Model validity - regression assumptions
Overview
Teaching: 45 min
Exercises: 2 minQuestions
How can we rigorously evaluate the validity and accuracy of a multivariate regression model?
What are the assumptions of linear regression models and why are they important?
How should we preprocess categorical predictors and sparse binary predictors?
Objectives
Understand how to assess the validity of a multivariate regression model.
Understand how to use statistics to evaluate the likelihood of existing relationships recovered by a multivariate model.
Model Validity And Interpretation
While using models strictly for predictive purposes is a completely valid approach for some domains and problems, researchers typically care more about being able to interpret their models such that interesting relationships between predictor(s) and target can be discovered and measured. When interpretting a linear regression model, we can look at the model’s estimated coefficients and p-values associated with each predictor to better understand the model. The coefficient’s magnitude can inform us of the effect size associated with a predictor, and the p-value tells us whether or not a predictor has a consistent (statistically significant) effect on the target.
Before we can blindly accept the model’s estimated coefficients and p-values, we must answer three questions that will help us determine whether or not our model is valid.
Model Validity Assessments
- Accounting for relevant predictors: Have we included as many relevant predictors in the model as possible?
- Bias/variance or under/overfitting: Does the model capture the variability of the target variable well? Does the model generalize well?
- Model assumptions: Does the fitted model follow the 5 assumptions of linear regression?
We will discuss the third assessment — regression assumptions — in detail throughout this episode.
Linear regression assumptions
When discussing machine learning models, it’s important to recognize that each model is built upon certain assumptions that define the relationship between the input data (features, predictors) and the output (target variable). The main goal of linear regression is to model the relationship between the target variable and the predictor variables using a linear equation. The assumptions that are typically discussed in the context of linear regression are related to how well this linear model represents the underlying data-generating process. These assumptions ensure that the linear regression estimates are accurate, interpretable, and can be used for valid statistical inference.
When interpretting multivariate models (coefficient size and p-values), the following assumpitons should be met to assure validty of results.
- Linearity: There is a linear relation between Y and X
- Normality: The error terms (residuals) are normally distributed
- Homoscedasticity: The variance of the error terms is constant over all X values (homoscedasticity)
- Independence: The error terms are independent
- Limited multicollinearity among predictors: This assumption applies to multivariate regression models but is not relevant in univariate regression since there is only one predictor variable. Multicollinearity refers to the presence of high correlation or linear dependence among the predictor variables in a regression model. It indicates that there is a strong linear relationship between two or more predictor variables. Multicollinearity can make it challenging to isolate the individual effects of predictors and can lead to unstable and unreliable coefficient estimates. It primarily focuses on the relationships among the predictors themselves.
We will explore assess all five assumptions using a multivariate model built from the Ames housing data.
0. Load and prep data
from sklearn.datasets import fetch_openml
housing = fetch_openml(name="house_prices", as_frame=True, parser='auto') #
y=housing['target']
# Log scale sale prices: In our previous univariate models, we observed that several predictors tend to linearly relate more with the log version of SalePrices. Target variables that exhibit an exponential trend, as we observe with house prices, typically need to be log scaled in order to observe a linear relationship with predictors that scale linearly. For this reason, we'll log scale our target variable here as well.
import numpy as np
y_log = y.apply(np.log)
Set predictors
Let’s assume we have two predictors recorded in this dataset — sale condition and OverallQual (don’t worry, we’ll use more predictors soon!). What values can the sale condition variable take?
cat_predictor = 'SaleCondition'
predictors = ['OverallQual', cat_predictor]
X=housing['data'][predictors]
print(X.head())
print(X[cat_predictor].unique())
OverallQual SaleCondition
0 7 Normal
1 6 Normal
2 7 Normal
3 7 Abnorml
4 8 Normal
['Normal' 'Abnorml' 'Partial' 'AdjLand' 'Alloca' 'Family']
SaleCondition: Condition of sale
Normal Normal Sale
Abnorml Abnormal Sale - trade, foreclosure, short sale
AdjLand Adjoining Land Purchase
Alloca Allocation - two linked properties with separate deeds, typically condo with a garage unit
Family Sale between family members
Partial Home was not completed when last assessed (associated with New Homes)
Encode categorical data as multiple binary predictors
import pandas as pd
nominal_fields =['SaleCondition']
X_enc = X.copy()
X_enc[nominal_fields]=X[nominal_fields].astype("category")
one_hot = pd.get_dummies(X_enc[nominal_fields])
one_hot.head()
| SaleCondition_Abnorml | SaleCondition_AdjLand | SaleCondition_Alloca | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 | 0 |
# Join the encoded df
X_enc = X.join(one_hot)
# Drop column SaleCondition as it is now encoded
X_enc = X_enc.drop(cat_predictor,axis = 1)
X_enc.head()
| OverallQual | SaleCondition_Abnorml | SaleCondition_AdjLand | SaleCondition_Alloca | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|---|---|
| 0 | 7 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 6 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 7 | 0 | 0 | 0 | 0 | 1 | 0 |
| 3 | 7 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 8 | 0 | 0 | 0 | 0 | 1 | 0 |
Alternatively, we could use one of the preprocessing helpers here.
from preprocessing import encode_predictors_housing_data
X_enc = encode_predictors_housing_data(X)
X_enc.head()
| OverallQual | SaleCondition_Abnorml | SaleCondition_AdjLand | SaleCondition_Alloca | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|---|---|
| 0 | 7 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 6 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 7 | 0 | 0 | 0 | 0 | 1 | 0 |
| 3 | 7 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 8 | 0 | 0 | 0 | 0 | 1 | 0 |
Handling sparse or near-constant predictors
After we’ve split our category variable into 6 binary predictors, it is important to assess the quantity of information present in each predictor. If a predictor shows very little variability (e.g., nearly all 0’s or 1’s in a binary variable), then it will be challenging to detect a meaningful relationship between that predictor and the target. The model needs to observe examples from both classes of a binary variable in order to reveal a measurable effect between a binary variable and the target.
To assess not only sparsity (presence of nearly all 0’s) but for the presence of any one constant value in a predictor, we will use the following procedure:
import pandas as pd
# Calculate value counts
value_counts_df = X_enc['OverallQual'].value_counts().reset_index()
value_counts_df.columns = ['Value', 'Count']
# Calculate percentages separately
value_counts_df['Percentage'] = value_counts_df['Count']/len(X_enc) * 100
# Sort the DataFrame
value_counts_df = value_counts_df.sort_values(by='Count', ascending=False)
# Display the DataFrame
value_counts_df.head()
| Value | Count | Percentage | |
|---|---|---|---|
| 0 | 5 | 397 | 27.191781 |
| 1 | 6 | 374 | 25.616438 |
| 2 | 7 | 319 | 21.849315 |
| 3 | 8 | 168 | 11.506849 |
| 4 | 4 | 116 | 7.945205 |
A few of the predictors (AdjLand, Alloca, Family) contain very little information since they are filled almost entirely with 0’s. With few observations to rely on, this makes it difficult to assess how house price changes when these predictors become active (1 instead of 0). If you encounter extremely sparse predictors, it’s best to remove them from the start to avoid wasting computational resources. While it’s important to pick a threshold that encourages different values of each predictor to land in both the training and test sets, the exact threshold chosen is somewhat arbitrary. It’s more important that you follow-up this choice with a thorough investigation of the resulting model and adjust the model downstream, if necessary.
Preprocessing helper function does the above calcuation at looks at the top percentage
We have a pre-made helper function that will run the above code for all predictors and remove any that contain that are nearly constant. Here, we’ll remove predictors that don’t have at are 99% constant.
from preprocessing import remove_bad_cols
X_good = remove_bad_cols(X_enc, 99)
X_good.head()
2 columns removed, 5 remaining.
Columns removed: ['SaleCondition_AdjLand', 'SaleCondition_Alloca']
| OverallQual | SaleCondition_Abnorml | SaleCondition_Family | SaleCondition_Normal | SaleCondition_Partial | |
|---|---|---|---|---|---|
| 0 | 7 | 0 | 0 | 1 | 0 |
| 1 | 6 | 0 | 0 | 1 | 0 |
| 2 | 7 | 0 | 0 | 1 | 0 |
| 3 | 7 | 1 | 0 | 0 | 0 |
| 4 | 8 | 0 | 0 | 1 | 0 |
Why not just use variance instead of counts? Variance = (Sum of the squared differences between each value and the mean) / (Number of values)
Using the variance measure to detect extremely sparse or near-constant features might not be the most suitable approach. Variance can be influenced by outliers and can be misleading results.
import numpy as np
# Array of continuous values (1 to 100)
continuous_data = np.arange(1, 101)
print(continuous_data)
# Array with mostly zeros and an outlier
sparse_data_with_outlier = np.array([0] * 100 + [1000])
print(sparse_data_with_outlier)
# Calculate variances
variance_continuous = np.var(continuous_data)
variance_sparse = np.var(sparse_data_with_outlier)
print("Continuous Data Variance:", variance_continuous)
print("Sparse Data Variance:", variance_sparse)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
91 92 93 94 95 96 97 98 99 100]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 1000]
Continuous Data Variance: 833.25
Sparse Data Variance: 9802.96049406921
2. Check for multicollinearity
Multicollinearity: In statistics, multicollinearity is a phenomenon in which one or more predictors in a multivariate regression model can be linearly predicted from the others with a substantial degree of accuracy. In other words, it means that one or more predictors are highly correlated with one another.
