Modelling
Overview
Teaching: 20 min
Exercises: 20 minQuestions
Broadly speaking, when talking about regression and classification, how does the prediction target differ?
Would linear regression be most useful for a regression or classification task? How about logistic regression?
Objectives
Use a linear regression model for prediction.
Use a logistic regression model for prediction.
Set a decision boundary to predict an outcome from a probability.
Regression vs classification
Predicting one or more classes is typically referred to as classification. The task of predicting a continuous variable on the other hand (for example, length of hospital stay) is typically referred to as a regression.
Note that “regression models” can be used for both regression tasks and classification tasks. Don’t let this throw you off!
We will begin with a linear regression, a type of model borrowed from statistics that has all of the hallmarks of machine learning (so let’s call it a machine learning model!), which can be written as:
\[\hat{y} = wX + b\]Our predictions can be denoted by $\hat{y}$ (pronounced “y hat”) and our explanatory variables (or “features”) denoted by $X$. In our case, we will use a single feature: the APACHE-IV score, a measure of severity of illness.
There are two parameters of the model that we would like to learn from the training data: $w$, weight and $b$, bias. Could we use a linear regression for our classification task? Let’s try fitting a line to our outcome data.
# import the regression model
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
# use a single feature (apache score)
# note: remove the reshape if fitting to >1 input variable
X = cohort.apachescore.values.reshape(-1, 1)
y = cohort.actualhospitalmortality_enc.values
# fit the model to our data
reg = reg.fit(X, y)
# get the y values
buffer = 0.2*max(X)
X_fit = np.linspace(min(X) - buffer, max(X) + buffer, num=50)
y_fit = reg.predict(X_fit)
# plot
plt.scatter(X, y, color='black', marker = 'x')
plt.plot(X_fit, y_fit, color='red', linewidth=2)
plt.show()
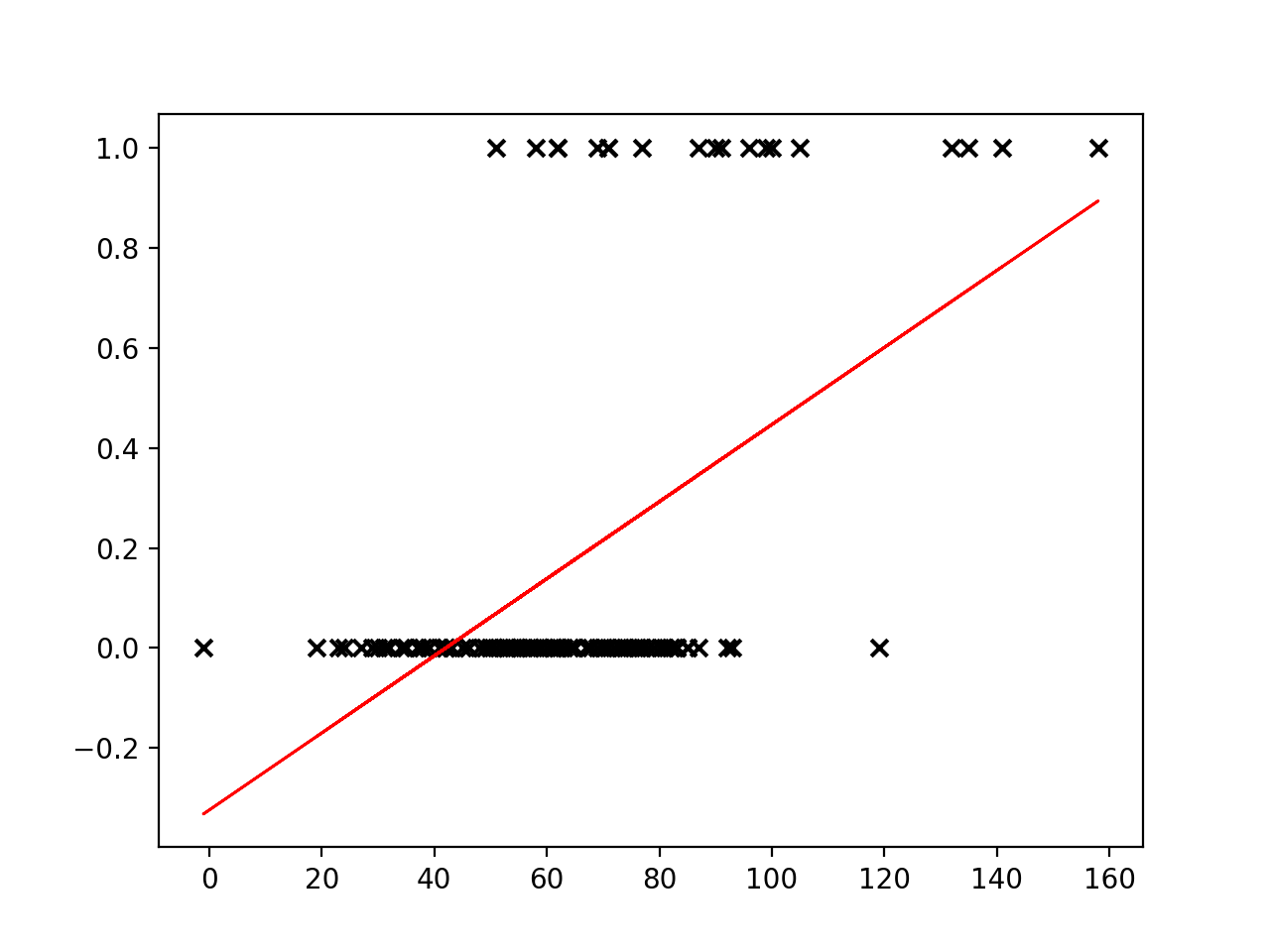
Linear regression places a line through a set of data points that minimizes the error between the line and the points. It is difficult to see how a meaningful threshold could be set to predict the binary outcome in our task. The predicted values can exceed our range of outcomes.
Sigmoid function
The sigmoid function (also known as a logistic function) comes to our rescue. This function gives an “s” shaped curve that can take a number and map it into a value between 0 and 1:
\[f : \mathbb{R} \mapsto (0,1)\]The sigmoid function can be written as:
\[f(x) = \frac{1}{1+e^{-x}}\]Let’s take a look at a curve generated by this function:
def sigmoid(x, k=0.1):
"""
Sigmoid function.
Adjust k to set slope.
"""
s = 1 / (1 + np.exp(-x / k))
