As we have seen, we have different programming paradigms that are suitable for different problems and affect the structure of our code. In programming languages that support multiple paradigms, such as Python, we have the luxury of using elements of different paradigms paradigms and we, as software designers and programmers, can decide how to use those elements in different architectural components of our software. Let’s now circle back to the architecture of our software for one final look.
MVC Revisited
We’ve been developing our software using the Model-View-Controller (MVC) architecture so far, but, as we have seen, MVC is just one of the common architectural patterns and is not the only choice we could have made.
Separation of Responsibilities
Separation of responsibilities is important when designing software architectures in order to reduce the code’s complexity and increase its maintainability. Note, however, there are limits to everything - and MVC architecture is no exception. Controller often transcends into Model and View and a clear separation is sometimes difficult to maintain. For example, the Command Line Interface provides both the View (what user sees and how they interact with the command line) and the Controller (invoking of a command) aspects of a CLI application. In Web applications, Controller often manipulates the data (received from the Model) before displaying it to the user or passing it from the user to the Model.
There are many variants of an MVC-like pattern (such as Model-View-Presenter (MVP), Model-View-Viewmodel (MVVM), etc.), but in most cases, the distinction between these patterns isn’t particularly important. What really matters is that we are making decisions about the architecture of our software that suit the way in which we expect to use it. We should reuse these established ideas where we can, but we don’t need to stick to them exactly.
The key thing to take away is the distinction between the Model and the View code, while
the View and the Controller can be more or less coupled together (e.g. the code that specifies
there is a button on the screen, might be the same code that specifies what that button does).
The View may be hard to test, or use special libraries to draw the UI, but should not contain any
complex logic, and is really just a presentation layer on top of the Model.
The Model, conversely, should not care how the data is displayed.
For example, the View may present dates as “Monday 24th July 2023”,
but the Model stores it using a Date object rather than its string representation.
Our Project’s Architecture (Revisited)
Recall that in our software project, the Controller module is in catchment-analysis.py,
and the View and Model modules are contained in
catchment/views.py and catchment/models.py, respectively.
Data underlying the Model is contained within the directory data.
Looking at the code in the branch full-data-analysis (where we should be currently located),
we can notice that the new code was added in a separate script catchment/compute_data.py and
contains a mix of Model, View and Controller code.
Exercise: Identify Model, View and Controller Parts of the Code
Looking at the code inside
compute_data.py, what parts could be considered Model, View and Controller code?Solution
- Computing the standard deviation belongs to Model.
- Reading the data from CSV files also belongs to Model.
- Displaying of the output as a graph is View.
- The logic that processes the supplied files is Controller.
Within the Model further separations make sense. For example, as we did in the before, separating out the impure code that interacts with the file system from the pure calculations helps with readability and testability. Nevertheless, the MVC architectural pattern is a great starting point when thinking about how you should structure your code.
Exercise: Split out the Model, View and Controller Code
Refactor
analyse_data()function so that the Model, View and Controller code we identified in the previous exercise is moved to appropriate modules.Solution
The idea here is for the
analyse_data()function not to have any “view” considerations. That is, it should just compute and return the data and should be located incatchment/models.py.def analyse_data(data_source): """Calculate the standard deviation by day between datasets Gets all the measurement data from the CSV files in the data directory, works out the mean for each day, and then graphs the standard deviation of these means. """ data = data_source.load_catchment_data() daily_standard_deviation = compute_standard_deviation_by_data(data) return daily_standard_deviationThere can be a separate bit of code in the Controller
catchment-analysis.pythat chooses how data should be presented, e.g. as a graph:if args.full_data_analysis: _, extension = os.path.splitext(InFiles[0]) if extension == '.json': data_source = JSONDataSource(os.path.dirname(InFiles[0])) elif extension == '.csv': data_source = CSVDataSource(os.path.dirname(InFiles[0])) else: raise ValueError(f'Unsupported file format: {extension}') data_result = analyse_data(data_source) graph_data = { 'daily standard deviation': data_result, } views.visualize(graph_data) returnNote that this is, more or less, the change we did to write our regression test. This demonstrates that splitting up Model code from View code can immediately make your code much more testable. Ensure you re-run our regression test to check this refactoring has not changed the output of
analyse_data().
At this point, you have refactored and tested all the code on branch full-data-analysis
and it is working as expected. The branch is ready to be incorporated into develop
and then, later on, main, which may also have been changed by other developers working on
the code at the same time so make sure to update accordingly or resolve any conflicts.
