF matrix), producing a vector representation of each document. This vector scores each document’s representation in different topic/concept areas which are derived based on word co-occurences (e.g., 45% topic A, 35% topic B, and 20% topic C). Importantly, LSA is considered a bag of words method since the order of words in a document is not considered.
To get a high-level overview of the embedding methods covered thus far, study the table below:
| Technique | Input | Embedding Structure | Output Vector Dimensions | Meaning Stored | Order Dependency |
|---|---|---|---|---|---|
| Word Counts | Raw text corpus | Sparse vectors | [1, Vocabulary Size] (per document) |
Word presence in documents | No (bag of words) |
| TF-IDF | Word Counts | Sparse vectors | [1, Vocabulary Size] (per document) |
Importance of terms in documents | No (bag of words) |
| Latent Semantic Analysis (LSA) | TF-IDF or similar | Dense vectors | [1, Number of Topics] (per document) |
Semantic topics present in documents | No (bag of words) |
Bag of Words limitations
In all of these emebdding methods, notice how the order of words in sentences does not matter. We are simply tossing all words in a corpus into a bag (“bag of words”) and attempting to glean insights from this bag of words. While such an approach can be effective for revealing broad topics/concepts from text, additional features of language may be revealed by zooming in on the context in which words appear throughout a text.
For instance, maybe our bag of words contains the following: “cook”, “I”, “family”, “my”, “to”, “dinner”, “love”, and “for”. Depending on how these words are arranged, the meaning conveyed will change drastically!
- I love to cook dinner for my family.
- I love to cook family for my dinner.
Distributional hypothesis: extracting more meaningful representations of text
To clarify whether our text is about a nice wholesome family or a cannibal on the loose, we need to include context in our embeddings. As the famous linguist JR Firth once said, “You shall know a word by the company it keeps.” Firth is referring to the distributional hypothesis, which states that words that repeatedly occur in similar contexts probably have similar meanings. While the LSA methodology is inspired by the distributional hypothesis, LSA ignores the context of words as they appear in sentences and only pays attention to global word co-occurence patterns across large chunks of texts. If we want to truly know a word based on the company it keeps, we’ll need to take into account how some words are more likely to appear before/after other words in a sentence. We’ll explore how one of the most famous embedding models, Word2Vec, does this in this episode.
Word embeddings with Word2Vec
Word2vec is a famous word embedding method that was created and published in the ancient year of 2013 by a team of researchers led by Tomas Mikolov at Google over two papers, [1, 2]. Unlike with TF-IDF and LSA, which are typically used to produce document and corpus embeddings, Word2Vec focuses on producing a single embedding for every word encountered in a corpus. These embeddings, which are represented as high-dimesional vectors, tend to look very similar for words that are used in similar contexts. Adding this method to our overview table, we get:
| Technique | Input | Embedding Structure | Output Vector Dimensions | Meaning Stored | Order Dependency |
|---|---|---|---|---|---|
| Word Counts | Raw text corpus | Sparse vectors | [1, Vocabulary Size] (per document) |
Word presence in documents | No (bag of words) |
| TF-IDF | Word Counts | Sparse vectors | [1, Vocabulary Size] (per document) |
Importance of terms in documents | No (bag of words) |
| Latent Semantic Analysis (LSA) | TF-IDF or similar | Dense vectors | [1, Number of Topics] (per document) |
Semantic topics present in documents | No (bag of words) |
| Word2Vec | Raw text corpus | Dense vectors | [1, Embedding Dimension] (per word) |
Semantic meaning of words | Yes (word order) |
The next supplemental episode unpacks the technology behind Word2Vec — neural networks. In the interest of time, we will only cover the key concepts and intuition. Please consider studying the next episode if you are interested in learning more about the fascinating world of neural networks and how they actually work. For now, it is sufficient to be aware of few key insights.
1. Neural networks have an exceptional ability to learn functions that can map a set of input features to some output.
Because of this general capability, they can be used for a wide assortment of tasks including…
- Predicting the weather tomorrow given historical weather patterns
- Classifying if an email is spam or not
- Classifying if an image contains a person or not
- Predicting a person’s weight based on their height, age, location, etc.
- Predicting commute times given traffic conditions
- Predicting house prices given stock market prices
2. Neural networks learn new meaningful features from the input data.
Specifically, the learned features will be features that are useful for whatever task the model is assigned. With this consideration, we can devise a language related task that allows a neural network model to learn interesting features of words which can then be extracted from the model as a word embedding representation (i.e., a vector).
What task can we give a neural network to learn meaningful word embeddings? Our friend RJ Firth gives us a hint when he says, “You shall know a word by the company it keeps.” Using the distributional hypothesis as motivation, which states that words that repeatedly occur in similar contexts probably have similar meanings, we can ask a neural network to predict the context words that surround a given word in a sentence or, similarly, ask it to predict the center word based on context words. Both variants are shown below — Skip Gram and Continous Bag of Words (CBOW).
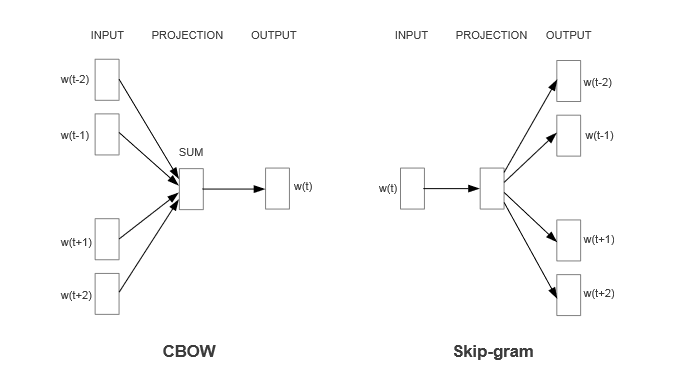
Learning a vector representation of the word, “outside”
Word2Vec is an neural network model that learns high-dimensional (many features) vector representations of individual words based on observing a word’s most likely surrounding words in multiple sentences (dist. hypothesis). For instance, suppose we want to learn a vector representation of the word “outside”. For this, we would train the Word2Vec model on many sentences containing the word, “outside”.
- It’s a beautiful day outside, perfect for a picnic.
- My cat loves to spend time outside, chasing birds and bugs.
- The noise outside woke me up early this morning.
- I always feel more relaxed after spending some time outside in nature.
- I can hear the rain pouring outside, it’s a good day to stay indoors.
- The sun is shining brightly outside, it’s time to put on some sunscreen.
- I saw a group of kids playing outside in the park.
- It’s not safe to leave your belongings outside unattended.
- I love to go for a walk outside after dinner to help me digest.
- The temperature outside is dropping, I need to grab a jacket before I leave.
In the process of training, the model’s weights learn to derive new features (weight optimized perceptrons) associated with the input data (single words). These new learned features will be conducive to accurately predicting the context words for each word. In addition, the features can be used as a information-rich vector representation of the word, “outside”.
Skip-gram versus Continuous Bag of Words: The primary difference between these two approaches lies in how CBOW and Skip-gram handle the context words for each target word. In CBOW, the context words are averaged together to predict the target word, while in Skip-gram, each context word is considered separately to predict the target word. While both CBOW and Skip-gram consider each word-context pair during training, Skip-gram often performs better with rare words because it treats each occurrence of a word separately, generating more training examples for rare words compared to CBOW. This can lead to better representations of rare words in Skip-gram embeddings.
3. The vectors learned by the model are a reflection of the model’s past experience.
Past experience = the specific data the model was “trained” on. This means that the vectors extracted from the model will reflect, on average, how words are used in a specific text. For example, notice how in the example sentences given above, the word “outside” tends to be surrounded by words associated with the outdoors.
4. The learned features or vectors are black boxes, lacking direct interpretability.
The learned vectors create useful and meaningful representations of words, capturing semantic relationships based on word co-occurrences. However, these vectors represent abstract features learned from the surrounding context of words in the training data, and are not directly interpretable. Still, once we have language mapped to a numerical space, we can compare things on a relative scale and ask a variety of reserach questions.
Word2Vec Applications
Take a few minutes to think about different types of questions or problems that could be addressed using Word2Vec and word embeddings. Share your thoughts and suggestions with the class.
Solution
- Semantic Change Over Time: How have the meanings of words evolved over different historical periods? By training Word2Vec models on texts from different time periods, researchers can analyze how word embeddings change over time, revealing shifts in semantic usage.
- Authorship Attribution: Can Word2Vec be used to identify the authors of anonymous texts or disputed authorship works? By comparing the word embeddings of known authors’ works with unknown texts, researchers can potentially attribute authorship based on stylistic similarities (e.g., Agrawal et al., 2023 and Liu, 2017).
- Authorship Attribution: Word2Vec has been applied to authorship attribution tasks (e.g., Tripto and Ali, 2023).
- Comparative Analysis of Multilingual Texts: Word2Vec enables cross-lingual comparisons. Researchers have explored multilingual embeddings to study semantic differences between languages (e.g., Heijden et al., 2019).
- Studying Cultural Concepts and Biases: Word2Vec helps uncover cultural biases in language. Researchers have examined biases related to race, religion, and colonialism (e.g., Petreski and Hashim, 2022).
Preliminary Considerations
In determining whether or not Word2Vec is a suitable embedding method for your research, it’s important to consider the following:
- Analysis Relevance: Does examining the relationships and meanings among words serve as a guideline for your research? Are you able to pinpoint specific terms or clusters of terms that encapsulate the broader conceptual realms you are investigating?
- Data Quality: Ensure that your text corpus is of high quality. Garbage or noisy data can adversely affect Word2Vec embeddings.
- Corpus Size: Word2Vec performs better with larger corpora. Having substantial text data improves the quality of learned word vectors.
- Domain-Specific Data Availability: Choose a dataset relevant to your DH research. If you’re analyzing historical texts, use historical documents. For sentiment analysis, domain-specific data matters.
Exploring Word2Vec in Python
With that said, let’s see what we can do with meaningful word vectors. The pre-trained model we loaded earlier was trained on a Google News dataset (about 100 billion words). We loaded this model as the variable wv earlier. Let’s check the type of this object.
print(type(wv))
<class 'gensim.models.keyedvectors.KeyedVectors'>
Gensim stores “KeyedVectors” representing the Word2Vec model. They’re called keyed vectors because you can use words as keys to extract the corresponding vectors. Let’s take a look at the vector representaton of whale.
wv['whale']
array([ 0.08154297, 0.41992188, -0.44921875, -0.01794434, -0.24414062,
-0.21386719, -0.16796875, -0.01831055, 0.32421875, -0.09228516,
-0.11523438, -0.5390625 , -0.00637817, -0.41601562, -0.02758789,
...,
0.078125 , 0.29882812, 0.34179688, 0.04248047, 0.03442383],
dtype=float32)
We can also check the shape of this vector with…
print(wv['whale'].shape)
(300,)
In this model, each word has a 300-dimensional representation. You can think of these 300 dimensions as 300 different features that encode a word’s meaning. Unlike LSA, which produces (somewhat) interpretable features (i.e., topics) relevant to a text, the features produced by Word2Vec will be treated as a black box. That is, we won’t actually know what each dimension of the vector represents. However, if the vectors have certain desirable properties (e.g., similar words produce similar vectors), they can still be very useful. Let’s check this with the help of the cosine similarity measure.
