Validation
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is meant by model accuracy?
What is the purpose of a validation set?
What are two types of cross validation?
What is overfitting?
Objectives
Train a model to predict patient outcomes on a held-out test set.
Use cross validation as part of our model training process.
Accuracy
One measure of the performance of a classification model is accuracy. Accuracy is defined as the overall proportion of correct predictions. If, for example, we take 50 shots and 40 of them hit the target, then our accuracy is 0.8 (40/50).

Accuracy can therefore be defined by the formula below:
\[Accuracy = \frac{Correct\ predictions}{All\ predictions}\]What is the accuracy of our model at predicting in-hospital mortality?
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# convert outcome to a categorical type
categories=['ALIVE', 'EXPIRED']
cohort['actualhospitalmortality'] = pd.Categorical(cohort['actualhospitalmortality'], categories=categories)
# add the encoded value to a new column
cohort['actualhospitalmortality_enc'] = cohort['actualhospitalmortality'].cat.codes
cohort[['actualhospitalmortality_enc','actualhospitalmortality']].head()
# define features and outcome
features = ['apachescore']
outcome = ['actualhospitalmortality_enc']
# partition data into training and test sets
X = cohort[features]
y = cohort[outcome]
x_train, x_test, y_train, y_test = train_test_split(X, y, train_size = 0.7, random_state = 42)
# restructure data for input into model
# note: remove the reshape if fitting to >1 input variable
x_train = x_train.values.reshape(-1, 1)
y_train = y_train.values.ravel()
x_test = x_test.values.reshape(-1, 1)
y_test = y_test.values.ravel()
# train model
reg = LogisticRegression(random_state=0)
reg.fit(x_train, y_train)
# generate predictions
y_hat_train = reg.predict(x_train)
y_hat_test = reg.predict(x_test)
# accuracy on training set
acc_train = np.mean(y_hat_train == y_train)
print(f'Accuracy on training set: {acc_train:.2f}')
# accuracy on test set
acc_test = np.mean(y_hat_test == y_test)
print(f'Accuracy on test set: {acc_test:.2f}')
Accuracy on training set: 0.86
Accuracy on test set: 0.82
Not bad! There was a slight drop in performance on our test set, but that is to be expected.
Validation set
Machine learning is iterative by nature. We want to improve our model, tuning and evaluating as we go. This leads us to a problem. Using our test set to iteratively improve our model would be cheating. It is supposed to be “held out”, not used for training! So what do we do?
The answer is that we typically partition off part of our training set to use for validation. The “validation set” can be used to iteratively improve our model, allowing us to save our test set for the *final* evaluation.

Cross validation
Why stop at one validation set? With sampling, we can create many training sets and many validation sets, each slightly different. We can then average our findings over the partitions to give an estimate of the model’s predictive performance
The family of resampling methods used for this is known as “cross validation”. It turns out that one major benefit to cross validation is that it helps us to build more robust models.
If we train our model on a single set of data, the model may learn rules that are overly specific (e.g. “all patients aged 63 years survive”). These rules will not generalise well to unseen data. When this happens, we say our model is “overfitted”.
If we train on multiple, subtly-different versions of the data, we can identify rules that are likely to generalise better outside out training set, helping to avoid overfitting.
Two popular of the most popular cross-validation methods:
- K-fold cross validation
- Leave-one-out cross validation
K-fold cross validation
In K-fold cross validation, “K” indicates the number of times we split our data into training/validation sets. With 5-fold cross validation, for example, we create 5 separate training/validation sets.
