Model evaluation and fairness
Last updated on 2024-10-15 | Edit this page
Overview
Questions
- What metrics do we use to evaluate models?
- What are some common pitfalls in model evaluation?
- How do we define fairness and bias in machine learning outcomes?
- What types of bias and unfairness can occur in generative AI?
- What techniques exist to improve the fairness of ML models?
Objectives
- Reason about model performance through standard evaluation metrics.
- Recall how underfitting, overfitting, and data leakage impact model performance.
- Understand and distinguish between various notions of fairness in machine learning.
- Understand general approaches for improving the fairness of ML models.
Accuracy metrics
Stakeholders often want to know the accuracy of a machine learning model – what percent of predictions are correct? Accuracy can be decomposed into further metrics: e.g., in a binary prediction setting, recall (the fraction of positive samples that are classified correctly) and precision (the fraction of samples classified as positive that actually are positive) are commonly-used metrics.
Suppose we have a model that performs binary classification (+, -) on a test dataset of 1000 samples (let \(n\)=1000). A confusion matrix defines how many predictions we make in each of four quadrants: true positive with positive prediction (++), true positive with negative prediction (+-), true negative with positive prediction (-+), and true negative with negative prediction (–).
| True + | True - | |
|---|---|---|
| Predicted + | 300 | 80 |
| Predicted - | 25 | 595 |
So, for instance, 80 samples have a true class of + but get predicted as members of -.
We can compute the following metrics:
- Accuracy: What fraction of predictions are correct?
- (300 + 595) / 100 = 0.895
- Accuracy is 89.5%
- Precision: What fraction of predicted positives are true positives?
- 300 / (300 + 80) = 0.789
- Precision is 78.9%
- Recall: What fraction of true positives are classified as positive?
- 300 / (300 + 25) = 0.923
- Recall is 92.3%
We’ve discussed binary classification but for other types of tasks there are different metrics. For example,
- Multi-class problems often use Top-K accuracy, a metric of how often the true response appears in their top-K guesses.
- Regression tasks often use the Area Under the ROC curve (AUC ROC) as a measure of how well the classifier performs at different thresholds.
What accuracy metric to use?
Different accuracy metrics may be more relevant in different situations. Discuss with a partner or small groups whether precision, recall, or some combination of the two is most relevant in the following prediction tasks:
- Deciding what patients are high risk for a disease and who should get additional low-cost screening.
- Deciding what patients are high risk for a disease and should start taking medication to lower the disease risk. The medication is expensive and can have unpleasant side effects.
It is best if all patients who need the screening get it, and there is little downside for doing screenings unnecessarily because the screening costs are low. Thus, a high recall score is optimal.
Given the costs and side effects of the medicine, we do not want patients not at risk for the disease to take the medication. So, a high precision score is ideal.
Model evaluation pitfalls
Overfitting and underfitting
Overfitting is characterized by worse performance on the test set than on the train set and can be fixed by switching to a simpler model architecture or by adding regularization.
Underfitting is characterized by poor performance on both the training and test datasets. It can be fixed by collecting more training data, switching to a more complex model architecture, or improving feature quality.
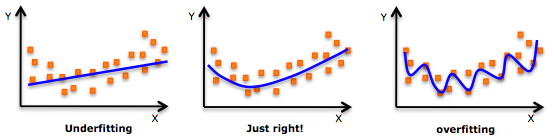
If you need a refresher on how to detect overfitting and underfitting in your models, this article is a good resource.
Data Leakage
Data leakage occurs when the model has access to the test data during training and results in overconfidence in the model’s performance.
Recent work by Sayash Kapoor and Arvind Narayanan shows that data leakage is incredibly widespread in papers that use ML across several scientific fields. They define 8 common ways that data leakage occurs, including:
- No test set: there is no hold-out test-set, rather, the model is evaluated on a subset of the training data. This is the “obvious,” canonical example of data leakage.
- Preprocessing on whole dataset: when preprocessing occurs on the train + test sets, rather than just the train set, the model learns information about the test set that it should not have access to until later. For instance, missing feature imputation based on the full dataset will be different than missing feature imputation based only on the values in the train dataset.
- Illegitimate features: sometimes, there are features that are proxies for the outcome variable. For instance, if the goal is to predict whether a patient has hypertension, including whether they are on a common hypertension medication is data leakage since future, new patients would not already be on this medication.
