Setting the Scene
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What are we teaching in this course?
What motivated the selection of topics covered in the course?
Objectives
Setting the scene and expectations
Making sure everyone has all the necessary software installed
Introduction
So, you have gained basic software development skills either by self-learning or attending, e.g., a novice Software Carpentry course. You have been applying those skills for a while by writing code to help with your work and you feel comfortable developing code and troubleshooting problems. However, your software has now reached a point where there’s too much code to be kept in one script. Perhaps it’s involving more researchers (developers) and users, and more collaborative development effort is needed to add new functionality while ensuring previous development efforts remain functional and maintainable.
This course provides the next step in software development - it teaches some intermediate software engineering skills and best practices to help you restructure existing code and design more robust, reusable and maintainable code, automate the process of testing and verifying software correctness and support collaborations with others in a way that mimics a typical software development process within a team.
The course uses a number of different software development tools and techniques interchangeably as you would in a real life. We had to make some choices about topics and tools to teach here, based on established best practices, ease of tool installation for the audience, length of the course and other considerations. Tools used here are not mandated though: alternatives exist and we point some of them out along the way. Over time, you will develop a preference for certain tools and programming languages based on your personal taste or based on what is commonly used by your group, collaborators or community. However, the topics covered should give you a solid foundation for working on software development in a team and producing high quality software that is easier to develop and sustain in the future by yourself and others. Skills and tools taught here, while Python-specific, are transferable to other similar tools and programming languages.
The course is organised into the following sections:
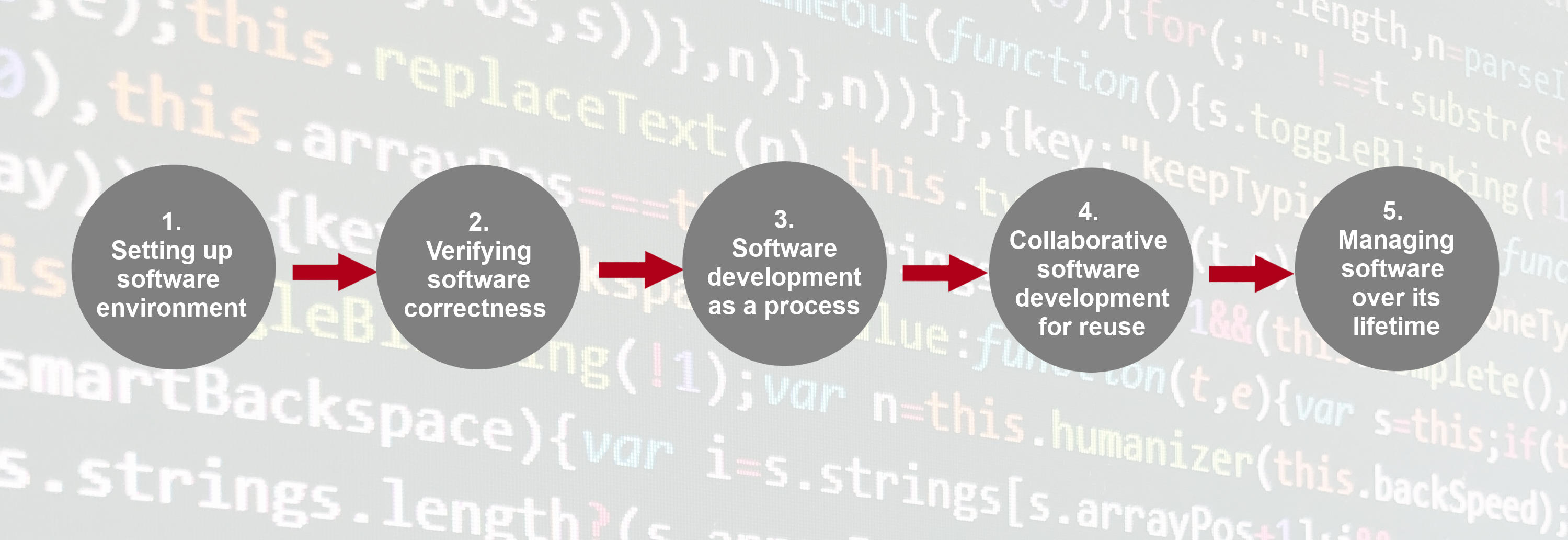
Section 1: Setting up Software Environment
In the first section we are going to set up our working environment and familiarise ourselves with various tools and techniques for software development in a typical collaborative code development cycle:
- Virtual environments for isolating a project from other projects developed on the same machine
- Command line for running code and interacting with the command line tool Git for
- Integrated Development Environment for code development, testing and debugging, Version control and using code branches to develop new features in parallel,
- GitHub (central and remote source code management platform supporting version control with Git) for code backup, sharing and collaborative development, and
- Python code style guidelines to make sure our code is documented, readable and consistently formatted.
Section 2: Verifying Software Correctness at Scale
Once we know our way around different code development tools, techniques and conventions, in this section we learn:
- how to set up a test framework and write tests to verify the behaviour of our code is correct, and
- how to automate and scale testing with Continuous Integration (CI) using GitHub Actions (a CI service available on GitHub).
Section 3: Software Development as a Process
In this section, we step away from writing code for a bit to look at software from a higher level as a process of development and its components:
- different types of software requirements and designing and architecting software to meet them, how these fit within the larger software development process and what we should consider when testing against particular types of requirements.
- different programming and software design paradigms, each representing a slightly different way of thinking about, structuring and implementing the code.
Section 4: Collaborative Software Development for Reuse
Advancing from developing code as an individual, in this section you will start working with your fellow learners on a group project (as you would do when collaborating on a software project in a team), and learn:
- how code review can help improve team software contributions, identify wider codebase issues, and increase codebase knowledge across a team.
- what we can do to prepare our software for further development and reuse, by adopting best practices in documenting, licencing, tracking issues, supporting your software, and packaging software for release to others.
Section 5: Managing and Improving Software Over Its Lifetime
Finally, we move beyond just software development to managing a collaborative software project and will look into:
- internal planning and prioritising tasks for future development using agile techniques and effort estimation, management of internal and external communication, and software improvement through feedback.
- how to adopt a critical mindset not just towards our own software project but also to assess other people’s software to ensure it is suitable for us to reuse, identify areas for improvement, and how to use GitHub to register good quality issues with a particular code repository.
Before We Start
A few notes before we start.
Prerequisite Knowledge
This is an intermediate-level software development course intended for people who have already been developing code in Python (or other languages) and applying it to their own problems after gaining basic software development skills. So, it is expected for you to have some prerequisite knowledge on the topics covered, as outlined at the beginning of the lesson. Check out this quiz to help you test your prior knowledge and determine if this course is for you.
Setup, Common Issues & Fixes
Have you setup and installed all the tools and accounts required for this course? Check the list of common issues, fixes & tips if you experience any problems running any of the tools you installed - your issue may be solved there.
Compulsory and Optional Exercises
Exercises are a crucial part of this course and the narrative. They are used to reinforce the points taught and give you an opportunity to practice things on your own. Please do not be tempted to skip exercises as that will get your local software project out of sync with the course and break the narrative. Exercises that are clearly marked as “optional” can be skipped without breaking things but we advise you to go through them too, if time allows. All exercises contain solutions but, wherever possible, try and work out a solution on your own.
Outdated Screenshots
Throughout this lesson we will make use and show content from Graphical User Interface (GUI) tools (Visual Studio Code (VS Code) and GitHub). These are evolving tools and platforms, always adding new features and new visual elements. Screenshots in the lesson may then become out-of-sync, refer to or show content that no longer exists or is different to what you see on your machine. If during the lesson you find screenshots that no longer match what you see or have a big discrepancy with what you see, please open an issue describing what you see and how it differs from the lesson content. Feel free to add as many screenshots as necessary to clarify the issue.
Key Points
This lesson focuses on core, intermediate skills covering the whole software development life-cycle that will be of most use to anyone working collaboratively on code.
For code development in teams - you need more than just the right tools and languages. You need a strategy (best practices) for how you’ll use these tools as a team.
The lesson follows on from the novice Software Carpentry lesson, but this is not a prerequisite for attending as long as you have some basic Python, command line and Git skills and you have been using them for a while to write code to help with your work.
Section 1: Setting Up Environment For Collaborative Code Development
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What tools are needed to collaborate on code development effectively?
Objectives
Provide an overview of all the different tools that will be used in this course.
The first section of the course is dedicated to setting up your environment for collaborative software development and introducing the project that we will be working on throughout the course. In order to build working (research) software efficiently and to do it in collaboration with others rather than in isolation, you will have to get comfortable with using a number of different tools interchangeably as they’ll make your life a lot easier. There are many options when it comes to deciding which software development tools to use for your daily tasks - we will use a few of them in this course that we believe make a difference. There are sometimes multiple tools for the job - we select one to use but mention alternatives too. As you get more comfortable with different tools and their alternatives, you will select the one that is right for you based on your personal preferences or based on what your collaborators are using.
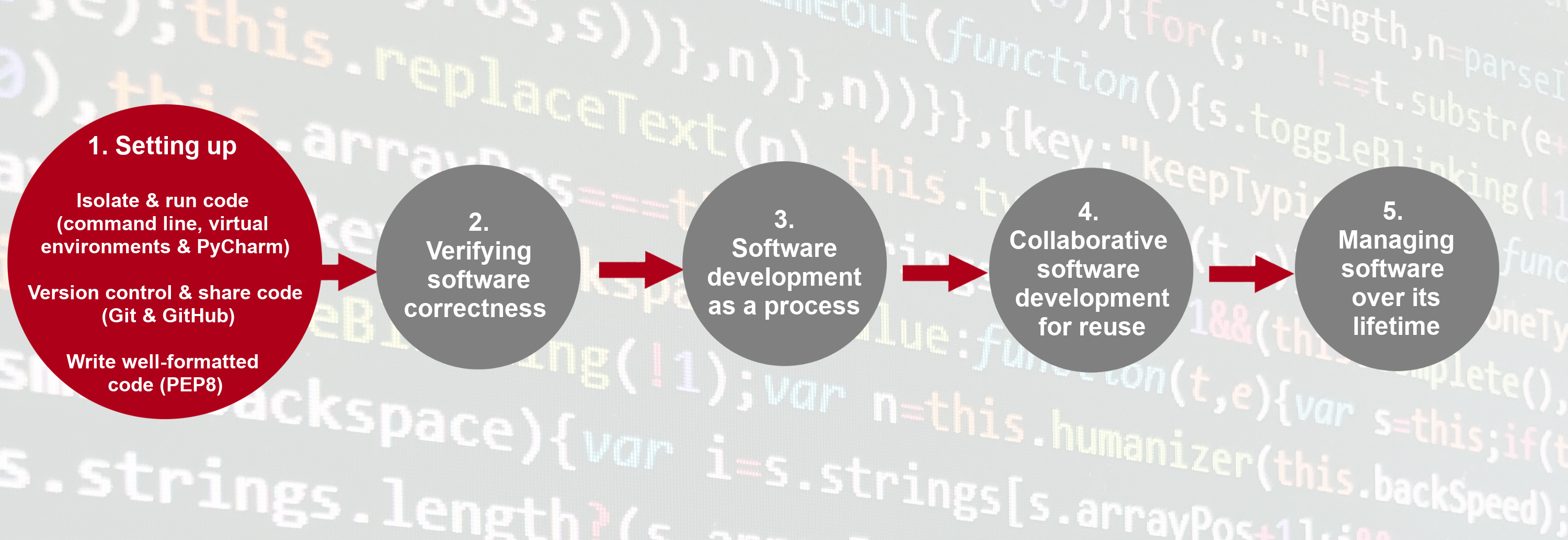
Here is an overview of the tools we will be using.
Setup, Common Issues & Fixes
Have you setup and installed all the tools and accounts required for this course? Check the list of common issues, fixes & tips if you experience any problems running any of the tools you installed - your issue may be solved there.
Command Line & Python Virtual Development Environment
We will use the command line
(also known as the command line shell/prompt/console)
to run our Python code
and interact with the version control tool Git and software sharing platform GitHub.
We will also use command line tools
venv
and pip
to set up a Python virtual development environment
and isolate our software project from other Python projects we may work on.
Note: some Windows users experience the issue where Python hangs from Git Bash
(i.e. typing python causes it to just hang with no error message or output) -
see the solution to this issue.
Integrated Development Environment (IDE)
An IDE integrates a number of tools that we need to develop a software project that goes beyond a single script - including a smart code editor, a code compiler/interpreter, a debugger, etc. It will help you write well-formatted and readable code that conforms to code style guides (such as PEP8 for Python) more efficiently by giving relevant and intelligent suggestions for code completion and refactoring. IDEs often integrate command line console and version control tools - we teach them separately in this course as this knowledge can be ported to other programming languages and command line tools you may use in the future (but is applicable to the integrated versions too).
We will use Visual Studio Code (VS Code) in this course - a free, open source IDE.
Git & GitHub
Git is a free and open source distributed version control system designed to save every change made to a (software) project, allowing others to collaborate and contribute. In this course, we use Git to version control our code in conjunction with GitHub for code backup and sharing. GitHub is one of the leading integrated products and social platforms for modern software development, monitoring and management - it will help us with version control, issue management, code review, code testing/Continuous Integration, and collaborative development. An important concept in collaborative development is version control workflows (i.e. how to effectively use version control on a project with others).
Python Coding Style
Most programming languages will have associated standards and conventions for how the source code should be formatted and styled. Although this sounds pedantic, it is important for maintaining the consistency and readability of code across a project. Therefore, one should be aware of these guidelines and adhere to whatever the project you are working on has specified. In Python, we will be looking at a convention called PEP8.
Let’s get started with setting up our software development environment!
Key Points
In order to develop (write, test, debug, backup) code efficiently, you need to use a number of different tools.
When there is a choice of tools for a task you will have to decide which tool is right for you, which may be a matter of personal preference or what the team or community you belong to is using.
Introduction to Our Software Project
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is the design architecture of our example software project?
Why is splitting code into smaller functional units (modules) good when designing software?
Objectives
Use Git to obtain a working copy of our software project from GitHub.
Inspect the structure and architecture of our software project.
Understand Model-View-Controller (MVC) architecture in software design and its use in our project.
National River Catchment Research Project
So, you have joined a software development team that has been working on the river catchment study project developed in Python and stored on GitHub. The project will involve the analysis of environmental measurement data to improve our understanding of the hydrological, hydrogeological, geomorphological and ecological interactions within permeable catchment systems. To help with the development of the analysis software, you will use baseline datasets from the Lowland Catchment Research (LOCAR) Programme.
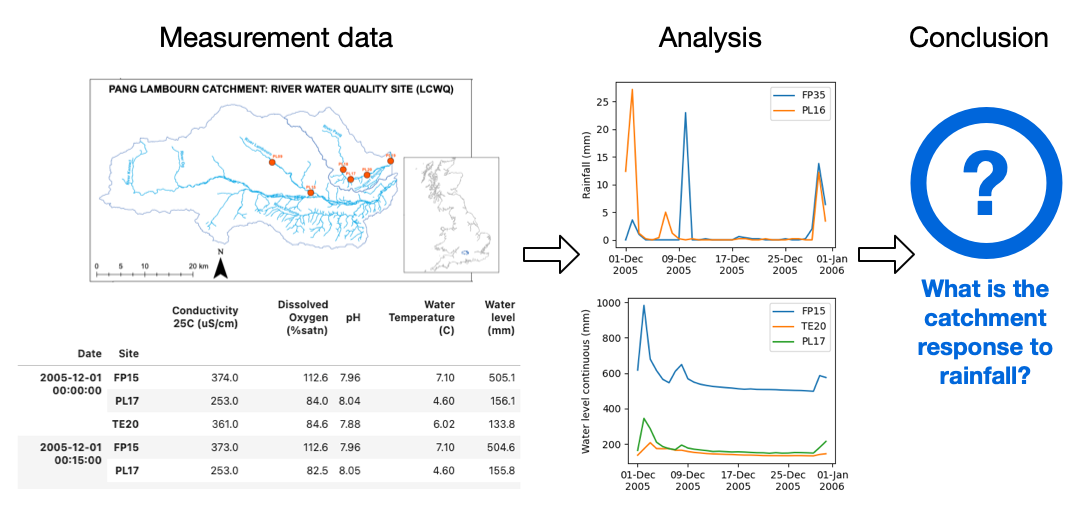
LOCAR study pipeline
What does the Measurement Data contain?
Each dataset records either rain fall or river water measurements, such as the pH, Temperature or Water Level, from a number of measurement sites within a given river catchment area.
Each of the data files uses the popular comma-separated (CSV) format, where:
- The first row contains the column headers
- All subsequent rows contain data for a given site, and date and time
- The first column gives the site identifier,
- The second column gives the site long name,
- The third column gives the date and time of the measurement
- All subsequent columns contain measurement data
These measurements are given at 15 minute intervals. The data in the git repository are a subset of the full dataset, for select sites during December 2005. The full dataset covers a wider range of sites, over the years 2002-2007, and is available to download from the project website linked above.
The project is not finished. It contains some errors and currently can only read the rainfall data files. You will be working on your own and in collaboration with others to fix and build on top of the existing code during the course.
Downloading Our Software Project
To start working on the project, you will first create a copy of the software project template repository from GitHub within your own GitHub account and then obtain a local copy of that project (from your GitHub) on your machine.
- Make sure you have a GitHub account and that you have set up your SSH key pair for authentication with GitHub, as explained in Setup. Note that, while it is possible to use HTTPS with a personal access token for authentication with GitHub, the recommended and supported authentication method to use for this course is via SSH and key pairs.
- Log into your GitHub account.
-
Go to the software project template repository in GitHub.
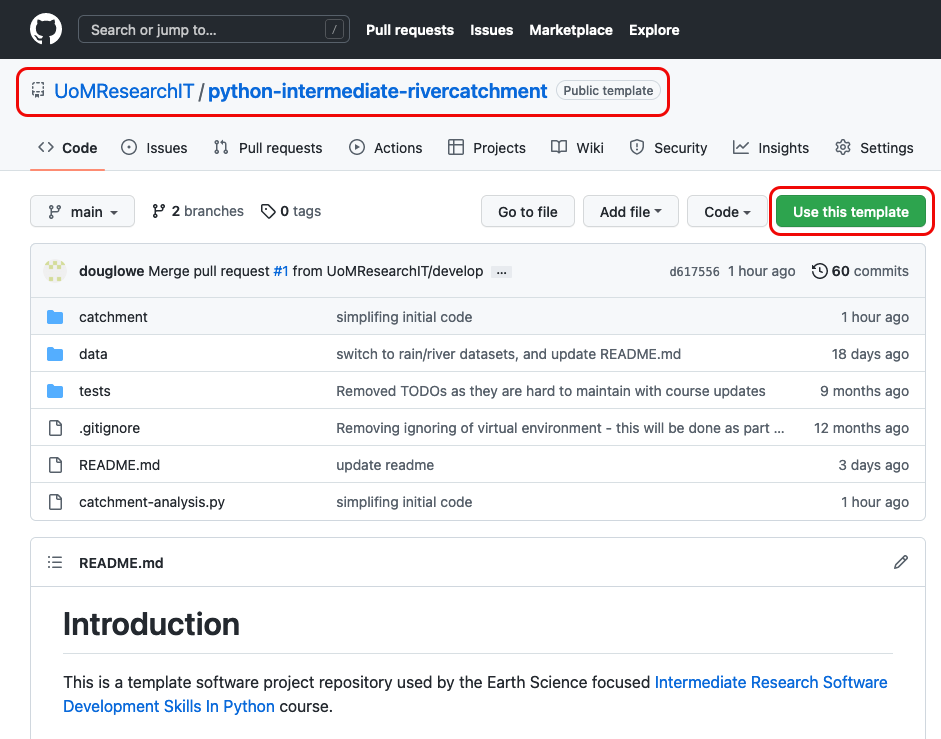
- Click the
Use this templatebutton towards the top right of the template repository’s GitHub page to create a copy of the repository under your GitHub account (you will need to be signed into GitHub to see theUse this templatebutton). Note that each participant is creating their own copy to work on. Also, we are not forking the directory but creating a copy (remember - you can have only one fork but can have multiple copies of a repository in GitHub). -
Make sure to select your personal account and set the name of the project to
python-intermediate-rivercatchment(you can call it anything you like, but it may be easier for future group exercises if everyone uses the same name). Also set the new repository’s visibility to ‘Public’ - so it can be seen by others and by third-party Continuous Integration (CI) services (to be covered later on in the course).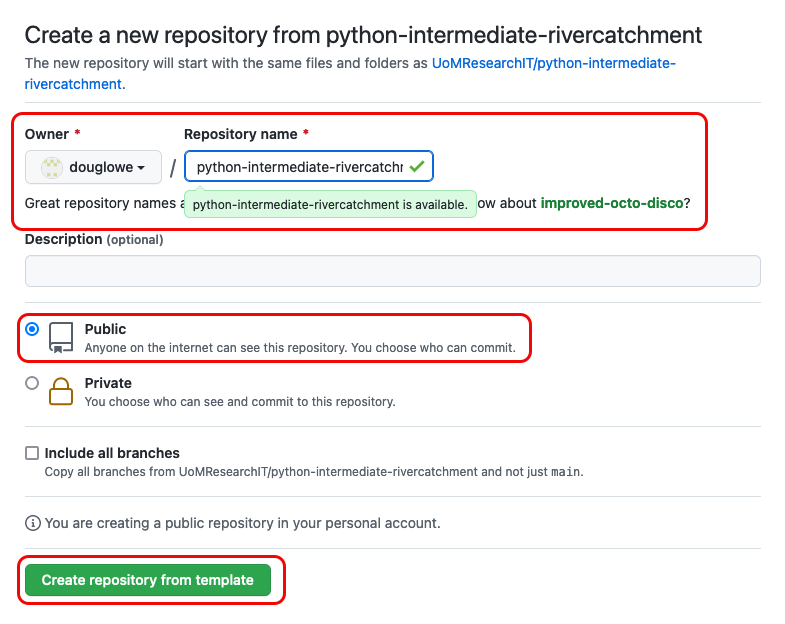
- Click the
Create repository from templatebutton and wait for GitHub to import the copy of the repository under your account. -
Locate the copied repository under your own GitHub account.
Exercise: Obtain the Software Project Locally
Using the command line, clone the copied repository from your GitHub account into the home directory on your computer using SSH. Which command(s) would you use to get a detailed list of contents of the directory you have just cloned?
Solution
- Find the SSH URL of the software project repository to clone from your GitHub account. Make sure you do not clone the original template repository but rather your own copy, as you should be able to push commits to it later on. Also make sure you select the SSH tab and not the HTTPS one - for this course, SSH is the preferred way of authenticating when sending your changes back to GitHub.
- Make sure you are located in your home directory in the command line with:
$ cd ~- From your home directory in the command line, do:
$ git clone git@github.com:<YOUR_GITHUB_USERNAME>/python-intermediate-rivercatchment.gitMake sure you are cloning your copy of the software project and not the template repository.
- Navigate into the cloned repository folder in your command line with:
$ cd python-intermediate-rivercatchmentNote: If you have accidentally copied the HTTPS URL of your repository instead of the SSH one, you can easily fix that from your project folder in the command line with:
$ git remote set-url origin git@github.com:<YOUR_GITHUB_USERNAME>/python-intermediate-catchment.git
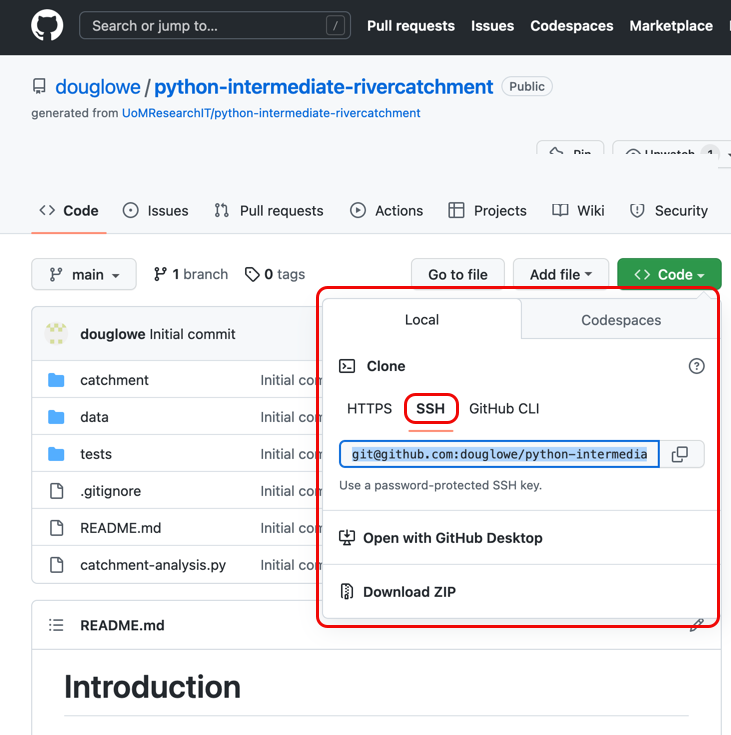
Our Software Project Structure
Let’s inspect the content of the software project from the command line.
From the root directory of the project,
you can use the command ls -l to get a more detailed list of the contents.
You should see something similar to the following.
$ cd ~/python-intermediate-rivercatchment
$ ls -l
total 24
-rw-r--r-- 1 carpentry users 1055 20 Apr 15:41 README.md
drwxr-xr-x 18 carpentry users 576 20 Apr 15:41 data
drwxr-xr-x 5 carpentry users 160 20 Apr 15:41 catchment
-rw-r--r-- 1 carpentry users 1122 20 Apr 15:41 catchment-analysis.py
drwxr-xr-x 4 carpentry users 128 20 Apr 15:41 tests
As can be seen from the above, our software project contains the README file
(that typically describes the project, its usage, installation, authors and how to contribute),
Python script catchment-analysis.py,
and three directories - catchment, data and tests.
The Python script catchment-analysis.py provides
the main entry point in the application,
and on closer inspection,
we can see that the catchment directory contains two more Python scripts -
views.py and models.py.
We will have a more detailed look into these shortly.
$ ls -l catchment
total 24
-rw-r--r-- 1 carpentry users 71 29 Jun 09:59 __init__.py
-rw-r--r-- 1 carpentry users 838 29 Jun 09:59 models.py
-rw-r--r-- 1 carpentry users 649 25 Jun 13:13 views.py
Directory data contains several files with rain and river data
(along with some other files):
$ ls -l data
total 1912
-rw-r--r-- 1 carpentry users 2874 15 Nov 14:30 LOCAR_Site_Information.csv
-rw-r--r-- 1 carpentry users 1360 15 Nov 15:41 README.md
-rw-r--r-- 1 carpentry users 243109 28 Sep 15:30 rain_data_2015-12.csv
drwxr-xr-x 17 carpentry users 544 15 Nov 15:36 river_catchments
-rw-r--r-- 1 carpentry users 721713 28 Sep 15:30 river_data_2015-12.csv
As previously mentioned, each of the data files contains measurement data for select sites in December 2005.
Exercise: Have a Peek at the Data
Which command(s) would you use to list the contents or a first few lines of
data/river_data_2015-12.csvfile?Solution
- To list the entire content of a file from the project root do:
cat data/river_data_2015-12.csv.- To list the first 5 lines of a file from the project root do:
head -n 5 data/river_data_2015-12.csv.Site,Site Name,Date,Battery (V),Conductivity 25C continuous (uS/cm),Oxygen dissolved continuous (%satn),pH continuous,Temperature water continuous (C),Water level continuous (mm) FP15,Frome at Chilfrome,2005-12-01 00:00:00,12.0,374.0,112.6,7.96,7.1,505.1 FP15,Frome at Chilfrome,2005-12-01 00:15:00,12.0,373.0,112.6,7.96,7.1,504.6 FP15,Frome at Chilfrome,2005-12-01 00:30:00,12.0,374.0,112.5,7.96,7.1,504.4 FP15,Frome at Chilfrome,2005-12-01 00:45:00,12.0,374.0,112.5,7.96,7.1,504.4
Directory tests contains several tests that have been implemented already.
We will be adding more tests during the course as our code grows.
An important thing to note here is that the structure of the project is not arbitrary. One of the big differences between novice and intermediate software development is planning the structure of your code. This structure includes software components and behavioural interactions between them (including how these components are laid out in a directory and file structure). A novice will often make up the structure of their code as they go along. However, for more advanced software development, we need to plan this structure - called a software architecture - beforehand.
Let’s have a more detailed look into what a software architecture is and which architecture is used by our software project before we start adding more code to it.
Software Architecture
A software architecture is the fundamental structure of a software system that is decided at the beginning of project development based on its requirements and cannot be changed that easily once implemented. It refers to a “bigger picture” of a software system that describes high-level components (modules) of the system and how they interact.
In software design and development,
large systems or programs are often decomposed into a set of smaller modules
each with a subset of functionality.
Typical examples of modules in programming are software libraries;
some software libraries, such as numpy and matplotlib in Python,
are bigger modules that contain several smaller sub-modules.
Another example of modules are classes in object-oriented programming languages.
Programming Modules and Interfaces
Although modules are self-contained and independent elements to a large extent (they can depend on other modules), there are well-defined ways of how they interact with one another. These rules of interaction are called programming interfaces - they define how other modules (clients) can use a particular module. Typically, an interface to a module includes rules on how a module can take input from and how it gives output back to its clients. A client can be a human, in which case we also call these user interfaces. Even smaller functional units such as functions/methods have clearly defined interfaces - a function/method’s definition (also known as a signature) states what parameters it can take as input and what it returns as an output.
There are various software architectures around defining different ways of dividing the code into smaller modules with well defined roles, for example:
- Model–View–Controller (MVC) architecture, which we will look into in detail and use for our software project,
- Service-oriented architecture (SOA), which separates code into distinct services, accessible over a network by consumers (users or other services) that communicate with each other by passing data in a well-defined, shared format (protocol),
- Client-server architecture, where clients request content or service from a server, initiating communication sessions with servers, which await incoming requests (e.g. email, network printing, the Internet),
- Multilayer architecture, is a type of architecture in which presentation, application processing and data management functions are split into distinct layers and may even be physically separated to run on separate machines - some more detail on this later in the course.
Model-View-Controller (MVC) Architecture
MVC architecture divides the related program logic into three interconnected modules:
- Model (data)
- View (client interface), and
- Controller (processes that handle input/output and manipulate the data).
Model represents the data used by a program and also contains operations/rules for manipulating and changing the data in the model. This may be a database, a file, a single data object or a series of objects - for example a table representing patients’ data.
View is the means of displaying data to users/clients within an application (i.e. provides visualisation of the state of the model). For example, displaying a window with input fields and buttons (Graphical User Interface, GUI) or textual options within a command line (Command Line Interface, CLI) are examples of Views. They include anything that the user can see from the application. While building GUIs is not the topic of this course, we will cover building CLIs in Python in later episodes.
Controller manipulates both the Model and the View. It accepts input from the View and performs the corresponding action on the Model (changing the state of the model) and then updates the View accordingly. For example, on user request, Controller updates a picture on a user’s GitHub profile and then modifies the View by displaying the updated profile back to the user.
MVC Examples
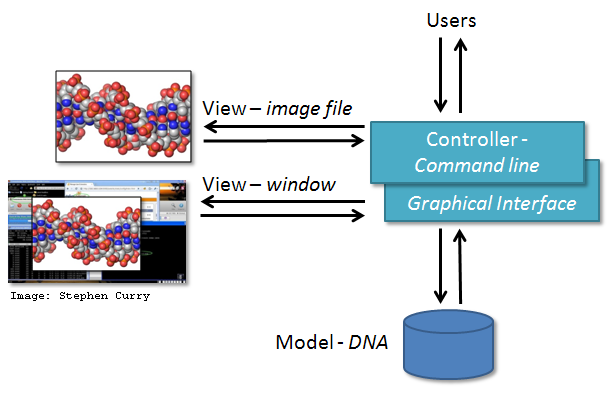
MVC architecture can be applied in scientific applications in the following manner. Model comprises those parts of the application that deal with some type of scientific processing or manipulation of the data, e.g. numerical algorithm, simulation, DNA. View is a visualisation, or format, of the output, e.g. graphical plot, diagram, chart, data table, file. Controller is the part that ties the scientific processing and output parts together, mediating input and passing it to the model or view, e.g. command line options, mouse clicks, input files. For example, the diagram below depicts the use of MVC architecture for the DNA Guide Graphical User Interface application.
Exercise: MVC Application Examples From your Work
Think of some other examples from your work or life where MVC architecture may be suitable or have a discussion with your fellow learners.
Solution
MVC architecture is a popular choice when designing web and mobile applications. Users interact with a web/mobile application by sending various requests to it. Forms to collect users inputs/requests together with the info returned and displayed to the user as a result represent the View. Requests are processed by the Controller, which interacts with the Model to retrieve or update the underlying data. For example, a user may request to view its profile. The Controller retrieves the account information for the user from the Model and passes it to the View for rendering. The user may further interact with the application by asking it to update its personal information. Controller verifies the correctness of the information (e.g. the password satisfies certain criteria, postal address and phone number are in the correct format, etc.) and passes it to the Model for permanent storage. The View is then updated accordingly and the user sees its updated profile details.
Note that not everything fits into the MVC architecture but it is still good to think about how things could be split into smaller units. For a few more examples, have a look at this short article on MVC from CodeAcademy.
Separation of Concerns
Separation of concerns is important when designing software architectures in order to reduce the code’s complexity. Note, however, there are limits to everything - and MVC architecture is no exception. Controller often transcends into Model and View and a clear separation is sometimes difficult to maintain. For example, the Command Line Interface provides both the View (what user sees and how they interact with the command line) and the Controller (invoking of a command) aspects of a CLI application. In Web applications, Controller often manipulates the data (received from the Model) before displaying it to the user or passing it from the user to the Model.
Our Project’s MVC Architecture
Our software project uses the MVC architecture.
The file catchment-analysis.py is the Controller module
that performs basic statistical analysis over catchment data
and provides the main entry point into the application.
The View and Model modules are contained in the files views.py and models.py, respectively,
and are conveniently named.
Data underlying the Model is contained within the directory data -
as we have seen already it contains several files with catchment information.
We will revisit the software architecture and MVC topics once again in later episodes when we talk in more detail about software’s business/user/solution requirements and software design. We now proceed to set up our virtual development environment and start working with the code using a more convenient graphical tool - IDE Visual Studio Code (VS Code).
Key Points
Programming interfaces define how individual modules within a software application interact among themselves or how the application itself interacts with its users.
MVC is a software design architecture which divides the application into three interconnected modules: Model (data), View (user interface), and Controller (input/output and data manipulation).
The software project we use throughout this course is an example of an MVC application that manipulates patients’ inflammation data and performs basic statistical analysis using Python.
Virtual Environments For Software Development
Overview
Teaching: 30 min
Exercises: 0 minQuestions
What are virtual environments in software development and why you should use them?
How can we manage Python virtual environments and external (third-party) libraries?
Objectives
Set up a Python virtual environment for our software project using
venvandpip.Run our software from the command line.
Introduction
So far we have cloned our software project from GitHub and inspected its contents and architecture a bit. We now want to run our code to see what it does - let’s do that from the command line. For the most part of the course we will run our code and interact with Git from the command line. While we will develop and debug our code using the Visual Studio Code (VS Code) IDE and it is possible to use Git from VS Code too, typing commands in the command line allows you to familiarise yourself and learn it well. A bonus is that this knowledge is transferable to running code in other programming languages and is independent from any IDE you may use in the future.
If you have a little peak into our code
(e.g. do cat catchment/views.py and cat catchment/models.py from the project root),
you will see some of the following lines somewhere at the top of the code.
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
Although not every file has the same lines,
taken together these mean that our project requires three external libraries
(also called third-party packages or dependencies) -
numpy, pandas, and matplotlib.
Python applications often use external libraries that don’t come as part of the standard Python distribution.
This means that you will have to use a package manager tool to install them on your system.
Applications will also sometimes need a
specific version of an external library
(e.g. because they were written to work with feature, class,
or function that may have been updated in more recent versions),
or a specific version of Python interpreter.
This means that each Python application you work with may require a different setup
and a set of dependencies so it is useful to be able to keep these configurations
separate to avoid confusion between projects.
The solution for this problem is to create a self-contained
virtual environment per project,
which contains a particular version of Python installation
plus a number of additional external libraries.
Virtual environments are not just a feature of Python - most modern programming languages use them to isolate libraries for a specific project and make it easier to develop, run, test and share code with others. Even languages that don’t explicitly have virtual environments have other mechanisms that promote per-project library collections. In this episode, we learn how to set up a virtual environment to develop our code and manage our external dependencies.
Virtual Environments
So what exactly are virtual environments, and why use them?
A Python virtual environment helps us create an isolated working copy of a software project that uses a specific version of Python interpreter together with specific versions of a number of external libraries installed into that virtual environment. Python virtual environments are implemented as directories with a particular structure within software projects, containing links to specified dependencies allowing isolation from other software projects on your machine that may require different versions of Python or external libraries.
As more external libraries are added to your Python project over time, you can add them to its specific virtual environment and avoid a great deal of confusion by having separate (smaller) virtual environments for each project rather than one huge global environment with potential package version clashes. Another big motivator for using virtual environments is that they make sharing your code with others much easier (as we will see shortly). Here are some typical scenarios where the use of virtual environments is highly recommended (almost unavoidable):
- You have an older project that only works under Python 2. You do not have the time to migrate the project to Python 3 or it may not even be possible as some of the third party dependencies are not available under Python 3. You have to start another project under Python 3. The best way to do this on a single machine is to set up two separate Python virtual environments.
- One of your Python 3 projects is locked to use a particular older version of a third party dependency. You cannot use the latest version of the dependency as it breaks things in your project. In a separate branch of your project, you want to try and fix problems introduced by the new version of the dependency without affecting the working version of your project. You need to set up a separate virtual environment for your branch to ‘isolate’ your code while testing the new feature.
You do not have to worry too much about specific versions of external libraries that your project depends on most of the time. Virtual environments also enable you to always use the latest available version without specifying it explicitly. They also enable you to use a specific older version of a package for your project, should you need to.
A Specific Python or Package Version is Only Ever Installed Once
Note that you will not have a separate Python or package installations for each of your projects - they will only ever be installed once on your system but will be referenced from different virtual environments.
Managing Python Virtual Environments
There are several commonly used command line tools for managing Python virtual environments:
venv, available by default from the standardPythondistribution fromPython 3.3+virtualenv, needs to be installed separately but supports bothPython 2.7+andPython 3.3+versionspipenv, created to fix certain shortcomings ofvirtualenvconda, package and environment management system (also included as part of the Anaconda Python distribution often used by the scientific community)poetry, a modern Python packaging tool which handles virtual environments automatically
While there are pros and cons for using each of the above,
all will do the job of managing Python virtual environments for you
and it may be a matter of personal preference which one you go for.
In this course, we will use venv to create and manage our virtual environment
(which is the preferred way for Python 3.3+).
The upside is that venv virtual environments created from the command line are
also recognised and picked up automatically by VS Code IDE,
as we will see in the next episode.
Managing External Packages
Part of managing your (virtual) working environment involves
installing, updating and removing external packages on your system.
The Python package manager tool pip is most commonly used for this -
it interacts and obtains the packages from the central repository called
Python Package Index (PyPI).
pip can now be used with all Python distributions (including Anaconda).
A Note on Anaconda and
condaAnaconda is an open source Python distribution commonly used for scientific programming - it conveniently installs Python, package and environment management
conda, and a number of commonly used scientific computing packages so you do not have to obtain them separately.condais an independent command line tool (available separately from the Anaconda distribution too) with dual functionality: (1) it is a package manager that helps you find Python packages from remote package repositories and install them on your system, and (2) it is also a virtual environment manager. So, you can usecondafor both tasks instead of usingvenvandpip.
Many Tools for the Job
Installing and managing Python distributions,
external libraries and virtual environments is, well, complex.
There is an abundance of tools for each task,
each with its advantages and disadvantages,
and there are different ways to achieve the same effect
(and even different ways to install the same tool!).
Note that each Python distribution comes with its own version of pip -
and if you have several Python versions installed you have to be extra careful to
use the correct pip to manage external packages for that Python version.
venv and pip are considered the de facto standards for virtual environment
and package management for Python 3.
However, the advantages of using Anaconda and conda are that
you get (most of the) packages needed for scientific code development included with the distribution.
If you are only collaborating with others who are also using Anaconda,
you may find that conda satisfies all your needs.
It is good, however, to be aware of all these tools, and use them accordingly.
As you become more familiar with them you will realise that
equivalent tools work in a similar way even though the command syntax may be different
(and that there are equivalent tools for other programming languages too
to which your knowledge can be ported).
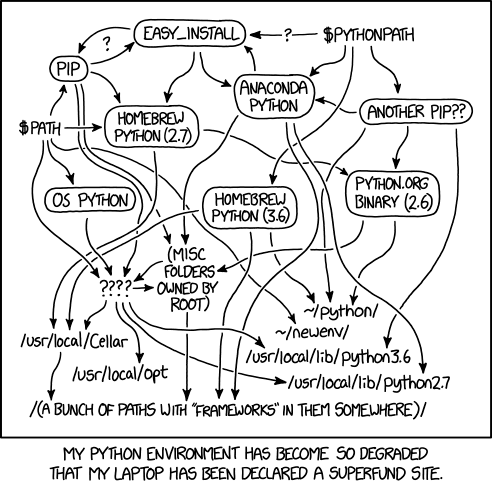
Python Environment Hell
From XKCD (Creative Commons Attribution-NonCommercial 2.5 License)
Let us have a look at how we can create and manage virtual environments from the command line
using venv and manage packages using pip.
Making Sure You Can Invoke Python
You can test your Python installation from the command line with:
$ python3 --version # on Mac/Linux $ python --version # on Windows — Windows installation comes with a python.exe file rather than a python3.exe fileIf you are using Windows and invoking
pythoncommand causes your Git Bash terminal to hang with no error message or output, you may need to create an alias for the python executablepython.exe, as explained in the troubleshooting section.
Creating Virtual Environments Using venv
Creating a virtual environment with venv is done by executing the following command:
$ python3 -m venv /path/to/new/virtual/environment
where /path/to/new/virtual/environment is a path to a directory where you want to place it -
conventionally within your software project so they are co-located.
This will create the target directory for the virtual environment
(and any parent directories that don’t exist already).
What is
-mFlag inpython3Command?The Python
-mflag means “module” and tells the Python interpreter to treat what follows-mas the name of a module and not as a single, executable program with the same name. Some modules (such asvenvorpip) have main entry points and the-mflag can be used to invoke them on the command line via thepythoncommand. The main difference between running such modules as standalone programs (e.g. executing “venv” by running thevenvcommand directly) versus usingpython3 -mcommand seems to be that with latter you are in full control of which Python module will be invoked (the one that came with your environment’s Python interpreter vs. some other version you may have on your system). This makes it a more reliable way to set things up correctly and avoid issues that could prove difficult to trace and debug.
For our project let’s create a virtual environment called “venv”. First, ensure you are within the project root directory, then:
$ python3 -m venv venv
If you list the contents of the newly created directory “venv”, on a Mac or Linux system (slightly different on Windows as explained below) you should see something like:
$ ls -l venv
total 8
drwxr-xr-x 12 alex staff 384 5 Oct 11:47 bin
drwxr-xr-x 2 alex staff 64 5 Oct 11:47 include
drwxr-xr-x 3 alex staff 96 5 Oct 11:47 lib
-rw-r--r-- 1 alex staff 90 5 Oct 11:47 pyvenv.cfg
So, running the python3 -m venv venv command created the target directory called “venv”
containing:
pyvenv.cfgconfiguration file with a home key pointing to the Python installation from which the command was run,binsubdirectory (calledScriptson Windows) containing a symlink of the Python interpreter binary used to create the environment and the standard Python library,lib/pythonX.Y/site-packagessubdirectory (calledLib\site-packageson Windows) to contain its own independent set of installed Python packages isolated from other projects,- various other configuration and supporting files and subdirectories.
Naming Virtual Environments
What is a good name to use for a virtual environment? Using “venv” or “.venv” as the name for an environment and storing it within the project’s directory seems to be the recommended way - this way when you come across such a subdirectory within a software project, by convention you know it contains its virtual environment details. A slight downside is that all different virtual environments on your machine then use the same name and the current one is determined by the context of the path you are currently located in. A (non-conventional) alternative is to use your project name for the name of the virtual environment, with the downside that there is nothing to indicate that such a directory contains a virtual environment. In our case, we have settled to use the name “venv” instead of “.venv” since it is not a hidden directory and we want it to be displayed by the command line when listing directory contents (the “.” in its name that would, by convention, make it hidden). In the future, you will decide what naming convention works best for you. Here are some references for each of the naming conventions:
- The Hitchhiker’s Guide to Python notes that “venv” is the general convention used globally
- The Python Documentation indicates that “.venv” is common
- “venv” vs “.venv” discussion
Once you’ve created a virtual environment, you will need to activate it.
On Mac or Linux, it is done as:
$ source venv/bin/activate
(venv) $
On Windows, recall that we have Scripts directory instead of bin
and activating a virtual environment is done as:
$ source venv/Scripts/activate
(venv) $
Activating the virtual environment will change your command line’s prompt to show what virtual environment you are currently using (indicated by its name in round brackets at the start of the prompt), and modify the environment so that running Python will get you the particular version of Python configured in your virtual environment.
You can verify you are using your virtual environment’s version of Python
by checking the path using the command which:
(venv) $ which python3
/home/alex/python-intermediate-rivercatchment/venv/bin/python3
When you’re done working on your project, you can exit the environment with:
(venv) $ deactivate
If you’ve just done the deactivate,
ensure you reactivate the environment ready for the next part:
$ source venv/bin/activate
(venv) $
Python Within A Virtual Environment
Within a virtual environment, commands
pythonandpipwill refer to the version of Python you created the environment with. If you create a virtual environment withpython3 -m venv venv,pythonwill refer topython3andpipwill refer topip3.On some machines with Python 2 installed,
pythoncommand may refer to the copy of Python 2 installed outside of the virtual environment instead, which can cause confusion. You can always check which version of Python you are using in your virtual environment with the commandwhich pythonto be absolutely sure. We continue usingpython3andpip3in this material to avoid confusion for those users, but commandspythonandpipmay work for you as expected.
Note that, since our software project is being tracked by Git, the newly created virtual environment will show up in version control - we will see how to handle it using Git in one of the subsequent episodes.
Installing External Packages Using pip
We noticed earlier that our code depends on two external packages/libraries -
numpy and matplotlib.
In order for the code to run on your machine,
you need to install these two dependencies into your virtual environment.
To install the latest version of a package with pip
you use pip’s install command and specify the package’s name, e.g.:
(venv) $ python3 -m pip install numpy
(venv) $ python3 -m pip install pandas
(venv) $ python3 -m pip install matplotlib
or like this to install multiple packages at once for short:
(venv) $ python3 -m pip install numpy pandas matplotlib
How About
pip3 install <package-name>Command?You may have seen or used the
pip3 install <package-name>command in the past, which is shorter and perhaps more intuitive thanpython3 -m pip install. However, the official Pip documentation recommendspython3 -m pip installand core Python developer Brett Cannon offers a more detailed explanation of edge cases when the two commands may produce different results and whypython3 -m pip installis recommended. In this material, we will usepython3 -mwhenever we have to invoke a Python module from command line.
If you run the python3 -m pip install command on a package that is already installed,
pip will notice this and do nothing.
To install a specific version of a Python package
give the package name followed by == and the version number,
e.g. python3 -m pip install numpy==1.21.1.
To specify a minimum version of a Python package,
you can do python3 -m pip install numpy>=1.20.
To upgrade a package to the latest version, e.g. python3 -m pip install --upgrade numpy.
To display information about a particular installed package do:
(venv) $ python3 -m pip show numpy
Name: numpy
Version: 1.26.2
Summary: Fundamental package for array computing in Python
Home-page: https://numpy.org
Author: Travis E. Oliphant et al.
Author-email:
License: Copyright (c) 2005-2023, NumPy Developers.
All rights reserved.
...
Required-by: contourpy, matplotlib
To list all packages installed with pip (in your current virtual environment):
(venv) $ python3 -m pip list
Package Version
--------------- -------
contourpy 1.0.5
cycler 0.11.0
fonttools 4.37.4
kiwisolver 1.4.4
matplotlib 3.6.1
numpy 1.23.4
packaging 21.3
pandas 1.5.0
Pillow 9.2.0
pip 20.2.3
pyparsing 3.0.9
python-dateutil 2.8.2
pytz 2022.4
setuptools 49.2.1
six 1.16.0
To uninstall a package installed in the virtual environment do: python3 -m pip uninstall <package-name>.
You can also supply a list of packages to uninstall at the same time.
Exporting/Importing Virtual Environments Using pip
You are collaborating on a project with a team so, naturally,
you will want to share your environment with your collaborators
so they can easily ‘clone’ your software project with all of its dependencies
and everyone can replicate equivalent virtual environments on their machines.
pip has a handy way of exporting, saving and sharing virtual environments.
To export your active environment -
use python3 -m pip freeze command to produce a list of packages installed in the virtual environment.
A common convention is to put this list in a requirements.txt file:
(venv) $ python3 -m pip freeze > requirements.txt
(venv) $ cat requirements.txt
contourpy==1.0.5
cycler==0.11.0
fonttools==4.37.4
kiwisolver==1.4.4
matplotlib==3.6.1
numpy==1.23.4
packaging==21.3
pandas==1.5.0
Pillow==9.2.0
pyparsing==3.0.9
python-dateutil==2.8.2
pytz==2022.4
six==1.16.0
The first of the above commands will create a requirements.txt file in your current directory.
Yours may look a little different,
depending on the version of the packages you have installed,
as well as any differences in the packages that they themselves use.
The requirements.txt file can then be committed to a version control system
(we will see how to do this using Git in one of the following episodes)
and get shipped as part of your software and shared with collaborators and/or users.
They can then replicate your environment
and install all the necessary packages from the project root as follows:
(venv) $ python3 -m pip install -r requirements.txt
As your project grows - you may need to update your environment for a variety of reasons.
For example, one of your project’s dependencies has just released a new version
(dependency version number update),
you need an additional package for data analysis (adding a new dependency)
or you have found a better package and no longer need the older package
(adding a new and removing an old dependency).
What you need to do in this case
(apart from installing the new and removing the packages that are no longer needed
from your virtual environment)
is update the contents of the requirements.txt file accordingly
by re-issuing pip freeze command
and propagate the updated requirements.txt file to your collaborators
via your code sharing platform (e.g. GitHub).
Official Documentation
For a full list of options and commands, consult the official
venvdocumentation and the Installing Python Modules withpipguide. Also check out the guide “Installing packages usingpipand virtual environments”.
Running Python Scripts From Command Line
Congratulations!
Your environment is now activated and set up
to run our catchment-analysis.py script from the command line.
You should already be located in the root of the python-intermediate-rivercatchment directory
(if not, please navigate to it from the command line now).
To run the script, type the following command:
(venv) $ python3 catchment-analysis.py
usage: catchment-analysis.py [-h] infiles [infiles ...]
catchment-analysis.py: error: the following arguments are required: infiles
In the above command, we tell the command line two things:
- to find a Python interpreter (in this case, the one that was configured via the virtual environment), and
- to use it to run our script
catchment-analysis.py, which resides in the current directory.
As we can see, the Python interpreter ran our script, which threw an error -
catchment-analysis.py: error: the following arguments are required: infiles.
It looks like the script expects a list of one or more input files to process,
as indicated by the infiles [infiles ...] text at the end of the usage statement.
We can solve this problem simply by providing those input files.
Let’s start with the rainfall data in the file data/rain_data_2015-12.csv:
(venv) $ python3 catchment-analysis.py data/rain_data_2015-12.csv
This will produce the following figure:
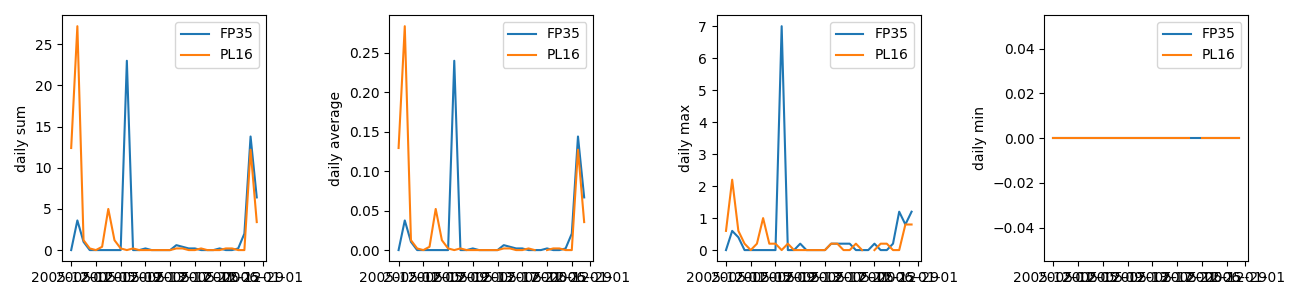 We can see now that the software calculates, and plots, for each site
the daily sum, average, maximum and minimum values of the data provided.
The presentation of the data is not perfect, but it is still a helpful overview of the data.
We can see now that the software calculates, and plots, for each site
the daily sum, average, maximum and minimum values of the data provided.
The presentation of the data is not perfect, but it is still a helpful overview of the data.
Let’s now provide the river data in the file data/river_data_2015-12.csv:
(venv) $ python3 catchment-analysis.py data/rain_data_2015-12.csv
This time, however, we get the following error message:
Traceback (most recent call last):
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 39, in <module>
main(args)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 22, in main
measurement_data = models.read_variable_from_csv(filename)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment/models.py", line 22, in read_variable_from_csv
dataset = pd.read_csv(filename, usecols=['Date', 'Site', 'Rainfall (mm)'])
...
ValueError: Usecols do not match columns, columns expected but not found: ['Rainfall (mm)']
We can see that error is caused by a mismatch
between the columns of data the program expects to find,
and what columns of data are present in the input file.
The traceback information also shows the cause of the error,
which is that the columns of data expected are hard-coded in the models.py file:
dataset = pd.read_csv(filename, usecols=['Date', 'Site', 'Rainfall (mm)'])
Hard-coding values like this into your code is problematic because it ultimately reduces the flexibility of your programs. We cannot correct this error right now, but will revisit the problem in a later episode.
Key Points
Virtual environments keep Python versions and dependencies required by different projects separate.
A virtual environment is itself a directory structure.
Use
venvto create and manage Python virtual environments.Use
pipto install and manage Python external (third-party) libraries.
pipallows you to declare all dependencies for a project in a separate file (by convention calledrequirements.txt) which can be shared with collaborators/users and used to replicate a virtual environment.Use
python3 -m pip freeze > requirements.txtto take snapshot of your project’s dependencies.Use
python3 -m pip install -r requirements.txtto replicate someone else’s virtual environment on your machine from therequirements.txtfile.
Integrated Software Development Environments
Overview
Teaching: 25 min
Exercises: 15 minQuestions
What are Integrated Development Environments (IDEs)?
What are the advantages of using IDEs for software development?
Objectives
Set up a (virtual) development environment in Visual Studio Code (VS Code)
Use VS Code to run a Python script
Introduction
As we have seen in the previous episode - even a simple software project is typically split into smaller functional units and modules, which are kept in separate files and subdirectories. As your code starts to grow and becomes more complex, it will involve many different files and various external libraries. You will need an application to help you manage all the complexities of, and provide you with some useful (visual) facilities for, the software development process. Such clever and useful graphical software development applications are called Integrated Development Environments (IDEs).