Multicollinearity presents a problem in multivariate regression because, without having independent/uncorrelated predictors, it is difficult to know how much each predictor truly contributes to predicting the target variable. In other words, when two or more predictors are closely related or measure almost the same thing, then the underlying impact on the target varible is being accounted for twice (or more) across the predictors.
While multicollinearity does not reduce a model’s overall predictive power, it can produce estimates of the regression coefficients that are not statistically valid.
Variance Inflation Factor (VIF)
The VIF (Variance Inflation Factor) is a statistical measure used to detect multicollinearity in regression analysis. VIF helps to quantify the extent to which multicollinearity is present in the model.
The intuition behind the VIF score is based on the idea that if two or more predictor variables are highly related, it becomes difficult for the model to distinguish the individual effects of these variables on the dependent variable. Consequently, the coefficient estimates for these variables become unstable, and their standard errors become inflated, making the results less reliable.
The VIF is calculated for each independent variable in the regression model. Specifically, to calculate the VIF for predictor i, the following steps are taken:
-
Fit a regression model with predictor variable i as the target/dependent variable and all other independent variables (excluding i) as predictors.
-
Calculate the R-squared value (R²) for this regression model. R² represents the proportion of variance in variable i that can be explained by the other independent variables.
-
Calculate the VIF for variable i using the formula: VIF(i) = 1 / (1 - R²)
-
The interpretation of the VIF score is as follows:
-
A VIF of 1 indicates that there is no multicollinearity for the variable, meaning it is not correlated with any other independent variable in the model.
-
VIF values between 1 and 5 (or an R² between 0 and .80) generally indicate low to moderate multicollinearity, which is typically considered acceptable in most cases.
-
VIF values greater than 5 (some sources use a threshold of 10) suggest high multicollinearity, indicating that the variable is highly correlated with other independent variables, and its coefficient estimates may be unreliable.
-
We can calculate VIF for all predictors quickly using the variance_inflation_factor function from the statsmodels package.
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calc_print_VIF(X):
# Calculate VIF for each predictor in X
vif = pd.DataFrame()
vif["Variable"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# Display the VIF values
print(vif)
The variance_inflation_factor() function expects a constant column to code for each model’s y-intercept. We will add this constant before calculating VIF scores.
# Add constant to the dataframe for VIF calculation
X_with_const = add_constant(X_good)
# Calc VIF scores
calc_print_VIF(X_with_const)
Variable VIF
0 OverallQual 19.518808
1 SaleCondition_Abnorml 2.072691
2 SaleCondition_Family 1.229967
3 SaleCondition_Normal 15.774223
4 SaleCondition_Partial 3.441928
It looks like two of the predictors, “Normal” and “OverallQual”, have high VIF scores. We can further investigate this score by creating a plot of the correlation matrix of all predictors.
from check_assumptions import plot_corr_matrix
# Calculate correlation matrix
fig = plot_corr_matrix(X_good.corr())
# import matplotlib.pyplot as plt
# plt.savefig('..//fig//regression//assumptions//corrMat_multicollinearity.png', bbox_inches='tight', dpi=300, facecolor='white');
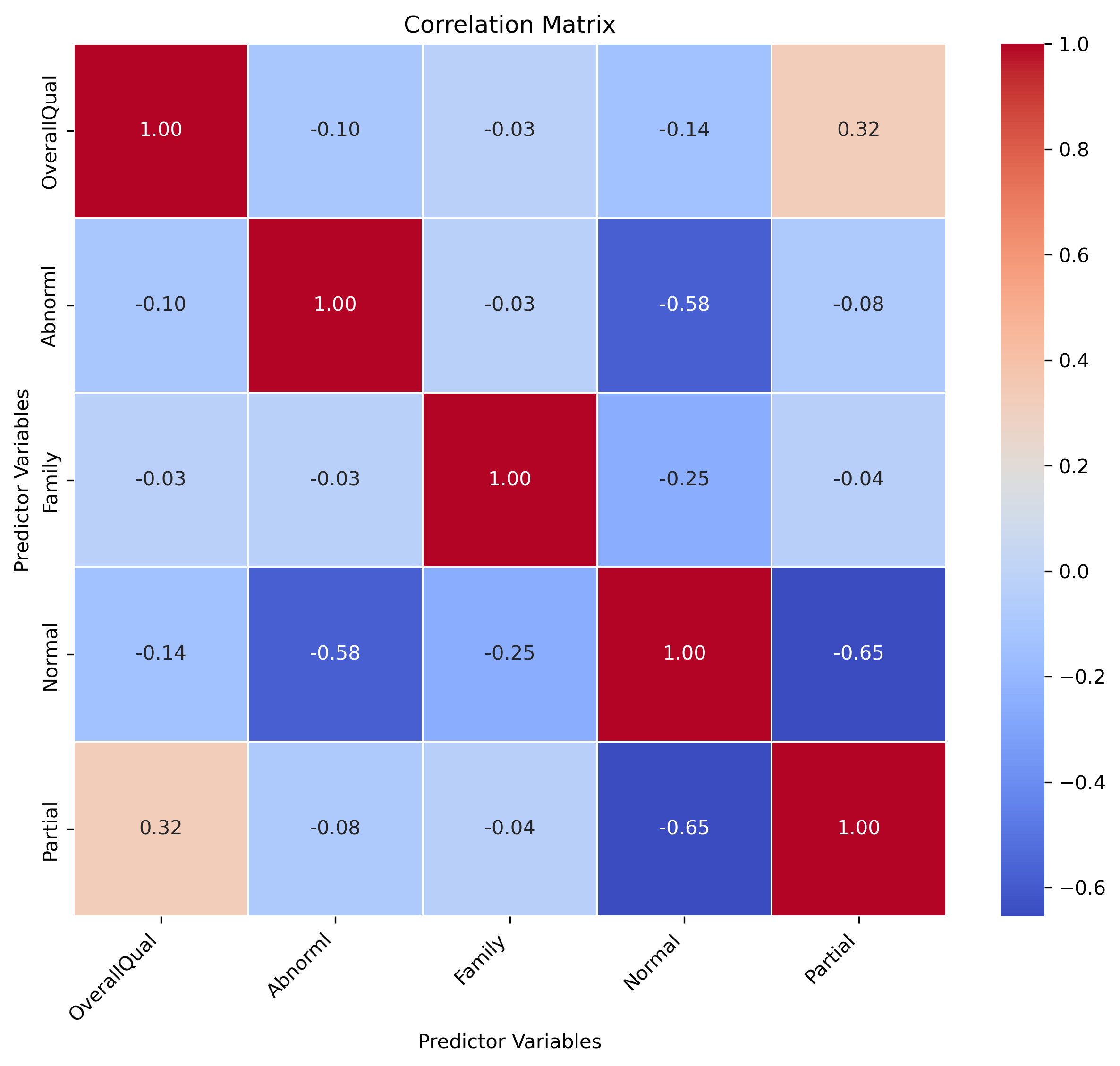
The Normal variable appears to be highly negatively correlated with both Partial and Abnormal. In fact, Normal has a considerable amount of negative corrleation with all predictors. If we think about our predictors holistically, it appears we have several categories describing somewhat rarer sale conditions, and then a more common/default “normal” condition. Regardless of the value of “Normal”, if all other predictors are set to 0, that is a very good indication that it was a “Normal” sale. Since “Normal” tends to negate the remaining predictors presense and is redundant, it makes sense to remove it form the list of predictors and only consider the manner in which the sale was unusal.
Correlation matrix vs VIF
You might wonder why we even bother calculating the VIF score given that we could easily inspect the correlation matrices instead. VIF scores give a more reliable estimate of multicollinearity mainly due to their ability to assess multivariate interactions. That is, the correlation matrix only shows pairwise relationships between variables, but it does not reveal the impact of all independent variables simultaneously on each other. The VIF, on the other hand, takes into account all other independent variables when assessing multicollinearity for a specific variable. This individual assessment allows you to pinpoint which variables are causing multicollinearity issues. In addition, the VIF helps identify which variables are causing the problem, enabling you to take appropriate actions to address the issue.
In summary, while the correlation matrix can give you a general idea of potential multicollinearity, the VIF score provides a more comprehensive and quantitative assessment, helping you identify, measure, and address multicollinearity issues in a regression model effectively.
X_better = X_good.drop('SaleCondition_Normal',axis = 1)
X_better.columns
Index(['OverallQual', 'SaleCondition_Abnorml', 'SaleCondition_Family',
'SaleCondition_Partial'],
dtype='object')
After dropping the problematic variable with multicollinearity, we can recalculate VIF for each predictor in X. This time we’ll call a helper function to save a little time.
from check_assumptions import multicollinearity_test
multicollinearity_test(X_better);
==========================
VERIFYING MULTICOLLINEARITY...