Cosine Similarity (Review): Recall from earlier in the workshop that cosine similarity helps evaluate vector similarity in terms of the angle that separates the two vectors, irrespective of vector magnitude. It can take a value ranging from -1 to 1, with…
- 1 indicating that the two vectors share the same angle
- 0 indicating that the two vectors are perpendicular or 90 degrees to one another
- -1 indicating that the two vectors are 180 degrees apart.
Words that occur in similar contexts should have similar vectors/embeddings. How similar are the word vectors representing whale and dolphin?
wv.similarity('whale','dolphin')
0.77117145
How about whale and fish?
wv.similarity('whale','fish')
0.55177623
How about whale and… potato?
wv.similarity('whale','potato')
0.15530972
Our similarity scale seems to be on the right track. We can also use the similarity function to quickly extract the top N most similar words to whale.
wv.most_similar(positive=['whale'], topn=10)
[('whales', 0.8474178910255432),
('humpback_whale', 0.7968777418136597),
('dolphin', 0.7711714506149292),
('humpback', 0.7535837292671204),
('minke_whale', 0.7365031838417053),
('humpback_whales', 0.7337379455566406),
('dolphins', 0.7213870882987976),
('humpbacks', 0.7138717174530029),
('shark', 0.7011443376541138),
('orca', 0.7007412314414978)]
Based on our ability to recover similar words, it appears the Word2Vec embedding method produces fairly good (i.e., semantically meaningful) word representations.
Exploring Words With Multiple Meanings
Use Gensim’s
most_similarfunction to find the top 10 most similar words to each of the following words (separately): “bark”, “pitcher”, “park”. Note that all of these words have multiple meanings depending on their context. Does Word2Vec capture the meaning of these words well? Why or why not?Solution
wv.most_similar(positive=['bark'], topn=15) # all seem to reflect tree bark wv.most_similar(positive=['park'], topn=15) # all seem to reflect outdoor parks wv.most_similar(positive=['pitcher'], topn=15) # all seem to reflect baseball pitchingBased on these three lists, it looks like Word2Vec is biased towards representing the predominant meaning or sense of a word. In fact, the Word2Vec does not explicitly differentiate between multiple meanings of a word during training. Instead, it treats each occurrence of a word in the training corpus as a distinct symbol, regardless of its meaning. As a result, resulting embeddings may be biased towards the most frequent meaning or sense of a word. This is because the more frequent a word sense appears in the training data, the more opportunities the algorithm has to learn that particular meaning.
Note that while this can be a limitation of Word2Vec, there are some techniques that can be applied to incorporate word sense disambiguation. One common approach is to train multiple embeddings for a word, where each embedding corresponds to a specific word sense. This can be done by pre-processing the training corpus to annotate word senses, and then training Word2Vec embeddings separately for each sense. This approach allows Word2Vec to capture different word senses as separate vectors, effectively representing the polysemy of the word.
Word2Vec Applications in Digital Humanities
From the above exercise, we see that the vectors produced by Word2Vec will reflect how words are typically used in a specific dataset. By training Word2Vec on large corpora of text from historical documents, literary works, or cultural artifacts, researchers can uncover semantic relationships between words and analyze word usage patterns over time, across genres, or within specific cultural contexts.
Taking this into consideration, what are some possible ways we could make use of Word2Vec to explore newspaper articles from the years 1900-2000?
Solution
One possible approach with this data is to investigate how the meaning of certain words can evolve over time by training separate models for different chunks of time (e.g., 1900-1950, 1951-2000, etc.). A few words that have changed their meaning over time include:
- Nice: This word used to mean “silly, foolish, simple.”
- Silly: In its earliest uses, it referred to things worthy or blessed; from there it came to refer to the weak and vulnerable, and more recently to those who are foolish.
- Awful: Awful things used to be “worthy of awe”.
We’ll explore how training a Word2Vec model on specific texts can yield insights into those texts later in this lesson.
Adding and Subtracting Vectors: King - Man + Woman = Queen
We can also add and subtract word vectors to reveal latent meaning in words. As a canonical example, let’s see what happens if we take the word vector representing King, subtract the Man vector from it, and then add the Woman vector to the result. We should get a new vector that closely matches the word vector for Queen. We can test this idea out in Gensim with:
print(wv.most_similar(positive=['woman','king'], negative=['man'], topn=3))
[('queen', 0.7118193507194519), ('monarch', 0.6189674139022827), ('princess', 0.5902431011199951)]
Behind the scenes of the most_similar function, Gensim first unit normalizes the length of all vectors included in the positive and negative function arguments. This is done before adding/subtracting, which prevents longer vectors from unjustly skewing the sum. Note that length here refers to the linear algebraic definition of summing the squared values of each element in a vector followed by taking the square root of that sum.
Visualizing word vectors with PCA
Similar to how we visualized our texts in the previous lesson to show how they relate to one another, we can visualize how a sample of words relate by plotting their respecitve word vectors.
Let’s start by extracting some word vectors from the pre-trained Word2Vec model.
import numpy as np
words = ['man','woman','boy','girl','king','queen','prince','princess']
sample_vectors = np.array([wv[word] for word in words])
sample_vectors.shape # 8 words, 300 dimensions
(8, 300)
Recall that each word vector has 300 dimensions that encode a word’s meaning. Considering humans can only visualize up to 3 dimensions, this dataset presents a plotting challenge. We could certainly try plotting just the first 2 dimensions or perhaps the dimensions with the largest amount of variability, but this would overlook a lot of the information stored in the other dimensions/variables. Instead, we can use a dimensionality-reduction technique known as Principal Component Analysis (PCA) to allow us to capture most of the information in the data with just 2 dimensions.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a data transformation technique that allows you to linearly combine a set of variables from a matrix (N observations and M variables) into a smaller set of variables called components. Specifically, it remaps the data onto new dimensions that are strictly orthogonal to one another and can be ordered according to the amount of information or variance they carry. The allows you to easily visualize most of the variability in the data with just a couple of dimensions.
We’ll use scikit-learn’s (a popular machine learning library) PCA functionality to explore the power of PCA, and matplotlib as our plotting library.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
In the code below, we will assess how much variance is stored in each dimension following PCA. The new dimensions are often referred to as principal components or eigenvectors, which relates to the underlying math behind this algorithm.
Notice how the first two dimensions capture around 70% of the variability in the dataset.
pca = PCA() # init PCA object
pca.fit(sample_vectors) # the fit function determines the new dimensions or axes to represent the data -- the result is sent back to the pca object
# Calculate cumulative variance explained
cumulative_variance_explained = np.cumsum(pca.explained_variance_ratio_)*100
# Plot cumulative variance explained
plt.figure()
plt.plot(range(1, len(cumulative_variance_explained) + 1), cumulative_variance_explained, '-o')
plt.xlabel("Number of Principal Components")
plt.ylabel("Cumulative Variance Explained (%)")
plt.title("Cumulative Variance Explained by Principal Components")
plt.show()
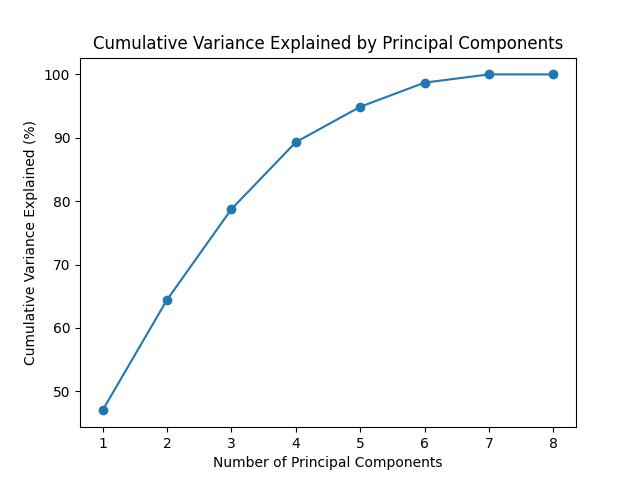
We can now use these new dimensions to transform the original data.
# transform the data
result = pca.transform(sample_vectors)
Once transformed, we can plot the first two principal components representing each word in our list: ['man', 'woman', 'boy', 'girl', 'king', 'queen', 'prince', 'princess']
plt.figure()
plt.scatter(result[:,0], result[:,1])
for i, word in enumerate(words):
plt.annotate(word, xy=(result[i, 0], result[i, 1]))
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.show()
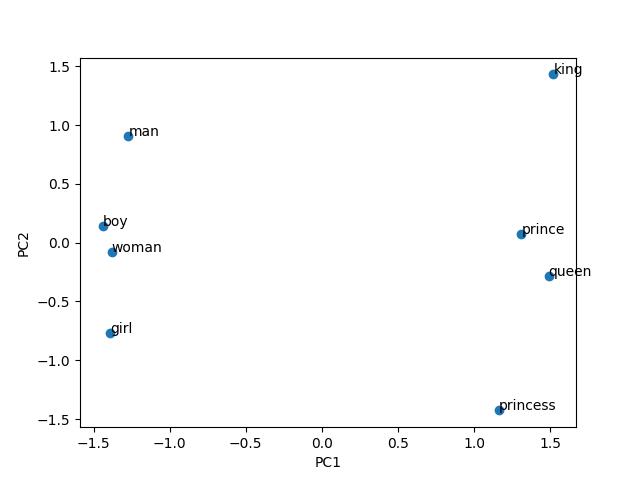
Note how the principal component 1 seems to represent the royalty dimension, while the principal component 2 seems to represent male vs female.
Recap
In summary, Word2Vec is a powerful text-embedding method that allows researchers to explore how different words relate to one another based on past observations (i.e., by being trained on a large list of sentences). Unlike LSA, which produces topics as features of the text to investigate, Word2Vec produces “black-box” features which have to be compared relative to one another. By training Word2Vec text from historical documents, literary works, or cultural artifacts, researchers can uncover semantic relationships between words and analyze word usage patterns over time, across genres, or within specific cultural contexts.
In the next section, we’ll explore the technology behind Word2Vec before training a Word2Vec model on some of the text data used in this workshop.
Key Points
Word emebddings can help us derive additional meaning stored in text at the level of individual words
Word embeddings have many use-cases in text-analysis and NLP related tasks
The Word2Vec Algorithm
Overview
Teaching: 45 min
Exercises: 0 minQuestions
How does the Word2Vec model produce meaningful word embeddings?
How is a Word2Vec model trained?
Objectives
Introduce artificial neural networks and their structure.
Understand the two training methods employed by the Word2Vec, CBOW and Skip-gram.
Related Carpentries workshops
We could spend an entire workshop on neural networks (see here and here for a couple of related lessons). Here, we will distill some of the most important concepts needed to understand them in the context of text-analysis.
Mapping inputs to outputs using neural networks
How is it that Word2Vec is able to represent words in such a semantically meaningful way? The key technology behind Word2Vec is an artificial neural network. Neural networks are highly prevalent in many fields now due to their exceptional ability to learn functions that can map a set of input features to some output (e.g., a label or predicted value for some target variable). Because of this general capability, they can be used for a wide assortment of tasks including…
- Predicting the weather tomorrow given historical weather patterns
- Classifying if an email is spam or not
- Classifying if an image contains a person or not
- Predicting a person’s weight based on their height
- Predicting commute times given traffic conditions
- Predicting house prices given stock market prices
Supervised learning
Most machine learning systems “learn” by taking tabular input data with N observations (rows), M features (cols), and an associated output (e.g., a class label or predicted value for some target variable), and using it to form a model. The maths behind the machine learning doesn’t care what the data is as long as it can represented numerically or categorised. When the model learns this function based on observed data, we call this “training” the model.