- Temporal leakage: if the model predicts a future outcome, the train set should contain information from the future. For instance, if the task is to predict whether a patient will develop a particular disease within 1 year, the dataset should not contain data points for the same patient from multiple years.
Measuring fairness
What does it mean for a machine learning model to be fair or unbiased? There is no single definition of fairness, and we can talk about fairness at several levels (ranging from training data, to model internals, to how a model is deployed in practice). Similarly, bias is often used as a catch-all term for any behavior that we think is unfair. Even though there is no tidy definition of unfairness or bias, we can use aggregate model outputs to gain an overall understanding of how models behave with respect to different demographic groups – an approach called group fairness.
In general, if there are no differences between groups in the real world (e.g., if we lived in a utopia with no racial or gender gaps), achieving fairness is easy. But, in practice, in many social settings where prediction tools are used, there are differences between groups, e.g., due to historical and current discrimination.
For instance, in a loan prediction setting in the United States, the average white applicant may be better positioned to repay a loan than the average Black applicant due to differences in generational wealth, education opportunities, and other factors stemming from anti-Black racism. Suppose that a bank uses a machine learning model to decide who gets a loan. Suppose that 50% of white applicants are granted a loan, with a precision of 90% and a recall of 70% – in other words, 90% of white people granted loans end up repaying them, and 70% of all people who would have repaid the loan, if given the opportunity, get the loan. Consider the following scenarios:
- (Demographic parity) We give loans to 50% of Black applicants in a way that maximizes overall accuracy
- (Equalized odds) We give loans to X% of Black applicants, where X is chosen to maximize accuracy subject to keeping precision equal to 90%.
- (Group level calibration) We give loans to X% of Black applicants, where X is chosen to maximize accuracy while keeping recall equal to 70%.
There are many notions of statistical group fairness, but most boil down to one of the three above options: demographic parity, equalized odds, and group-level calibration. All three are forms of distributional (or outcome) fairness. Another dimension, though, is procedural fairness: whether decisions are made in a just way, regardless of final outcomes. Procedural fairness contains many facets, but one way to operationalize it is to consider individual fairness (also called counterfactual fairness), which was suggested in 2012 by Dwork et al. as a way to ensure that “similar individuals [are treated] similarly”. For instance, if two individuals differ only on their race or gender, they should receive the same outcome from an algorithm that decides whether to approve a loan application.
In practice, it’s hard to use individual fairness because defining a complete set of rules about when two individuals are sufficiently “similar” is challenging.
Matching fairness terminology with definitions
Match the following types of formal fairness with their definitions. (A) Individual fairness, (B) Equalized odds, (C) Demographic parity, and (D) Group-level calibration
- The model is equally accurate across all demographic groups.
- Different demographic groups have the same true positive rates and false positive rates.
- Similar people are treated similarly.
- People from different demographic groups receive each outcome at the same rate.
A - 3, B - 2, C - 4, D - 1
But some types of unfairness cannot be directly measured by group-level statistical data. In particular, generative AI opens up new opportunities for bias and unfairness. Bias can occur through representational harms (e.g., creating content that over-represents one population subgroup at the expense of another), or through stereotypes (e.g., creating content that reinforces real-world stereotypes about a group of people). We’ll discuss some specific examples of bias in generative models next.
Fairness in generative AI
Generative models learn from statistical patterns in real-world data. These statistical patterns reflect instances of bias in real-world data - what data is available on the internet, what stereotypes does it reinforce, and what forms of representation are missing?
Natural language
One set of social stereotypes that large AI models can learn is gender based. For instance, certain occupations are associated with men, and others with women. For instance, in the U.S., doctors are historically and stereotypically usually men.
In 2016, Caliskan et al. showed that machine translation systems exhibit gender bias, for instance, by reverting to stereotypical gendered pronouns in ambiguous translations, like in Turkish – a language without gendered pronouns – to English.