Variable VIF
0 OverallQual 1.237386
1 SaleCondition_Abnorml 1.068003
2 SaleCondition_Family 1.014579
3 SaleCondition_Partial 1.154805
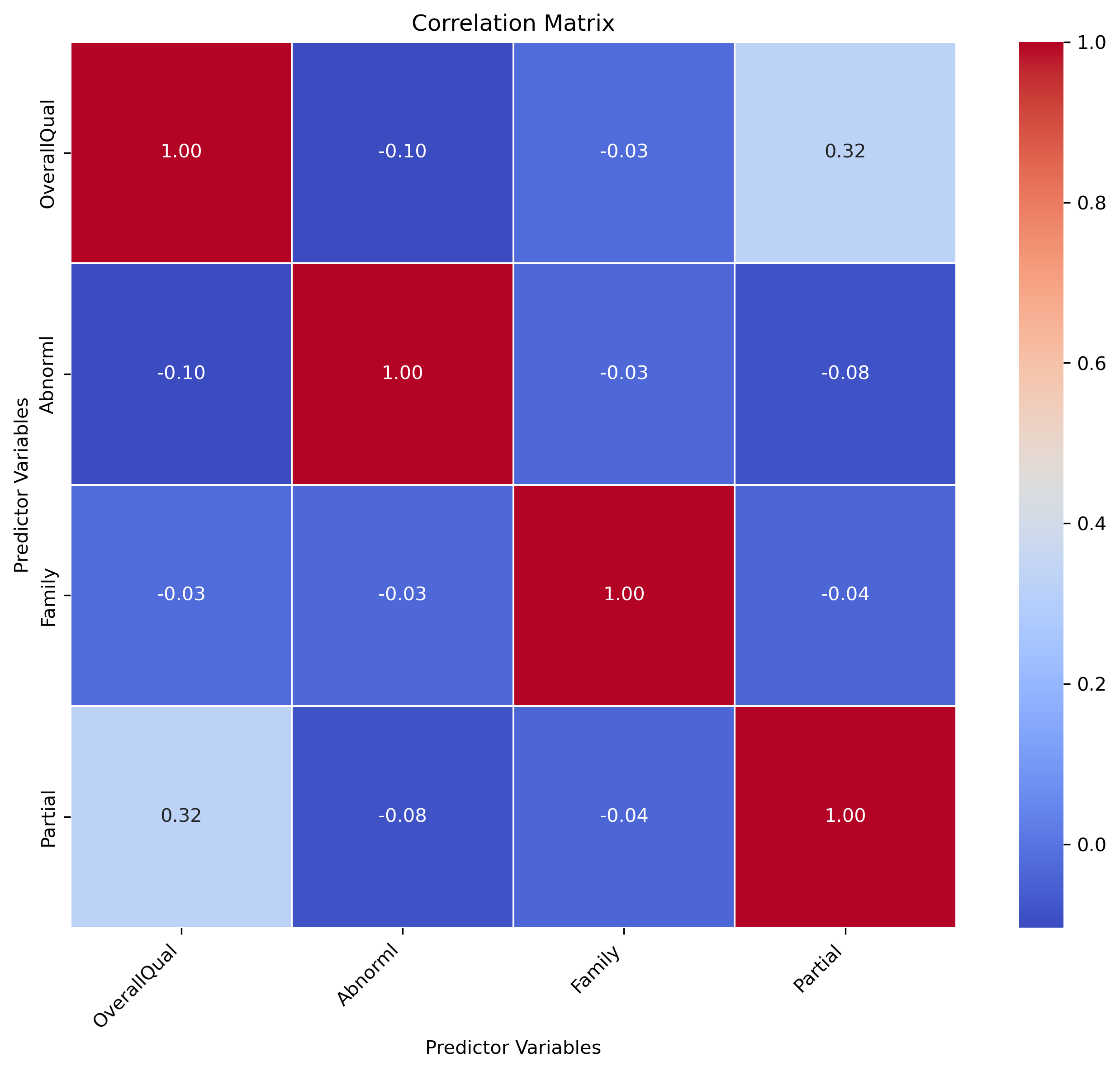
Note that we still see some correlation between OverallQual and Partial. However, the correlation is not so strong that those predictors can be reasonably well predicted from one another (low VIF score).
3. Fit the model
Before we can assess the remaining assumptions of the model (linearity, normality, homoscedasticiy, and independence), we first must fit the model.
Train/test split
Since we’re working with multiple predictors, we must take care evaluate evidence of overfitting in this model. The test set will be left out during model fitting/training so that we can measure the model’s ability to generalize to new data.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_better, y_log,
test_size=0.33,
random_state=4)
print(X_train.shape)
print(X_test.shape)
(978, 4)
(482, 4)
Zscore the data
As in the previous episode, we will zscore this data so that all predictors are on the same scale. This will allow us to compare coefficient sizes later.
from preprocessing import zscore
X_train_z = zscore(df=X_train, train_means=X_train.mean(), train_stds=X_train.std())
X_test_z = zscore(df=X_test, train_means=X_train.mean(), train_stds=X_train.std())
X_train_z.head()
| OverallQual | SaleCondition_Abnorml | SaleCondition_Family | SaleCondition_Partial | |
|---|---|---|---|---|
| 368 | -0.819197 | -0.262263 | -0.124741 | -0.300348 |
| 315 | 0.630893 | -0.262263 | -0.124741 | -0.300348 |
| 135 | 0.630893 | -0.262263 | -0.124741 | -0.300348 |
| 473 | 1.355938 | -0.262263 | -0.124741 | 3.326071 |
| 1041 | -0.094152 | -0.262263 | -0.124741 | -0.300348 |
import statsmodels.api as sm
# Add a constant column to the predictor variables dataframe - this acts as the y-intercept in the model
X_train_z = sm.add_constant(X_train_z)
# Add the constant to the test set as well so we can use the model to form predictions on the test set later
X_test_z = sm.add_constant(X_test_z)
X_test_z.head()
| const | OverallQual | SaleCondition_Abnorml | SaleCondition_Family | SaleCondition_Partial | |
|---|---|---|---|---|---|
| 280 | 1.0 | 0.630893 | -0.262263 | -0.124741 | -0.300348 |
| 1365 | 1.0 | 0.630893 | -0.262263 | -0.124741 | -0.300348 |
| 132 | 1.0 | -0.819197 | -0.262263 | -0.124741 | -0.300348 |
| 357 | 1.0 | -0.819197 | -0.262263 | -0.124741 | -0.300348 |
| 438 | 1.0 | -0.819197 | -0.262263 | -0.124741 | -0.300348 |
# Fit the multivariate regression model
model = sm.OLS(y_train, X_train_z)
trained_model = model.fit()
4. Evaluate evidence of overfitting or severe underfitting
Before we go any further in assessing the model’s assumptions and ultimately running hypothesis tests, we should first check to see if there is evidence of overfitting or severe underfitting.
- Overfitting: If error is notably higher (accounting for sample size) in the test set than the train set, this indicates overfitting. Recall that overfitting means that the model will poorly generalize. When running hypothesis tests, the goal is typically to reveal general relationships that hold true across datasets. Therefore, overfitting must first be ruled out before we bother with hypothesis testing.
- Severe underfitting: If the error is extremely high in the train set, this indicates the model describes the data poorly and is underfitting. In the context of hypothesis testing, it is okay for predictors to have small but consistent effects (low R-squared, high error). However, depending on the field and line of inquiry, a small effect may or may not be interesting. Some researchers might consider R-squared values above 0.50 or 0.60 to be satisfactory in certain contexts. Others might find R-squared values as low as 0.20 or 0.30 to be meaningful, depending on many factors (dataset size, model relevance in ongoing studies, common benchmarks, etc.)
from regression_predict_sklearn import measure_model_err
# to calculate residuals and R-squared for the test set, we'll need to get the model predictions first
y_pred_train = trained_model.predict(X_train_z)
y_pred_test = trained_model.predict(X_test_z)
errors_df = measure_model_err(y, np.mean(y),
y_train, y_pred_train,
y_test, y_pred_test,
'R-squared', y_log_scaled=True)
errors_df
| Baseline Error | Train Error | Test Error | |
|---|---|---|---|
| 0 | 0.0 | 0.662168 | 0.723296 |
You can also extract rsquared for the training data directly from the trained statsmodels object.
# R-squared for train set
R2_train = trained_model.rsquared
print(R2_train)
0.6656610907646399
No evidence of overfitting (test and train errors are comparable) or severe underfitting (R-squared is not astonishingly low). You may notice that the test set R-squared is actually slightly higher than the train set R-squared. This may come as a surprise given that the test set was left out during model training. However, test set performance often can appear to be slightly better than train set simply given the limited number of samples often available in the test set.
5a) Check linearity assumption
The linearity assumption of multivariate regression states that the overall relationship between the predictors and the target variable should be approximately linear. This doesn’t necessarily imply that each predictor must have a perfectly linear relationship. So long as the sum of combined effects is linear, then the linearity assumption has been met. That said, if you observe a strong nonlinear pattern between one or more predictors, this often does cascade into an overall nonlinear effect in the model. We will review one method to investigate each individual predictor’s relationship with the target as well
Why do we care?