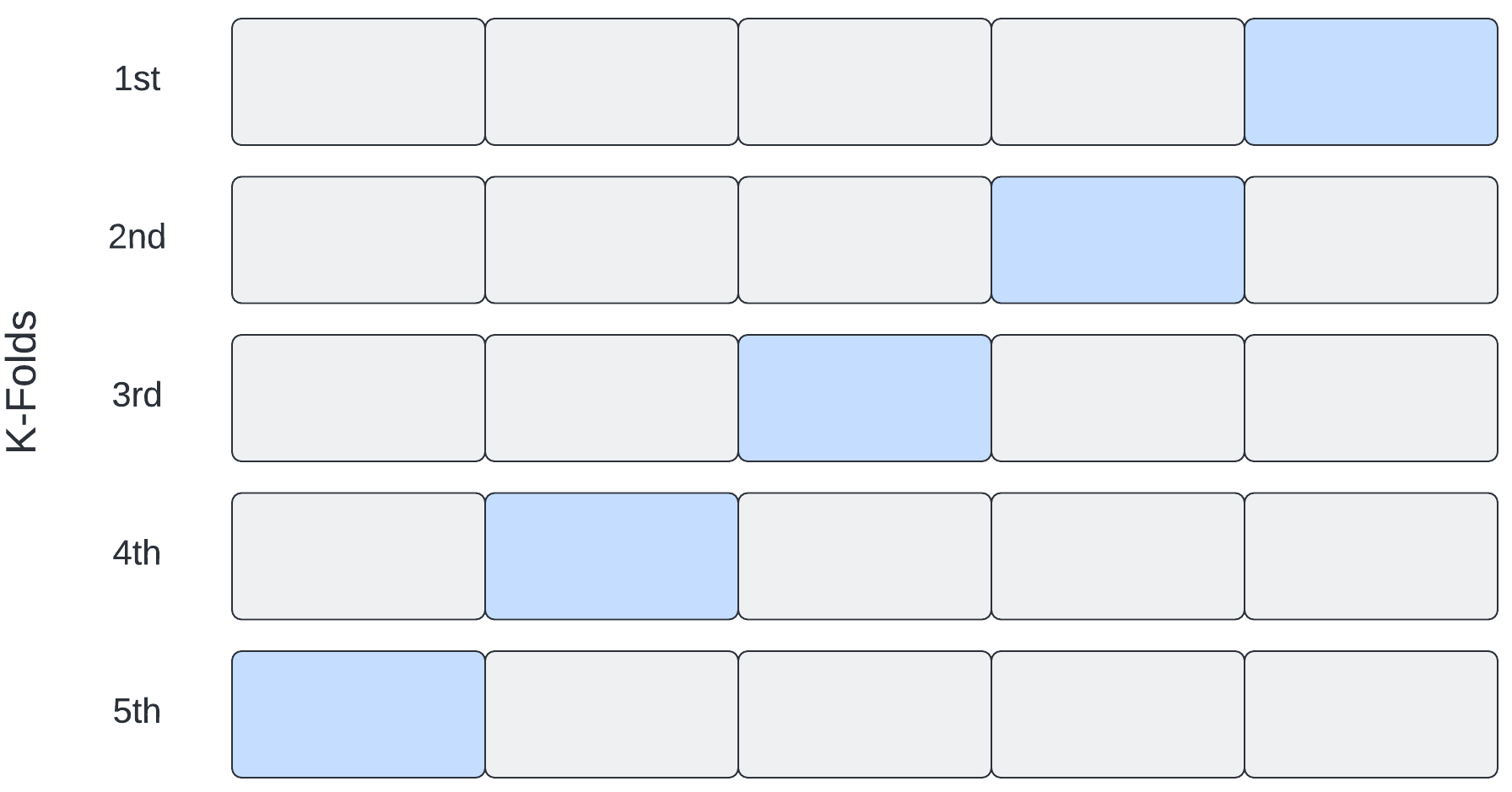
With K-fold cross validation, we select our model to evaluate and then:
- Partition the training data into a training set and a validation set. An 80%, 20% split is common.
- Fit the model to the training set and make a record of the optimal parameters.
- Evaluate performance on the validation set.
- Repeat the process 5 times, then average the parameter and performance values.
When creating our training and test sets, we needed to be careful to avoid data leaks. The same applies when creating training and validation sets. We can use a pipeline object to help manage this issue.
from numpy import mean, std
from sklearn.model_selection import cross_val_score, RepeatedStratifiedKFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
# define dataset
X = x_train
y = y_train
# define the pipeline
steps = list()
steps.append(('scaler', MinMaxScaler()))
steps.append(('model', LogisticRegression()))
pipeline = Pipeline(steps=steps)
# define the evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1)
# evaluate the model using cross-validation
scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Cross-validation accuracy, mean (std): %.2f (%.2f)' % (mean(scores)*100, std(scores)*100))
Cross-validation accuracy, mean (std): 81.53 (3.31)
Leave-one-out cross validation is the same idea, except that we have many more folds. In fact, we have one fold for each data point. Each fold we leave out one data point for validation and use all of the other points for training.
Key Points
Validation sets are used during model development, allowing models to be tested prior to testing on a held-out set.
Cross-validation is a resampling technique that creates multiple validation sets.
Cross-validation can help to avoid overfitting.