Integrated Development Environments
An IDE normally consists of at least a source code editor, build automation tools and a debugger. The boundaries between modern IDEs and other aspects of the broader software development process are often blurred. Nowadays IDEs also offer version control support, tools to construct graphical user interfaces (GUI) and web browser integration for web app development, source code inspection for dependencies and many other useful functionalities. The following is a list of the most commonly seen IDE features:
- syntax highlighting - to show the language constructs, keywords and the syntax errors with visually distinct colours and font effects
- code completion - to speed up programming by offering a set of possible (syntactically correct) code options
- code search - finding package, class, function and variable declarations, their usages and referencing
- version control support - to interact with source code repositories
- debugging - for setting breakpoints in the code editor, step-by-step execution of code and inspection of variables
IDEs are extremely useful and modern software development would be very hard without them. There are a number of IDEs available for Python development; a good overview is available from the Python Project Wiki. In addition to IDEs, there are also a number of code editors that have Python support. Code editors can be as simple as a text editor with syntax highlighting and code formatting capabilities (e.g., GNU EMACS, Vi/Vim). Most good code editors can also execute code and control a debugger, and some can also interact with a version control system. Compared to an IDE, a good dedicated code editor is usually smaller and quicker, but often less feature-rich. You will have to decide which one is the best for you - in this course we will learn how to use VS Code, a free multi-language (including Python) IDE. Some popular alternatives for Python include free and open source IDE Spyder and JetBrain’s free and open source PyCharm.
Using PyCharm for This Course
If you want to use PyCharm as your IDE for this course, you can use the IDE episode of the original course to help you set up. The instructions for VS Code in the course will not apply to you verbatim but there is an equivalent functionality in PyCharm for each of the actions we ask you to do in VS Code.
Using the VS Code IDE
Let’s open our project in VS Code now and familiarise ourselves with some commonly used features.
Opening a Software Project
If you don’t have VS Code running yet, start it up now.
An interactive Welcome page will appear,
which allows you to configure your development environment’s themes and other aspects,
but can skip these steps for now, by clicking on Mark Done near the bottom of that page.
The Welcome page will now ask you what you want to do,
e.g. open a New File, Open File to select an existing one, Open Folder or Clone a Git Repository.
Select Open Folder and find the software project directory
python-intermediate-rivercatchment you cloned earlier.
This directory is now the current working directory for VS Code,
so when we run scripts from VS Code, this is the directory they will run from.
If VS Code asks you: Do you trust the authors of the files in this folder?,
select Yes, I trust the authors.
On the left side of the VS Code interface is the ‘Activity Bar’, which contains several tabs.
The top (default) tab is the Explorer view,
and is represented by an icon of a couple of sheets of paper.
This opens a project/file navigator window which can be used to traverse
and select the files (and any subdirectories) within the working directory,
and selected files are opened in an editor window on the right.
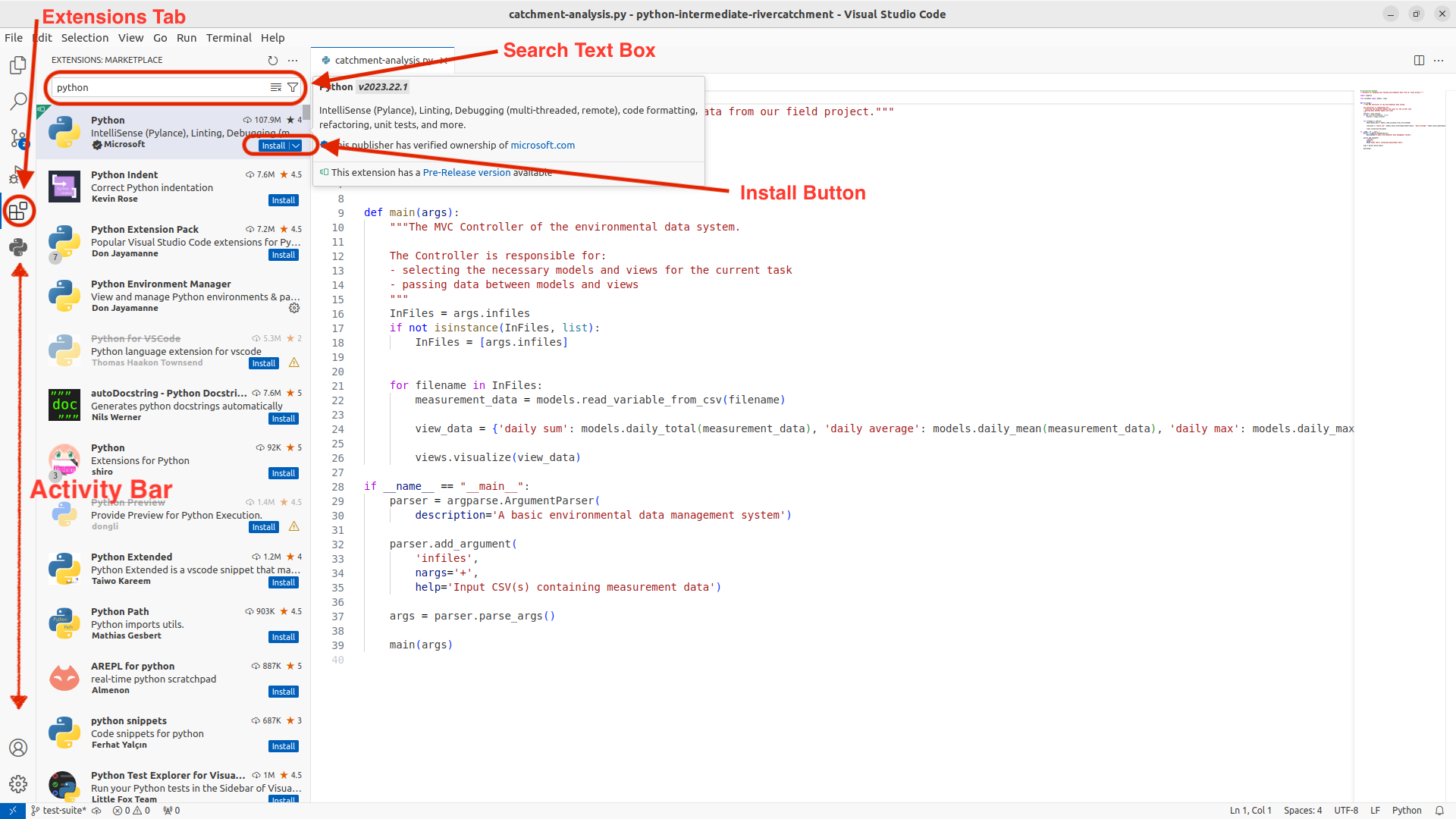
Further down the Activity Bar is the Extensions Tab,
represented by four squares, the top-right square not yet connected to the others.
We will use this to add the Python extension for VS Code.
Click on the Extensions tab and, in the search text box,
type Python. Select the Python extension, as shown in the following figure,
and click the blue install button.
At the bottom of the screen, you have a status bar which shows the current Git branch, and typically the Virtual Environment being used by our project. The latter isn’t displayed here because we haven’t set it yet, we’ll do that soon. Along the top, the menu bar has a variety of options, for example opening a terminal (the command line within VS Code). We will be using some of these in our upcoming episodes.
You can close the Welcome and any other open documents in the main editor window.
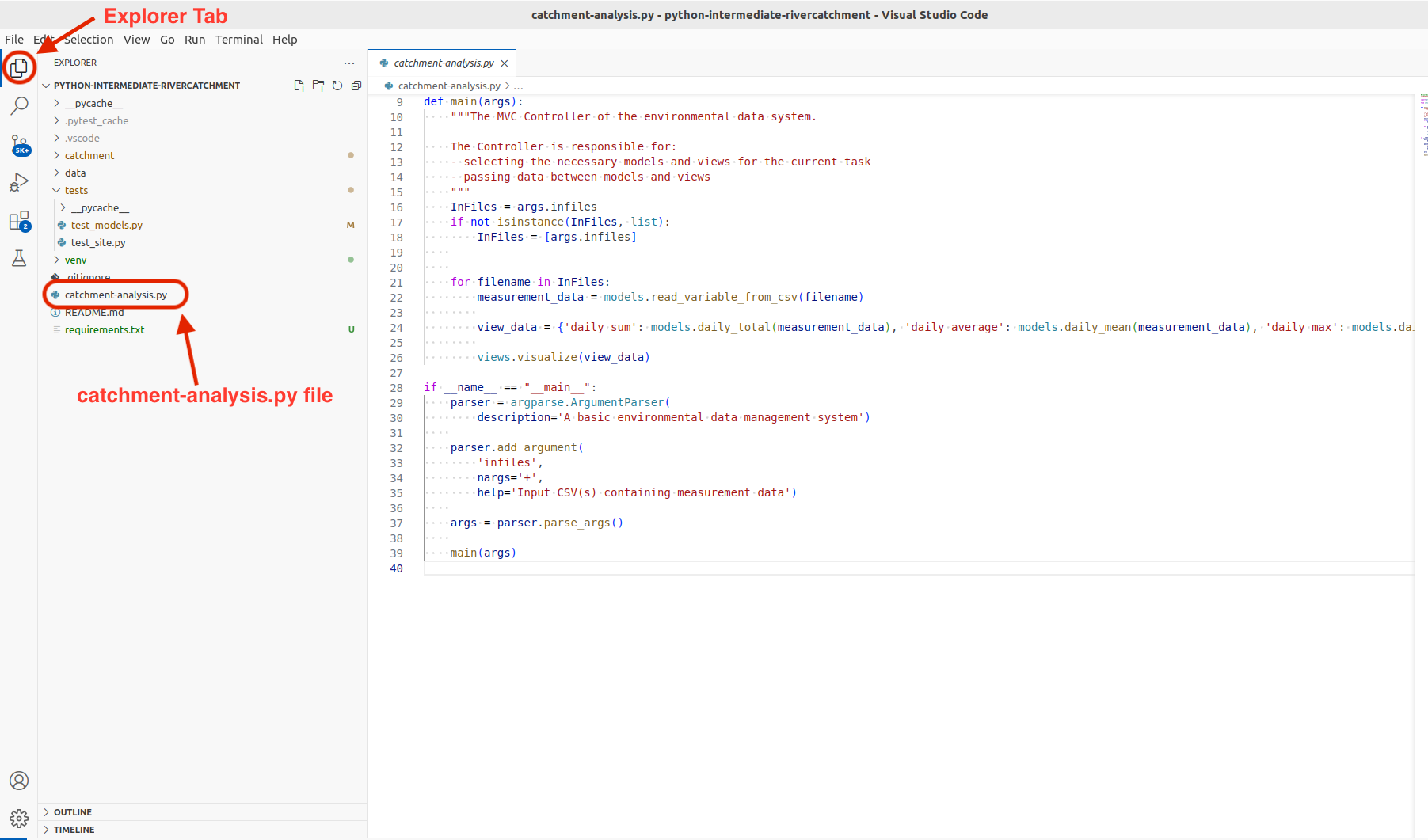
Now click on the Explorer tab on the left hand side.
Use this view to navigate to the catchment-analysis.py file and select it,
so that its contents are displayed in the editor window.
You may have noticed that the virtual environment (venv) that we created previously
(held in the ./venv folder in our project directory)
is now showing on the bottom status bar, on the right hand side.
If this is the case, it shows that VS Code is using that environment as the interpreter.
In many cases, VS Code will have been able to locate this environment automatically,
and add it as the most likely option (as it is located within the current project directory).
But it is better to explicitly select an interpeter for your project,
to do this follow these steps:
- Press
Command-Shift-P(on Mac) orControl-Shift-P(on Windows or Linux) to bring up the VS Code Command Palette - Search for
Python: select interpreterand select it - This will display a drop-down list of options, select
+ Enter interpreter path... - Click on
Find...and browse in the pop-up window to select the path to thepythonbinary file held in the./venv/bin/directory.
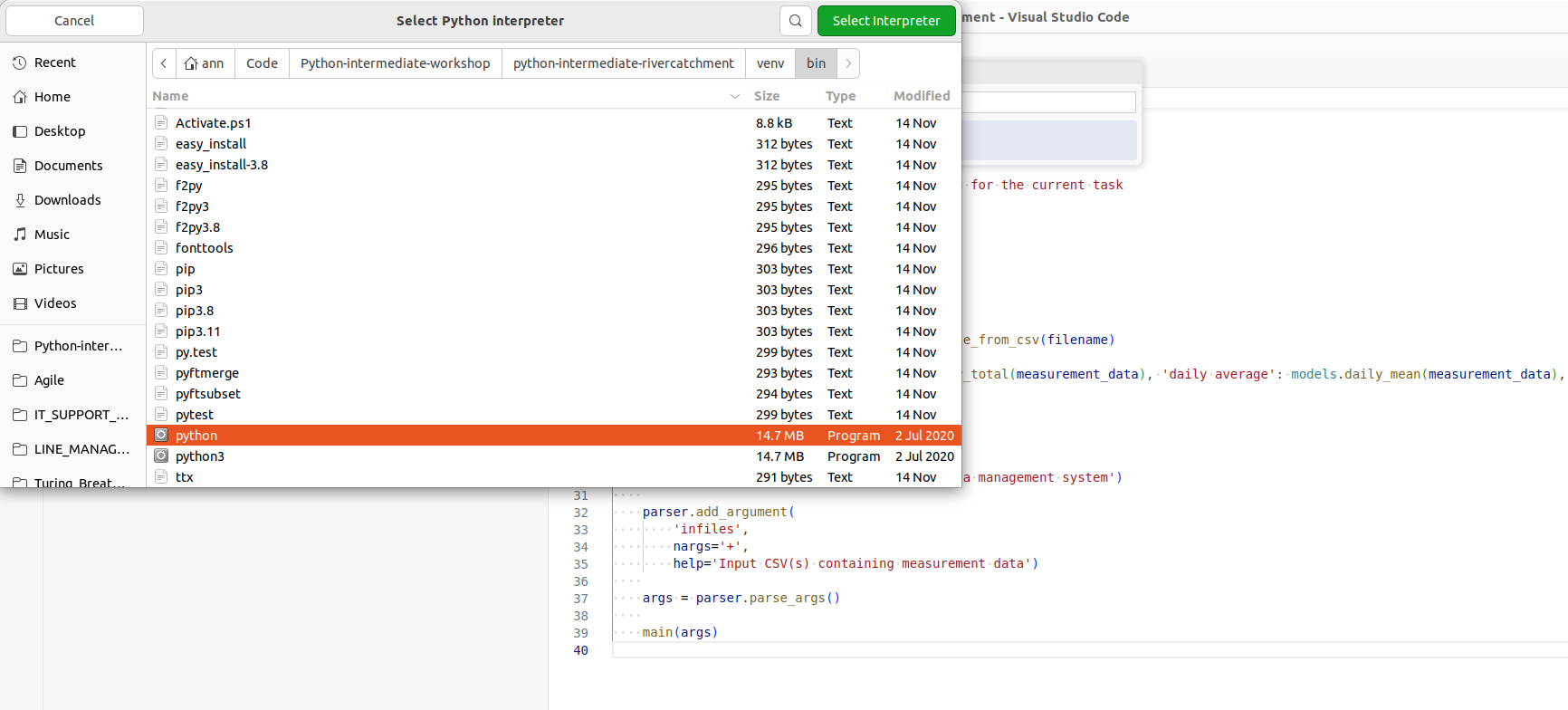
To make working with Python virtual environments easier in VS Code
we will install another extension called Python Environment Manager.
Click on the Extensions tab and in the search edit box, type Python Environment Manager,
select the correct extension, and click the blue install button.
A new tab will appear at the bottom of the Activity Bar, as shown below:
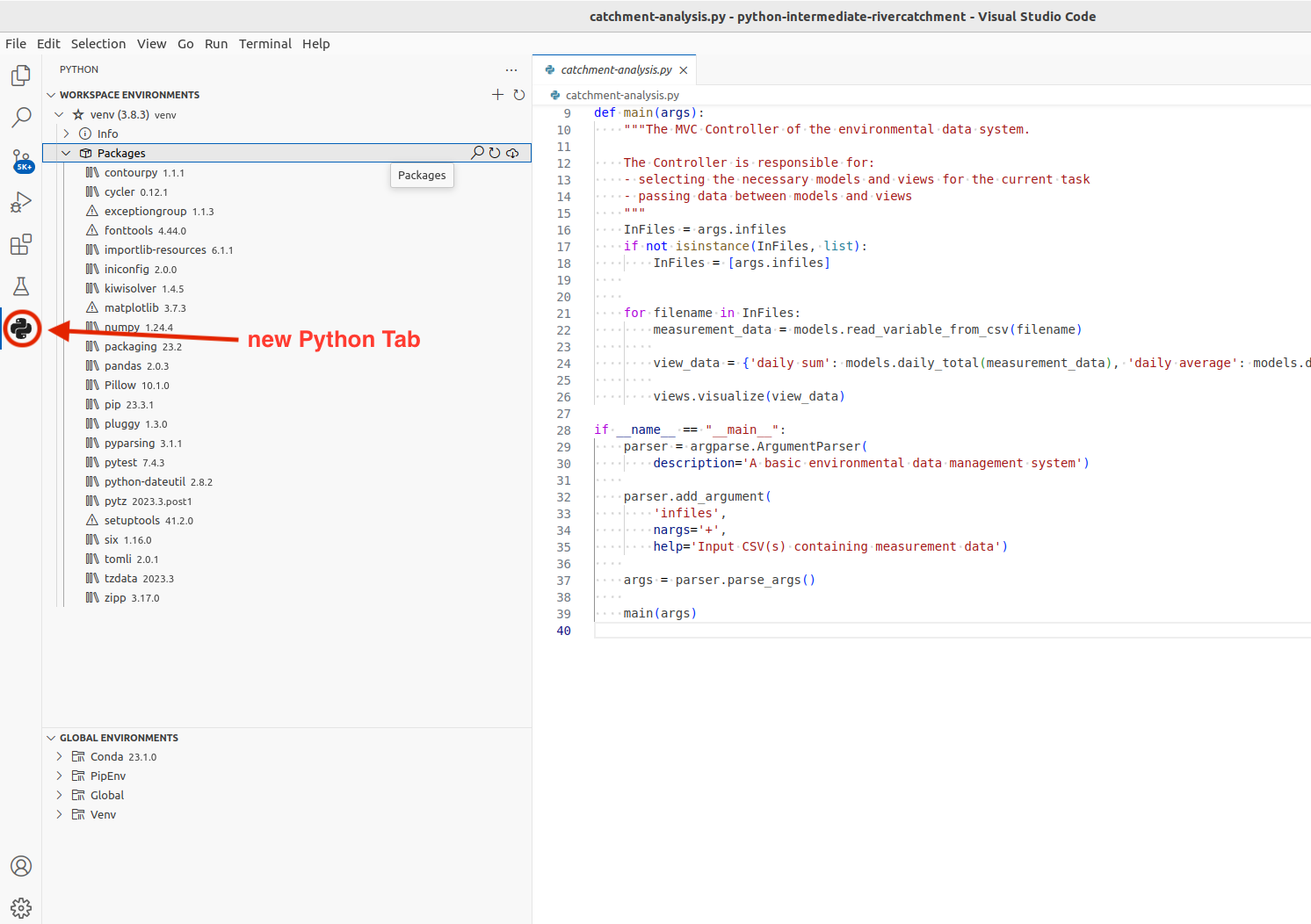
You can navigate around the current venv environment or look at alternatives environments,
either within the current workspace or elsewhere on your computer (listed under “Global Environments”).
Note that the external libraries we installed earlier are listed here, under “venv”.
VS Code has recognised the virtual environment we created from the command line using venv,
and enables us to work with the installed libraries as we would from the command line.
Also note that, although the names are not the same - this is one and the same virtual environment and changes made to it in VS Code will be accessible from the command line and vice versa. Let’s see this in action through the following exercise.
Exercise: Compare External Libraries in the Command Line and VS Code
Can you recall two places where information about our project’s dependencies can be found from the command line? Compare that information with the equivalent configuration in VS Code.
Hint: We can use an argument to
pip, or find the packages directly in a subdirectory of our virtual environment directory “venv”.Solution
From the previous episode, you may remember that we can get the list of packages in the current virtual environment using
pip:(venv) $ python3 -m pip listPackage Version --------------- ------- contourpy 1.0.5 cycler 0.11.0 fonttools 4.37.4 kiwisolver 1.4.4 matplotlib 3.6.1 numpy 1.23.4 packaging 21.3 pandas 1.5.0 Pillow 9.2.0 pip 21.3.1 pyparsing 3.0.9 python-dateutil 2.8.2 pytz 2022.5 setuptools 60.2.0 six 1.16.0 wheel 0.37.1However,
python3 -m pip listshows all the packages in the virtual environment - if we want to see only the list of packages that we installed, we can use thepython3 -m pip freezecommand instead:(venv) $ python3 -m pip freezecontourpy==1.0.5 cycler==0.11.0 fonttools==4.37.4 kiwisolver==1.4.4 matplotlib==3.6.1 numpy==1.23.4 packaging==21.3 pandas==1.5.0 Pillow==9.2.0 pyparsing==3.0.9 python-dateutil==2.8.2 pytz==2022.5 six==1.16.0We see the
pippackage inpython3 -m pip listbut not inpython3 -m pip freezeas we did not install it usingpip. Remember that we usepython3 -m pip freezeto update ourrequirements.txtfile, to keep a list of the packages our virtual environment includes. Python will not do this automatically; we have to manually update the file when our requirements change using:python3 -m pip freeze > requirements.txtIf we want, we can also see the list of packages directly in the following subdirectory of
venv:(venv) $ ls -l venv/lib/python3.11/site-packagestotal 88 drwxr-xr-x 105 alex staff 3360 20 Nov 15:34 PIL drwxr-xr-x 9 alex staff 288 20 Nov 15:34 Pillow-10.1.0.dist-info drwxr-xr-x 4 alex staff 128 20 Nov 15:34 __pycache__ drwxr-xr-x 5 alex staff 160 20 Nov 15:32 _distutils_hack drwxr-xr-x 16 alex staff 512 20 Nov 15:34 contourpy drwxr-xr-x 7 alex staff 224 20 Nov 15:34 contourpy-1.2.0.dist-info drwxr-xr-x 5 alex staff 160 20 Nov 15:34 cycler drwxr-xr-x 8 alex staff 256 20 Nov 15:34 cycler-0.12.1.dist-info drwxr-xr-x 14 alex staff 448 20 Nov 15:34 dateutil -rw-r--r-- 1 alex staff 151 20 Nov 15:32 distutils-precedence.pth drwxr-xr-x 33 alex staff 1056 20 Nov 15:34 fontTools drwxr-xr-x 9 alex staff 288 20 Nov 15:34 fonttools-4.45.0.dist-info drwxr-xr-x 8 alex staff 256 20 Nov 15:34 kiwisolver drwxr-xr-x 8 alex staff 256 20 Nov 15:34 kiwisolver-1.4.5.dist-info drwxr-xr-x 150 alex staff 4800 20 Nov 15:34 matplotlib drwxr-xr-x 20 alex staff 640 20 Nov 15:34 matplotlib-3.8.2.dist-info drwxr-xr-x 5 alex staff 160 20 Nov 15:34 mpl_toolkits drwxr-xr-x 43 alex staff 1376 20 Nov 15:34 numpy drwxr-xr-x 9 alex staff 288 20 Nov 15:34 numpy-1.26.2.dist-info drwxr-xr-x 18 alex staff 576 20 Nov 15:34 packaging drwxr-xr-x 9 alex staff 288 20 Nov 15:34 packaging-23.2.dist-info drwxr-xr-x 9 alex staff 288 20 Nov 15:32 pip drwxr-xr-x 10 alex staff 320 20 Nov 15:33 pip-23.0.1.dist-info drwxr-xr-x 6 alex staff 192 20 Nov 15:32 pkg_resources -rw-r--r-- 1 alex staff 90 20 Nov 15:34 pylab.py drwxr-xr-x 15 alex staff 480 20 Nov 15:34 pyparsing drwxr-xr-x 7 alex staff 224 20 Nov 15:34 pyparsing-3.1.1.dist-info drwxr-xr-x 9 alex staff 288 20 Nov 15:34 python_dateutil-2.8.2.dist-info drwxr-xr-x 49 alex staff 1568 20 Nov 15:32 setuptools drwxr-xr-x 10 alex staff 320 20 Nov 15:32 setuptools-67.6.1.dist-info drwxr-xr-x 8 alex staff 256 20 Nov 15:34 six-1.16.0.dist-info -rw-r--r-- 1 alex staff 34549 20 Nov 15:34 six.pyFinally, if you look at both the contents of
venv/lib/python3.11/site-packagesandrequirements.txtand compare that with the packages shown in VS Code’s Python Interpreter Configuration - you will see that they all contain equivalent information.
Adding an External Library
We have already added packages numpy and matplotlib to our virtual environment
from the command line in the previous episode,
so we are up-to-date with all external libraries we require at the moment.
However, we will need library pytest soon to implement tests for our code.
We will use this opportunity to install it from VS Code in order to see
an alternative way of doing this and how it propagates to the command line.
- Select the Python tab in the Activity Bar on the left, as we did earlier.
- Under our
venvenvironment, hover overPackages - Select the magnifying glass icon (Install Package)
- In the window that appears, search for the name of the library (
pytest), then click on this package in the list below to install it.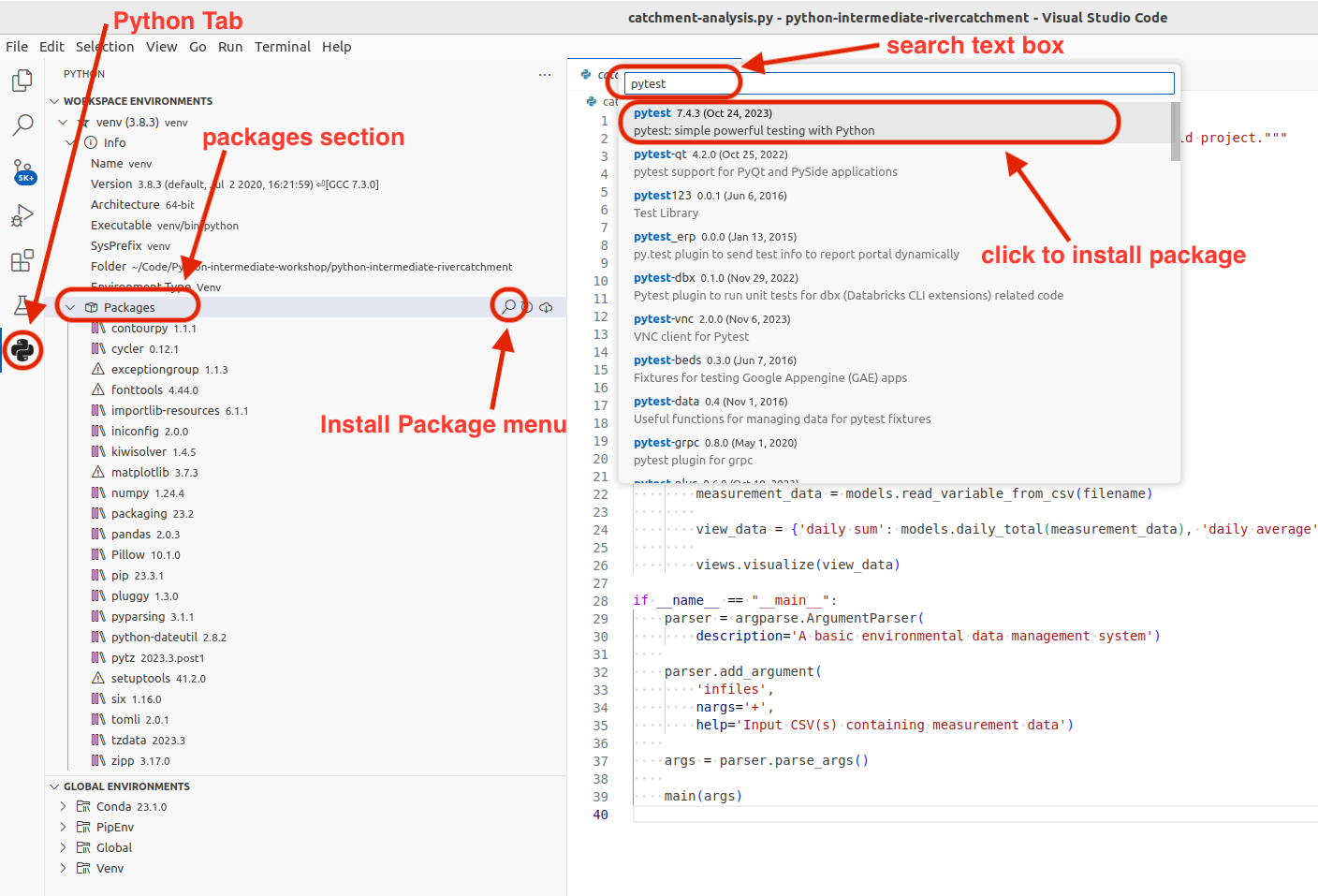
It may take a few minutes for VS Code to install it.
After it is done, the pytest library is added to our virtual environment.
You can also verify this from the command line by
listing the venv/lib/python3.11/site-packages subdirectory.
Note, however, that requirements.txt is not updated -
as we mentioned earlier this is something you have to do manually.
Let’s do this as an exercise.
Exercise: Update
requirements.txtAfter Adding a New DependencyExport the newly updated virtual environment into
requirements.txtfile.Solution
Let’s verify first that the newly installed library
pytestis appearing in our virtual environment but not inrequirements.txt. First, let’s check the list of installed packages:(venv) $ python3 -m pip listPackage Version --------------- ------- attrs 22.1.0 contourpy 1.0.5 cycler 0.11.0 fonttools 4.37.4 iniconfig 1.1.1 kiwisolver 1.4.4 matplotlib 3.6.1 numpy 1.23.4 packaging 21.3 pandas 1.5.0 Pillow 9.2.0 pip 21.3.1 pluggy 1.0.0 py 1.11.0 pyparsing 3.0.9 pytest 7.1.3 python-dateutil 2.8.2 pytz 2022.5 setuptools 60.2.0 six 1.16.0 tomli 2.0.1 wheel 0.37.1We can see the
pytestlibrary appearing in the listing above. However, if we do:(venv) $ cat requirements.txtcontourpy==1.0.5 cycler==0.11.0 fonttools==4.37.4 kiwisolver==1.4.4 matplotlib==3.6.1 numpy==1.23.4 packaging==21.3 pandas==1.5.0 Pillow==9.2.0 pyparsing==3.0.9 python-dateutil==2.8.2 pytz==2022.5 six==1.16.0
pytestis missing fromrequirements.txt. To add it, we need to update the file by repeating the command:(venv) $ python3 -m pip freeze > requirements.txt
pytestis now present inrequirements.txt:attrs==22.1.0 contourpy==1.0.5 cycler==0.11.0 fonttools==4.37.4 iniconfig==1.1.1 kiwisolver==1.4.4 matplotlib==3.6.1 numpy==1.23.4 packaging==21.3 pandas==1.5.0 Pillow==9.2.0 pluggy==1.0.0 py==1.11.0 pyparsing==3.0.9 pytest==7.1.3 python-dateutil==2.8.2 pytz==2022.5 six==1.16.0 tomli==2.0.1
Adding a Run Configuration for Our Project
Having configured a virtual environment, we now need to tell VS Code how to use it for our project. This is done by creating and adding a Run Configuration to a project. Run Configurations in VS Code are named sets of startup properties that define which main Python script to execute and what (optional) runtime parameters/environment variables (i.e. additional configuration options) to pass and use on top of virtual environments.
Run Configurations are defined in a launch.json file,
usually stored in the .vscode directory within your project directory.
At first this file will not exist,
and clicking on the Run and Debug tab in the Activity Bar will,
as shown below, present a dialog box asking you to create one.
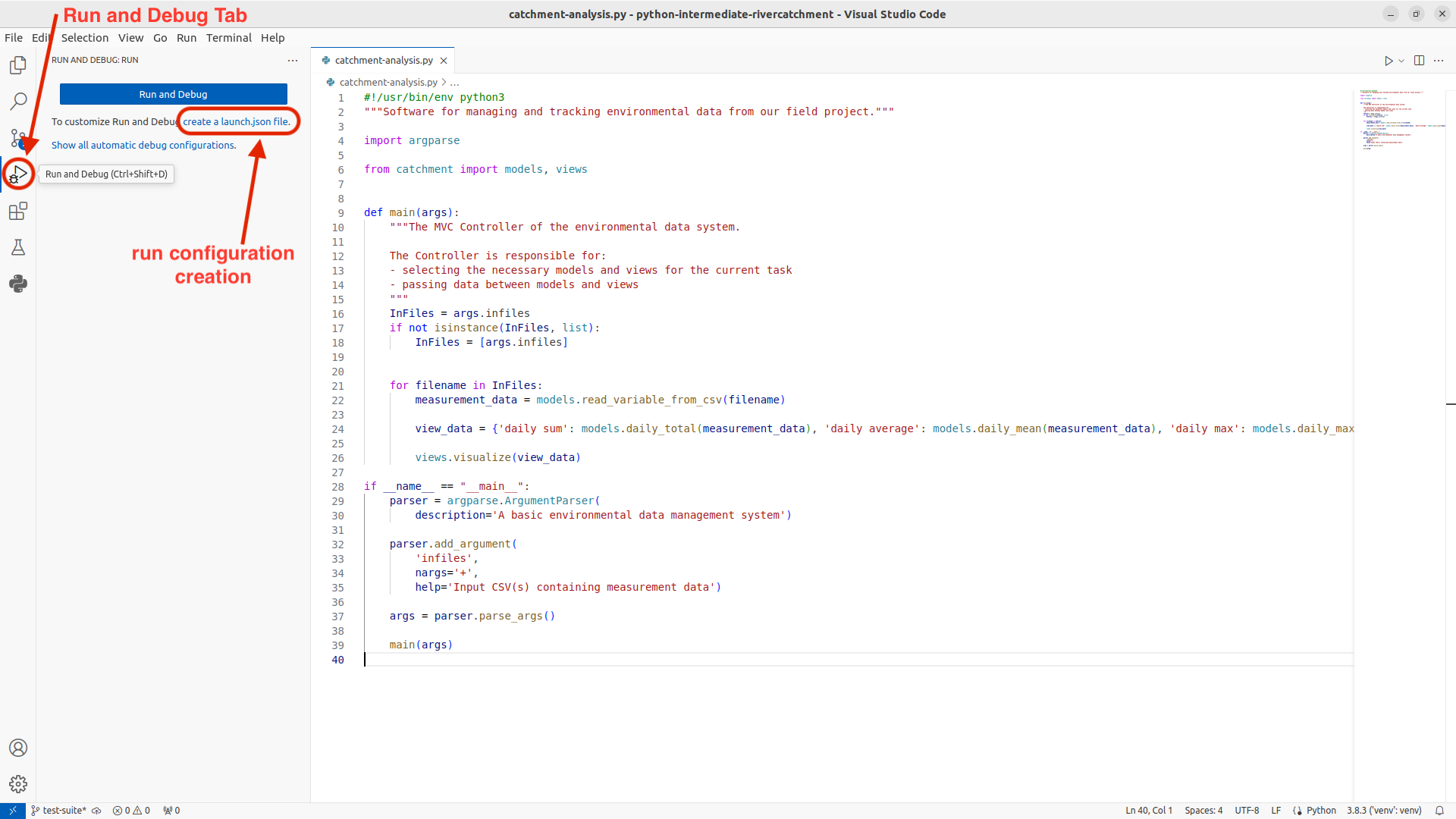
We will create two run configurations for the catchment-analysis module:
- Click on the
Run and Debugtab in the Activity Bar on the left. - In the
Run and Debugpanel click on thecreate a launch.json filelink. - This will open a search text box, from which select
Python File: Debug the currently active Python File - This will create a
launch.jsonfile, and open it in the editor window, with a configuration for just python files - Change the contents of the file, to match the code below.
- Save the file.
{
"version": "0.2.0",
"configurations": [
{
"name": "Catchment-analysis: Rain",
"type": "debugpy",
"request": "launch",
"args" : [ "data/rain_data_2015-12.csv" ],
"module": "catchment-analysis",
"console": "integratedTerminal",
"justMyCode": true
},
{
"name": "Catchment-analysis: River",
"type": "debugpy",
"request": "launch",
"args" : [ "data/river_data_2015-12.csv" ],
"module": "catchment-analysis",
"console": "integratedTerminal",
"justMyCode": true
}
]
}
Click again on the Run and Debug tab in the Activity Bar.
The Run and Debug panel should have changed,
and there will now be a Run symbol at the top of the panel.
When you click on the Run symbol there should be a drop-down list with two choices,
run Catchment-analysis: Rain or Catchment-analysis: River,
each of which will run the catchment-analysis.py script as a module,
but with the relevant data file passed as an argument.
You can edit the launch.json file further
by clicking on the Settings cog symbol next to the Run symbol.
This is useful for adding further configurations,
or more arguments to be input when running the scripts.
Now you know how to configure and manipulate your environment in both tools (command line and VS Code), which is a useful parallel to be aware of. Let’s have a look at some other features afforded to us by VS Code.
Syntax Highlighting
The first thing you may notice is that code is displayed using different colours. Syntax highlighting is a feature that displays source code terms in different colours and fonts according to the syntax category the highlighted term belongs to. It also makes syntax errors visually distinct. Highlighting does not affect the meaning of the code itself - it’s intended only for humans to make reading code and finding errors easier.
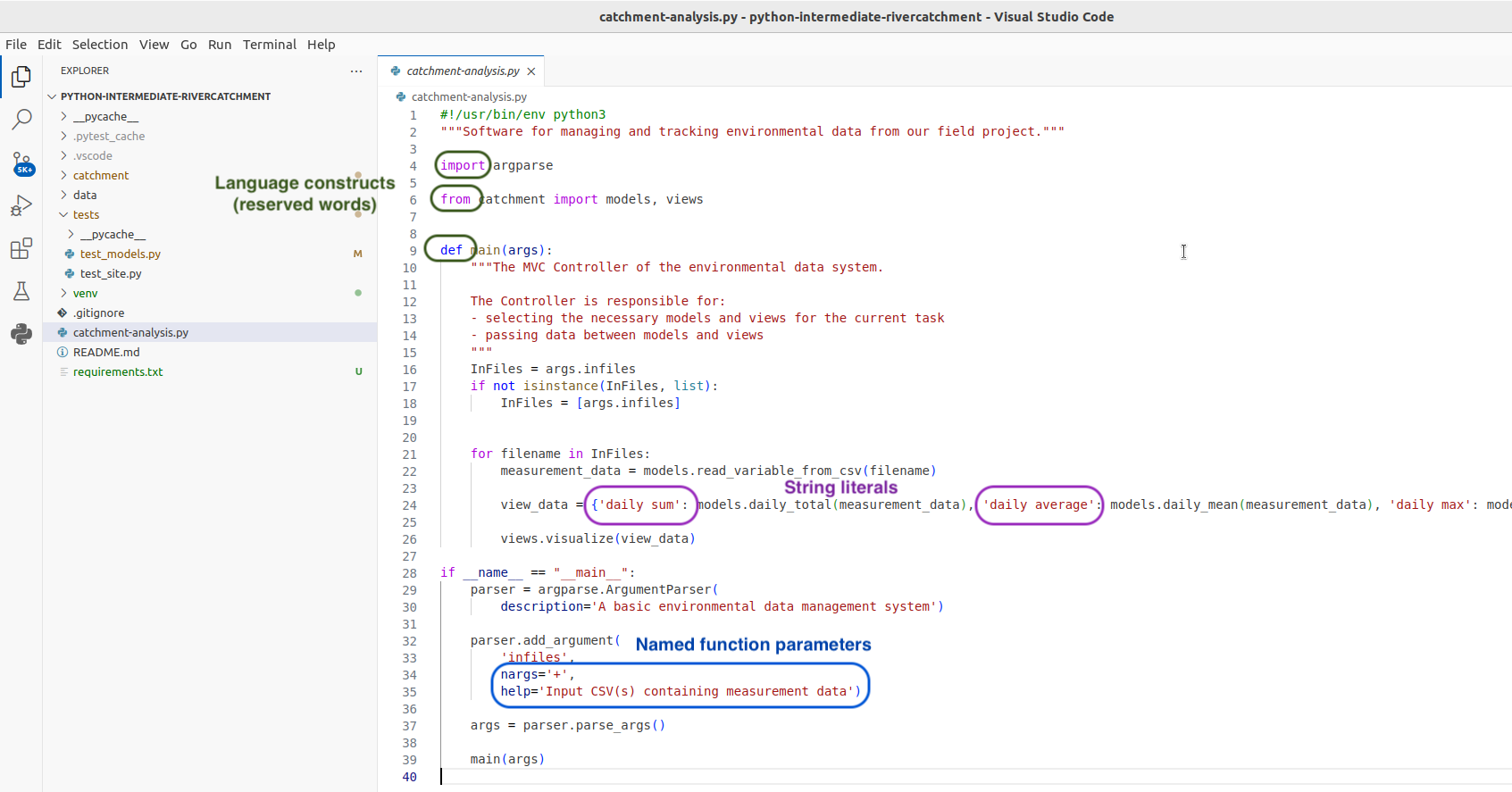
Code Completion
As you start typing code, VS Code will offer to complete some of the code for you in the form of an auto completion popup. This is a context-aware code completion feature that speeds up the process of coding (e.g. reducing typos and other common mistakes) by offering available variable names, functions from available packages, parameters of functions, hints related to syntax errors, etc.
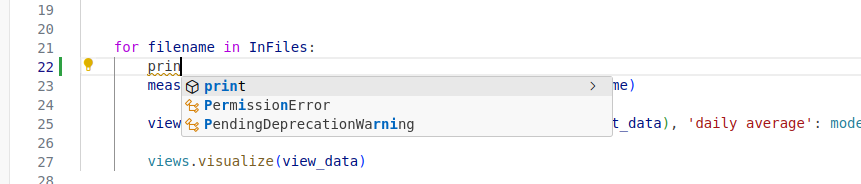
Code Definition & Documentation References
You will often need code reference information to help you code. VS Code shows this useful information, such as definitions of symbols (e.g. functions, parameters, classes, fields, and methods) and documentation references (docstrings for any symbol created in accordance with PEP-257) by means of quick popups and inline tooltips.
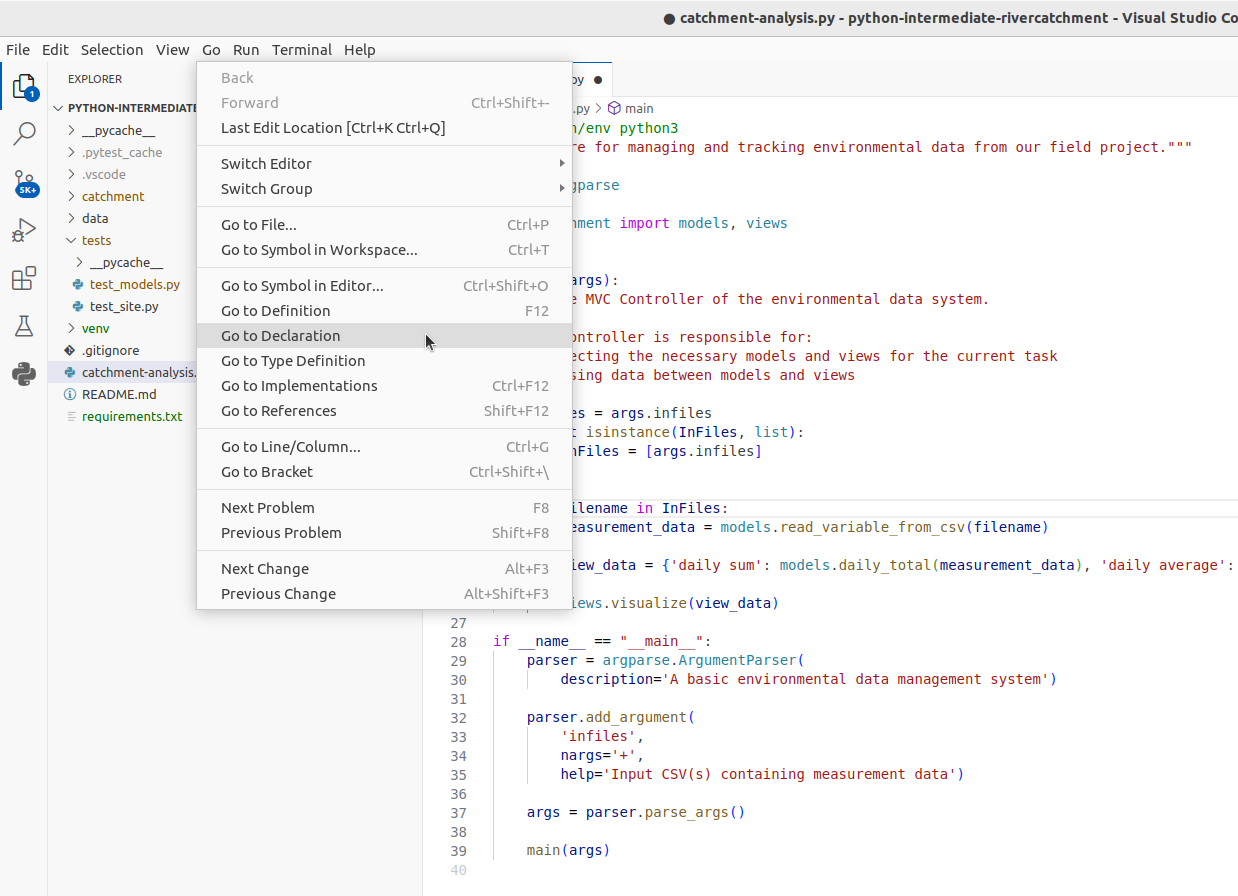
For a selected piece of code, you can access the original source code using the Go menu.
You can also access various code reference information by right-clicking on the code,
then selecting the Peek submenu. This includes:
- Peek Definition - where and how symbols (functions, parameters, classes, fields, and methods) are defined
- Peek Type Definition - type definition of variables, fields or any other symbols
- Peek References - where this code is referenced elsewhere in the program.
Code Search
You can search for a text string within a project, use different scopes to narrow your search process, use regular expressions for complex searches, include/exclude certain files from your search, find usages and occurrences. To find a search string in the whole project:
- From the main menu,
select
Edit | Find in Files ... -
Type your search string in the search field of the search panel. Alternatively, in the editor, highlight the string you want to find and press
Command-Shift-F(on Mac) orControl-Shift-F(on Windows). VS Code places the highlighted string into the search field of the search panel.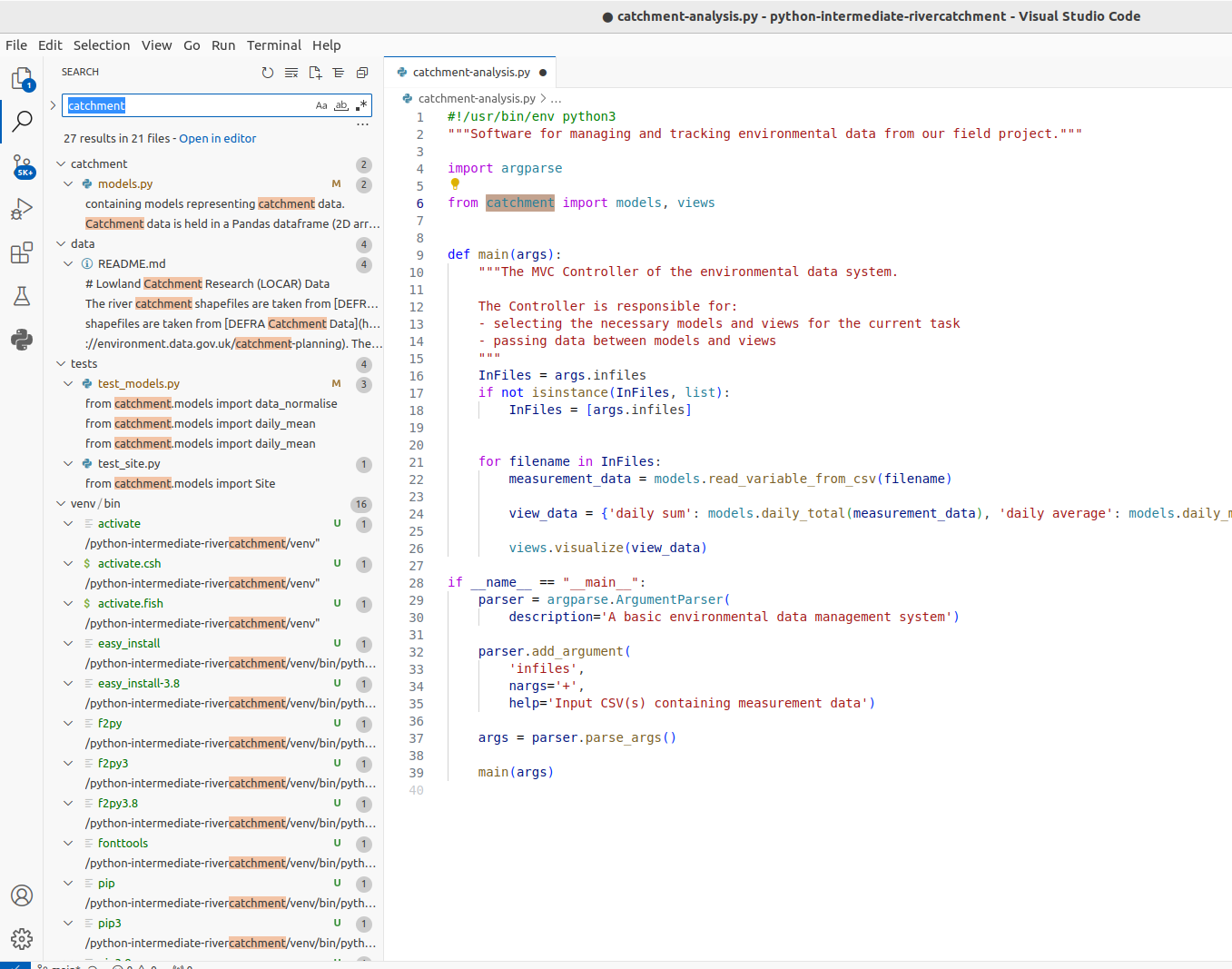 VS Code will list the search strings and all the files that contain them.
You can also group the files by folder/sub-folder names.
VS Code will list the search strings and all the files that contain them.
You can also group the files by folder/sub-folder names. - Check the results in the preview area of the dialog where you can replace the search string
or select another string,
or press
Command-Shift-F(on Mac) orControl-Shift-F(on Windows) again to start a new search. -
To see the list of occurrences in a separate tab, click the
Open New Search Editorbutton at the top of the search panel. The new find panel will appear as a new tab in the editor window; use this panel and its options to group the results, preview them, and work with them further.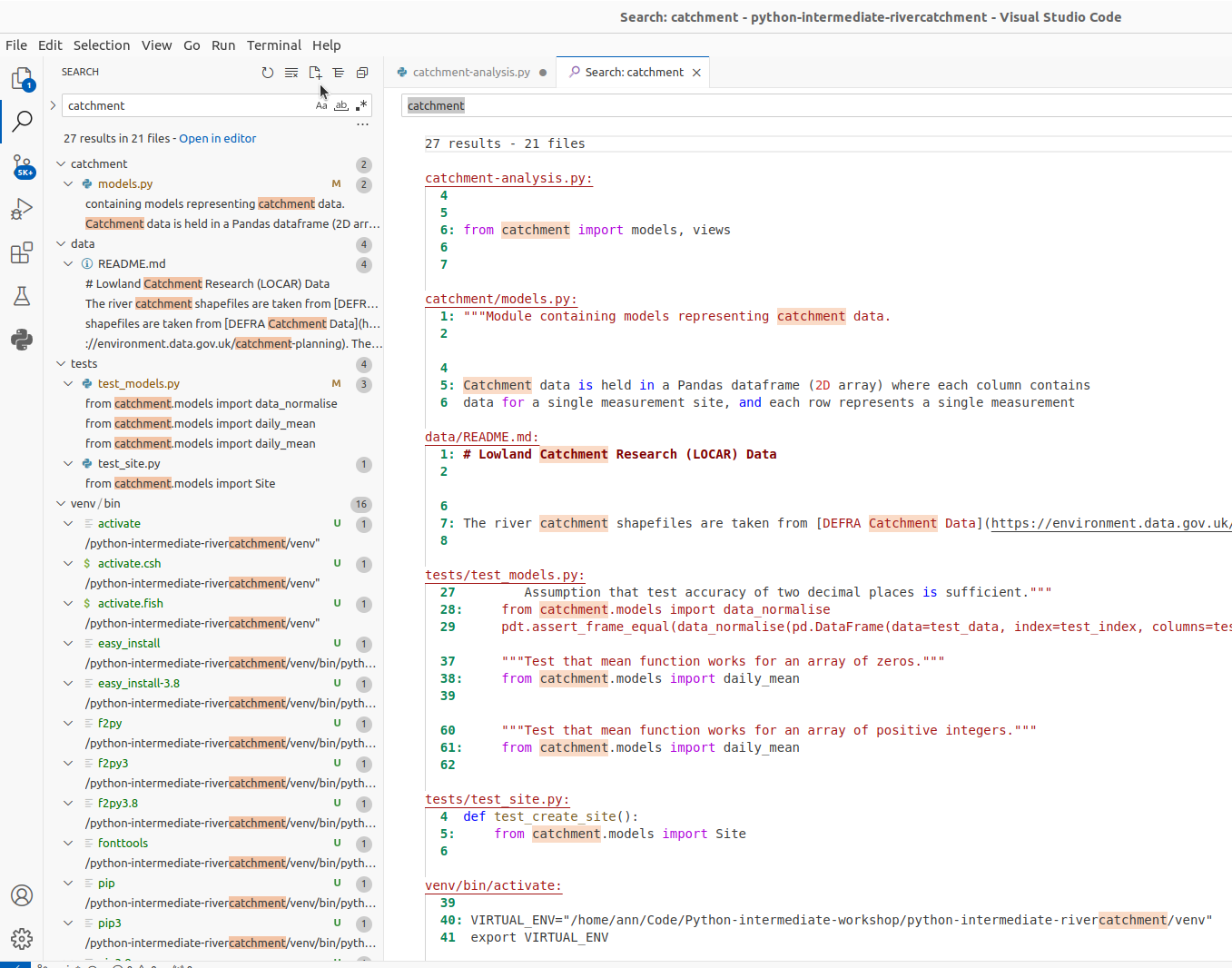
Version Control
VS Code supports a directory-based versioning model, which means that each project directory can be associated with a different version control system. Our project was already under Git version control and VS Code recognised it. It is also possible to add an unversioned project directory to version control directly from VS Code.
During this course, we will do all our version control commands from the command line but it is worth noting that VS Code supports a comprehensive subset of Git commands (i.e. it is possible to perform a set of common Git commands from VS Code but not all). A very useful version control feature in VS Code is graphically comparing changes you made locally to a file with the version of the file in a repository, a different commit version or a version in a different branch - this is something that cannot be done equally well from the text-based command line.
You can get a full documentation on VS Code’s built-in version control support online.
Running Scripts in VS Code
We have configured our environment and explored some of the most commonly used VS Code features
and are now ready to run our script from VS Code!
We could select the catchment-analysis.py file
in the VS Code project/file explorer, and select Run.
However this will not pass any command line arguments to the file,
and so does not work for us.
To run our script instead use the Run and Debug tab
and then select either of the Catchment-analysis: Rain and Catchment-analysis: River
configurations that we created earlier.
The script will run in a terminal window at the bottom of the IDE window
and should return either the rain statistical data,
or a ValueError exception, as we got before for the river data file.
This time, however, VS Code will helpfully enter debug mode,
open the module file where that error occurs
and display the error message below the appropriate line of code.
