Introduction to Natural Language Processing
Overview
Teaching: 15 minutes min
Exercises: 20 minutes minQuestions
What is Natural Language Processing?
What tasks can be done by Natural Language Processing?
What does a workflow for an NLP project look?
Objectives
Learn the tasks that NLP can do
Use a pretrained chatbot in python
Discuss our workflow for performing NLP tasks
Introduction
What is Natural Language Processing?
Text Analysis, also known as Natural Language Processing or NLP, is a subdiscipline of the larger disciplines of machine learning and artificial intelligence.
AI and machine learning both use complex mathematical constructs called models to take data as an input and produce a desired output.
What distinguishes NLP from other types of machine learning is that text and human language is the main input for NLP tasks.
Context for Digital Humanists
Before we get started, we would like to also provide a disclaimer. The humanities involves a wide variety of fields. Each of those fields brings a variety of research interests and methods to focus on a wide variety of questions.
AI is not infallible or without bias. NLP is simply another tool you can use to analyze texts and should be critically considered in the same way any other tool would be. The goal of this workshop is not to replace or discredit existing humanist methods, but to help humanists learn new tools to help them accomplish their research.
The Interpretive Loop
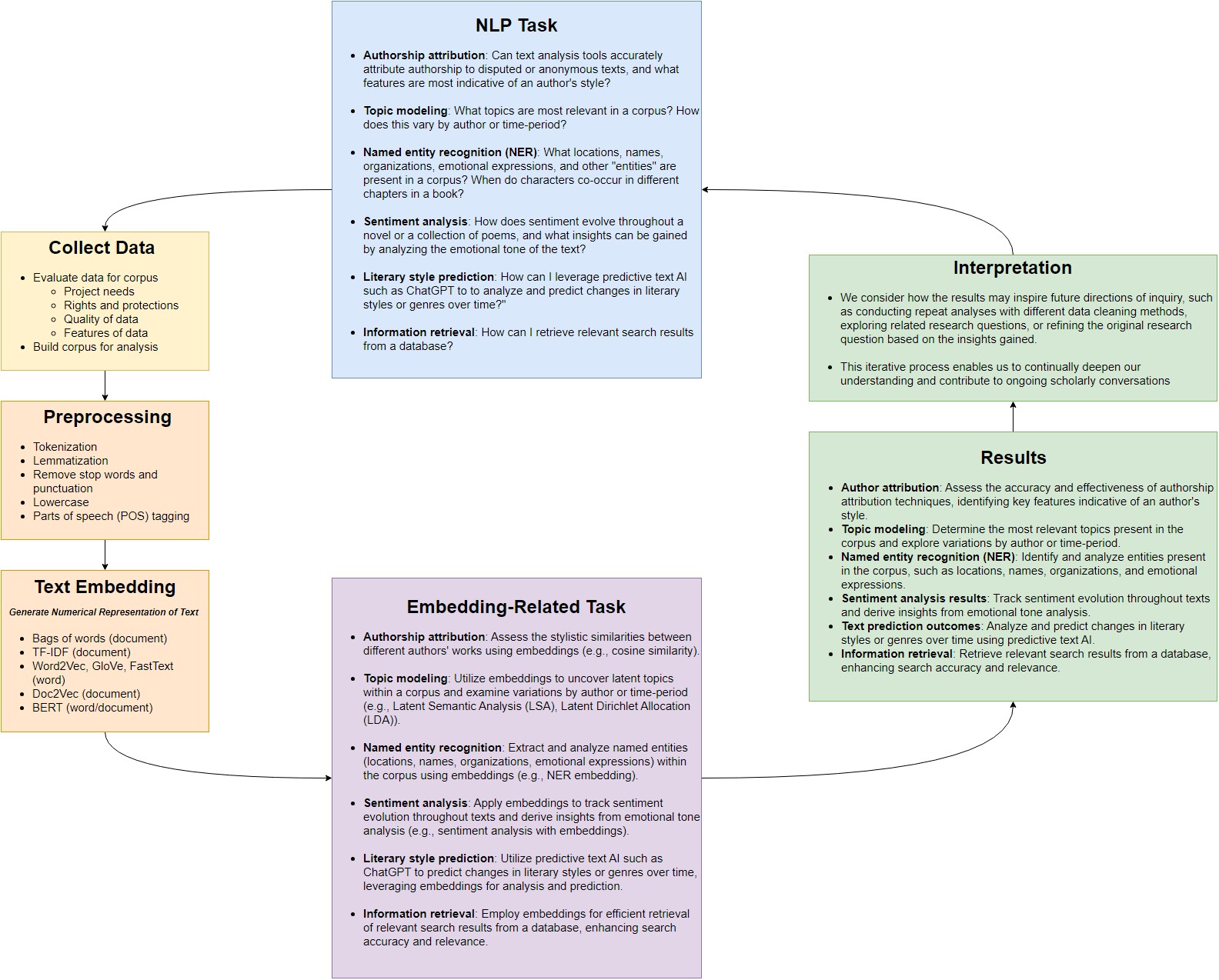
Despite the array of tasks encompassed within text analysis, many share common underlying processes and methodologies. Throughout our exploration, we’ll navigate an ‘interpretive loop’ that connects our research inquiries with the tools and techniques of natural language processing (NLP). This loop comprises several recurring stages:
- Formulating a research question or NLP task: Each journey begins with defining a task or problem within the domain of the digital humanities. This might involve authorship attribution, topic modeling, named entity recognition (NER), sentiment analysis, text prediction, or search, among others.
- Data collection and corpus building: With a clear objective in mind, the next step involves gathering relevant data and constructing a corpus (a set of documents). This corpus serves as the foundation for our analysis and model training. It may include texts, documents, articles, social media posts, or any other textual data pertinent to the research task.
- Data preprocessing: Before our data can be fed into NLP models, it undergoes preprocessing steps to clean, tokenize, and format the text. This ensures compatibility with our chosen model and facilitates efficient computation.