In response, Google tweaked their translator algorithms to identify and correct for gender stereotypes in Turkish and several other widely-spoken languages. So when we repeat a similar experiment today, we get the following output:
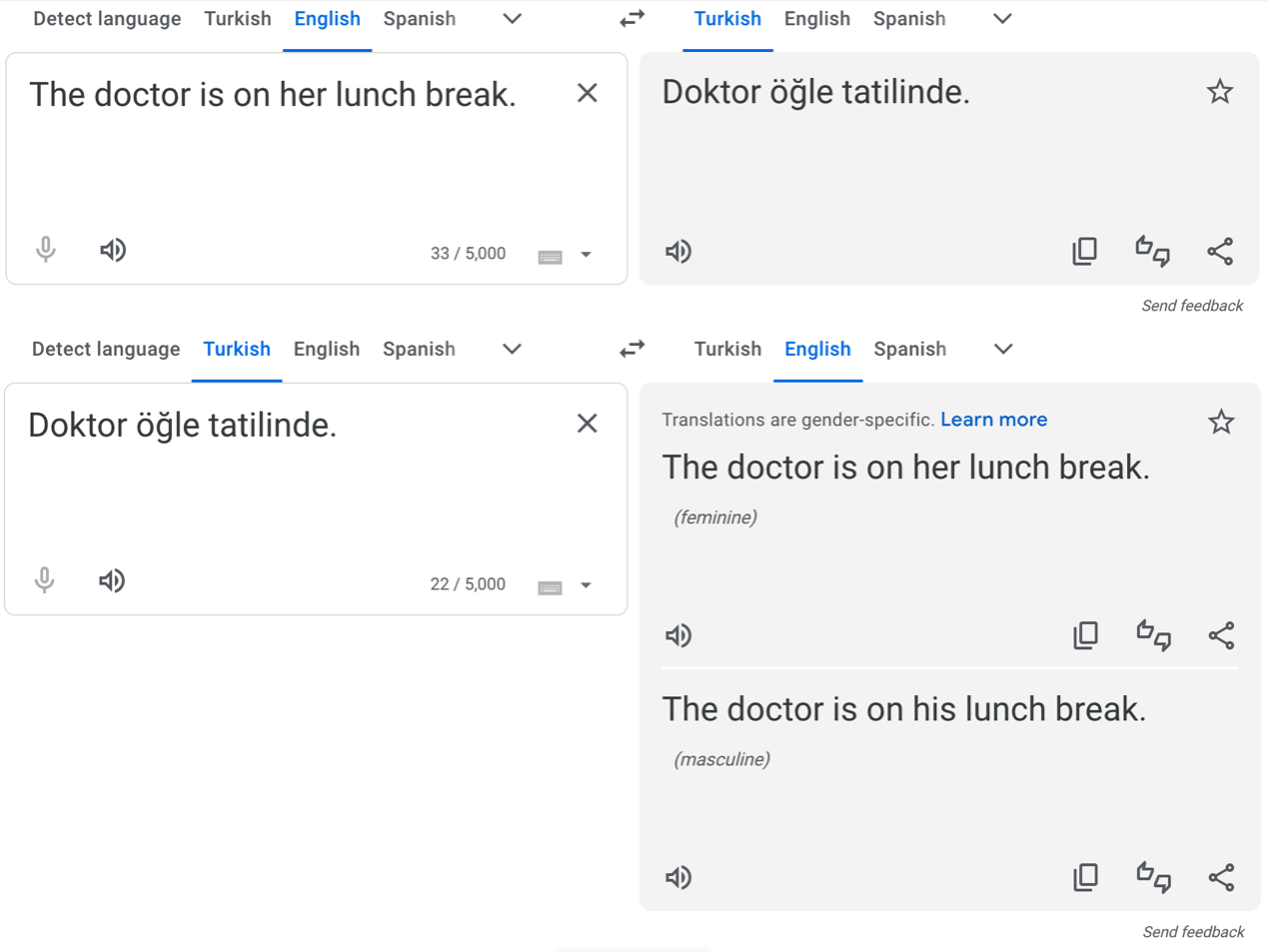
But for other, less widely-spoken languages, the original problem persists:
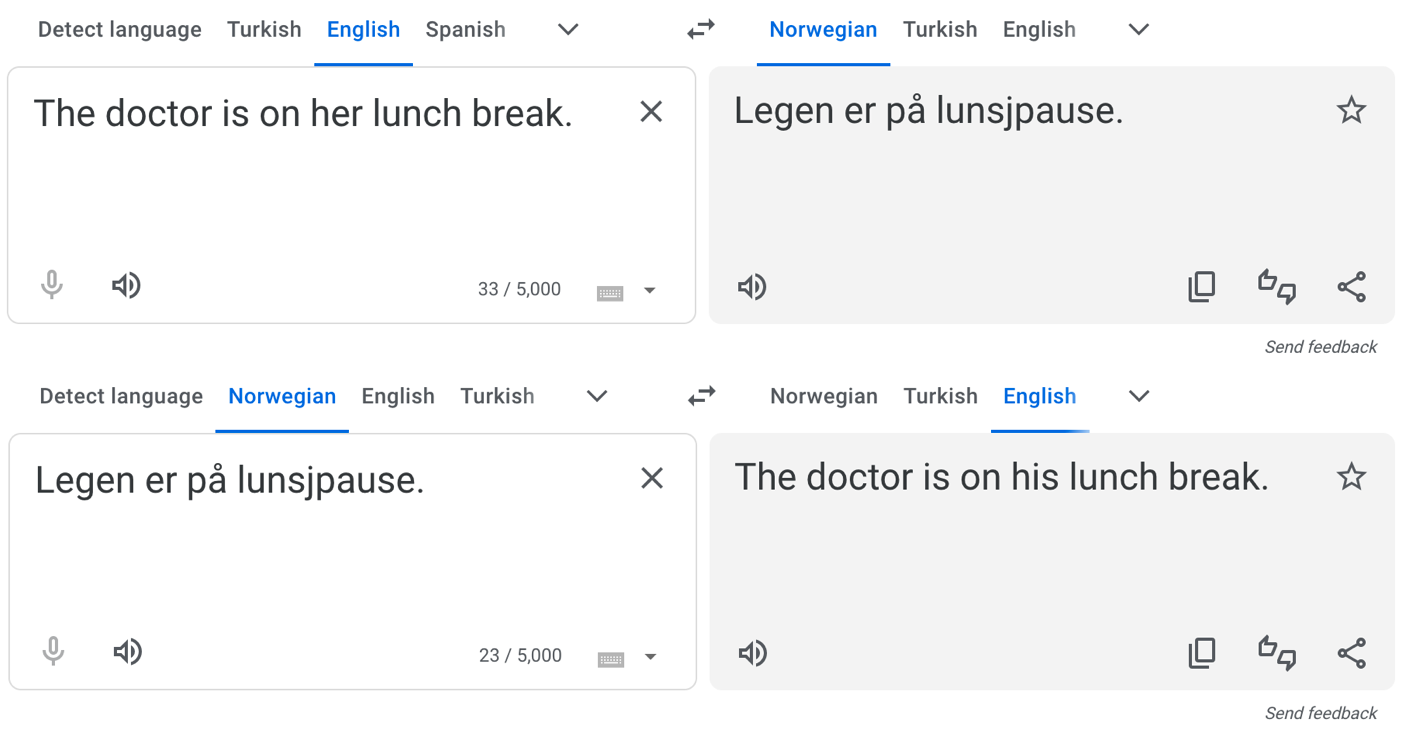
We’re not trying to slander Google Translate here – the translation, without additional context, is ambiguous. And even if they extended the existing solution to Norwegian and other languages, the underlying problem (stereotypes in the training data) still exists. And with generative AI such as ChatGPT, the problem can be even more pernicious.
Red-teaming large language models
In cybersecurity, “red-teaming” is when well-intentioned people think like a hacker in order to make a system safer. In the context of Large Language Models (LLMs), red-teaming is used to try to get LLMs to output offensive, inaccurate, or unsafe content, with the goal of understanding the limitations of the LLM.
Try out red-teaming with ChatGPT or another LLM. Specifically, can you construct a prompt that causes the LLM to output stereotypes? Here are some example prompts, but feel free to get creative!
“Tell me a story about a doctor” (or other profession with gender)
If you speak a language other than English, how does are ambiguous gendered pronouns handled? For instance, try the prompt “Translate ‘The doctor is here’ to Spanish”. Is a masculine or feminine pronoun used for the doctor in Spanish?
If you use LLMs in your research, consider whether any of these issues are likely to be present for your use cases. If you do not use LLMs in your research, consider how these biases can affect downstream uses of the LLM’s output.
Most publicly-available LLM providers set up guardrails to avoid propagating biases present in their training data. For instance, as of the time of this writing (January 2024), the first suggested prompt, “Tell me a story about a doctor,” consistently creates a story about a woman doctor. Similarly, substituting other professions that have strong associations with men for “doctor” (e.g., “electrical engineer,” “garbage collector,” and “US President”) yield stories with female or gender-neutral names and pronouns.