As discussed in the previous episode, the predictions will be inaccurate because our model is underfitting (i.e., not adquately capturing the variance of the data since you can’t effectively draw a line through nonlinear data). In addition to having a fatal impact on predictive power, violations of linearity can affect the validity of hypothesis tests on the regression coefficients. The p-values associated with the coefficients may not accurately reflect the statistical significance, potentially leading to erroneous conclusions.
Visualizing linearity in multivariate models
When working with univariate models, we are able to assess the linearity assumption PRIOR to model fitting simply by creating a scatterplot between the predictor and target. With multivariate models, however, we need a different approach in order to isolate the relationship between individual predictors and the target. That is, we need to account for effects of the remaining predictors.
Partial regression plots
Partial regression plots, otherwise known as added variable plots, help visualize the relationship between a single predictor and the target variable while taking into account the effects of other predictor variables. By plotting the partial regressions against the target variable of interest, we can assess whether the relationship is approximately linear for each predictor.
Partial regression plots are formed by:
- Computing the residuals of regressing the target variable against the predictor variables but omitting Xi (predictor of interest)
- Computing the residuals from regressing Xi against the remaining independent variables.
- Plot the residuals from (1) against the residuals from (2).
By looking at the visualization, we can assess the impact of adding individual predictors to a model that has all remaining predictors. If we see a non-zero slope, this indicates a predictor has a meaningful relationship with the target after accounting for effects from other predictors.
# Create the partial regression plots using statsmodels
import matplotlib.pyplot as plt
from statsmodels.graphics.regressionplots import plot_partregress_grid;
fig = plt.figure(figsize=(12, 8));
plot_partregress_grid(trained_model, fig=fig, exog_idx=list(range(1,X_train_z.shape[1])))
# fig.savefig('..//fig//regression//assumptions//partialRegression.png', bbox_inches='tight', dpi=300, facecolor='white');
eval_env: 1
eval_env: 1
eval_env: 1
eval_env: 1
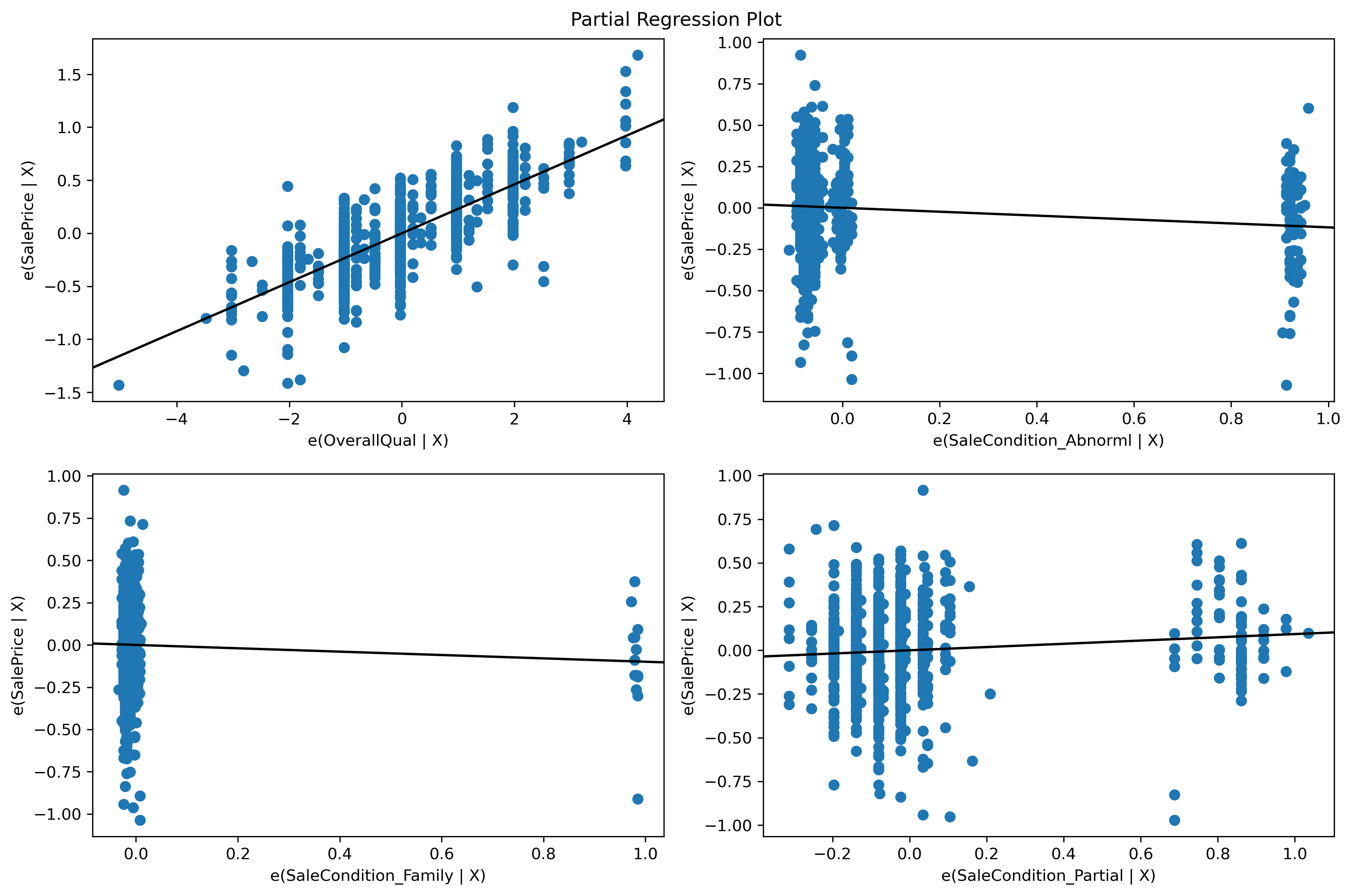
Inspect the plots
- You may notice how Partial and Abnormal now appear to be continuous predictors rather than binary predictors. This effect is commonly observed when you plot partial regressions of correlated or interacting predictors. In both cases, it is difficult to fully isolate the effect of just one predictor. However, the correlation is not so bad that we need to be concerned about the validity of our hypothesis tests later (based on the VIF scores we observed)
- The plots show the impact of adding each individual predictor while accounting for the remaining predictor effects
- The plot can be used to investigate whether or not each predictor has a linear relationship with the target
- Binary predictors will, by definition, always show a linear relationship since they will always have two means
- Some predictors, like Family, may show a non-zero slope, which indicates that this predictor is not really very useful in our model. We can wait until we run our hypothesis tests before fully excluding this predictor from the model
In conclusion, our model appears to be satisfying the linearity assumption based on these plots.
5b) A more wholesome view of linearity (and homoscedasticity)
What if instead of 4 predictors, we have 100 predictors in our model? Partial regression plots can become burdensome to look through when working with many predictors. Furthermore, we still need to assess whether or not the overall relationship revealed by the model is linear or not. For this analysis, we can create two plots that both help evaluate both homoscedasticity and linearity.
Homoscedasticity refers to when the variance of the model residuals is constant over all X values. Homoscedasticity is desirable because we want the residuals to be the same across all values of the independent variables / predictors. For hypothesis testing, confidence intervals, and p-values to be valid and meaningful, it is crucial that the underlying assumptions, including homoscedasticity, are met. If the assumption is violated, the inference drawn from the hypothesis tests may not be accurate.
We will call a pre-baked helper function to generate the plots and calculate a test statistic that assesses homoscedasticity (Goldfeld-Quandt test).
Fig1. Predictions vs actual values
- Linearity: We want to observe the data scattered about the diagonal to ensure the linearity assumption is met
- Homoscedasticity (Constant Variance): If the variance of the data changes as you move along the X-axis, this indicates heterscedasticity
Fig2. Residuals vs predicted values
- Linearity: In the predicted vs residuals scatterplot, if we observe a random scattering of points around the red dashed line (y=0), it suggests that the linearity assumption is met. However, if we notice any patterns, such as a curved shape or a funnel-like structure, it might indicate a nonlinear relationship, and we may need to consider transformations or alternative modeling approaches to address the nonlinearity.
- Homoscedasticity (Constant Variance): In the same plot, you examine whether the spread of the residuals remains consistent along the range of predicted values. If the spread of points around y = 0 does not change noticeably as you move along the x-axis (the predicted values), it suggests homoscedasticity.
Goldfeld-Quandt test
The Goldfeld-Quandt test is a statistical test used to check for heteroscedasticity (unequal variances) in a regression model. It splits the data into two groups based on a specified split point (default is the median) and then estimates separate variances for each group. The test statistic is calculated based on the F-distribution, and the p-value is obtained by comparing the test statistic to the critical value from the F-distribution.
If the p-value is greater than your chosen significance level (e.g., 0.05), you fail to reject the null hypothesis, indicating no evidence of heteroscedasticity. In this case, the variance of residuals is assumed to be equal for both groups. If the p-value is less than your significance level, you can reject the null hypothesis, suggesting the presence of heteroscedasticity. This means that the variance of residuals is different for different groups, indicating potential issues with the regression model’s assumptions.
from check_assumptions import homoscedasticity_linearity_test
fig = homoscedasticity_linearity_test(trained_model=trained_model,
y=y_train, y_pred=y_pred_train,
y_log_scaled=True, plot_raw=False)
# fig.savefig('..//fig//regression//assumptions//linearity-homoscedasticity_pred_v_residuals.png',bbox_inches='tight', dpi=300)
=======================================
VERIFYING LINEARITY & HOMOSCEDASTICITY...