- Generating embeddings: Our processed data is then transformed into mathematical representations known as embeddings. These embeddings capture semantic and contextual information in the corpus, bridging the gap between human intuition and machine algorithms.
- Embedding-related tasks: Leveraging embeddings, we perform various tasks such as measuring similarity between documents, summarizing texts, or extracting key insights.
- Results: Results are generated from specific embedding-related tasks, such as measuring document similarity, document summarization, or topic modeling to uncover latent themes within a corpus.
- Interpreting results: Finally, we interpret the outputs in the context of our research objectives, stakeholder interests, and broader scholarly discourse. This critical analysis allows us to draw conclusions, identify patterns, and refine our approach as needed.
Additionally, we consider how the results may inspire future directions of inquiry, such as conducting repeat analyses with different data cleaning methods, exploring related research questions, or refining the original research question based on the insights gained. This iterative process enables us to continually deepen our understanding and contribute to ongoing scholarly conversations.
NLP Tasks
We’ll start by trying to understand what tasks NLP can do. Some of the many functions of NLP include topic modelling and categorization, named entity recognition, search, summarization and more.
We’re going to explore some of these tasks in this lesson using the popular “HuggingFace” library.
Launch a web browser and navigate to https://huggingface.co/tasks. Here we can see examples of many of the tasks achievable using NLP.
What do these different tasks mean? Let’s take a look at an example. A user engages in conversation with a bot. The bot generates a response based on the user’s prompt. This is called text generation. Let’s click on this task now: https://huggingface.co/tasks/text-generation
HuggingFace usefully provides an online demo as well as a description of the task. On the right, we can see there is a demo of a particular model that does this task. Give conversing with the chatbot a try.
If we scroll down, much more information is available. There is a link to sample models and datasets HuggingFace has made available that can do variations of this task. Documentation on how to use the model is available by scrolling down the page. Model specific information is available by clicking on the model.
