Interpretablility versus explainability
Last updated on 2024-11-29 | Edit this page
Overview
Questions
- What are model interpretability and model explainability? Why are they important?
- How do you choose between interpretable models and explainable models in different contexts?
Objectives
- Understand and distinguish between explainable machine learning models and interpretable machine learning models.
- Make informed model selection choices based on the goals of your model.
Introduction
In this lesson, we will explore the concepts of interpretability and explainability in machine learning models. For applied scientists, choosing the right model for your research data is critical. Whether you’re working with patient data, environmental factors, or financial information, understanding how a model arrives at its predictions can significantly impact your work.
Interpretability
In the context of machine learning, interpretability is the degree to which a human can understand the cause of a decision made by a model, crucial for verifying correctness and ensuring compliance.
“Interpretable” models: Generally refers to models that are “inherently” understandable, such as…
- Linear regression: Examining the coefficients along with confidence intervals (CIs) helps understand the strength and direction of the relationship between features and predictions.
- Decision trees: Visualizing decision trees allows users to see the rules that lead to specific predictions, clarifying how features interact in the decision-making process.
- Rule-based classifiers. These models provide clear insights into how input features influence predictions, making it easier for users to verify and trust the outcomes.
However, as we scale up these models (e.g., high-dimensional regression models or random forests), it is important to note that the complexity can increase significantly, potentially making these models less interpretable than their simpler counterparts.
Explainability
In the context of machine learning, explainability is the extent to which the internal mechanics of a machine learning model can be articulated in human terms, important for transparency and building trust.
Explainable models: Typical refers to more complex models, such as neural networks or ensemble methods, that may be considered “black boxes” without the use of specialized explainability methods.
Explainability methods preview: Various explainability methods exist to help clarify how complex models work. For instance…
- LIME (Local Interpretable Model-agnostic Explanations) provides insights into individual predictions by approximating the model locally with a simpler, interpretable model.
- SHAP (SHapley Additive exPlanations) assigns each feature an importance value for a particular prediction, helping understand the contribution of each feature.
- Saliency Maps visually highlight which parts of an input (e.g., in images) are most influential for a model’s prediction.
These techniques, which we’ll talk more about in a later episode, bridge the gap between complex models and user understanding, enhancing transparency while still leveraging powerful algorithms.
Accuracy vs. Complexity
The traditional idea that simple models (e.g., regression, decision trees) are inherently interpretable and complex models (neural nets) are truly black-box is increasingly inadequate. Modern interpretable models, such as high-dimensional regression or tree-based methods with hundreds of variables, can be as difficult to understand as neural networks. This leads to a more fluid spectrum of complexity versus accuracy.
The accuracy vs. complexity plot from the AAAI tutorial helps to visualize the continuous relationship between model complexity, accuracy, and interpretability. It showcases that the trade-off is not always straightforward, and some models can achieve a balance between interpretability and strong performance.