Goldfeld-Quandt test (homoscedasticity) ----
value
F statistic 0.920670
p-value 0.818216
Homoscedasticity test: Passes (homoscedasticity is assumed)
Residuals plots ----
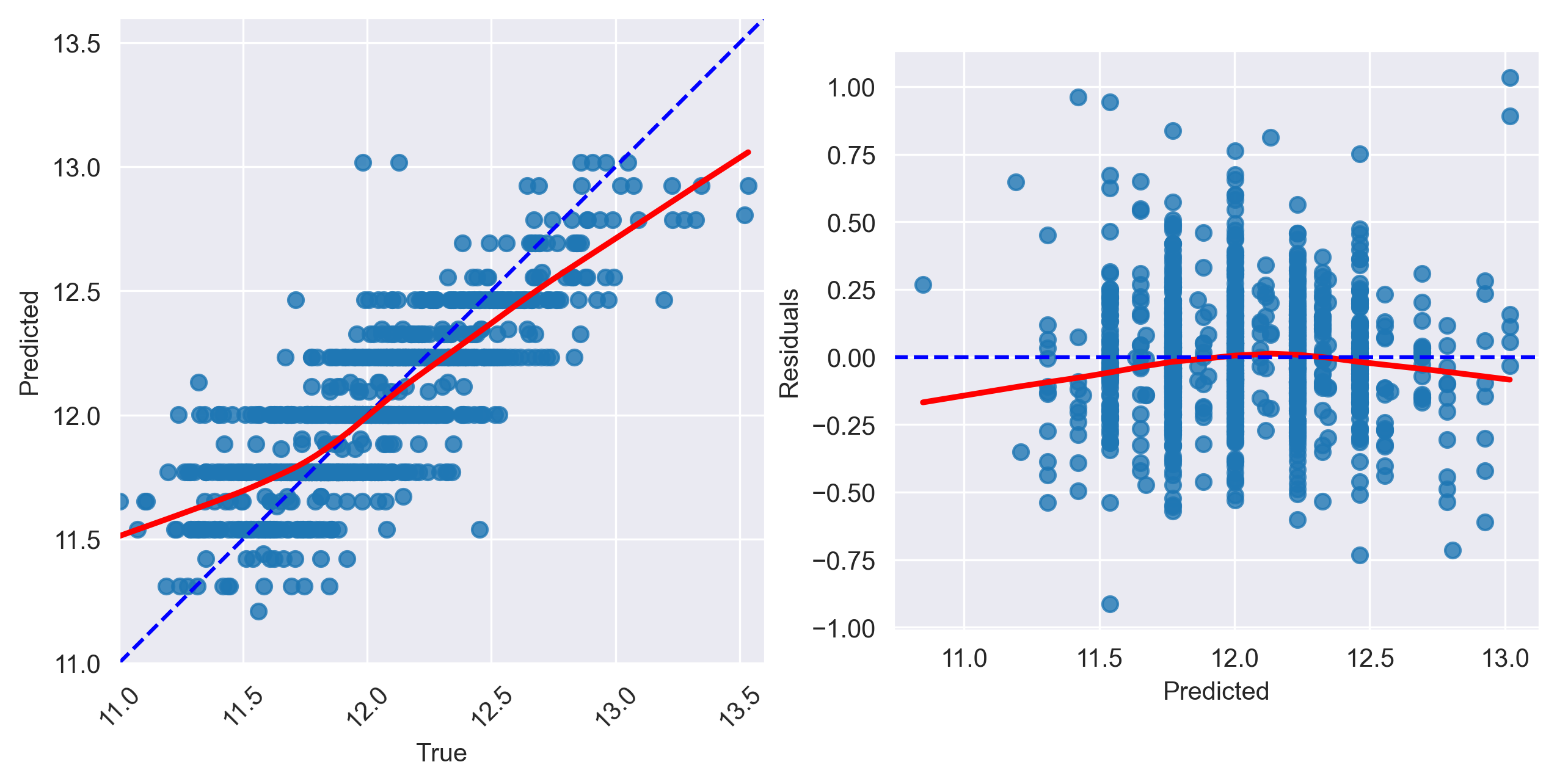
Inspect the plot and Goldfeld-Quandt test
Fig1. Predictions vs actual values
- Linearity: While the model is somewhat linear, it appears to be overestimating the value of low-cost homes while underestimating the most expensive homes.
- Homoscedasticity (Constant Variance): The variance of the data appears to be mostly consistent across the diagonal.
Fig2. Residuals vs predicted values
- Linearity: The errors have some curvature across predicted values indicating that the linearity assumption is again questionable with this data.
- Homoscedasticity: The errors here are fairly consistently distributed across the x-axis
How to remedy issues with linearity
If you encounter issues with the linearity assumption, you can try the following solutions:
- Transformations: Apply nonlinear transformations to X and/or Y. Common transformations are the natural logarithm, square root, and inverse. A Box-Cox transformation of the outcome may help, as well. Partial regression plots can help identify predictors that have a nonlinear relationship with Y.
- Remove nonlinear predictors: Remove predictors that exhibit a nonlinear trend with the target (e.g., via inspecting partial regression plots)
- Limit range of training data: With data like ours, you could try to limit the training data to sale prices in the 25-75th percentile range. This would yield an accurate (linear) description of the data, but the model would not generalize well to sale prices outside this range. If your goal is only to describe data and not extrapolate to unseen datasets, this approach may be sufficient.
- Adding additional predictors: Add predictors to help capture the relationship between the predictors and the label. Remember, we really just need the overall relationship between target and predictors to be linear. Sometimes, adding additional predictors that relate to the target can help produce an overall linear model. With our housing data, there may be
- Try spline or polynomial regression: In polynomial regression, you add polynomial terms to some of the predictors (i.e., polynomial regression). In a similar vein to solution 1, polynomial regression will allow you to include transformed predictors which may linearly relate to the target. Spline regression is similar, however, it allows you to fit separate polynomials to different segments of the data
If none of those approaches work, you can also consider nonlinear models if you have a sufficiently large dataset (learning nonlinear relationships requires lots of data).
5. Evaluate normality of residuals & constant variance (homoscedasticity) of residuals
Given that the linearity assumption is in question with this model, we would typically begin exploring alternative models/predictors/transformations for our analysis. However, we will check the remaining assumptions here as practice for future work.
Normal residuals: In a linear regression model, it is assumed that the model residuals/errors are normally distributed. If the residuals are not normally distributed, their randomness is lost, which implies that the model is not able to explain the relation in the data.
Many statistical tests and estimators used in multivariate regression, such as t-tests and confidence intervals, also rely on the assumption of normality. If the residuals are not approximately normally distributed, the results of these tests and estimators may be invalid or biased.
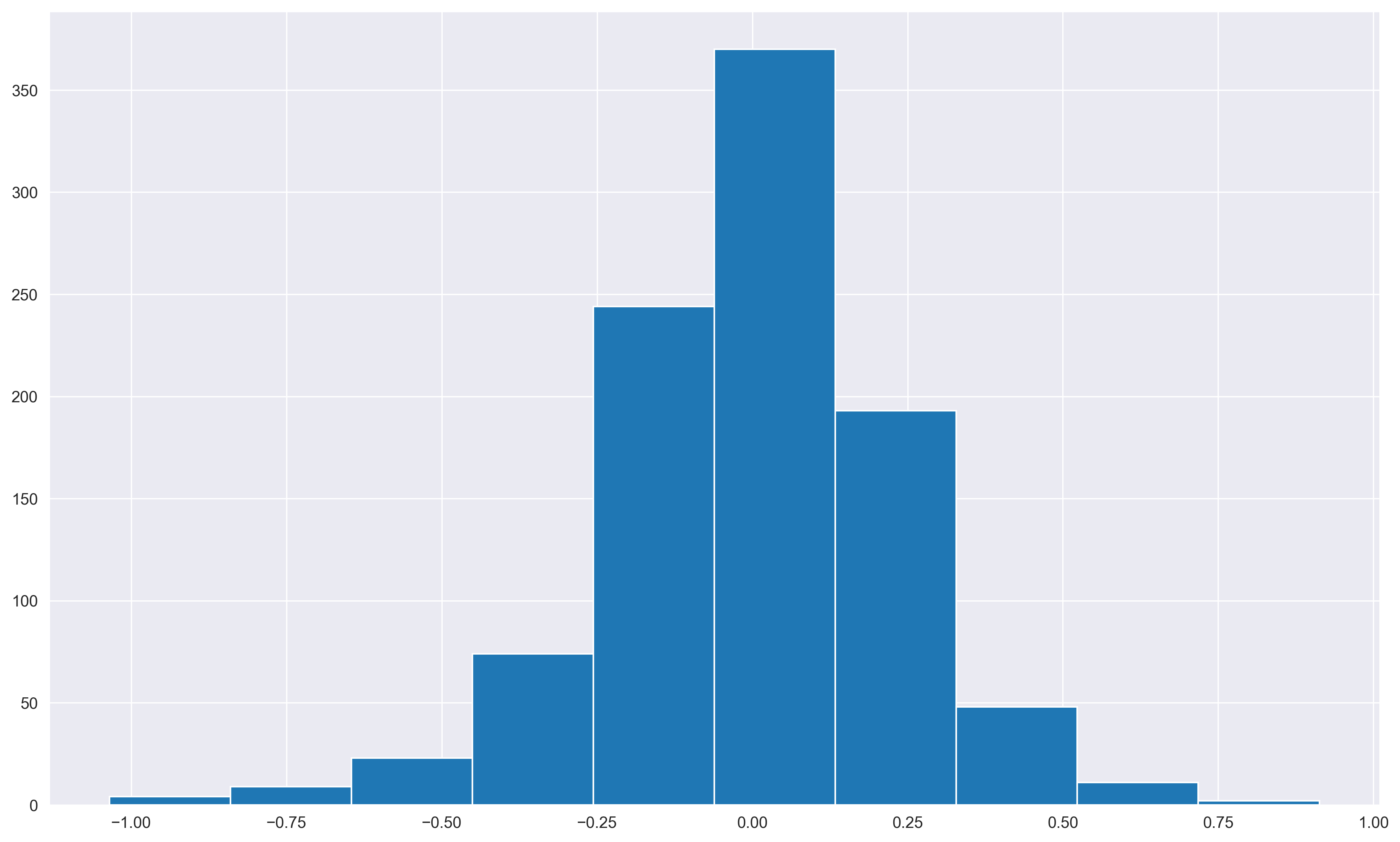
Histograms
Histograms can help give a preliminary sense of the overall distribution of the data. We can also quickly calculate the “skew” of a distribution using numpy’s skew() function.