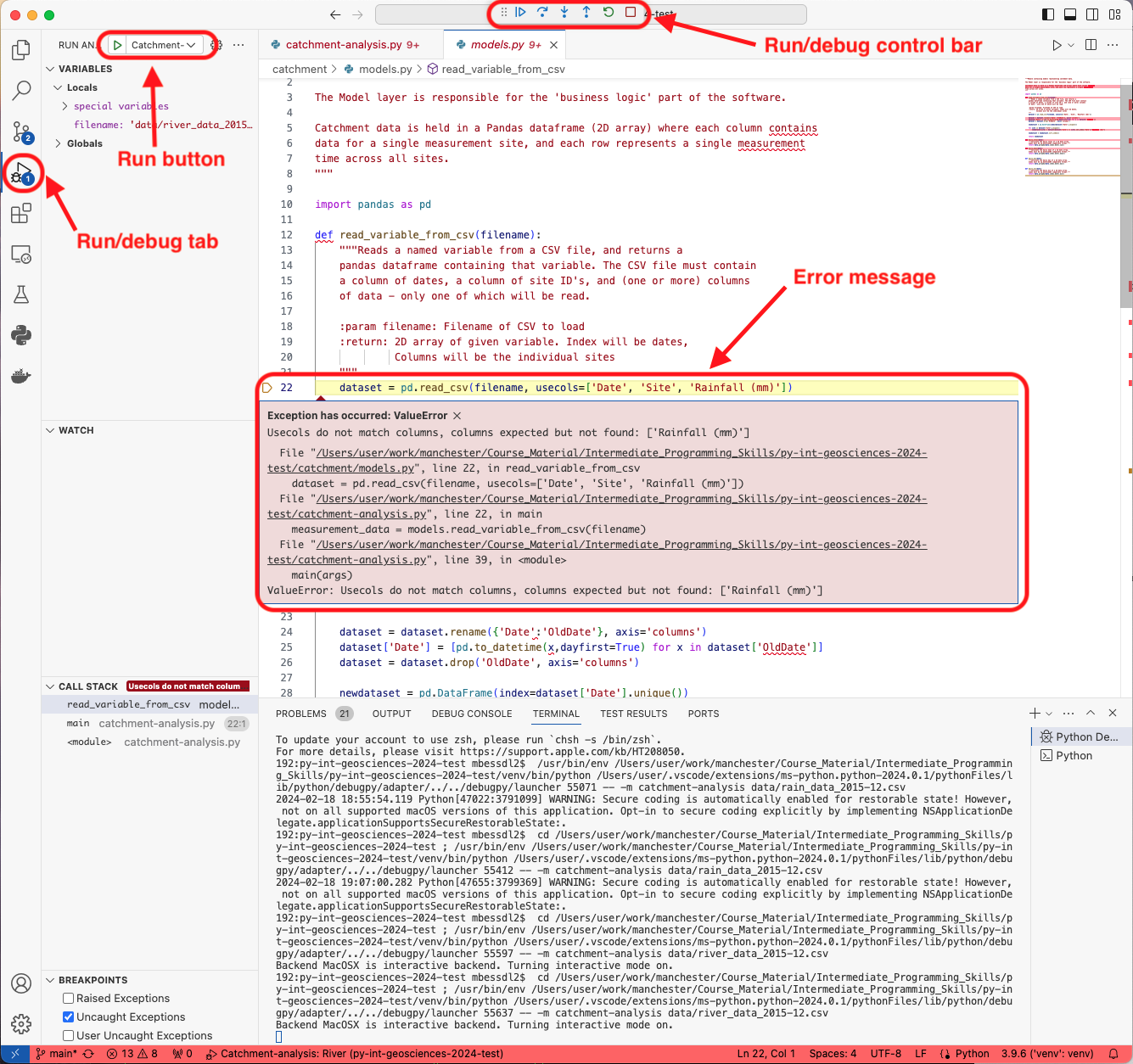
Note that VS Code has a control bar for the running program at the top of the window, you can press the red square to stop the program running, or exit debug mode.
We will get back to the river data error shortly - for now, the good thing is that we managed to set up our project for development both from the command line and VS Code and are getting the same outputs. Before we move on to fixing errors and writing more code, let’s have a look at the last set of tools for collaborative code development which we will be using in this course - Git and GitHub.
Key Points
An IDE is an application that provides a comprehensive set of facilities for software development, including syntax highlighting, code search and completion, version control, testing and debugging.
VS Code recognises virtual environments configured from the command line using
venvandpip.
Collaborative Software Development Using Git and GitHub
Overview
Teaching: 35 min
Exercises: 0 minQuestions
What are Git branches and why are they useful for code development?
What are some best practices when developing software collaboratively using Git?
Objectives
Commit changes in a software project to a local repository and publish them in a remote repository on GitHub
Create branches for managing different threads of code development
Learn to use feature branch workflow to effectively collaborate with a team on a software project
Introduction
So far we have checked out our software project from GitHub and used command line tools to configure a virtual environment for our project and run our code. We have also familiarised ourselves with VS Code - a graphical tool we will use for code development, testing and debugging. We are now going to start using another set of tools from the collaborative code development toolbox - namely, the version control system Git and code sharing platform GitHub. These two will enable us to track changes to our code and share it with others.
You may recall that we have already made some changes to our project locally -
we created a virtual environment in the directory called “venv”
and exported it to the requirements.txt file.
We should now decide which of those changes we want to check in and share with others in our team.
This is a typical software development workflow -
you work locally on code,
test it to make sure it works correctly and as expected,
then record your changes using version control
and share your work with others via a shared and centrally backed-up repository.
Firstly, let’s remind ourselves how to work with Git from the command line.
Git Refresher
Git is a version control system for tracking changes in computer files and coordinating work on those files among multiple people. It is primarily used for source code management in software development but it can be used to track changes in files in general - it is particularly effective for tracking text-based files (e.g. source code files, CSV, Markdown, HTML, CSS, Tex, etc. files).
Git has several important characteristics:
- support for non-linear development allowing you and your colleagues to work on different parts of a project concurrently,
- support for distributed development allowing for multiple people to be working on the same project (even the same file) at the same time,
- every change recorded by Git remains part of the project history and can be retrieved at a later date, so even if you make a mistake you can revert to a point before it.
The diagram below shows a typical software development lifecycle with Git (starting from making changes locally) and the commonly used commands to interact with different parts of the Git infrastructure, such as:
- working directory -
a local directory (including any subdirectories) where your project files live
and where you are currently working.
It is also known as the “untracked” area of Git.
Any changes to files will be marked by Git in the working directory.
If you make changes to the working directory and do not explicitly tell Git to save them -
you will likely lose those changes.
Using
git add filenamecommand, you tell Git to start tracking changes to filefilenamewithin your working directory. - staging area (index) -
once you tell Git to start tracking changes to files
(with
git add filenamecommand), Git saves those changes in the staging area on your local machine. Each subsequent change to the same file needs to be followed by anothergit add filenamecommand to tell Git to update it in the staging area. To see what is in your working directory and staging area at any moment (i.e. what changes is Git tracking), run the commandgit status. - local repository -
stored within the
.gitdirectory of your project locally, this is where Git wraps together all your changes from the staging area and puts them using thegit commitcommand. Each commit is a new, permanent snapshot (checkpoint, record) of your project in time, which you can share or revert to. - remote repository -
this is a version of your project that is hosted somewhere on the Internet
(e.g., on GitHub, GitLab or somewhere else).
While your project is nicely version-controlled in your local repository,
and you have snapshots of its versions from the past,
if your machine crashes - you still may lose all your work. Furthermore, you cannot
share or collaborate on this local work with others easily.
Working with a remote repository involves pushing your local changes remotely
(using
git push) and pulling other people’s changes from a remote repository to your local copy (usinggit fetchorgit pull) to keep the two in sync in order to collaborate (with a bonus that your work also gets backed up to another machine). Note that a common best practice when collaborating with others on a shared repository is to always do agit pullbefore agit push, to ensure you have any latest changes before you push your own.

Software development lifecycle with Git
Checking-in Changes to Our Project
Let’s check-in the changes we have done to our project so far. The first thing to do upon navigating into our software project’s directory root is to check the current status of our local working directory and repository.
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
requirements.txt
venv/
nothing added to commit but untracked files present (use "git add" to track)
As expected,
Git is telling us that we have some untracked files -
requirements.txt and directory “venv” -
present in our working directory which we have not
staged nor committed to our local repository yet.
You do not want to commit the newly created directory “venv” and share it with others
because this directory is specific to your machine and setup only
(i.e. it contains local paths to libraries on your system
that most likely would not work on any other machine).
You do, however, want to share requirements.txt with your team
as this file can be used to replicate the virtual environment on your collaborators’ systems.
To tell Git to intentionally ignore and not track certain files and directories,
you need to specify them in the .gitignore text file in the project root.
Our project already has .gitignore,
but in cases where you do not have it -
you can simply create it yourself.
In our case, we want to tell Git to ignore the “venv” directory
(and “.venv” as another naming convention for directories containing virtual environments)
and stop notifying us about it.
Edit your .gitignore file in VS Code
and add a line containing “venv/” and another one containing “.venv/”.
It does not matter much in this case where within the file you add these lines,
so let’s do it at the end.
Your .gitignore should look something like this:
# IDEs
.vscode/
.idea/
# Intermediate Coverage file
.coverage
# Output files
*.png
# Python runtime
*.pyc
*.egg-info
.pytest_cache
# Virtual environments
venv/
.venv/
You may notice that we are already not tracking certain files and directories
with useful comments about what exactly we are ignoring.
You may also notice that each line in .gitignore is actually a pattern,
so you can ignore multiple files that match a pattern
(e.g. “*.png” will ignore all PNG files in the current directory).
If you run the git status command now,
you will notice that Git has cleverly understood that
you want to ignore changes to the “venv” directory so it is not warning us about it any more.
However, it has now detected a change to .gitignore file that needs to be committed.
$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .gitignore
Untracked files:
(use "git add <file>..." to include in what will be committed)
requirements.txt
no changes added to commit (use "git add" and/or "git commit -a")
To commit the changes .gitignore and requirements.txt to the local repository,
we first have to add these files to staging area to prepare them for committing.
We can do that at the same time as:
$ git add .gitignore requirements.txt
Now we can commit them to the local repository with:
$ git commit -m "Initial commit of requirements.txt. Ignoring virtual env. folder."
Remember to use meaningful messages for your commits.
So far we have been working in isolation -
all the changes we have done are still only stored locally on our individual machines.
In order to share our work with others,
we should push our changes to the remote repository on GitHub.
Before we push our changes however, we should first do a git pull.
This is considered best practice, since any changes made to the repository -
notably by other people -
may impact the changes we are about to push.
This could occur, for example,
by two collaborators making different changes to the same lines in a file.
By pulling first, we are made aware of any changes made by others,
in particular if there are any conflicts between their changes and ours.
$ git pull
Now we’ve ensured our repository is synchronised with the remote one, we can now push our changes:
$ git push origin main
In the above command,
origin is an alias for the remote repository you used when cloning the project locally
(it is called that by convention and set up automatically by Git
when you run git clone remote_url command to replicate a remote repository locally);
main is the name of our main (and currently only) development branch.
GitHub Authentication/Authorisation Error
If, at this point (i.e. the first time you try to write to a remote repository on GitHub), you get a warning/error that HTTPS access is deprecated, or a personal access token is required, then you have cloned the repository using HTTPS and not SSH. You should revisit the instructions on setting up your GitHub for SSH and key pair authentication and can fix this from the command line by changing the remote repository’s HTTPS URL to its SSH equivalent:
$ git remote set-url origin git@github.com:<YOUR_GITHUB_USERNAME>/python-intermediate-inflammation.git
Git Remotes
Note that systems like Git allow us to synchronise work between any two or more copies of the same repository - the ones that are not located on your machine are “Git remotes” for you. In practice, though, it is easiest to agree with your collaborators to use one copy as a central hub (such as GitHub or GitLab), where everyone pushes their changes to. This also avoid risks associated with keeping the “central copy” on someone’s laptop. You can have more than one remote configured for your local repository, each of which generally is either read-only or read/write for you. Collaborating with others involves managing these remote repositories and pushing and pulling information to and from them when you need to share work.
Git - distributed version control system
From W3Docs (freely available)
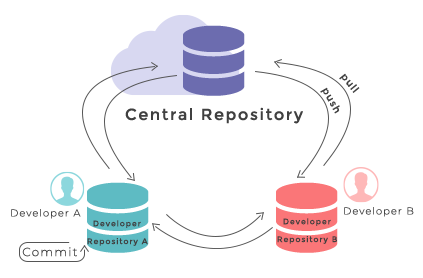
Git Branches
When we do git status,
Git also tells us that we are currently on the main branch of the project.
A branch is one version of your project (the files in your repository)
that can contain its own set of commits.
We can create a new branch,
make changes to the code which we then commit to the branch,
and, once we are happy with those changes,
merge them back to the main branch.
To see what other branches are available, do:
$ git branch
* main
At the moment, there’s only one branch (main)
and hence only one version of the code available.
When you create a Git repository for the first time,
by default you only get one version (i.e. branch) - main.
Let’s have a look at why having different branches might be useful.
Feature Branch Software Development Workflow
While it is technically OK to commit your changes directly to main branch,
and you may often find yourself doing so for some minor changes,
the best practice is to use a new branch for each separate and self-contained unit/piece of work
you want to add to the project.
This unit of work is also often called a feature
and the branch where you develop it is called a feature branch.
Each feature branch should have its own meaningful name -
indicating its purpose (e.g. “issue23-fix”).
If we keep making changes and pushing them directly to main branch on GitHub,
then anyone who downloads our software from there will get all of our work in progress -
whether or not it’s ready to use!
So, working on a separate branch for each feature you are adding is good for several reasons:
- it enables the main branch to remain stable while you and the team explore and test the new code on a feature branch,
- it enables you to keep the untested and not-yet-functional feature branch code under version control and backed up,
- you and other team members may work on several features at the same time independently from one another,
- if you decide that the feature is not working or is no longer needed - you can easily and safely discard that branch without affecting the rest of the code.
Branches are commonly used as part of a feature-branch workflow, shown in the diagram below.

Git feature branches
Adapted from Git Tutorial by sillevl (Creative Commons Attribution 4.0 International License)
In the software development workflow,
we typically have a main branch which is the version of the code that is
tested, stable and reliable.
Then, we normally have a development branch
(called develop or dev by convention)
that we use for work-in-progress code.
As we work on adding new features to the code,
we create new feature branches that first get merged into develop
after a thorough testing process.
After even more testing - develop branch will get merged into main.
The points when feature branches are merged to develop,
and develop to main
depend entirely on the practice/strategy established in the team.
For example, for smaller projects
(e.g. if you are working alone on a project or in a very small team),
feature branches sometimes get directly merged into main upon testing,
skipping the develop branch step.
In other projects,
the merge into main happens only at the point of making a new software release.
Whichever is the case for you, a good rule of thumb is -
nothing that is broken should be in main.
Creating Branches
Let’s create a develop branch to work on:
$ git branch develop
This command does not give any output,
but if we run git branch again,
without giving it a new branch name, we can see the list of branches we have -
including the new one we have just made.
$ git branch
develop
* main
The * indicates the currently active branch.
So how do we switch to our new branch?
We use the git switch command with the name of the branch:
$ git switch develop
Switched to branch 'develop'
Create and Switch to Branch Shortcut
A shortcut to create a new branch and immediately switch to it:
$ git switch -c develop
Updating Branches
If we start updating and committing files now,
the commits will happen on the develop branch
and will not affect the version of the code in main.
We add and commit things to develop branch in the same way as we do to main.
Let’s make a small modification to catchment/models.py in VS Code,
and, say, change the spelling of “2d” to “2D” in docstrings for functions
daily_mean(),
daily_max() and
daily_min() to see updating branches in action.
If we do:
$ git status
On branch develop
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: catchment/models.py
no changes added to commit (use "git add" and/or "git commit -a")
Git is telling us that we are on branch develop
and which tracked files have been modified in our working directory.
We can now add and commit the changes in the usual way.
$ git add catchment/models.py
$ git commit -m "Spelling fix"
Currently Active Branch
Remember,
addandcommitcommands always act on the currently active branch. You have to be careful and aware of which branch you are working with at any given moment.git statuscan help with that, and you will find yourself invoking it very often.
Pushing New Branch Remotely
We push the contents of the develop branch to GitHub
in the same way as we pushed the main branch.
However, as we have just created this branch locally,
it still does not exist in our remote repository.
You can check that in GitHub by listing all branches.
To push a new local branch remotely for the first time,
you could use the -u flag and the name of the branch you are creating and pushing to:
$ git push -u origin develop
Git Push With
-uFlagUsing the
-uswitch with thegit pushcommand is a handy shortcut for: (1) creating the new remote branch and (2) setting your local branch to automatically track the remote one at the same time. You need to use the-uswitch only once to set up that association between your branch and the remote one explicitly. After that you could simply usegit pushwithout specifying the remote repository, if you wished so. We still prefer to explicitly state this information in commands.
Let’s confirm that the new branch develop now exist remotely on GitHub too.
From the < > Code tab in your repository in GitHub,
click the branch dropdown menu (currently showing the default branch main).
You should see your develop branch in the list too.
Now the others can check out the develop branch too and continue to develop code on it.
After the initial push of the new branch,
each next time we push to it in the usual manner (i.e. without the -u switch):
$ git push origin develop
What is the Relationship Between Originating and New Branches?
It’s natural to think that new branches have a parent/child relationship with their originating branch, but in actual Git terms, branches themselves do not have parents but single commits do. Any commit can have zero parents (a root, or initial, commit), one parent (a regular commit), or multiple parents (a merge commit), and using this structure, we can build a ‘view’ of branches from a set of commits and their relationships. A common way to look at it is that Git branches are really only lightweight, movable pointers to commits. So as a new commit is added to a branch, the branch pointer is moved to the new commit.
What this means is that when you accomplish a merge between two branches, Git is able to determine the common ‘commit ancestor’ through the commits in a ‘branch’, and use that common ancestor to determine which commits need to be merged onto the destination branch. It also means that, in theory, you could merge any branch with any other at any time… although it may not make sense to do so!
Merging Into Main Branch
Once you have tested your changes on the develop branch,
you will want to merge them onto the main branch.
To do so, make sure you have committed all your changes on the develop branch and then switch to main:
$ git switch main
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
To merge the develop branch on top of main do:
$ git merge develop
Updating 05e1ffb..be60389
Fast-forward
catchment/models.py | 6 +++---
1 files changed, 3 insertions(+), 3 deletions(-)
If there are no conflicts,
Git will merge the branches without complaining
and replay all commits from develop on top of the last commit from main.
If there are merge conflicts
(e.g. a team collaborator modified the same portion of the same file you are working on
and checked in their changes before you),
the particular files with conflicts will be marked
and you will need to resolve those conflicts
and commit the changes before attempting to merge again.
Since we have no conflicts, we can now push the main branch to the remote repository:
git push origin main
All Branches Are Equal
In Git, all branches are equal - there is nothing special about the
mainbranch. It is called that by convention and is created by default, but it can also be called something else. A good example isgh-pagesbranch which is often the source branch for website projects hosted on GitHub (rather thanmain).
Keeping Main Branch Stable
Good software development practice is to keep the
mainbranch stable while you and the team develop and test new functionalities on feature branches (which can be done in parallel and independently by different team members). The next step is to merge feature branches onto thedevelopbranch, where more testing can occur to verify that the new features work well with the rest of the code (and not just in isolation). We talk more about different types of code testing in one of the following episodes.
Key Points
A branch is one version of your project that can contain its own set of commits.
Feature branches enable us to develop / explore / test new code features without affecting the stable
maincode.
Python Code Style Conventions
Overview
Teaching: 20 min
Exercises: 15 minQuestions
Why should you follow software code style conventions?
Who is setting code style conventions?
What code style conventions exist for Python?
Objectives
Understand the benefits of following community coding conventions
Introduction
We now have all the tools we need for software development and are raring to go. But before you dive into writing some more code and sharing it with others, ask yourself what kind of code should you be writing and publishing? It may be worth spending some time learning a bit about Python coding style conventions to make sure that your code is consistently formatted and readable by yourself and others.
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” - Martin Fowler, British software engineer, author and international speaker on software development
Python Coding Style Guide
One of the most important things we can do to make sure our code is readable by others (and ourselves a few months down the line) is to make sure that it is descriptive, cleanly and consistently formatted and uses sensible, descriptive names for variable, function and module names. In order to help us format our code, we generally follow guidelines known as a style guide. A style guide is a set of conventions that we agree upon with our colleagues or community, to ensure that everyone contributing to the same project is producing code which looks similar in style. While a group of developers may choose to write and agree upon a new style guide unique to each project, in practice many programming languages have a single style guide which is adopted almost universally by the communities around the world. In Python, although we do have a choice of style guides available, the PEP 8 style guide is most commonly used. PEP here stands for Python Enhancement Proposals; PEPs are design documents for the Python community, typically specifications or conventions for how to do something in Python, a description of a new feature in Python, etc.
Style consistency
One of the key insights from Guido van Rossum, one of the PEP 8 authors, is that code is read much more often than it is written. Style guidelines are intended to improve the readability of code and make it consistent across the wide spectrum of Python code. Consistency with the style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important. However, know when to be inconsistent - sometimes style guide recommendations are just not applicable. When in doubt, use your best judgment. Look at other examples and decide what looks best. And don’t hesitate to ask!
As we have already covered in the
episode on VS Code IDE,
VS Code highlights the language constructs (reserved words)
and syntax errors to help us with coding. We would also like VS Code to give us recommendations
for formatting the code (for example using
the PEP 8 style guide above). To do this we will need to install another extension.
(See the episode on VS Code IDE if you need a reminder on how to add extensions.)
On ‘Activity Bar’, on the left hand side of the VS Code interface, click on the Extensions Tab,
so that we can add the an extension called Flake8 for VS Code.
In the search text box, type Flake8. Select the Flake8 extension, as shown in the following figure,
and click the blue install button. Note that other Python style guide extensions are available.
Another useful one at the time of writing, is one called Pylint.
VS Code will now give us recommendations for formatting the code - these recommendations are mostly taken from the PEP 8 style guide.
A full list of style guidelines for this style is available from the PEP 8 website; here we highlight a few.
Indentation
Python is a kind of language that uses indentation as a way of grouping statements that belong to a particular block of code. Spaces are the recommended indentation method in Python code. The guideline is to use 4 spaces per indentation level - so 4 spaces on level one, 8 spaces on level two and so on. Many people prefer the use of tabs to spaces to indent the code for many reasons (e.g. additional typing, easy to introduce an error by missing a single space character, accessibility for individuals using screen readers, etc.) and do not follow this guideline. Whether you decide to follow this guideline or not, be consistent and follow the style already used in the project.
Indentation in Python 2 vs Python 3
Python 2 allowed code indented with a mixture of tabs and spaces. Python 3 disallows mixing the use of tabs and spaces for indentation. Whichever you choose, be consistent throughout the project.
VS Code has built-in support for converting tab indentation to spaces
“under the hood” for Python code in order to conform to PEP8.
So, you can type a tab character and VS Code will automatically convert it to 4 spaces.
You can control the amount of spaces that VS Code uses to replace one tab character
or you can decide to keep the tab character altogether and prevent automatic conversion.
You can modify these settings by selecting File>Preferences>Settings on Windows,
or Code>Settings...>Settings on Mac,
and then searching on editor tab size, editor indent size and editor insert spaces
You can also tell the editor to show non-printable characters
if you are ever unsure what character exactly is being used
by again selecting File>Preferences>Settings on Windows,
or Code>Settings...>Settings on Mac,
and search on Render Whitespace.
Select all from the drop-down editbox menu.
There are more complex rules on indenting single units of code that continue over several lines,
e.g. function, list or dictionary definitions can all take more than one line.
The preferred way of wrapping such long lines is
by using Python’s implied line continuation inside delimiters such as
parentheses (()),
brackets ([])
and braces ({}),
or a hanging indent.
# Add an extra level of indentation (extra 4 spaces) to distinguish arguments from the rest of the code that follows
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# Aligned with opening delimiter
foo = long_function_name(var_one, var_two,
var_three, var_four)
# Use hanging indents to add an indentation level like paragraphs of text where all the lines in a paragraph are
# indented except the first one
foo = long_function_name(
var_one, var_two,
var_three, var_four)
# Using hanging indent again, but closing bracket aligned with the first non-blank character of the previous line
a_long_list = [
[[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[0.33, 0.66, 1], [0.66, 0.83, 1], [0.77, 0.88, 1]]
]
# Using hanging indent again, but closing bracket aligned with the start of the multiline contruct
a_long_list2 = [
1,
2,
3,
# ...
79
]
More details on good and bad practices for continuation lines can be found in PEP 8 guideline on indentation.
Maximum Line Length
All lines should be up to 80 characters long;
for lines containing comments or docstrings (to be covered later)
the line length limit should be 73 -
see this discussion
for reasoning behind these numbers.
Some teams strongly prefer a longer line length,
and seemed to have settled on the length of 100.
Long lines of code can be broken over multiple lines
by wrapping expressions in delimiters,
as mentioned above (preferred method),
or using a backslash (\) at the end of the line
to indicate line continuation (slightly less preferred method).
# Using delimiters ( ) to wrap a multi-line expression
if (a == True and
b == False):
# Using a backslash (\) for line continuation
if a == True and \
b == False:
Should a Line Break Before or After a Binary Operator?
Lines should break before binary operators so that the operators do not get scattered across different columns on the screen. In the example below, the eye does not have to do the extra work to tell which items are added and which are subtracted:
# PEP 8 compliant - easy to match operators with operands
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
Blank Lines
Top-level function and class definitions should be surrounded with two blank lines. Method definitions inside a class should be surrounded by a single blank line. You can use blank lines in functions, sparingly, to indicate logical sections.
Whitespace in Expressions and Statements
Avoid extraneous whitespace in the following situations:
- immediately inside parentheses, brackets or braces
# PEP 8 compliant: my_function(colour[1], {id: 2}) # Not PEP 8 compliant: my_function( colour[ 1 ], { id: 2 } ) - Immediately before a comma,
semicolon,
or colon
(unless doing slicing where the colon acts like a binary operator
in which case it should should have equal amounts of whitespace on either side)
# PEP 8 compliant: if x == 4: print(x, y); x, y = y, x # Not PEP 8 compliant: if x == 4 : print(x , y); x , y = y, x - Immediately before the open parenthesis that starts the argument list of a function call
# PEP 8 compliant: my_function(1) # Not PEP 8 compliant: my_function (1) - Immediately before the open parenthesis that starts an indexing or slicing
# PEP 8 compliant: my_dct['key'] = my_lst[id] first_char = my_str[:, 1] # Not PEP 8 compliant: my_dct ['key'] = my_lst [id] first_char = my_str [:, 1] - More than one space around an assignment (or other) operator to align it with another
# PEP 8 compliant: x = 1 y = 2 student_loan_interest = 3 # Not PEP 8 compliant: x = 1 y = 2 student_loan_interest = 3 - Avoid trailing whitespace anywhere - it is not necessary and can cause errors.
For example, if you use backslash (
\) for continuation lines and have a space after it, the continuation line will not be interpreted correctly. - Surround these binary operators with a single space on either side: assignment (=), augmented assignment (+=, -= etc.), comparisons (==, <, >, !=, <>, <=, >=, in, not in, is, is not), booleans (and, or, not).
- Don’t use spaces around the = sign
when used to indicate a keyword argument assignment
or to indicate a default value for an unannotated function parameter
# PEP 8 compliant use of spaces around = for variable assignment axis = 'x' angle = 90 size = 450 name = 'my_graph' # PEP 8 compliant use of no spaces around = for keyword argument assignment in a function call my_function( 1, 2, axis=axis, angle=angle, size=size, name=name)
String Quotes
In Python, single-quoted strings and double-quoted strings are the same. PEP8 does not make a recommendation for this apart from picking one rule and consistently sticking to it. When a string contains single or double quote characters, use the other one to avoid backslashes in the string as it improves readability.
Naming Conventions
There are a lot of different naming styles in use, including:
- lower_case_with_underscores (or snake_case)
- UPPER_CASE_WITH_UNDERSCORES
- CapitalisedWords (or PascalCase) (note: when using acronyms in CapitalisedWords, capitalise all the letters of the acronym, e.g HTTPServerError)
- camelCase (differs from CapitalisedWords/PascalCase by the initial lowercase character)
- Capitalised_Words_With_Underscores
As with other style guide recommendations - consistency is key. Follow the one already established in the project, if there is one. If there isn’t, follow any standard language style (such as PEP8 for Python). Failing that, just pick one, document it and stick to it.
Some things to be wary of when naming things in the code:
- Avoid any names that could cause confusion (e.g. lower case
lis hard to distinguish from a1(one), ‘O’ (uppercase o) from a ‘0’ (zero), ‘I’ (uppercase i) from ‘l’ (lowercase L)). - Avoid using non-ASCII (e.g. Unicode) characters for identifiers as these can trip up software that does not support Unicode.
- If your audience is international and English is the common language, try to use English words for identifiers and comments whenever possible but try to avoid abbreviations/local slang as they may not be understood by everyone. Also consider sticking with either ‘American’ or ‘British’ English spellings and try not to mix the two.
Function, Variable, Class, Module, Package Naming in Python
- Function and variable names should use lower_case_with_underscores
- Avoid single character names in almost all instances.
- Variable names should tell you what they store, and not just the type (e.g.
name_of_patientis better thanstring)- Function names should tell you what the function does.
- Class names should use the CapitalisedWords convention.
- Modules should have short, all-lowercase names. Underscores can be used in the module name if it improves readability.
- Packages should also have short, all-lowercase names, although the use of underscores is discouraged.
A more detailed guide on naming functions, modules, classes and variables is available from PEP8.
Comments
Comments allow us to provide the reader with additional information on what the code does - reading and understanding source code is slow, laborious and can lead to misinterpretation, plus it is always a good idea to keep others in mind when writing code. A good rule of thumb is to assume that someone will always read your code at a later date, and this includes a future version of yourself. It can be easy to forget why you did something a particular way in six months’ time. Write comments as complete sentences and in English unless you are 100% sure the code will never be read by people who don’t speak your language.
The Good, the Bad, and the Ugly Comments
As a side reading, check out the ‘Putting comments in code: the good, the bad, and the ugly’ blogpost. Remember - a comment should answer the ‘why’ question”. Occasionally the “what” question. The “how” question should be answered by the code itself.
Block comments generally apply to some (or all) code that follows them,
and are indented to the same level as that code.
Each line of a block comment starts with a # and a single space
(unless it is indented text inside the comment).
def fahr_to_cels(fahr):
# Block comment example: convert temperature in Fahrenheit to Celsius
cels = (fahr + 32) * (5 / 9)
return cels
An inline comment is a comment on the same line as a statement.
Inline comments should be separated by at least two spaces from the statement.
They should start with a # and a single space and should be used sparingly.
def fahr_to_cels(fahr):
cels = (fahr + 32) * (5 / 9) # Inline comment example: convert temperature in Fahrenheit to Celsius
return cels
Python doesn’t have any multi-line comments, like you may have seen in other languages like C++ or Java. However, there are ways to do it using docstrings as we’ll see in a moment.
The reader should be able to understand a single function or method from its code and its comments, and should not have to look elsewhere in the code for clarification. The kind of things that need to be commented are:
- Why certain design or implementation decisions were adopted, especially in cases where the decision may seem counter-intuitive
- The names of any algorithms or design patterns that have been implemented
- The expected format of input files or database schemas
However, there are some restrictions. Comments that simply restate what the code does are redundant, and comments must be accurate and updated with the code, because an incorrect comment causes more confusion than no comment at all.
Exercise: Improve Code Style of Our Project
Let’s look at improving the coding style of our project. First, from the project root, use
git switchto create a new feature branch calledstyle-fixesfrom our develop branch. (Note that at this pointdevelopandmainbranches are pointing at the same commit so it does not really matter which one we are branching off - in real collaborative software development environments, you’d likely be expected to branch offdevelopas it would contain the latest code developed by your team.)$ git switch develop $ git switch -c style-fixesNext look at the
catchment-analysis.pyfile in VS Code and identify where the above guidelines have not been followed. Fix the discovered inconsistencies and commit them to the feature branch.Solution
Modify
catchment-analysis.pyfrom VS Code, which is helpfully marking inconsistencies with coding guidelines by underlying them. There are a few things to fix incatchment-analysis.py, for example:
Line 24 in
catchment-analysis.pyis too long and not very readable A better style would be to use multiple lines and hanging indent, with the closing brace `}’ aligned either with the first non-whitespace character of the last line of list or the first character of the line that starts the multiline construct or simply moved to the end of the previous line. All three acceptable modifications are shown below.# Using hanging indent, with the closing '}' aligned with the first non-blank character of the previous line view_data = {'daily sum': models.daily_total(measurement_data), 'daily average': models.daily_mean(measurement_data), 'daily max': models.daily_max(measurement_data), 'daily min': models.daily_min(measurement_data)}# Using hanging indent with the, closing '}' aligned with the start of the multiline contruct view_data = { 'daily sum': models.daily_total(measurement_data), 'daily average': models.daily_mean(measurement_data), 'daily max': models.daily_max(measurement_data), 'daily min': models.daily_min(measurement_data) }# Using hanging indent where all the lines of the multiline contruct are indented except the first one view_data = { 'daily sum': models.daily_total(measurement_data), 'daily average': models.daily_mean(measurement_data), 'daily max': models.daily_max(measurement_data), 'daily min': models.daily_min(measurement_data)}Variable ‘InFiles’ in
catchment-analysis.pyuses CapitalisedWords naming convention which is recommended for class names but not variable names. By convention, variable names should be in lowercase with optional underscores so you should rename the variable ‘InFiles’ to, e.g., ‘infiles’ or ‘in_files’.There is an extra blank line on line 20 in
catchment-analysis.py. Normally, you should not use blank lines in the middle of the code unless you want to separate logical units - in which case only one blank line is used. Note how VS Code is warning us by underlining the whole line.Only one blank line after the end of definition of function
mainand the rest of the code on line 30 incatchment-analysis.py- should be two blank lines (PEP8 recommends surrounding top-level function (and class) definitions with two blank lines). Note how VS Code is warning us by underlining the whole line.Finally, let’s add and commit our changes to the feature branch. We will check the status of our working directory first.
$ git statusOn branch style-fixes Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: catchment-analysis.py no changes added to commit (use "git add" and/or "git commit -a")Git tells us we are on branch
style-fixesand that we have unstaged and uncommited changes tocatchment-analysis.py. Let’s commit them to the local repository.$ git add catchment-analysis.py $ git commit -m "Code style fixes."
Optional Exercise: Improve Code Style of Your Other Python Projects
If you have another Python project, check to which extent it conforms to PEP8 coding style.
Documentation Strings aka Docstrings
If the first thing in a function is a string that is not assigned to a variable, that string is attached to the function as its documentation. Consider the following code implementing function for calculating the nth Fibonacci number:
def fibonacci(n):
"""Calculate the nth Fibonacci number.
A recursive implementation of Fibonacci array elements.
:param n: integer
:raises ValueError: raised if n is less than zero
:returns: Fibonacci number
"""
if n < 0:
raise ValueError('Fibonacci is not defined for N < 0')
if n == 0:
return 0
if n == 1:
return 1
return fibonacci(n - 1) + fibonacci(n - 2)
Note here we are explicitly documenting our input variables,
what is returned by the function,
and also when the ValueError exception is raised.
Along with a helpful description of what the function does,
this information can act as a contract for readers to understand what to expect in terms of
behaviour when using the function,
as well as how to use it.
A special comment string like this is called a docstring.
We do not need to use triple quotes when writing one,
but if we do, we can break the text across multiple lines.
Docstrings can also be used at the start of a Python module
(a file containing a number of Python functions)
or at the start of a Python class
(containing a number of methods)
to list their contents as a reference.
You should not confuse docstrings with comments though -
docstrings are context-dependent and should only be used in specific locations
(e.g. at the top of a module and immediately after class and def keywords as mentioned).
Using triple quoted strings in locations where
they will not be interpreted as docstrings
or using triple quotes as a way to ‘quickly’ comment out an entire block of code
is considered bad practice.
In our example case, we used the
Sphynx/ReadTheDocs docstring style
formatting for the param, raises and returns - other docstring formats exist as well.
Python PEP 257 - Recommendations for Docstrings
PEP 257 is another one of Python Enhancement Proposals and this one deals with docstring conventions to standardise how they are used. For example, on the subject of module-level docstrings, PEP 257 says:
The docstring for a module should generally list the classes, exceptions and functions (and any other objects) that are exported by the module, with a one-line summary of each. (These summaries generally give less detail than the summary line in the object's docstring.) The docstring for a package (i.e., the docstring of the package's `__init__.py` module) should also list the modules and subpackages exported by the package.Note that
__init__.pyfile used to be a required part of a package (pre Python 3.3) where a package was typically implemented as a directory containing an__init__.pyfile which got implicitly executed when a package was imported.
So, at the beginning of a module file we can just add
a docstring explaining the nature of a module.
For example, if fibonacci() was included in a module with other functions,
our module could have at the start of it:
"""A module for generating numerical sequences of numbers that occur in nature.
Functions:
fibonacci - returns the Fibonacci number for a given integer
golden_ratio - returns the golden ratio number to a given Fibonacci iteration
...
"""
...
The docstring for a function or a module
is returned when calling the help function and passing its name -
for example from the interactive Python console/terminal available from the command line
or when rendering code documentation online
(e.g. see Python documentation).
VS Code also displays the docstring for a function/module
in a little help popup window when using tab-completion.
help(fibonacci)
Exercise: Fix the Docstrings
Look into
models.pyin VS Code and improve docstrings for functionsdaily_mean,daily_min,daily_max. Commit those changes to feature branchstyle-fixes.Solution
For example, the improved docstrings for the above functions would contain explanations for parameters and return values.
def daily_total(data): """Calculate the daily total of a 2D data array. :param data: A 2D Pandas data frame with measurement data. Index must be np.datetime64 compatible format. Columns are measurement sites. :returns: A 2D Pandas data frame with total values of the measurements for each day. """ return data.groupby(data.index.date).sum()def daily_mean(data): """Calculate the daily mean of a 2D data array. :param data: A 2D Pandas data frame with measurement data. Index must be np.datetime64 compatible format. Columns are measurement sites. :returns: A 2D Pandas data frame with mean values of the measurements for each day. """ return data.groupby(data.index.date).mean()def daily_min(data): """Calculate the daily minimum of a 2D data array. :param data: A 2D Pandas data frame with measurement data. Index must be np.datetime64 compatible format. Columns are measurement sites. :returns: A 2D Pandas data frame with minimum values of the measurements for each day. """ return data.groupby(data.index.date).min()def daily_max(data): """Calculate the daily maximum of a 2D data array. :param data: A 2D Pandas data frame with measurement data. Index must be np.datetime64 compatible format. Columns are measurement sites. :returns: A 2D Pandas data frame with maximum values of the measurements for each day. """ return data.groupby(data.index.date).max()Once we are happy with modifications, as usual before staging and commit our changes, we check the status of our working directory:
$ git statusOn branch style-fixes Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: catchment/models.py no changes added to commit (use "git add" and/or "git commit -a")As expected, Git tells us we are on branch
style-fixesand that we have unstaged and uncommited changes tocatchment/models.py. Let’s commit them to the local repository.$ git add catchment/models.py $ git commit -m "Docstring improvements."
In the previous exercises, we made some code improvements on feature branch style-fixes.
We have committed our changes locally but
have not pushed this branch remotely for others to have a look at our code
before we merge it onto the develop branch.
Let’s do that now, namely:
- push
style-fixesto GitHub - merge
style-fixesintodevelop(once we are happy with the changes) - push updates to
developbranch to GitHub (to keep it up to date with the latest developments) - finally, merge
developbranch into the stablemainbranch
Here is a set commands that will achieve the above set of actions
(remember to use git status often in between other Git commands
to double check which branch you are on and its status):
$ git push -u origin style-fixes
$ git switch develop
$ git merge style-fixes
$ git push origin develop
$ git switch main
$ git merge develop
$ git push origin main
Typical Code Development Cycle
What you’ve done in the exercises in this episode mimics a typical software development workflow - you work locally on code on a feature branch, test it to make sure it works correctly and as expected, then record your changes using version control and share your work with others via a centrally backed-up repository. Other team members work on their feature branches in parallel and similarly share their work with colleagues for discussions. Different feature branches from around the team get merged onto the development branch, often in small and quick development cycles. After further testing and verifying that no code has been broken by the new features - the development branch gets merged onto the stable main branch, where new features finally resurface to end-users in bigger “software release” cycles.
Key Points
Always assume that someone else will read your code at a later date, including yourself.
Community coding conventions help you create more readable software projects that are easier to contribute to.
Python Enhancement Proposals (or PEPs) describe a recommended convention or specification for how to do something in Python.
Style checking to ensure code conforms to coding conventions is often part of IDEs.
Consistency with the style guide is important - whichever style you choose.
Verifying Code Style Using Linters
Overview
Teaching: 15 min
Exercises: 10 minQuestions
What tools can help with maintaining a consistent code style?
How can we automate code style checking?
Objectives
Use code linting tools to verify a program’s adherence to a Python coding style convention.
Verifying Code Style Using Linters
We’ve seen how we can use VS Code to help us format our Python code in a consistent style.
This aids reusability,
since consistent-looking code is easier to modify
since it’s easier to read and understand.
We can also use tools,
called code linters,
to identify consistency issues in a report-style.
Linters analyse source code to identify and report on stylistic and even programming errors.
Let’s look at a very well used one of these called pylint.
First, let’s ensure we are on the style-fixes branch once again.
$ git switch style-fixes
Pylint is just a Python package so we can install it in our virtual environment using:
$ python3 -m pip install pylint
We should also update our requirements.txt with this new addition:
$ python3 -m pip freeze > requirements.txt
Pylint is a command-line tool that can help our code in many ways:
- Check PEP8 compliance: whilst in-IDE context-sensitive highlighting such as that provided via VS Code (using an extension such as Flake8, which we installed in the previous episode) helps us stay consistent with PEP8 as we write code, this tool provides a full report
- Perform basic error detection: Pylint can look for certain Python type errors
- Check variable naming conventions: Pylint often goes beyond PEP8 to include other common conventions, such as naming variables outside of functions in upper case
- Customisation: you can specify which errors and conventions you wish to check for, and those you wish to ignore
Pylint can also identify code smells.
How Does Code Smell?
There are many ways that code can exhibit bad design whilst not breaking any rules and working correctly. A code smell is a characteristic that indicates that there is an underlying problem with source code, e.g. large classes or methods, methods with too many parameters, duplicated statements in both if and else blocks of conditionals, etc. They aren’t functional errors in the code, but rather are certain structures that violate principles of good design and impact design quality. They can also indicate that code is in need of maintenance and refactoring.
The phrase has its origins in Chapter 3 “Bad smells in code” by Kent Beck and Martin Fowler in Fowler, Martin (1999). Refactoring. Improving the Design of Existing Code. Addison-Wesley. ISBN 0-201-48567-2.
Pylint recommendations are given as warnings or errors,
and Pylint also scores the code with an overall mark.
We can look at a specific file (e.g. catchment-analysis.py),
or a module (e.g. catchment).
Let’s look at our catchment module and code inside it (namely models.py and views.py).
From the project root do:
$ pylint catchment
You should see an output similar to the following:
************* Module catchment.models
catchment/models.py:5:82: C0303: Trailing whitespace (trailing-whitespace)
catchment/models.py:6:66: C0303: Trailing whitespace (trailing-whitespace)
catchment/models.py:34:0: C0305: Trailing newlines (trailing-newlines)
************* Module catchment.views
catchment/views.py:4:0: W0611: Unused numpy imported as np (unused-import)
------------------------------------------------------------------
Your code has been rated at 8.00/10 (previous run: 8.00/10, +0.00)
Your own outputs of the above commands may vary depending on how you have implemented and fixed the code in previous exercises and the coding style you have used.
The five digit codes, such as C0303, are unique identifiers for warnings,
with the first character indicating the type of warning.
There are five different types of warnings that Pylint looks for,
and you can get a summary of them by doing:
$ pylint --long-help
Near the end you’ll see:
Output:
Using the default text output, the message format is :
MESSAGE_TYPE: LINE_NUM:[OBJECT:] MESSAGE
There are 5 kind of message types :
* (C) convention, for programming standard violation
* (R) refactor, for bad code smell
* (W) warning, for python specific problems
* (E) error, for probable bugs in the code
* (F) fatal, if an error occurred which prevented pylint from doing
further processing.
So for an example of a Pylint Python-specific warning,
see the “W0611: Unused numpy imported as np (unused-import)” warning.
It is important to note that while tools such as Pylint are great at giving you a starting point to consider how to improve your code, they won’t find everything that may be wrong with it.
How Does Pylint Calculate the Score?
The Python formula used is (with the variables representing numbers of each type of infraction and
statementindicating the total number of statements):10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)For example, with a total of 31 statements of models.py and views.py, with a count of the errors shown above, we get a score of 8.00. Note whilst there is a maximum score of 10, given the formula, there is no minimum score - it’s quite possible to get a negative score!
Exercise: Further Improve Code Style of Our Project
Select and fix a few of the issues with our code that Pylint detected. Make sure you do not break the rest of the code in the process and that the code still runs. After making any changes, run Pylint again to verify you’ve resolved these issues.
Make sure you commit and push requirements.txt
and any file with further code style improvements you did
and merge onto your development and main branches.
$ git add requirements.txt
$ git commit -m "Added Pylint library"
$ git push origin style-fixes
$ git switch develop
$ git merge style-fixes
$ git push origin develop
$ git switch main
$ git merge develop
$ git push origin main
Optional Exercise: Improve Code Style of Your Other Python Projects
If you have a Python project you are working on or you worked on in the past, run it past Pylint to see what issues with your code are detected, if any.
It is possible to automate these kind of code checks with GitHub’s Continuous Integration service GitHub Actions - we will come back to automated linting in the episode on “Diagnosing Issues and Improving Robustness”.
Key Points
Use linting tools on the command line (or via continuous integration) to automatically check your code style.
Section 2: Ensuring Correctness of Software at Scale
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What should we do to ensure our code is correct?
Objectives
Introduce the testing tools, techniques, and infrastructure that will be used in this section.
We’ve just set up a suitable environment for the development of our software project and are ready to start coding. However, we want to make sure that the new code we contribute to the project is actually correct and is not breaking any of the existing code. So, in this section, we’ll look at testing approaches that can help us ensure that the software we write is behaving as intended, and how we can diagnose and fix issues once faults are found. Using such approaches requires us to change our practice of development. This can take time, but potentially saves us considerable time in the medium to long term by allowing us to more comprehensively and rapidly find such faults, as well as giving us greater confidence in the correctness of our code - so we should try and employ such practices early on. We will also make use of techniques and infrastructure that allow us to do this in a scalable, automated and more performant way as our codebase grows.
In this section we will:
- Make use of a test framework called Pytest, a free and open source Python library to help us structure and run automated tests.
- Design, write and run unit tests using Pytest to verify the correct behaviour of code and identify faults, making use of test parameterisation to increase the number of different test cases we can run.
- Automatically run a set of unit tests using GitHub Actions - a Continuous Integration infrastructure that allows us to automate tasks when things happen to our code, such as running those tests when a new commit is made to a code repository.
- Use VS Code’s integrated debugger to help us locate a fault in our code while it is running, and then fix it.
Key Points
Using testing requires us to change our practice of code development, but saves time in the long run by allowing us to more comprehensively and rapidly find faults in code, as well as giving us greater confidence in the correctness of our code.
The use of test techniques and infrastructures such as parameterisation and Continuous Integration can help scale and further automate our testing process.
Automatically Testing Software
Overview
Teaching: 30 min
Exercises: 20 minQuestions
Does the code we develop work the way it should do?
Can we (and others) verify these assertions for themselves?
To what extent are we confident of the accuracy of results that appear in publications?
Objectives
Explain the reasons why testing is important
Describe the three main types of tests and what each are used for
Implement and run unit tests to verify the correct behaviour of program functions
Introduction
Being able to demonstrate that a process generates the right results is important in any field of research, whether it’s software generating those results or not. So when writing software we need to ask ourselves some key questions:
- Does the code we develop work the way it should do?
- Can we (and others) verify these assertions for themselves?
- Perhaps most importantly, to what extent are we confident of the accuracy of results that software produces?
If we are unable to demonstrate that our software fulfills these criteria, why would anyone use it? Having well-defined tests for our software is useful for this, but manually testing software can prove an expensive process.
Automation can help, and automation where possible is a good thing - it enables us to define a potentially complex process in a repeatable way that is far less prone to error than manual approaches. Once defined, automation can also save us a lot of effort, particularly in the long run. In this episode we’ll look into techniques of automated testing to improve the predictability of a software change, make development more productive, and help us produce code that works as expected and produces desired results.
What Is Software Testing?
For the sake of argument, if each line we write has a 99% chance of being right, then a 70-line program will be wrong more than half the time. We need to do better than that, which means we need to test our software to catch these mistakes.
We can and should extensively test our software manually, and manual testing is well-suited to testing aspects such as graphical user interfaces and reconciling visual outputs against inputs. However, even with a good test plan, manual testing is very time consuming and prone to error. Another style of testing is automated testing, where we write code that tests the functions of our software. Since computers are very good and efficient at automating repetitive tasks, we should take advantage of this wherever possible.
There are three main types of automated tests:
- Unit tests are tests for fairly small and specific units of functionality, e.g. determining that a particular function returns output as expected given specific inputs.
- Functional or integration tests work at a higher level, and test functional paths through your code, e.g. given some specific inputs, a set of interconnected functions across a number of modules (or the entire code) produce the expected result. These are particularly useful for exposing faults in how functional units interact.
- Regression tests make sure that your program’s output hasn’t changed, for example after making changes your code to add new functionality or fix a bug.
For the purposes of this course, we’ll focus on unit tests. But the principles and practices we’ll talk about can be built on and applied to the other types of tests too.
Set Up a New Feature Branch for Writing Tests
We’re going to look at how to run some existing tests and also write some new ones,
so let’s ensure we’re initially on our develop branch we created earlier.
And then, we’ll create a new feature branch called test-suite off the develop branch -
a common term we use to refer to sets of tests - that we’ll use for our test writing work:
$ git switch develop
$ git switch -c test-suite
Good practice is to write our tests around the same time we write our code on a feature branch. But since the code already exists, we’re creating a feature branch for just these extra tests. Git branches are designed to be lightweight, and where necessary, transient, and use of branches for even small bits of work is encouraged.
Later on, once we’ve finished writing these tests and are convinced they work properly,
we’ll merge our test-suite branch back into develop.
Catchment Data Analysis
Let’s go back to our river catchment software project.
Recall that it is based on a measurement campaign
to record and analyse meteorological and hydrological data.
There are a number of datasets in the data directory
recording rainfall and hydrological data across three river catchment areas.
There is one file for rainfall for all three catchments,
and one file for hydrological data for each catchment.
Each dataset is stored in comma-separated values (CSV) format.
The first row contains the column headers,
and each subsequent row holds information for a given site at a given time,
as indicated by the values in the Site and Date columns.
The values are a mix of dates, strings, and numbers,
making the processing of the data difficult.
Let’s take a quick look at the data now from within the Python command line console.
Change directory to the repository root
(which should be in your home directory ~/python-intermediate-rivercatchment),
ensure you have your virtual environment activated in your command line terminal
(particularly if opening a new one),
and then start the Python console by invoking the Python interpreter without any parameters, e.g.:
$ cd ~/python-intermediate-rivercatchment
$ source venv/bin/activate
$ python3
The last command will start the Python console within your shell, which enables us to execute Python commands interactively. Inside the console enter the following:
import pandas as pd
pd.read_csv('data/rain_data_2015-12.csv', usecols=['Site', 'Date', 'Rainfall (mm)'])
Site Date Rainfall (mm)
0 FP35 01/12/2005 00:00 0.0
1 FP35 01/12/2005 00:15 0.0
2 FP35 01/12/2005 00:30 0.0
3 FP35 01/12/2005 00:45 0.0
4 FP35 01/12/2005 01:00 0.0
... ... ...
5761 PL16 31/12/2005 22:45 0.2
5762 PL16 31/12/2005 23:00 0.0
5763 PL16 31/12/2005 23:15 0.0
5764 PL16 31/12/2005 23:30 0.0
5765 PL16 31/12/2005 23:45 0.0
The data has been read in using the Panda’s read_csv() function,
where the columns to be read have been specified in the list ['Site', 'Date', 'Rainfall (mm)'].
As mentioned above,
the Site and Date columns indicate the location and time of each measurement.
The data itself is stored in the one-dimensional Rainfall (mm) column.
While this format is convenient for data storage,
it is not particularly useful for analysing the data,
and so we must do some preprocessing of the dataset.
Fortunately the code for this has already been prepared for you,
in the read_variable_from_csv() function,
available in the catchment/models.py library.
To use this enter the following in the python console:
from catchment import models
dataset = models.read_variable_from_csv('data/rain_data_2015-12.csv')
dataset.shape
(2976, 2)
The data is now two-dimensional, with 2 columns and 2976 rows of data. We can simply view the data by entering the following in the python console:
dataset
FP35 PL16
2005-12-01 00:00:00 0.0 0.0
2005-12-01 00:15:00 0.0 0.0
2005-12-01 00:30:00 0.0 0.0
2005-12-01 00:45:00 0.0 0.0
2005-12-01 01:00:00 0.0 0.0
... ...
2005-12-31 22:45:00 0.2 0.2
2005-12-31 23:00:00 0.0 0.0
2005-12-31 23:15:00 0.2 0.0
2005-12-31 23:30:00 0.2 0.0
2005-12-31 23:45:00 0.0 0.0
Each measurement site, FP35 and PL16, now has it’s own column, and the index contains the timestamp for each measurement, stored as a Pandas DatetimeIndex object (enter type(dataset.index) into the python console to verify this for yourselves).
Our catchment study application has a number of statistical functions, also held in catchment/models.py: daily_mean(), daily_max(), daily_min(), and daily_total(), for calculating the mean average, the maximum, the minimum, and the total values for each day in our data. For example, the daily_total() function looks like this:
def daily_total(data):
"""Calculate the daily total of a 2D data array.
:param data: A 2D Pandas data frame with measurement data.
Index must be np.datetime64 compatible format. Columns are measurement sites.
:returns: A 2D Pandas data frame with total values of the measurements for each day.
"""
return data.groupby(data.index.date).sum()
Here, we use the Panda’s dataset built-in groupby() function,
to group the data according to the date
(given by the built-in date() function, which returns only the dates for each index entry).
The total value of each group is calculated using the built-in sum() function,
and returned from the function.
So that we can clearly show this working with our measurement data, we will use a small subsample of two hours of measurements from near the start of our dataset, across midnight of the 1st December 2005. This sample has been stored in a separate datafile, and can be loaded in the same manner as the main dataset:
sample_dataset = models.read_variable_from_csv('data/rain_data_small.csv')
sample_dataset
FP35 PL16
2005-12-01 23:00:00 0.0 0.4
2005-12-01 23:15:00 0.0 0.4
2005-12-01 23:30:00 0.0 0.4
2005-12-01 23:45:00 0.0 0.6
2005-12-02 00:00:00 0.2 0.2
2005-12-02 00:15:00 0.0 0.4
2005-12-02 00:30:00 0.0 0.8
2005-12-02 00:45:00 0.2 0.6
This data can be passed to the function by entering the following lines in the python console:
from catchment.models import daily_total
daily_total(sample_dataset)
Note we use a different form of import here -
only importing the daily_total function from our models module instead of everything.
This also has the effect that we can refer to the function using only its name,
without needing to include the module name too (i.e. models.daily_total()).
The above code will return the mean rainfall for each day across each hour (labelled according to the day each is in), as another Pandas dataframe:
FP35 PL16
2005-12-01 0.0 1.8
2005-12-02 0.4 2.0
The other statistical functions are similar. Note that in real situations functions we write are often likely to be more complicated than these, but simplicity here allows us to reason about what’s happening - and what we need to test - more easily.
Let’s now look into how we can test each of our application’s statistical functions to ensure they are functioning correctly.
Writing Tests to Verify Correct Behaviour
Testing Basics
The principle method for testing our functions is to write a series of checks or tests, each executing a function we want to test with known inputs against known valid results, and throw an error if we encounter a result that is incorrect. To help with this process both the NumPy and Pandas libraries provide testing functions, which we will make use of here.
Working with only real data for testing is limiting though,
so we will instead create artificial inputs for our tests.
For example, we will test the daily_mean() function,
using [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]] as an input to that function
and check whether the result equals [3.0, 4.0]:
import pandas as pd
import pandas.testing as pdt
from catchment.models import daily_mean
import datetime
test_input = pd.DataFrame(
data=[[1.0, 2.0],
[3.0, 4.0],
[5.0, 6.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[3.0, 4.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
pdt.assert_frame_equal(daily_mean(test_input), test_result)
So we use the assert_frame_equal() function -
part of Panda’s testing library -
to test that our calculated result is the same as our expected result.
This function explicitly checks the frame’s shape and elements are the same,
as well as the index and column values,
and throws an AssertionError if they are not
(and, it should be noted, returns nothing if they are).