return s
# set range of values for x
x = np.linspace(-1, 1, 50)
plt.plot(x, sigmoid(x))
plt.show()
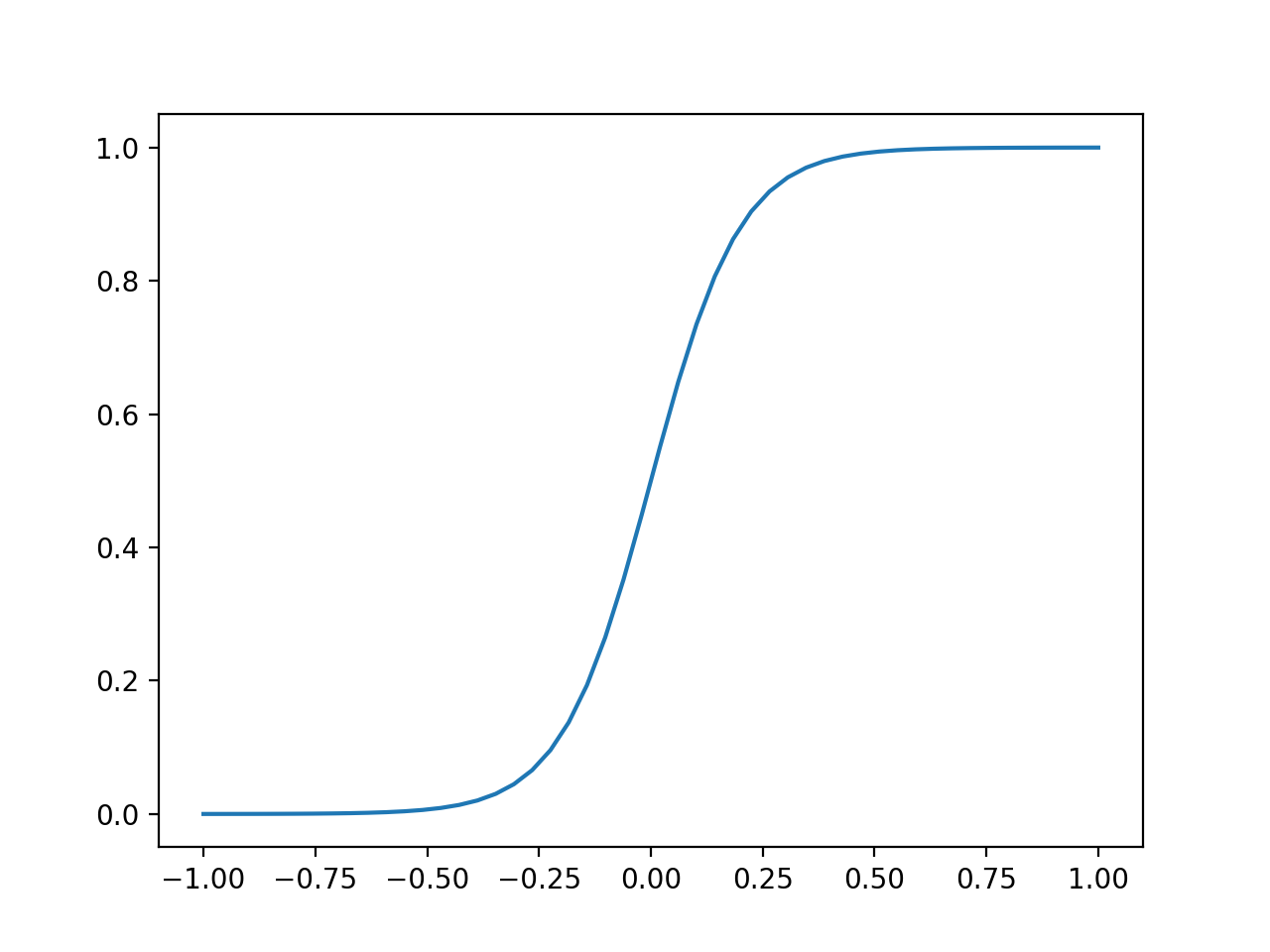
We can use this to map our linear regression to produce output values that fall between 0 and 1.
\[f(x) = \frac{1}{1+e^{-({wX + b})}}\]As an added benefit, we can interpret the output value as a probability. The probability relates to the positive class (the outcome with value “1”), which in our case is in-hospital mortality (“EXPIRED”).
Logistic regression
Logistic regressions are powerful models that often outperform more sophisticated machine learning models. In machine learning studies it is typical to include performance of a logistic regression model as a baseline (as they do, for example, in Rajkomar and colleagues).
We need to find the parameters for the best-fitting logistic model given our data. As before, we do this with the help of a loss function that quantifies error. Our goal is to find the parameters of the model that minimise the error. With this model, we no longer use least squares due to the model’s non-linear properties. Instead we will use log loss.
Training (or fitting) the model
As is typically the case when using machine learning packages, we don’t need to code the loss function ourselves. The function is implemented as part of our machine learning package (in this case scikit-learn). Let’s try fitting a Logistic Regression to our data.