# Extract the residuals and calculate median — should lie close to 0 if it is a normal distribution
resids = y_train - y_pred_train
print('Median of residuals:', np.median(resids))
plt.hist(resids);
resids.skew()
# plt.savefig('..//fig//regression//assumptions//normal_resids_histogram.png',bbox_inches='tight', dpi=300)
Median of residuals: 0.0047744607860336075
-0.3768190722299776
Quantile-quantile (QQ) plots
While histograms are helpful as a preliminary glance at the data, it can be difficult to tell by eye just how different the distribution is from a normal distribtion. Instead, we can use a popular type of plot known as a quantile-quantile plot (QQ-plot) of the model residuals. Quantiles — often referred to as percentiles — indicate values in your data below which a certain proportion of the data falls. For instance, if data comes from a classical bell-curve Normal distrubtion with a mean of 0 and a standard deviation of 1, the 0.5 quantile, or 50th percentile, is 0 (half the data falls above 0, half below zero).
import statsmodels.graphics.gofplots as smg
# Plot the QQ-plot of residuals
smg.qqplot(resids, line='s')
# Add labels and title
plt.xlabel('Theoretical Quantiles')
plt.ylabel('Sample Quantiles')
plt.title('QQ-Plot of Residuals')
# plt.savefig('..//fig//regression//assumptions//normal_resids_QQplot.png',bbox_inches='tight', dpi=300)
Text(0.5, 1.0, 'QQ-Plot of Residuals')
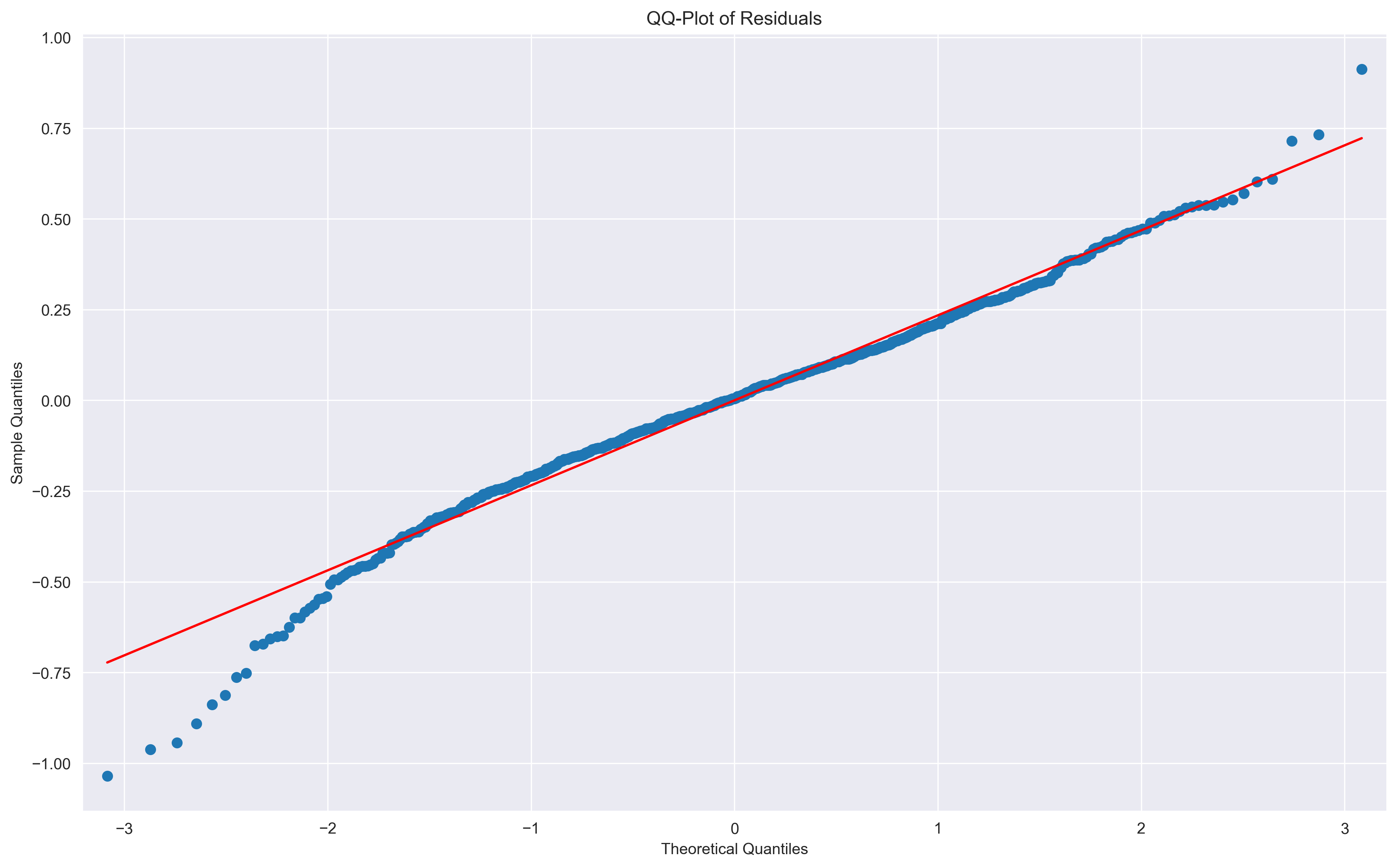
Unpacking the QQ-plot
To construct a QQ-plot, the raw data is first sorted from smaller to larger values. Then, empirical quantiles can be assigned to each sample in the dataset. These measurements can then be compared to theoretical quantiles from a normal distribution. Oftentimes, QQ-plots show zscores rather than actual quantile values since zscores can be interpreted more easily.
X-axis: Theoretical Quantiles This x-axis represents nothing but Z-values/Z-scores of standard normal distribution.
- The 0.5 quantile corresponds to the 50th percentile, which is at a Z-score of 0.
- The 90th percentile is approximately 1.282 .
- The 95th percentile is approximately 1.645
- The 99th percentile corresponds to a Z-score of approximately 2.326
- The 0.25 quantile or 25th percentile corresponds to a Z-score of approximately -0.675.
- The 0.75 quantile or 75th percentile corresponds to a Z-score of approximately 0.675.
Y-axis: Sample Quantiles The y-axis represents the quantiles of your observed data (i.e., the sorted possible values of the residuals).
Red diagonal line Data drawn from a normal distribution fall along the line y = x in the Q-Q plot. If the residuals are perfectly normal, they will follow this diagonal perfectly.
Common Diagnostics
- Right-skewed: If the data falls above the red line (where y=x) where x > 0, that means that you have a right skewed distrution (long tail on the right side of the distrubtion). A right-skewed distribution will have have higher than expected z-scores for data that is greater than the mean (zscore = 0).
- Left-skewed: If the data falls below the red line (where y=x) where x < 0, that means that you have a left skewed distrution (long tail on the left side of the distrubtion). This causes the sample distribtuion to have lower (more negative) than expected z-scores for data that is greater than the mean (zscore = 0).
- Long tails / tall peak: Combination of 1&2 above — points below the mean (zscore = 0) will fall below the red line, and points above the mean will fall above the red line
Quantitative assessments of normality
Shapiro-Wilk test and Kolmogorov–Smirnov tests: There are a couple of methods that can yield quantiative assessments of normality. However, they are both very sensitive to sample size and pale in comparison to visual inspection of the residuals (via histogram/density plot or a QQ-plot). With larger sample sizes (>1000 observations), even minor deviations from normality may lead to rejecting the null hypothesis, making these tests less useful.