This evolving landscape demonstrates that the old clusters of “interpretable” versus “black-box” models break down. Instead, we must evaluate models across the dimensions of complexity and accuracy.
Understanding the trade-off between model complexity and accuracy is crucial for effective model selection. As model complexity increases, accuracy typically improves. However, more complicated models become more difficult to interpret and explain.
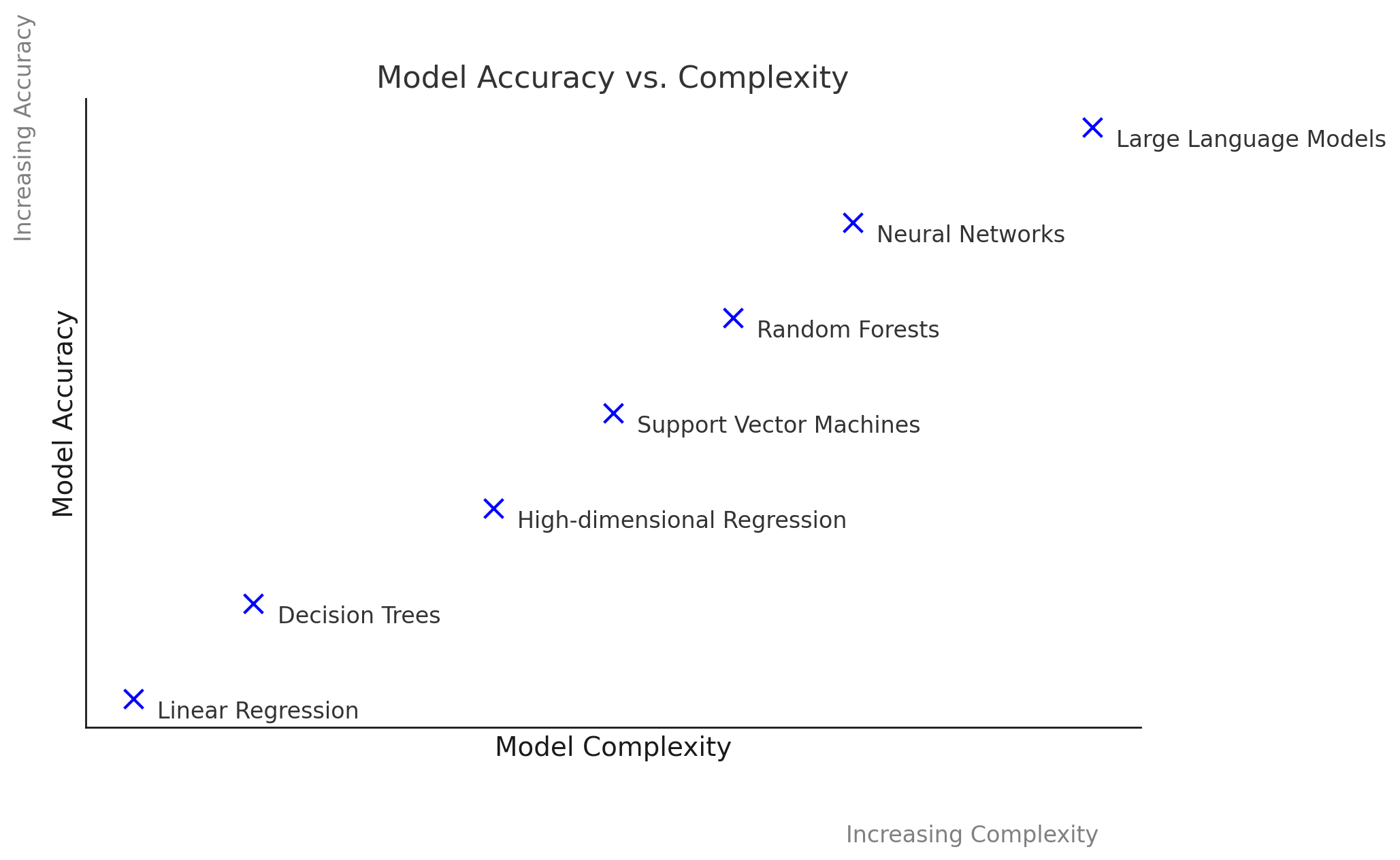
Discussion of the Plot:
- X-Axis: Represents model complexity, ranging from simple models (like linear regression) to complex models (like deep neural networks).
- Y-Axis: Represents accuracy, demonstrating how well each model performs on a given task.
This plot illustrates that while simpler models offer clarity and ease of understanding, they may not effectively capture complex relationships in the data. Conversely, while complex models can achieve higher accuracy, they may sacrifice interpretability, which can hinder trust in their predictions.
Exploring Model Choices
We will analyze a few real-world scenarios and discuss the trade-offs between “interpretable models” (e.g., regression, decision trees, etc.) and “explainable models” (e.g., neural nets).
For each scenario, you’ll consider key factors like accuracy, complexity, and transparency, and answer discussion questions to evaluate the strengths and limitations of each approach.
Here are some of the questions you’ll reflect on during the exercises:
- What are the advantages of using interpretable models versus explainable (black box) models in the given context?
- What are the potential drawbacks of each approach?
- How might the specific goals of the task influence your choice of model?
- Are there situations where high accuracy justifies the use of less interpretable models?
As you work through these exercises, keep in mind the broader implications of these decisions, especially in fields like healthcare, where model transparency can directly impact trust and outcomes.
Exercise 1: Model Selection for Predicting COVID-19 Progression, a study by Giotta et al.
Scenario:
In the early days of the COVID-19 pandemic, healthcare professionals
faced unprecedented challenges in predicting which patients were at
higher risk of severe outcomes. Accurate predictions of death or the
need for intensive care could guide resource allocation and improve
patient care. A study explored the use of various biomarkers to build
predictive models, highlighting the importance of both accuracy and
transparency in such high-stakes settings.
Objective:
Predict severe outcomes (death or transfer to intensive care) in
COVID-19 patients using biomarkers.
Dataset features:
The dataset includes biomarkers from three categories:
- Hematological markers: White blood cell count,
neutrophils, lymphocytes, platelets, hemoglobin, etc.
- Biochemical markers: Albumin, bilirubin, creatinine,
cardiac troponin, LDH, etc.
- Inflammatory markers: CRP, serum ferritin,
interleukins, TNFα, etc.
These features are critical for understanding disease progression and predicting outcomes.
Discussion questions
Compare the advantages
- What are the advantages of using interpretable models such as decision trees in predicting COVID-19 outcomes?
- What are the advantages of using black box models such as neural networks in this scenario?
Compare the advantages
- Interpretable models: Allow healthcare professionals to understand and trust the model’s decisions, providing clear insights into which biomarkers contribute most to predicting bad outcomes. This transparency is crucial in critical fields such as healthcare, where understanding the decision-making process can inform treatment plans and improve patient outcomes.
- Black box models: Often provide higher predictive accuracy, which can be crucial for identifying patterns in complex datasets. They can capture non-linear relationships and interactions that simpler models might miss.