Exercise
A) Following the previous example for a linear regression, fit a logistic regression to your data and create a new plot. How do the predictions differ from before? Hint:
from sklearn.linear_model import LogisticRegression.Solution
A) You should see a plot similar to the one below:
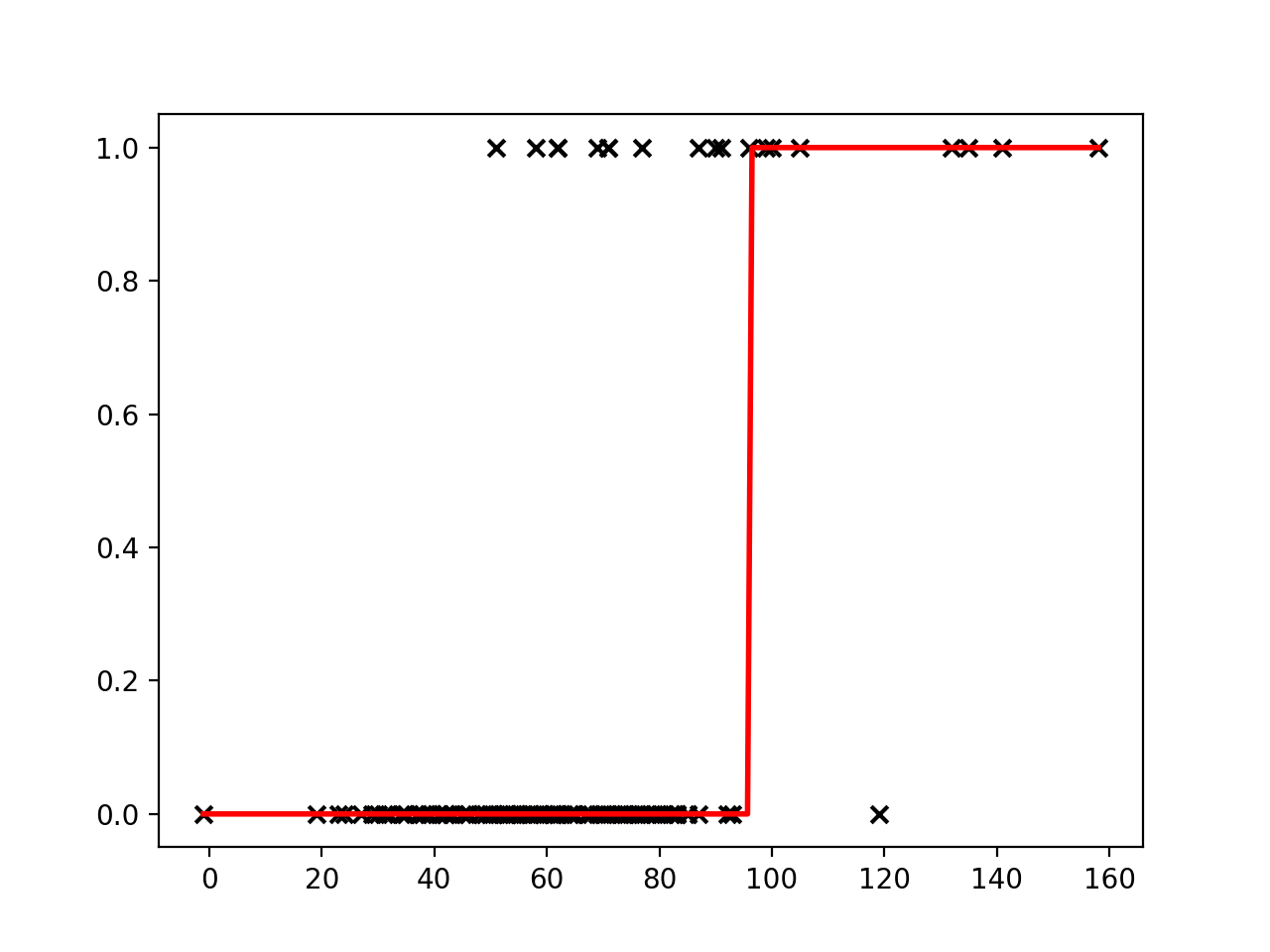
Decision boundary
Now that our model is able to output the probability of our outcome, we can set a decision boundary for the classification task. For example, we could classify probabilities of < 0.5 as “ALIVE” and >= 0.5 as “EXPIRED”. Using this approach, we can predict outcomes for a given input.
x = [[90]]
outcome = reg.predict(x)
probs = reg.predict_proba(x)[0]
print(f'For x={x[0][0]}, we predict an outcome of "{outcome[0]}".\n'
f'Class probabilities (0, 1): {round(probs[0],2), round(probs[1],2)}.')
For x=90, we predict an outcome of "0".
Class probabilities (0, 1): (0.77, 0.23).
Key Points
Linear regression is a popular model for regression tasks.
Logistic regression is a popular model for classification tasks.
Probabilities that can be mapped to a prediction class.