-
The Shapiro-Wilk test is a test for normality. The null hypothesis of this test is that the data follows a normal distribution. A small p-value indicates that you have enough evidence to reject the null hypothesis, suggesting that the data does not follow a normal distribution.
-
The Kolmogorov-Smirnov test is also a test for normality, but it compares the cumulative distribution function (CDF) of your data to the CDF of a normal distribution. Again, a small p-value suggests that the data significantly deviates from a normal distribution.
from scipy import stats
# Shapiro-Wilk
shapiro_stat, shapiro_p = stats.shapiro(resids)
print(f"Shapiro-Wilk test: statistic={shapiro_stat:.4f}, p-value={shapiro_p:.10f}")
# Perform the Kolmogorov-Smirnov test on the test_residuals
ks_stat, ks_p = stats.kstest(resids, 'norm')
print(f"Kolmogorov-Smirnov test: statistic={ks_stat:.4f}, p-value={ks_p:.10f}")
# Display the plot (assuming you have implemented a plot in your function)
plt.show()
Shapiro-Wilk test: statistic=0.9825, p-value=0.0000000019
Kolmogorov-Smirnov test: statistic=0.3115, p-value=0.0000000000
Causes of non-normal residuals
Violations of normality often arise due to…
- Outliers present in the target variable
- Skewed target variables: When the target variable is highly skewed, it can also impact the normality of residuals. Skewed target variables might result in a skewed distribution of residuals, especially if the model does not account for the skewed nature of the data.
- Violations of the linearity assumption: If the relationship between the dependent variable and one or more predictor variables is nonlinear, the residuals may show a pattern that deviates from normality. Nonlinear relationships can cause the model to under- or overestimate the dependent variable, leading to non-normal residuals.
- Violations of homoscedasticity: Non-constant variance can lead to residuals that have a non-normal distribution, particularly if the variance increases or decreases systematically with the predicted values.
- Missing predictor variables: Omitted variable bias can occur when important predictor variables are not included in the model. If these omitted variables are related to the dependent variable, the residuals can deviate from normality.
Later in the workshop, we can use the following helper function to run the normality tests/visualizations.
from check_assumptions import normal_resid_test
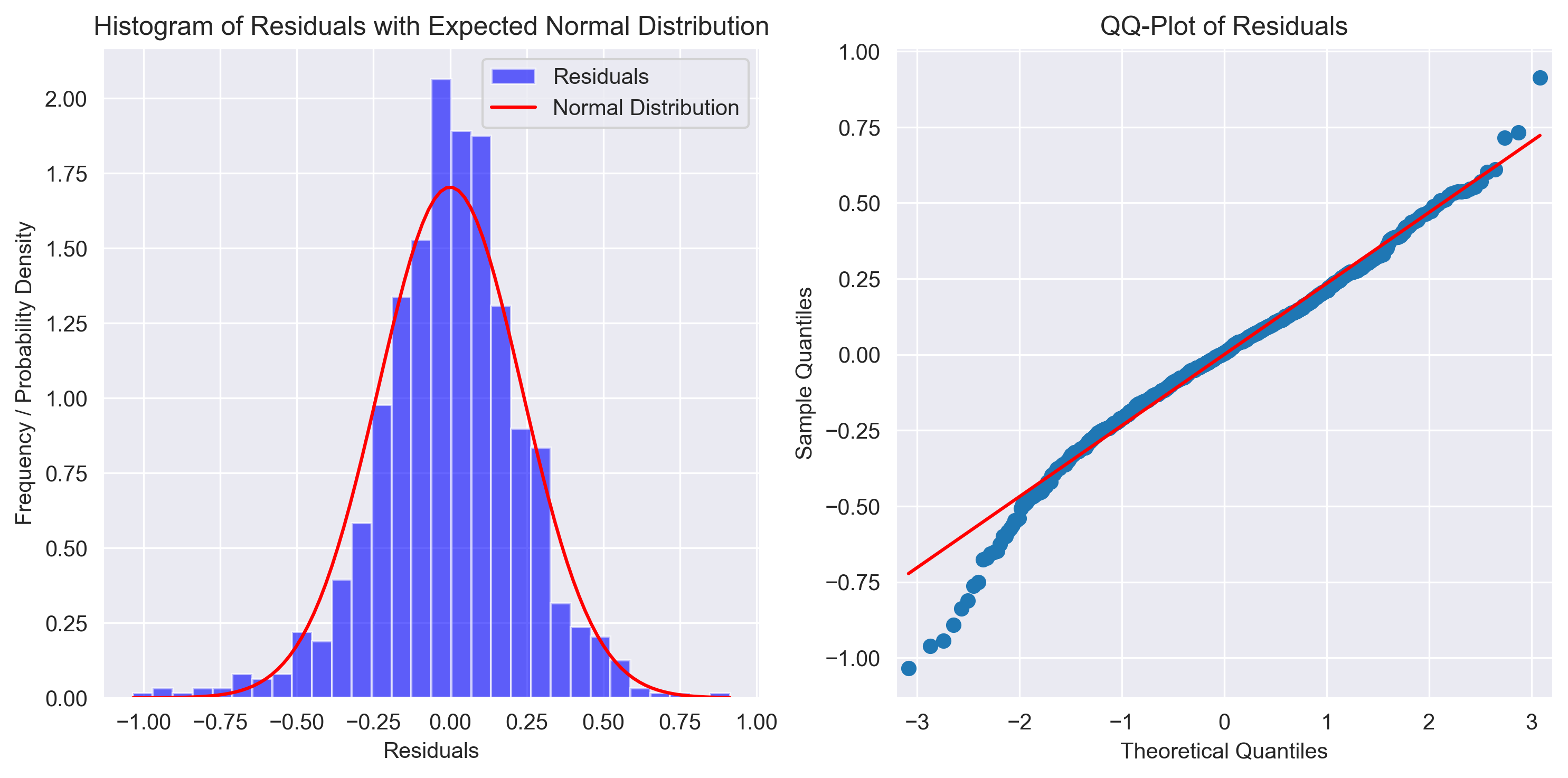
fig = normal_resid_test(resids)
# fig.savefig('..//fig//regression//assumptions//normal_resids_fullTest.png',bbox_inches='tight', dpi=300)
==========================
VERIFYING NORMAL ERRORS...
Median of residuals: 0.0047744607860336075
Skewness of resids (+/- 0.5 is bad): -0.3768190722299776
Shapiro-Wilk test: statistic=0.9825, p-value=0.0000000019
Shapiro-Wilk test passes: False
Kolmogorov-Smirnov test: statistic=0.3115, p-value=0.0000000000
Kolmogorov-Smirnov test passes: False
6. Independent errors test
Independent errors assumption: In the context of linear regression, the independent errors assumption states that the errors (also called residuals) in the model are not correlated with each other. The assumption of independent errors implies that, on average, the errors are balanced around zero, meaning that the model is equally likely to overestimate as it is to underestimate the true values of the dependent variable.
The importance of this assumption lies in its role in ensuring that the estimated coefficients obtained from the regression analysis are unbiased. When the errors have a mean of zero and are independent, the regression coefficients are estimated in such a way that they minimize the sum of squared errors between the observed data and the model’s predictions. This property ensures that the estimates of the coefficients are not systematically biased in one direction, and they tend to converge to the true population parameters as the sample size increases.
Mathematically, for a linear regression model, the independent errors assumption can be written as:
Corr(εi, εj) = 0 for all i ≠ j
Where:
- εi is the error (residual) for the ith observation.
- εj is the error (residual) for the jth observation.
- Corr(εi, εj) represents the correlation between the errors for the ith and jth observations.