$ git switch develop
$ git merge full-data-analysis
Let’s now have a closer look at our Controller, and how can handling command line arguments in Python (which is something you may find yourself doing often if you need to run the code from a command line tool).
Controller file structure
You will have noticed already that structure of the catchment-analysis.py file
follows this pattern:
# import modules
def main():
# perform some actions
if __name__ == "__main__":
# perform some actions before main()
main()
In this pattern the actions performed by the script are contained within the main function
(which does not need to be called main,
but using this convention helps others in understanding your code).
The main function is then called within the if statement __name__ == "__main__",
after some other actions have been performed
(usually the parsing of command-line arguments, which will be explained below).
__name__ is a special dunder variable which is set,
along with a number of other special dunder variables,
by the python interpreter before the execution of any code in the source file.
What value is given by the interpreter to __name__ is determined by
the manner in which it is loaded.
If we run the source file directly using the Python interpreter, e.g.:
python catchment-analysis.py
then the interpreter will assign the hard-coded string "__main__" to the __name__ variable:
__name__ = "__main__"
...
# rest of your code
However, if your source file is imported by another Python script, e.g:
import catchment-analysis
then the interpreter will assign the name "catchment-analysis"
from the import statement to the __name__ variable:
__name__ = "catchment-analysis"
...
# rest of your code
Because of this behaviour of the interpreter,
we can put any code that should only be executed when running the script
directly within the if __name__ == "__main__": structure,
allowing the rest of the code within the script to be
safely imported by another script if we so wish.
While it may not seem very useful to have your controller script importable by another script, there are a number of situations in which you would want to do this:
- for testing of your code, you can have your testing framework import the main script,
and run special test functions which then call the
mainfunction directly; - where you want to not only be able to run your script from the command-line, but also provide a programmer-friendly application programming interface (API) for advanced users.
Passing Command-line Options to Controller
The standard python library for reading command line arguments passed to a script is
argparse.
This module reads arguments passed by the system,
and enables the automatic generation of help and usage messages.
These include, as we saw at the start of this course,
the generation of helpful error messages when users give the program invalid arguments.
The basic usage of argparse can be seen in the catchment-analysis.py script.
First we import the library:
import argparse
We then initialise the argument parser class, passing an (optional) description of the program:
parser = argparse.ArgumentParser(
description='A basic environmental data management system')
Once the parser has been initialised we can add the arguments that we want argparse to look out for. In our basic case, we want only the names of the file(s) to process:
parser.add_argument(
'infiles',
nargs='+',
help='Input CSV(s) containing measurement data')
Here we have defined what the argument will be called ('infiles') when it is read in;
the number of arguments to be expected
(nargs='+', where '+' indicates that there should be 1 or more arguments passed);
and a help string for the user
(help='Input CSV(s) containing measurement data').
You can add as many arguments as you wish,
and these can be either mandatory (as the one above) or optional.
Most of the complexity in using argparse is in adding the correct argument options,
and we will explain how to do this in more detail below.
Finally we parse the arguments passed to the script using:
args = parser.parse_args()
This returns an object (that we’ve called arg) containing all the arguments requested.
These can be accessed using the names that we have defined for each argument,
e.g. args.infiles would return the filenames that have been input.
The help for the script can be accessed using the -h or --help optional argument
(which argparse includes by default):
python catchment-analysis.py --help
usage: catchment-analysis.py [-h] infiles [infiles ...]
A basic environmental data management system
positional arguments:
infiles Input CSV(s) containing measurement data
optional arguments:
-h, --help show this help message and exit
The help page starts with the command line usage,
illustrating what inputs can be given (any within [] brackets are optional).
It then lists the positional and optional arguments,
giving as detailed a description of each as you have added to the add_argument() command.
Positional arguments are arguments that need to be included
in the proper position or order when calling the script.
Note that optional arguments are indicated by - or --, followed by the argument name.
Positional arguments are simply inferred by their position.
It is possible to have multiple positional arguments,
but usually this is only practical where all (or all but one) positional arguments
contains a clearly defined number of elements.
If more than one option can have an indeterminate number of entries,
then it is better to create them as ‘optional’ arguments.
These can be made a required input though,
by setting required = True within the add_argument() command.
Positional and Optional Argument Order
The usage section of the help page above shows the optional arguments going before the positional arguments. This is the customary way to present options, but is not mandatory. Instead there are two rules which must be followed for these arguments:
- Positional and optional arguments must each be given all together, and not inter-mixed. For example, the order can be either
optional - positionalorpositional - optional, but notoptional - positional - optional.- Positional arguments must be given in the order that they are shown in the usage section of the help page.