Training Dataset Example
As a example, maybe we have recorded tail lengths, weights, and snout lengths from a disorganized vet clinic database that is missing some of the animals’ labels (e.g., cat vs dog). For simplicity, let’s say that this vet clinic only treats cats and dogs. With the help of neural networks, we could use a labelled dataset to learn a function mapping from tail length, weight, and snout length to the animal’s species label (i.e., a cat or a dog).
| Tail length (in) | Weight (lbs) | Snout length (in) | Label |
|---|---|---|---|
| 12.2 | 10.1 | 1.1 | cat |
| 11.6 | 9.8 | .82 | cat |
| 9.5 | 61.2 | 2.6 | dog |
| 9.1 | 65.7 | 2.9 | dog |
| … | … | … | … |
| 11.2 | 12.1 | .91 | cat |
In the above table used to train a neural network model, the model learns how best to map the observed features (tail length, weight, and snout length) to their assigned classes. After the model is trained, it can be used to infer the labels of unlabelled samples (so long as they hae tail length, weight, and snouth length recorded).
The Perceptron

The diagram above shows a perceptron — the computational unit that makes up artificial neural networks. Perceptrons are inspired by real biological neurons. From the diagram, we can see that the perceptron…
- Input features: Receives multiple input features and returns a single output
- Weights connecting features: Has adjustable weights which scale the impact of individual inputs
- Nonlinear activation function: Has a nonlinear activation function which takes as input, the weighted sum of inputs. If the sum is above some threshold, the neuron “fires” a signal (outputs -1 or 1 which represents two different class labels)
The goal then is to determine what specific weight values will allow us to separate the two classes based on the input features (e.g., shown below).

In order to determine the optimal weights, we will need to “train” the model on a labelled “training” dataset. As we pass each observation in the training data to the model, the model is able to adjust its weights in a direction that leads better performance. By training the model on many observations, we can derive weights that can accurately classify cats and dogs based on the observed input features. More explicitly, its training method can be outlined as follows:
Training algorithm
-
Initialize weights: The perceptron model starts with randomly initialized weights. These weights are the parameters/coefficients that the model will learn during training to make accurate predictions.
-
Input data: The perceptron model takes in the input data, which consists of feature vectors representing the input samples, and their corresponding labels or target values.
-
Compute weighted sum: The model computes the weighted sum of the input features by multiplying the feature values with their corresponding weights, and summing them up. This is followed by adding the bias term.
-
Activation function: The perceptron model applies an activation function, typically a step function or a threshold function, to the computed weighted sum. The activation function determines the output of the perceptron, usually producing a binary output of 0 or 1.
-
Compare with target label: The output of the perceptron is compared with the target label of the input sample to determine the prediction error. If the prediction is correct, no weight updates are made. If the prediction is incorrect, the weights and bias are updated to minimize the error.
-
Update weights: The perceptron model updates the weights based on a learning rate and the prediction error. The learning rate determines the step size of the weight updates, and it is a hyperparameter that needs to be tuned. The weights are updated using the formula:
weight_new = weight_old + learning_rate * (target - prediction) * feature
Perceptron limitations
A single perceptron cannot solve any function that is not linearly separable, meaning that we need to be able to divide the classes of inputs and outputs with a straight line. To overcome this key limitation of the perceptron (a single aritifical neuron), we need to stack together multiple perceptrons in a hierarchical fashion. Such models are referred to as multilayer perceptrons or simply neural networks
The multilayer perceptron (MLP)
To overcome the limitation of the perceptron, we can stack together multiple perceptrons in a multilayer neural network (shown below) called a multilayer perceptron (MLP). An MLP refers to a type of artificial neural network (ANN) that consists of multiple layers of interconnected nodes (neurons) organized in a feedforward manner. It typically has one or more hidden layers between the input and output layers, with each hidden layer applying an activation function to the weighted sum of its inputs. By stacking together layers of perceptrons, the MLP model can learn complex non-linear relationships in the data and make predictions based on those learned patterns.

In the diagram above, the general structure of a multilayer neural network is shown with…
- Input Layer: The input layer is the first layer of the MLP and consists of input nodes that receive the features of the input data. Each node in the input layer represents a feature or attribute of the input data. The input layer is not involved in any computation or activation; it simply passes the input features to the next layer.
- Hidden Layer(s): The hidden layers are the intermediate layers between the input and output layers. In the above diagram, there is only 1 hidden layer, but MLPs often have more. They are called “hidden” because their outputs are not directly visible in the input or output data. Each hidden layer consists of multiple nodes (neurons) that compute a weighted sum of the inputs from the previous layer, followed by an activation function. The number of hidden layers and the number of nodes in each hidden layer are hyperparameters that can be tuned during model design and training.
- Weighted Connections: Each connection between nodes in adjacent layers has a weight associated with it. These weights are the parameters that the model learns during training to determine the strength of the connections. The weighted sum of inputs to a node is computed by multiplying the input values with their corresponding weights and summing them up. Also referred to as “weights” for short.
- Weights: The weights of each neuron send its (weighted) output to each neuron in the subsequent layer
- Output Layer: The output layer is the last layer of the MLP and produces the final output of the model. It typically consists of one or more nodes, depending on the specific task. For binary classification, a single output node with a sigmoid activation function is commonly used. For multi-class classification, multiple output nodes with a softmax activation function are used. For regression tasks, a single output node with a linear activation function is often used.
Training algorithm
Similar to the perceptron, the MLP is trained using a supervised learning algorithm that updates the weights iteratively based on the prediction error of each training sample.
- Initialization: The network’s weights are randomly initialized.
- Forward Propagation: Input data is fed through the network from input nodes to output nodes, with weights applied at each connection, and the output is computed.
- Error Calculation: The difference between the predicted output and the actual output (target) is calculated as the error.
- Backpropagation: The error is propagated backward through the network, and the weights are adjusted to minimize the error.
- Iterative Process: Steps 2-4 are repeated for multiple iterations or epochs, with input data fed through the network and weights updated until the network’s performance converges to a satisfactory level.
- Function Mapping: Once the network is trained, it can be used to map new input data to corresponding outputs, leveraging the learned weights.
Deriving New Features from Neural Networks
After training a neural network, the neural weights encode new features of the data that are conducive to performing well on whatever task the neural network is given. This is due to the feedforward processing built into the network — the outputs of previous layers are sent to subsequent layers, and the so additional transformations get applied to the original inputs as they transcend the network.
Generally speaking, the deeper the neural network is, the more complicated/abstract these features can become. We call this a hierarchical feature representation. For example, in deep convolutional neural networks (a special kind of neural network designed for image processing), the features in each layer look something like the image shown below when the model is trained on a facial recognition task.
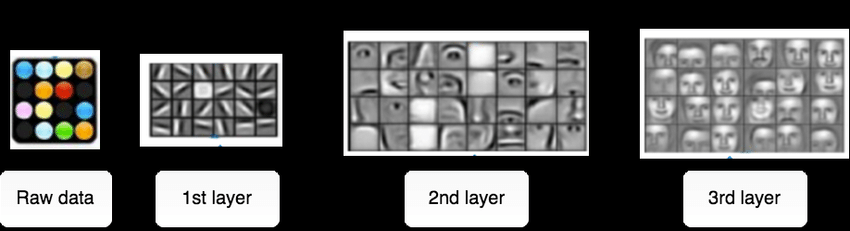
Training Word2Vec to Learn Word Embeddings
Recall that the ultimate goal of the Word2Vec method is to output meaningful word embeddings/vectors. How can we train a neural network for such a task? We could try to tediously hand-craft a large list of word vectors that have the properties we seek (e.g., similar words have similar vectors), and then train a neural network to learn this mapping before applying it to new words. However, crafting a list of vectors manually would be an arudous task. Furthermore, it is not immediately clear what kind of vector representation would be best.
Instead, we can capitalize on the fact that neural networks are well posed to learn new features from the input data. Specifically, the new features will be features that are useful for whatever task the model is assigned. With this consideration, we can devise a language related task that allows a neural network model to learn interesting features of words which can then be extracted from the model as a word embedding representation (i.e., a vector). We’ll unpack how the embedding gets extracted from the trained model shortly. For now, let’s focus on what kind of language-related task to give the model.
Predicting context words
What task can we give a neural network to learn meaningful word embeddings? Our friend RJ Firth gives us a hint when he says, “You shall know a word by the company it keeps.” Using the distributional hypothesis as motivation, which states that words that repeatedly occur in similar contexts probably have similar meanings, we can ask a neural network to predict the context words that surround a given word in a sentence. The Skip-gram algorithm shown on the right side of the below diagram does just that.
Sentence Processing With Skip-Gram
The Skip-gram version takes as input each word in a sentence, and tries to guess the most likely surrounding context words associated with that word. It does this for all sentences and words in a corpus in order to learn a function that can map each word to its most likely context words.
Have a very nice day.
| Input | Output (context words) |
|---|---|
| Have | a, very |
| a | Have, very, nice |
| very | Have, a, nice, day |
| nice | a, very, day |
| day | very, nice |
In the process of training, the model’s weights learn to derive new features (weight optimized perceptrons) associated with the input data (single words). These new learned features will be conducive to accurately predicting the context words for each word. We will see next how we can extract these features as word vectors.
Extracting Word Embeddings From the Model
With a model trained to predict context words, how can we extract the model’s learned features as word embeddings? For this, we need a set of model weights associated with each word fed into the model. We can achieve this property by:
- Converting each input word into a one-hot encoded vector representation. The vector dimensionality will be equal to the size of the vocabularly contained in the training data.
- Connecting each element of the one-hot encoded vector to each node/neuron in the subsequent hidden layer of neurons
These steps can be visualized in the Word2Vec model diagram shown below, with Sigmas representing individual neurons and their ability to integrate input from previous layers.