Worked Example: Chatbot in Python
We’ve got an overview of what different tasks we can accomplish. Now let’s try getting started with doing these tasks in Python. We won’t worry too much about how this model works for the time being, but will instead just focusing trying it out. We’ll start by running a chatbot, just like the one we used online.
NLP tasks often need to be broken down into simpler subtasks to be executed in a particular order. These are called pipelines since the output from one subtask is used as the input to the next subtask. We will now define a “pipeline” in Python.
Launch either colab or our Anaconda environment, depending on your setup. Try following the example below.
from transformers import pipeline
from transformers.utils import logging
#disable warning about optional authentication
logging.set_verbosity_error()
text2text_generator = pipeline("text2text-generation")
print(text2text_generator("question: What is 42 ? context: 42 is the answer to life, the universe and everything"))
[{'generated_text': 'the answer to life, the universe and everything'}]
Feel free to prompt the chatbot with a few prompts of your own.
Group Activity and Discussion
With some experience with a task, let’s get a broader overview of the types of tasks we can do. Relaunch a web browser and go back to https://huggingface.co/tasks. Break out into groups and look at a couple of tasks for HuggingFace. The groups will be based on general categories for each task. Discuss possible applications of this type of model to your field of research. Try to brainstorm possible applications for now, don’t worry about technical implementation.
- Tasks that seek to convert non-text into text
- Searching and classifying documents as a whole
- Classifying individual words- Sequence based tasks
- Interactive and generative tasks such as conversation and question answering
Briefly present a summary of some of the tasks you explored. What types of applications could you see this type of task used in? How might this be relevant to a research question you have? Summarize these tasks and present your findings to the group.
What tasks can NLP do?
There are many models for representing language. The model we chose for our task will depend on what we want the output of our model to do. In other words, our model will vary based on the task we want it to accomplish.
We can think of the various tasks NLP can do as different types of desired outputs, which may require different models depending on the task.
Let’s discuss tasks you may find interesting in more detail. These are not the only tasks NLP can accomplish, but they are frequently of interest for Humanities scholars.
Search
Search attempts to retrieve documents that are similar to a query. In order to do this, there must be some way to compute the similarity between documents. A search query can be thought of as a small input document, and the outputs could be a score of relevant documents stored in the corpus. While we may not be building a search engine, we will find that similarity metrics such as those used in search are important to understanding NLP.
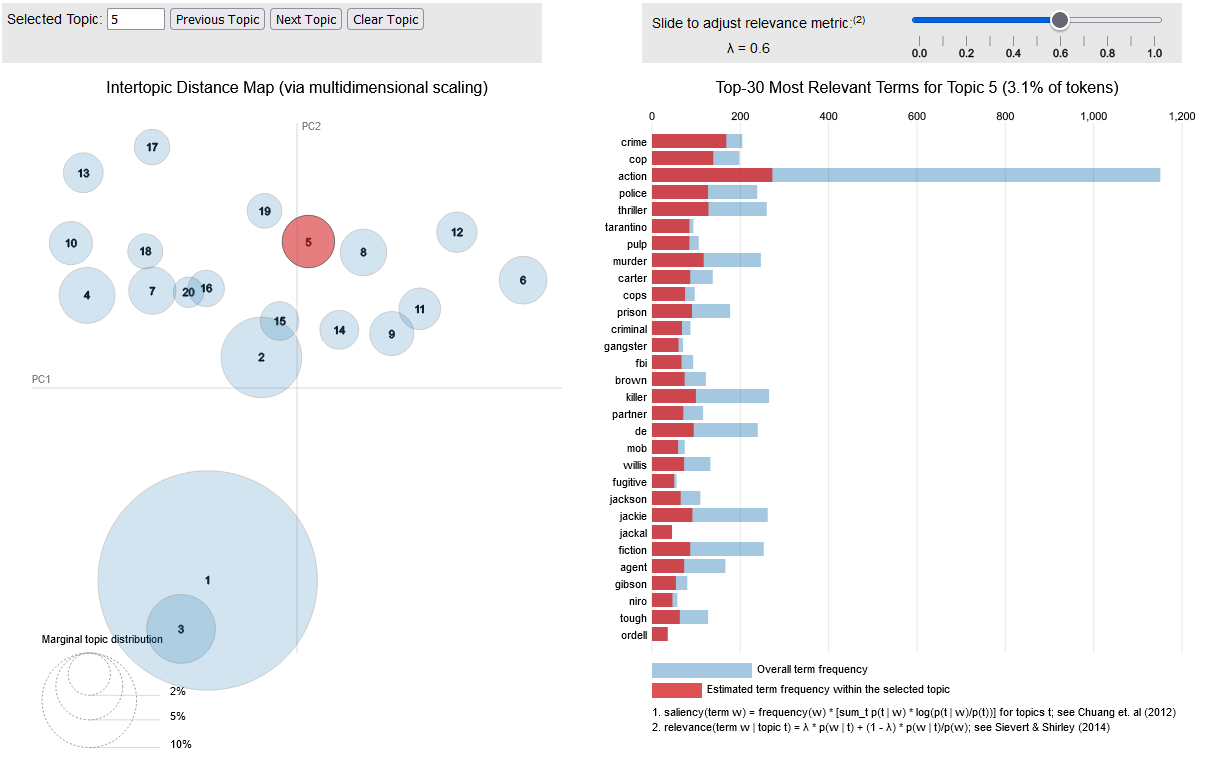
Topic Modeling