In particular, note that we can’t just use == or other Python equality methods,
since these won’t work properly with NumPy-based arrays in all cases.
We could then add to this with other tests that use and test against other values, and end up with something like:
import pandas as pd
import pandas.testing as pdt
from catchment.models import daily_mean
import datetime
test_input = pd.DataFrame(
data=[[2.0, 0.0],
[4.0, 0.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[2.0, 0.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
pdt.assert_frame_equal(daily_mean(test_input), test_result)
test_input = pd.DataFrame(
data=[[0.0, 0.0],
[0.0, 0.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[0.0, 0.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
pdt.assert_frame_equal(daily_mean(test_input), test_result)
test_input = pd.DataFrame(
data=[[1.0, 2.0],
[3.0, 4.0],
[5.0, 6.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[3.0, 4.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
pdt.assert_frame_equal(daily_mean(test_input), test_result)
However, if we were to enter these in this order, we’ll find we get the following after the first test:
...
AssertionError: DataFrame.iloc[:, 0] (column name="A") are different
DataFrame.iloc[:, 0] (column name="A") values are different (100.0 %)
[index]: [2000-01-01]
[left]: [3.0]
[right]: [2.0]
This tells us that one element between our generated and expected arrays doesn’t match, and shows us the different values, and the indices to locate these.
We could put these tests in a separate script to automate the running of these tests. But a Python script halts at the first failed assertion, so the second and third tests aren’t run at all. It would be more helpful if we could get data from all of our tests every time they’re run, since the more information we have, the faster we’re likely to be able to track down bugs. It would also be helpful to have some kind of summary report: if our set of tests - known as a test suite - includes thirty or forty tests (as it well might for a complex function or library that’s widely used), we’d like to know how many passed or failed.
Going back to our failed first test, what was the issue? As it turns out, the test itself was incorrect, and should have read:
test_input = pd.DataFrame(
data=[[2.0, 0.0],
[4.0, 0.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[3.0, 0.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
pdt.assert_frame_equal(daily_mean(test_input), test_result)
Which highlights an important point: as well as making sure our code is returning correct answers, we also need to ensure the tests themselves are also correct. Otherwise, we may go on to fix our code only to return an incorrect result that appears to be correct. So a good rule is to make tests simple enough to understand so we can reason about both the correctness of our tests as well as our code. Otherwise, our tests hold little value.
Using a Testing Framework
Keeping these things in mind, here’s a different approach that builds on the ideas we’ve seen so far but uses a unit testing framework. In such a framework we define our tests we want to run as functions, and the framework automatically runs each of these functions in turn, summarising the outputs. And unlike our previous approach, it will run every test regardless of any encountered test failures.
Most people don’t enjoy writing tests, so if we want them to actually do it, it must be easy to:
- Add or change tests,
- Understand the tests that have already been written,
- Run those tests, and
- Understand those tests’ results
Test results must also be reliable. If a testing tool says that code is working when it’s not, or reports problems when there actually aren’t any, people will lose faith in it and stop using it.
Look at tests/test_models.py:
"""Tests for statistics functions within the Model layer."""
import pandas as pd
import pandas.testing as pdt
import datetime
def test_daily_mean_zeros():
"""Test that mean function works for an array of zeros."""
from catchment.models import daily_mean
test_input = pd.DataFrame(
data=[[0.0, 0.0],
[0.0, 0.0],
[0.0, 0.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[0.0, 0.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
# Need to use Pandas testing functions to compare arrays
pdt.assert_frame_equal(daily_mean(test_input), test_result)
def test_daily_mean_integers():
"""Test that mean function works for an array of positive integers."""
from catchment.models import daily_mean
test_input = pd.DataFrame(
data=[[1.0, 2.0],
[3.0, 4.0],
[5.0, 6.0]],
index=[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
columns=['A', 'B']
)
test_result = pd.DataFrame(
data=[[3.0, 4.0]],
index=[datetime.date(2000, 1, 1)],
columns=['A', 'B']
)
# Need to use Pandas testing functions to compare arrays
pdt.assert_frame_equal(daily_mean(test_input), test_result)
...
Here, although we have specified two of our previous manual tests as separate functions, they run the same assertions. Each of these test functions, in a general sense, are called test cases - these are a specification of:
- Inputs, e.g. the
test_inputPandas dataframe - Execution conditions -
what we need to do to set up the testing environment to run our test,
e.g. importing the
daily_mean()function so we can use it. Note that for clarity of testing environment, we only import the necessary library function we want to test within each test function - Testing procedure, e.g. running
daily_mean()with ourtest_inputarray and usingassert_frame_equal()to test its validity - Expected outputs, e.g. our
test_resultPandas dataframe that we test against
Also, we’re defining each of these things for a test case we can run independently that requires no manual intervention.
Going back to our list of requirements, how easy is it to run these tests?
We can do this using a Python package called pytest.
Pytest is a testing framework that allows you to write test cases using Python.
You can use it to test things like Python functions,
database operations,
or even things like service APIs -
essentially anything that has inputs and expected outputs.
We’ll be using Pytest to write unit tests,
but what you learn can scale to more complex functional testing for applications or libraries.
What About Unit Testing in Other Languages?
Other unit testing frameworks exist for Python, including Nose2 and Unittest, and the approach to unit testing can be translated to other languages as well, e.g. pFUnit for Fortran, JUnit for Java (the original unit testing framework), Catch or gtest for C++, etc.
Why Use pytest over unittest?
We could alternatively use another Python unit test framework, unittest, which has the advantage of being installed by default as part of Python. This is certainly a solid and established option, however pytest has many distinct advantages, particularly for learning, including:
- unittest requires additional knowledge of object-oriented frameworks (covered later in the course) to write unit tests, whereas in pytest these are written in simpler functions so is easier to learn
- Being written using simpler functions, pytest’s scripts are more concise and contain less boilerplate, and thus are easier to read
- pytest output, particularly in regard to test failure output, is generally considered more helpful and readable
- pytest has a vast ecosystem of plugins available if ever you need additional testing functionality
- unittest-style unit tests can be run from pytest out of the box!
A common challenge, particularly at the intermediate level, is the selection of a suitable tool from many alternatives for a given task. Once you’ve become accustomed to object-oriented programming you may find unittest a better fit for a particular project or team, so you may want to revisit it at a later date.
Installing Pytest
If you have already installed pytest package in your virtual environment,
you can skip this step.
Otherwise, as we have seen, we have a couple of options for installing external libraries:
- via VS Code (see “Adding an External Library” section in “Integrated Software Development Environments” episode), or
- via the command line
(see “Installing External Libraries in an Environment With
pip” section in “Virtual Environments For Software Development” episode).
To do it via the command line -
exit the Python console first (either with Ctrl-D or by typing exit()),
then do:
$ python3 -m pip install pytest
Whether we do this via VS Code or the command line,
the results are exactly the same:
our virtual environment will now have the pytest package installed for use.
Running Tests
Now we can run these tests using pytest:
$ python3 -m pytest tests/test_models.py
Here, we use -m flag of the python3 command to invoke the pytest module,
and specify the tests/test_models.py file to run the tests in that file explicitly.
Why Run Pytest Using
python3 -m pytestand Notpytest?
pytestis another Python module that can be run via its own command but this is a good example why invoking Python modules viapython3 -mmay be better (recall the explanation of Python interpreter’s-mflag). Had we usedpytest tests/test_models.pycommand directly, this would have led to a “ModuleNotFoundError: No module named ‘catchment’” error. This is becausepytestcommand (unlikepython3 -m pytest) does not add the current directory to its list of directories to search for modules, hence thecatchmentsubdirectory’s contents are not being ‘seen’ bypytestcausing theModuleNotFoundError. There are ways to work around this problem butpython3 -m pytestensures it does not happen in the first place.
============================================== test session starts =====================================================
platform darwin -- Python 3.11.4, pytest-7.4.3, pluggy-1.3.0
rootdir: /Users/alex/python-intermediate-rivercatchment
plugins: anyio-3.3.4
collected 2 items
tests/test_models.py .. [100%]
=============================================== 2 passed in 0.79s ==================================
Pytest looks for functions whose names also start with the letters ‘test_’ and runs each one.
Notice the .. after our test script:
- If the function completes without an assertion being triggered,
we count the test as a success (indicated as
.). - If an assertion fails, or we encounter an error,
we count the test as a failure (indicated as
F). The error is included in the output so we can see what went wrong.
So if we have many tests, we essentially get a report indicating which tests succeeded or failed. Going back to our list of requirements (the bullet points under Using a Testing Framework section), do we think these results are easy to understand?
Exercise: Write Some Unit Tests
We already have a couple of test cases in
test/test_models.pythat test thedaily_mean()function. Looking atcatchment/models.py, write at least two new test cases that test thedaily_max()anddaily_min()functions, adding them totest/test_models.py. Here are some hints:
- You could choose to format your functions very similarly to
daily_mean(), defining test input and expected result arrays followed by the equality assertion.- Try to choose cases that are suitably different, and remember that these functions take a 2D array and return a 1D array with each element the result of analysing each column of the data.
Once added, run all the tests again with
python -m pytest tests/test_models.py, and you should also see your new tests pass.Solution
... def test_daily_max(): """Test that max function works for an array of positive integers.""" from catchment.models import daily_max test_input = pd.DataFrame( data=[[4, 2, 5], [1, 6, 2], [4, 1, 9]], index=[pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00')], columns=['A', 'B', 'C'] ) test_result = pd.DataFrame( data=[[4, 6, 9]], index=[datetime.date(2000, 1, 1)], columns=['A', 'B', 'C'] ) pdt.assert_frame_equal(daily_max(test_input), test_result) def test_daily_min(): """Test that min function works for an array of positive and negative integers.""" from catchment.models import daily_min test_input = pd.DataFrame( data=[[ 4, -2, 5], [ 1, -6, 2], [-4, -1, 9]], index=[pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00')], columns=['A', 'B', 'C'] ) test_result = pd.DataFrame( data=[[-4, -6, 2]], index=[datetime.date(2000, 1, 1)], columns=['A', 'B', 'C'] ) pdt.assert_frame_equal(daily_min(test_input), test_result) ...
The big advantage is that as our code develops we can update our test cases and commit them back, ensuring that ourselves (and others) always have a set of tests to verify our code at each step of development. This way, when we implement a new feature, we can check a) that the feature works using a test we write for it, and b) that the development of the new feature doesn’t break any existing functionality.
What About Testing for Errors?
There are some cases where seeing an error is actually the correct behaviour,
and Python allows us to test for exceptions.
Add this test in tests/test_models.py:
import pytest
...
def test_daily_min_python_list():
"""Test for AttributeError when passing a python list"""
from catchment.models import daily_min
with pytest.raises(AttributeError):
error_expected = daily_min([[3, 4, 7],[-3, 0, 5]])
Note that you need to import the pytest library at the top of our test_models.py file
with import pytest so that we can use pytest’s raises() function.
Run all your tests as before.
Since we’ve installed pytest to our environment,
we should also regenerate our requirements.txt:
$ python3 -m pip freeze > requirements.txt
Finally, let’s commit our new test_models.py file,
requirements.txt file,
and test cases to our test-suite branch,
and push this new branch and all its commits to GitHub:
$ git add requirements.txt tests/test_models.py
$ git commit -m "Add initial test cases for daily_max() and daily_min()"
$ git push -u origin test-suite
Why Should We Test Invalid Input Data?
Testing the behaviour of inputs, both valid and invalid, is a really good idea and is known as data validation. Even if you are developing command line software that cannot be exploited by malicious data entry, testing behaviour against invalid inputs prevents generation of erroneous results that could lead to serious misinterpretation (as well as saving time and compute cycles which may be expensive for longer-running applications). It is generally best not to assume your user’s inputs will always be rational.
Key Points
The three main types of automated tests are unit tests, functional tests and regression tests.
We can write unit tests to verify that functions generate expected output given a set of specific inputs.
It should be easy to add or change tests, understand and run them, and understand their results.
We can use a unit testing framework like Pytest to structure and simplify the writing of tests in Python.
We should test for expected errors in our code.
Testing program behaviour against both valid and invalid inputs is important and is known as data validation.
Scaling Up Unit Testing
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How can we make it easier to write lots of tests?
How can we know how much of our code is being tested?
Objectives
Use parameterisation to automatically run tests over a set of inputs
Use code coverage to understand how much of our code is being tested using unit tests
Introduction
We’re starting to build up a number of tests that test the same function, but just with different parameters. However, continuing to write a new function for every single test case isn’t likely to scale well as our development progresses. How can we make our job of writing tests more efficient? And importantly, as the number of tests increases, how can we determine how much of our code base is actually being tested?
Parameterising Our Unit Tests
So far, we’ve been writing a single function for every new test we need. But when we simply want to use the same test code but with different data for another test, it would be great to be able to specify multiple sets of data to use with the same test code. Test parameterisation gives us this.
So instead of writing a separate function for each different test,
we can parameterise the tests with multiple test inputs.
For example, in tests/test_models.py let us rewrite
the test_daily_mean_zeros() and test_daily_mean_integers()
into a single test function:
@pytest.mark.parametrize(
"test_input, expected_output",
[
(
pd.DataFrame(
data=[ [0.0, 0.0], [0.0, 0.0], [0.0, 0.0] ],
index=[ pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00') ],
columns=[ 'A', 'B' ]
),
pd.DataFrame(
data=[ [0.0, 0.0] ],
index=[ datetime.date(2000, 1, 1) ],
columns=[ 'A', 'B' ]
)
),
(
pd.DataFrame(
data=[ [1, 2], [3, 4], [5, 6] ],
index=[ pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00') ],
columns=[ 'A', 'B' ],
),
pd.DataFrame(
data=[ [3.0, 4.0] ],
index=[ datetime.date(2000, 1, 1) ],
columns=[ 'A', 'B' ]
)
),
])
def test_daily_mean(test_input, expected_output):
"""Test mean function works for array of zeroes and positive integers."""
from catchment.models import daily_mean
pdt.assert_frame_equal(daily_mean(test_input), expected_output)
Here, we use Pytest’s mark capability to add metadata to this specific test -
in this case, marking that it’s a parameterised test.
parameterize() function is actually a
Python decorator.
A decorator, when applied to a function,
adds some functionality to it when it is called, and here,
what we want to do is specify multiple input and expected output test cases
so the function is called over each of these inputs automatically when this test is called.
We specify these as arguments to the parameterize() decorator,
firstly indicating the names of these arguments that will be
passed to the function (test, expected),
and secondly the actual arguments themselves that correspond to each of these names -
the input data (the test argument),
and the expected result (the expected argument).
In this case, we are passing in two tests to test_daily_mean() which will be run sequentially.
So our first test will run daily_mean() on [ [0.0, 0.0], [0.0, 0.0], [0.0, 0.0] ] (our test argument),
and check to see if it equals [0.0, 0.0] (our expected argument).
Similarly, our second test will run daily_mean()
with [ [1, 2], [3, 4], [5, 6] ] and check it produces [3.0, 4.0].
The big plus here is that we don’t need to write separate functions for each of the tests - our test code can remain compact and readable as we write more tests and adding more tests scales better as our code becomes more complex.
Exercise: Write Parameterised Unit Tests
Rewrite your test functions for
daily_max()anddaily_min()to be parameterised, adding in new test cases for each of them.Solution
Test function for
daily_max()... @pytest.mark.parametrize( "test_input, expected_output", [ ( pd.DataFrame( data = [ [0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [0.0, 0.0, 0.0] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ( pd.DataFrame( data = [ [4, 2, 5], [1, 6, 2], [4, 1, 9] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [4, 6, 9] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ( pd.DataFrame( data = [ [4, -2, 5], [1, -6, 2], [-4, -1, 9] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [4, -1, 9] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ]) def test_daily_max(test_input, expected_output): """Test max function works for array of zeroes and positive integers.""" from catchment.models import daily_max pdt.assert_frame_equal(daily_max(test_input), expected_output) ...and for
daily_min()... @pytest.mark.parametrize( "test_input, expected_output", [ ( pd.DataFrame( data = [ [0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [0.0, 0.0, 0.0] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ( pd.DataFrame( data = [ [4, 2, 5], [1, 6, 2], [4, 1, 9] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [1, 1, 2] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ( pd.DataFrame( data = [ [4, -2, 5], [1, -6, 2], [-4, -1, 9] ], index = [ pd.to_datetime('2000-01-01 01:00'), pd.to_datetime('2000-01-01 02:00'), pd.to_datetime('2000-01-01 03:00') ], columns = [ 'A', 'B', 'C' ] ), pd.DataFrame( data = [ [-4, -6, 2] ], index = [ datetime.date(2000, 1, 1) ], columns = [ 'A', 'B', 'C' ] ) ), ]) def test_daily_min(test_input, expected_output): """Test min function works for array of zeroes and positive integers.""" from catchment.models import daily_min pdt.assert_frame_equal(daily_min(test_input), expected_output) ...
Try them out!
Let’s commit our revised test_models.py file and test cases to our test-suite branch
(but don’t push them to the remote repository just yet!):
$ git add tests/test_models.py
$ git commit -m "Add parameterisation mean, min, max test cases"
Code Coverage - How Much of Our Code is Tested?
Pytest can’t think of test cases for us.
We still have to decide what to test and how many tests to run.
Our best guide here is economics:
we want the tests that are most likely to give us useful information that we don’t already have.
For example, if daily_mean(np.array([[2, 0], [4, 0]]))) works,
there’s probably not much point testing daily_mean(np.array([[3, 0], [4, 0]]))),
since it’s hard to think of a bug that would show up in one case but not in the other.
Now, we should try to choose tests that are as different from each other as possible, so that we force the code we’re testing to execute in all the different ways it can - to ensure our tests have a high degree of code coverage.
A simple way to check the code coverage for a set of tests is
to install an additional package pytest-cov to our virtual environment,
which is used by pytest to tell us how many statements in our code are being tested.
$ python3 -m pip install pytest-cov
$ python3 -m pytest --cov=catchment.models tests/test_models.py
So here, we specify the additional named argument --cov to pytest
specifying the code to analyse for test coverage.
...
tests/test_models.py ......... [100%]
---------- coverage: platform darwin, python 3.9.4-final-0 -----------
Name Stmts Miss Cover
-----------------------------------------
catchment/models.py 19 10 47%
-----------------------------------------
TOTAL 19 10 47%
============================== 9 passed in 0.26s ===============================
Here we can see that our tests are doing okay -
47% of statements in catchment/models.py have been executed.
But which statements are not being tested?
The additional argument --cov-report term-missing can tell us:
$ python3 -m pytest --cov=catchment.models --cov-report term-missing tests/test_models.py
...
Name Stmts Miss Cover Missing
---------------------------------------------------
catchment/models.py 19 10 47% 22-35, 44
---------------------------------------------------
TOTAL 19 10 47%
...
So there’s two groups of statements not being tested.
The last is at line 44,
which is in the daily_total() function,
for which we could write tests in the same manner as we have for daily_max() and daily_min().
The other group is at lines 22-35,
which is within the read_variable_from_csv() function.
Here we should consider whether or not to write a test for this function,
and, in general, any other functions that may not be tested.
Of course, if there are hundreds or thousands of lines that are not covered
it may not be feasible to write tests for them all.
But we should prioritise the ones for which we write tests, considering
how often they’re used,
how complex they are,
and importantly, the extent to which they affect our program’s results.
Again, we should also update our requirements.txt file with our latest package environment,
which now also includes pytest-cov, and commit it:
$ python3 -m pip freeze > requirements.txt
$ cat requirements.txt
You’ll notice pytest-cov and coverage have been added.
Let’s commit this file and push our new branch to GitHub:
$ git add requirements.txt
$ git commit -m "Add coverage support"
$ git push origin test-suite
What about Testing Against Indeterminate Output?
What if your implementation depends on a degree of random behaviour? This can be desired within a number of applications, particularly in simulations (for example, molecular simulations) or other stochastic behavioural models of complex systems. So how can you test against such systems if the outputs are different when given the same inputs?
One way is to remove the randomness during testing. For those portions of your code that use a language feature or library to generate a random number, you can instead produce a known sequence of numbers instead when testing, to make the results deterministic and hence easier to test against. You could encapsulate this different behaviour in separate functions, methods, or classes and call the appropriate one depending on whether you are testing or not. This is essentially a type of mocking, where you are creating a “mock” version that mimics some behaviour for the purposes of testing.
Another way is to control the randomness during testing to provide results that are deterministic - the same each time. Implementations of randomness in computing languages, including Python, are actually never truly random - they are pseudorandom: the sequence of ‘random’ numbers are typically generated using a mathematical algorithm. A seed value is used to initialise an implementation’s random number generator, and from that point, the sequence of numbers is actually deterministic. Many implementations just use the system time as the default seed, but you can set your own. By doing so, the generated sequence of numbers is the same, e.g. using Python’s
randomlibrary to randomly select a sample of ten numbers from a sequence between 0-99:import random random.seed(1) print(random.sample(range(0, 100), 10)) random.seed(1) print(random.sample(range(0, 100), 10))Will produce:
[17, 72, 97, 8, 32, 15, 63, 57, 60, 83] [17, 72, 97, 8, 32, 15, 63, 57, 60, 83]So since your program’s randomness is essentially eliminated, your tests can be written to test against the known output. The trick of course, is to ensure that the output being testing against is definitively correct!
The other thing you can do while keeping the random behaviour, is to test the output data against expected constraints of that output. For example, if you know that all data should be within particular ranges, or within a particular statistical distribution type (e.g. normal distribution over time), you can test against that, conducting multiple test runs that take advantage of the randomness to fill the known “space” of expected results. Note that this isn’t as precise or complete, and bear in mind this could mean you need to run a lot of tests which may take considerable time.
Test Driven Development
In the previous episode we learnt how to create unit tests to make sure our code is behaving as we intended. Test Driven Development (TDD) is an extension of this. If we can define a set of tests for everything our code needs to do, then why not treat those tests as the specification.
When doing Test Driven Development, we write our tests first and only write enough code to make the tests pass. We tend to do this at the level of individual features - define the feature, write the tests, write the code. The main advantages are:
- It forces us to think about how our code will be used before we write it
- It prevents us from doing work that we don’t need to do, e.g. “I might need this later…”
- It forces us to test that the tests fail before we’ve implemented the code, meaning we don’t inadvertently forget to add the correct asserts.
You may also see this process called Red, Green, Refactor: ‘Red’ for the failing tests, ‘Green’ for the code that makes them pass, then ‘Refactor’ (tidy up) the result.
For the challenges from here on, try to first convert the specification into a unit test, then try writing the code to pass the test.
Limits to Testing
Like any other piece of experimental apparatus, a complex program requires a much higher investment in testing than a simple one. Putting it another way, a small script that is only going to be used once, to produce one figure, probably doesn’t need separate testing: its output is either correct or not. A linear algebra library that will be used by thousands of people in twice that number of applications over the course of a decade, on the other hand, definitely does. The key is identify and prioritise against what will most affect the code’s ability to generate accurate results.
It’s also important to remember that unit testing cannot catch every bug in an application, no matter how many tests you write. To mitigate this manual testing is also important. Also remember to test using as much input data as you can, since very often code is developed and tested against the same small sets of data. Increasing the amount of data you test against - from numerous sources - gives you greater confidence that the results are correct.
Our software will inevitably increase in complexity as it develops. Using automated testing where appropriate can save us considerable time, especially in the long term, and allows others to verify against correct behaviour.
Key Points
We can assign multiple inputs to tests using parametrisation.
It’s important to understand the coverage of our tests across our code.
Writing unit tests takes time, so apply them where it makes the most sense.
Continuous Integration for Automated Testing
Overview
Teaching: 45 min
Exercises: 0 minQuestions
How can I automate the testing of my repository’s code in a way that scales well?
What can I do to make testing across multiple platforms easier?
Objectives
Describe the benefits of using Continuous Integration for further automation of testing
Enable GitHub Actions Continuous Integration for public open source repositories
Use continuous integration to automatically run unit tests and code coverage when changes are committed to a version control repository
Use a build matrix to specify combinations of operating systems and Python versions to run tests over
Introduction
So far we’ve been manually running our tests as we require. Once we’ve made a change, or added a new feature with accompanying tests, we can re-run our tests, giving ourselves (and others who wish to run them) increased confidence that everything is working as expected. Now we’re going to take further advantage of automation in a way that helps testing scale across a development team with very little overhead, using Continuous Integration.
What is Continuous Integration?
The automated testing we’ve done so far only takes into account the state of the repository we have on our own machines. In a software project involving multiple developers working and pushing changes on a repository, it would be great to know holistically how all these changes are affecting our codebase without everyone having to pull down all the changes and test them. If we also take into account the testing required on different target user platforms for our software and the changes being made to many repository branches, the effort required to conduct testing at this scale can quickly become intractable for a research project to sustain.
Continuous Integration (CI) aims to reduce this burden by further automation, and automation - wherever possible - helps us to reduce errors and makes predictable processes more efficient. The idea is that when a new change is committed to a repository, CI clones the repository, builds it if necessary, and runs any tests. Once complete, it presents a report to let you see what happened.
There are many CI infrastructures and services, free and paid for, and subject to change as they evolve their features. We’ll be looking at GitHub Actions - which unsurprisingly is available as part of GitHub.
Continuous Integration with GitHub Actions
A Quick Look at YAML
YAML is a text format used by GitHub Action workflow files. It is also increasingly used for configuration files and storing other types of data, so it’s worth taking a bit of time looking into this file format.
YAML (a recursive acronym which stands for “YAML Ain’t Markup Language”) is a language designed to be human readable. A few basic things you need to know about YAML to get started with GitHub Actions are key-value pairs, arrays, maps and multi-line strings.
So firstly, YAML files are essentially made up of key-value pairs,
in the form key: value, for example:
name: Kilimanjaro
height_metres: 5892
first_scaled_by: Hans Meyer
In general, you don’t need quotes for strings,
but you can use them when you want to explicitly distinguish between numbers and strings,
e.g. height_metres: "5892" would be a string,
but in the above example it is an integer.
It turns out Hans Meyer isn’t the only first ascender of Kilimanjaro,
so one way to add this person as another value to this key is by using YAML arrays,
like this:
first_scaled_by:
- Hans Meyer
- Ludwig Purtscheller
An alternative to this format for arrays is the following, which would have the same meaning:
first_scaled_by: [Hans Meyer, Ludwig Purtscheller]
If we wanted to express more information for one of these values we could use a feature known as maps (dictionaries/hashes), which allow us to define nested, hierarchical data structures, e.g.
...
height:
value: 5892
unit: metres
measured:
year: 2008
by: Kilimanjaro 2008 Precise Height Measurement Expedition
...
So here, height itself is made up of three keys value, unit, and measured,
with the last of these being another nested key with the keys year and by.
Note the convention of using two spaces for tabs, instead of Python’s four.
We can also combine maps and arrays to describe more complex data. Let’s say we want to add more detail to our list of initial ascenders:
...
first_scaled_by:
- name: Hans Meyer
date_of_birth: 22-03-1858
nationality: German
- name: Ludwig Purtscheller
date_of_birth: 22-03-1858
nationality: Austrian
So here we have a YAML array of our two mountaineers, each with additional keys offering more information.
GitHub Actions also makes use of | symbol to indicate a multi-line string
that preserves new lines. For example:
shakespeare_couplet: |
Good night, good night. Parting is such sweet sorrow
That I shall say good night till it be morrow.
They key shakespeare_couplet would hold the full two line string,
preserving the new line after sorrow.
As we’ll see shortly, GitHub Actions workflows will use all of these.
YAML support in VS Code
YAML language support is available within VS Code. Select the Extensions tab, and type ‘YAML’ into the extension search bar. The first result should be the YAML extension from redhat (see graphic below). Select and install this extension.
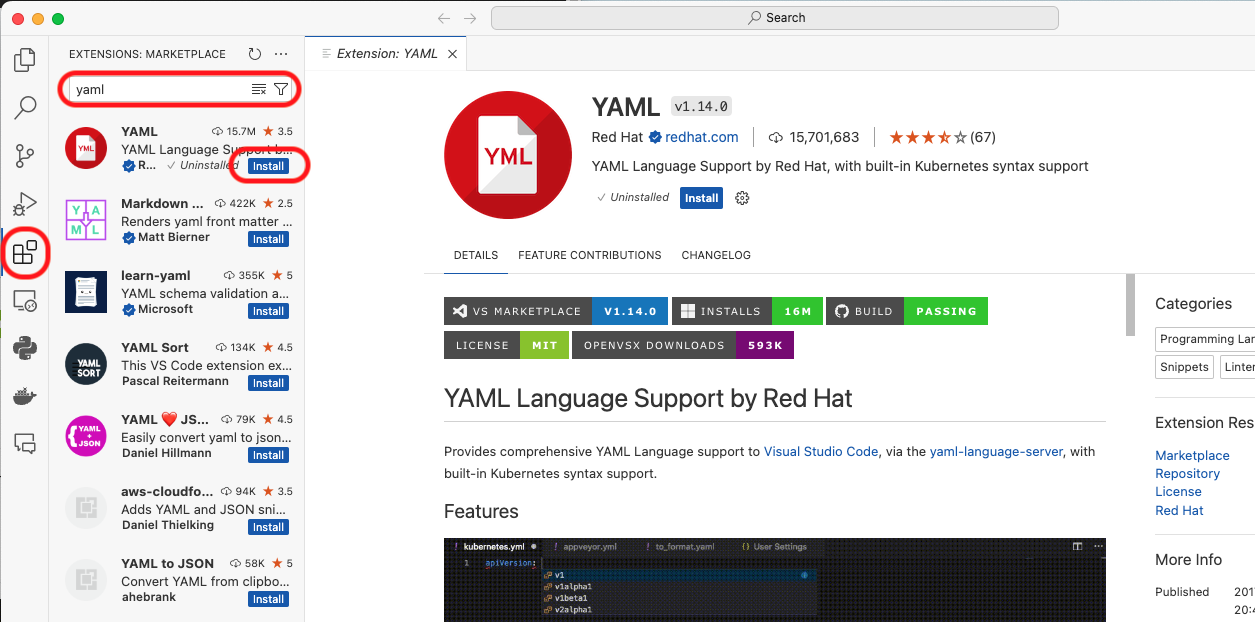
Defining Our Workflow
With a GitHub repository there’s a way we can set up CI
to run our tests automatically when we commit changes.
Let’s do this now by adding a new file to our repository whilst on the test-suite branch.
First, create the new directories .github/workflows:
$ mkdir -p .github/workflows
This directory is used specifically for GitHub Actions,
allowing us to specify any number of workflows that can be run under a variety of conditions,
which is also written using YAML.
So let’s add a new YAML file called main.yml
(note its extension is .yml without the a)
within the new .github/workflows directory:
name: CI
# We can specify which Github events will trigger a CI build
on: push
# now define a single job 'build' (but could define more)
jobs:
build:
# we can also specify the OS to run tests on
runs-on: ubuntu-latest
# a job is a seq of steps
steps:
# Next we need to checkout out repository, and set up Python
# A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python 3.11
uses: actions/setup-python@v2
with:
python-version: "3.11"
- name: Install Python dependencies
run: |
python3 -m pip install --upgrade pip
python3 -m pip install -r requirements.txt
- name: Test with PyTest
run: |
python3 -m pytest --cov=catchment.models tests/test_models.py
Note: be sure to create this file as main.yml
within the newly created .github/workflows directory,
or it won’t work!
So as well as giving our workflow a name - CI -
we indicate with on that we want this workflow to run when we push commits to our repository.
The workflow itself is made of a single job named build,
and we could define any number of jobs after this one if we wanted,
and each one would run in parallel.
Next, we define what our build job will do.
With runs-on we first state which operating systems we want to use,
in this case just Ubuntu for now.
We’ll be looking at ways we can scale this up to testing on more systems later.
Lastly, we define the steps that our job will undertake in turn,
to set up the job’s environment and run our tests.
You can think of the job’s environment initially as a blank slate:
much like a freshly installed machine (albeit virtual) with very little installed on it,
we need to prepare it with what it needs to be able to run our tests.
Each of these steps are:
- Checkout repository for the job:
usesindicates that want to use a GitHub Action calledcheckoutthat does this - Set up Python version:
here we use the
setup-pythonAction, indicating that we want Python version 3.11. Note we specify the version within quotes, to ensure that this is interpreted as a complete string. Otherwise, if we wanted to test against for example Python 3.10, by specifying3.10without the quotes, it would be interpreted as the number3.1which - although it’s the same number as3.10- would be interpreted as the wrong version! - Install latest version of pip, dependencies, and our catchment package:
In order to locally install our
catchmentpackage it’s good practice to upgrade the version of pip that is present first, then we use pip to install our package dependencies. Once installed, we can usepython3 -m pip install -e .as before to install our own package. We userunhere to run theses commands in the CI shell environment - Test with PyTest: lastly, we run
python3 -m pytest, with the same arguments we used manually before
What about other Actions?
Our workflow here uses standard GitHub Actions (indicated by
actions/*). Beyond the standard set of actions, others are available via the GitHub Marketplace. It contains many third-party actions (as well as apps) that you can use with GitHub for many tasks across many programming languages, particularly for setting up environments for running tests, code analysis and other tools, setting up and using infrastructure (for things like Docker or Amazon’s AWS cloud), or even managing repository issues. You can even contribute your own.
Triggering a Build on GitHub Actions
Now if we commit and push this change a CI run will be triggered:
$ git add .github
$ git commit -m "Add GitHub Actions configuration"
$ git push
Since we are only committing the GitHub Actions configuration file
to the test-suite branch for the moment,
only the contents of this branch will be used for CI.
We can pass this file upstream into other branches (i.e. via merges) when we’re happy it works,
which will then allow the process to run automatically on these other branches.
This again highlights the usefulness of the feature-branch model -
we can work in isolation on a feature until it’s ready to be passed upstream
without disrupting development on other branches,
and in the case of CI,
we’re starting to see its scaling benefits across a larger scale development team
working across potentially many branches.
Checking Build Progress and Reports
Handily, we can see the progress of the build from our repository on GitHub
by selecting the test-suite branch from the dropdown menu
(which currently says main),
and then selecting commits
(located just above the code directory listing on the right,
alongside the last commit message and a small image of a timer).
You’ll see a list of commits for this branch,
and likely see an orange marker next to the latest commit
(clicking on it yields Some checks haven’t completed yet)
meaning the build is still in progress.
This is a useful view, as over time, it will give you a history of commits,
who did them, and whether the commit resulted in a successful build or not.
Hopefully after a while, the marker will turn into a green tick indicating a successful build.
Clicking it gives you even more information about the build,
and selecting Details link takes you to a complete log of the build and its output.
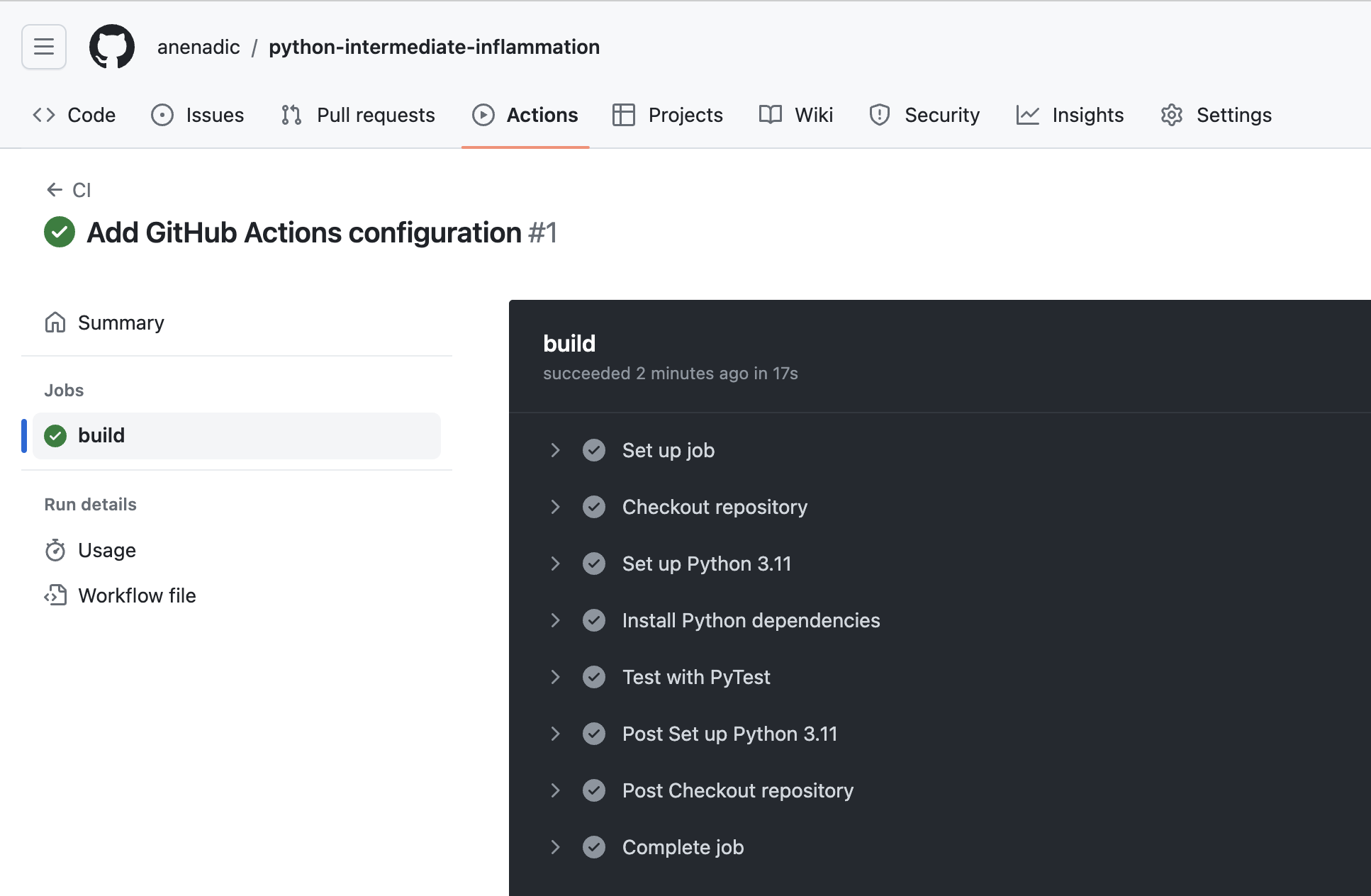
The logs are actually truncated; selecting the arrows next to the entries -
which are the name labels we specified in the main.yml file -
will expand them with more detail, including the output from the actions performed.
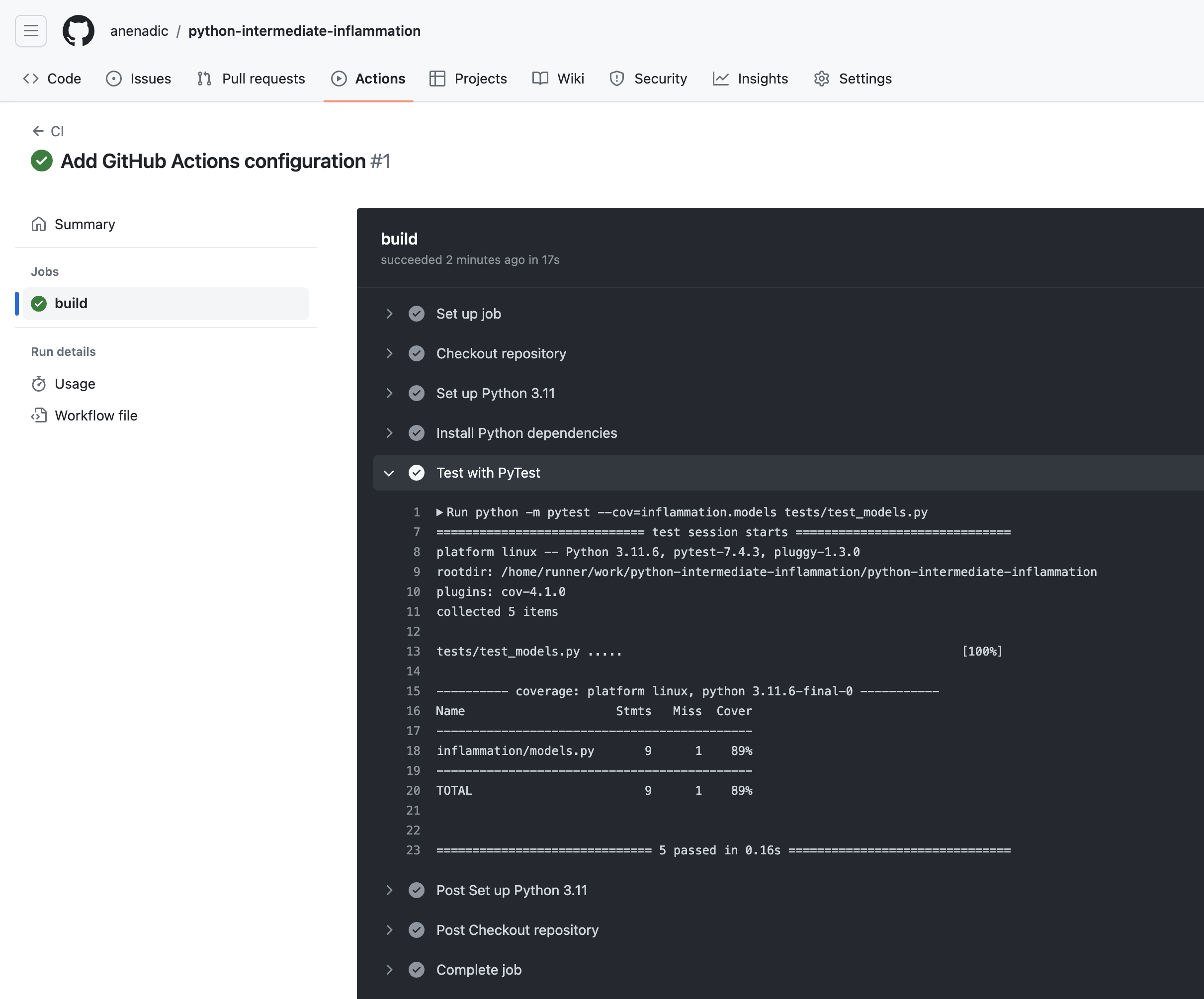
GitHub Actions offers these continuous integration features as a completely free service for public repositories, and supplies 2000 build minutes a month on as many private repositories that you like. Paid levels are available too.
Scaling Up Testing Using Build Matrices
Now we have our CI configured and building, we can use a feature called build matrices which really shows the value of using CI to test at scale.
Suppose the intended users of our software use either Ubuntu, Mac OS, or Windows, and either have Python version 3.10 or 3.11 installed, and we want to support all of these. Assuming we have a suitable test suite, it would take a considerable amount of time to set up testing platforms to run our tests across all these platform combinations. Fortunately, CI can do the hard work for us very easily.
Using a build matrix we can specify testing environments and parameters (such as operating system, Python version, etc.) and new jobs will be created that run our tests for each permutation of these.
Let’s see how this is done using GitHub Actions.
To support this, we define a strategy as
a matrix of operating systems and Python versions within build.
We then use matrix.os and matrix.python-version to reference these configuration possibilities
instead of using hardcoded values -
replacing the runs-on and python-version parameters
to refer to the values from the matrix.
So, our .github/workflows/main.yml should look like the following:
...
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
python-version: ["3.10", "3.11"]
runs-on: ${{ matrix.os }}
...
# a job is a seq of steps
steps:
# Next we need to checkout out repository, and set up Python
# A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything
- name: Checkout repository
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
...
The ${{ }} are used
as a means to reference configuration values from the matrix.
This way, every possible permutation of Python versions 3.10 and 3.11
with the latest versions of Ubuntu, Mac OS and Windows operating systems
will be tested and we can expect 6 build jobs in total.
Let’s commit and push this change and see what happens:
$ git add .github/workflows/main.yml
$ git commit -m "Add GA build matrix for os and Python version"
$ git push
If we go to our GitHub build now, we can see that a new job has been created for each permutation.
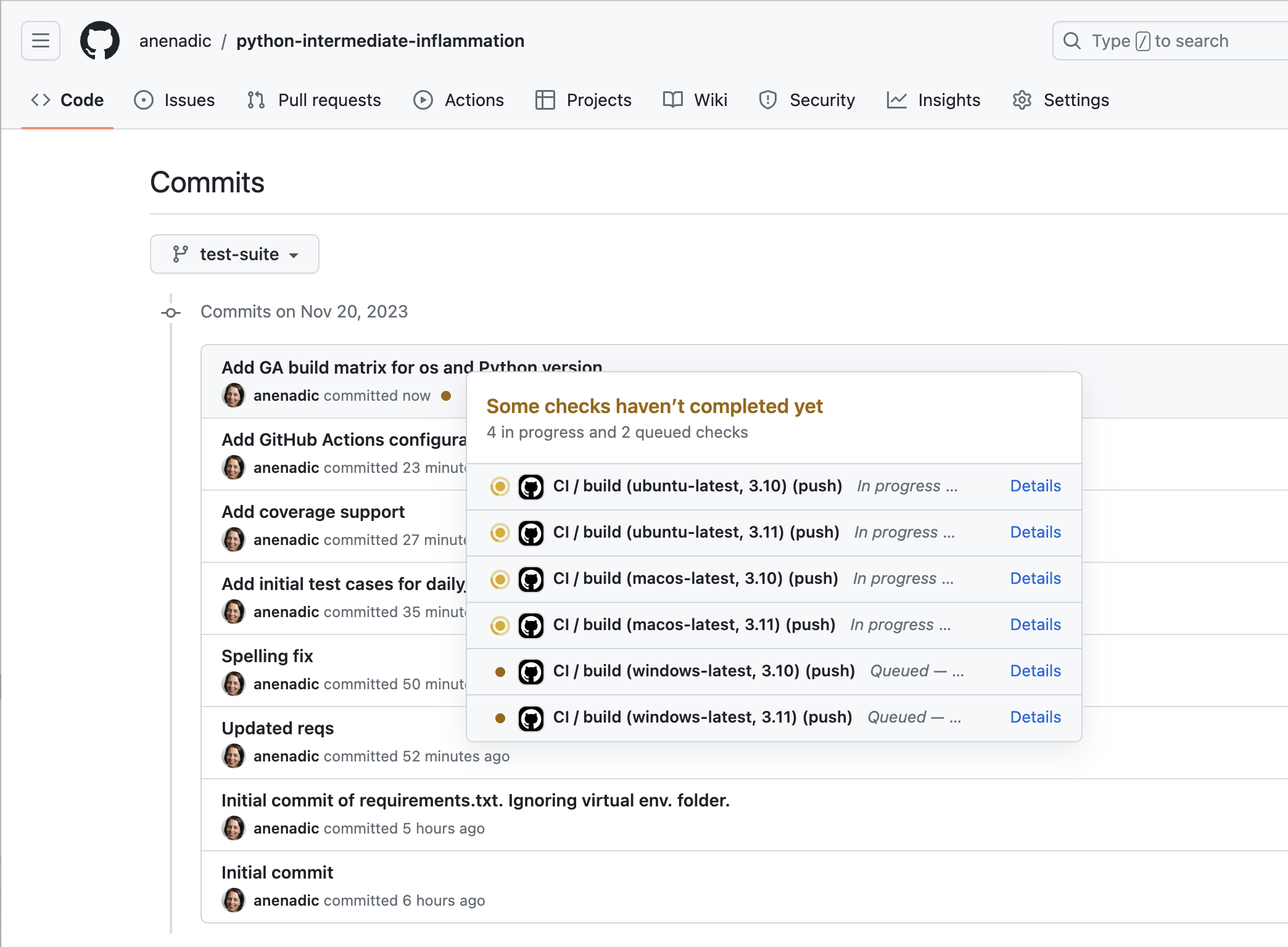
Note all jobs running in parallel (up to the limit allowed by our account) which potentially saves us a lot of time waiting for testing results. Overall, this approach allows us to massively scale our automated testing across platforms we wish to test.
Merging Back to develop Branch
Now we’re happy with our test suite, we can merge this work
(which currently only exist on our test-suite branch)
with our parent develop branch.
Again, this reflects us working with impunity on a logical unit of work,
involving multiple commits,
on a separate feature branch until it’s ready to be escalated to the develop branch:
$ git switch develop
$ git merge test-suite
Then, assuming no conflicts we can push these changes back to the remote repository as we’ve done before:
$ git push origin develop
Now these changes have migrated to our parent develop branch,
develop will also inherit the configuration to run CI builds,
so these will run automatically on this branch as well.
This highlights a big benefit of CI when you perform merges (and apply pull requests).
As new branch code is merged into upstream branches like develop and main
these newly integrated code changes are automatically tested together with existing code -
which of course may also have changed in the meantime!
Key Points
Continuous Integration can run tests automatically to verify changes as code develops in our repository.
CI builds are typically triggered by commits pushed to a repository.
We need to write a configuration file to inform a CI service what to do for a build.
We can specify a build matrix to specify multiple platforms and programming language versions to test against
Builds can be enabled and configured separately for each branch.
We can run - and get reports from - different CI infrastructure builds simultaneously.
Diagnosing Issues and Improving Robustness
Overview
Teaching: 30 min
Exercises: 20 minQuestions
Once we know our program has errors, how can we locate them in the code?
How can we make our programs more resilient to failure?
Objectives
Use a debugger to explore behaviour of a running program
Describe and identify edge and corner test cases and explain why they are important
Apply error handling and defensive programming techniques to improve robustness of a program
Integrate linting tool style checking into a continuous integration job
Introduction
Unit testing can tell us something is wrong in our code and give a rough idea of where the error is by which test(s) are failing. But it does not tell us exactly where the problem is (i.e. what line of code), or how it came about. To give us a better idea of what is going on, we can:
- output program state at various points, e.g. by using print statements to output the contents of variables,
- use a logging capability to output the state of everything as the program progresses, or
- look at intermediately generated files.
But such approaches are often time consuming and sometimes not enough to fully pinpoint the issue. In complex programs, like simulation codes, we often need to get inside the code while it is running and explore. This is where using a debugger can be useful.
Setting the Scene
Let us add a new function called data_normalise() to our catchment example
to normalise a given measurement data array so that all entries fall between 0 and 1.
(Make sure you create a new feature branch for this work off your develop branch.)
To normalise each set of measurement data
we need to divide it by the maximum measurement value taken.
To do so, we can add the following code to catchment/models.py:
import numpy as np
...
def data_normalise(data):
"""Normalise any given 2D data array"""
max = np.array(np.max(data, axis=1))
return data / max[np.newaxis, :]
Note: there are intentional mistakes in the above code, which will be detected by further testing and code style checking below so bear with us for the moment.
For this work we will make use of the NumPy library. Pandas dataframes are built on top of NumPy arrays, which means that we can make use of the NumPy toolkit for manipulating Pandas data if we find that this would be more appropriate than using a Pandas tool.
In the code above, we first go column by column
and find the maximum data value for each measurement site
and store these values in a 1-dimensional NumPy array max.
We then want to use NumPy’s element-wise division,
to divide each value in every column of measurement data
(belonging to the same site)
by the maximum value for that site stored in the 1D array max.
However, we cannot do that division automatically
as data is a 2D array (of shape (2976, 2))
and max is a 1D array (of shape (, 2)),
which means that their shapes are not compatible.
Hence, to make sure that we can perform this division and get the expected result,
we need to convert max to be a 2D array
by using the newaxis index operator to insert a new axis into max,
making it a 2D array of shape (1, 2).
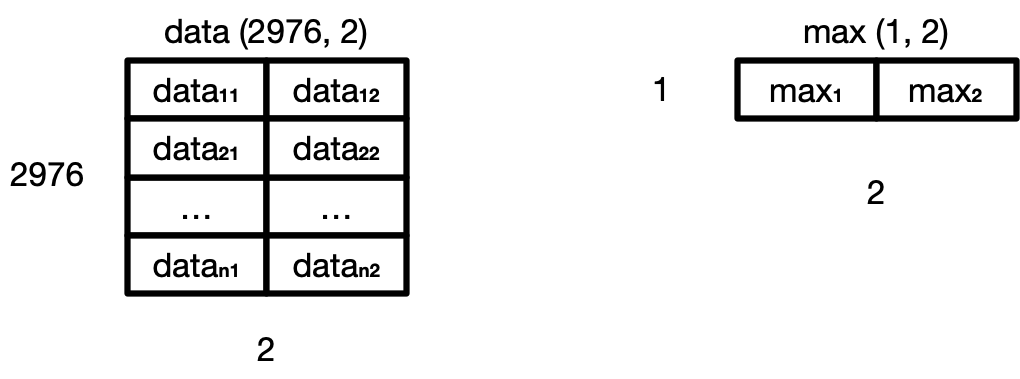
Now the division will give us the expected result.
Even though the shapes are not identical,
NumPy’s automatic broadcasting (adjustment of shapes) will make sure that
the shape of the 2D max array is now “stretched” (“broadcast”)
to match that of data - i.e. (2976, 2),
and element-wise division can be performed.
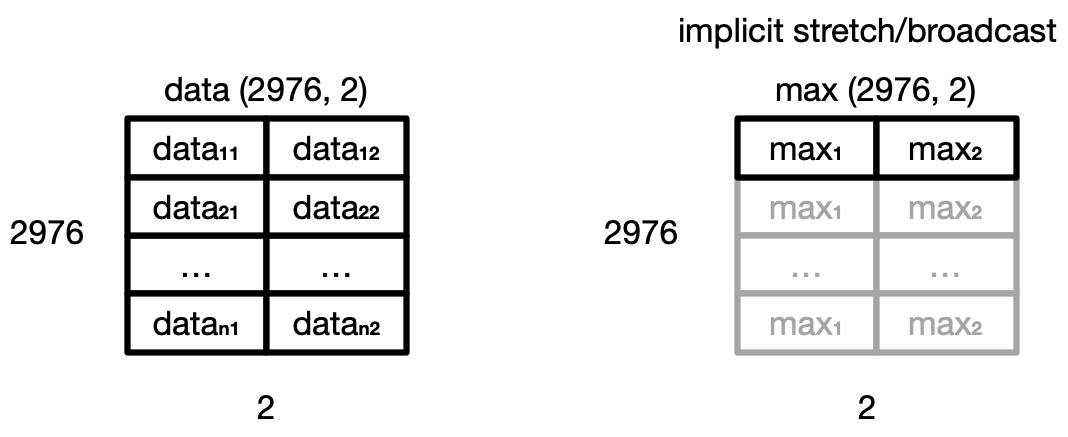
Broadcasting
The term broadcasting describes how NumPy treats arrays with different shapes during arithmetic operations. Subject to certain constraints, the smaller array is “broadcast” across the larger array so that they have compatible shapes. Be careful, though, to understand how the arrays get stretched to avoid getting unexpected results.
Note there is an assumption in this calculation that the minimum value we want is always zero. This is a sensible assumption for this particular application, since the zero value is a special case indicating that a patient experienced no inflammation on a particular day.
Let us now add a new test in tests/test_models.py
to check that the normalisation function is correct for some test data.
@pytest.mark.parametrize(
"test_data, test_index, test_columns, expected_data, expected_index, expected_columns",
[
(
[[1, 2, 3], [4, 5, 6], [7, 8, 9]],
[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
['A', 'B', 'C'],
[[0.14, 0.25, 0.33], [0.57, 0.63, 0.66], [1.0, 1.0, 1.0]],
[pd.to_datetime('2000-01-01 01:00'),
pd.to_datetime('2000-01-01 02:00'),
pd.to_datetime('2000-01-01 03:00')],
['A', 'B', 'C']
),
])
def test_normalise(test_data, test_index, test_columns, expected_data, expected_index, expected_columns):
"""Test normalisation works for arrays of one and positive integers.
Assumption that test accuracy of two decimal places is sufficient."""
from catchment.models import data_normalise
pdt.assert_frame_equal(data_normalise(pd.DataFrame(data=test_data, index=test_index, columns=test_columns)),
pd.DataFrame(data=expected_data, index=expected_index, columns=expected_columns),
atol=1e-2)
Note another assumption made here that a test accuracy of two decimal places is sufficient -
so we state this explicitly by setting the absolute tolerance of the tests using atol=1e-2,
and have rounded our expected values up accordingly.