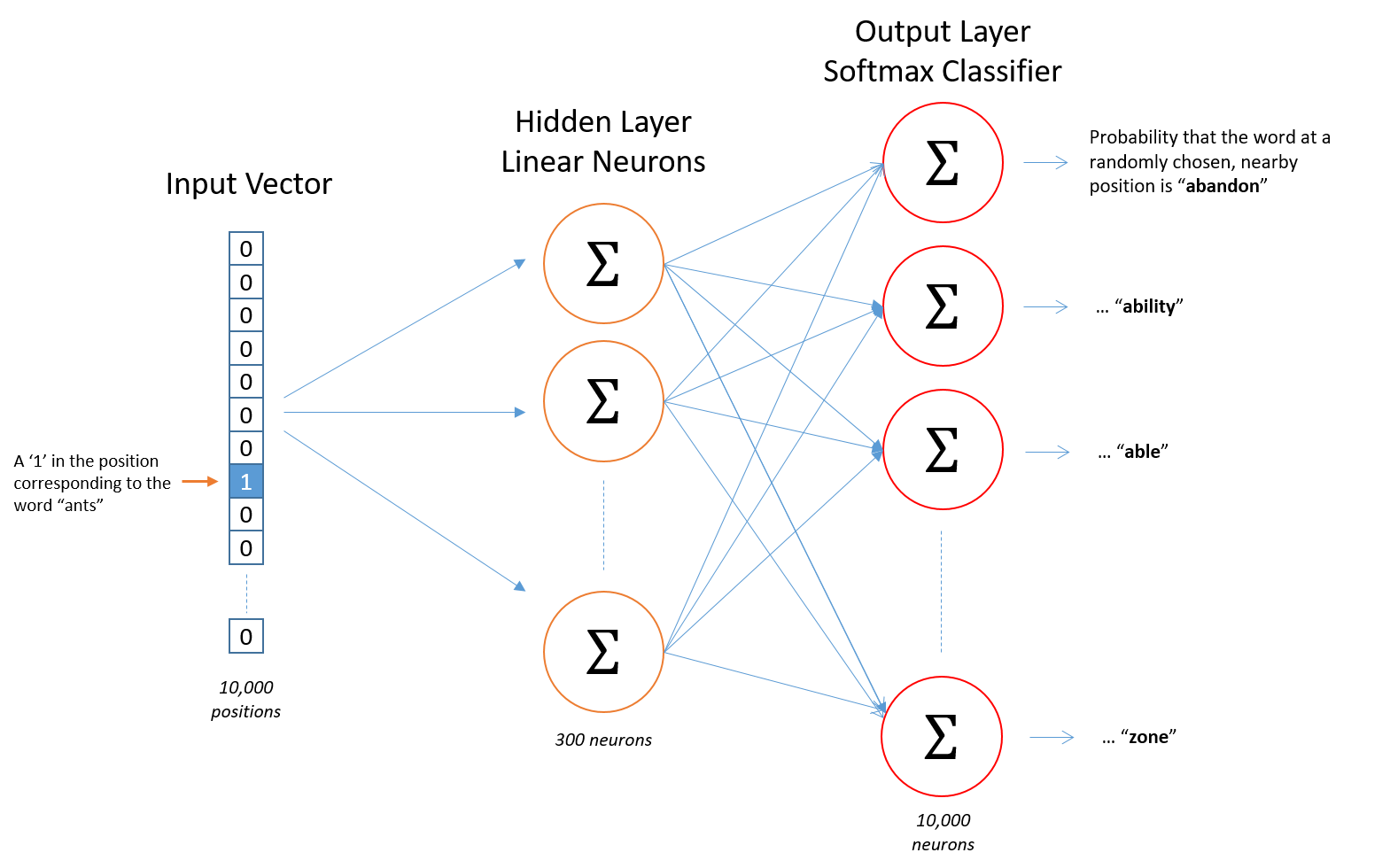
In the above digram, we can see…
- The input layer has 10,000 dimensions representing 10,000 words in this model’s vocabulary
- The hidden layer of the model has 300 neurons. Note that this number also corresponds to the dimensionality of the word vectors extracted from the model.
- The output layer has one neuron for each possible word in the model’s vocabulary
The word vectors, themselves, are stored in the weights connecting the input layer to the hidden layer of neurons. Each word will have its own set of learned weights which we call word vectors. You can think of each element of the word vectors as encoding different features which are relevant to the prediction task at hand — predicting context words.
Continuous Bag-of-Words (CBOW)
Before wrapping up with the mechanisms underlying the Word2Vec model, it is important to mention that the Skip-gram algorithm is not the only way to train word embeddings using Word2Vec. A similar method known as the Continuous Bag-of-Words (CBOW) takes as an input the context words surrounding a target word, and tries to guess the target word based on those words. Thus, it flips the prediction task faced by Skip-gram. The CBOW algorithm does not care how far away different context words are from the target word, which is why it is called a bag-of-words method. With this task setup, the neural network will learn a function that can map the surrounding context words to a target word. Similar to Skip-gram, the CBOW method will generate word vectors stored as weights of the neural network. However, given the slight adjustment in task, the weights extracted from CBOW are the ones that connect the hidden layer of neurons to the output layer.
CBOW vs Skip-gram
Since there are two popular word2vec training methods, how should we decide which one to pick? Like with many things in machine learning, the best course of action is typically to take a data-driven approach to see which one works better for your specific application. However, as general guidelines according to Mikolov et al.,
- Skip-Gram works well with smaller datasets and has been found to perform better in terms of its ability to represent rarer words
- CBOW trains several times faster than Skip-gram and has slightly better accuracy for more frequent words
Recap
Artificial neural networks are powerful machine learning models that can learn to map input data containing features to a predicted label or continuous value. In addition, neural networks learn to encode the input data as hierarchical features of the text during training. The Word2Vec model exploits this capability, and trains the model on a word prediction task in order to generate features of words which are conducive to the prediction task at hand.
In the next episode, we’ll train a Word2Vec model using both training methods and empirically evaluate the performance of each. We’ll also see how training Word2Vec models from scratch (rather than using a pretrained model) can be beneficial in some circumstances.
Key Points
Artificial neural networks (ANNs) are powerful models that can approximate any function given sufficient training data.
The best method to decide between training methods (CBOW and Skip-gram) is to try both methods and see which one works best for your specific application.
Training Word2Vec
Overview
Teaching: 45 min
Exercises: 20 minQuestions
How can we train a Word2Vec model?
When is it beneficial to train a Word2Vec model on a specific dataset?
Objectives
Understand the benefits of training a Word2Vec model on your own data rather than using a pre-trained model
Colab Setup
Run this code to enable helper functions and read data back in.
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
# Show existing colab notebooks and helpers.py file
from os import listdir
wksp_dir = '/content/drive/My Drive/Colab Notebooks/text-analysis/code'
print(listdir(wksp_dir))
# Add folder to colab's path so we can import the helper functions
import sys
sys.path.insert(0, wksp_dir)
Mounted at /content/drive
['analysis.py',
'pyldavis.py',
'.gitkeep',
'helpers.py',
'preprocessing.py',
'attentionviz.py',
'mit_restaurants.py',
'plotfrequency.py',
'__pycache__']
# pip install necessary to access parse module (called from helpers.py)
!pip install parse
Load in the data
# Read the data back in.
from pandas import read_csv
data = read_csv("/content/drive/My Drive/Colab Notebooks/text-analysis/data/data.csv")
Create list of files we’ll use for our analysis. We’ll start by fitting a word2vec model to just one of the books in our list — Moby Dick.
single_file = data.loc[data['Title'] == 'moby_dick','File'].item()
single_file
'/content/drive/My Drive/Colab Notebooks/text-analysis/data/melville-moby_dick.txt'
Let’s preview the file contents to make sure our code and directory setup is working correctly.
# open and read file
f = open(single_file,'r')
file_contents = f.read()
f.close()
# preview file contents
preview_len = 500
print(file_contents[0:preview_len])
[Moby Dick by Herman Melville 1851]
ETYMOLOGY.
(Supplied by a Late Consumptive Usher to a Grammar School)
The pale Usher--threadbare in coat, heart, body, and brain; I see him
now. He was ever dusting his old lexicons and grammars, with a queer
handkerchief, mockingly embellished with all the gay flags of all the
known nations of the world. He loved to dust his old grammars; it
somehow mildly reminded him of his mortality.
"While you take in hand to school others, and to teach them by wha
file_contents[0:preview_len] # Note that \n are still present in actual string (print() processes these as new lines)
'[Moby Dick by Herman Melville 1851]\n\n\nETYMOLOGY.\n\n(Supplied by a Late Consumptive Usher to a Grammar School)\n\nThe pale Usher--threadbare in coat, heart, body, and brain; I see him\nnow. He was ever dusting his old lexicons and grammars, with a queer\nhandkerchief, mockingly embellished with all the gay flags of all the\nknown nations of the world. He loved to dust his old grammars; it\nsomehow mildly reminded him of his mortality.\n\n"While you take in hand to school others, and to teach them by wha'
Preprocessing steps
- Split text into sentences
- Tokenize the text
- Lemmatize and lowercase all tokens
- Remove stop words
1. Convert text to list of sentences
Remember that we are using the sequence of words in a sentence to learn meaningful word embeddings. The last word of one sentence does not always relate to the first word of the next sentence. For this reason, we will split the text into individual sentences before going further.
Punkt Sentence Tokenizer
NLTK’s sentence tokenizer (‘punkt’) works well in most cases, but it may not correctly detect sentences when there is a complex paragraph that contains many punctuation marks, exclamation marks, abbreviations, or repetitive symbols. It is not possible to define a standard way to overcome these issues. If you want to ensure every “sentence” you use to train the Word2Vec is truly a sentence, you would need to write some additional (and highly data-dependent) code that uses regex and string manipulation to overcome rare errors.
For our purposes, we’re willing to overlook a few sentence tokenization errors. If this work were being published, it would be worthwhile to double-check the work of punkt.
import nltk
nltk.download('punkt') # dependency of sent_tokenize function
sentences = nltk.sent_tokenize(file_contents)
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
sentences[300:305]
['How then is this?',
'Are the green fields gone?',
'What do they\nhere?',
'But look!',
'here come more crowds, pacing straight for the water, and\nseemingly bound for a dive.']
2-4: Tokenize, lemmatize, and remove stop words
Pull up preprocess text helper function and unpack the code…
- We’ll run this function on each sentence
- Lemmatization, tokenization, lowercase and stopwords are all review
- For the lemmatization step, we’ll use NLTK’s lemmatizer which runs very quickly
- We’ll also use NLTK’s stop word lists and its tokenization function. Recall that stop words are usually thought of as the most common words in a language. By removing them, we can let the Word2Vec model focus on sequences of meaningful words, only.
from helpers import preprocess_text
# test function
string = 'It is not down on any map; true places never are.'
tokens = preprocess_text(string,
remove_stopwords=True,
verbose=True)
print('Result', tokens)
Tokens ['It', 'is', 'not', 'down', 'on', 'any', 'map', 'true', 'places', 'never', 'are']
Lowercase ['it', 'is', 'not', 'down', 'on', 'any', 'map', 'true', 'places', 'never', 'are']
Lemmas ['it', 'is', 'not', 'down', 'on', 'any', 'map', 'true', 'place', 'never', 'are']
StopRemoved ['map', 'true', 'place', 'never']
Result ['map', 'true', 'place', 'never']
# convert list of sentences to pandas series so we can use the apply functionality
import pandas as pd
sentences_series = pd.Series(sentences)
tokens_cleaned = sentences_series.apply(preprocess_text,
remove_stopwords=True,
verbose=False)
# view sentences before clearning
sentences[300:305]
['How then is this?',
'Are the green fields gone?',
'What do they\nhere?',
'But look!',
'here come more crowds, pacing straight for the water, and\nseemingly bound for a dive.']
# view sentences after cleaning
tokens_cleaned[300:305]
300 []
301 [green, field, gone]
302 []
303 [look]
304 [come, crowd, pacing, straight, water, seeming...
dtype: object
tokens_cleaned.shape # 9852 sentences
(9852,)
# remove empty sentences and 1-word sentences (all stop words)
tokens_cleaned = tokens_cleaned[tokens_cleaned.apply(len) > 1]
tokens_cleaned.shape
(9007,)
Train Word2Vec model using tokenized text
We can now use this data to train a word2vec model. We’ll start by importing the Word2Vec module from gensim. We’ll then hand the Word2Vec function our list of tokenized sentences and set sg=0 (“skip-gram”) to use the continuous bag of words (CBOW) training method.
Set seed and workers for a fully deterministic run: Next we’ll set some parameters for reproducibility. We’ll set the seed so that our vectors get randomly initialized the same way each time this code is run. For a fully deterministically-reproducible run, we’ll also limit the model to a single worker thread (workers=1), to eliminate ordering jitter from OS thread scheduling — noted in gensim’s documentation
# import gensim's Word2Vec module
from gensim.models import Word2Vec
# train the word2vec model with our cleaned data
model = Word2Vec(sentences=tokens_cleaned, seed=0, workers=1, sg=0)
Gensim’s implementation is based on the original Tomas Mikolov’s original model of word2vec, which downsamples all frequent words automatically based on frequency. The downsampling saves time when training the model.
