Data leakage
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What are common types of data leakage?
How does data leakage occur?
What are the implications of data leakage?
Objectives
Learn to recognise common causes of data leakage.
Understand how data leakage affects models.
Data leakage
Data leakage is the mistaken use of information in the model training process that in reality would not be available at prediction time. The result of data leakage is overly optimistic expectations and poor performance in out-of-sample datasets.
An extreme example of data leakage would be accidentally including a prediction target in a training dataset. In this case our model would perform very well on training data. The model would fail, however, when moved to a real-life setting where the outcome was not available at prediction time.
In most cases information leakage is much more subtle than including the outcome in the training data, and it may occur at many stages during the model training process.
Subset contamination
It is common to impute missing values, for example by replacing missing values with the mean or median. Similarly, data is often normalised by dividing through by the average or maximum.
If these steps are done using the full dataset (i.e. the training and testing data), then information about the testing data will “leak” into the training data. The result is likely to be overoptimistic performance on the test set. For this reason, imputation and normalisation should be done on subsets independently.
Another issue that can lead to data leakage is to not account for grouping within a dataset when creating train-test splits. Let’s say, for example, that we are trying to use chest x-rays to predict which patients have cardiac disease. If the same patient appears multiple times within our dataset and this patient appears in both our training and test set, this may be cause for concern.
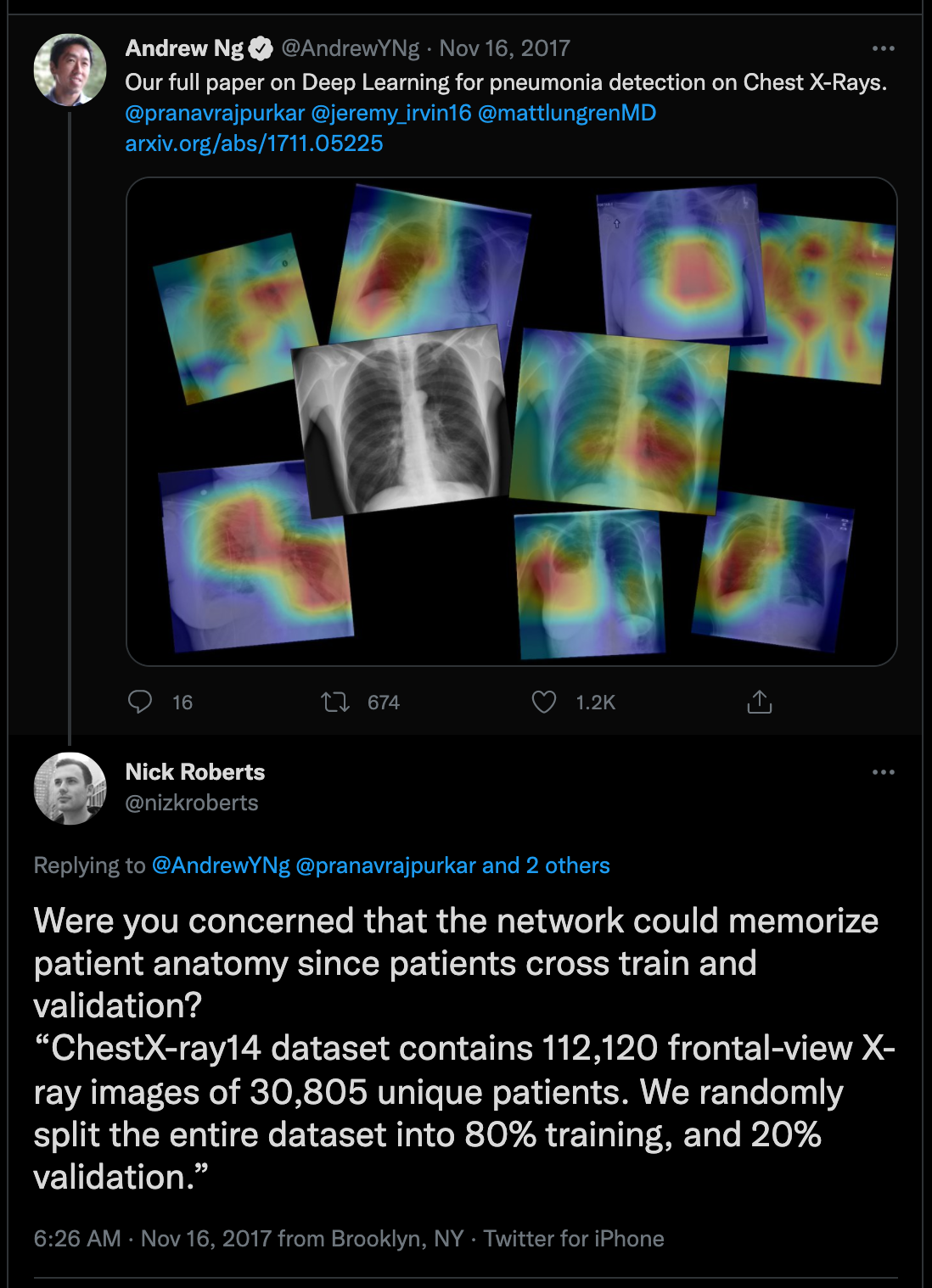
Target leakage
Target leakage occurs when a prediction target is inadvertently used in the training process.