Now that you have some familiarity with argparse,
we will demonstrate below how you can use this to add extra functionality to your controller.
Choosing the Measurement Dataseries
Up until now we have only read the rainfall data from our data/rain_data_2015-12.csv file.
But what if we want to read the river measurement data too?
We can, simply, change the file that we are reading,
by passing a different file name.
But when we do this with the river data we get the following error:
python catchment-analysis.py data/river_data_2015-12.csv
Traceback (most recent call last):
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 39, in <module>
main(args)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 22, in main
measurement_data = models.read_variable_from_csv(filename)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment/models.py", line 22, in read_variable_from_csv
dataset = pd.read_csv(filename, usecols=['Date', 'Site', 'Rainfall (mm)'])
...
ValueError: Usecols do not match columns, columns expected but not found: ['Rainfall (mm)']
This error message tells us that the pandas read_csv function
has failed to find one of the columns that are listed to be read.
We would not expect a column called 'Rainfall (mm)' in the river data file,
so we need to make the read_variable_from_csv more flexible,
so that it can read any defined measurement dataset.
The first step is to add an argument to our command line interface,
so that users can specify the measurement dataset.
This can be done by adding the following argument to your catchment-analysis.py script:
parser.add_argument(
'-m', '--measurements',
help = 'Name of measurement data series to load',
required = True)
Here we have defined the name of the argument (--measurements),
as well as a short name (-m) for lazy users to use.
Note that the short name is preceded by a single dash (-),
while the full name is preceded by two dashes (--).
We provide a help string for the user,
and finally we set required = True,
so that the end user must define which data series they want to read.
Once this is added, then your help message should look like this:
python catchment-analysis.py --help
usage: catchment-analysis.py [-h] -m MEASUREMENTS infiles [infiles ...]
A basic environmental data management system
positional arguments:
infiles Input CSV(s) containing measurement data
optional arguments:
-h, --help show this help message and exit
-m MEASUREMENTS, --measurements MEASUREMENTS
Name of measurement data series to use
Optional vs Required Arguments, and Argument Groups
You will note that the
--measurementsargument is still listed as an optional argument. This is because the two basic option groups inargparseare positional and optional. In the usage section the--measurementsoption is listed without[]brackets, indicating that it is an expected argument, but still this is not very clear for end users.To make the help clearer we can add an extra argument group, and assign
--measurementsto this:... req_group = parser.add_argument_group('required arguments') ... req_group.add_argument( '-m', '--measurements', help = 'Name of measurement data series to load', required = True) ...This will return the following help message:
python catchment-analysis.py --helpusage: catchment-analysis.py [-h] -m MEASUREMENTS infiles [infiles ...] A basic environmental data management system positional arguments: infiles Input CSV(s) containing measurement data optional arguments: -h, --help show this help message and exit required arguments: -m MEASUREMENTS, --measurements MEASUREMENTS Name of measurement data series to useThis solution is not perfect, because the positional arguments are also required, but it will at least help end users distinguish between optional and required flagged arguments.
Default Argument Number and Type
argparsewill, by default, assume that each argument added will take a single value, and will be a string (type = str). If you want to change this for any argument you should explicitly settypeandnargs.Note also, that the returned object will be a single item unless
nargshas been set, in which case a list of items is returned (even ifnargs = 1is used).
Controller and Model Adaption
The new measurement string needs to be passed to the read_variable_from_csv function,
and applied appropriately within that function.
First we add a measurements argument to the read_variable_from_csv function in catchment/models.py
(remembering to update the function docstring at the same time):
# catchment/models.py
...
def read_variable_from_csv(filename, measurement):
"""Reads a named variable from a CSV file, and returns a
pandas dataframe containing that variable. The CSV file must contain
a column of dates, a column of site ID's, and (one or more) columns
of data - only one of which will be read.
:param filename: Filename of CSV to load
:param measurement: Name of data column to be read
:return: 2D array of given variable. Index will be dates,
Columns will be the individual sites
"""
...
Following this we need to change two lines of code, the first being the CSV reading code, and the second being the code which reorganises the dataset before it is returned:
# catchment/models.py
...
def read_variable_from_csv(filename, measurement):
...
dataset = pd.read_csv(filename, usecols=['Date', 'Site', measurement])
...
for site in dataset['Site'].unique():
newdataset[site] = dataset[dataset['Site'] == site].set_index('Date')[measurement]
...