Next steps: word embedding use-cases
We now have a vector representation for all the (lemmatized and non-stop words) words referenced throughout Moby Dick. Let’s see how we can use these vectors to gain insights from our text data.
Most similar words
Just like with the pretrained word2vec models, we can use the most_similar function to find words that meaningfully relate to a queried word.
# default
model.wv.most_similar(positive=['whale'], topn=10)
[('great', 0.9986481070518494),
('white', 0.9984517097473145),
('fishery', 0.9984385371208191),
('sperm', 0.9984176158905029),
('among', 0.9983417987823486),
('right', 0.9983320832252502),
('three', 0.9983301758766174),
('day', 0.9983181357383728),
('length', 0.9983041882514954),
('seen', 0.998255729675293)]
Vocabulary limits
Note that Word2Vec can only produce vector representations for words encountered in the data used to train the model.
model.wv.most_similar(positive=['orca'],topn=30)
KeyError: "Key 'orca' not present in vocabulary"
fastText solves OOV issue
If you need to obtain word vectors for out of vocabulary (OOV) words, you can use the fastText word embedding model, instead (also provided from Gensim). The fastText model can obtain vectors even for out-of-vocabulary (OOV) words, by summing up vectors for its component char-ngrams, provided at least one of the char-ngrams was present in the training data.
Word2Vec for Named Entity Recognition
What can we do with this most similar functionality? One way we can use it is to construct a list of similar words to represent some sort of category. For example, maybe we want to know what other sea creatures are referenced throughout Moby Dick. We can use gensim’s most_smilar function to begin constructing a list of words that, on average, represent a “sea creature” category.
We’ll use the following procedure:
- Initialize a small list of words that represent the category, sea creatures.
- Calculate the average vector representation of this list of words
- Use this average vector to find the top N most similar vectors (words)
- Review similar words and update the sea creatures list
- Repeat steps 1-4 until no additional sea creatures can be found
# start with a small list of words that represent sea creatures
sea_creatures = ['whale','fish','creature','animal']
# The below code will calculate an average vector of the words in our list,
# and find the vectors/words that are most similar to this average vector
model.wv.most_similar(positive=sea_creatures, topn=30)
[('great', 0.9997826814651489),
('part', 0.9997532963752747),
('though', 0.9997507333755493),
('full', 0.999735951423645),
('small', 0.9997267127037048),
('among', 0.9997209906578064),
('case', 0.9997204542160034),
('like', 0.9997190833091736),
('many', 0.9997131824493408),
('fishery', 0.9997081756591797),
('present', 0.9997068643569946),
('body', 0.9997056722640991),
('almost', 0.9997050166130066),
('found', 0.9997038245201111),
('whole', 0.9997023940086365),
('water', 0.9996949434280396),
('even', 0.9996913075447083),
('time', 0.9996898174285889),
('two', 0.9996897578239441),
('air', 0.9996871948242188),
('length', 0.9996850490570068),
('vast', 0.9996834397315979),
('line', 0.9996828436851501),
('made', 0.9996813535690308),
('upon', 0.9996812343597412),
('large', 0.9996775984764099),
('known', 0.9996767640113831),
('harpooneer', 0.9996761679649353),
('sea', 0.9996750354766846),
('shark', 0.9996744990348816)]
# we can add shark to our list
model.wv.most_similar(positive=['whale','fish','creature','animal','shark'],topn=30)
[('great', 0.9997999668121338),
('though', 0.9997922778129578),
('part', 0.999788761138916),
('full', 0.999781608581543),
('small', 0.9997766017913818),
('like', 0.9997683763504028),
('among', 0.9997652769088745),
('many', 0.9997631311416626),
('case', 0.9997614622116089),
('even', 0.9997515678405762),
('body', 0.9997514486312866),
('almost', 0.9997509717941284),
('present', 0.9997479319572449),
('found', 0.999747633934021),
('water', 0.9997465014457703),
('made', 0.9997431635856628),
('air', 0.9997406601905823),
('whole', 0.9997400641441345),
('fishery', 0.9997299909591675),
('harpooneer', 0.9997295141220093),
('time', 0.9997290372848511),
('two', 0.9997289776802063),
('sea', 0.9997265934944153),
('strange', 0.9997244477272034),
('large', 0.999722421169281),
('place', 0.9997209906578064),
('dead', 0.9997198581695557),
('leviathan', 0.9997192025184631),
('sometimes', 0.9997178316116333),
('high', 0.9997177720069885)]
# add leviathan (sea serpent) to our list
model.wv.most_similar(positive=['whale','fish','creature','animal','shark','leviathan'],topn=30)
[('though', 0.9998274445533752),
('part', 0.9998168349266052),
('full', 0.9998133182525635),
('small', 0.9998107552528381),
('great', 0.9998067021369934),
('like', 0.9998064041137695),
('even', 0.9997999668121338),
('many', 0.9997966885566711),
('body', 0.9997950196266174),
('among', 0.999794602394104),
('found', 0.9997929334640503),
('case', 0.9997885823249817),
('almost', 0.9997871518135071),
('made', 0.9997868537902832),
('air', 0.999786376953125),
('water', 0.9997802972793579),
('whole', 0.9997780919075012),
('present', 0.9997757077217102),
('harpooneer', 0.999768853187561),
('place', 0.9997684955596924),
('much', 0.9997658729553223),
('time', 0.999765157699585),
('sea', 0.999765157699585),
('dead', 0.999764621257782),
('strange', 0.9997624158859253),
('high', 0.9997615218162537),
('two', 0.999760091304779),
('sometimes', 0.9997592568397522),
('half', 0.9997562170028687),
('vast', 0.9997541904449463)]
No additional sea creatures. It appears we have our list of sea creatures recovered using Word2Vec
Limitations
There is at least one sea creature missing from our list — a giant squid. The giant squid is only mentioned a handful of times throughout Moby Dick, and therefore it could be that our word2vec model was not able to train a good representation of the word “squid”. Neural networks only work well when you have lots of data
Exploring the skip-gram algorithm
The skip-gram algoritmm sometimes performs better in terms of its ability to capture meaning of rarer words encountered in the training data. Train a new Word2Vec model using the skip-gram algorithm, and see if you can repeat the above categorical search task to find the word, “squid”.
Solution
# import gensim's Word2Vec module from gensim.models import Word2Vec # train the word2vec model with our cleaned data model = Word2Vec(sentences=tokens_cleaned, seed=0, workers=1, sg=1) model.wv.most_similar(positive=['whale','fish','creature','animal','shark','leviathan'],topn=100) # still no sight of squid[('whalemen', 0.9931729435920715), ('specie', 0.9919217824935913), ('bulk', 0.9917919635772705), ('ground', 0.9913252592086792), ('skeleton', 0.9905602931976318), ('among', 0.9898401498794556), ('small', 0.9887762665748596), ('full', 0.9885162115097046), ('captured', 0.9883950352668762), ('found', 0.9883666634559631), ('sometimes', 0.9882548451423645), ('snow', 0.9880553483963013), ('magnitude', 0.9880378842353821), ('various', 0.9878063201904297), ('hump', 0.9876748919487), ('cuvier', 0.9875931739807129), ('fisherman', 0.9874721765518188), ('general', 0.9873012900352478), ('living', 0.9872495532035828), ('wholly', 0.9872384667396545), ('bone', 0.987160861492157), ('mouth', 0.9867696762084961), ('natural', 0.9867129921913147), ('monster', 0.9865870475769043), ('blubber', 0.9865683317184448), ('indeed', 0.9864518046379089), ('teeth', 0.9862186908721924), ('entire', 0.9861844182014465), ('latter', 0.9859246015548706), ('book', 0.9858523607254028)]Discuss Exercise Result: When using Word2Vec to reveal items from a category, you risk missing items that are rarely mentioned. This is true even when we use the Skip-gram training method, which has been found to have better performance on rarer words. For this reason, it’s sometimes better to save this task for larger text corpuses. In a later lesson, we will explore how large language models (LLMs) can yield better performance on Named Entity Recognition related tasks.
Entity Recognition Applications
How else might you exploit this kind of analysis in your research? Share your ideas with the group.
Solution
Example: Train a model on newspaper articles from the 19th century, and collect a list of foods (the topic chosen) referenced throughout the corpus. Do the same for 20th century newspaper articles and compare to see how popular foods have changed over time.
Comparing Vector Representations Across Authors
Recall that the Word2Vec model learns to encode a word’s meaning/representation based on that word’s most common surrounding context words. By training two separate Word2Vec models on, e.g., books collected from two different authors (one model for each author), we can compare how the different authors tend to use words differently. What are some research questions or words that we could investigate with this kind of approach?
Solution
As one possible approach, we could compare how authors tend to represent different genders. It could be that older (outdated!) books tend to produce word vectors for man and women that are further apart from one another than newer books due to historic gender norms.
Other word embedding models
While Word2Vec is a famous model that is still used throughout many NLP applications today, there are a few other word embedding models that you might also want to consider exploring. GloVe and fastText are among the two most popular choices to date.
# Preview other word embedding models available
print(list(api.info()['models'].keys()))
['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis']
Similarities
- All three algorithms generate vector representations of words in a high-dimensional space.
- They can be used to solve a wide range of natural language processing tasks.
- They are all open-source and widely used in the research community.
Differences
- Word2Vec focuses on generating embeddings by predicting the context of a word given its surrounding words in a sentence, while GloVe and fastText generate embeddings by predicting the probability of a word co-occurring with another word in a corpus.
- fastText also includes character n-grams, allowing it to generate embeddings for words not seen during training, making it particularly useful for handling out-of-vocabulary words.
- In general, fastText is considered to be the fastest to train among the three embedding techniques (GloVe, fastText, and Word2Vec). This is because fastText uses subword information, which reduces the vocabulary size and allows the model to handle out-of-vocabulary words. Additionally, fastText uses a hierarchical softmax for training, which is faster than the traditional softmax used by Word2Vec. Finally, fastText can be trained on multiple threads, further speeding up the training process.
Key Points
As an alternative to using a pre-trained model, training a Word2Vec model on a specific dataset allows you use Word2Vec for NER-related tasks.
Finetuning LLMs
Overview
Teaching: 60 min
Exercises: 60 minQuestions
How can I fine-tune preexisting LLMs for my own research?
How do I pick the right data format?
How do I create my own labels?
How do I put my data into a model for finetuning?
How do I evaluate success at my task?
Objectives
Examine CONLL2003 data.
Learn about Label Studio.
Learn about finetuning a BERT model.
Setup
If you are running this lesson on Google Colab, it is strongly recommended that you enable GPU acceleration. If you are running locally without CUDA, you should be able to run most of the commands, but training will take a long time and you will want to use the pretrained model when using it.
To enable GPU, click “Edit > Notebook settings” and select GPU. If enabled, this command will return a status window and not an error:
!nvidia-smi
Thu Mar 28 20:50:47 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 64C P8 11W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
These installation commands will take time to run. Begin them now.
!pip install transformers datasets evaluate seqeval
Finetuning LLMs
In 2017, a revolutionary breakthrough for NLP occurred. A new type of hidden layer for neural networks called Transfomers were invented. Transformers made processing huge amounts of data feasible for the first time.
Large Language Models, or LLMs, were the result. LLMs are the current state of the art when it comes to many tasks, and although LLMs can differ, they are mostly based on a similar architecture to one another. We will be looking at an influential LLM called BERT.