The assert_frame_equal Pandas testing function allows
the setting of absolute (atol) and relative (rtol) tolerances
to enable testing against values that are almost equal:
very useful when we have numbers with arbitrary decimal places
and are only concerned with a certain degree of precision,
like the test case above.
Run the tests again using python -m pytest tests/test_models.py
and you will note that the new test is failing,
with an error message that does not give many clues as to what went wrong.
tests/test_models.py:142:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
pandas/_libs/testing.pyx:52: in pandas._libs.testing.assert_almost_equal
???
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
> ???
E AssertionError: DataFrame.iloc[:, 0] (column name="A") are different
E
E DataFrame.iloc[:, 0] (column name="A") values are different (100.0 %)
E [index]: [2000-01-01T01:00:00.000000000, 2000-01-01T02:00:00.000000000, 2000-01-01T03:00:00.000000000]
E [left]: [0.3333333333333333, 1.3333333333333333, 2.3333333333333335]
E [right]: [0.14, 0.57, 1.0]
Let us use a debugger at this point to see what is going on and why the function failed.
Debugging in VS Code
Think of debugging like performing exploratory surgery - on code! Debuggers allow us to peer at the internal workings of a program, such as variables and other state, as it performs its functions.
Running Tests Within VS Code
Firstly, to make it easier to track what’s going on, we can set up VS Code to run and debug our tests instead of running them from the command line. If you have not done so already, you will first need to enable the Pytest framework in VS Code. You can do this by:
- In VS Code, select the ‘Testing’ tab on the Activity Bar on the left side of the window
(icon resembles a chemistry flask/beaker).
If you have not yet configured any tests,
you will see a blue
Configure Python Testsbutton. If tests have already been configured and are incorrect, or you wish to review this process, open the Command Palette (Command+Shift+P for Mac, Control+Shift+P for Windows) and search forPython: Configure Tests(keeping the>character at the start of the search string). - Then, in the text search box that appears at the top of the edit window,
type
pytestand selectpytest pytest frameworkfrom the drop-down list. - You will be asked for the root directory of your tests.
Select the
testsfolder in our project folder. - The left hand panel will then display the
testsfolder with each of the files it contains.
We can now run pytest over our tests in VS Code,
similarly to how we ran our catchment-analysis.py script before.
In the Testing panel, right-click the test_models.py file in the tests folder.
under the tests directory in the file navigation window on the left,
and select Run test.
You’ll see the results of the tests appear in VS Code in a bottom panel.
If you scroll down in that panel you should see
the failed test_normalise() test result
looking something like the following:
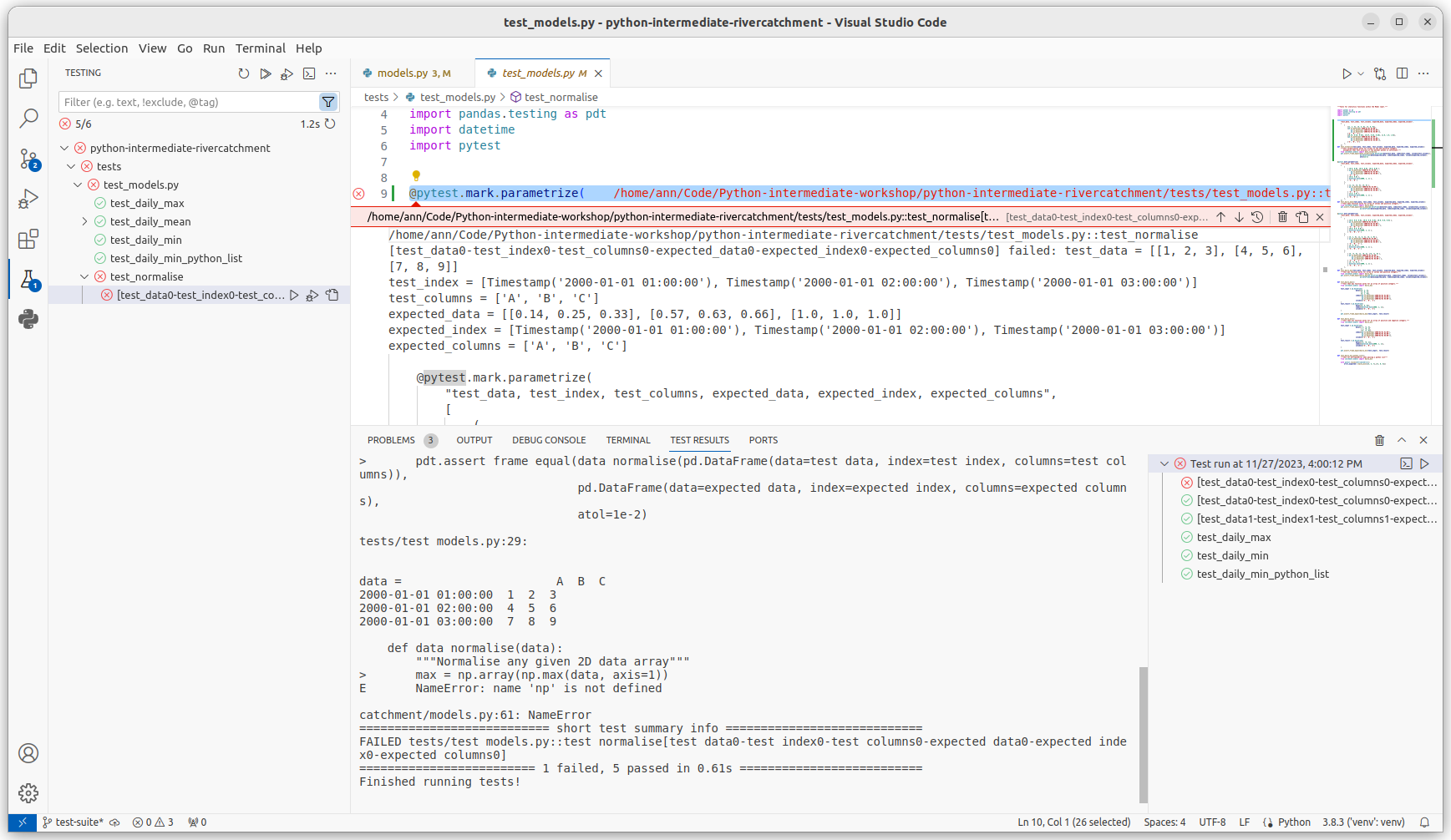
We can also run our test functions individually.
Click on a green check next to a test function
in our test_models.py script in VS Code,
(or right click it and select Run test),
we can run just that test:
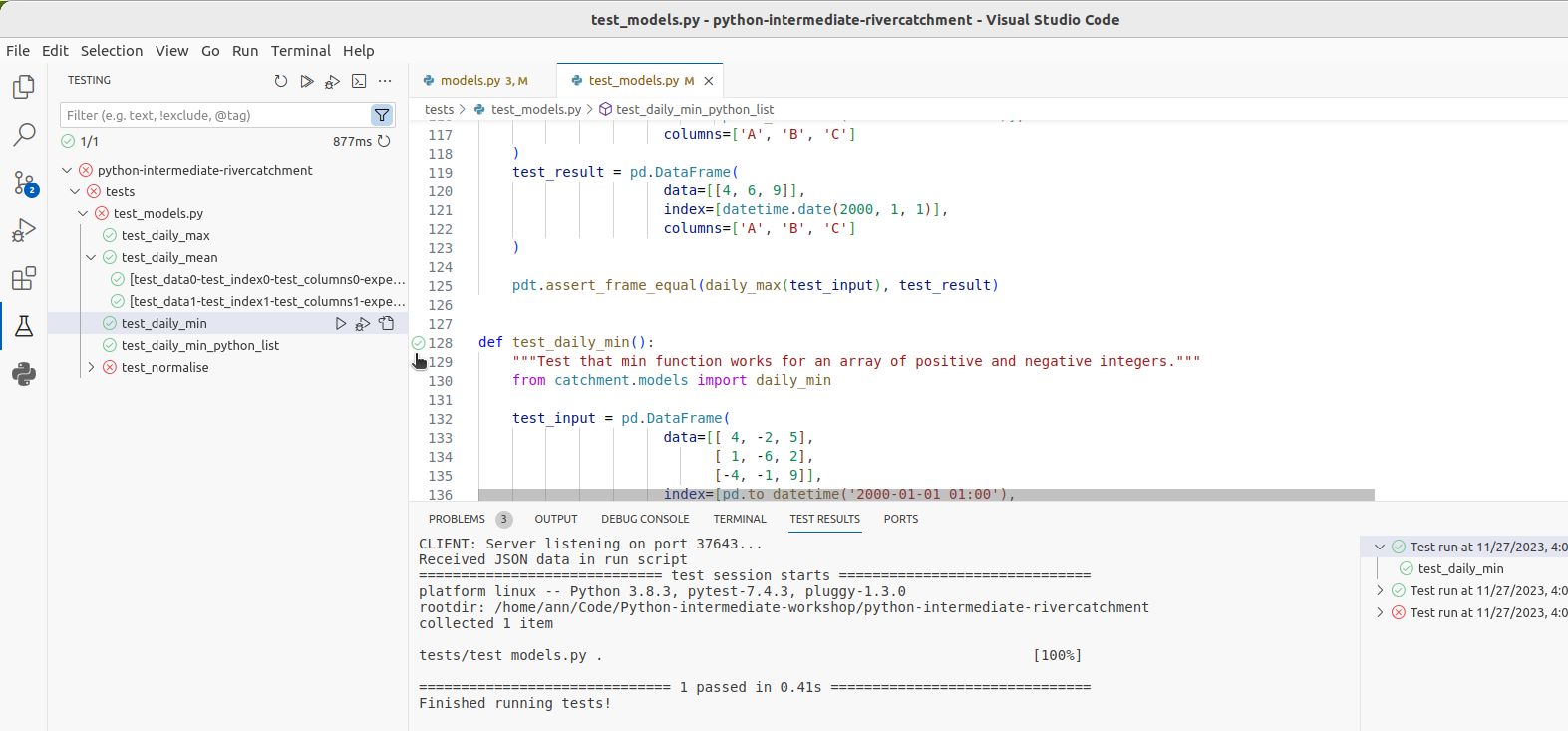
Click on the Run Test button next to test_normalise,
and you will be able to see that VS Code runs just that test function,
and we see the same AssertionError that we saw before.
Running the Debugger
Now we want to use the debugger to investigate
what is happening inside the data_normalise function.
To do this we will add a breakpoint in the code.
A breakpoint will pause execution at that point allowing us to explore the state of the program.
To set a breakpoint, navigate to the models.py file
and move your mouse to the return statement of the data_normalise function.
Click on just to the right of the line number for that line
and a small red dot will appear,
indicating that you have placed a breakpoint on that line.
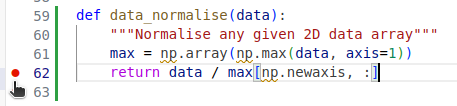
Now if you find test_models.py in the Testing panel, and locate the green play/right-arrow marker
for the test_normalise function
(in VS Code this appears next to the decorator function
@pytest.mark.parameterize that we recently added to test_normalise).
Right click on that arrow and select Debug Test from the drop down menu.
You will notice that execution will be paused
at the return statement of data_normalise,
where we placed our breakpoint.
In the debug panel that appears below,
we can now investigate the exact state of the program
prior to it executing this line of code.
In the debug panel on the left hand side, you will be able to see three sections that looks something like the following:
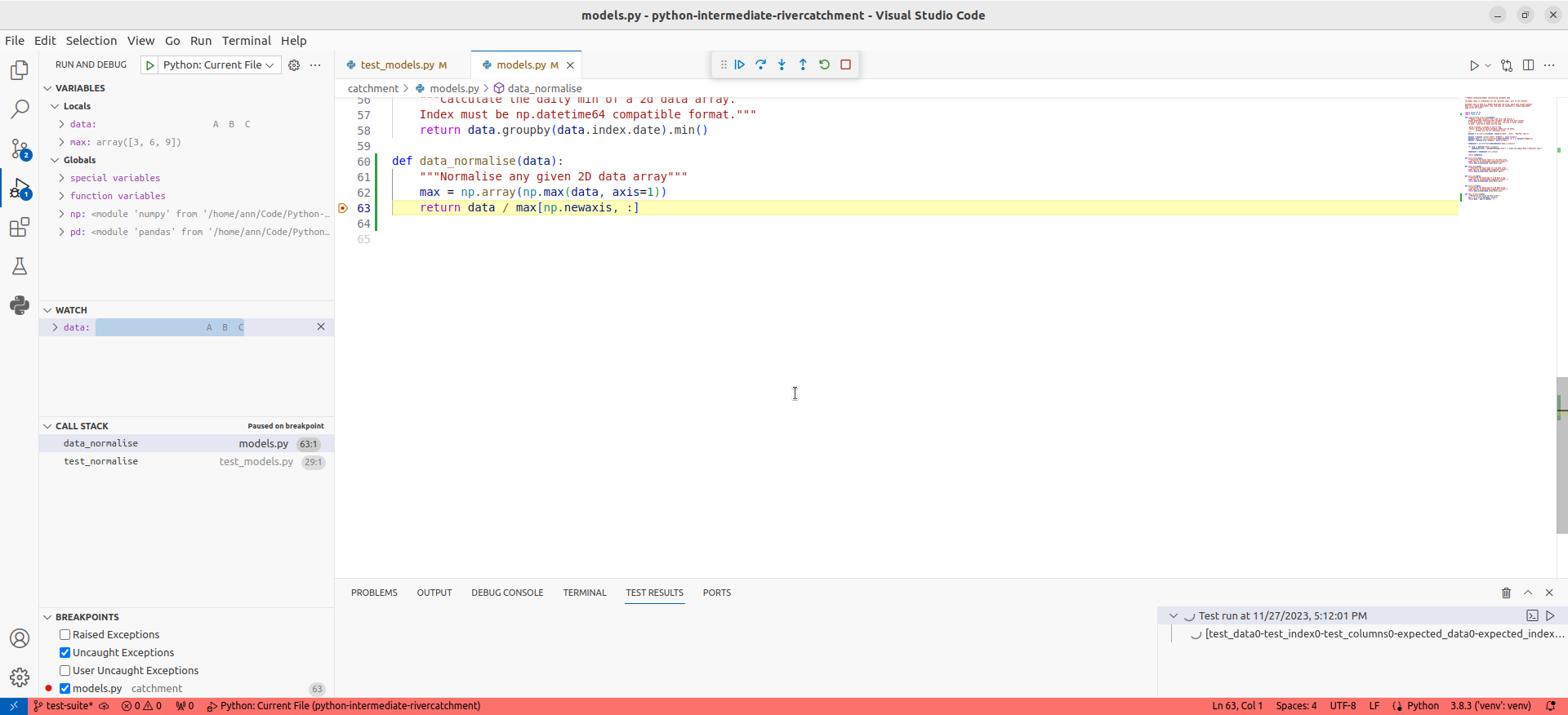
- The
Variablessection at the top, which displays the local and global variables currently in memory. You will be able to see thedataarray that is input to thedata_normalisefunction, as well as themaxlocal array that was created to hold the maximum inflammation values for each patient. - The
Watchsection in the middle where we can add/remove expressions that we need to evaluate. - The
Call Stacksection at the bottom, which shows the chain of functions that have been executed to lead to this point. We can traverse this chain of functions if we wish, to observe the state of each function.
We also have the ability run any Python code we wish at this point to explore the state of the program even further! This is useful if you want to view a particular combination of variables, or perhaps a single element or slice of an array to see what went wrong.
Select the Debug Console tab in the bottom panel,
and you’ll be presented with a Python prompt.
Try putting in the expression max[np.newaxis, :] into the console,
and you will be able to see the row vector that we are dividing data by
in the return line of the function.
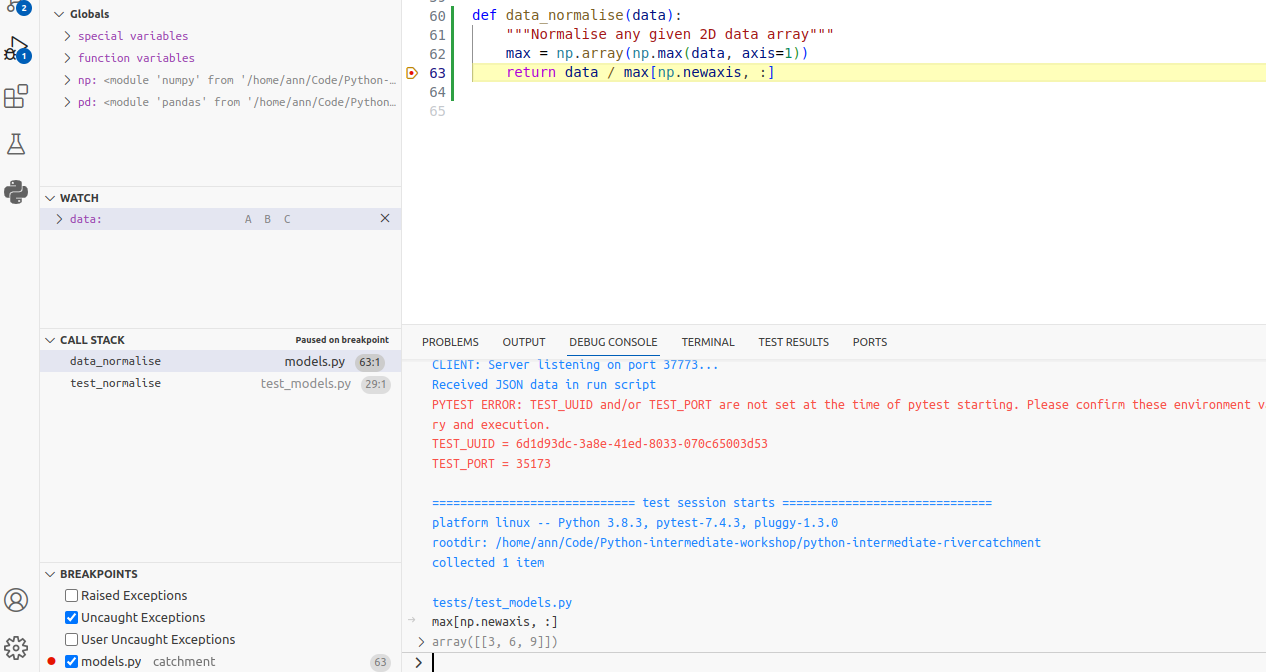
Now, looking at the max variable,
we can see that something looks wrong,
as the maximum values for each patient do not correspond to the data array.
Recall that the input data array we are using for the function is
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
So the maximum value for each measurement set (column) should be [7, 8, 9],
whereas the debugger shows [3, 6, 9].
You can see that the latter corresponds exactly to the last row of data,
and we can immediately conclude that
we took the maximum along the wrong axis of data.
Now we have our answer,
stop the debugging process by selecting
the red square at the top centre of the main VS Code editor window.
So to fix the data_normalise function in models.py,
change axis=1 in the first line of the function to axis=0.
With this fix in place,
running all the tests again should result in all tests passing.
Navigate back to the Testing tab (chemistry flask/beaker icon) on the left hand vertical bar and click on
the arrow next to test_models.py
You should be rewarded with:
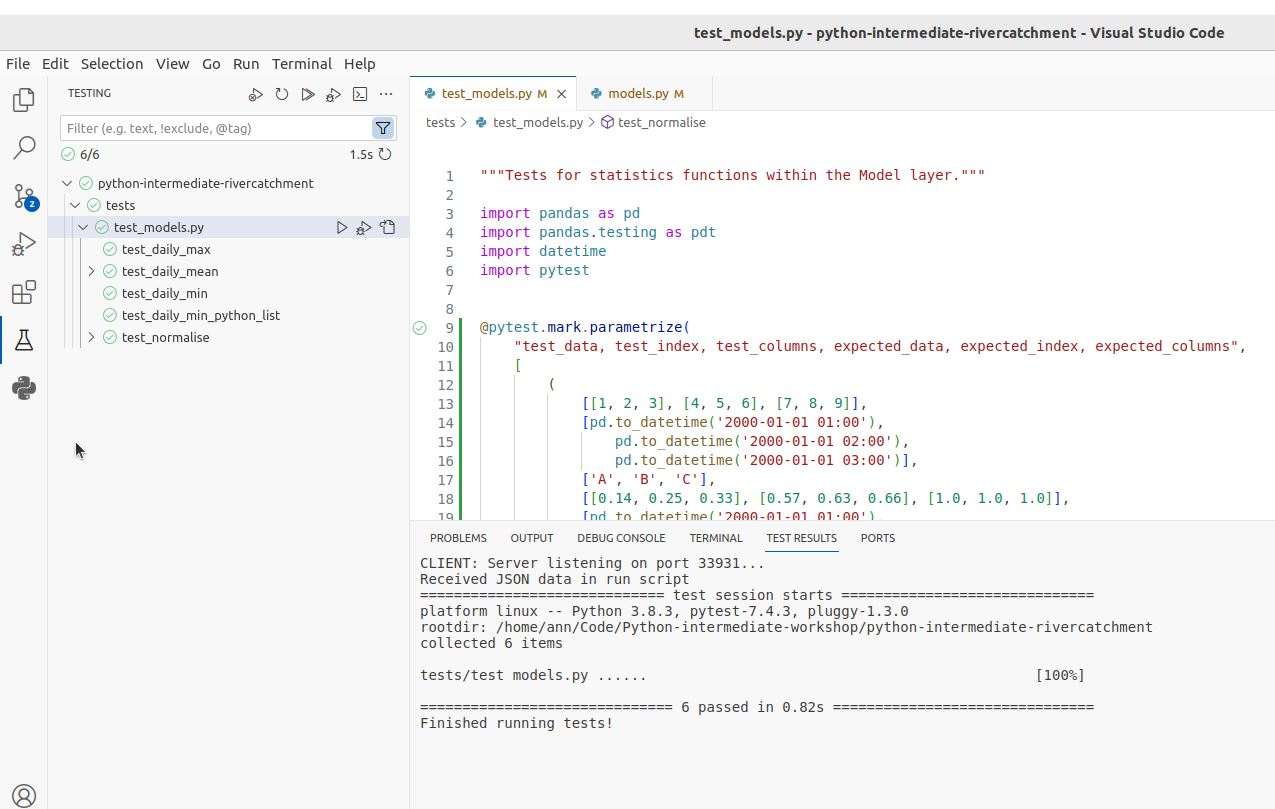
NumPy Axis
Getting the axes right in NumPy is not trivial - the following tutorial offers a good explanation on how axes work when applying NumPy functions to arrays.
NumPy vs Pandas: Reducing Test Complexity
So far we have used Pandas testing functions, because the functions we have been testing
make use of Pandas Dataframe functionality. However, even though we will be using the
data_normalise function on Pandas dataframes, the function itself does not actually
require Pandas functionality. The test above demonstrates that the data_normalise
function does not change the input dataframe in any unexpected way; the returned Dataframe
has the same indices and columns as the input Dataframe. Because we know this, we can
simplify the rest of our tests for this function, by using NumPy arrays and testing
functions, instead of the Pandas equivalents. Reducing complexity like this, where you
can, helps you understand what is being tested, and avoid possible confusions.
Before we carry on with new tests, we will reproduce the test above using NumPy, so that you can compare the two testing frameworks. Add an import statement for numpy.testing, and the test test_numpy_normalise, as shown below, to your test_models.py script. Then run the test to confirm it works as expected.
import numpy.testing as npt
...
@pytest.mark.parametrize(
"test, expected",
[
(
[[1, 2, 3], [4, 5, 6], [7, 8, 9]],
[[0.14, 0.25, 0.33], [0.57, 0.63, 0.66], [1.0, 1.0, 1.0]]
)
])
def test_numpy_normalise(test, expected):
"""Test normalisation works for numpy arrays"""
from catchment.models import data_normalise
npt.assert_almost_equal(data_normalise(np.array(test)), np.array(expected), decimal=2)
Note here that we are using the Numpy testing function npt.assert_almost_equal, which allows us to set a relevant test accuracy, using decimal=2. This is equivalent to the atol=1e-2 tolerance setting that we used for the equivalent Pandas test pdt.assert_frame_equal. Numpy also has a testing function npt.assert_array_equal, which tests for exact array matches. The functionality of this test is closely replicated by the default tolerance settings in pd.assert_frame_equal (atol=1e-8 and rtol=1e-5), and can be fully replicated by setting the option check_exact=True when using this function.
Corner or Edge Cases
The test case that we have currently written for data_normalise
is parameterised with a fairly standard data array.
However, when writing your test cases,
it is important to consider parameterising them by unusual or extreme values,
in order to test all the edge or corner cases that your code could be exposed to in practice.
Generally speaking, it is at these extreme cases that you will find your code failing,
so it’s beneficial to test them beforehand.
What is considered an “edge case” for a given component depends on
what that component is meant to do.
In the case of data_normalise function, the goal is to normalise a numeric array of numbers.
For numerical values, extreme cases could be zeros,
very large or small values,
not-a-number (NaN) or infinity values.
Since we are specifically considering an array of values,
an edge case could be that all the numbers of the array are equal.
For all the given edge cases you might come up with,
you should also consider their likelihood of occurrence.
It is often too much effort to exhaustively test a given function against every possible input,
so you should prioritise edge cases that are likely to occur.
For our data_normalise function, some common edge cases might be the occurrence of zeros,
and the case where all the values of the array are the same.
When you are considering edge cases to test for,
try also to think about what might break your code.
For data_normalise we can see that there is a division by
the maximum measurement value for each site,
so this will clearly break if we are dividing by zero here,
resulting in NaN values in the normalised array.
With all this in mind,
let us add a few edge cases to our parametrisation of test_numpy_normalise.
We will add two extra tests,
corresponding to an input array of all 0,
and an input array of all 1.
@pytest.mark.parametrize(
"test, expected",
[
(
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]]
),
(
[[1.0, 1.0, 1.0], [1.0, 1.0, 1.0], [1.0, 1.0, 1.0]],
[[1.0, 1.0, 1.0], [1.0, 1.0, 1.0], [1.0, 1.0, 1.0]]
),
(
[[1, 2, 3], [4, 5, 6], [7, 8, 9]],
[[0.14, 0.25, 0.33], [0.57, 0.63, 0.66], [1.0, 1.0, 1.0]]
)
])
def test_numpy_normalise(test, expected):
"""Test normalisation works for numpy arrays"""
from catchment.models import data_normalise
npt.assert_almost_equal(data_normalise(np.array(test)), np.array(expected), decimal=2)
Running the tests now from the command line results in the following assertion error, due to the division by zero as we predicted.
E AssertionError:
E Arrays are not almost equal to 2 decimals
E
E x and y nan location mismatch:
E x: array([[nan, nan, nan],
E [nan, nan, nan],
E [nan, nan, nan]])
E y: array([[0., 0., 0.],
E [0., 0., 0.],
E [0., 0., 0.]])
tests/test_models.py:160: AssertionError
How can we fix this?
Luckily, there is a NumPy function that is useful here,
np.isnan(),
which we can use to replace all the NaN’s with our desired result,
which is 0.
We can also silence the run-time warning using
np.errstate:
...
def data_normalise(data):
"""
Normalise any given 2D data array
NaN values are replaced with a value of 0
"""
max = np.array(np.max(data, axis=0))
with np.errstate(invalid='ignore', divide='ignore'):
normalised = data / max[np.newaxis, :]
normalised[np.isnan(normalised)] = 0.0
return normalised
...
Exercise: Exploring Tests for Edge Cases
Think of some more suitable edge cases to test our
data_normalise()function and add them to the parametrised tests. Remember to build tests for the functionality we want from the function - it does not matter at the moment if some of the tests fail. After you have finished remember to commit your changes.Possible Solution
@pytest.mark.parametrize( "test, expected", [ ( [[0, 0, 0], [0, 0, 0], [0, 0, 0]], [[0, 0, 0], [0, 0, 0], [0, 0, 0]], ), ( [[1, 1, 1], [1, 1, 1], [1, 1, 1]], [[1, 1, 1], [1, 1, 1], [1, 1, 1]], ), ( [[float('nan'), 1, 1], [1, 1, 1], [1, 1, 1]], [[0, 1, 1], [1, 1, 1], [1, 1, 1]], ), ( [[1, 2, 3], [4, 5, float('nan')], [7, 8, 9]], [[0.14, 0.25, 0.33], [0.57, 0.63, 0.0], [1.0, 1.0, 1.0]], ), ( [[-1, 2, 3], [4, 5, 6], [7, 8, 9]], [[0.0, 0.67, 1], [0.67, 0.83, 1], [0.78, 0.89, 1]], ), ( [[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[0.33, 0.67, 1], [0.67, 0.83, 1], [0.78, 0.89, 1]], ) ]) def test_numpy_normalise(test, expected): """Test normalisation works for numpy arrays of one and positive integers.""" from catchment.models import data_normalise npt.assert_almost_equal(data_normalise(np.array(test)), np.array(expected), decimal=2) ...You could also, for example, test and handle the case of a whole row of NaNs.
Defensive Programming
In the previous section, we made a few design choices for our data_normalise function:
- We are implicitly converting any
NaN, - Normalising a constant 0 array of inflammation results in an identical array of 0s,
- We don’t warn the user of any of these situations.
This could have be handled differently. We might decide that we do not want to silently make these changes to the data, but instead to explicitly check that the input data satisfies a given set of assumptions (e.g. no strings) and raise an error if this is not the case. Then we can proceed with the normalisation, confident that our normalisation function will work correctly.
Checking that input to a function is valid via a set of preconditions
is one of the simplest forms of defensive programming
which is used as a way of avoiding potential errors.
Preconditions are checked at the beginning of the function
to make sure that all assumptions are satisfied.
These assumptions are often based on the value of the arguments, like we have already discussed.
However, in a dynamic language like Python
one of the more common preconditions is to check that the arguments of a function
are of the correct type.
Currently there is nothing stopping someone from calling data_normalise with
a string, a dictionary, or another object that is not a pandas.DataFrame or numpy.ndarray.
As an example, let us change the behaviour of the data_normalise() function
to raise an error on negative inflammation values.
Edit the catchment/models.py file,
and add a precondition check to the beginning of the data_normalise() function like so:
...
if np.any(data < 0):
raise ValueError('Measurement values should not be negative')
...
We can then modify our test function in tests/test_models.py
to check that the function raises the correct exception - a ValueError -
when input to the test contains negative values
(i.e. input case [[-1, 2, 3], [4, 5, 6], [7, 8, 9]]).
The ValueError exception
is part of the standard Python library
and is used to indicate that the function received an argument of the right type,
but of an inappropriate value.
@pytest.mark.parametrize(
"test, expected, expect_raises",
[
... # previous test cases here, with None for expect_raises, except for the next one - add ValueError
... # as an expected exception (since it has a negative input value)
(
[[-1, 2, 3], [4, 5, 6], [7, 8, 9]],
[[0, 0.67, 1], [0.67, 0.83, 1], [0.78, 0.89, 1]],
ValueError,
),
(
[[1, 2, 3], [4, 5, 6], [7, 8, 9]],
[[0.33, 0.67, 1], [0.67, 0.83, 1], [0.78, 0.89, 1]],
None,
),
])
def test_normalise(test, expected, expect_raises):
"""Test normalisation works for arrays of one and positive integers."""
from catchment.models import data_normalise
if expect_raises is not None:
with pytest.raises(expect_raises):
npt.assert_almost_equal(data_normalise(np.array(test)), np.array(expected), decimal=2)
else:
npt.assert_almost_equal(data_normalise(np.array(test)), np.array(expected), decimal=2)
Be sure to commit your changes so far and push them to GitHub.
Optional Exercise: Add a Precondition to Check the Correct Type and Shape of Data
Add preconditions to check that data is a
DataFrameorndarrayobject and that it is of the correct shape. Add corresponding tests to check that the function raises the correct exception. You will find the Python functionisinstanceuseful here, as well as the Python exceptionTypeError. Once you are done, commit your new files, and push the new commits to your remote repository on GitHub.Solution
In
inflammation/models.py:... def data_normalise(data): """ Normalise any given 2D data array NaN values are replaced with a value of 0 :param data: 2D array of inflammation data :type data: ndarray """ if not isinstance(data, np.ndarray) or not isinstance(data, pd.DataFrame): raise TypeError('data input should be DataFrame or ndarray') if len(data.shape) != 2: raise ValueError('data array should be 2-dimensional') if np.any(data < 0): raise ValueError('Measurement values should be non-negative') max = np.nanmax(data, axis=0) with np.errstate(invalid='ignore', divide='ignore'): normalised = data / max[np.newaxis, :] normalised[np.isnan(normalised)] = 0 return normalised ...In
test/test_models.py:... @pytest.mark.parametrize( "test, expected, expect_raises", [ ... ( 'hello', None, TypeError, ), ( 3, None, TypeError, ), ( [[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[0.33, 0.67, 1], [0.67, 0.83, 1], [0.78, 0.89, 1]], None, ) ]) def test_data_normalise(test, expected, expect_raises): """Test normalisation works for arrays of one and positive integers.""" from catchment.models import data_normalise if isinstance(test, list): test = np.array(test) if expect_raises is not None: with pytest.raises(expect_raises): npt.assert_almost_equal(data_normalise(test), np.array(expected), decimal=2) else: npt.assert_almost_equal(data_normalise(test), np.array(expected), decimal=2) ...Note the conversion from
listtonp.arrayhas been moved out of the call tonpt.assert_almost_equal()within the test function, and is now only applied to list items (rather than all items). This allows for greater flexibility with our test inputs, since this wouldn’t work in the test case that uses a string.
If you do the challenge, again, be sure to commit your changes and push them to GitHub.
You should not take it too far by trying to code preconditions for every conceivable eventuality.
You should aim to strike a balance between
making sure you secure your function against incorrect use,
and writing an overly complicated and expensive function
that handles cases that are likely never going to occur.
For example, it would be sensible to validate the shape of your measurement data array
when it is actually read from the csv file (in load_csv),
and therefore there is no reason to test this again in data_normalise.
You can also decide against adding explicit preconditions in your code,
and instead state the assumptions and limitations of your code
for users of your code in the docstring
and rely on them to invoke your code correctly.
This approach is useful when explicitly checking the precondition is too costly.
Improving Robustness with Automated Code Style Checks
Let’s re-run Pylint over our project after having added some more code to it. From the project root do:
$ pylint catchment
You may see something like the following in Pylint’s output:
************* Module catchment.models
...
catchment/models.py:60:4: W0622: Redefining built-in 'max' (redefined-builtin)
...
The above output indicates that by using the local variable called max
in the data_normalise function,
we have redefined a built-in Python function called max.
This isn’t a good idea and may have some undesired effects
(e.g. if you redefine a built-in name in a global scope
you may cause yourself some trouble which may be difficult to trace).
Exercise: Fix Code Style Errors
Rename our local variable
maxto something else (e.g. call itmax), then rerun your tests and commit these latest changes and push them to GitHub using our usual feature branch workflow. Make sure yourdevelopandmainbranches are up to date.
It may be hard to remember to run linter tools every now and then.
Luckily, we can now add this Pylint execution to our continuous integration builds
as one of the extra tasks.
Since we’re adding an extra feature to our CI workflow,
let’s start this from a new feature branch from the develop branch:
$ git switch -c pylint-ci develop # note a shorthand for creating a branch from another and switching to it
Then to add Pylint to our CI workflow,
we can add the following step to our steps in .github/workflows/main.yml:
...
- name: Check style with Pylint
run: |
python3 -m pylint --fail-under=0 --reports=y catchment
...
Note we need to add --fail-under=0 otherwise
the builds will fail if we don’t get a ‘perfect’ score of 10!
This seems unlikely, so let’s be more pessimistic.
We’ve also added --reports=y which will give us a more detailed report of the code analysis.
Then we can just add this to our repo and trigger a build:
$ git add .github/workflows/main.yml
$ git commit -m "Add Pylint run to build"
$ git push
Then once complete, under the build(s) reports you should see an entry with the output from Pylint as before, but with an extended breakdown of the infractions by category as well as other metrics for the code, such as the number and line percentages of code, docstrings, comments, and empty lines.
So we specified a score of 0 as a minimum which is very low. If we decide as a team on a suitable minimum score for our codebase, we can specify this instead. There are also ways to specify specific style rules that shouldn’t be broken which will cause Pylint to fail, which could be even more useful if we want to mandate a consistent style.
We can specify overrides to Pylint’s rules in a file called .pylintrc
which Pylint can helpfully generate for us.
In our repository root directory:
$ pylint --generate-rcfile > .pylintrc
Looking at this file, you’ll see it’s already pre-populated.
No behaviour is currently changed from the default by generating this file,
but we can amend it to suit our team’s coding style.
For example, a typical rule to customise - favoured by many projects -
is the one involving line length.
You’ll see it’s set to 100, so let’s set that to a more reasonable 120.
While we’re at it, let’s also set our fail-under in this file:
...
# Specify a score threshold to be exceeded before program exits with error.
fail-under=0
...
# Maximum number of characters on a single line.
max-line-length=120
...
Don’t forget to remove the --fail-under argument to Pytest
in our GitHub Actions configuration file too,
since we don’t need it anymore.
Now when we run Pylint we won’t be penalised for having a reasonable line length. For some further hints and tips on how to approach using Pylint for a project, see this article.
Before moving on, be sure to commit all your changes
and then merge to the develop and main branches in the usual manner,
and push them all to GitHub.
Key Points
Unit testing can show us what does not work, but does not help us locate problems in code.
Use a debugger to help you locate problems in code.
A debugger allows us to pause code execution and examine its state by adding breakpoints to lines in code.
Use preconditions to ensure correct behaviour of code.
Ensure that unit tests check for edge and corner cases too.
Using linting tools to automatically flag suspicious programming language constructs and stylistic errors can help improve code robustness.
Section 3: Software Development as a Process
Overview
Teaching: 5 min
Exercises: 0 minQuestions
How can we design and write ‘good’ software that meets its goals and requirements?
Objectives
Describe the differences between writing code and engineering software.
Define the fundamental stages in a software development process.
List the benefits of following a process of software development.
In this section, we will take a step back from coding development practices and tools and look at the bigger picture of software as a process of development.
“If you fail to plan, you are planning to fail.” - Benjamin Franklin
Writing Code vs Engineering Software
Traditionally in academia, software - and the process of writing it - is often seen as a necessary but throwaway artefact in research. For example, there may be research questions for a given research project, code is created to answer those questions, the code is run over some data and analysed, and finally a publication is written based on those results. These steps are often taken informally.
The terms programming (or even coding) and software engineering are often used interchangeably. They are not. Programmers or coders tend to focus on one part of software development: implementation, more than any other. In academic research, often they are writing software for themselves, where they are their own stakeholders. And ideally, they write software from a design, that fulfils a research goal to publish research papers.
Someone who is engineering software takes a wider view:
- The lifecycle of software: recognises that software development is a process that proceeds from understanding what is needed, to writing the software and using/releasing it, to what happens afterwards.
- Who will (or may) be involved: software is written for stakeholders. This may only be the researcher initially, but there is an understanding that others may become involved later (even if that isn’t evident yet). A good rule of thumb is to always assume that code will be read and used by others later on, which includes yourself!
- Software (or code) is an asset: software inherently contains value - for example, in terms of what it can do, the lessons learned throughout its development, and as an implementation of a research approach (i.e. a particular research algorithm, process, or technical approach).
- As an asset, it could be reused: again, it may not be evident initially that the software will have use beyond its initial purpose or project, but there is an assumption that the software - or even just a part of it - could be reused in the future.
The Software Development Process
The typical stages of a software development process can be categorised as follows:
- Requirements gathering: the process of identifying and recording the exact requirements for a software project before it begins. This helps maintain a clear direction throughout development, and sets clear targets for what the software needs to do.
- Design: where the requirements are translated into an overall design for the software. It covers what will be the basic software ‘components’ and how they’ll fit together, as well as the tools and technologies that will be used, which will together address the requirements identified in the first stage.
- Implementation: the software is developed according to the design, implementing the solution that meets the requirements set out in the requirements gathering stage.
- Testing: the software is tested with the intent to discover and rectify any defects, and also to ensure that the software meets its defined requirements, i.e. does it actually do what it should do reliably?
- Deployment: where the software is deployed or in some way released, and used for its intended purpose within its intended environment.
- Maintenance: where updates are made to the software to ensure it remains fit for purpose, which typically involves fixing any further discovered issues and evolving it to meet new or changing requirements.
The process of following these stages, particularly when undertaken in this order, is referred to as the waterfall model of software development: each stage’s outputs flow into the next stage sequentially.
Whether projects or people that develop software are aware of them or not, these stages are followed implicitly or explicitly in every software project. What is required for a project (during requirements gathering) is always considered, for example, even if it isn’t explored sufficiently or well understood.
Following a process of development offers some major benefits:
- Stage gating: a quality gate at the end of each stage, where stakeholders review the stage’s outcomes to decide if that stage has completed successfully before proceeding to the next one (and even if the next stage is not warranted at all - for example, it may be discovered during requirements of design that development of the software isn’t practical or even required).
- Predictability: each stage is given attention in a logical sequence; the next stage should not begin until prior stages have completed. Returning to a prior stage is possible and may be needed, but may prove expensive, particularly if an implementation has already been attempted. However, at least this is an explicit and planned action.
- Transparency: essentially, each stage generates output(s) into subsequent stages, which presents opportunities for them to be published as part of an open development process.
- It saves time: a well-known result from empirical software engineering studies is that it becomes exponentially more expensive to fix mistakes in future stages. For example, if a mistake takes 1 hour to fix in requirements, it may take 5 times that during design, and perhaps as much as 20 times that to fix if discovered during testing.
In this section we will place the actual writing of software (implementation) within the context of the typical software development process:
- Explore the importance of software requirements, the different classes of requirements, and how we can interpret and capture them.
- How requirements inform and drive the design of software, the importance, role, and examples of software architecture, and the ways we can describe a software design.
- Implementation choices in terms of programming paradigms, looking at procedural, functional, and object oriented paradigms of development. Modern software will often contain instances of multiple paradigms, so it is worthwhile being familiar with them and knowing when to switch in order to make better code.
- How you can (and should) assess and update a software’s architecture when requirements change and complexity increases - is the architecture still fit for purpose, or are modifications and extensions becoming increasingly difficult to make?
Key Points
Software engineering takes a wider view of software development beyond programming (or coding).
Ensuring requirements are sufficiently captured is critical to the success of any project.
Following a process makes development predictable, can save time, and helps ensure each stage of development is given sufficient consideration before proceeding to the next.
Software Requirements
Overview
Teaching: 15 min
Exercises: 30 minQuestions
Where do we start when beginning a new software project?
How can we capture and organise what is required for software to function as intended?
Objectives
Describe the different types of software requirements.
Explain the difference between functional and non-functional requirements.
Describe some of the different kinds of software and explain how the environment in which software is used constrains its design.
Derive new user and solution requirements from business requirements.
The requirements of our software are the basis on which the whole project rests - if we get the requirements wrong, we’ll build the wrong software. However, it’s unlikely that we’ll be able to determine all of the requirements upfront. Especially when working in a research context, requirements are flexible and may change as we develop our software.
Types of Requirements
Requirements can be categorised in many ways, but at a high level a useful way to split them is into business requirements, user requirements, and solution requirements. Let’s take a look at these now.
Business Requirements
Business requirements describe what is needed from the perspective of the organisation, and define the strategic path of the project, e.g. to increase profit margin or market share, or embark on a new research area or collaborative partnership. These are captured in something like a Business Requirements Specification.
For adapting our catchment software project, example business requirements could include:
- BR1: improving the statistical quality of data reporting to meet the needs of external audits
- BR2: increase the throughput of data analyses to meet higher demand as more more measurement sites are added
Exercise: New Business Requirements
Think of a new hypothetical business-level requirements for this software. This can be anything you like, but be sure to keep it at the high-level of the business itself.
Solution
One hypothetical new business requirement (BR3) could be extending our data system to keep track of which catchment areas contain each measurement station.
Another hypothetical new business requirement (BR4) may be adding correlation tests between measurement sites - e.g. to help establish catchment response to rainfall.
User (or Stakeholder) Requirements
These define what particular stakeholder groups each expect from an eventual solution, essentially acting as a bridge between the higher-level business requirements and specific solution requirements. These are typically captured in a User Requirements Specification.
For our inflammation project, they could include things for trial managers such as (building on the business requirements):
- UR1.1 (from BR1): add support for statistical measures in generated trial reports as required by revised auditing standards (standard deviation, …)
- UR1.2 (from BR1): add support for producing textual representations of statistics in trial reports as required by revised auditing standards
- UR2.1 (from BR2): ability to have an individual data report processed and generated in under 30 seconds (if we assume it usually takes longer than that)
Exercise: New User Requirements
Break down your new business requirements from the previous exercise into a number of logical user requirements, ensuring they stay above the level and detail of implementation.
Solution
For our business requirement BR3 from the previous exercise, the new user/stakeholder requirements may be the ability to see all the measurement sites within a given catchment area (UR3.1), and to find out which catchment area any given measurement site is in (UR3.2).
For our business requirement BR4 from the previous exercise, the new user/stakeholder requirements may be the ability to see the correlations between each measurement site, and data type, in all reports and graphs (UR4.1).
Solution Requirements
Solution (or product) requirements describe characteristics that software must have to satisfy the stakeholder requirements. They fall into two key categories:
- Functional requirements focus on functions and features of a solution.
For our software, building on our user requirements, e.g.:
- SR1.1.1 (from UR1.1): add standard deviation to data model and include a graph visualisation view
- SR1.2.1 (from UR1.2): add a new view to generate a textual representation of statistics, which is invoked by an optional command line argument
- Non-functional requirements focus on
how the behaviour of a solution is expressed or constrained,
e.g. performance, security, usability, or portability.
These are also known as quality of service requirements.
For our project, e.g.:
- SR2.1.1 (from UR2.1): generate graphical statistics report on a project workstation configuration in under 30 seconds
Labelling Requirements
Note that the naming scheme we used for labelling our requirements is quite arbitrary - you should reference them in a way that is consistent and makes sense within your project and team.
The Importance of Non-functional Requirements
When considering software requirements, it’s very tempting to just think about the features users need. However, many design choices in a software project quite rightly depend on the users themselves and the environment in which the software is expected to run, and these aspects should be considered as part of the software’s non-functional requirements.
Exercise: Types of Software
Think about some software you are familiar with (could be software you have written yourself or by someone else) and how the environment it is used in have affected its design or development. Here are some examples of questions you can use to get started:
- What environment does the software run in?
- How do people interact with it?
- Why do people use it?
- What features of the software have been affected by these factors?
- If the software needed to be used in a different environment, what difficulties might there be?
Some examples of design / development choices constrained by environment might be:
- Mobile Apps
- Must have graphical interface suitable for a touch display
- Usually distributed via a controlled app store
- Users will not (usually) modify / compile the software themselves
- Should work on a range of hardware specifications with a range of Operating System (OS) versions
- But OS is unlikely to be anything other than Android or iOS
- Documentation probably in the software itself or on a Web page
- Typically written in one of the platform preferred languages (e.g. Java, Kotlin, Swift)
- Embedded Software
- May have no user interface - user interface may be physical buttons
- Usually distributed pre-installed on a physical device
- Often runs on low power device with limited memory and CPU performance - must take care to use these resources efficiently
- Exact specification of hardware is known - often not necessary to support multiple devices
- Documentation probably in a technical manual with a separate user manual
- May need to run continuously for the lifetime of the device
- Typically written in a lower-level language (e.g. C) for better control of resources
Some More Examples
- Desktop Application
- Has a graphical interface for use with mouse and keyboard
- May need to work on multiple, very different operating systems
- May be intended for users to modify / compile themselves
- Should work on a wide range of hardware configurations
- Documentation probably either in a manual or in the software itself
- Command-line Application - UNIX Tool
- User interface is text based, probably via command-line arguments
- Intended to be modified / compiled by users - though most will choose not to
- Documentation has standard formats - also accessible from the command line
- Should be usable as part of a pipeline
- Command-line Application - High Performance Computing
- Similar to a UNIX Tool
- Usually supports running across multiple networked machines simultaneously
- Usually operated via a scheduler - interface should be scriptable
- May need to run on a wide range of hardware (e.g. different CPU architectures)
- May need to process large amounts of data
- Often entirely or partially written in a lower-level language for performance (e.g. C, C++, Fortran)
- Web Application
- Usually has components which run on server and components which run on the user’s device
- Graphical interface should usually support both Desktop and Mobile devices
- Client-side component should run on a range of browsers and operating systems
- Documentation probably part of the software itself
- Client-side component typically written in JavaScript
Exercise: New Solution Requirements
Now break down your new user requirements from the earlier exercise into a number of logical solution requirements (functional and non-functional), that address the detail required to be able to implement them in the software.
Solution
For our new hypothetical business requirement BR3, new functional solution requirements could be extending the clinical trial system to keep track of:
- the names and location, or geographic extent, of all measurement sites (SR3.1.1) and catchment areas (SR3.1.2) involved in the project
- the name of the catchment area for a particular measurement site (SR3.1.3)
- a group of measurement sites within a particular catchment area (SR3.2.1).
Optional Exercise: Requirements for Your Software Project
Think back to a piece of code or software (either small or large) you’ve written, or which you have experience using. First, try to formulate a few of its key business requirements, then derive these into user and then solution requirements (in a similar fashion to the ones above in Types of Requirements).
Long- or Short-Lived Code?
Along with requirements, here’s something to consider early on. You, perhaps with others, may be developing open-source software with the intent that it will live on after your project completes. It could be important to you that your software is adopted and used by other projects as this may help you get future funding. It can make your software more attractive to potential users if they have the confidence that they can fix bugs that arise or add new features they need, if they can be assured that the evolution of the software is not dependant upon the lifetime of your project. The intended longevity and post-project role of software should be reflected in its requirements - particularly within its non-functional requirements - so be sure to consider these aspects.
On the other hand, you might want to knock together some code to prove a concept or to perform a quick calculation and then just discard it. But can you be sure you’ll never want to use it again? Maybe a few months from now you’ll realise you need it after all, or you’ll have a colleague say “I wish I had a…” and realise you’ve already made one. A little effort now could save you a lot in the future.
From Requirements to Implementation, via Design
In practice, these different types of requirements are sometimes confused and conflated when different classes of stakeholder are discussing them, which is understandable: each group of stakeholders has a different view of what is required from a project. The key is to understand the stakeholder’s perspective as to how their requirements should be classified and interpreted, and for that to be made explicit. A related misconception is that each of these types are simply requirements specified at different levels of detail. At each level, not only are the perspectives different, but so are the nature of the objectives and the language used to describe them, since they each reflect the perspective and language of their stakeholder group.
It’s often tempting to go right ahead and implement requirements within existing software, but this neglects a crucial step: do these new requirements fit within our existing design, or does our design need to be revisited? It may not need any changes at all, but if it doesn’t fit logically our design will need a bigger rethink so the new requirement can be implemented in a sensible way. We’ll look at this a bit later in this section, but simply adding new code without considering how the design and implementation need to change at a high level can make our software increasingly messy and difficult to change in the future.
Key Points
When writing software used for research, requirements will almost always change.
Consider non-functional requirements (how the software will behave) as well as functional requirements (what the software is supposed to do).
The environment in which users run our software has an effect on many design choices we might make.
Consider the expected longevity of any code before you write it.
The perspective and language of a particular requirement stakeholder group should be reflected in requirements for that group.
Software Architecture and Design
Overview
Teaching: 15 min
Exercises: 30 minQuestions
What should we consider when designing software?
How can we make sure the components of our software are reusable?
Objectives
Understand the use of common design patterns to improve the extensibility, reusability and overall quality of software.
Understand the components of multi-layer software architectures.
Introduction
In this episode, we’ll be looking at how we can design our software to ensure it meets the requirements, but also retains the other qualities of good software. As a piece of software grows, it will reach a point where there’s too much code for us to keep in mind at once. At this point, it becomes particularly important that the software be designed sensibly. What should be the overall structure of our software, how should all the pieces of functionality fit together, and how should we work towards fulfilling this overall design throughout development?
It’s not easy to come up with a complete definition for the term software design, but some of the common aspects are:
- Algorithm design - what method are we going to use to solve the core business problem?
- Software architecture - what components will the software have and how will they cooperate?
- System architecture - what other things will this software have to interact with and how will it do this?
- UI/UX (User Interface / User Experience) - how will users interact with the software?
As usual, the sooner you adopt a practice in the lifecycle of your project, the easier it will be. So we should think about the design of our software from the very beginning, ideally even before we start writing code - but if you didn’t, it’s never too late to start.
The answers to these questions will provide us with some design constraints which any software we write must satisfy. For example, a design constraint when writing a mobile app would be that it needs to work with a touch screen interface - we might have some software that works really well from the command line, but on a typical mobile phone there isn’t a command line interface that people can access.
Software Architecture
At the beginning of this episode we defined software architecture as an answer to the question “what components will the software have and how will they cooperate?”. Software engineering borrowed this term, and a few other terms, from architects (of buildings) as many of the processes and techniques have some similarities. One of the other important terms we borrowed is ‘pattern’, such as in design patterns and architecture patterns. This term is often attributed to the book ‘A Pattern Language’ by Christopher Alexander et al. published in 1977 and refers to a template solution to a problem commonly encountered when building a system.
Design patterns are relatively small-scale templates which we can use to solve problems which affect a small part of our software. For example, the adapter pattern (which allows a class that does not have the “right interface” to be reused) may be useful if part of our software needs to consume data from a number of different external data sources. Using this pattern, we can create a component whose responsibility is transforming the calls for data to the expected format, so the rest of our program doesn’t have to worry about it.
Architecture patterns are similar, but larger scale templates which operate at the level of whole programs, or collections or programs. Model-View-Controller (which we chose for our project) is one of the best known architecture patterns. Many patterns rely on concepts from Object Oriented Programming, so we’ll come back to the MVC pattern shortly after we learn a bit more about Object Oriented Programming.
There are many online sources of information about design and architecture patterns, often giving concrete examples of cases where they may be useful. One particularly good source is Refactoring Guru.
Multilayer Architecture
One common architectural pattern for larger software projects is Multilayer Architecture. Software designed using this architecture pattern is split into layers, each of which is responsible for a different part of the process of manipulating data.
Often, the software is split into three layers:
- Presentation Layer
- This layer is responsible for managing the interaction between our software and the people using it
- May include the View components if also using the MVC pattern
- Application Layer / Business Logic Layer
- This layer performs most of the data processing required by the presentation layer
- Likely to include the Controller components if also using an MVC pattern
- May also include the Model components
- Persistence Layer / Data Access Layer
- This layer handles data storage and provides data to the rest of the system
- May include the Model components of an MVC pattern if they’re not in the application layer
Although we’ve drawn similarities here between the layers of a system and the components of MVC, they’re actually solutions to different scales of problem. In a small application, a multilayer architecture is unlikely to be necessary, whereas in a very large application, the MVC pattern may be used just within the presentation layer, to handle getting data to and from the people using the software.
Addressing New Requirements
So, let’s assume we now want to extend our application - designed around an MVC architecture - with some new functionalities (more statistical processing and a new view to see measurement data). Let’s recall the solution requirements we discussed in the previous episode:
- Functional Requirements:
- SR1.1.1 (from UR1.1): add daily standard deviation to the data model and include in graph visualisation view
- SR1.2.1 (from UR1.2): add a new view to generate a textual representation of statistics, which is invoked by an optional command line argument
- Non-functional Requirements:
- SR2.1.1 (from UR2.1): generate graphical statistics report on project workstation configuration in under 30 seconds
How Should We Test These Requirements?
Sometimes when we make changes to our code that we plan to test later, we find the way we’ve implemented that change doesn’t lend itself well to how it should be tested. So what should we do?
Consider requirement SR1.2.1 - we have (at least) two things we should test in some way, for which we could write unit tests. For the textual representation of statistics, in a unit test we could invoke our new view function directly with known inflammation data and test the text output as a string against what is expected. The second one, invoking this new view with an optional command line argument, is more problematic since the code isn’t structured in a way where we can easily invoke the argument parsing portion to test it. To make this more amenable to unit testing we could move the command line parsing portion to a separate function, and use that in our unit tests. So in general, it’s a good idea to make sure your software’s features are modularised and accessible via logical functions.