Finally, within the main function of the controller we should add args.measurements as an argument:
# catchment-analysis.py
...
def main(args):
...
for filename in in_files:
measurement_data = models.read_variable_from_csv(filename, args.measurements)
...
You can now test your new code, to ensure it works as expected:
python catchment-analysis.py -m 'Rainfall (mm)' data/rain_data_2015-12.csv
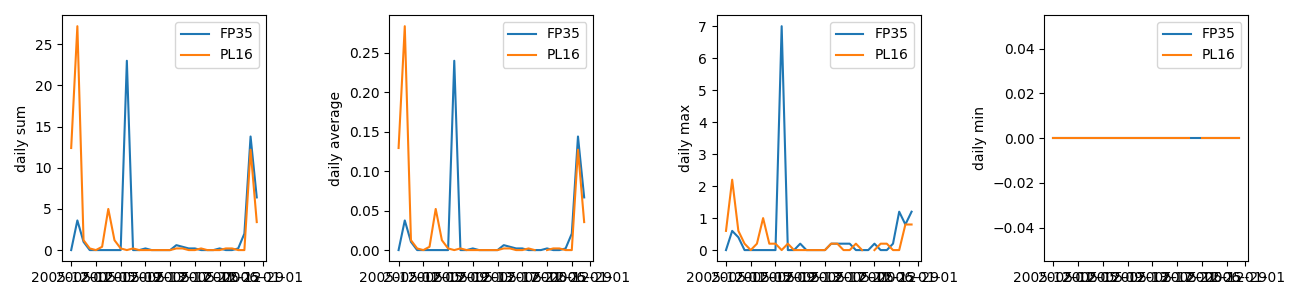
python catchment-analysis.py -m 'pH continuous' data/river_data_2015-12.csv
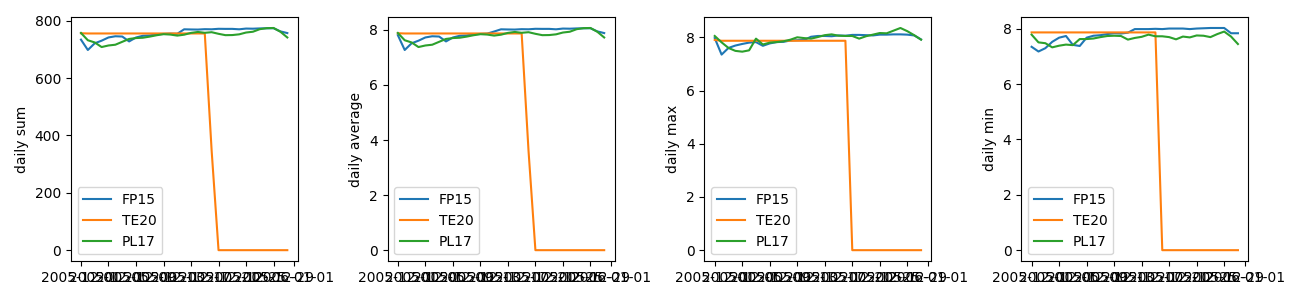
Note that we have to use quotation marks to pass any strings which contain spaces or special characters, so that they are properly read by the parser.
Additional Material
Now that we’ve covered the basics of different programming paradigms and how we can integrate them into our multi-layer architecture, there are two optional extra episodes which you may find interesting.
Both episodes cover the persistence layer of software architectures and methods of persistently storing data, but take different approaches. The episode on persistence with JSON covers some more advanced concepts in Object Oriented Programming, while the episode on databases starts to build towards a true multilayer architecture, which would allow our software to handle much larger quantities of data.
Towards Collaborative Software Development
Having looked at some theoretical aspects of software design, we are now circling back to implementing our software design and developing our software to satisfy the requirements collaboratively in a team. At an intermediate level of software development, there is a wealth of practices that could be used, and applying suitable design and coding practices is what separates an intermediate developer from someone who has just started coding. The key for an intermediate developer is to balance these concerns for each software project appropriately, and employ design and development practices enough so that progress can be made.
One practice that should always be considered, and has been shown to be very effective in team-based software development, is that of code review. Code reviews help to ensure the ‘good’ coding standards are achieved and maintained within a team by having multiple people have a look and comment on key code changes to see how they fit within the codebase. Such reviews check the correctness of the new code, test coverage, functionality changes, and confirm that they follow the coding guides and best practices. In the following episodes we will have a look at some code review techniques available to us.