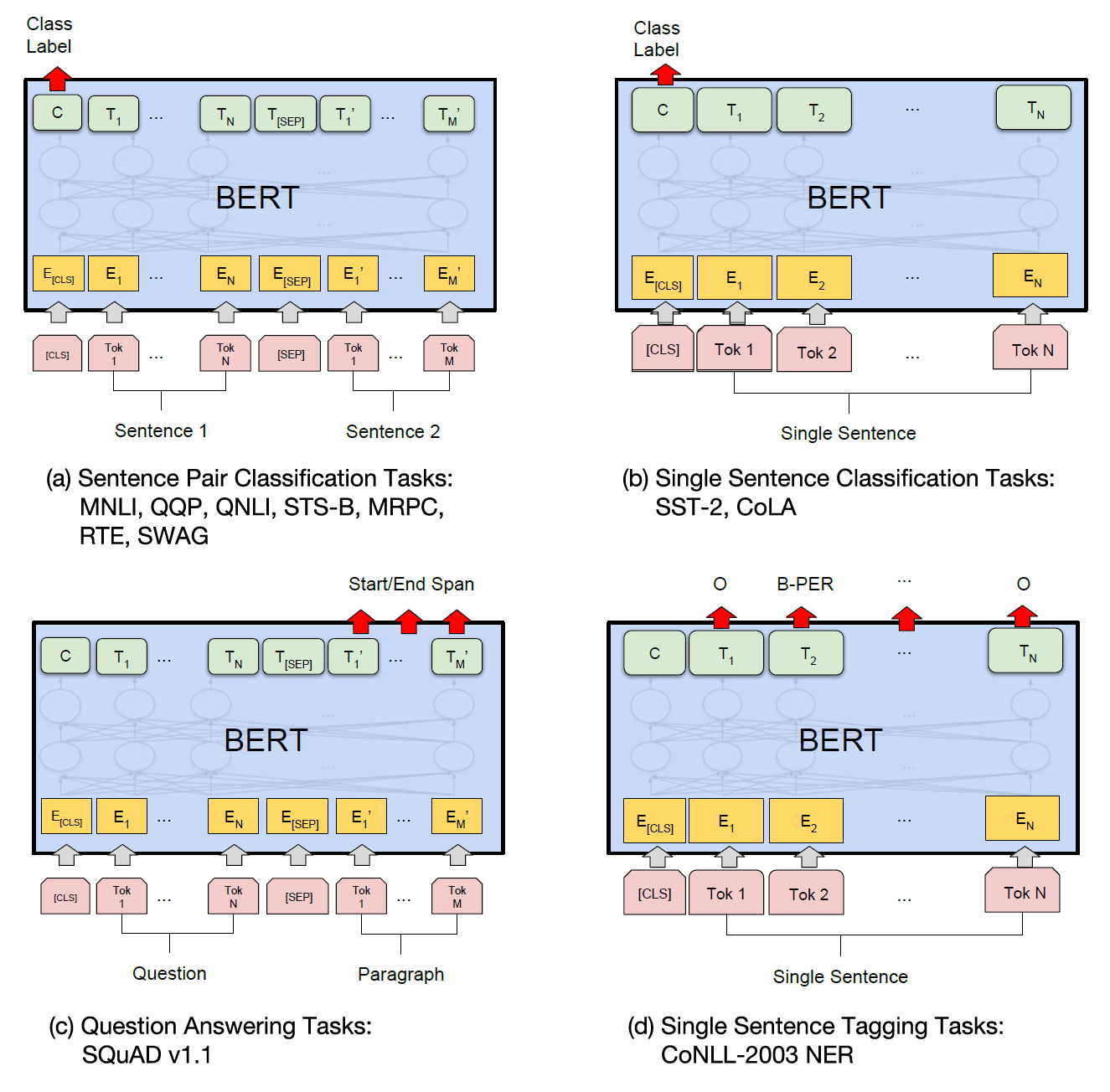
Training these models from scratch requires a huge amount of data and compute power. The majority of work is done for the many hidden layers of the model. However, by tweaking only the output layer, BERT can effectively perform many tasks with a minimal amount of data. This process of adapting an LLM is called fine-tuning.
Because of this, we will not be writing the code for this lesson from scratch. Rather, this lesson will focus on creating our own data, adapting existing code and modifying it to achieve the task we want to accomplish.
Using Existing Model- DistilBERT
We will be using a miniture LLM called DistilBERT for this lesson. We are using the “uncased” version of distilbert, which removes capitalization.
Much like many of our models, DistilBERT is available through HuggingFace. https://huggingface.co/docs/transformers/model_doc/distilbert
Let’s start by importing the library, and importing both the pretrained model and the tokenizer that BERT uses.
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Davlan/distilbert-base-multilingual-cased-ner-hrl")
model = AutoModelForTokenClassification.from_pretrained("Davlan/distilbert-base-multilingual-cased-ner-hrl")
#The aggregation strategy combines all of the tokens with a given label. Useful when our tokenizer uses subword tokens.
nlp = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy='simple')
Next, we’ll use the tokenizer to preprocess our example sentence.
example = "Nader Jokhadar had given Syria the lead with a well-struck header in the seventh minute."
ner_results = nlp(example)
for result in ner_results:
print(result)
{'entity_group': 'PER', 'score': 0.9993166, 'word': 'Nader Jokhadar', 'start': 0, 'end': 14}
{'entity_group': 'LOC', 'score': 0.99975127, 'word': 'Syria', 'start': 25, 'end': 30}
LLMs are highly performant at not just one, but a variety of tasks. And there are many versions of LLMs, designed to perform well on a variety of tasks available on HuggingFace.
We could use this existing model for research purposes as is. We might use an existing NER model to find examples of the most common locations in a set of fiction. You could categorize product reviews as positive or negative automatically using sentiment analysis. You could automatically translate documents from one language to another.
There are many possible tasks that LLMs can handle!
Why Fine Tune?
Given that there are many many prebuilt models for BERT, why would you want to go through the trouble of fine tuning your own?
LLM’s are very robust. They aren’t just capable of doing tasks other people have already trained them for. LLMs can also do specific and novel tasks you might want to accomplish as part of research!
Imagine using a LLM to classify a group of documents using training data you create. Or imagine an LLM pulling out specific types of words based on examples you provide. LLM’s can be trained to do these specific tasks fairly well, without needing terabytes of data to do so.
Let’s take a look on how we fine tune an LLM on a novel task by walking through an example.
The Interpretive Loop
To fine-tune, we will walk through all of the steps of our interpretive loop diagram. Let’s take a look at our diagram once more:
If no existing model does a given task, we can fine-tune a LLM to do it. How do we start? We’re going to create versions of all the items listed in our diagram.
We need the following:
- A task, so we can find a model and LLM pipeline to finetune.
- A dataset for our task, properly formatted in a way BERT can interpret.
- A tokenizer and helpers to preprocess our data in a way BERT expects.
- A model that has been pretrained on millions of documents for us. We will only fine-tune this model, not recreate it from scratch.
- A trainer to fine-tune our model to perform our task.
- A set of metrics so that we can evaluate how well our model performs.
The final product of all this work will be a fine-tuned model that classifies all the elements of reviews that we want. Let’s get started!
NLP task
The first thing we can do is identify our task. Suppose our research question is to look carefully at different elements of restaurant reviews. We want to classify different elements of restaurant reviews, such as amenities, locations, ratings, cuisine types and so on using an LLM.
Our task here is Token Classification, or more specifically, Named Entity Recognition. Classifying tokens will enable us to pull out categories that are of interest to us.
The standard set of Named Entity Recognition labels is designed to be broad: people, organizations and so on. However, it doesn’t have to be. We can define our own entities of interest and have our model search for them.
Now that we have an idea of what we’re aiming to do, lets look at some of the LLMs provided by HuggingFace that perform this activity. HuggingFace hosts many instructional Colab notebooks available at: https://huggingface.co/docs/transformers/notebooks.
We can find an example of Token Classification using PyTorch there. This document will be the basis for our code.
Examining Working Example
Looking at the notebook, we can get an idea of how it functions and adapt it for our own purposes.
- The existing model it uses is a compressed version of BERT, “distilbert.” While not as accurate as the full BERT model, it is smaller and easier to fine tune. We’ll use this model as well.
- The existing dataset for our task is something called “conll2003”. We will want to look at this and replace it with our own data, taking care to copy the formatting of existing data.
- The existing tokenizer requires a special helper method called an aligner. We will copy this directly.
- The existing model that we will tweak to accomplish our task.
- A trainer, which will largely use existing parameters. We will need to tweak our output labels for our new data.
- The existing metrics will be fine, but we have to feed them into our trainer.
Creating training data
It’s a good idea to pattern your data output based on what the model is expecting. You will need to make adjustments, but if you have selected a model that is appropriate to the task you can reuse most of the code already in place. We’ll start by installing our dependencies.
Now, let’s take a look at the example data from the dataset used in the example. The dataset used is called the CoNLL2003 dataset.
from datasets import load_dataset, load_metric
ds = load_dataset("conll2003", trust_remote_code=True)
print(ds)
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 14041
})
validation: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 3250
})
test: Dataset({
features: ['id', 'tokens', 'pos_tags', 'chunk_tags', 'ner_tags'],
num_rows: 3453
})
})
We can see that the CONLL dataset is split into three sets- training data, validation data, and test data. Training data should make up about 80% of your corpus and is fed into the model to fine tune it. Validation data should be about 10%, and is used to check how the training progress is going as the model is trained. The test data is about 10% withheld until the model is fully trained and ready for testing, so you can see how it handles new documents that the model has never seen before.
Let’s take a closer look at a record in the train set so we can get an idea of what our data should look like. The NER tags are the ones we are interested in, so lets print them out and take a look. We’ll also select the dataset and then an index for the document to look at an example.
traindoc = ds["train"][0]
conll_tags = ds["train"].features[f"ner_tags"].feature.names
print(traindoc['tokens'])
print(traindoc['ner_tags'])
print(conll_tags)
print()
for token, ner_tag in zip(traindoc['tokens'], traindoc['ner_tags']):
print(token+" "+conll_tags[ner_tag])
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
[3, 0, 7, 0, 0, 0, 7, 0, 0]
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
EU B-ORG
rejects O
German B-MISC
call O
to O
boycott O
British B-MISC
lamb O
. O
Each document has it’s own ID number. We can see that the tokens are a list of words in the document. For each word in the tokens, there are a series of numbers. Those numbers correspond to the labels in the database. Based on this, we can see that the EU is recognized as an ORG and the terms “German” and “British” are labelled as MISC.
These datasets are loaded using specially written loading scripts. We can look at this script by searching for the ‘conll2003’ in huggingface and selecting “Files”. The loading script is always named after the dataset. In this case it is “conll2003.py”.
https://huggingface.co/datasets/conll2003/blob/main/conll2003.py
Opening this file up, we can see that a zip file is downloaded and text files are extracted. We can manually download this ourselves if we would really like to take a closer look. For the sake of convienence, the example we looked just looked at is reproduced below:
"""
-DOCSTART- -X- -X- O
EU NNP B-NP B-ORG
rejects VBZ B-VP O
German JJ B-NP B-MISC
call NN I-NP O
to TO B-VP O
boycott VB I-VP O
British JJ B-NP B-MISC
lamb NN I-NP O
. . O O
"""
'\n-DOCSTART- -X- -X- O\n\nEU NNP B-NP B-ORG\nrejects VBZ B-VP O\nGerman JJ B-NP B-MISC\ncall NN I-NP O\nto TO B-VP O\nboycott VB I-VP O\nBritish JJ B-NP B-MISC\nlamb NN I-NP O\n. . O O\n'
This is a simple format, similar to a CSV. Each document is seperated by a blank line. The token we look at is first, then space seperated tags for POS, chunk_tags and NER tags. Many of the token classifications use BIO tagging, which specifies that “B” is the beginning of a tag, “I” is inside a tag, and “O” means that the token outside of our tagging schema.