We could also consider writing unit tests for SR2.1.1, ensuring that the system meets our performance requirement, so should we? We do need to verify it’s being met with the modified implementation, however it’s generally considered bad practice to use unit tests for this purpose. This is because unit tests test if a given aspect is behaving correctly, whereas performance tests test how efficiently it does it. Performance testing produces measurements of performance which require a different kind of analysis (using techniques such as code profiling), and require careful and specific configurations of operating environments to ensure fair testing. In addition, unit testing frameworks are not typically designed for conducting such measurements, and only test units of a system, which doesn’t give you an idea of performance of the system as it is typically used by stakeholders.
The key is to think about which kind of testing should be used to check if the code satisfies a requirement, but also what you can do to make that code amenable to that type of testing.
Exercise: Implementing Requirements
Pick one of the requirements SR1.1.1 or SR1.2.1 above to implement and create an appropriate feature branch - e.g.
add-std-devoradd-viewfrom your most up-to-datedevelopbranch.One aspect you should consider first is whether the new requirement can be implemented within the existing design. If not, how does the design need to be changed to accommodate the inclusion of this new feature? Also try to ensure that the changes you make are amenable to unit testing: is the code suitably modularised such that the aspect under test can be easily invoked with test input data and its output tested?
If you have time, feel free to implement the other requirement, or invent your own!
Also make sure you push changes to your new feature branch remotely to your software repository on GitHub.
Note: do not add the tests for the new feature just yet - even though you would normally add the tests along with the new code, we will do this in a later episode. Equally, do not merge your changes to the
developbranch just yet.Note 2: we have intentionally left this exercise without a solution to give you more freedom in implementing it how you see fit. If you are struggling with adding a new view and command line parameter, you may find adding the daily standard deviation requirement easier. A later episode in this section will look at how to handle command line parameters in a scalable way.
Best Practices for ‘Good’ Software Design
Aspirationally, what makes good code can be summarised in the following quote from the Intent HG blog:
“Good code is written so that is readable, understandable, covered by automated tests, not over complicated and does well what is intended to do.”
By taking time to design our software to be easily modifiable and extensible, we can save ourselves a lot of time later when requirements change. The sooner we do this the better - ideally we should have at least a rough design sketched out for our software before we write a single line of code. This design should be based around the structure of the problem we’re trying to solve: what are the concepts we need to represent and what are the relationships between them. And importantly, who will be using our software and how will they interact with it?
Here’s another way of looking at it.
Not following good software design and development practices can lead to accumulated ‘technical debt’, which (according to Wikipedia), is the “cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer”. So, the pressure to achieve project goals can sometimes lead to quick and easy solutions, which make the software become more messy, more complex, and more difficult to understand and maintain. The extra effort required to make changes in the future is the interest paid on the (technical) debt. It’s natural for software to accrue some technical debt, but it’s important to pay off that debt during a maintenance phase - simplifying, clarifying the code, making it easier to understand - to keep these interest payments on making changes manageable. If this isn’t done, the software may accrue too much technical debt, and it can become too messy and prohibitive to maintain and develop, and then it cannot evolve.
Importantly, there is only so much time available. How much effort should we spend on designing our code properly and using good development practices? The following XKCD comic summarises this tension:
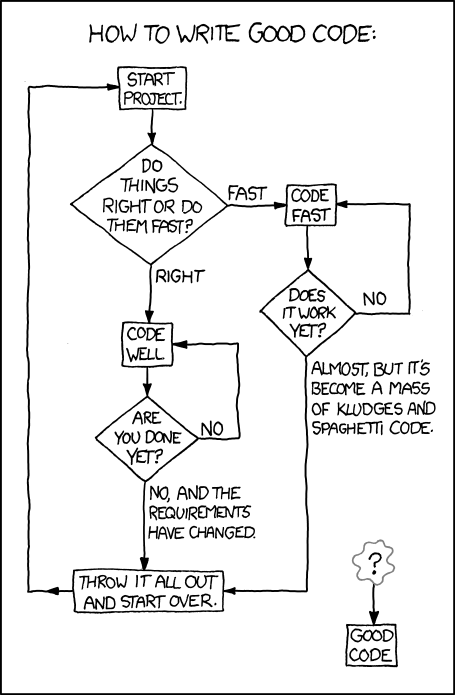
At an intermediate level there are a wealth of practices that could be used, and applying suitable design and coding practices is what separates an intermediate developer from someone who has just started coding. The key for an intermediate developer is to balance these concerns for each software project appropriately, and employ design and development practices enough so that progress can be made. It’s very easy to under-design software, but remember it’s also possible to over-design software too.
Key Points
Planning software projects in advance can save a lot of effort and reduce ‘technical debt’ later - even a partial plan is better than no plan at all.
By breaking down our software into components with a single responsibility, we avoid having to rewrite it all when requirements change. Such components can be as small as a single function, or be a software package in their own right.
When writing software used for research, requirements will almost always change.
‘Good code is written so that is readable, understandable, covered by automated tests, not over complicated and does well what is intended to do.’
Programming Paradigms
Overview
Teaching: 10 min
Exercises: 0 minQuestions
How does the structure of a problem affect the structure of our code?
How can we use common software paradigms to improve the quality of our software?
Objectives
Describe some of the major software paradigms we can use to classify programming languages.
Introduction
As you become more experienced in software development it becomes increasingly important to understand the wider landscape in which you operate, particularly in terms of the software decisions the people around you made and why? Today, there are a multitude of different programming languages, with each supporting at least one way to approach a problem and structure your code. In many cases, particularly with modern languages, a single language can allow many different structural approaches within your code.
One way to categorise these structural approaches is into paradigms. Each paradigm represents a slightly different way of thinking about and structuring our code and each has certain strengths and weaknesses when used to solve particular types of problems. Once your software begins to get more complex it’s common to use aspects of different paradigms to handle different subtasks. Because of this, it’s useful to know about the major paradigms, so you can recognise where it might be useful to switch.
There are two major families that we can group the common programming paradigms into: Imperative and Declarative. An imperative program uses statements that change the program’s state - it consists of commands for the computer to perform and focuses on describing how a program operates step by step. A declarative program expresses the logic of a computation to describe what should be accomplished rather than describing its control flow as a sequence steps.
We will look into three major paradigms from the imperative and declarative families that may be useful to you - Procedural Programming, Functional Programming and Object-Oriented Programming. Note, however, that most of the languages can be used with multiple paradigms, and it is common to see multiple paradigms within a single program - so this classification of programming languages based on the paradigm they use isn’t as strict.
Procedural Programming
Procedural Programming comes from a family of paradigms known as the Imperative Family. With paradigms in this family, we can think of our code as the instructions for processing data.
Procedural Programming is probably the style you’re most familiar with and the one we used up to this point, where we group code into procedures performing a single task, with exactly one entry and one exit point. In most modern languages we call these functions, instead of procedures - so if you’re grouping your code into functions, this might be the paradigm you’re using. By grouping code like this, we make it easier to reason about the overall structure, since we should be able to tell roughly what a function does just by looking at its name. These functions are also much easier to reuse than code outside of functions, since we can call them from any part of our program.
So far we have been using this technique in our code - it contains a list of instructions that execute one after the other starting from the top. This is an appropriate choice for smaller scripts and software that we’re writing just for a single use. Aside from smaller scripts, Procedural Programming is also commonly seen in code focused on high performance, with relatively simple data structures, such as in High Performance Computing (HPC). These programs tend to be written in C (which doesn’t support Object Oriented Programming) or Fortran (which didn’t until recently). HPC code is also often written in C++, but C++ code would more commonly follow an Object Oriented style, though it may have procedural sections.
Note that you may sometimes hear people refer to this paradigm as “functional programming” to contrast it with Object Oriented Programming, because it uses functions rather than objects, but this is incorrect. Functional Programming is a separate paradigm that places much stronger constraints on the behaviour of a function and structures the code differently as we’ll see soon.
Functional Programming
Functional Programming comes from a different family of paradigms - known as the Declarative Family. The Declarative Family is a distinct set of paradigms which have a different outlook on what a program is - here code describes what data processing should happen. What we really care about here is the outcome - how this is achieved is less important.
Functional Programming is built around a more strict definition of the term function borrowed from mathematics. A function in this context can be thought of as a mapping that transforms its input data into output data. Anything a function does other than produce an output is known as a side effect and should be avoided wherever possible.
Being strict about this definition allows us to break down the distinction between code and data, for example by writing a function which accepts and transforms other functions - in Functional Programming code is data.
The most common application of Functional Programming in research is in data processing, especially when handling Big Data. One popular definition of Big Data is data which is too large to fit in the memory of a single computer, with a single dataset sometimes being multiple terabytes or larger. With datasets like this, we can’t move the data around easily, so we often want to send our code to where the data is instead. By writing our code in a functional style, we also gain the ability to run many operations in parallel as it’s guaranteed that each operation won’t interact with any of the others - this is essential if we want to process this much data in a reasonable amount of time.
Object Oriented Programming
Object Oriented Programming focuses on the specific characteristics of each object and what each object can do. An object has two fundamental parts - properties (characteristics) and behaviours. In Object Oriented Programming, we first think about the data and the things that we’re modelling - and represent these by objects.
For example, if we’re writing a simulation for our chemistry research, we’re probably going to need to represent atoms and molecules. Each of these has a set of properties which we need to know about in order for our code to perform the tasks we want - in this case, for example, we often need to know the mass and electric charge of each atom. So with Object Oriented Programming, we’ll have some object structure which represents an atom and all of its properties, another structure to represent a molecule, and a relationship between the two (a molecule contains atoms). This structure also provides a way for us to associate code with an object, representing any behaviours it may have. In our chemistry example, this could be our code for calculating the force between a pair of atoms.
Most people would classify Object Oriented Programming as an extension of the Imperative family of languages (with the extra feature being the objects), but others disagree.
So Which one is Python?
Python is a multi-paradigm and multi-purpose programming language. You can use it as a procedural language and you can use it in a more object oriented way. It does tend to land more on the object oriented side as all its core data types (strings, integers, floats, booleans, lists, sets, arrays, tuples, dictionaries, files) as well as functions, modules and classes are objects.
Since functions in Python are also objects that can be passed around like any other object, Python is also well suited to functional programming. One of the most popular Python libraries for data manipulation, Pandas (built on top of NumPy), supports a functional programming style as most of its functions on data are not changing the data (no side effects) but producing a new data to reflect the result of the function.
Other Paradigms
The three paradigms introduced here are some of the most common, but there are many others which may be useful for addressing specific classes of problem - for much more information see the Wikipedia’s page on programming paradigms. Having mainly used Procedural Programming so far, we will now have a closer look at Functional and Object Oriented Programming paradigms and how they can affect our architectural design choices.
Key Points
A software paradigm describes a way of structuring or reasoning about code.
Different programming languages are suited to different paradigms.
Different paradigms are suited to solving different classes of problems.
A single piece of software will often contain instances of multiple paradigms.
Functional Programming
Overview
Teaching: 30 min
Exercises: 30 minQuestions
What is functional programming?
Which situations/problems is functional programming well suited for?
Objectives
Describe the core concepts that define the functional programming paradigm
Describe the main characteristics of code that is written in functional programming style
Learn how to generate and process data collections efficiently using MapReduce and Python’s comprehensions
Introduction
Functional programming is a programming paradigm where
programs are constructed by applying and composing/chaining functions.
Functional programming is based on the
mathematical definition of a function
f(),
which applies a transformation to some input data giving us some other data as a result
(i.e. a mapping from input x to output f(x)).
Thus, a program written in a functional style becomes a series of transformations on data
which are performed to produce a desired output.
Each function (transformation) taken by itself is simple and straightforward to understand;
complexity is handled by composing functions in various ways.
Often when we use the term function we are referring to a construct containing a block of code which performs a particular task and can be reused. We have already seen this in procedural programming - so how are functions in functional programming different? The key difference is that functional programming is focussed on what transformations are done to the data, rather than how these transformations are performed (i.e. a detailed sequence of steps which update the state of the code to reach a desired state). Let’s compare and contrast examples of these two programming paradigms.
Functional vs Procedural Programming
The following two code examples implement the calculation of a factorial
in procedural and functional styles, respectively.
Recall that the factorial of a number n (denoted by n!) is calculated as
the product of integer numbers from 1 to n.
The first example provides a procedural style factorial function.
def factorial(n):
"""Calculate the factorial of a given number.
:param int n: The factorial to calculate
:return: The resultant factorial
"""
if n < 0:
raise ValueError('Only use non-negative integers.')
factorial = 1
for i in range(1, n + 1): # iterate from 1 to n
# save intermediate value to use in the next iteration
factorial = factorial * i
return factorial
Functions in procedural programming are procedures that describe a detailed list of instructions to tell the computer what to do step by step and how to change the state of the program and advance towards the result. They often use iteration to repeat a series of steps. Functional programming, on the other hand, typically uses recursion - an ability of a function to call/repeat itself until a particular condition is reached. Let’s see how it is used in the functional programming example below to achieve a similar effect to that of iteration in procedural programming.
# Functional style factorial function
def factorial(n):
"""Calculate the factorial of a given number.
:param int n: The factorial to calculate
:return: The resultant factorial
"""
if n < 0:
raise ValueError('Only use non-negative integers.')
if n == 0 or n == 1:
return 1 # exit from recursion, prevents infinite loops
else:
return n * factorial(n-1) # recursive call to the same function
Note: You may have noticed that both functions in the above code examples have the same signature (i.e. they take an integer number as input and return its factorial as output). You could easily swap these equivalent implementations without changing the way that the function is invoked. Remember, a single piece of software may well contain instances of multiple programming paradigms - including procedural, functional and object-oriented - it is up to you to decide which one to use and when to switch based on the problem at hand and your personal coding style.
Functional computations only rely on the values that are provided as inputs to a function and not on the state of the program that precedes the function call. They do not modify data that exists outside the current function, including the input data - this property is referred to as the immutability of data. This means that such functions do not create any side effects, i.e. do not perform any action that affects anything other than the value they return. For example: printing text, writing to a file, modifying the value of an input argument, or changing the value of a global variable. Functions without side affects that return the same data each time the same input arguments are provided are called pure functions.
Exercise: Pure Functions
Which of these functions are pure? If you’re not sure, explain your reasoning to someone else, do they agree?
def add_one(x): return x + 1 def say_hello(name): print('Hello', name) def append_item_1(a_list, item): a_list += [item] return a_list def append_item_2(a_list, item): result = a_list + [item] return resultSolution
add_oneis pure - it has no effects other than to return a value and this value will always be the same when given the same inputssay_hellois not pure - printing text counts as a side effect, even though it is the clear purpose of the functionappend_item_1is not pure - the argumenta_listgets modified as a side effect - try this yourself to prove itappend_item_2is pure - the result is a new variable, so this timea_listdoes not get modified - again, try this yourself
Benefits of Functional Code
There are a few benefits we get when working with pure functions:
- Testability
- Composability
- Parallelisability
Testability indicates how easy it is to test the function - usually meaning unit tests. It is much easier to test a function if we can be certain that a particular input will always produce the same output. If a function we are testing might have different results each time it runs (e.g. a function that generates random numbers drawn from a normal distribution), we need to come up with a new way to test it. Similarly, it can be more difficult to test a function with side effects as it is not always obvious what the side effects will be, or how to measure them.
Composability refers to the ability to make a new function from a chain of other functions
by piping the output of one as the input to the next.
If a function does not have side effects or non-deterministic behaviour,
then all of its behaviour is reflected in the value it returns.
As a consequence of this, any chain of combined pure functions is itself pure,
so we keep all these benefits when we are combining functions into a larger program.
As an example of this, we could make a function called add_two,
using the add_one function we already have.
def add_two(x):
return add_one(add_one(x))
Parallelisability is the ability for operations to be performed at the same time (independently). If we know that a function is fully pure and we have got a lot of data, we can often improve performance by splitting data and distributing the computation across multiple processors. The output of a pure function depends only on its input, so we will get the right result regardless of when or where the code runs.
Everything in Moderation
Despite the benefits that pure functions can bring, we should not be trying to use them everywhere. Any software we write needs to interact with the rest of the world somehow, which requires side effects. With pure functions you cannot read any input, write any output, or interact with the rest of the world in any way, so we cannot usually write useful software using just pure functions. Python programs or libraries written in functional style will usually not be as extreme as to completely avoid reading input, writing output, updating the state of internal local variables, etc.; instead, they will provide a functional-appearing interface but may use non-functional features internally. An example of this is the Python Pandas library for data manipulation built on top of NumPy - most of its functions appear pure as they return new data objects instead of changing existing ones.
There are other advantageous properties that can be derived from the functional approach to coding. In languages which support functional programming, a function is a first-class object like any other object - not only can you compose/chain functions together, but functions can be used as inputs to, passed around or returned as results from other functions (remember, in functional programming code is data). This is why functional programming is suitable for processing data efficiently - in particular in the world of Big Data, where code is much smaller than the data, sending the code to where data is located is cheaper and faster than the other way round. Let’s see how we can do data processing using functional programming.
MapReduce Data Processing Approach
When working with data you will often find that you need to apply a transformation to each datapoint of a dataset and then perform some aggregation across the whole dataset. One instance of this data processing approach is known as MapReduce and is applied when processing (but not limited to) Big Data, e.g. using tools such as Spark or Hadoop. The name MapReduce comes from applying an operation to (mapping) each value in a dataset, then performing a reduction operation which collects/aggregates all the individual results together to produce a single result. MapReduce relies heavily on composability and parallelisability of functional programming - both map and reduce can be done in parallel and on smaller subsets of data, before aggregating all intermediate results into the final result.
Mapping
map(f, C) is a function takes another function f() and a collection C of data items as inputs.
Calling map(f, C) applies the function f(x) to every data item x in a collection C
and returns the resulting values as a new collection of the same size.
This is a simple mapping that takes a list of names and
returns a list of the lengths of those names using the built-in function len():
name_lengths = map(len, ["Mary", "Isla", "Sam"])
print(list(name_lengths))
[4, 4, 3]
This is a mapping that squares every number in the passed collection using anonymous, inlined lambda expression (a simple one-line mathematical expression representing a function):
squares = map(lambda x: x * x, [0, 1, 2, 3, 4])
print(list(squares))
[0, 1, 4, 9, 16]
Lambda
Lambda expressions are used to create anonymous functions that can be used to write more compact programs by inlining function code. A lambda expression takes any number of input parameters and creates an anonymous function that returns the value of the expression. So, we can use the short, one-line
lambda x, y, z, ...: expressioncode instead of defining and calling a named functionf()as follows:def f(x, y, z, ...): return expressionThe major distinction between lambda functions and ‘normal’ functions is that lambdas do not have names. We could give a name to a lambda expression if we really wanted to - but at that point we should be using a ‘normal’ Python function instead.
# Don't do this add_one = lambda x: x + 1 # Do this instead def add_one(x): return x + 1
In addition to using built-in or inlining anonymous lambda functions,
we can also pass a named function that we have defined ourselves to the map() function.
def add_one(num):
return num + 1
result = map(add_one, [0, 1, 2])
print(list(result))
[1, 2, 3]
Exercise: Check Measurement Data Against A Threshold Using Map
Write a new function called
data_above_threshold()in our catchmentmodels.pythat determines whether or not each measurement value for a given site exceeds a given threshold.Given a site identifier, the measurement dataframe itself, and a given threshold, write the function to use
map()to generate and return a list of booleans, with each value representing whether or not the measurement values for that given site exceeded the given threshold.Solution
def daily_above_threshold(site_id, data, threshold): """Determine whether or not each data value exceeds a given threshold for a given site. :param site_id: The identifier for the site column :param data: A 2D Pandas data frame with measurement data. Columns are measurement sites. :param threshold: A threshold value to check against :returns: A boolean list representing whether or not each data point for a given site exceeded the threshold """ return list(map(lambda x: x > threshold, data[site_id]))Note:
map()function returns a map iterator object which needs to be converted to a collection object (such as a list, dictionary, set, tuple) using the corresponding “factory” function (in our caselist()).
Comprehensions for Mapping/Data Generation
Another way you can generate new collections of data from existing collections in Python is
using comprehensions,
which are an elegant and concise way of creating data from
iterable objects using for loops.
While not a pure functional concept,
comprehensions provide data generation functionality
and can be used to achieve the same effect as the built-in “pure functional” function map().
They are commonly used and actually recommended as a replacement of map() in modern Python.
Let’s have a look at some examples.
integers = range(5)
double_ints = [2 * i for i in integers]
print(double_ints)
[0, 2, 4, 6, 8]
The above example uses a list comprehension to double each number in a sequence. Notice the similarity between the syntax for a list comprehension and a for loop - in effect, this is a for loop compressed into a single line. In this simple case, the code above is equivalent to using a map operation on a sequence, as shown below:
integers = range(5)
double_ints = map(lambda i: 2 * i, integers)
print(list(double_ints))
[0, 2, 4, 6, 8]
We can also use list comprehensions to filter data, by adding the filter condition to the end:
double_even_ints = [2 * i for i in integers if i % 2 == 0]
print(double_even_ints)
[0, 4, 8]
Set and Dictionary Comprehensions and Generators
We also have set comprehensions and dictionary comprehensions, which look similar to list comprehensions but use the set literal and dictionary literal syntax, respectively.
double_even_int_set = {2 * i for i in integers if i % 2 == 0} print(double_even_int_set) double_even_int_dict = {i: 2 * i for i in integers if i % 2 == 0} print(double_even_int_dict){0, 4, 8} {0: 0, 2: 4, 4: 8}Finally, there’s one last ‘comprehension’ in Python - a generator expression - a type of an iterable object which we can take values from and loop over, but does not actually compute any of the values until we need them. Iterable is the generic term for anything we can loop or iterate over - lists, sets and dictionaries are all iterables.
The
rangefunction is an example of a generator - if we created arange(1000000000), but didn’t iterate over it, we’d find that it takes almost no time to do. Creating a list containing a similar number of values would take much longer, and could be at risk of running out of memory.We can build our own generators using a generator expression. These look much like the comprehensions above, but act like a generator when we use them. Note the syntax difference for generator expressions - parenthesis are used in place of square or curly brackets.
doubles_generator = (2 * i for i in integers) for x in doubles_generator: print(x)0 2 4 6 8
Exercise: Comprehensions Applied
Within the
read_variable_from_csvfunction in thecatchment/models.pyfile contains a list comprehension. Can you identify which line of code this is, and work out what it does?Solution
The list comprehension is this line of code:
# catchment/models.py import pandas as pd ... dataset['Date'] = [pd.to_datetime(x,dayfirst=True) for x in dataset['OldDate']] ...It iterates over the date strings in the
OldDatecolumn within the dataframe, converts each string to apandasdatetime object, and adds these to the dataframe as theDatecolumn.
Let’s now have a look at reducing the elements of a data collection into a single result.
Reducing
reduce(f, C, initialiser) function accepts a function f(),
a collection C of data items
and an optional initialiser,
and returns a single cumulative value which
aggregates (reduces) all the values from the collection into a single result.
The reduction function first applies the function f() to the first two values in the collection
(or to the initialiser, if present, and the first item from C).
Then for each remaining value in the collection,
it takes the result of the previous computation
and the next value from the collection as the new arguments to f()
until we have processed all of the data and reduced it to a single value.
For example, if collection C has 5 elements, the call reduce(f, C) calculates:
f(f(f(f(C[0], C[1]), C[2]), C[3]), C[4])
One example of reducing would be to calculate the product of a sequence of numbers.
from functools import reduce
sequence = [1, 2, 3, 4]
def product(a, b):
return a * b
print(reduce(product, sequence))
# The same reduction using a lambda function
print(reduce((lambda a, b: a * b), sequence))
24
24
Note that reduce() is not a built-in function like map() -
you need to import it from library functools.
Exercise: Calculate the Sum of a Sequence of Numbers Using Reduce
Using reduce calculate the sum of a sequence of numbers. Although in practice we would use the built-in
sum()function for this - try doing it without it.Solution
from functools import reduce sequence = [1, 2, 3, 4] def add(a, b): return a + b print(reduce(add, sequence)) # The same reduction using a lambda function print(reduce((lambda a, b: a + b), sequence))10 10
Functions as First-Class Objects
Putting It All Together
Let’s now put together what we have learned about map and reduce so far by writing a function that calculates the sum of the squares of the values in a list using the MapReduce approach.
from functools import reduce
def sum_of_squares(sequence):
squares = [x * x for x in sequence] # use list comprehension for mapping
return reduce(lambda a, b: a + b, squares)
We should see the following behaviour when we use it:
print(sum_of_squares([0]))
print(sum_of_squares([1]))
print(sum_of_squares([1, 2, 3]))
print(sum_of_squares([-1]))
print(sum_of_squares([-1, -2, -3]))
0
1
14
1
14
Now let’s assume we’re reading in these numbers from an input file, so they arrive as a list of strings. We’ll modify the function so that it passes the following tests:
print(sum_of_squares(['1', '2', '3']))
print(sum_of_squares(['-1', '-2', '-3']))
14
14
The code may look like:
from functools import reduce
def sum_of_squares(sequence):
integers = [int(x) for x in sequence]
squares = [x * x for x in integers]
return reduce(lambda a, b: a + b, squares)
Finally, like comments in Python, we’d like it to be possible for users to comment out numbers in the input file they give to our program. We’ll finally extend our function so that the following tests pass:
print(sum_of_squares(['1', '2', '3']))
print(sum_of_squares(['-1', '-2', '-3']))
print(sum_of_squares(['1', '2', '#100', '3']))
14
14
14
To do so, we may filter out certain elements and have:
from functools import reduce
def sum_of_squares(sequence):
integers = [int(x) for x in sequence if x[0] != '#']
squares = [x * x for x in integers]
return reduce(lambda a, b: a + b, squares)
Exercise: Extend Data Threshold Function Using Reduce
Extend the
data_above_threshold()function you wrote previously to return a count of the number of data points for which the measurement data for a given site are over the threshold. Usereduce()over the boolean array that was previously returned to generate the count, then return that value from the function.You may choose to define a separate function to pass to
reduce(), or use an inline lambda expression to do it (which is a bit trickier!).Hints:
- Remember that you can define an
initialiservalue withreduce()to help you start the counter- If defining a lambda expression, note that it can conditionally return different values using the syntax
<value> if <condition> else <another_value>in the expression.Solution
Using a separate function:
from functools import reduce ... def data_above_threshold(site_id, data, threshold): """Count how many data points for a given site exceed a given threshold. :param site_id: The identifier for the site column :param data: A 2D Pandas data frame with measurement data. Columns are measurement sites. :param threshold: A threshold value to check against :returns: An integer representing the number of data points over a given threshold """ def count_above_threshold(a, b): if b: return a + 1 else: return a # Use map to determine if each daily inflammation value exceeds a given threshold for a patient above_threshold = map(lambda x: x > threshold, data[site_id]) # Use reduce to count on how many data points are above a threshold for a site return reduce(count_above_threshold, above_threshold, 0)Note that the
count_above_thresholdfunction used byreduce()was defined within thedata_above_threshold()function to limit its scope and clarify its purpose (i.e. it may only be useful as part ofdata_above_threshold()hence being defined as an inner function).The equivalent code using a lambda expression may look like:
from functools import reduce ... def data_above_threshold(site_id, data, threshold): """Count how many data points for a given site exceed a given threshold. :param site_id: The identifier for the site column :param data: A 2D Pandas data frame with measurement data. Columns are measurement sites. :param threshold: A threshold value to check against :returns: An integer representing the number of data points over a given threshold """ above_threshold = map(lambda x: x > threshold, data[site_id]) return reduce(lambda a, b: a + 1 if b else a, above_threshold, 0)Where could this be useful? For example, you could define a period as being particularly wet by saying that 60% of days exceed a given threshold of rain (by combining this function with the
daily_max), or some similar metrics.
Decorators
Finally, we will look at one last aspect of Python where functional programming is coming handy. As we have seen in the episode on parametrising our unit tests, a decorator can take a function, modify/decorate it, then return the resulting function. This is possible because Python treats functions as first-class objects that can be passed around as normal data. Here, we discuss decorators in more detail and learn how to write our own. Let’s look at the following code for ways on how to “decorate” functions.
def with_logging(func):
"""A decorator which adds logging to a function."""
def inner(*args, **kwargs):
print("Before function call")
result = func(*args, **kwargs)
print("After function call")
return result
return inner
def add_one(n):
print("Adding one")
return n + 1
# Redefine function add_one by wrapping it within with_logging function
add_one = with_logging(add_one)
# Another way to redefine a function - using a decorator
@with_logging
def add_two(n):
print("Adding two")
return n + 2
print(add_one(1))
print(add_two(1))
Before function call
Adding one
After function call
2
Before function call
Adding two
After function call
3
In this example, we see a decorator (with_logging)
and two different syntaxes for applying the decorator to a function.
The decorator is implemented here as a function which encloses another function.
Because the inner function (inner()) calls the function being decorated (func())
and returns its result,
it still behaves like this original function.
Part of this is the use of *args and **kwargs -
these allow our decorated function to accept any arguments or keyword arguments
and pass them directly to the function being decorated.
Our decorator in this case does not need to modify any of the arguments,
so we do not need to know what they are.
Any additional behaviour we want to add as part of our decorated function,
we can put before or after the call to the original function.
Here we print some text both before and after the decorated function,
to show the order in which events happen.
We also see in this example the two different ways in which a decorator can be applied.
The first of these is to use a normal function call (with_logging(add_one)),
where we then assign the resulting function back to a variable -
often using the original name of the function, so replacing it with the decorated version.
The second syntax is the one we have seen previously (@with_logging).
This syntax is equivalent to the previous one -
the result is that we have a decorated version of the function,
here with the name add_two.
Both of these syntaxes can be useful in different situations:
the @ syntax is more concise if we never need to use the un-decorated version,
while the function-call syntax gives us more flexibility -
we can continue to use the un-decorated function
if we make sure to give the decorated one a different name,
and can even make multiple decorated versions using different decorators.
Exercise: Measuring Performance Using Decorators
One small task you might find a useful case for a decorator is measuring the time taken to execute a particular function. This is an important part of performance profiling.
Write a decorator which you can use to measure the execution time of the decorated function using the time.process_time_ns() function. There are several different timing functions each with slightly different use-cases, but we won’t worry about that here.
For the function to measure, you may wish to use this as an example:
def measure_me(n): total = 0 for i in range(n): total += i * i return totalSolution
import time def profile(func): def inner(*args, **kwargs): start = time.process_time_ns() result = func(*args, **kwargs) stop = time.process_time_ns() print("Took {0} seconds".format((stop - start) / 1e9)) return result return inner @profile def measure_me(n): total = 0 for i in range(n): total += i * i return total print(measure_me(1000000))Took 0.124199753 seconds 333332833333500000
Key Points
Functional programming is a programming paradigm where programs are constructed by applying and composing smaller and simple functions into more complex ones (which describe the flow of data within a program as a sequence of data transformations).
In functional programming, functions tend to be pure - they do not exhibit side-effects (by not affecting anything other than the value they return or anything outside a function). Functions can also be named, passed as arguments, and returned from other functions, just as any other data type.
MapReduce is an instance of a data generation and processing approach, in particular suited for functional programming and handling Big Data within parallel and distributed environments.
Python provides comprehensions for lists, dictionaries, sets and generators - a concise (if not strictly functional) way to generate new data from existing data collections while performing sophisticated mapping, filtering and conditional logic on original dataset’s members.
Object Oriented Programming
Overview
Teaching: 30 min
Exercises: 20 minQuestions
How can we use code to describe the structure of data?
How should the relationships between structures be described?
Objectives
Describe the core concepts that define the object oriented paradigm
Use classes to encapsulate data within a more complex program
Structure concepts within a program in terms of sets of behaviour
Identify different types of relationship between concepts within a program
Structure data within a program using these relationships
Introduction
Object oriented programming is a programming paradigm based on the concept of objects, which are data structures that contain (encapsulate) data and code. Data is encapsulated in the form of fields (attributes) of objects, while code is encapsulated in the form of procedures (methods) that manipulate objects’ attributes and define “behaviour” of objects. So, in object oriented programming, we first think about the data and the things that we’re modelling - and represent these by objects - rather than define the logic of the program, and code becomes a series of interactions between objects.
Structuring Data
One of the main difficulties we encounter when building more complex software is how to structure our data. So far, we’ve been processing data from a single source and with a simple tabular structure, but it would be useful to be able to combine data from a range of different sources and with more data than just an array of numbers.
data = pd.DataFrame([[1., 2., 3.], [4., 5., 6.]],
index=['FP35','FP56'])
Using this data structure has the advantage of being able to use Pandas and NumPy operations to process the data, and Matplotlib to plot it, but often we need to have more structure than this. For example, the measurement data we are interested in has a hierarchy of situational information: each data set is recorded by a particular instrument, in a particular measurement site, in a particular catchment area. This structure can be captured using Pandas MultiIndexes, for example:
location_measurement = [
("FP", "FP35", "Rainfall"),
("FP", "FP56", "River Level"),
("PL", "PL23", "River Level"),
("PL", "PL23", "Water pH")
]
index_names = ["Catchment", "Site", "Measurement"]
index = pd.MultiIndex.from_tuples(location_measurement,names=index_names)
data = [
[0., 2., 1.],
[30., 29., 34.],
[34., 32., 33.],
[7.8, 8., 7.9]
]
pd.DataFrame(data,index=index)
0 1 2
Catchment Site Measurement
FP FP35 Rainfall 0.0 2.0 1.0
FP56 River Level 30.0 29.0 34.0
PL PL23 River Level 34.0 32.0 33.0
Water pH 7.8 8.0 7.9
However, we may need to attach more information about the sites and store this alongside our measurement data. Or we might want to store the data from different sites or instruments at different frequencies. These requirements are more difficult to accomodate within a Pandas DataFrame, and would require the use of extra data structures, or lead to messy data frames.
Instead, we can do this using the Python data structures we’re already familiar with, dictionaries and lists. For instance, we could attach an identifier to the measurements from each site:
measurement_data = [
{
'site': 'FP35',
'measurement': 'Rainfall'
'data': [0.0, 2.0, 1.0],
},
{
'site': 'FP56',
'measurement': 'River level'
'data': [30.0, 29.0, 34.0],
},
]
Exercise: Structuring Data
Write a function, called
attach_sites, which can be used to attach IDs to our measurement dataset. When used as below, it should produce the expected output.If you’re not sure where to begin, think about ways you might be able to effectively loop over two collections at once. Also, don’t worry too much about the data type of the
datavalue, it can be a Python list, a NumPy array, or a Pandas DataFrame - any is fine.data = np.array([[34., 32., 33.], [7.8, 8.0, 7.9]]) output = attach_information(data, ['PL23', 'PL23'], ['River Level', 'pH']) print(output)[ { 'site': 'PL23', 'measurement': 'River Level', 'data': [34., 32., 33.], }, { 'site': 'PL23', 'measurement': 'pH', 'data': [7.8, 8.0, 7.9], }, ]Solution
One possible solution, perhaps the most obvious, is to use the
rangefunction to index into all three lists at the same location:def attach_information(data, sites, measurements): """Create datastructure containing data from a range of sites and instruments.""" output = [] for i in range(len(data)): output.append({'site': sites[i], 'measurement': measurements[i], 'data': data[i]}) return outputHowever, this solution has a potential problem that can occur sometimes, depending on the input. What might go wrong with this solution? How could we fix it?
A Better Solution
What would happen if the
data,measurements, and/orsitesinputs were different lengths?If
sitesormeasurementsis longer, we’ll loop through, until we run out of rows in thedatainput, at which point we’ll stop processing the last few names. Ifdatais longer, we’ll loop through, but at some point we’ll run out of sites or measurements - but this time we try to access part of the list that doesn’t exist, so we’ll get an exception.A better solution would be to use the
zipfunction, which allows us to iterate over multiple iterables without needing an index variable. Thezipfunction also limits the iteration to whichever of the iterables is smaller, so we won’t raise an exception here, but this might not quite be the behaviour we want, so we’ll also explicitlyassertthat the inputs should be the same length. Checking that our inputs are valid in this way is an example of a precondition, which we introduced conceptually in an earlier episode.If you’ve not previously come across the
zipfunction, read this section of the Python documentation.def attach_names(data, sites, measurements): """Create datastructure containing measurement data from a range of sites.""" assert len(data) == len(sites) assert len(data) == len(measurements) output = [] for data_row, measurement, site in zip(data, measurements, sites): output.append({'site': site, 'measurement': measurement, 'data': data_row}) return output
Classes in Python
Using nested dictionaries and lists should work for some of the simpler cases where we need to handle structured data, but they get quite difficult to manage once the structure becomes a bit more complex. For this reason, in the object oriented paradigm, we use classes to help with managing this data and the operations we would want to perform on it. A class is a template (blueprint) for a structured piece of data, so when we create some data using a class, we can be certain that it has the same structure each time.
With our list of dictionaries we had in the example above,
we have no real guarantee that each dictionary has the same structure,
e.g. the same keys (site and data) unless we check it manually.
With a class, if an object is an instance of that class
(i.e. it was made using that template)
we know it will have the structure defined by that class.
Different programming languages make slightly different guarantees
about how strictly the structure will match,
but in object oriented programming this is one of the core ideas -
all objects derived from the same class must follow the same behaviour.
You may not have realised, but you should already be familiar with some of the classes that come bundled as part of Python, for example:
my_list = [1, 2, 3]
my_dict = {1: '1', 2: '2', 3: '3'}
my_set = {1, 2, 3}
print(type(my_list))
print(type(my_dict))
print(type(my_set))
<class 'list'>
<class 'dict'>
<class 'set'>
Lists, dictionaries and sets are a slightly special type of class, but they behave in much the same way as a class we might define ourselves:
- They each hold some data (attributes or state).
- They also provide some methods describing the behaviours of the data - what can the data do and what can we do to the data?
The behaviours we may have seen previously include:
- Lists can be appended to
- Lists can be indexed
- Lists can be sliced
- Key-value pairs can be added to dictionaries
- The value at a key can be looked up in a dictionary
- The union of two sets can be found (the set of values present in any of the sets)
- The intersection of two sets can be found (the set of values present in all of the sets)
Encapsulating Data
Let’s start with a minimal example of a class representing a measurement site.
# file: catchment/models.py
class Site:
def __init__(self, name):
self.name = name
self.measurements = {}
from catchment.models import Site
FP35 = Site('FP35')
print(FP35.name)
FP35
Here we’ve defined a class with one method: __init__.
This method is the initialiser method,
which is responsible for setting up the initial values and structure of the data
inside a new instance of the class -
this is very similar to constructors in other languages,
so the term is often used in Python too.
The __init__ method is called every time we create a new instance of the class,
as in Site('FP35').
The argument self refers to the instance on which we are calling the method
and gets filled in automatically by Python -
we don’t need to provide a value for this when we call the method.
Data encapsulated within our Site class includes the name of the site and a dictionary of measurement datasets. In the initialiser method, we set a site’s name to the value provided, and create a dictionary of measurement datasets for the site (initially empty). Such data is also referred to as the attributes of a class and holds the current state of an instance of the class. Attributes are typically hidden (encapsulated) internal object details ensuring that access to data is protected from unintended changes. They are manipulated internally by the class, which, in addition, can expose certain functionality as public behavior of the class to allow other objects to interact with this class’ instances.
Encapsulating Behaviour
In addition to representing a piece of structured data (e.g. a site which has a name and a dictionary of measurement data), a class can also provide a set of functions, or methods, which describe the behaviours of the data encapsulated in the instances of that class. To define the behaviour of a class we add functions which operate on the data the class contains. These functions are the member functions or methods.
Methods on classes are the same as normal functions,
except that they live inside a class and have an extra first parameter self.
Using the name self is not strictly necessary, but is a very strong convention -
it is extremely rare to see any other name chosen.
When we call a method on an object,
the value of self is automatically set to this object - hence the name.
As we saw with the __init__ method previously,
we do not need to explicitly provide a value for the self argument,
this is done for us by Python.
Let’s add another method on our Site class that adds a new measurement dataset to a Site instance.
# file: catchment/models.py
class Site:
"""A measurement site in the study."""
def __init__(self, name):
self.name = name
self.measurements = {}
def add_measurement(self, measurement_id, data):
if measurement_id in self.measurements.keys():
self.measurements[measurement_id] = \
pd.concat([self.measurements[measurement_id], data])
else:
self.measurements[measurement_id] = data
self.measurements[measurement_id].name = measurement_id
from catchment.models import Site
import pandas as pd
import datetime
FP35 = Site('FP35')
print(FP35)
rainfall_data = pd.Series(
[0.0,2.0,1.0],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3)
]
)
FP35.add_measurement('Rainfall',rainfall_data)
print(FP35.measurements.keys())
print(FP35.measurements['Rainfall'])
<__main__.Site object at 0x7fada93d0820>
dict_keys(['Rainfall'])
2000-01-01 0.0
2000-01-02 2.0
2000-01-03 1.0
Name: Rainfall, dtype: float64
Note here that we have created a pandas.Series object,
rather than a pandas.DataFrame object,
to contain our measurement data,
and that we are setting the name of each series to match the measurement_id.
DataFrames can be considered to be a collection of series,
each containing separate data.
Our Site object replaces the dataframe for this purpose,
later we will show you how to combine the series objects into dataframes again,
using the series name that we set here.
Class and Static Methods
Sometimes, the function we’re writing doesn’t need access to any data belonging to a particular object. For these situations, we can instead use a class method or a static method. Class methods have access to the class that they’re a part of, and can access data on that class - but do not belong to a specific instance of that class, whereas static methods have access to neither the class nor its instances.
By convention, class methods use
clsas their first argument instead ofself- this is how we access the class and its data, just likeselfallows us to access the instance and its data. Static methods have neitherselfnorclsso the arguments look like a typical free function. These are the only common exceptions to usingselffor a method’s first argument.Both of these method types are created using decorators - for more information see the classmethod and staticmethod decorator sections of the Python documentation.
Dunder Methods
Why is the __init__ method not called init?
There are a few special method names that we can use
which Python will use to provide a few common behaviours,
each of which begins and ends with a double-underscore,
hence the name dunder method.
When writing your own Python classes,
you’ll almost always want to write an __init__ method,
but there are a few other common ones you might need sometimes.
You may have noticed in the code above that the method print(FP35)
returned <__main__.Site object at 0x7fada93d0820>,
which is the string represenation of the FP35 object.
We may want the print statement to display the object’s name instead.
We can achieve this by overriding the __str__ method of our class.
# file: catchment/models.py
class Site:
"""A measurement site in the study."""
def __init__(self, name):
self.name = name
self.measurements = {}
def add_measurement(self, measurement_id, data):
if measurement_id in self.measurements.keys():
self.measurements[measurement_id] = \
pd.concat([self.measurements[measurement_id], data])
else:
self.measurements[measurement_id] = data
self.measurements[measurement_id].name = measurement_id
def __str__(self):
return self.name
from catchment.models import Site
FP35 = Site('FP35')
print(FP35)
FP35
These dunder methods are not usually called directly,
but rather provide the implementation of some functionality we can use -
we didn’t call FP35.__str__(),
but it was called for us when we did print(FP35).
Some we see quite commonly are:
__str__- converts an object into its string representation, used when you callstr(object)orprint(object)__getitem__- Accesses an object by key, this is howlist[x]anddict[x]are implemented__len__- gets the length of an object when we uselen(object)- usually the number of items it contains
There are many more described in the Python documentation, but it’s also worth experimenting with built in Python objects to see which methods provide which behaviour. For a more complete list of these special methods, see the Special Method Names section of the Python documentation.
Exercise: A Basic Class
Implement a class to represent a book. Your class should:
- Have a title
- Have an author
- When printed using
print(book), show text in the format “title by author”book = Book('A Book', 'Me') print(book)A Book by MeSolution
class Book: def __init__(self, title, author): self.title = title self.author = author def __str__(self): return self.title + ' by ' + self.author
Properties
The final special type of method we will introduce is a property. Properties are methods which behave like data - when we want to access them, we do not need to use brackets to call the method manually.
For example, we will add a method which will return the last data point in each measurement series, combined into a single dataframe:
# file: catchment/models.py
class Site:
...
@property
def last_measurements(self):
return pd.concat(
[self.measurements[key].series[-1:] for key in self.measurements.keys()],
axis=1).sort_index()
from catchment.models import Site
import pandas as pd
import datetime
PL23 = Site('PL23')
riverlevel_data = pd.Series(
[34.0,32.0,33.0,31.0],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3),
datetime.date(2000,1,4),
]
)
waterph_data = pd.Series(
[7.8,8.0,7.9],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3)
]
)
PL23.add_measurement('River Level', riverlevel_data)
PL23.add_measurement('Water pH', waterph_data)
lastdata = PL23.last_measurements
print(lastdata)
River Level Water pH
2000-01-03 NaN 7.9
2000-01-04 31.0 NaN
You may recognise the @ syntax from episodes on
parameterising unit tests and functional programming -
property is another example of a decorator.
In this case the property decorator is taking the last_measurements function
and modifying its behaviour,
so it can be accessed as if it were a normal attribute.
It is also possible to make your own decorators, but we won’t cover it here.
Relationships Between Classes
We now have a language construct for grouping data and behaviour related to a single conceptual object. The next step we need to take is to describe the relationships between the concepts in our code.
There are two fundamental types of relationship between objects which we need to be able to describe:
- Ownership - x has a y - this is composition
- Identity - x is a y - this is inheritance
Composition
You should hopefully have come across the term composition already - in the novice Software Carpentry, we use composition of functions to reduce code duplication. That time, we used a function which converted temperatures in Celsius to Kelvin as a component of another function which converted temperatures in Fahrenheit to Kelvin.
In the same way, in object oriented programming, we can make things components of other things.
We often use composition where we can say ‘x has a y’ - for example in our catchment study project, we might want to say that a catchment area has measurement sites or that a measurement site has a collection of measurement sets.
In the case of our example,
we have said any given measurement site has a collection of measurement sets,
so we’re already using composition here.
We’re currently implementing the collection of measurement sets
as a dictionary with a known set of keys though,
so maybe we should make a MeasurementSeries class as well.
This class will contain the Pandas Series it replaces,
but enable us to now associate extra information and methods with that dataset.
# file: catchment/models.py
class MeasurementSeries:
def __init__(self, series, name, units):
self.series = series
self.name = name
self.units = units
self.series.name = self.name
def add_measurement(self, data):
self.series = pd.concat([self.series,data])
self.series.name = self.name
def __str__(self):
if self.units:
return f"{self.name} ({self.units})"
else:
return self.name
class Site:
def __init__(self,name):
self.name = name
self.measurements = {}
def add_measurement(self, measurement_id, data, units=None):
if measurement_id in self.measurements.keys():
self.measurements[measurement_id].add_measurement(data)
else:
self.measurements[measurement_id] = MeasurementSeries(data, measurement_id, units)
@property
def last_measurements(self):
return pd.concat(
[self.measurements[key].series[-1:] for key in self.measurements.keys()],
axis=1).sort_index()
def __str__(self):
return self.name
from catchment.models import Site
import pandas as pd
PL23 = Site('PL23')
riverlevel_data = pd.Series(
[34.0,32.0,33.0,31.0],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3),
datetime.date(2000,1,4),
]
)
waterph_data = pd.Series(
[7.8,8.0,7.9],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3)
]
)
PL23.add_measurement('River Level', riverlevel_data, 'mm')
PL23.add_measurement('Water pH', waterph_data)
print(PL23.measurements['River Level'])
print(PL23.measurements['Water pH'])
lastdata = PL23.last_measurements
print(lastdata)
River Level (mm)
Water pH
River Level Water pH
2000-01-03 NaN 7.9
2000-01-04 31.0 NaN
Note that, within the Site class, we now access the measurement series by adding .series to the end of the self.measurements[measurement_id] object.
Note also how we used units=None in the parameter list of the add_measurement method, enabling us to still initialise the MeasurementSet class even if the end user doesn’t supply the measurement unit information. This is one of the common ways to handle an optional argument in Python, so we’ll see this pattern quite a lot in real projects.
Now we’re using a composition of two custom classes to describe the relationship between two types of entity in the system that we’re modelling.
Inheritance
The other type of relationship used in object oriented programming is inheritance.
Inheritance is about data and behaviour shared by classes,
because they have some shared identity - ‘x is a y’.
If class X inherits from (is a) class Y,
we say that Y is the superclass or parent class of X,
or X is a subclass of Y.
If we want to extend the previous example to also manage locations which aren’t measurement sites
we can add another class Location.
But Location will share some data and behaviour with Site -
in this case both have a name and show that name when you print them.
Since we expect all sites to be locations,
it makes sense to implement the behaviour in Location and then reuse it in Site.
To write our class in Python,
we used the class keyword, the name of the class,
and then a block of the functions that belong to it.
If the class inherits from another class,
we include the parent class name in brackets.
# file: catchment/models.py
class MeasurementSeries:
def __init__(self, series, name, units):
self.series = series
self.name = name
self.units = units
self.series.name = self.name
def add_measurement(self, data):
self.series = pd.concat([self.series,data])
self.series.name = self.name
def __str__(self):
if self.units:
return f"{self.name} ({self.units})"
else:
return self.name
class Location:
def __init__(self, name):
self.name = name
def __str__(self):
return self.name
class Site(Location):
def __init__(self,name):
super().__init__(name)
self.measurements = {}
def add_measurement(self, measurement_id, data, units=None):
if measurement_id in self.measurements.keys():
self.measurements[measurement_id].add_measurement(data)
else:
self.measurements[measurement_id] = MeasurementSeries(data, measurement_id, units)
@property
def last_measurements(self):
return pd.concat(
[self.measurements[key].series[-1:] for key in self.measurements.keys()],
axis=1).sort_index()
from catchment.models import Site
import pandas as pd
import datetime
FP23 = Site('FP23')
print(FP23)
riverlevel_data = pd.Series(
[34.0,32.0,33.0,31.0],
index=[
datetime.date(2000,1,1),
datetime.date(2000,1,2),
datetime.date(2000,1,3),
datetime.date(2000,1,4),
]
)
FP23.add_measurement('River Level',riverlevel_data,'mm')
print(FP23.measurements['River Level'].series)
PL12 = Location('PL12')
print(PL12)
PL12.add_measurement('River Level',riverlevel_data,'mm')
FP23
2000-01-01 34.0
2000-01-02 32.0
2000-01-03 33.0
2000-01-04 31.0
name: River Level, dtype: float 64
PL12
...
AttributeError: 'Location' object has no attribute 'add_measurement'
As expected, an error is thrown because we cannot add measurement data to PL12,
which is a Location but not a Site.
We see in the example above that to say that a class inherits from another, we put the parent class (or superclass) in brackets after the name of the subclass.
There’s something else we need to add as well -
Python doesn’t automatically call the __init__ method on the parent class
if we provide a new __init__ for our subclass,
so we’ll need to call it ourselves.
This makes sure that everything that needs to be initialised on the parent class has been,
before we need to use it.
If we don’t define a new __init__ method for our subclass,
Python will look for one on the parent class and use it automatically.
This is true of all methods -
if we call a method which doesn’t exist directly on our class,
Python will search for it among the parent classes.
The order in which it does this search is known as the method resolution order -
a little more on this in the Multiple Inheritance callout below.
The line super().__init__(name) gets the parent class,
then calls the __init__ method,
providing the name variable that Location.__init__ requires.
This is quite a common pattern, particularly for __init__ methods,
where we need to make sure an object is initialised as a valid X,
before we can initialise it as a valid Y -
e.g. a valid Location must have a name,
before we can properly initialise a Site model with the corresponding measurement data.
Composition vs Inheritance
When deciding how to implement a model of a particular system, you often have a choice of either composition or inheritance, where there is no obviously correct choice. For example, it’s not obvious whether a photocopier is a printer and is a scanner, or has a printer and has a scanner.
class Machine: pass class Printer(Machine): pass class Scanner(Machine): pass class Copier(Printer, Scanner): # Copier `is a` Printer and `is a` Scanner passclass Machine: pass class Printer(Machine): pass class Scanner(Machine): pass class Copier(Machine): def __init__(self): # Copier `has a` Printer and `has a` Scanner self.printer = Printer() self.scanner = Scanner()Both of these would be perfectly valid models and would work for most purposes. However, unless there’s something about how you need to use the model which would benefit from using a model based on inheritance, it’s usually recommended to opt for composition over inheritance. This is a common design principle in the object oriented paradigm and is worth remembering, as it’s very common for people to overuse inheritance once they’ve been introduced to it.
For much more detail on this see the Python Design Patterns guide.
Multiple Inheritance
Multiple Inheritance is when a class inherits from more than one direct parent class. It exists in Python, but is often not present in other Object Oriented languages. Although this might seem useful, like in our inheritance-based model of the photocopier above, it’s best to avoid it unless you’re sure it’s the right thing to do, due to the complexity of the inheritance heirarchy. Often using multiple inheritance is a sign you should instead be using composition - again like the photocopier model above.
Exercise: A Model Site
Let’s use what we have learnt in this episode and combine it with what we have learnt on software requirements to formulate and implement a few new solution requirements to extend the model layer of our measurement campaign system.
Let’s can start with extending the system such that there must be a
Catchmentclass to hold the data representing a single catchment, which:
- must have a
nameattribute- must have a dictionary of sites that are within this catchment area.
In addition to these, try to think of an extra feature you could add to the models which would be useful for managing a dataset like this - imagine we’re running a field measurement campaign, what else might we want to know? Try using Test Driven Development for any features you add: write the tests first, then add the feature. The tests have been started for you in
tests/test_sites.py, but you will probably want to add some more.Once you’ve finished the initial implementation, do you have much duplicated code? Is there anywhere you could make better use of composition or inheritance to improve your implementation?
For any extra features you’ve added, explain them and how you implemented them to your neighbour. Would they have implemented that feature in the same way?
Solution
One example solution is shown below. You may start by writing some tests (that will initially fail), and then develop the code to satisfy the new requirements and pass the tests.
# file: tests/test_sites.py """Tests for the Site model.""" def test_create_site(): """Check a site is created correctly given a name.""" from catchment.models import Site name = 'PL23' p = Site(name=name) assert p.name == name def test_create_catchment(): """Check a catchment is created correctly given a name.""" from catchment.models import Catchment name = 'Spain' catchment = Catchment(name=name) assert catchment.name == name def test_catchment_is_location(): """Check if a catchment is a location.""" from catchment.models import Catchment, Location catchment = Catchment("Spain") assert isinstance(catchment, Location) def test_site_is_location(): """Check if a site is a location.""" from catchment.models import Site, Location PL23 = Site("PL23") assert isinstance(PL23, Location) def test_sites_added_correctly(): """Check sites are being added correctly by a catchment. """ from catchment.models import Catchment, Site catchment = Catchment("Spain") PL23 = Site("PL23") catchment.add_site(PL23) assert catchment.sites is not None assert len(catchment.sites) == 1 def test_no_duplicate_sites(): """Check adding the same site to the same catchment twice does not result in duplicates. """ from catchment.models import Catchment, Site catchment = Catchment("Sheila Wheels") PL23 = Site("PL23") catchment.add_site(PL23) catchment.add_site(PL23) assert len(catchment.sites) == 1 ...# file: catchment/models.py ... class Location: """A Location.""" def __init__(self, name): self.name = name def __str__(self): return self.name class Site(Location): """A measurement site in the study.""" def __init__(self, name): super().__init__(name) self.measurements = {} def add_measurement(self, measurement_id, data, units=None): if measurement_id in self.measurements.keys(): self.measurements[measurement_id].add_measurement(data) else: self.measurements[measurement_id] = MeasurementSeries(data, measurement_id, units) @property def last_measurements(self): return pd.concat( [self.measurements[key].series[-1:] for key in self.measurements.keys()], axis=1).sort_index() class Catchment(Location): """A catchment area in the study.""" def __init__(self, name): super().__init__(name) self.sites = {} def add_site(self, new_site): # Basic check to see if the site has already been added to the catchment area for site in self.sites: if site == new_site: print(f'{new_site} has already been added to site list') return self.sites[new_site.name] = Site(new_site) ...
Geospatial Data
Once we have objects for both Sites and Catchments we can make use of the Geopandas library and geospatial data for each Site and Catchment to check the relationships between these. This is covered in the extra episode on Geospatial data with Geopandas.
Key Points
Object oriented programming is a programming paradigm based on the concept of classes, which encapsulate data and code.
Classes allow us to organise data into distinct concepts.
