This lesson provides an introduction to some of the common methods and terminologies used in machine learning research. We cover areas such as data preparation and resampling, model building, and model evaluation.
It is a prerequisite for the other lessons in the machine learning curriculum. In later lessons we explore tree-based models for prediction, neural networks for image classification, and responsible machine learning.
Predicting the outcome of critical care patients
Critical care units are home to sophisticated monitoring systems, helping carers to support the lives of the sickest patients within a hospital. These monitoring systems produce large volumes of data that could be used to improve patient care.
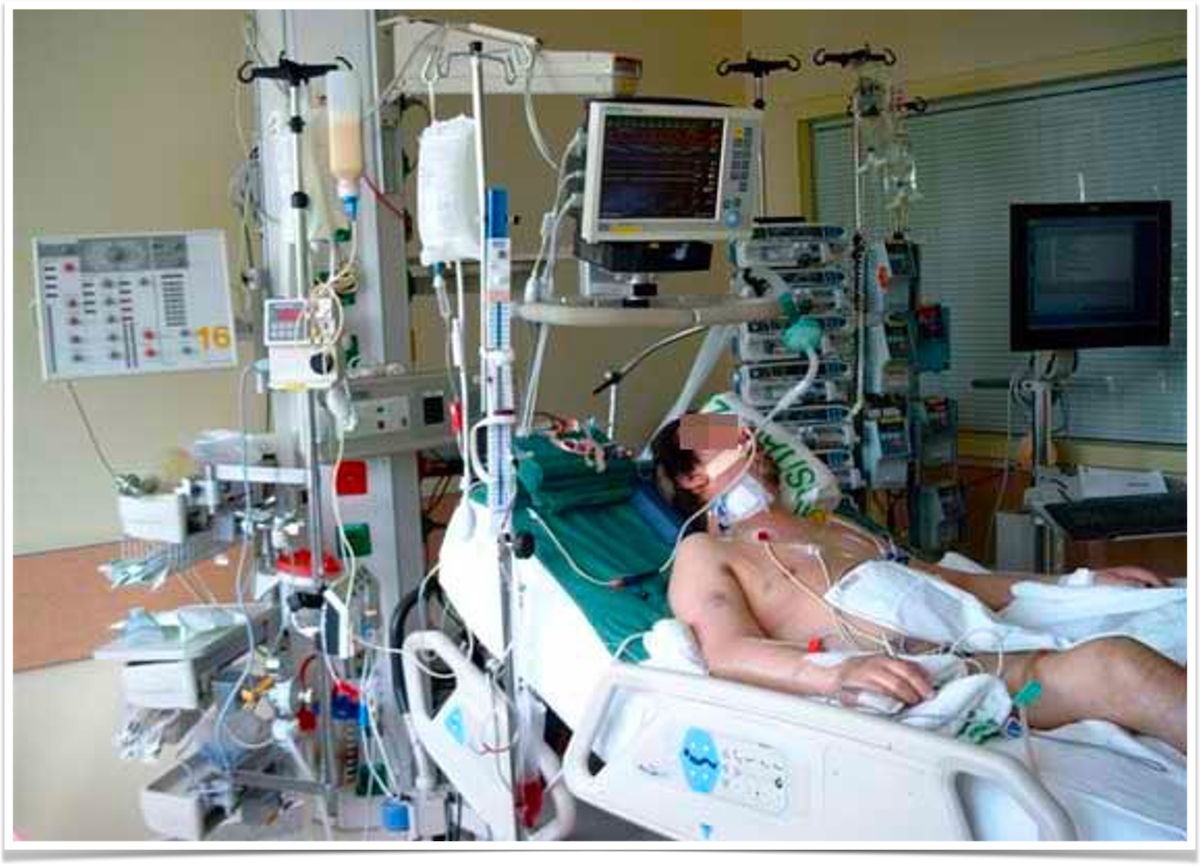
Our goal will be to predict the outcome of critical care patients using physiological data available on the first day of admission to the intensive care unit. These predictions could be used for resource planning or to assist with family discussions.
The dataset used in this lesson was extracted from the eICU Collaborative Research Database, a publicly available dataset comprising deidentified physiological data collected from critically ill patients.
Prerequisites
You need to understand the basics of Python before tackling this lesson. The lesson sometimes references Jupyter Notebook although you can use any Python interpreter mentioned in the Setup.
Getting Started
To get started, follow the directions on the “Setup” page to download data and install a Python interpreter.