So, now that we have an idea of what the HuggingFace models expect, let’s start thinking about how we can create our own set of data and labels.
Tagging a dataset
Most of the human time spent training a model will be spent pre-processing and labelling data. If we expect our model to label data with an arbitrary set of labels, we need to give it some idea of what to look for. We want to make sure we have enough data for the model to perform at a good enough degree of accuracy for our purpose. Of course, this number will vary based on what level of performance is “good enough” and the difficulty of the task. While there’s no set number, a set of approximately 100,000 tokens is enough to train many NER tasks.
Fortunately, software exists to help streamline the tagging process. One open source example of tagging software is Label Studio. However, it’s not the only option, so feel free to select a data labelling software that matches your preferences or needs for a given project. An online demo of Label Studio is available here: https://labelstud.io/playground. It’s also possible to install locally.
Select “Named Entity Recognition” as the task to see what the interface would look like if we were doing our own tagging. We can define our own labels by copying in the following code (minus the quotations):
"""
<View>
<Labels name="label" toName="text">
<Label value="Amenity" background="red"/>
<Label value="Cuisine" background="darkorange"/>
<Label value="Dish" background="orange"/>
<Label value="Hours" background="green"/>
<Label value="Location" background="darkblue"/>
<Label value="Price" background="blue"/>
<Label value="Rating" background="purple"/>
<Label value="Restaurant_Name" background="#842"/>
</Labels>
<Text name="text" value="$text"/>
</View>
"""
'\n<View>\n <Labels name="label" toName="text">\n <Label value="Amenity" background="red"/>\n <Label value="Cuisine" background="darkorange"/>\n <Label value="Dish" background="orange"/>\n <Label value="Hours" background="green"/>\n <Label value="Location" background="darkblue"/>\n <Label value="Price" background="blue"/>\n <Label value="Rating" background="purple"/>\n <Label value="Restaurant_Name" background="#842"/>\n </Labels>\n\n <Text name="text" value="$text"/>\n</View>\n'
In Label Studio, labels can be applied by hitting a number on your keyboard and highlighting the relevant part of the document. Try doing so on our example text and looking at the output.
Once done, we will have to export our files for use in our model. Label Studio supports a number of different types of labelling tasks, so you may want to use it for tasks other than just NER.
One additional note: There is a github project for direct integration between label studio and HuggingFace available as well. Given that the task selected may vary on the model and you may not opt to use Label Studio for a given project, we will simply point to this project as a possible resource (https://github.com/heartexlabs/label-studio-transformers) rather than use it in this lesson.
Export to desired format
So, let’s say you’ve finished your tagging project. How do we get these labels out of label studio and into our model?
Label Studio supports export into many formats, including one called CoNLL2003. This is the format our test dataset is in. It’s a space seperated CSV, with words and their tags.
We’ll skip the export step as well, as we already have a prelabeled set of tags in a similar format published by MIT. For more details about supported export formats consult the help page for Label Studio here: https://labelstud.io/guide/export.html
At this point, we’ve got all the labelled data we want. We now need to load our dataset into HuggingFace and then train our model. The following code will be largely based on the example code from HuggingFace, substituting in our data for the CoNLL data.
Loading our custom dataset
Let’s import our carpentries files and helper methods first, as they contain our data and a loading script.
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
# pip install necessary to access parse module (called from helpers.py)
!pip install parse
Finally, lets make our own tweaks to the HuggingFace colab notebook. We’ll start by importing some key metrics.
import datasets
from datasets import load_dataset, Features
The HuggingFace example uses CONLL 2003 dataset.
All datasets from huggingface are loaded using scripts. Datasets can be defined from a JSON or csv file (see the Datasets documentation) but selecting CSV will by default create a new document for every token and NER tag and will not load the documents correctly. So we will use a tweaked version of the Conll loading script instead. Let’s take a look at the regular Conll script first:
https://huggingface.co/datasets/conll2003/tree/main
The loading script is the python file. Usually the loading script is named after the dataset in question. There are a couple of things we want to change-
- We want to tweak the metadata with citations to reflect where we got our data. If you created the data, you can add in your own citation here.
- We want to define our own categories for NER_TAGS, to reflect our new named entities.
- The order for our tokens and NER tags is flipped in our data files.
- Delimiters for our data files are tabs instead of spaces.
- We will replace the method names with ones appropriate for our dataset.
Those modifications have been made in our mit_restaurants.py file. Let’s briefly take a look at that file before we proceed with the huggingface script. Again, these are modifications, not working from scratch.
HuggingFace Code
Now that we have a modified huggingface script, let’s load our data.
ds = load_dataset("/content/drive/MyDrive/Colab Notebooks/text-analysis/code/mit_restaurants.py", trust_remote_code=True)
/usr/local/lib/python3.10/dist-packages/datasets/load.py:926: FutureWarning: The repository for mit_restaurants contains custom code which must be executed to correctly load the dataset. You can inspect the repository content at /content/drive/MyDrive/Colab Notebooks/text-analysis/code/mit_restaurants.py
You can avoid this message in future by passing the argument `trust_remote_code=True`.
Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.
warnings.warn(
How does our dataset compare to the CONLL dataset? Let’s look at a record and compare.
ds
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'ner_tags'],
num_rows: 7660
})
validation: Dataset({
features: ['id', 'tokens', 'ner_tags'],
num_rows: 815
})
test: Dataset({
features: ['id', 'tokens', 'ner_tags'],
num_rows: 706
})
})
label_list = ds["train"].features[f"ner_tags"].feature.names
label_list
['O',
'B-Amenity',
'I-Amenity',
'B-Cuisine',
'I-Cuisine',
'B-Dish',
'I-Dish',
'B-Hours',
'I-Hours',
'B-Location',
'I-Location',
'B-Price',
'I-Price',
'B-Rating',
'I-Rating',
'B-Restaurant_Name',
'I-Restaurant_Name']
Our data looks pretty similar to the CONLL data now. This is good since we can now reuse many of the methods listed by HuggingFace in their Colab notebook.
Preprocessing the data
We start by defining some variables that HuggingFace uses later on.
import torch
task = "ner" # Should be one of "ner", "pos" or "chunk"
model_checkpoint = "distilbert-base-uncased"
batch_size = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Next, we create our special BERT tokenizer.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
example = ds["train"][4]
tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
print(tokens)
['[CLS]', 'a', 'great', 'lunch', 'spot', 'but', 'open', 'till', '2', 'a', 'm', 'pass', '##im', '##s', 'kitchen', '[SEP]']
Since our words are broken into just words, and the BERT tokenizer sometimes breaks words into subwords, we need to retokenize our words. We also need to make sure that when we do this, the labels we created don’t get misaligned. More details on these methods are available through HuggingFace, but we will simply use their code to do this.
word_ids = tokenized_input.word_ids()
aligned_labels = [-100 if i is None else example[f"{task}_tags"][i] for i in word_ids]
label_all_tokens = True
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"{task}_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
label_ids.append(label[word_idx] if label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
tokenized_datasets = ds.map(tokenize_and_align_labels, batched=True)
print(tokenized_datasets)
Map: 0%| | 0/815 [00:00<?, ? examples/s]
DatasetDict({
train: Dataset({
features: ['id', 'tokens', 'ner_tags', 'input_ids', 'attention_mask', 'labels'],
num_rows: 7660
})
validation: Dataset({
features: ['id', 'tokens', 'ner_tags', 'input_ids', 'attention_mask', 'labels'],
num_rows: 815
})
test: Dataset({
features: ['id', 'tokens', 'ner_tags', 'input_ids', 'attention_mask', 'labels'],
num_rows: 706
})
})
The preprocessed features we’ve just added will be the ones used to actually train the model.
Fine-tuning the model
Now that our data is ready, we can download the pretrained LLM model. Since our task is token classification, we use the AutoModelForTokenClassification class. Before we do though, we want to specify the mapping for ids and labels to our model so it does not simply return CLASS_1, CLASS_2 and so on.
id2label = {
0: "O",
1: "B-Amenity",
2: "I-Amenity",
3: "B-Cuisine",
4: "I-Cuisine",
5: "B-Dish",
6: "I-Dish",
7: "B-Hours",
8: "I-Hours",
9: "B-Location",
10: "I-Location",
11: "B-Price",
12: "I-Price",
13: "B-Rating",
14: "I-Rating",
15: "B-Restaurant_Name",
16: "I-Restaurant_Name",
}
label2id = {
"O": 0,
"B-Amenity": 1,
"I-Amenity": 2,
"B-Cuisine": 3,
"I-Cuisine": 4,
"B-Dish": 5,
"I-Dish": 6,
"B-Hours": 7,
"I-Hours": 8,
"B-Location": 9,
"I-Location": 10,
"B-Price": 11,
"I-Price": 12,
"B-Rating": 13,
"I-Rating": 14,
"B-Restaurant_Name": 15,
"I-Restaurant_Name": 16,
}
from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, id2label=id2label, label2id=label2id, num_labels=len(label_list)).to(device)
Some weights of DistilBertForTokenClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The warning is telling us we are throwing away some weights. We’re training our model, so we should be fine.
##Configuration Arguments
Next, we configure our trainer. The are lots of settings here but the defaults are fine. More detailed documentation on what each of these mean are available through Huggingface: TrainingArguments,
model_name = model_checkpoint.split("/")[-1]
args = TrainingArguments(
#f"{model_name}-finetuned-{task}",
f"{model_name}-carpentries-restaurant-ner",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
report_to="none",
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=False, #You can have your model automatically pushed to HF if you uncomment this and log in.
)
Collator
One finicky aspect of the model is that all of the inputs have to be the same size. When the sizes do not match, something called a data collator is used to batch our processed examples together and pad them to the same size.
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer)
Metrics
The last thing we want to define is the metric by which we evaluate how our model did. We will use seqeval. The metric used will vary based on the task- make sure to check the huggingface notebooks for the appropriate metric for a given task.
import evaluate
seqeval = evaluate.load("seqeval")
Post Processing
Per HuggingFace- we need to do a bit of post-processing on our predictions. The following function and description is taken directly from HuggingFace. The function does the following:
- Selected the predicted index (with the maximum logit) for each token
- Converts it to its string label
- Ignore everywhere we set a label of -100
import numpy as np
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
Finally, after all of the preparation we’ve done, we’re ready to create a Trainer to train our model.