Durbin-Watson Test
The Durbin-Watson test is a statistical test that checks for autocorrelation in the residuals. If the residuals are independent, there should be no significant autocorrelation. The test statistic ranges between 0 and 4. A value around 2 indicates no autocorrelation, while values significantly below 2 indicate positive autocorrelation, and values above 2 indicate negative autocorrelation. You can use the statsmodels library to calculate the Durbin-Watson test statistic:
from statsmodels.stats.stattools import durbin_watson
durbin_watson_statistic = durbin_watson(resids)
print(f"Durbin-Watson test statistic: {durbin_watson_statistic}")
Durbin-Watson test statistic: 1.9864287360736372
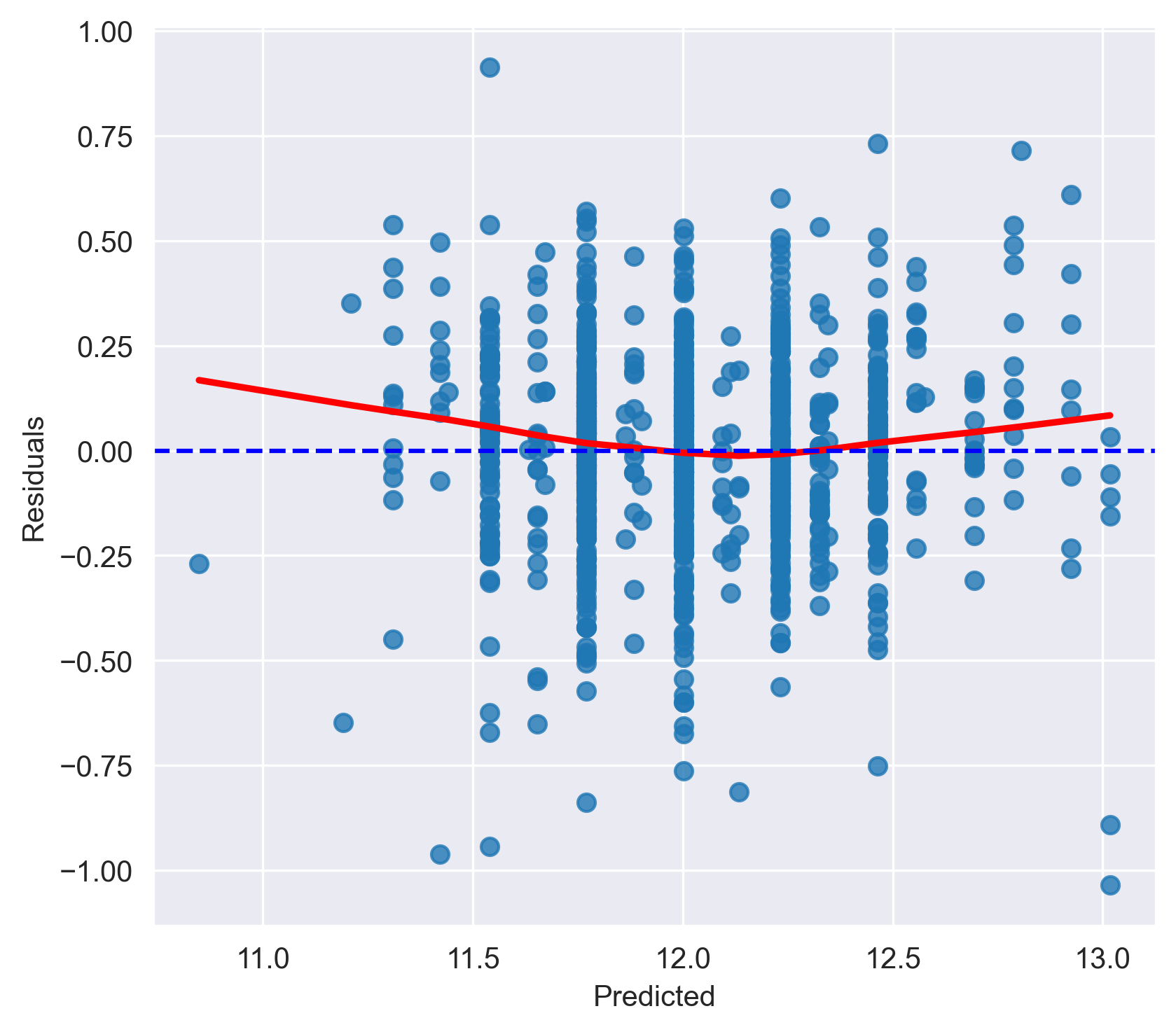
It can also be helpful to re-examine the model predictions vs residual plot to look for violations of this assumption. If the errors are independent, the residuals should be randomly scattered around zero with no specific patterns or trends. We’ll call a pre-baked helper function to quickly create this plot and run the Durbin-Watson test.
from check_assumptions import independent_resid_test
fig = independent_resid_test(y_pred_train, resids, include_plot=True)
# fig.savefig('..//fig//regression//assumptions//independentResids_fullTest.png',bbox_inches='tight', dpi=300)
==========================
VERIFYING INDEPENDENT ERRORS...
Durbin-Watson test statistic: 1.9864287360736372
Durbin-Watson test statistic is within the expected range (1.5 to 2.5) for no significant autocorrelation.
Running all assumptions tests at once
from check_assumptions import eval_regression_assumptions
eval_regression_assumptions(trained_model=trained_model, X=X_train_z, y=y_train,
y_pred=y_pred_train, y_log_scaled=True, plot_raw=False, threshold_p_value=.05);
==========================
VERIFYING MULTICOLLINEARITY...
Variable VIF
0 OverallQual 1.098041
1 SaleCondition_Abnorml 1.009233
2 SaleCondition_Family 1.003844
3 SaleCondition_Partial 1.100450
=======================================
VERIFYING LINEARITY & HOMOSCEDASTICITY...
Goldfeld-Quandt test (homoscedasticity) ----
value
F statistic 0.920670
p-value 0.818216
Homoscedasticity test: Passes (homoscedasticity is assumed)
Residuals plots ----
==========================
VERIFYING NORMAL ERRORS...
Median of residuals: 0.0047744607860336075
Skewness of resids (+/- 0.5 is bad): -0.3768190722299776
Shapiro-Wilk test: statistic=0.9825, p-value=0.0000000019
Shapiro-Wilk test passes: False
Kolmogorov-Smirnov test: statistic=0.3115, p-value=0.0000000000
Kolmogorov-Smirnov test passes: False
==========================
VERIFYING INDEPENDENT ERRORS...
Durbin-Watson test statistic: 1.9864287360736372
Durbin-Watson test statistic is within the expected range (1.5 to 2.5) for no significant autocorrelation.
Exploring an alternative set of predictors
Now that you know how to assess the 5 assumptions of linear regression, try validating a multivariate linear model that predicts log(SalePrice) from the following predictors:
- LotArea
- YearBuilt
- YearRemodAdd
- GarageArea
- GarageCars
- Neighborhood
First, extract the data you’ll be using to fit the model.
Next, preprocess the data using
encode_predictors_housing_data(X)andremove_bad_cols(X, 95)from preprocessing.py.Use
multicollinearity_test()from check_assumptions.py to check for multicollinearity and remove any problematic predictors. Repeat the test until multicollinearity is removed (VIF scores < 10).Perform a train/test split leaving 33% of the data out for the test set. Use
random_state=0to match the same results as everyone else.Use the
zscore()helper from preprocessing.py to zscore the train and test sets. This will allow us to compare coefficient sizes later.Train the model using the statsmodels package. Don’t forget to add the constant to both train/test sets (so you can do prediciton on both)
Check for evidence of extreme underfitting or overfitting using
measure_model_err()from regression_predict_sklearn.pyCheck all model assumptions
Solution
1) First, extract the data you’ll be using to fit the model.
# Extract target, `y` and predictors, `X`. y = housing['target'] y_log = np.log(y) predictors = ['LotArea', 'YearBuilt', 'YearRemodAdd', 'GarageArea', 'GarageCars', 'Neighborhood'] X=housing['data'][predictors] X.head()2) Next, preprocess the data using
encode_predictors_housing_data(X)andremove_bad_cols(X, 95)from preprocessing.py.# Preprocess the data from preprocessing import encode_predictors_housing_data X_enc = encode_predictors_housing_data(X) X_enc.head() from preprocessing import remove_bad_cols X_good = remove_bad_cols(X_enc, 95)3) Use
multicollinearity_test()from check_assumptions.py to check for multicollinearity and remove any problematic predictors. Repeat the test until multicollinearity is removed (VIF scores < 10).multicollinearity_test(X_good); X_better = X_good.drop(['GarageCars','YearBuilt'],axis = 1) multicollinearity_test(X_better);4) Perform a train/test split leaving 33% of the data out for the test set. Use
random_state=0to match the same results as everyone else.from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X_better, y_log, test_size=0.33, random_state=0)5) Use the
zscore()helper from preprocessing.py to zscore the train and test sets. This will allow us to compare coefficient sizes later.from preprocessing import zscore X_train_z = zscore(df=X_train, train_means=X_train.mean(), train_stds=X_train.std()) X_test_z = zscore(df=X_test, train_means=X_train.mean(), train_stds=X_train.std()) X_train_z.head()6) Train the model using the statsmodels package. Don’t forget to add the constant to both train/test sets (so you can do prediciton on both)
# Add a constant column to the predictor variables dataframe X_train_z = sm.add_constant(X_train_z) # Add the constant to the test set as well so we can use the model to form predictions on the test set later X_test_z = sm.add_constant(X_test_z) # Fit the multivariate regression model model = sm.OLS(y_train, X_train_z) trained_model = model.fit()7) Check for evidence of extreme underfitting or overfitting using
measure_model_err()from regression_predict_sklearn.pyfrom regression_predict_sklearn import measure_model_err # to calculate residuals and R-squared for the test set, we'll need to get the model predictions first y_pred_train = trained_model.predict(X_train_z) y_pred_test = trained_model.predict(X_test_z) errors_df = measure_model_err(y, np.mean(y), y_train, y_pred_train, y_test, y_pred_test, 'RMSE', y_log_scaled=True) errors_df.head()8) Check all model assumptions
eval_regression_assumptions(trained_model=trained_model, X=X_train_z, y=y_train, y_pred=y_pred_train, y_log_scaled=True, plot_raw=False, threshold_p_value=.05);
Key Points
All models are wrong, but some are useful.
Before reading into a model’s estimated coefficients, modelers must take care to check for evidence of overfitting and assess the 5 assumptions of linear regression.
One-hot enoding, while necesssary, can often produce very sparse binary predictors which have little information. Predictors with very little variability should be removed prior to model fitting.