The following abstract is taken from a 2018 paper entitled: “Prediction of Incident Hypertension Within the Next Year: Prospective Study Using Statewide Electronic Health Records and Machine Learning”:
Background: As a high-prevalence health condition, hypertension is clinically costly, difficult to manage, and often leads to severe and life-threatening diseases such as cardiovascular disease (CVD) and stroke.
Objective: The aim of this study was to develop and validate prospectively a risk prediction model of incident essential hypertension within the following year.
Methods: Data from individual patient electronic health records (EHRs) were extracted from the Maine Health Information Exchange network. Retrospective (N=823,627, calendar year 2013) and prospective (N=680,810, calendar year 2014) cohorts were formed. A machine learning algorithm, XGBoost, was adopted in the process of feature selection and model building. It generated an ensemble of classification trees and assigned a final predictive risk score to each individual.
Results: The 1-year incident hypertension risk model attained areas under the curve (AUCs) of 0.917 and 0.870 in the retrospective and prospective cohorts, respectively. Risk scores were calculated and stratified into five risk categories, with 4526 out of 381,544 patients (1.19%) in the lowest risk category (score 0-0.05) and 21,050 out of 41,329 patients (50.93%) in the highest risk category (score 0.4-1) receiving a diagnosis of incident hypertension in the following 1 year. Type 2 diabetes, lipid disorders, CVDs, mental illness, clinical utilization indicators, and socioeconomic determinants were recognized as driving or associated features of incident essential hypertension. The very high risk population mainly comprised elderly (age>50 years) individuals with multiple chronic conditions, especially those receiving medications for mental disorders. Disparities were also found in social determinants, including some community-level factors associated with higher risk and others that were protective against hypertension.
Conclusions: With statewide EHR datasets, our study prospectively validated an accurate 1-year risk prediction model for incident essential hypertension. Our real-time predictive analytic model has been deployed in the state of Maine, providing implications in interventions for hypertension and related diseases and hopefully enhancing hypertension care.
Exercise
A) What is the prediction target?
B) What kind of algorithm is used in the study?
C) What performance metric is reported in the results?
D) How many features were included in the model? (Hint: see Appendix 3 in the paper)Solution
A) The prediction target is “hypertension within the following year.”
B) The study uses XGBoost, a tree based model.
C) The abstract reports AUC (Area under the Receiver Operating Characteristic Curve.
D) Appendix 3 includes a list of features. There are 80 in total.
In a subsequent paper, entitled Data Leakage in Health Outcomes Prediction With Machine Learning Chiavegatto, Filho et al reflect on the previous study. The abstract is copied below:
The objective of the study was to “develop and validate prospectively a risk prediction model of incident essential hypertension within the following year.” The authors follow good prediction protocols by applying a high-performing machine learning algorithm (XGBoost) and by validating the results on unseen data from the following year. The algorithm attained a very high area under the curve (AUC) value of 0.870 for incidence prediction of hypertension in the following year.
The authors follow this impressive result by commenting on some of the most important predictive variables, such as demographic features, diagnosed chronic diseases, and mental illness. The ranking of the variables that were most important for the predictive performance of hypertension is included in a multimedia appendix; however, the above-mentioned variables are not listed near the top. Of the six most important variables, five were: lisinopril, hydrochlorothiazide, enalapril maleate, amlodipine besylate, and losartan potassium. All of these are popular antihypertensive drugs.
By including the use of antihypertensive drugs as predictors for hypertension incidence in the following year, Dr Ye and colleagues’work opens the possibility that the machine learning algorithm will focus on predicting those already with hypertension but did not have this information on their medical record at baseline. … just one variable (the use of a hypertension drug) is sufficient for physicians to infer the presence of hypertension.
Exercise
A) What are lisinopril, hydrochlorothiazide, enalapril maleate, amlodipine besylate, and losartan potassium?
B) Why is it problematic that these drugs are included as features in the model?Solution
A) They are drugs that are prescribed to people with hypertension.
B) The fact that patients were taking the drugs suggests that hypertension was already known.
Key Points
Leakage occurs when training data is contaminated with information that is not available at prediction time.
Leakage leads to over-optimistic expectations of performance.