By breaking down our data into classes, we can reason about the behaviour of parts of our data.
Relationships between concepts can be described using inheritance (is a) and composition (has a).
Architecture Revisited: Extending Software
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How can we extend our software within the constraints of the MVC architecture?
Objectives
Extend our software to add a view of a single patient in the study and the software’s command line interface to request a specific view.
As we have seen, we have different programming paradigms that are suitable for different problems and affect the structure of our code. In programming languages that support multiple paradigms, such as Python, we have the luxury of using elements of different paradigms paradigms and we, as software designers and programmers, can decide how to use those elements in different architectural components of our software. Let’s now circle back to the architecture of our software for one final look.
MVC Revisited
We’ve been developing our software using the Model-View-Controller (MVC) architecture so far, but, as we have seen, MVC is just one of the common architectural patterns and is not the only choice we could have made.
There are many variants of an MVC-like pattern (such as Model-View-Presenter (MVP), Model-View-Viewmodel (MVVM), etc.), but in most cases, the distinction between these patterns isn’t particularly important. What really matters is that we are making decisions about the architecture of our software that suit the way in which we expect to use it. We should reuse these established ideas where we can, but we don’t need to stick to them exactly.
In this episode we’ll be taking our Object Oriented code from the previous episode
and integrating it into our existing MVC pattern.
But first we will explain some features of
the Controller (catchment-analysis.py) component of our architecture.
Controller file structure
You will have noticed already that structure of the catchment-analysis.py file
follows this pattern:
# import modules
def main():
# perform some actions
if __name__ == "__main__":
# perform some actions before main()
main()
In this pattern the actions performed by the script are contained within the main function
(which does not need to be called main,
but using this convention helps others in understanding your code).
The main function is then called within the if statement __name__ == "__main__",
after some other actions have been performed
(usually the parsing of command-line arguments, which will be explained below).
__name__ is a special dunder variable which is set,
along with a number of other special dunder variables,
by the python interpreter before the execution of any code in the source file.
What value is given by the interpreter to __name__ is determined by
the manner in which it is loaded.
If we run the source file directly using the Python interpreter, e.g.:
python catchment-analysis.py
then the interpreter will assign the hard-coded string "__main__" to the __name__ variable:
__name__ = "__main__"
...
# rest of your code
However, if your source file is imported by another Python script, e.g:
import catchment-analysis
then the interpreter will assign the name "catchment-analysis"
from the import statement to the __name__ variable:
__name__ = "catchment-analysis"
...
# rest of your code
Because of this behaviour of the interpreter,
we can put any code that should only be executed when running the script
directly within the if __name__ == "__main__": structure,
allowing the rest of the code within the script to be
safely imported by another script if we so wish.
While it may not seem very useful to have your controller script importable by another script, there are a number of situations in which you would want to do this:
- for testing of your code, you can have your testing framework import the main script,
and run special test functions which then call the
mainfunction directly; - where you want to not only be able to run your script from the command-line, but also provide a programmer-friendly application programming interface (API) for advanced users.
Passing Command-line Options to Controller
The standard python library for reading command line arguments passed to a script is
argparse.
This module reads arguments passed by the system,
and enables the automatic generation of help and usage messages.
These include, as we saw at the start of this course,
the generation of helpful error messages when users give the program invalid arguments.
The basic usage of argparse can be seen in the catchment-analysis.py script.
First we import the library:
import argparse
We then initialise the argument parser class, passing an (optional) description of the program:
parser = argparse.ArgumentParser(
description='A basic environmental data management system')
Once the parser has been initialised we can add the arguments that we want argparse to look out for. In our basic case, we want only the names of the file(s) to process:
parser.add_argument(
'infiles',
nargs='+',
help='Input CSV(s) containing measurement data')
Here we have defined what the argument will be called ('infiles') when it is read in;
the number of arguments to be expected
(nargs='+', where '+' indicates that there should be 1 or more arguments passed);
and a help string for the user
(help='Input CSV(s) containing measurement data').
You can add as many arguments as you wish,
and these can be either mandatory (as the one above) or optional.
Most of the complexity in using argparse is in adding the correct argument options,
and we will explain how to do this in more detail below.
Finally we parse the arguments passed to the script using:
args = parser.parse_args()
This returns an object (that we’ve called arg) containing all the arguments requested.
These can be accessed using the names that we have defined for each argument,
e.g. args.infiles would return the filenames that have been input.
The help for the script can be accessed using the -h or --help optional argument
(which argparse includes by default):
python catchment-analysis.py --help
usage: catchment-analysis.py [-h] infiles [infiles ...]
A basic environmental data management system
positional arguments:
infiles Input CSV(s) containing measurement data
optional arguments:
-h, --help show this help message and exit
The help page starts with the command line usage,
illustrating what inputs can be given (any within [] brackets are optional).
It then lists the positional and optional arguments,
giving as detailed a description of each as you have added to the add_argument() command.
Positional arguments are arguments that need to be included
in the proper position or order when calling the script.
Note that optional arguments are indicated by - or --, followed by the argument name.
Positional arguments are simply inferred by their position.
It is possible to have multiple positional arguments,
but usually this is only practical where all (or all but one) positional arguments
contains a clearly defined number of elements.
If more than one option can have an indeterminate number of entries,
then it is better to create them as ‘optional’ arguments.
These can be made a required input though,
by setting required = True within the add_argument() command.
Positional and Optional Argument Order
The usage section of the help page above shows the optional arguments going before the positional arguments. This is the customary way to present options, but is not mandatory. Instead there are two rules which must be followed for these arguments:
- Positional and optional arguments must each be given all together, and not inter-mixed. For example, the order can be either
optional - positionalorpositional - optional, but notoptional - positional - optional.- Positional arguments must be given in the order that they are shown in the usage section of the help page.
Now that you have some familiarity with argparse,
we will demonstrate below how you can use this to add extra functionality to your controller.
Choosing the Measurement Dataseries
Up until now we have only read the rainfall data from our data/rain_data_2015-12.csv file.
But what if we want to read the river measurement data too?
We can, simply, change the file that we are reading,
by passing a different file name.
But when we do this with the river data we get the following error:
python catchment-analysis.py data/river_data_2015-12.csv
Traceback (most recent call last):
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 39, in <module>
main(args)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment-analysis.py", line 22, in main
measurement_data = models.read_variable_from_csv(filename)
File "/Users/mbessdl2/work/manchester/Course_Material/Intermediate_Programming_Skills/python-intermediate-rivercatchment-template/catchment/models.py", line 22, in read_variable_from_csv
dataset = pd.read_csv(filename, usecols=['Date', 'Site', 'Rainfall (mm)'])
...
ValueError: Usecols do not match columns, columns expected but not found: ['Rainfall (mm)']
This error message tells us that the pandas read_csv function
has failed to find one of the columns that are listed to be read.
We would not expect a column called 'Rainfall (mm)' in the river data file,
so we need to make the read_variable_from_csv more flexible,
so that it can read any defined measurement dataset.
The first step is to add an argument to our command line interface,
so that users can specify the measurement dataset.
This can be done by adding the following argument to your catchment-analysis.py script:
parser.add_argument(
'-m', '--measurements',
help = 'Name of measurement data series to load',
required = True)
Here we have defined the name of the argument (--measurements),
as well as a short name (-m) for lazy users to use.
Note that the short name is preceded by a single dash (-),
while the full name is preceded by two dashes (--).
We provide a help string for the user,
and finally we set required = True,
so that the end user must define which data series they want to read.
Once this is added, then your help message should look like this:
python catchment-analysis.py --help
usage: catchment-analysis.py [-h] -m MEASUREMENTS infiles [infiles ...]
A basic environmental data management system
positional arguments:
infiles Input CSV(s) containing measurement data
optional arguments:
-h, --help show this help message and exit
-m MEASUREMENTS, --measurements MEASUREMENTS
Name of measurement data series to use
Optional vs Required Arguments, and Argument Groups
You will note that the
--measurementsargument is still listed as an optional argument. This is because the two basic option groups inargparseare positional and optional. In the usage section the--measurementsoption is listed without[]brackets, indicating that it is an expected argument, but still this is not very clear for end users.To make the help clearer we can add an extra argument group, and assign
--measurementsto this:... req_group = parser.add_argument_group('required arguments') ... req_group.add_argument( '-m', '--measurements', help = 'Name of measurement data series to load', required = True) ...This will return the following help message:
python catchment-analysis.py --helpusage: catchment-analysis.py [-h] -m MEASUREMENTS infiles [infiles ...] A basic environmental data management system positional arguments: infiles Input CSV(s) containing measurement data optional arguments: -h, --help show this help message and exit required arguments: -m MEASUREMENTS, --measurements MEASUREMENTS Name of measurement data series to useThis solution is not perfect, because the positional arguments are also required, but it will at least help end users distinguish between optional and required flagged arguments.
Default Argument Number and Type
argparsewill, by default, assume that each argument added will take a single value, and will be a string (type = str). If you want to change this for any argument you should explicitly settypeandnargs.Note also, that the returned object will be a single item unless
nargshas been set, in which case a list of items is returned (even ifnargs = 1is used).
Controller and Model Adaption
The new measurement string needs to be passed to the read_variable_from_csv function,
and applied appropriately within that function.
First we add a measurements argument to the read_variable_from_csv function in catchment/models.py
(remembering to update the function docstring at the same time):
# catchment/models.py
...
def read_variable_from_csv(filename, measurement):
"""Reads a named variable from a CSV file, and returns a
pandas dataframe containing that variable. The CSV file must contain
a column of dates, a column of site ID's, and (one or more) columns
of data - only one of which will be read.
:param filename: Filename of CSV to load
:param measurement: Name of data column to be read
:return: 2D array of given variable. Index will be dates,
Columns will be the individual sites
"""
...
Following this we need to change two lines of code, the first being the CSV reading code, and the second being the code which reorganises the dataset before it is returned:
# catchment/models.py
...
def read_variable_from_csv(filename, measurement):
...
dataset = pd.read_csv(filename, usecols=['Date', 'Site', measurement])
...
for site in dataset['Site'].unique():
newdataset[site] = dataset[dataset['Site'] == site].set_index('Date')[measurement]
...
Finally, within the main function of the controller we should add args.measurements as an argument:
# catchment-analysis.py
...
def main(args):
...
for filename in in_files:
measurement_data = models.read_variable_from_csv(filename, args.measurements)
...
You can now test your new code, to ensure it works as expected:
python catchment-analysis.py -m 'Rainfall (mm)' data/rain_data_2015-12.csv
python catchment-analysis.py -m 'pH continuous' data/river_data_2015-12.csv
Note that we have to use quotation marks to pass any strings which contain spaces or special characters, so that they are properly read by the parser.
Adding a new View
Now that we can select the data we require,
let’s add a view that allows us to see the data for a single site.
First, we need to add the code for the view itself
and make sure our Site class has the necessary data -
including the ability to pass a list of measurements to the __init__ method.
Note that your Site class may look very different now,
so adapt this example to fit what you have.
# file: catchment/views.py
...
def display_measurement_record(site):
"""Display each dataset for a single site."""
print(site.name)
for measurement in site.measurements:
print(site.measurements[measurement].series)
# file: catchment/models.py
...
class MeasurementSeries:
def __init__(self, series, name, units):
self.series = series
self.name = name
self.units = units
self.series.name = self.name
def add_measurement(self, data):
self.series = pd.concat([self.series,data])
self.series.name = self.name
def __str__(self):
if self.units:
return f"{self.name} ({self.units})"
else:
return self.name
class Location:
def __init__(self, name):
self.name = name
def __str__(self):
return self.name
class Site(Location):
def __init__(self,name):
super().__init__(name)
self.measurements = {}
def add_measurement(self, measurement_id, data, units=None):
if measurement_id in self.measurements.keys():
self.measurements[measurement_id].add_measurement(data)
else:
self.measurements[measurement_id] = MeasurementSeries(data, measurement_id, units)
@property
def last_measurements(self):
return pd.concat(
[self.measurements[key].series[-1:] for key in self.measurements.keys()],
axis=1).sort_index()
Now we need to make sure people can call this view - that means connecting it to the controller and ensuring that there’s a way to request this view when running the program.
Adapting the Controller
The changes we need to make here are that the main function
needs to be able to direct us to the view we’ve requested -
and we need to add to the command line interface - the controller -
the necessary data to drive the new view.
As the argument parsing routines are getting more involved, we have moved these into a
single function (parse_cli_arguments), to make the script more readable.
# file: catchment-analysis.py
#!/usr/bin/env python3
"""Software for managing measurement data for our catchment project."""
import argparse
from catchment import models, views
def main(args):
"""The MVC Controller of the patient data system.
The Controller is responsible for:
- selecting the necessary models and views for the current task
- passing data between models and views
"""
infiles = args.infiles
if not isinstance(infiles, list):
infiles = [args.infiles]
for filename in in_files:
measurement_data = models.read_variable_from_csv(filename, arg.measurements)
### MODIFIED START ###
if args.view == 'visualize':
view_data = {'daily sum': models.daily_total(measurement_data),
'daily average': models.daily_mean(measurement_data),
'daily max': models.daily_max(measurement_data),
'daily min': models.daily_min(measurement_data)}
views.visualize(view_data)
elif args.view == 'record':
measurement_data = measurement_data[args.site]
site = models.Site(args.site)
site.add_measurement(arg.measurements, measurement_data)
views.display_measurement_record(site)
### MODIFIED END ###
def parse_cli_arguments():
"""Definitions and logic tests for the CLI argument parser"""
parser = argparse.ArgumentParser(
description='A basic environmental data management system')
req_group = parser.add_argument_group('required arguments')
parser.add_argument(
'infiles',
nargs = '+',
help = 'Input CSV(s) containing measurement data')
req_group.add_argument(
'-m', '--measurements',
help = 'Name of measurement data series to load',
required = True)
### MODIFIED START ###
parser.add_argument(
'--view',
default = 'visualize',
choices = ['visualize', 'record'],
help = 'Which view should be used?')
parser.add_argument(
'--site',
type = str,
default = None,
help = 'Which site should be displayed?')
### MODIFIED END ###
args = parser.parse_args()
if args.view == 'record' and args.site is None:
parser.error("'record' --view requires that --site is set")
return args
if __name__ == "__main__":
args = parse_cli_arguments()
main(args)
We’ve added two options to our command line interface here:
one to request a specific view (--view)
and one for the site ID that we want to lookup (--site).
Note that both are optional,
but have default values if they are not set.
For the view option,
the default is for the graphic visualize view,
and we have set a defined list of choices that users are allowed to specify.
For the site option the default value is None.
We have added an if statement after the arguments are parsed,
but before calling the main function,
to ensure that the site option is set if we are using the record view,
which will return an error using the parser.error function:
python3 catchment-analysis.py --view record -m 'Rainfall (mm)' data/rain_data_2015-12.csv
usage: catchment-analysis.py [-h] -m MEASUREMENTS [--view {visualize,record}] [--site SITE] infiles [infiles ...]
catchment-analysis.py: error: 'record' --view requires that --site is set
Because we used the parser.error function,
the usage information for the command is given,
followed by the error message that we have added.
We can now call our program with these extra arguments to see the record for a single site:
$ python3 catchment-analysis.py --view record --site FP35 -m 'Rainfall (mm)' data/rain_data_2015-12.csv
FP35
2005-12-01 00:00:00 0.0
2005-12-01 00:15:00 0.0
2005-12-01 00:30:00 0.0
2005-12-01 00:45:00 0.0
2005-12-01 01:00:00 0.0
...
2005-12-31 22:45:00 0.2
2005-12-31 23:00:00 0.0
2005-12-31 23:15:00 0.2
2005-12-31 23:30:00 0.2
2005-12-31 23:45:00 0.0
Name: Rainfall, Length: 2976, dtype: float64
For the full range of features that we have access to with argparse see the
Python module documentation.
Allowing the user to request a specific view like this is
a similar model to that used by the popular Python library Click -
if you find yourself needing to build more complex interfaces than this,
Click would be a good choice.
You can find more information in Click’s documentation.
Additional Material
Now that we’ve covered the basics of different programming paradigms and how we can integrate them into our multi-layer architecture, there are two optional extra episodes which you may find interesting.
Both episodes cover the persistence layer of software architectures and methods of persistently storing data, but take different approaches. The episode on persistence with JSON covers some more advanced concepts in Object Oriented Programming, while the episode on databases starts to build towards a true multilayer architecture, which would allow our software to handle much larger quantities of data.
Towards Collaborative Software Development
Having looked at some theoretical aspects of software design, we are now circling back to implementing our software design and developing our software to satisfy the requirements collaboratively in a team. At an intermediate level of software development, there is a wealth of practices that could be used, and applying suitable design and coding practices is what separates an intermediate developer from someone who has just started coding. The key for an intermediate developer is to balance these concerns for each software project appropriately, and employ design and development practices enough so that progress can be made.
One practice that should always be considered, and has been shown to be very effective in team-based software development, is that of code review. Code reviews help to ensure the ‘good’ coding standards are achieved and maintained within a team by having multiple people have a look and comment on key code changes to see how they fit within the codebase. Such reviews check the correctness of the new code, test coverage, functionality changes, and confirm that they follow the coding guides and best practices. Let’s have a look at some code review techniques available to us.
Key Points
By breaking down our software into components with a single responsibility, we avoid having to rewrite it all when requirements change. Such components can be as small as a single function, or be a software package in their own right.
Section 4: Collaborative Software Development for Reuse
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What practices help us develop software collaboratively that will make it easier for us and others to further develop and reuse it?
Objectives
Understand the code review process and employ it to improve the quality of code.
Understand the process and best practices for preparing Python code for reuse by others.
When changes - particularly big changes - are made to a codebase, how can we as a team ensure that these changes are well considered and represent good solutions? And how can we increase the overall knowledge of a codebase across a team? Sometimes project goals and time pressures take precedence and producing maintainable, reusable code is not given the time it deserves. So, when a change or a new feature is needed - often the shortest route to making it work is taken as opposed to a more well thought-out solution. For this reason, it is important not to write the code alone and in isolation and use other team members to verify each other’s code and measure our coding standards against. This process of having multiple team members comment on key code changes is called code review - this is one of the most important practices of collaborative software development that helps ensure the ‘good’ coding standards are achieved and maintained within a team, as well as increasing knowledge about the codebase across the team. We’ll thus look at the benefits of reviewing code, in particular, the value of this type of activity within a team, and how this can fit within various ways of team working. We’ll see how GitHub can support code review activities via pull requests, and how we can do these ourselves making use of best practices.
After that, we’ll look at some general principles of software maintainability and the benefits that writing maintainable code can give you. There will also be some practice at identifying problems with existing code, and some general, established practices you can apply when writing new code or to the code you’ve already written. We’ll also look at how we can package software for release and distribution, using Poetry to manage our Python dependencies and produce a code package we can use with a Python package indexing service to illustrate these principles.
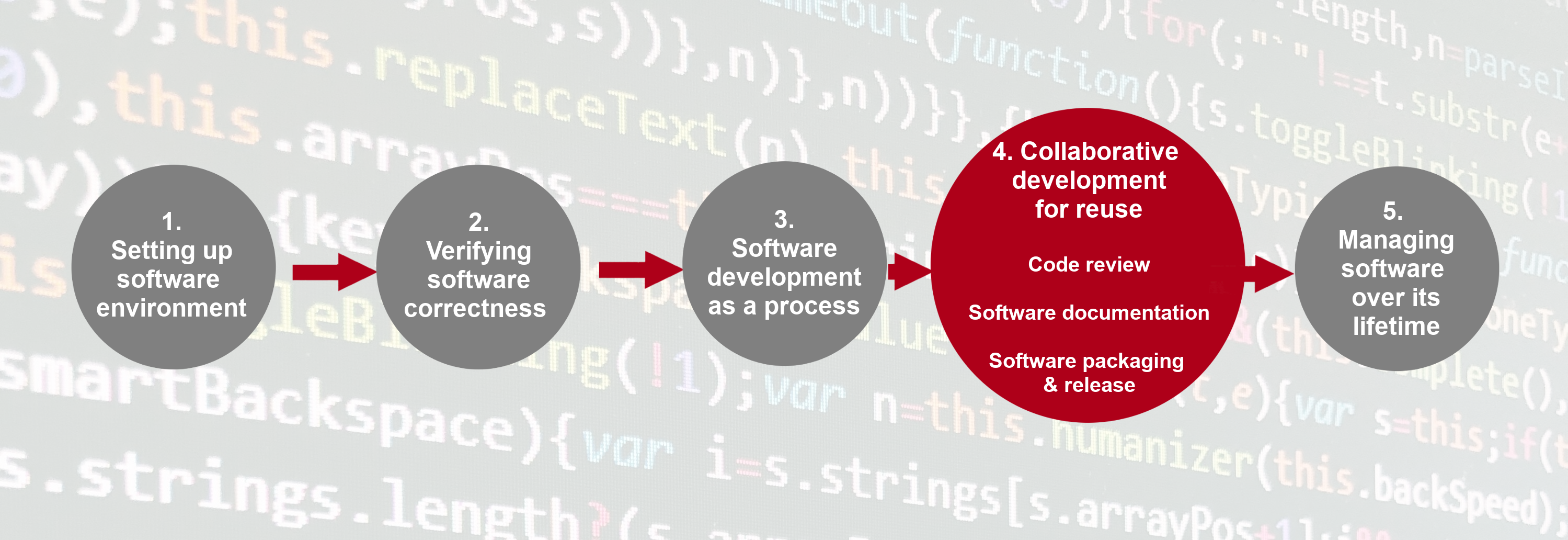
Key Points
Agreeing on a set of best practices within a software development team will help to improve your software’s understandability, extensibility, testability, reusability and overall sustainability.
Developing Software In a Team: Code Review
Overview
Teaching: 15 min
Exercises: 30 minQuestions
How do we develop software in a team?
What is code review and how it can improve the quality of code?
Objectives
Describe commonly used code review techniques.
Understand how to do a pull request via GitHub to engage in code review with a team and contribute to a shared code repository.
Introduction
So far in this course we’ve focused on learning software design and (some) technical practices, tools and infrastructure that help the development of software in a team environment, but in an individual setting. Despite developing tests to check our code - no one else from the team had a look at our code before we merged it into the main development stream. Software is often designed and built as part of a team, so in this episode we’ll be looking at how to manage the process of team software development and improve our code by engaging in code review process with other team members.
Collaborative Code Development Models
The way your team provides contributions to the shared codebase depends on the type of development model you use in your project. Two commonly used models are:
- Fork and pull model
- Shared repository model
Fork and Pull Model
In this model, anyone can fork an existing repository (to create their copy of the project linked to the source) and push changes to their personal fork. A contributor can work independently on their own fork as they do not need permissions on the source repository to push modifications to a fork they own. The changes from contributors can then be pulled into the source repository by the project maintainer on request and after a code review process. This model is popular with open source projects as it reduces the start up costs for new contributors and allows them to work independently without upfront coordination with source project maintainers. So, for example, you may use this model when you are an external collaborator on a project rather than a core team member.
Shared Repository Model
In this model, collaborators are granted push access to a single shared code repository. By default, collaborators have write access to the main branch. However, it is best practice to create feature branches for new developments, and protect the main branch. See the extra on protecting the main branch for how to do this. While it requires more upfront coordination, it is easier to share each others work, so it works well for more stable teams. This model is more prevalent with teams and organizations collaborating on private projects.
Regardless of the collaborative code development model you and your collaborators use - code reviews are one of the widely accepted best practices for software development in teams and something you should adopt in your development process too.
Code Review
Code review is a software quality assurance practice where one or several people from the team (different from the code’s author) check the software by viewing parts of its source code.
Group Exercise: Advantages of Code Review
Discuss as a group: what do you think are the reasons behind, and advantages of, code review?
Solution
The purposes of code review include:
- improving internal code readability, understandability, quality and maintainability
- checking for coding standards compliance, code uniformity and consistency
- checking for test coverage and detecting bugs and code defects early
- detecting performance problems and identifying code optimisation points
- finding alternative/better solutions.
An effective code review prevents errors from creeping into your software by improving code quality at an early stage of the software development process. It helps with learning, i.e. sharing knowledge about the codebase, solution approaches, expectations regarding quality, coding standards, etc. Developers use code review feedback from more senior developers to improve their own coding practices and expertise. Finally, it helps increase the sense of collective code ownership and responsibility, which in turn helps increase the “bus factor” and reduce the risk resulting from information and capabilities being held by a single person “responsible” for a certain part of the codebase and not being shared among team members.
Code review is one of the most useful team code development practices - someone checks your design or code for errors, they get to learn from your solution, having to explain code to someone else clarifies your rationale and design decisions in your mind too, and collaboration helps to improve the overall team software development process. It is universally applicable throughout the software development cycle - from design to development to maintenance. According to Michael Fagan, the author of the code inspection technique, rigorous inspections can remove 60-90% of errors from the code even before the first tests are run (Fagan, 1976). Furthermore, according to Fagan, the cost to remedy a defect in the early (design) stage is 10 to 100 times less compared to fixing the same defect in the development and maintenance stages, respectively. Since the cost of bug fixes grows in orders of magnitude throughout the software lifecycle, it is far more efficient to find and fix defects as close as possible to the point where they were introduced.
There are several code review techniques with various degree of formality and the use of a technical infrastructure, including:
- Over-the-shoulder code review is the most common and informal of code review techniques and involves one or more team members standing over the code author’s shoulder while the author walks the reviewers through a set of code changes.
- Email pass-around code review is another form of lightweight code review where the code author packages up a set of changes and files and sends them over to reviewers via email. Reviewers examine the files and differences against the code base, ask questions and discuss with the author and other developers, and suggest changes over email. The difficult part of this process is the manual collection the files under review and noting differences.
- Pair programming is a code development process that incorporates continuous code review - two developers sit together at a computer, but only one of them actively codes whereas the other provides real-time feedback. It is a great way to inspect new code and train developers, especially if an experienced team member walks a younger developer through the new code, providing explanations and suggestions through a conversation. It is conducted in-person and synchronously but it can be time-consuming as the reviewer cannot do any other work during the pair programming period.
- Fagan code inspection is a formal and heavyweight process of finding defects in specifications or designs during various phases of the software development process. There are several roles taken by different team members in a Fagan inspection and each inspection is a formal 7-step process with a predefined entry and exit criteria. See Fagan inspection for full details on this method.
- Tool-assisted code review process uses a specialised tool to facilitate the process of code review, which typically helps with the following tasks: (1) collecting and displaying the updated files and highlighting what has changed, (2) facilitating a conversation between team members (reviewers and developers), and (3) allowing code administrators and product managers a certain control and overview of the code development workflow. Modern tools may provide a handful of other functionalities too, such as metrics (e.g. inspection rate, defect rate, defect density).
Each of the above techniques have their pros and cons and varying degrees practicality - it is up to the team to decide which ones are most suitable for the project and when to use them. We will have a look at the tool-assisted code review process using GitHub’s built-in code review tool - pull requests. It is a lightweight tool, included with GitHub’s core service for free and has gained popularity within the software development community in recent years.
Code Reviews via GitHub’s Pull Requests
Pull requests are fundamental to how teams review and improve code
on GitHub (and similar code sharing platforms) -
they let you tell others about changes you’ve pushed to a branch in a repository on GitHub
and that your code is ready for review.
Once a pull request is opened,
you can discuss and review the potential changes with others on the team
and add follow-up commits based on the feedback
before your changes are merged from your feature branch into the develop branch.
The name ‘pull request’ suggests you are requesting the codebase moderators
to pull your changes into the codebase.
Such changes are normally done on a feature branch,
to ensure that they are separate and self-contained,
that the main branch only contains “production-ready” work,
and that the develop branch contains code that has already been extensively tested.
You create a branch for your work based on one of the existing branches
(typically the develop branch but can be any other branch),
do some commits on that branch,
and, once you are ready to merge your changes,
create a pull request to bring the changes back to the branch that you started from.
In this context, the branch from which you branched off to do your work
and where the changes should be applied back to
is called the base branch,
while the feature branch that contains changes you would like to be applied is the head branch.
How you create your feature branches and open pull requests in GitHub will depend on your collaborative code development model:
- In the shared repository model, in order to create a feature branch and open a pull request based on it you must have write access to the source repository or, for organisation-owned repositories, you must be a member of the organisation that owns the repository. Once you have access to the repository, you proceed to create a feature branch on that repository directly.
- In the fork and pull model, where you do not have write permissions to the source repository, you need to fork the repository first before you create a feature branch (in your fork) to base your pull request on.
In both development models, it is recommended to create a feature branch for your work and the subsequent pull request, even though you can submit pull requests from any branch or commit. This is because, with a feature branch, you can push follow-up commits as a response to feedback and update your proposed changes within a self-contained bundle. The only difference in creating a pull request between the two models is how you create the feature branch. In either model, once you are ready to merge your changes in - you will need to specify the base branch and the head branch.
Code Review and Pull Requests In Action
Let’s see this in action - you and your fellow learners are going to be organised in small teams and assume to be collaborating in the shared repository model. You will be added as a collaborator to another team member’s repository (which becomes the shared repository in this context) and, likewise, you will add other team members as collaborators on your repository. You can form teams of two and work on each other’s repositories. If there are 3 members in your group you can go in a round robin fashion (the first team member does a pull request on the second member’s repository and receives a pull request on their repository from the third team member). If you are going through the material on your own and do not have a collaborator, you can do pull requests on your own repository from one to another branch.
Recall solution requirements SR1.1.1 and SR1.2.1
from an earlier episode.
Your team member has implemented one of them according to the specification
(let’s call it feature-x)
but tests are still missing.
You are now tasked with implementing tests on top of that existing implementation
to make sure the new feature indeed satisfies the requirements.
You will propose changes to their repository
(the shared repository in this context)
via pull request (acting as the code author)
and engage in code review with your team member (acting as a code reviewer).
Similarly, you will receive a pull request on your repository from another team member,
in which case the roles will be reversed.
The following diagram depicts the branches that you should have in the repository.

Adapted from Git Tutorial by sillevl (Creative Commons Attribution 4.0 International License)
To achieve this, the following steps are needed.
Step 1: Adding Collaborators to a Shared Repository
You need to add the other team member(s) as collaborator(s) on your repository to enable them to create branches and pull requests. To do so, each repository owner needs to:
- Head over to Settings section of your software project’s repository in GitHub.
- Select the vertical tab ‘Collaborators’ from the left and click the ‘Add people’ button.
- Add your collaborator(s) by their GitHub username(s), full name(s) or email address(es).
- Collaborator(s) will be notified of your invitation to join your repository based on their notification preferences.
- Once they accept the invitation, they will have the collaborator-level access to your repository and will show up in the list of your collaborators.
See the full details on collaborator permissions for personal repositories to understand what collaborators will be able to do within your repository. Note that repositories owned by an organisation have a more granular access control compared to that of personal repositories.
Step 2: Preparing Your Local Environment for a Pull Request
- Obtain the GitHub URL of the shared repository you will be working on and clone it locally
(make sure you do it outside your software repository’s folder you have been working on so far).
This will create a copy of the repository locally on your machine
along with all of its (remote) branches.
$ git clone <remote-repo-url> $ cd <remote-repo-name> - Check with the repository owner (your team member)
which feature (SR1.1.1 or SR1.2.1) they implemented in the
previous exercise
and what is the name of the branch they worked on.
Let’s assume the name of the branch was
feature-x(you should amend the branch name for your case accordingly). -
Your task is to add tests for the code on
feature-xbranch. You should do so on a separate branch calledfeature-x-tests, which will branch offfeature-x. This is to enable you later on to create a pull request from yourfeature-x-testsbranch with your changes that can then easily be reviewed and compared withfeature-xby the team member who created it.To do so, branch off a new local branch
feature-x-testsfrom the remotefeature-xbranch (making sure you use the branch names that match your case). Also note that, while we say “remote” branchfeature-x- you have actually obtained it locally on your machine when you cloned the remote repository.$ git switch -c feature-x-tests origin/feature-xYou are now located in the new (local)
feature-x-testsbranch and are ready to start adding your code.
Step 3: Adding New Code
Exercise: Implement Tests for the New Feature
Look back at the solution requirements (SR1.1.1 or SR1.2.1) for the feature that was implemented in your shared repository. Implement tests against the appropriate specification in your local feature branch.
Note: Try not to not fall into the trap of writing the tests to test the existing code/implementation - you should write the tests to make sure the code satisfies the requirements regardless of the actual implementation. You can treat the implementation as a black box - a typical approach to software testing - as a way to make sure it is properly tested against its requirements without introducing assumptions into the tests about its implementation.
Testing Based on Requirements
Tests should test functionality, which stem from the software requirements, rather than an implementation. Tests can be seen as a reflection of those requirements - checking if the requirements are satisfied.
Remember to commit your new code to your branch feature-x-tests.
$ git add -A
$ git commit -m "Added tests for feature-x."
Step 4: Submitting a Pull Request
When you have finished adding your tests
and committed the changes to your local feature-x-tests,
and are ready for the others in the team to review them,
you have to do the following:
- Push your local feature branch
feature-x-testsremotely to the shared repository.$ git push -u origin feature-x-tests - Head over to the remote repository in GitHub
and locate your new (
feature-x-tests) branch from the dropdown box on the Code tab (you can search for your branch or use the “View all branches” option).
- Open a pull request by clicking “Compare & pull request” button.
- Select the base and the head branch, e.g.
feature-xandfeature-x-tests, respectively. Recall that the base branch is where you want your changes to be merged and the head branch contains your changes. - Add a comment describing the nature of the changes, and then submit the pull request.
- Repository moderator and other collaborators on the repository (code reviewers) will be notified of your pull request by GitHub.
- At this point, the code review process is initiated.
You should receive a similar pull request from other team members on your repository.
Step 5: Code Review
- The repository moderator/code reviewers reviews your changes and provides feedback to you in the form of comments.
- Respond to their comments and do any subsequent commits, as requested by reviewers.
- It may take a few rounds of exchanging comments and discussions until the team is ready to accept your changes.
Perform the above actions on the pull request you received, this time acting as the moderator/code reviewer.
Step 6: Closing a Pull Request
- Once the moderator approves your changes, either one of you can merge onto the base branch.
Typically, it is the responsibility of the code’s author to do the merge
but this may differ from team to team.
- Delete the merged branch to reduce the clutter in the repository.
Repeat the above actions for the pull request you received.
If the work on the feature branch is completed and it is sufficiently tested,
the feature branch can now be merged into the develop branch.
Best Practice for Code Review
There are multiple perspectives to a code review process - from general practices to technical details relating to different roles involved in the process. It is critical for the code’s quality, stability and maintainability that the team decides on this process and sticks to it. Here are some examples of best practices for you to consider (also check these useful code review blogs from Swarmia and Smartbear):
- Decide the focus of your code review process, e.g., consider some of the following:
- code design and functionality - does the code fit in the overall design and does it do what was intended?
- code understandability and complexity - is the code readable and would another developer be able to understand it?
- tests - does the code have automated tests?
- naming - are names used for variables and functions descriptive, do they follow naming conventions?
- comments and documentation - are there clear and useful comments that explain complex designs well and focus on the “why/because” rather than the “what/how”?
- Do not review code too quickly and do not review for too long in one sitting. According to “Best Kept Secrets of Peer Code Review” (Cohen, 2006) - the first hour of review matters the most as detection of defects significantly drops after this period. Studies into code review also show that you should not review more than 400 lines of code at a time. Conducting more frequent shorter reviews seems to be more effective.
- Decide on the level of depth for code reviews to maintain the balance between the creation time and time spent reviewing code - e.g. reserve them for critical portions of code and avoid nit-picking on small details. Try using automated checks and linters when possible, e.g. for consistent usage of certain terminology across the code and code styles.
- Communicate clearly and effectively - when reviewing code, be explicit about the action you request from the author.
- Foster a positive feedback culture:
- give feedback about the code, not about the author
- accept that there are multiple correct solutions to a problem
- sandwich criticism with positive comments and praise
- Utilise multiple code review techniques - use email, pair programming, over-the-shoulder, team discussions and tool-assisted or any combination that works for your team. However, for the most effective and efficient code reviews, tool-assisted process is recommended.
- From a more technical perspective:
- use a feature branch for pull requests as you can push follow-up commits if you need to update your proposed changes
- avoid large pull requests as they are more difficult to review. You can refer to some studies and Google recommendations as to what a “large pull request” is but be aware that it is not exact science.
- don’t force push to a pull request as it changes the repository history and can corrupt your pull request for other collaborators
- use pull request states in GitHub effectively (based on your team’s code review process) -
e.g. in GitHub you can open a pull request in a
DRAFTstate to show progress or request early feedback;READY FOR REVIEWwhen you are ready for feedback;CHANGES REQUESTEDto let the author know they need to fix the requested changes or discuss more;APPROVEDto let the author they can merge their pull request.
Exercise: Code Review in Your Own Working Environment
At the start of this episode we briefly looked at a number of techniques for doing code review, and as an example, went on to see how we can use GitHub Pull Requests to review team member code changes. Finally, we also looked at some best practices for doing code reviews in general.
Now think about how you typically develop code, and how you might institute code review practices within your own working environment. Write down briefly for your own reference (perhaps using bullet points) some answers to the following questions:
- Which 2 or 3 key circumstances would code review be most useful for you and your colleagues?
- Referring to the first section of this episode above, which type of code review would be most useful for each circumstance (and would work best within your own working environment)?
- Taking one of these circumstances where code review would be most beneficial, how would you organise such a code review, e.g.:
- Which aspects of the codebase would be the most useful to cover?
- How often would you do them?
- How long would the activity take?
- Who would ideally be involved?
- Any particular practices you would use?
Key Points
Code review is a team software quality assurance practice where team members look at parts of the codebase in order to improve their code’s readability, understandability, quality and maintainability.
It is important to agree on a set of best practices and establish a code review process in a team to help to sustain a good, stable and maintainable code for many years.
Preparing Software for Reuse and Release
Overview
Teaching: 35 min
Exercises: 20 minQuestions
What can we do to make our programs reusable by others?
How should we document and license our code?
Objectives
Describe the different levels of software reusability
Explain why documentation is important
Describe the minimum components of software documentation to aid reuse
Create a repository README file to guide others to successfully reuse a program
Understand other documentation components and where they are useful
Describe the basic types of open source software licence
Explain the importance of conforming to data policy and regulation
Prioritise and work on improvements for release as a team
Introduction
In previous episodes we’ve looked at skills, practices, and tools to help us design and develop software in a collaborative environment. In this lesson we’ll be looking at a critical piece of the development puzzle that builds on what we’ve learnt so far - sharing our software with others.
The Levels of Software Reusability - Good Practice Revisited
Let’s begin by taking a closer look at software reusability and what we want from it.
Firstly, whilst we want to ensure our software is reusable by others, as well as ourselves, we should be clear what we mean by ‘reusable’. There are a number of definitions out there, but a helpful one written by Benureau and Rougler in 2017 offers the following levels by which software can be characterised:
- Re-runnable: the code is simply executable and can be run again (but there are no guarantees beyond that)
- Repeatable: the software will produce the same result more than once
- Reproducible: published research results generated from the same version of the software can be generated again from the same input data
- Reusable: easy to use, understand, and modify
- Replicable: the software can act as an available reference for any ambiguity in the algorithmic descriptions made in the published article. That is, a new implementation can be created from the descriptions in the article that provide the same results as the original implementation, and that the original - or reference - implementation, can be used to clarify any ambiguity in those descriptions for the purposes of reimplementation
Later levels imply the earlier ones. So what should we aim for? As researchers who develop software - or developers who write research software - we should be aiming for at least the fourth one: reusability. Reproducibility is required if we are to successfully claim that what we are doing when we write software fits within acceptable scientific practice, but it is also crucial that we can write software that can be understood and ideally modified by others. If others are unable to verify that a piece of software follows published algorithms, how can they be certain it is producing correct results? Where ‘others’, of course, can include a future version of ourselves.
Documenting Code to Improve Reusability
Reproducibility is a cornerstone of science, and scientists who work in many disciplines are expected to document the processes by which they’ve conducted their research so it can be reproduced by others. In medicinal, pharmacological, and similar research fields for example, researchers use logbooks which are then used to write up protocols and methods for publication.
Many things we’ve covered so far contribute directly to making our software reproducible - and indeed reusable - by others. A key part of this we’ll cover now is software documentation, which is ironically very often given short shrift in academia. This is often the case even in fields where the documentation and publication of research method is otherwise taken very seriously.
A few reasons for this are that writing documentation is often considered:
- A low priority compared to actual research (if it’s even considered at all)
- Expensive in terms of effort, with little reward
- Writing documentation is boring!
A very useful form of documentation for understanding our code is code commenting, and is most effective when used to explain complex interfaces or behaviour, or the reasoning behind why something is coded a certain way. But code comments only go so far.
Whilst it’s certainly arguable that writing documentation isn’t as exciting as writing code, it doesn’t have to be expensive and brings many benefits. In addition to enabling general reproducibility by others, documentation…
- Helps bring new staff researchers and developers up to speed quickly with using the software
- Functions as a great aid to research collaborations involving software, where those from other teams need to use it
- When well written, can act as a basis for detailing algorithms and other mechanisms in research papers, such that the software’s functionality can be replicated and re-implemented elsewhere
- Provides a descriptive link back to the science that underlies it. As a reference, it makes it far easier to know how to update the software as the scientific theory changes (and potentially vice versa)
- Importantly, it can enable others to understand the software sufficiently to modify and reuse it to do different things
In the next section we’ll see that writing a sensible minimum set of documentation in a single document doesn’t have to be expensive, and can greatly aid reproducibility.
Writing a README
A README file is the first piece of documentation (perhaps other than publications that refer to it) that people should read to acquaint themselves with the software. It concisely explains what the software is about and what it’s for, and covers the steps necessary to obtain and install the software and use it to accomplish basic tasks. Think of it not as a comprehensive reference of all functionality, but more a short tutorial with links to further information - hence it should contain brief explanations and be focused on instructional steps.
Our repository already has a README that describes the purpose of the repository for this workshop, but let’s replace it with a new one that describes the software itself. First let’s delete the old one:
$ rm README.md
In the root of your repository create a replacement README.md file.
The .md indicates this is a Markdown file,
a lightweight markup language which is basically a text file with
some extra syntax to provide ways of formatting them.
A big advantage of them is that they can be read as plain-text files
or as source files for rendering them with formatting structures,
and are very quick to write.
GitHub provides a very useful guide to writing Markdown for its repositories.
Let’s start writing README.md using a text editor of your choice and add the following line.
# RiverCatch
So here, we’re giving our software a name.
Ideally something unique, short, snappy, and perhaps to some degree an indicator of what it does.
We would ideally rename the repository to reflect the new name, but let’s leave that for now.
In Markdown, the # designates a heading, two ## are used for a subheading, and so on.
The Software Sustainability Institute’s
guide on naming projects
and products provides some helpful pointers.
We should also add a short description underneath the title.
# RiverCatch
RiverCatch is a data management system written in Python that manages measurement data collected in river catchment surveys and campaigns.
To give readers an idea of the software’s capabilities, let’s add some key features next:
# RiverCatch
RiverCatch is a data management system written in Python that manages measurement data collected in river catchment surveys and campaigns.
## Main features
Here are some key features of Inflam:
- Provide basic statistical analyses of data
- Ability to work on measurement data in Comma-Separated Value (CSV) format
- Generate plots of measurement data
- Analytical functions and views can be easily extended based on its Model-View-Controller architecture
As well as knowing what the software aims to do and its key features,
it’s very important to specify what other software and related dependencies
are needed to use the software (typically called dependencies or prerequisites):
# RiverCatch
RiverCatch is a data management system written in Python that manages measurement data collected in river catchment surveys and campaigns.
## Main features
Here are some key features of Inflam:
- Provide basic statistical analyses of data
- Ability to work on measurement data in Comma-Separated Value (CSV) format
- Generate plots of measurement data
- Analytical functions and views can be easily extended based on its Model-View-Controller architecture
## Prerequisites
RiverCatch requires the following Python packages:
- [NumPy](https://www.numpy.org/) - makes use of NumPy's statistical functions
- [Pandas](https://pandas.pydata.org/) - makes use of Panda's dataframes
- [GeoPandas](https://geopandas.org/) - makes use of GeoPanda's spatial operations
- [Matplotlib](https://matplotlib.org/stable/index.html) - uses Matplotlib to generate statistical plots
The following optional packages are required to run RiverCatch's unit tests:
- [pytest](https://docs.pytest.org/en/stable/) - RiverCatch's unit tests are written using pytest
- [pytest-cov](https://pypi.org/project/pytest-cov/) - Adds test coverage stats to unit testing
Here we’re making use of Markdown links,
with some text describing the link within [] followed by the link itself within ().
One really neat feature - and a common practice - of using many CI infrastructures is that
we can include the status of running recent tests within our README file.
Just below the # RiverCatch title on our README.md file,
add the following (replacing <your_github_username> with your own:
# RiverCatch

...
This will embed a badge (icon) at the top of our page that
reflects the most recent GitHub Actions build status of your software repository,
essentially showing whether the tests that were run
when the last change was made to the main branch succeeded or failed.
That’s got us started with documenting our code, but there are other aspects we should also cover:
- Installation/deployment: step-by-step instructions for setting up the software so it can be used
- Basic usage: step-by-step instructions that cover using the software to accomplish basic tasks
- Contributing: for those wishing to contribute to the software’s development, this is an opportunity to detail what kinds of contribution are sought and how to get involved
- Contact information/getting help: which may include things like key author email addresses, and links to mailing lists and other resources
- Credits/acknowledgements: where appropriate, be sure to credit those who have helped in the software’s development or inspired it
- Citation: particularly for academic software, it’s a very good idea to specify a reference to an appropriate academic publication so other academics can cite use of the software in their own publications and media. You can do this within a separate CITATION text file within the repository’s root directory and link to it from the Markdown
- Licence: a short description of and link to the software’s licence
For more verbose sections, there are usually just highlights in the README with links to further information, which may be held within other Markdown files within the repository or elsewhere.
We’ll finish these off later. See Matias Singer’s curated list of awesome READMEs for inspiration.
Other Documentation
There are many different types of other documentation you should also consider writing and making available that’s beyond the scope of this course. The key is to consider which audiences you need to write for, e.g. end users, developers, maintainers, etc., and what they need from the documentation. There’s a Software Sustainability Institute blog post on best practices for research software documentation that helpfully covers the kinds of documentation to consider and other effective ways to convey the same information.
One that you should always consider is technical documentation. This typically aims to help other developers understand your code sufficiently well to make their own changes to it, including external developers, other members in your team and a future version of yourself too. This may include documentation that covers the software’s architecture, including its different components and how they fit together, API (Application Programming Interface) documentation that describes the interface points designed into your software for other developers to use, e.g. for a software library, or technical tutorials/’HOW TOs’ to accomplish developer-oriented tasks.
Choosing an Open Source Licence
Software licensing is a whole topic in itself, so we’ll just summarise here. Your institution’s Intellectual Property (IP) team will be able to offer specific guidance that fits the way your institution thinks about software.
In IP law, software is considered a creative work of literature, so any code you write automatically has copyright protection applied. This copyright will usually belong to the institution that employs you, but this may be different for PhD students. If you need to check, this should be included in your employment/studentship contract or talk to your university’s IP team.
Since software is automatically under copyright, without a licence no one may:
- Copy it
- Distribute it
- Modify it
- Extend it
- Use it (actually unclear at present - this has not been properly tested in court yet)
Fundamentally there are two kinds of licence, Open Source licences and Proprietary licences, which serve slightly different purposes:
- Proprietary licences are designed to pass on limited rights to end users, and are most suitable if you want to commercialise your software. They tend to be customised to suit the requirements of the software and the institution to which it belongs - again your institutions IP team will be able to help here.
- Open Source licences are designed more to protect the rights of end users - they specifically grant permission to make modifications and redistribute the software to others. The website Choose A License provides recommendations and a simple summary of some of the most common open source licences.
Within the open source licences, there are two categories, copyleft and permissive:
- The permissive licences such as MIT and the multiple variants of the BSD licence are designed to give maximum freedom to the end users of software. These licences allow the end user to do almost anything with the source code.
- The copyleft licences in the GPL still give a lot of freedom to the end users, but any code that they write based on GPLed code must also be licensed under the same licence. This gives the developer assurance that anyone building on their code is also contributing back to the community. It’s actually a little more complicated than this, and the variants all have slightly different conditions and applicability, but this is the core of the licence.
Which of these types of licence you prefer is up to you and those you develop code with. If you want more information, or help choosing a licence, the Choose An Open-Source Licence or tl;dr Legal sites can help.
Exercise: Preparing for Release
In a (hopefully) highly unlikely and thoroughly unrecommended scenario, your project leader has informed you of the need to release your software within the next half hour, so it can be assessed for use by another team. You’ll need to consider finishing the README, choosing a licence, and fixing any remaining problems you are aware of in your codebase. Ensure you prioritise and work on the most pressing issues first!
Merging into main
Once you’ve done these updates,
commit your changes,
and if you’re doing this work on a feature branch also ensure you merge it into develop,
e.g.:
$ git switch develop
$ git merge my-feature-branch
Finally, once we’ve fully tested our software
and are confident it works as expected on develop,
we can merge our develop branch into main:
$ git switch main
$ git merge develop
$ git push
Tagging a Release in GitHub
There are many ways in which Git and GitHub can help us make a software release from our code. One of these is via tagging, where we attach a human-readable label to a specific commit. Let’s see what tags we currently have in our repository:
$ git tag
Since we haven’t tagged any commits yet, there’s unsurprisingly no output. We can create a new tag on the last commit we did by doing:
$ git tag -a v1.0.0 -m "Version 1.0.0"
So we can now do:
$ git tag
v.1.0.0
And also, for more information:
$ git show v1.0.0
You should see something like this:
tag v1.0.0
Tagger: <Name> <email>
Date: Fri Dec 10 10:22:36 2021 +0000
Version 1.0.0
commit 2df4bfcbfc1429c12f92cecba751fb2d7c1a4e28 (HEAD -> main, tag: v1.0.0, origin/main, origin/develop, origin/HEAD, develop)
Author: <Name> <email>
Date: Fri Dec 10 10:21:24 2021 +0000
Finalising README.
diff --git a/README.md b/README.md
index 4818abb..5b8e7fd 100644
--- a/README.md
+++ b/README.md
@@ -22,4 +22,33 @@ Flimflam requires the following Python packages:
The following optional packages are required to run Flimflam's unit tests:
- [pytest](https://docs.pytest.org/en/stable/) - Flimflam's unit tests are written using pytest
-- [pytest-cov](https://pypi.org/project/pytest-cov/) - Adds test coverage stats to unit testing
\ No newline at end of file
+- [pytest-cov](https://pypi.org/project/pytest-cov/) - Adds test coverage stats to unit testing
+
+## Installation
+- Clone the repo ``git clone repo``
+- Check everything runs by running ``python -m pytest`` in the root directory
+- Hurray 😊
+
+## Contributing
+- Create an issue [here](https://github.com/Onoddil/python-intermediate-inflammation/issues)
+ - What works, what doesn't? You tell me
+- Randomly edit some code and see if it improves things, then submit a [pull request](https://github.com/Onoddil/python-intermediate-inflammation/pulls)
+- Just yell at me while I edit the code, pair programmer style!
+
+## Getting Help
+- Nice try
+
+## Credits
+- Directed by Michael Bay
+
+## Citation
+Please cite [J. F. W. Herschel, 1829, MmRAS, 3, 177](https://ui.adsabs.harvard.edu/abs/1829MmRAS...3..177H/abstract) if you used this work in your day-to-day life.
+Please cite [C. Herschel, 1787, RSPT, 77, 1](https://ui.adsabs.harvard.edu/abs/1787RSPT...77....1H/abstract) if you actually use this for scientific work.
+
+## License
+This source code is protected under international copyright law. All rights
+reserved and protected by the copyright holders.
+This file is confidential and only available to authorized individuals with the
+permission of the copyright holders. If you encounter this file and do not have
+permission, please contact the copyright holders and delete this file.
\ No newline at end of file
So now we’ve added a tag, we need this reflected in our Github repository. You can push this tag to your remote by doing:
$ git push origin v1.0.0
What is a Version Number Anyway?
Software version numbers are everywhere, and there are many different ways to do it. A popular one to consider is Semantic Versioning, where a given version number uses the format MAJOR.MINOR.PATCH. You increment the:
- MAJOR version when you make incompatible API changes
- MINOR version when you add functionality in a backwards compatible manner
- PATCH version when you make backwards compatible bug fixes
You can also add a hyphen followed by characters to denote a pre-release version, e.g. 1.0.0-alpha1 (first alpha release) or 1.2.3-beta4 (fourth beta release)
We can now use the more memorable tag to refer to this specific commit.
Plus, once we’ve pushed this back up to GitHub,
it appears as a specific release within our code repository
which can be downloaded in compressed .zip or .tar.gz formats.
Note that these downloads just contain the state of the repository at that commit,
and not its entire history.
Using features like tagging allows us to highlight commits that are particularly important, which is very useful for reproducibility purposes. We can (and should) refer to specific commits for software in academic papers that make use of results from software, but tagging with a specific version number makes that just a little bit easier for humans.
Conforming to Data Policy and Regulation
We may also wish to make data available to either be used with the software or as generated results. This may be via GitHub or some other means. An important aspect to remember with sharing data on such systems is that they may reside in other countries, and we must be careful depending on the nature of the data.
We need to ensure that we are still conforming to the relevant policies and guidelines regarding how we manage research data, which may include funding council, institutional, national, and even international policies and laws. Within Europe, for example, there’s the need to conform to things like GDPR. It’s a very good idea to make yourself aware of these aspects.
Key Points
The reuse battle is won before it is fought. Select and use good practices consistently throughout development and not just at the end.
Packaging Code for Release and Distribution
Overview
Teaching: 0 min
Exercises: 20 minQuestions
How do we prepare our code for sharing as a Python package?
How do we release our project for other people to install and reuse?
Objectives
Describe the steps necessary for sharing Python code as installable packages.
Use Poetry to prepare an installable package.
Explain the differences between runtime and development dependencies.
Why Package our Software?
We’ve now got our software ready to release - the last step is to package it up so that it can be distributed.
For very small pieces of software, for example a single source file, it may be appropriate to distribute to non-technical end-users as source code, but in most cases we want to bundle our application or library into a package. A package is typically a single file which contains within it our software and some metadata which allows it to be installed and used more simply - e.g. a list of dependencies. By distributing our code as a package, we reduce the complexity of fetching, installing and integrating it for the end-users.
In this session we’ll introduce one widely used method for building an installable package from our code. There are range of methods in common use, so it’s likely you’ll also encounter projects which take different approaches.
There’s some confusing terminology in this episode around the use of the term “package”. This term is used to refer to both:
- A directory containing Python files / modules and an
__init__.py- a “module package” - A way of structuring / bundling a project for easier distribution and installation - a “distributable package”
Packaging our Software with Poetry
Installing Poetry
Because we’ve recommended GitBash if you’re using Windows, we’re going to install Poetry using a different method to the officially recommended one. If you’re on MacOS or Linux, are comfortable with installing software at the command line and want to use Poetry to manage multiple projects, you may instead prefer to follow the official Poetry installation instructions.
We can install Poetry much like any other Python distributable package, using pip:
$ source venv/bin/activate
$ python3 -m pip install poetry
To test, we can ask where Poetry is installed:
$ which poetry
/home/<user>/python-intermediate-rivercatchment/venv/bin/poetry
If you don’t get similar output, make sure you’ve got the correct virtual environment activated.
Poetry can also handle virtual environments for us, so in order to behave similarly to how we used them previously, let’s change the Poetry config to put them in the same directory as our project:
$ poetry config virtualenvs.in-project true
Setting up our Poetry Config
Poetry uses a pyproject.toml file to describe the build system and requirements of the distributable package. This file format was introduced to solve problems with bootstrapping packages (the processing we do to prepare to process something) using the older convention with setup.py files and to support a wider range of build tools. It is described in PEP 518 (Specifying Minimum Build System Requirements for Python Projects).
Make sure you are in the root directory of your software project and have activated your virtual environment, then we’re ready to begin.
To create a pyproject.toml file for our code, we can use poetry init.
This will guide us through the most important settings -
for each prompt, we either enter our data or accept the default.
Displayed below are the questions you should see with the recommended responses to each question so try to follow these, although use your own contact details!