Assess the drawbacks
- Interpretable models: May not capture complex relationships in the data as effectively as black box models, potentially leading to lower predictive accuracy in some cases.
- Black box models: Can be difficult to interpret, which hinders trust and adoption by medical professionals. Without understanding the model’s reasoning, it becomes challenging to validate its correctness, ensure regulatory compliance, and effectively debug or refine the model.
Decision-making criteria
- Interpretable models: When transparency, trust, and regulatory compliance are critical, such as in healthcare settings where understanding and validating decisions is essential.
- Black box models: When the need for high predictive accuracy outweighs the need for transparency, and when supplementary methods for interpreting the model’s output can be employed.
Exercise 2: COVID-19 Diagnosis Using Chest X-Rays, a study by Ucar and Korkmaz
Objective: Diagnose COVID-19 through chest X-rays.
Motivation:
The COVID-19 pandemic has had an unprecedented impact on global health, affecting millions of people worldwide. One of the critical challenges in managing this pandemic is the rapid and accurate diagnosis of infected individuals. Traditional methods, such as the Reverse Transcription Polymerase Chain Reaction (RT-PCR) test, although widely used, have several drawbacks. These tests are time-consuming, require specialized equipment and personnel, and often suffer from low detection rates, necessitating multiple tests to confirm a diagnosis.
In this context, radiological imaging, particularly chest X-rays, has emerged as a valuable tool for COVID-19 diagnosis. Early studies have shown that COVID-19 causes specific abnormalities in chest X-rays, such as ground-glass opacities, which can be used as indicators of the disease. However, interpreting these images requires expertise and time, both of which are in short supply during a pandemic.
To address these challenges, researchers have turned to machine learning techniques…
Dataset Specification: Chest X-ray images
{kind=link}
Real-World Impact:
The COVID-19 pandemic highlighted the urgent need for rapid and accurate diagnostic tools. Traditional methods like RT-PCR tests, while effective, are often time-consuming and have variable detection rates. Using chest X-rays for diagnosis offers a quicker and more accessible alternative. By analyzing chest X-rays, healthcare providers can swiftly identify COVID-19 cases, enabling timely treatment and isolation measures. Developing a machine learning method that can quickly and accurately analyze chest X-rays can significantly enhance the speed and efficiency of the healthcare response, especially in areas with limited access to RT-PCR testing.
Discussion Questions:
-
Compare the Advantages:
- What are the advantages of using deep neural networks in diagnosing COVID-19 from chest X-rays?
- What are the advantages of traditional methods, such as genomic data analysis, for COVID-19 diagnosis?
-
Assess the Drawbacks:
- What are the potential drawbacks of using deep neural networks for COVID-19 diagnosis from chest X-rays?
- How do these drawbacks compare to those of traditional methods?
-
Decision-Making Criteria:
- In what situations might you prioritize using deep neural networks over traditional methods, and why?
- Are there scenarios where the rapid availability of X-ray results justifies the use of deep neural networks despite potential drawbacks?
-
Compare the Advantages:
- Deep Neural Networks: Provide high accuracy (e.g., 98%) in diagnosing COVID-19 from chest X-rays, offering a quick and non-invasive diagnostic tool. They can handle large amounts of image data and identify complex patterns that might be missed by human eyes.
- Traditional Methods: Provide detailed and specific diagnostic information by analyzing genomic data and biomarkers, which can be crucial for understanding the virus’s behavior and patient response.
-
Assess the Drawbacks:
- Deep Neural Networks: Require large labeled datasets for training, which may not always be available. The models can be seen as “black boxes”, making it challenging to interpret their decisions without additional explainability methods.
- Traditional Methods: Time-consuming and may have lower detection accuracy. They often require specialized equipment and personnel, leading to delays in diagnosis.
-
Decision-Making Criteria:
- Prioritizing Deep Neural Networks: When rapid diagnosis is critical, and chest X-rays are readily available. Useful in large-scale screening scenarios where speed is more critical than the detailed understanding provided by genomic data.
- Using Traditional Methods: When detailed and specific information about the virus is needed for treatment planning, and when the availability of genomic data and biomarkers is not a bottleneck.
-
Model Explainability vs. Model Interpretability:
- Interpretability: The degree to which a human can understand the cause of a decision made by a model, crucial for verifying correctness and ensuring compliance.
- Explainability: The extent to which the internal mechanics of a machine learning model can be articulated in human terms, important for transparency and building trust.
-
Choosing Between Explainable and Interpretable
Models:
- When Transparency is Critical: Use interpretable models when understanding how decisions are made is essential.
- When Performance is a Priority: Use explainable models when accuracy is more important, leveraging techniques like LIME and SHAP to clarify complex models.
-
Accuracy vs. Complexity:
- The relationship between model complexity and accuracy is not always linear. Increasing complexity can improve accuracy up to a point but may lead to overfitting, highlighting the gray area in model selection. This is illustrated by the accuracy vs. complexity plot, which shows different models on these axes.