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py:432: FutureWarning: Passing the following arguments to `Accelerator` is deprecated and will be removed in version 1.0 of Accelerate: dict_keys(['dispatch_batches', 'split_batches', 'even_batches', 'use_seedable_sampler']). Please pass an `accelerate.DataLoaderConfiguration` instead:
dataloader_config = DataLoaderConfiguration(dispatch_batches=None, split_batches=False, even_batches=True, use_seedable_sampler=True)
warnings.warn(
We can now finetune our model by just calling the train method. Note that this step will take about 5 minutes if you are running it on a GPU, and 4+ hours if you are not.
print("Training starts NOW")
trainer.train()
Training starts NOW
<div>
<progress value='1437' max='1437' style='width:300px; height:20px; vertical-align: middle;'></progress>
[1437/1437 01:46, Epoch 3/3]
</div>
<table border="1" class="dataframe">
</table><p>
TrainOutput(global_step=1437, training_loss=0.39008279799087725, metrics={'train_runtime': 109.3751, 'train_samples_per_second': 210.103, 'train_steps_per_second': 13.138, 'total_flos': 117213322331568.0, 'train_loss': 0.39008279799087725, 'epoch': 3.0})
We’ve done it! We’ve fine-tuned the model for our task. Now that it’s trained, we want to save our work so that we can reuse the model whenever we wish. A saved version of this model has also been published through huggingface, so if you are using a CPU, skip the remaining evaluation steps and launch a new terminal so you can participate in the
trainer.save_model("/content/drive/MyDrive/Colab Notebooks/text-analysis/ft-model")
Evaluation Metrics for NER
We have some NER evaluation metrics, so let’s discuss what they mean. Accuracy is the most obvious metric for NER. Accuracy is the number of correctly labelled entities divided by the number of total entities. The problem with this metric can be illustrated by supposing we want a model to identify a needle in a haystack. A model that identifies everything as hay would be highly accurate, as most of the entities in a haystack ARE hay, but it wouldn’t allow us to find the rare needles we’re looking for. Similarly, our named entities will likely not make up most of our documents, so accuracy is not a good metric.
We can classify recommendations made by a model into four categories- true positive, true negative, false positive and false negative.
| Document is in our category | Document is not in our category | |
|---|---|---|
| Model predicts it is in our category | True Positive (TP) | False Positive (FP) |
| Model predicts it is not in category | False Negative (FN) | True Negative (TN) |
Precision is TP / TP + FP. It measures how correct your model’s labels were among the set of entities the model predicted were part of the class. This measure could be gamed, however, by being very conservative about making positive labels and only doing so when the model was absolutely certain, possibly missing relevant entities.
Recall is TP / TP + FN. It measures how correct your model’s labels are among the set of every entity actually belonging to the class. Recall could be trivally gamed by simply classify all documents as being part of the class.
The F1 score is a harmonic mean between the two, ensuring the model is neither too conservative or too prone to overclassification.
Now let’s see how our model did. We’ll run a more detailed evaluation step from HuggingFace if desired, to see how well our model performed. It is likely a good idea to have these metrics so that you can compare your performance to more generic models for the task.
from evaluate import evaluator
task_evaluator = evaluator("ner")
data= load_dataset("/content/drive/MyDrive/Colab Notebooks/text-analysis/code/mit_restaurants.py", split="test", trust_remote_code=True)
eval_results = task_evaluator.compute(
model_or_pipeline="/content/drive/MyDrive/Colab Notebooks/text-analysis/ft-model",
data=data,
)
for r in eval_results:
print(r, eval_results[r])
Amenity {'precision': 0.6354515050167224, 'recall': 0.7011070110701108, 'f1': 0.6666666666666667, 'number': 271}
Cuisine {'precision': 0.8378378378378378, 'recall': 0.8641114982578397, 'f1': 0.8507718696397942, 'number': 287}
Dish {'precision': 0.6935483870967742, 'recall': 0.6991869918699187, 'f1': 0.6963562753036437, 'number': 123}
Hours {'precision': 0.5675675675675675, 'recall': 0.7078651685393258, 'f1': 0.6299999999999999, 'number': 89}
Location {'precision': 0.8277777777777777, 'recall': 0.8713450292397661, 'f1': 0.849002849002849, 'number': 342}
Price {'precision': 0.7875, 'recall': 0.863013698630137, 'f1': 0.8235294117647058, 'number': 73}
Rating {'precision': 0.7311827956989247, 'recall': 0.8395061728395061, 'f1': 0.7816091954022988, 'number': 81}
Restaurant_Name {'precision': 0.8323699421965318, 'recall': 0.8323699421965318, 'f1': 0.8323699421965318, 'number': 173}
overall_precision 0.7552083333333334
overall_recall 0.8061153578874218
overall_f1 0.7798319327731092
overall_accuracy 0.9171441163508154
total_time_in_seconds 4.749443094000526
samples_per_second 148.64900705765186
latency_in_seconds 0.006727256507082897
Whether a F1 score of .779 is ‘good enough’ depends on the performance of other models, how difficult the task is, and so on. It may be good enough for our needs, or we may want to collect more data, train on a bigger model, or adjust our parameters. For the purposes of the workshop, we will say that this is fine.
Using our Model
Now that we’ve created our model, we can run it just like we did the pretrained models. The code below should do just that. Feel free to compose your own example and see how well the model performs!
from transformers import pipeline
from transformers import AutoModelForTokenClassification
from transformers import AutoTokenizer
from transformers import TokenClassificationPipeline
import torch
#Colab code
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
model = AutoModelForTokenClassification.from_pretrained("/content/drive/MyDrive/Colab Notebooks/text-analysis/ft-model")
nlp = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="first")
#This code imports this model, which I've uploaded to HuggingFace.
#tokenizer = AutoTokenizer.from_pretrained("karlholten/distilbert-carpentries-restaurant-ner")
#model = AutoModelForTokenClassification.from_pretrained("karlholten/distilbert-carpentries-restaurant-ner")
EXAMPLE = "where is a four star restaurant in milwaukee with tapas"
ner_results = nlp(EXAMPLE)
for entity in ner_results:
print(entity)
{'entity_group': 'Rating', 'score': 0.96475923, 'word': 'four star', 'start': 11, 'end': 20}
{'entity_group': 'Location', 'score': 0.9412049, 'word': 'milwaukee', 'start': 35, 'end': 44}
{'entity_group': 'Dish', 'score': 0.87943256, 'word': 'tapas', 'start': 50, 'end': 55}
Outro
That’s it! Let’s review briefly what we have done. We’ve discussed how to select a task. We used a HuggingFace example to help decide on a data format, and looked over it to get an idea of what the model expects. We went over Label Studio, one way to label your own data. We retokenized our example data and fine-tuned a model. Then we went over the results of our model.
LLM’s are the state-of-the-art for many types of task, and now you have an idea of how to use and even fine tune them in your own research. Our next lesson will discuss the ethics and implications of text analysis.
Key Points
HuggingFace has many examples of LLMs you can fine-tune.
Examine preexisting examples to get an idea of what your model expects.
Label Studio and other tagging software allows you to easily tag your own data.
Looking at common metrics used and other models performance in your subject area will give you an idea of how your model did.
Ethics and Text Analysis
Overview
Teaching: 20 min
Exercises: 20 minQuestions
Is text analysis artificial intelligence?
How can training data influence results?
What are the risk zones to consider when using text analysis for research?
Objectives
Understand how text analysis fits into the larger picture of artificial intelligence
Be able to consider the tool against your research objectives
Consider the drawbacks and inherent biases that may be present in large language models
Is text analysis artificial intelligence?
Artificial intelligence is loosely defined as the ability for computer systems to perform tasks that have traditionally required human reasoning and perception.
- To the extent that text analysis performs a task that resembles reading, understanding, and analyzing meaning, it can be understood to be part of the definition of artificial intelligence.
- The methods in this lesson all demonstrate models that learn from data - specifically, from text corpora that are not structured to explicitly tell the machine anything other than, perhaps, title, author, date, and body of text.
-
As a method and a tool, it is important to understand the tasks to which it is best suited, and to understand the process well enough to be able to interpret the results, including:
- whether the results are relevant or meaningful
- whether the results have been overly influenced by the model or training data
- how to responsibly use the results
We can describe these as commitments to ethical research methods.
Relevance or meaningfulness
As with any research, the relevance or meaningfulness of your results is relative to the research question itself. However, when you have a particular research question (or a particular set of research interests), it can be hard to connect the results of these models back to your bigger picture aims. It can feel like trying to write a book report but all you were given were the table of contents. One reason for this difficulty is that the dimensions of the model are atheoretical. That is, regardless of what research questions you are asking, the models always start from the same starting point: the words of the text, with no understanding of what those words mean to you. Our job is to interpret the meaning of the model’s results, or the qualitative work that follows.
The model is making a statistical determination based on the training data it has been fed, and on the training itself, as well as the methods you have used to parse the data set you’re analyzing. If you are using a tool like ChatGPT, you may have access only to your own methods, and will need to make an educated guess about the training data and training methods. That doesn’t mean you can’t use that tool, but it does mean you need to keep what is known and what is obscured about your methods at the forefront as you conduct your research.
Exercise: You use LSA as a method to identify important topics that are common across a set of popular 19th century English novels, and conclude that X is most common. How might you explain this result and why you used LSA?
Training data can influence results
There are numerous examples of how training data - or the language model, ultimately - can negatively influence results. Reproducing bias in the data is probably one of the most discussed negative outcomes. Let’s look at one real world example:
In 2016, ProPublica published an investigative report that exposed the clear bias against Black people in computer programs used to determine the likelihood of defendants committing crimes in the future. That bias was built into the tool because the training data that it relied on included historical data about crime statistics, which reflected - and then reproduced - existing racist bias in sentencing.
Exercise: How might a researcher avoid introducing bias into their methodology when using pre-trained data to conduct text analysis?
Using your research
Rarely will results from topic modeling, text analysis, etc. stand on their own as evidence of anything. Researchers should be able to explain their method and how they got their results, and be able to talk about the data sets and training models used. As discussed above, though, the nature of the large language models that may underlie the methods used to do LSA topic modeling, identify relationships between words using Word2Vec, or summarize themes using BERT, is that they contain vast numbers of parameters that cannot be reverse engineered or described. The tool can still be part of the explanation, and any results that may change due to the randommness of the LLM can be called out, for example.
Risk zones
Another area to consider when using any technology are the risk zones that are introduced. We’re talking about unintended consequences, for the most part, but consequences nonethless.
Let’s say you were using BERT to help summarize a large body of texts to understand broad themes and relationships. Could this same method be used to distort the contents of those texts to spread misinformation? How can we mitigate that risk?
In the case of the LLMs that underlie many of the text analysis methods you learned in this workshop, is there a chance that the results could reinforce existing biases because of existing biases in the training data? Consider this example:
Exercise: You are identifying topics across a large number of archival texts from hundreds of 20th century collections documenting LGBTQ organizations. You are using a LLM where the training data is petabytes of data collected over a decade of web crawling, starting in 2013. What risks are introduced by this method and how might they be anticipated and mitigated?
Hype cycles and AI
Because this workshop is being introduced shortly after the release of ChatGPT3 by OpenAI, we want to address how AI and tech hype cycles can influence tool selection and use of tech. The inscrutability of LLMs, the ability of chatbots to output coherent and meaningful text on a seemingly infinite variety of topics, and the rhetoric of the tech industry can make these tools seem magical and unfathomable. They aren’t magical, though the black box nature of the training data and the parameters does lend itself to unfathomability. Regardless, the output of any of the methods described in this workshop, and by LLMs to come, is the product of mathematical processes and statistical weights. That is why learning some of the methodology behind text analysis is important, even if it takes much longer to become fluent in LSA or Word2Vec. We all will use tools based on these methods in the years to come, whether for our research or for more mundane administrative tasks. Understanding something about how these tools work helps hold tech accountable, and enables better use of these tools for apprpriate tasks. Regrdless of the sophistication of the tool, it is humans who attribute meaning to the results and not the machine.
Key Points
Text analysis is a tool and can’t assign meaning to results
As researchers we are responsible for understanding and explaining our methods and results