NB: When you get to the questions about defining our dependencies, answer no, so we can do this separately later.
$ poetry init
This command will guide you through creating your pyproject.toml config.
Package name [example]: catchment
Version [0.1.0]: 1.0.0
Description []: Analyse river catchment project data
Author [None, n to skip]: James Graham <J.Graham@software.ac.uk>
License []: MIT
Compatible Python versions [^3.11]: ^3.11
Would you like to define your main dependencies interactively? (yes/no) [yes] no
Would you like to define your development dependencies interactively? (yes/no) [yes] no
Generated file
[tool.poetry]
name = "catchment"
version = "1.0.0"
description = "Analyse river catchment project data"
authors = ["James Graham <J.Graham@software.ac.uk>"]
license = "MIT"
[tool.poetry.dependencies]
python = "^3.11"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
Do you confirm generation? (yes/no) [yes] yes
We’ve called our package “catchment” in the setup above,
instead of “catchment-analysis” like we did in our previous setup.py.
This is because Poetry will automatically find our code
if the name of the distributable package matches the name of our module package.
If we wanted our distributable package to have a different name,
for example “catchment-analysis”,
we could do this by explicitly listing the module packages to bundle -
see the Poetry docs on packages
for how to do this.
Project Dependencies
Previously, we looked at using a requirements.txt file to define the dependencies of our software.
Here, Poetry takes inspiration from package managers in other languages,
particularly NPM (Node Package Manager),
often used for JavaScript development.
Tools like Poetry and NPM understand that there are two different types of dependency:
runtime dependencies and development dependencies.
Runtime dependencies are those dependencies that
need to be installed for our code to run, like NumPy and Pandas.
Development dependencies are dependencies which
are an essential part of your development process for a project,
but are not required to run it.
Common examples of developments dependencies are linters and test frameworks,
like pylint or pytest.
When we add a dependency using Poetry,
Poetry will add it to the list of dependencies in the pyproject.toml file,
add a reference to it in a new poetry.lock file,
and automatically install the package into our virtual environment.
If we don’t yet have a virtual environment activated,
Poetry will create it for us - using the name .venv,
so it appears hidden unless we do ls -a.
Because we’ve already activated a virtual environment, Poetry will use ours instead.
The pyproject.toml file has two separate lists,
allowing us to distinguish between runtime and development dependencies.
$ poetry add matplotlib numpy pandas geopandas
$ poetry add --dev pylint
$ poetry install
These two sets of dependencies will be used in different circumstances.
When we build our package and upload it to a package repository,
Poetry will only include references to our runtime dependencies.
This is because someone installing our software through a tool like pip is only using it,
but probably doesn’t intend to contribute to the development of our software
and does not require development dependencies.
In contrast, if someone downloads our code from GitHub,
together with our pyproject.toml,
and installs the project that way,
they will get both our runtime and development dependencies.
If someone is downloading our source code,
that suggests that they intend to contribute to the development,
so they’ll need all of our development tools.
Have a look at the pyproject.toml file again to see what’s changed.
Packaging Our Code
The final preparation we need to do is to
make sure that our code is organised in the recommended structure.
This is the Python module structure -
a directory containing an __init__.py and our Python source code files.
Make sure that the name of this Python package
(catchment - unless you’ve renamed it)
matches the name of your distributable package in pyproject.toml
unless you’ve chosen to explicitly list the module packages.
By convention distributable package names use hyphens, whereas module package names use underscores. While we could choose to use underscores in a distributable package name, we cannot use hyphens in a module package name, as Python will interpret them as a minus sign in our code when we try to import them.
Once we’ve got our pyproject.toml configuration done and our project is in the right structure,
we can go ahead and build a distributable version of our software:
$ poetry build
This should produce two files for us in the dist directory.
The one we care most about is the .whl or wheel file.
This is the file that pip uses to distribute and install Python packages,
so this is the file we’d need to share with other people who want to install our software.
Now if we gave this wheel file to someone else,
they could install it using pip -
you don’t need to run this command yourself,
you’ve already installed it using poetry install above.
$ python3 -m pip install dist/catchment*.whl
The star in the line above is a wildcard,
that means Bash should use any filenames that match that pattern,
with any number of characters in place for the star.
We could also rely on Bash’s autocomplete functionality and type dist/catchment,
then hit the Tab key if we’ve only got one version built.
After we’ve been working on our code for a while and want to publish an update,
we just need to update the version number in the pyproject.toml file
(using SemVer perhaps),
then use Poetry to build and publish the new version.
If we don’t increment the version number,
people might end up using this version,
even though they thought they were using the previous one.
Any re-publishing of the package, no matter how small the changes,
needs to come with a new version number.
The advantage of SemVer is that the change in the version number
indicates the degree of change in the code and thus the degree of risk of breakage when we update.
$ poetry build
In addition to the commands we’ve already seen, Poetry contains a few more that can be useful for our development process. For the full list see the Poetry CLI documentation.
The final step is to publish our package to a package repository. A package repository could be either public or private - while you may at times be working on public projects, it’s likely the majority of your work will be published internally using a private repository such as JFrog Artifactory. Every repository may be configured slightly differently, so we’ll leave that to you to investigate.
What if We Need More Control?
Sometimes we need more control over the process of building our distributable package than Poetry allows. There many ways to distribute Python code in packages, with some degree of flux in terms of which methods are most popular. For a more comprehensive overview of Python packaging you can see the Python docs on packaging, which contains a helpful guide to the overall packaging process, or ‘flow’, using the Twine tool to upload created packages to PyPI for distribution as an alternative.
Optional Exercise: Enhancing our Package Metadata
The Python Packaging User Guide provides documentation on how to package a project using a manual approach to building a
pyproject.tomlfile, and using Twine to upload the distribution packages to PyPI.Referring to the section on metadata in the documentation, enhance your
pyproject.tomlwith some additional metadata fields to improve the information your package.
Key Points
Poetry allows us to produce an installable package and upload it to a package repository.
Making our software installable with Pip makes it easier for others to start using it.
For complete control over building a package, we can use a
setup.pyfile.
Section 5: Managing and Improving Software Over Its Lifetime
Overview
Teaching: 5 min
Exercises: 0 minQuestions
How do we manage the process of developing and improving our software?
How do we ensure we reuse other people’s code while maintaining the sustainability of our own software?
Objectives
Use established tools to track and manage software problems and enhancements in a team.
Understand the importance of critical reflection to improving software quality and reusability.
Improve software through feedback, work estimation, prioritisation and agile development.
In this section of the course we look at managing the development and evolution of software - how to keep track of the tasks the team has to do, how to improve the quality and reusability of our software for others as well as ourselves, and how to assess other people’s software for reuse within our project. The focus in this section will move beyond just software development to software management: internal planning and prioritising tasks for future development, management of internal communication as well as how the outside world interacts with and makes use of our software, how others can interact with ourselves to report issues, and the ways we can successfully manage software improvement in response to feedback.
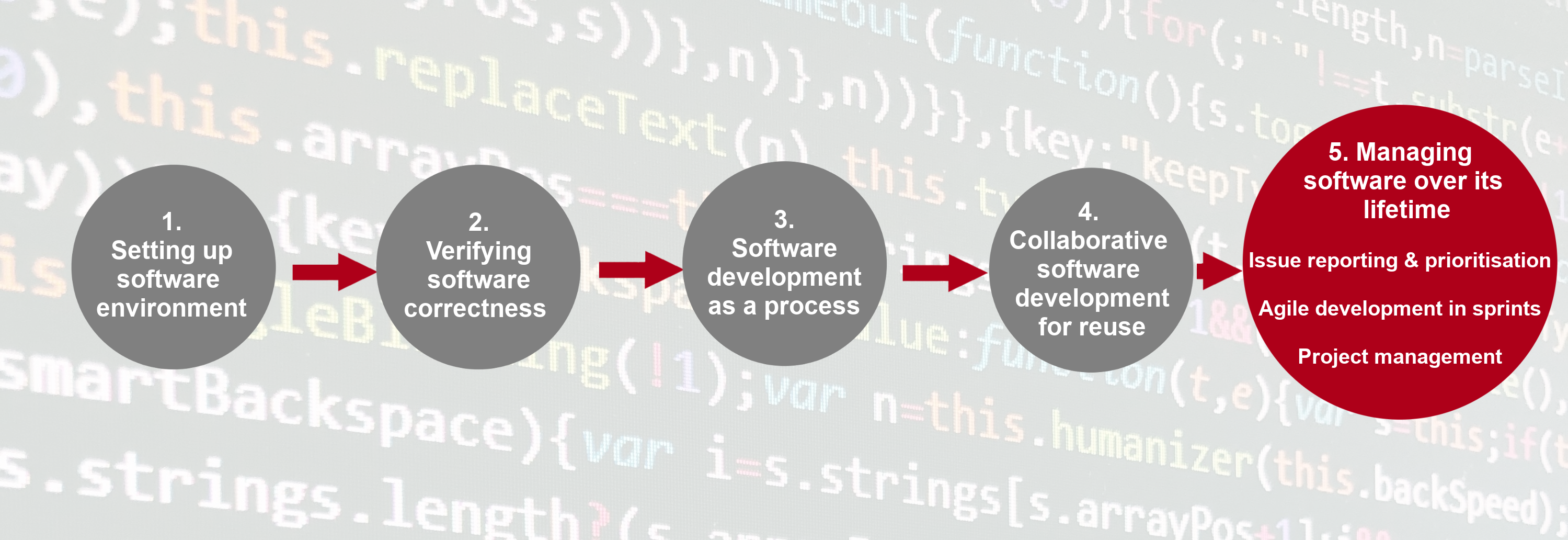
In this section we will:
- Use GitHub to track issues with our software registered by ourselves and external users.
- Use GitHub’s Mentions and notifications system to effectively communicate within the team on software development tasks.
- Use GitHub’s Project Boards and Milestones for project planning and management.
- Learn to manage the improvement of our software through feedback using agile management techniques.
- Employ effort estimation of development tasks as a foundational tool for prioritising future team work, and use the MoSCoW approach and software development sprints to manage improvement. As we will see, it is very difficult to prioritise work effectively without knowing both its relative importance to others as well as the effort required to deliver those work items.
- Learn how to employ a critical mindset when reviewing software for reuse.
Key Points
For software to succeed it needs to be managed as well as developed.
Estimating the effort to deliver work items is a foundational tool for prioritising that work.
Managing a Collaborative Software Project
Overview
Teaching: 15 min
Exercises: 30 minQuestions
How can we keep track of identified issues and the list of tasks the team has to do?
How can we communicate within a team on code-related issues and share responsibilities?
How can we plan, prioritise and manage tasks for future development?
Objectives
Register and track progress on issues with the code in our project repository
Describe some different types of issues we can have with software
Manage communications on software development activities within the team using GitHub’s notification system Mentions
Use GitHub’s Project Boards and Milestones for software project management, planning sprints and releases
Introduction
Developing software is a project and, like most projects, it consists of multiple tasks. Keeping track of identified issues with the software, the list of tasks the team has to do, progress on each, prioritising tasks for future development, planning sprints and releases, etc., can quickly become a non-trivial task in itself. Without a good team project management process and framework, it can be hard to keep track of what’s done, or what needs doing, and particularly difficult to convey that to others in the team or share the responsibilities.
Using GitHub to Manage Issues With Software
As a piece of software is used, bugs and other issues will inevitably come to light - nothing is perfect! If you work on your code with collaborators, or have non-developer users, it can be helpful to have a single shared record of all the problems people have found with the code, not only to keep track of them for you to work on later, but to avoid people emailing you to report a bug that you already know about!
GitHub provides Issues - a framework for managing bug reports, feature requests, and lists of future work.
Go back to the home page for your python-intermediate-inflammation repository in GitHub,
and click on the Issue tab.
You should see a page listing the open issues on your repository -
currently there should be none.
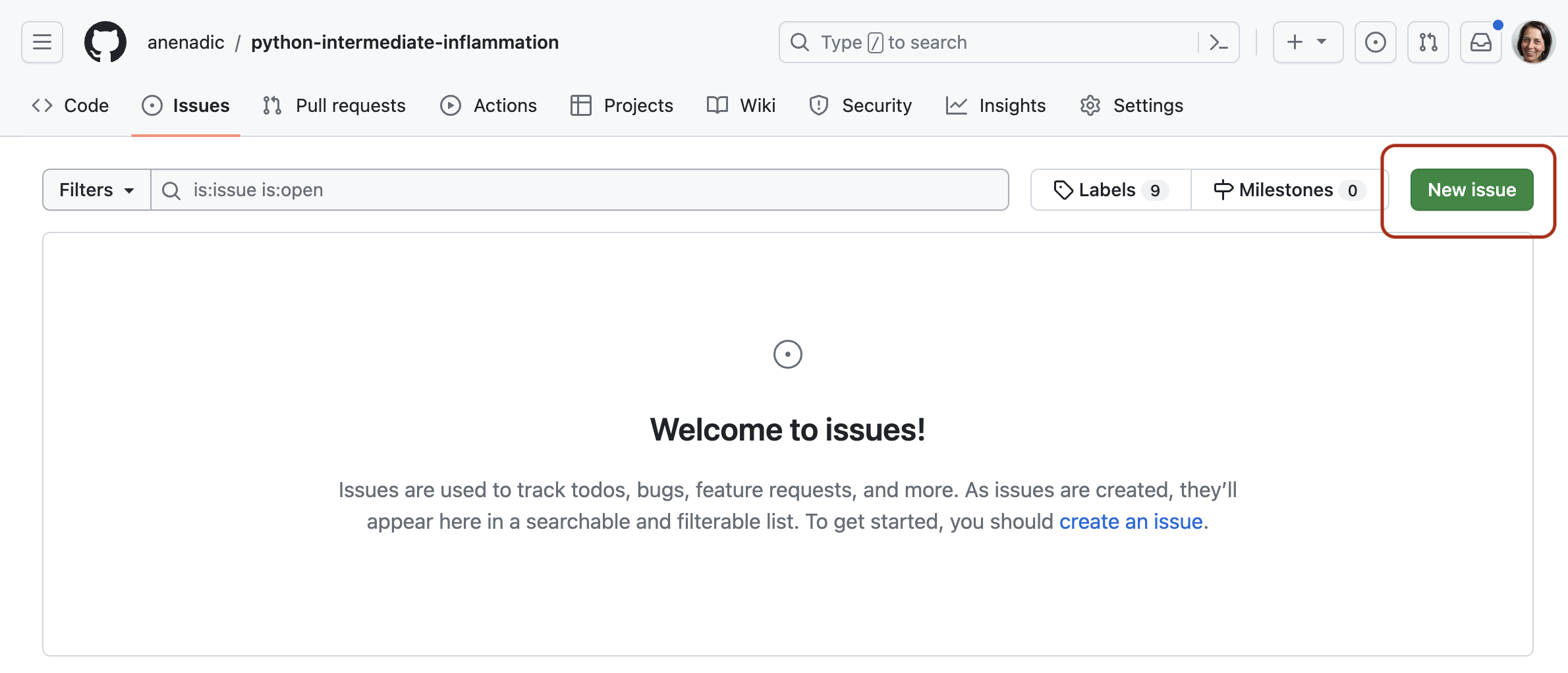
Let’s go through the process of creating a new issue.
Start by clicking the New issue button.
When you create an issue, you can add a range of details to them. They can be assigned to a specific developer for example - this can be a helpful way to know who, if anyone, is currently working to fix the issue, or a way to assign responsibility to someone to deal with it.
They can also be assigned a label. The labels available for issues can be customised, and given a colour, allowing you to see at a glance the state of your code’s issues. The default labels available in GitHub include:
bug- indicates an unexpected problem or unintended behaviordocumentation- indicates a need for improvements or additions to documentationduplicate- indicates similar or already reported issues, pull requests, or discussionsenhancement- indicates new feature requests, or if they are created by a developer, indicate planned new featuresgood first issue- indicates a good issue for first-time contributorshelp wanted- indicates that a maintainer wants help on an issue or pull requestinvalid- indicates that an issue, pull request, or discussion is no longer relevantquestion- indicates that an issue, pull request, or discussion needs more informationwontfix- indicates that work won’t continue on an issue, pull request, or discussion
You can also create your own custom labels to help with classifying issues.
There are no rules really about naming the labels -
use whatever makes sense for your project.
Some conventional custom labels include:
status:in progress (to indicate that someone started working on the issue),
status:blocked (to indicate that the progress on addressing issue is
blocked by another issue or activity), etc.
As well as highlighting problems,
the bug label can make code much more usable by
allowing users to find out if anyone has had the same problem before,
and also how to fix (or work around) it on their end.
Enabling users to solve their own problems can save you a lot of time.
In general, a good bug report should contain only one bug,
specific details of the environment in which the issue appeared
(e.g. operating system or browser, version of the software and its dependencies),
and sufficiently clear and concise steps that allow a developer to reproduce the bug themselves.
They should also be clear on what the bug reporter considers factual
(“I did this and this happened”)
and speculation
(“I think it was caused by this”).
If an error report was generated from the software itself,
it’s a very good idea to include that in the issue.
The enhancement label is a great way to communicate your future priorities
to your collaborators but also to yourself -
it’s far too easy to leave a software project for a few months to work on something else,
only to come back and forget the improvements you were going to make.
If you have other users for your code,
they can use the label to request new features,
or changes to the way the code operates.
It’s generally worth paying attention to these suggestions,
especially if you spend more time developing than running the code.
It can be very easy to end up with quirky behaviour
because of off-the-cuff choices during development.
Extra pairs of eyes can point out ways the code can be made more accessible -
the easier the code is to use, the more widely it will be adopted
and the greater impact it will have.
One interesting label is wontfix,
which indicates that an issue simply won’t be worked on for whatever reason.
Maybe the bug it reports is outside of the use case of the software,
or the feature it requests simply isn’t a priority.
This can make it clear you’ve thought about an issue and dismissed it.
Locking and Pinning Issues
The Lock conversation and Pin issue buttons are both available from individual issue pages. Locking conversations allows you to block future comments on the issue, e.g. if the conversation around the issue is not constructive or violates your team’s code of conduct. Pinning issues allows you to pin up to three issues to the top of the issues page, e.g. to emphasise their importance.
Manage Issues With Your Code Openly
Having open, publicly-visible lists of the limitations and problems with your code is incredibly helpful. Even if some issues end up languishing unfixed for years, letting users know about them can save them a huge amount of work attempting to fix what turns out to be an unfixable problem on their end. It can also help you see at a glance what state your code is in, making it easier to prioritise future work!
Exercise: Our First Issue!
Individually, with a critical eye, think of an aspect of the code you have developed so far that needs improvement. It could be a bug, for example, or a documentation issue with your README, a missing LICENSE file, or an enhancement. In GitHub, enter the details of the issue and select
Submit new issue. Add a label to your issue, if appropriate.Time: 5 mins
Solution
For example, “Add a licence file” could be a good first issue, with a label
documentation.
Issue (and Pull Request) Templates
GitHub also allows you to set up issue and pull request templates for your software project. Such templates provide a structure for the issue/pull request descriptions, and/or prompt issue reporters and collaborators to fill in answers to pre-set questions. They can help contributors raise issues or submit pull requests in a way that is clear, helpful and provides enough information for maintainers to act upon (without going back and forth to extract it). GitHub provides a range of default templates, but you can also write your own.
Using GitHub’s Notifications & Referencing System to Communicate
GitHub implements a comprehensive notifications system to keep the team up-to-date with activities in your code repository and notify you when something happens or changes in your software project. You can choose whether to watch or unwatch an individual repository, or can choose to only be notified of certain event types such as updates to issues, pull requests, direct mentions, etc. GitHub also provides an additional useful notification feature for collaborative work - Mentions. In addition to referencing team members (which will result in an appropriate notification), GitHub allows us to reference issues, pull requests and comments from one another - providing a useful way of connecting things and conversations in your project.
Referencing Team Members Using Mentions
The mention system notifies team members when somebody else references them in an issue, comment or pull request - you can use this to notify people when you want to check a detail with them, or let them know something has been fixed or changed (much easier than writing out all the same information again in an email).
You can use the mention system to link to/notify an individual GitHub account or a whole team for notifying multiple people. Typing @ in GitHub will bring up a list of all accounts and teams linked to the repository that can be “mentioned”. People will then receive notifications based on their preferred notification methods - e.g. via email or GitHub’s User Interface.
Referencing Issues, Pull Requests and Comments
GitHub also lets you mention/reference one issue or pull request from another (and people “watching” these will be notified of any such updates). Whilst writing the description of an issue, or commenting on one, if you type # you should see a list of the issues and pull requests on the repository. They are coloured green if they’re open, or white if they’re closed. Continue typing the issue number, and the list will narrow down, then you can hit Return to select the entry and link the two. For example, if you realise that several of your bugs have common roots, or that one enhancement can’t be implemented before you’ve finished another, you can use the mention system to indicate the depending issue(s). This is a simple way to add much more information to your issues.
While not strictly notifying anyone,
GitHub lets you also reference individual comments and commits.
If you click the ... button on a comment,
from the drop down list you can select to Copy link
(which is a URL that points to that comment that can be pasted elsewhere)
or to Reference [a comment] in a new issue
(which opens a new issue and references the comment by its URL).
Within a text box for comments, issue and pull request descriptions,
you can reference a commit by pasting its long, unique identifier
(or its first few digits which uniquely identify it)
and GitHub will render it nicely using the identifier’s short form
and link to the commit in question.
Exercise: Our First Mention/Reference!
Add a mention to one of your team members using the
@notation in a comment within an issue or a pull request in your repository - e.g. to ask them a question or a clarification on something or to do some additional work.Alternatively, add another issue to your repository and reference the issue you created in the previous exercise using the
#notation.Time: 5 mins
You Are Also a User of Your Code
This section focuses a lot on how issues and mentions can help communicate the current state of the code to others and document what conversations were held around particular issues. As a sole developer, and possibly also the only user of the code, you might be tempted to not bother with recording issues, comments and new features as you don’t need to communicate the information to anyone else.
Unfortunately, human memory isn’t infallible! After spending six months on a different topic, it’s inevitable you’ll forget some of the plans you had and problems you faced. Not documenting these things can lead to you having to re-learn things you already put the effort into discovering before. Also, if others are brought on to the project at a later date, the software’s existing issues and potential new features are already in place to build upon.
Software Project Management in GitHub
Managing issues within your software project is one aspect of project management but it gives a relative flat representation of tasks and may not be as suitable for higher-level project management such as prioritising tasks for future development, planning sprints and releases. Luckily, GitHub provides two project management tools for this purpose - Projects and Milestones.
Both Projects and Milestones provide agile development and project management systems and ways of organising issues into smaller “sub-projects” (i.e. smaller than the “project” represented by the whole repository). Projects provide a way of visualising and organising work which is not time-bound and is on a higher level (e.g. more suitable for project management tasks). Milestones are typically used to organise lower-level tasks that have deadlines and progress of which needs to be closely tracked (e.g. release and version management). The main difference is that Milestones are a repository-level feature (i.e. they belong and are managed from a single repository), whereas projects are account-level and can manage tasks across many repositories under the same user or organisational account.
How you organise and partition your project work and which tool you want to use to track progress (if at all) is up to you and the size of your project. For example, you could create a project per milestone or have several milestones in a single project, or split milestones into shorter sprints. We will use Milestones soon to organise work on a mini sprint within our team - for now, we will have a brief look at Projects.
Projects
A Project uses a “project board” consisting of columns and cards to keep track of tasks (although GitHub now also provides a table view over a project’s tasks). You break down your project into smaller sub-projects, which in turn are split into tasks which you write on cards, then move the cards between columns that describe the status of each task. Cards are usually small, descriptive and self-contained tasks that build on each other. Breaking a project down into clearly-defined tasks makes it a lot easier to manage. GitHub project boards interact and integrate with the other features of the site such as issues and pull requests - cards can be added to track the progress of such tasks and automatically moved between columns based on their progress or status.
Project are a Cross-Repository Management Tool
Project in GitHub are created on a user or organisation level, i.e. they can span all repositories owned by a user or organisation in GitHub and are not a repository-level feature any more. A project can integrate your issues and pull requests on GitHub from multiple repositories to help you plan and track your team’s work effectively.
Let’s create a Project in GitHub to plan the first release of our code.
-
From your GitHub account’s home page (not your repository’s home page!), select the “Projects” tab, then click the
New projectbutton on the right.
-
In the “Select a template” pop-up window, select “Board” - this will give you a classic “cards on a board” view of the project. An alternative is the “Table” view, which presents a spreadsheet-like and slightly more condensed view of a project.
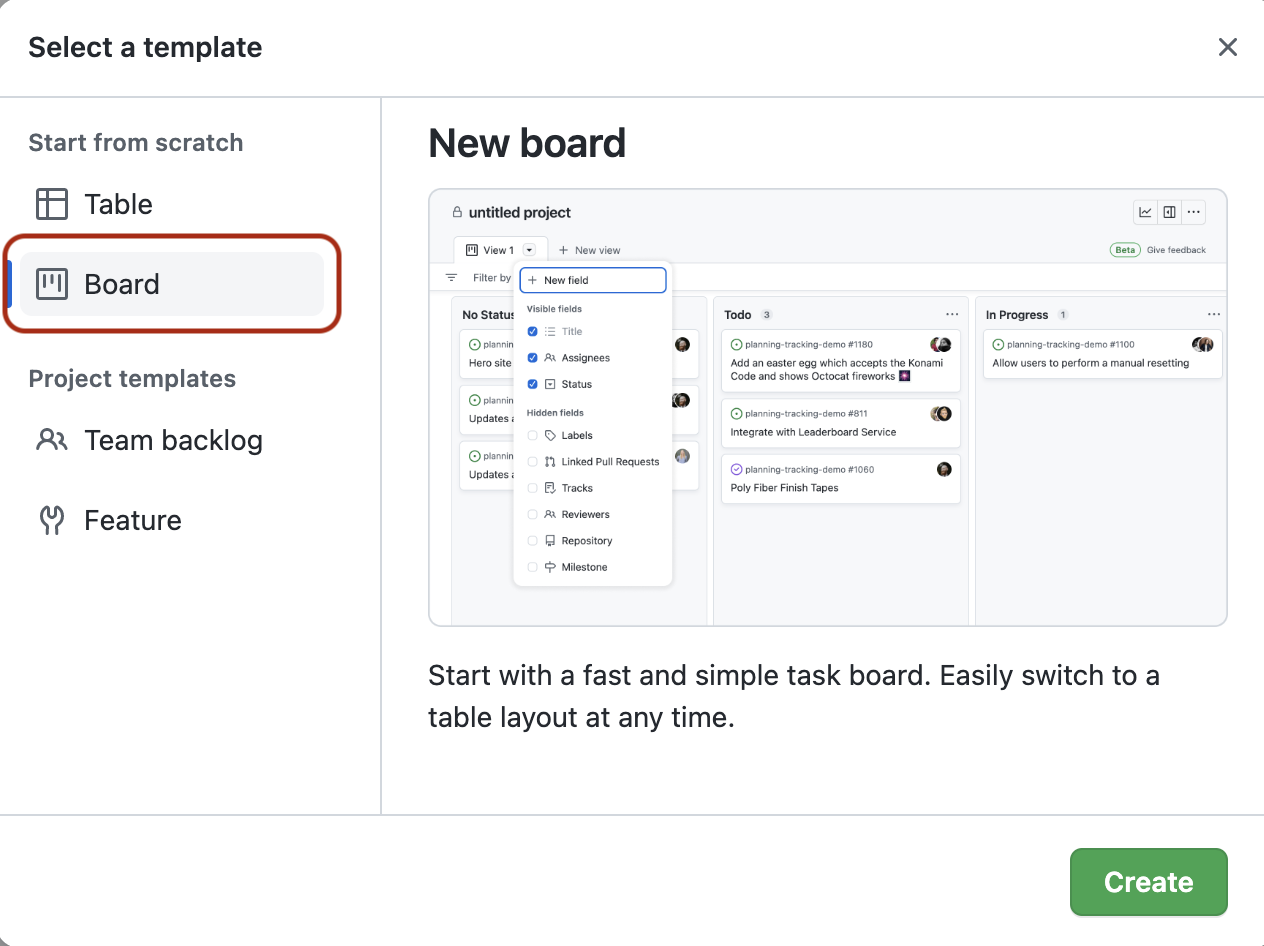
-
GitHub will create an unnamed project board for you. You should populate the name and the description of the project from the project’s Settings, which can be found by clicking the
...button in the top right corner of the board.
-
We can, for example, use “Inflammation project - release v0.1” and “Tasks for the v0.1 release of the inflammation project” for the name and description of our project, respectively. Or you can use anything that suits your project.
-
GitHub’s default card board template contains the following three columns with pretty self-explanatory names:
To DoIn ProgressDone
You can add or remove columns from your project board to suit your use case. One commonly seen extra column is
On holdorWaiting- if you have tasks that get held up by waiting on other people (e.g. to respond to your questions) then moving them to a separate column makes their current state clearer.To add a new column, press the
+button on the right; to remove a column select the...button in the top right corner of the column itself and then theDelete columnoption. -
You can now add new items (cards) to columns by pressing the
+ Add itembutton at the bottom of each column (see the previous image) - a text box to add a card will appear. Cards can be simple textual notes which you type into the text box and presEnterwhen finished. Cards can also be (links to) existing issues and pull requests, which can be filtered out from the text box by pressing#(to activate GitHub’s referencing mechanism) and selecting the repository and an issue or pull request from that repository that you want to add.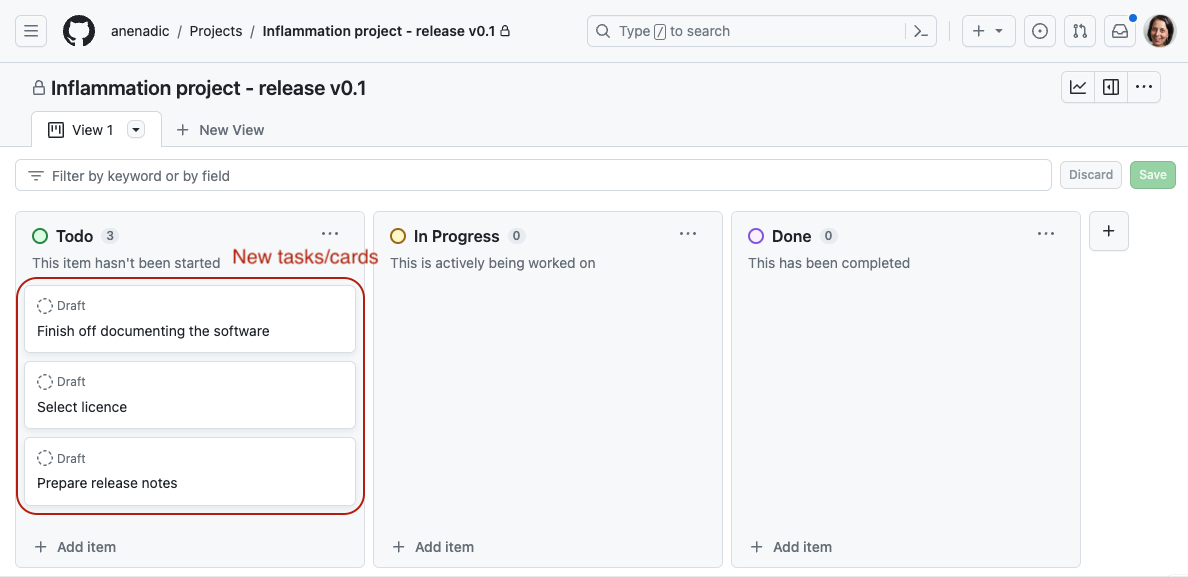
Notes contain task descriptions and can have detailed content like checklists. In some cases, e.g. if a note becomes too complex, you may want to convert it into an issue so you can add labels, assign them to team members or write more detailed comments (for that, use the
Convert to issueoption from the...menu on the card itself).
- In addition to creating new tasks as notes and converting them to issues -
you can add an existing issue or pull request (from any repository visible to you)
as a task on a column by pasting its URL into the
Add itemfield and pressing theEnterkey. - You can drag a task/card from
TodotoIn Progresscolumn to indicate that you are working on it or to theDonecolumn to indicate that it has been completed. Issues and pull requests on cards will automatically be moved to theDonecolumn for you when you close the issue or merge the pull request - which is very convenient and can save you some project management time.
Exercise: Working With Projects
Spend a few minutes planning what you want to do with your project as a bigger chunk of work (you can continue working on the first release of your software if you like) and play around with your project board to manage tasks around the project:
- practice adding and removing columns,
- practice adding different types of cards (notes and from already existing open issues and/or unmerged pull requests),
- practice turing cards into issues and closing issues, etc.
Make sure to add a certain number of issues to your repository to be able to use in your project board.
Time: 10 mins
Prioritisation With Project Boards
Once your project board has a large number of cards on it, you might want to begin priorisiting them. Not all tasks are going to be equally important, and some will require others to be completed before they can even be begun. Common methods of prioritisation include:
- Vertical position: the vertical arrangement of cards in a column implicitly represents their importance. High-priority issues go to the top of
To Do, whilst tasks that depend on others go beneath them. This is the easiest one to implement, though you have to remember to correctly place cards when you add them.- Priority columns: instead of a single
To Docolumn, you can have two or more, for example -To Do: Low PriorityandTo Do: High Priority. When adding a card, you pick which is the appropriate column for it. You can even add aTriagecolumn for newly-added issues that you’ve not yet had time to classify. This format works well for project boards devoted to bugs.- Labels: if you convert each card into an issue, then you can label them with their priority - remember GitHub lets you create custom labels and set their colours. Label colours can provide a very visually clear indication of issue priority but require more administrative work on the project, as each card has to be an issue to be assigned a label. If you choose this route for issue prioritisation - be aware of accessibility issues for colour-blind people when picking colours.
Key Points
We should use GitHub’s Issues to keep track of software problems and other requests for change - even if we are the only developer and user.
GitHub’s Mentions play an important part in communicating between collaborators and is used as a way of alerting team members of activities and referencing one issue/pull requests/comment/commit from another.
Without a good project and issue management framework, it can be hard to keep track of what’s done, or what needs doing, and particularly difficult to convey that to others in the team or sharing the responsibilities.
Assessing Software for Suitability and Improvement
Overview
Teaching: 15 min
Exercises: 30 minQuestions
What makes good code actually good?
What should we look for when selecting software to reuse?
Objectives
Explain why a critical mindset is important when selecting software
Conduct an assessment of software against suitability criteria
Describe what should be included in software issue reports and register them
Introduction
What we’ve been looking at so far enables us to adopt a more proactive and managed attitude and approach to the software we develop. But we should also adopt this attitude when selecting and making use of third-party software we wish to use. With pressing deadlines it’s very easy to reach for a piece of software that appears to do what you want without considering properly whether it’s a good fit for your project first. A chain is only as strong as its weakest link, and our software may inherit weaknesses in any dependent software or create other problems.
Overall, when adopting software to use it’s important to consider not only whether it has the functionality you want, but a broader range of qualities that are important for your project. Adopting a critical mindset when assessing other software against suitability criteria will help you adopt the same attitude when assessing your own software for future improvements.
Assessing Software for Suitability
Exercise: Decide on Your Group’s Repository!
You all have your code repositories you have been working on throughout the course so far. For the upcoming exercise, groups will exchange repositories and review the code of the repository they inherit, and provide feedback.
Time: 5 mins
- Decide as a team on one of your repositories that will represent your group. You can do this any way you wish, but if you are having trouble then a pseudo-random number might help:
python -c "import numpy as np; print(np.random.randint(low=1, high=<size_group_plus_1>))"- Add the URL of the repository to the section of the shared notes labelled ‘Decide on your Group’s Repository’, next to your team’s name.
Exercise: Conduct Assessment on Third-Party Software
The scenario: It is envisaged that a piece of software developed by another team will be adopted and used for the long term in a number of future projects. You have been tasked with conducting an assessment of this software to identify any issues that need resolving prior to working with it, and will provide feedback to the developing team to fix these issues.
Time: 20 mins
- As a team, briefly decide who will assess which aspect of the repository, e.g. its documentation, tests, codebase, etc.
- Obtain the URL for the repository you will assess from the shared notes document, in the section labelled ‘Decide on your Group’s Repository’ - see the last column which indicates which team’s repository you are assessing.
- Conduct the assessment and register any issues you find on the other team’s software repository on GitHub.
- Be meticulous in your assessment and register as many issues as you can!
Supporting Your Software - How and How Much?
Within your collaborations and projects, what should you do to support other users? Here are some key aspects to consider:
- Provide contact information: so users know what to do and how to get in contact if they run into problems
- Manage your support: an issue tracker - like the one in GitHub - is essential to track and manage issues
- Manage expectations: let users know the level of support you offer, in terms of when they can expect responses to queries, the scope of support (e.g. which platforms, types of releases, etc.), the types of support (e.g. bug resolution, helping develop tailored solutions), and expectations for support in the future (e.g. when project funding runs out)
All of this requires effort, and you can’t do everything. It’s therefore important to agree and be clear on how the software will be supported from the outset, whether it’s within the context of a single laboratory, project, or other collaboration, or across an entire community.
Key Points
It’s as important to have a critical attitude to adopting software as we do to developing it.
As a team agree on who and to what extent you will support software you make available to others.
Software Improvement Through Feedback
Overview
Teaching: 5 min
Exercises: 45 minQuestions
How should we handle feedback on our software?
How, and to what extent, should we provide support to our users?
Objectives
Prioritise and work on externally registered issues
Respond to submitted issue reports and provide feedback
Explain the importance of software support and choosing a suitable level of support
Introduction
When a software project has been around for even just a short amount of time, you’ll likely discover many aspects that can be improved. These can come from issues that have been registered via collaborators or users, but also those you’re aware of internally, which should also be registered as issues. When starting a new software project, you’ll also have to determine how you’ll handle all the requirements. But which ones should you work on first, which are the most important and why, and how should you organise all this work?
Software has a fundamental role to play in doing science, but unfortunately software development is often given short shrift in academia when it comes to prioritising effort. There are also many other draws on our time in addition to the research, development, and writing of publications that we do, which makes it all the more important to prioritise our time for development effectively.
In this lesson we’ll be looking at prioritising work we need to do and what we can use from the agile perspective of project management to help us do this in our software projects.
Estimation as a Foundation for Prioritisation
For simplicity, we’ll refer to our issues as requirements, since that’s essentially what they are - new requirements for our software to fulfil.
But before we can prioritise our requirements, there are some things we need to find out.
Firstly, we need to know:
- The period of time we have to resolve these requirements - e.g. before the next software release, pivotal demonstration, or other deadlines requiring their completion. This is known as a timebox. This might be a week or two, but for agile, this should not be longer than a month. Longer deadlines with more complex requirements may be split into a number of timeboxes.
- How much overall effort we have available -
- i.e. who will be involved and how much of their time we will have during this period.
We also need estimates for how long each requirement will take to resolve, since we cannot meaningfully prioritise requirements without knowing what the effort tradeoffs will be. Even if we know how important each requirement is, how would we even know if completing the project is possible? Or if we don’t know how long it will take to deliver those requirements we deem to be critical to the success of a project, how can we know if we can include other less important ones?
It is often not the reality, but estimation should ideally be done by the people likely to do the actual work (i.e. the Research Software Engineers, researchers, or developers). It shouldn’t be done by project managers or PIs simply because they are not best placed to estimate, and those doing the work are the ones who are effectively committing to these figures.
Why is it so Difficult to Estimate?
Estimation is a very valuable skill to learn, and one that is often difficult. Lack of experience in estimation can play a part, but a number of psychological causes can also contribute. One of these is Dunning-Kruger, a type of cognitive bias in which people tend to overestimate their abilities, whilst in opposition to this is imposter syndrome, where due to a lack of confidence people underestimate their abilities. The key message here is to be honest about what you can do, and find out as much information that is reasonably appropriate before arriving at an estimate.
More experience in estimation will also help to reduce these effects. So keep estimating!
An effective way of helping to make your estimates more accurate is to do it as a team. Other members can ask prudent questions that may not have been considered, and bring in other sanity checks and their own development experience. Just talking things through can help uncover other complexities and pitfalls, and raise crucial questions to clarify ambiguities.
Where to Record Effort Estimates?
There is no dedicated place to record the effort estimate on an issue in current GitHub’s interface. Therefore, you can agree on a convention within your team on how to record this information - e.g. you can add the effort in person/days in the issue title. Recording estimates within comments on an issue may not be the best idea as it may get lost among other comments. Another place where you can record estimates for your issues is on project boards - there is no default field for this but you can create a custom numeric field and use it to assign effort estimates (note that you cannot sum them yet in the current GitHub’s interface).
Exercise: Estimate!
As a team go through the issues that your partner team has registered with your software repository, and quickly estimate how long each issue will take to resolve in minutes. Do this by blind consensus first, each anonymously submitting an estimate, and then briefly discuss your rationale and decide on a final estimate. Make sure these are honest estimates, and you are able to complete them in the allotted time!
Time: 15 mins
Using MoSCoW to Prioritise Work
Now we have our estimates we can decide how important each requirement is to the success of the project. This should be decided by the project stakeholders; those - or their representatives - who have a stake in the success of the project and are either directly affected or affected by the project, e.g. Principle Investigators, researchers, Research Software Engineers, collaborators, etc.
To prioritise these requirements we can use a method called MoSCoW, a way to reach a common understanding with stakeholders on the importance of successfully delivering each requirement for a timebox. MoSCoW is an acronym that stands for Must have, Should have, Could have, and Won’t have. Each requirement is discussed by the stakeholder group and falls into one of these categories:
- Must Have (MH) - these requirements are critical to the current timebox for it to succeed. Even the inability to deliver just one of these would cause the project to be considered a failure.
- Should Have (SH) - these are important requirements but not necessary for delivery in the timebox. They may be as important as Must Haves, but there may be other ways to achieve them or perhaps they can be held back for a future development timebox.
- Could Have (CH) - these are desirable but not necessary, and each of these will be included in this timebox if it can be achieved.
- Won’t Have (WH) - these are agreed to be out of scope for this timebox, perhaps because they are the least important or not critical for this phase of development.
In typical use, the ratio to aim for of requirements to the MH/SH/CH categories is 60%/20%/20% for a particular timebox. Importantly, the division is by the requirement estimates, not by number of requirements, so 60% means 60% of the overall estimated effort for requirements are Must Haves.
Why is this important? Because it gives you a unique degree of control of your project for each time period. It awards you 40% of flexibility with allocating your effort depending on what’s critical and how things progress. This effectively forces a tradeoff between the effort available and critical objectives, maintaining a significant safety margin. The idea is that as a project progresses, even if it becomes clear that you are only able to deliver the Must Haves for a particular time period, you have still delivered it successfully.
GitHub’s Milestones
Once we’ve decided on those we’ll work on (i.e. not Won’t Haves),
we can (optionally) use a GitHub’s Milestone to organise them for a particular timebox.
Remember, a milestone is a collection of issues to be worked on in a given period (or timebox).
We can create a new one by selecting Issues on our repository,
then Milestones to display any existing milestones,
then clicking the “New milestone” button to the right.
We add in a title, a completion date (i.e. the end of this timebox), and any description for the milestone.
Once created, we can view our issues
and assign them to our milestone from the Issues page or from an individual issue page.
Let’s now use Milestones to plan and prioritise our team’s next sprint.
Exercise: Prioritise!
Put your stakeholder hats on, and as a team apply MoSCoW to the repository issues to determine how you will prioritise effort to resolve them in the allotted time. Try to stick to the 60/20/20 rule, and assign all issues you’ll be working on (i.e. not
Won't Haves) to a new milestone, e.g. “Tidy up documentation” or “version 0.1”.Time: 10 mins
Using Sprints to Organise and Work on Issues
A sprint is an activity applied to a timebox, where development is undertaken on the agreed prioritised work for the period. In a typical sprint, there are daily meetings called scrum meetings which check on how work is progressing, and serves to highlight any blockers and challenges to meeting the sprint goal.
Exercise: Conduct a Mini Mini-Sprint
For the remaining time in this course, assign repository issues to team members and work on resolving them as per your MoSCoW breakdown. Once an issue has been resolved, notable progress made, or an impasse has been reached, provide concise feedback on the repository issue. Be sure to add the other team members to the chosen repository so they have access to it. You can grant
Writeaccess to others on a GitHub repository via theSettingstab for a repository, then selectingCollaborators, where you can invite other GitHub users to your repository with specific permissions.Time: however long is left
Depending on how many issues were registered on your repository, it’s likely you won’t have resolved all the issues in this first milestone. Of course, in reality, a sprint would be over a much longer period of time. In any event, as the development progresses into future sprints any unresolved issues can be reconsidered and prioritised for another milestone, which are then taken forward, and so on. This process of receiving new requirements, prioritisation, and working on them is naturally continuous - with the benefit that at key stages you are repeatedly re-evaluating what is important and needs to be worked on which helps to ensure real concrete progress against project goals and requirements which may change over time.
Project Boards For Planning Sprints
Remember, you can use project boards for higher-level project management - e.g. planning several sprints in advance (and use milestones for tracking progress on individual sprints).
Key Points
Prioritisation is a key tool in academia where research goals can change and software development is often given short shrift.
In order to prioritise things to do we must first estimate the effort required to do them.
For accurate effort estimation, it should be done by the people who will actually do the work.
Aim to reduce cognitive biases in effort estimation by being honest about your abilities.
Ask other team members - or do estimation as a team - to help make accurate estimates.
MoSCoW is a useful technique for prioritising work to help ensure projects deliver successfully.
Aim for a 60%/20%/20% ratio of Must Haves/Should Haves/Could Haves for requirements within a timebox.
Wrap-up
Overview
Teaching: 15 min
Exercises: 0 minQuestions
Looking back at what was covered and how different pieces fit together
Where are some advanced topics and further reading available?
Objectives
Put the course in context with future learning.
Summary
As part of this course we have looked at a core set of established, intermediate-level software development tools and best practices for working as part of a team. The course teaches a selected subset of skills that have been tried and tested in collaborative research software development environments, although not an all-encompassing set of every skill you might need (check some further reading). It will provide you with a solid basis for writing industry-grade code, which relies on the same best practices taught in this course:
- Collaborative techniques and tools play an important part of research software development in teams, but also have benefits in solo development. We’ve looked at the benefits of a well-considered development environment, using practices, tools and infrastructure to help us write code more effectively in collaboration with others.
- We’ve looked at the importance of being able to verify the correctness of software and automation, and how we can leverage techniques and infrastructure to automate and scale tasks such as testing to save us time - but automation has a role beyond simply testing: what else can you automate that would save you even more time? Once found, we’ve also examined how to locate faults in our software.
- We’ve gone beyond procedural programming and explored different software design paradigms, such as object-oriented and functional styles of programming. We’ve contrasted their pros, cons, and the situations in which they work best, and how separation of concerns through modularity and architectural design can help shape good software.
- As an intermediate developer, aspects other than technical skills become important, particularly in development teams. We’ve looked at the importance of good, consistent practices for team working, and the importance of having a self-critical mindset when developing software, and ways to manage feedback effectively and efficiently.
Reflection Exercise: Putting the Pieces Together
As a group, reflect on the concepts (e.g. tools, techniques and practices) covered throughout the course, how they relate to one another, how they fit together in a bigger picture or skill learning pathways and in which order you need to learn them.
Solution
One way to think about these concepts is to make a list and try to organise them along two axes - ‘perceived usefulness of a concept’ versus ‘perceived difficulty or time needed to master a concept’, as shown in the table below (for the exercise, you can make your own copy of the template table for the purpose of this exercise). You then may think in which order you want to learn the skills and how much effort they require - e.g. start with those that are more useful but, for the time being, hold off those that are not too useful to you and take loads of time to master. You will likely want to focus on the concepts in the top right corner of the table first, but investing time to master more difficult concepts may pay off in the long run by saving you time and effort and helping reduce technical debt.
Another way you can organise the concepts is using a concept map (a directed graph depicting suggested relationships between concepts) or any other diagram/visual aid of your choice. Below are some example views of tools and techniques covered in the course using concept maps. Your views may differ but that is not to say that either view is right or wrong. This exercise is meant to get you to reflect on what was covered in the course and hopefully to reinforce the ideas and concepts you learned.
A different concept map tries to organise concepts/skills based on their level of difficulty (novice, intermediate and advanced, and in-between!) and tries to show which skills are prerequisite for others and in which order you should consider learning skills.
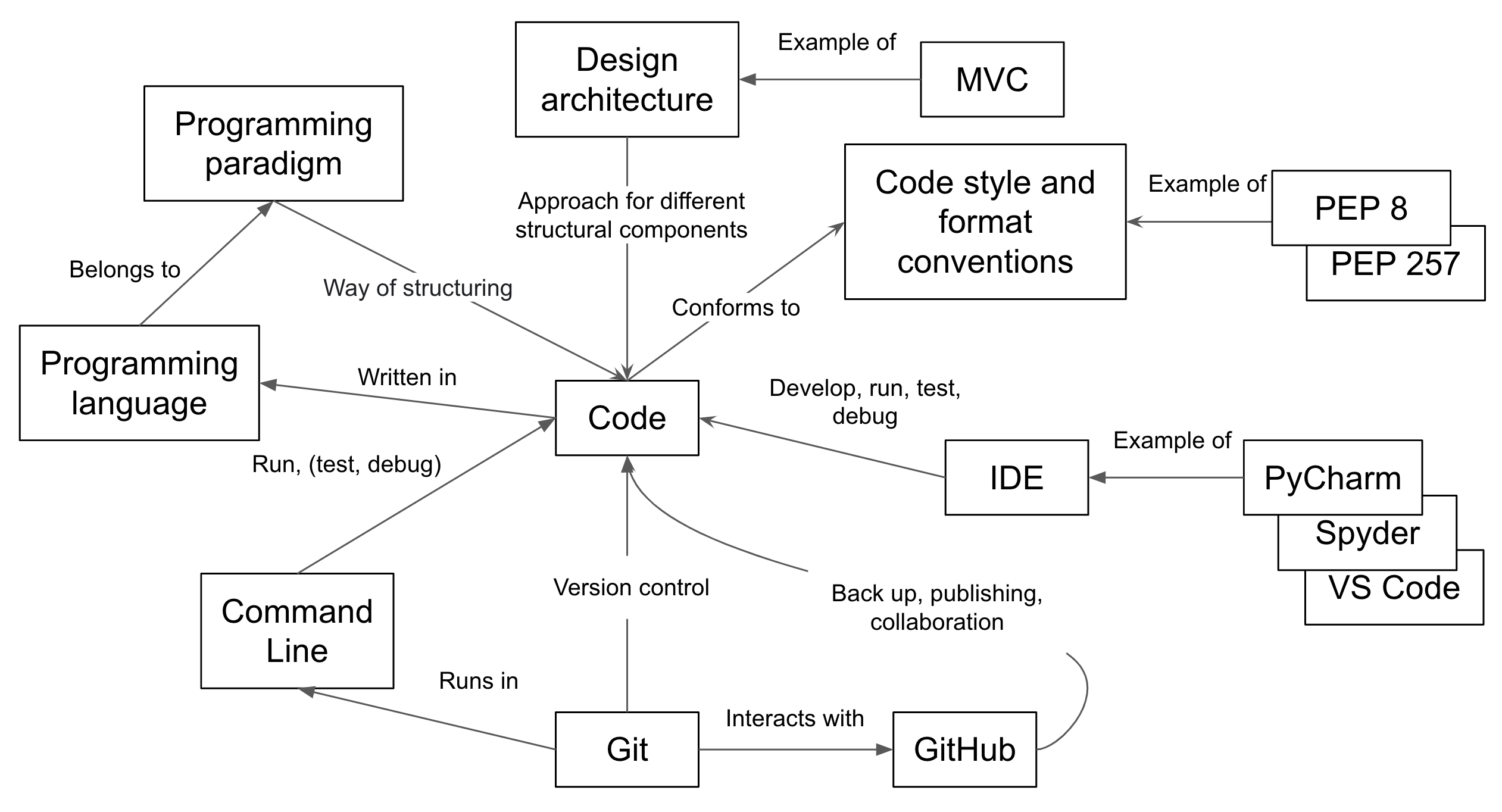
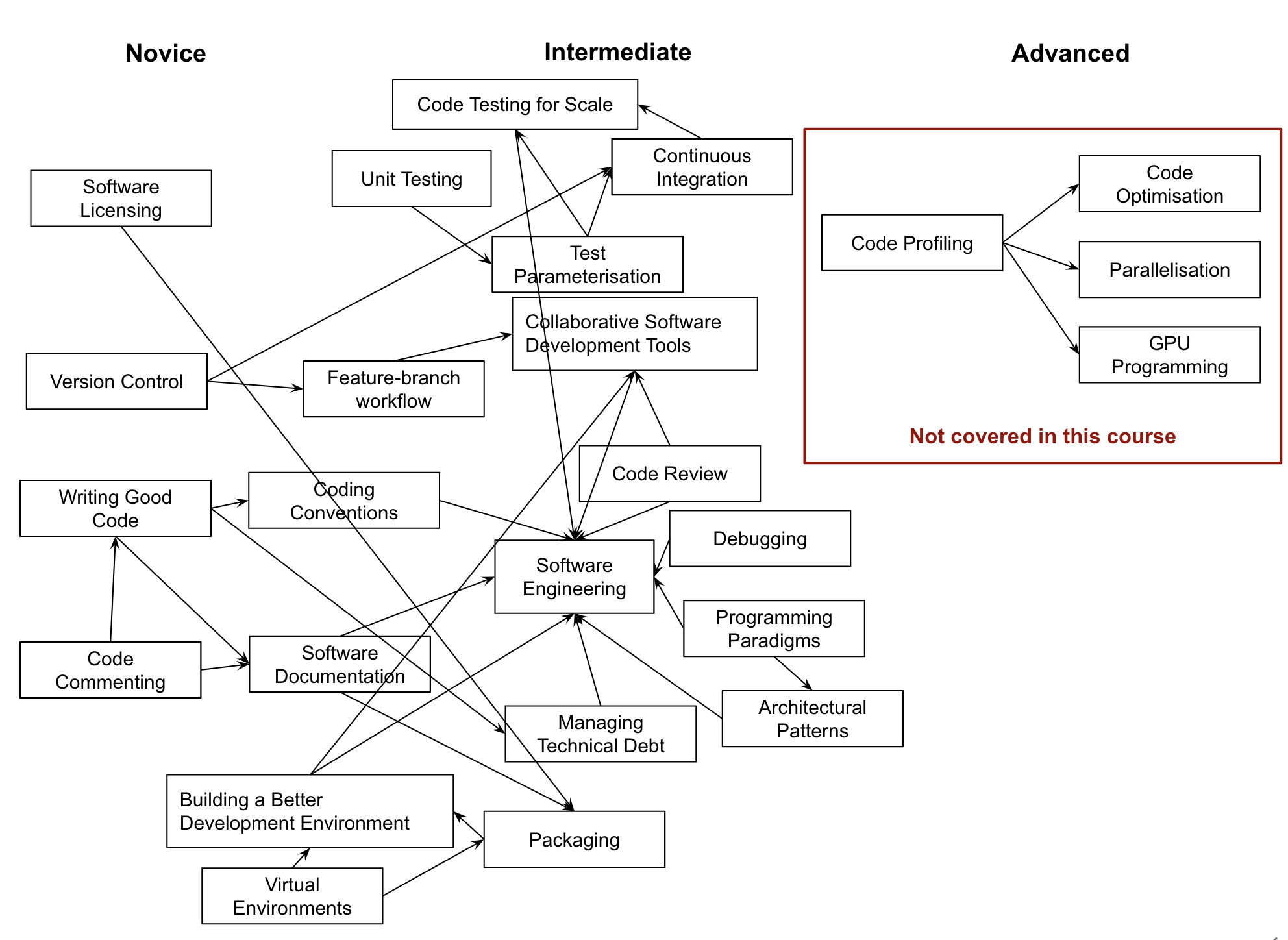
Further Resources
Below are some additional resources to help you continue learning:
- Additional episode on persisting data
- Additional episode on databases
- CodeRefinery courses on FAIR (Findable, Accessible, Interoperable, and Reusable) software practices
- Python documentation
- GitHub Actions documentation
Key Points
Collaborative techniques and tools play an important part of research software development in teams.