Topic modeling is a type of analysis that attempts to categorize documents into categories. These categories could be human generated labels, or we could ask our model to group together similar texts and create its own labels. For example, the Federalist Papers are a set of 85 essays written by three American Founding Fathers- Alexander Hamilton, James Madison and John Jay. These papers were written under pseudonyms, but many of the papers authors were later identified. One use for topic modelling might be to present a set of papers from each author that are known, and ask our model to label the federalist papers whose authorship is in dispute.
Alternatively, the computer might be asked to come up with a set number of topics, and create categories without precoded documents, in a process called unsupervised learning. Supervised learning requires human labelling and intervention, where unsupervised learning does not. Scholars may then look at the categories created by the NLP model and try to interpret them. One example of this is Mining the Dispatch, which tries to categorize articles based on unsupervised learning topics.
Token Classification
The task of token classification is trying to apply labels on a more granular level- labelling words as belonging to a certain group. The entities we are looking to recognize may be common. Parts of Speech (POS) Tagging looks to give labels to entities such as verbs, nouns, and so on. Named Entity Recognition (NER) seeks to label things such as places, names of individuals, or countries might not be easily enumerated. A possible application of this would be to track co-occurrence of characters in different chapters in a book.

Document Summarization
Document summarization takes documents which are longer, and attempts to output a document with the same meaning by finding relevant snippets or by generating a smaller document that conveys the meaning of the first document. Think of this as taking a large set of input data of words and outputting a smaller output of words that describe our original text.
Text Prediction
Text prediction attempts to predict future text inputs from a user based on previous text inputs. Predictive text is used in search engines and also on smartphones to help correct inputs and speed up the process of text input. It is also used in popular models such as ChatGPT.
Summary and Outro
We’ve looked at a general process or ‘interpretive loop’ for NLP. We’ve also seen a variety of different tasks you can accomplish with NLP. We used Python to generate text based on one of the models available through HuggingFace. Hopefully this gives some ideas about how you might use NLP in your area of research.
In the lessons that follow, we will be working on better understanding what is happening in these models. Before we can use a model though, we need to make sure we have data to build our model on. Our next lesson will be looking at one tool to build a dataset called APIs.
Key Points
NLP is comprised of models that perform different tasks.
Our workflow for an NLP project consists of designing, preprocessing, representation, running, creating output, and interpreting that output.
NLP tasks can be adapted to suit different research interests.