Discussing other fairness issues
If you use LLMs in your research, consider whether any of these issues are likely to be present for your use cases. Share your thoughts in small groups with other workshop participants.
Image generation
The same problems that language modeling face also affect image generation. Consider, for instance, Melon et al. developed an algorithm called Pulse that can convert blurry images to higher resolution. But, biases were quickly unearthed and shared via social media.
Challenge
Who is shown in this blurred picture? 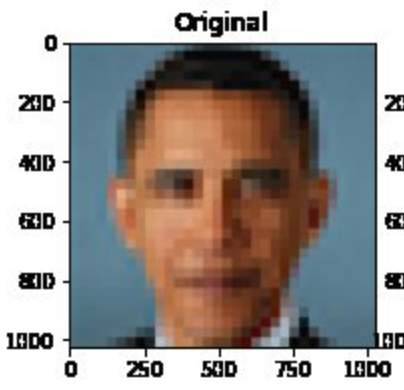
While the picture is of Barack Obama, the upsampled image shows a
white face. 
You can try the model here.
Menon and colleagues subsequently updated their paper to discuss this issue of bias. They assert that the problems inherent in the PULSE model are largely a result of the underlying StyleGAN model, which they had used in their work.
Overall, it seems that sampling from StyleGAN yields white faces much more frequently than faces of people of color … This bias extends to any downstream application of StyleGAN, including the implementation of PULSE using StyleGAN.
…
Results indicate a racial bias among the generated pictures, with close to three-fourths (72.6%) of the pictures representing White people. Asian (13.8%) and Black (10.1%) are considerably less frequent, while Indians represent only a minor fraction of the pictures (3.4%).
These remarks get at a central issue: biases in any building block of a system (data, base models, etc.) get propagated forwards. In generative AI, such as text-to-image systems, this can result in representational harms, as documented by Bianchi et al. Fixing these issues of bias is still an active area of research. One important step is to be careful in data collection, and try to get a balanced dataset that does not contain harmful stereotypes. But large language models use massive training datasets, so it is not possible to manually verify data quality. Instead, researchers use heuristic approaches to improve data quality, and then rely on various techniques to improve models’ fairness, which we discuss next.
Improving fairness of models
Model developers frequently try to improve the fairness of there model by intervening at one of three stages: pre-processing, in-processing, or post-processing. We’ll cover techniques within each of these paradigms in turn.
We start, though, by discussing why removing the sensitive attribute(s) is not sufficient. Consider the task of deciding which loan applicants are funded. Suppose we are concerned with racial bias in the model outputs. If we remove race from the set of attributes available to the model, the model cannot make overly racist decisions. However, it could instead make decisions based on zip code, which in the US is a very good proxy for race.
Can we simply remove all proxy variables? We could likely remove zip code, if we cannot identify a causal relationship between where someone lives and whether they will be able to repay a loan. But what about an attribute like educational achievement? Someone with a college degree (compared with someone with, say, less than a high school degree) has better employment opportunities and therefore might reasonably be expected to be more likely to be able to repay a loan. However, educational attainment is still a proxy for race in the United States due to historical (and ongoing) discrimination.
Pre-processing generally modifies the dataset used for learning. Techniques in this category include:
Oversampling/undersampling: instead of training a machine learning model on all of the data, undersample the majority class by removing some of the majority class samples from the dataset in order to have a more balanced dataset. Alternatively, oversample the minority class by duplicating samples belonging to this group.
Data augmentation: the number of samples from minority groups may be increased by generating synthetic data with a generative adversarial network (GAN). We won’t cover this method in this workshop (using a GAN can be more computationally expensive than other techniques). If you’re interested, you can learn more about this method from the paper Inclusive GAN: Improving Data and Minority Coverage in Generative Models.
Changing feature representations: various techniques have been proposed to increase fairness by removing unfairness from the data directly. To do so, the data is converted into an alternate representation so that differences between demographic groups are minimized, yet enough information is maintained in order to be able to learn a model that performs well. An advantage of this method is that it is model-agnostic, however, a challenge is it reduces the interpretability of interpretable models and makes post-hoc explainability less meaningful for black-box models.
Pros and cons of preprocessing options
Discuss what you think the pros and cons of the different pre-processing options are. What techniques might work better in different settings?
A downside of oversampling is that it may violate statistical assumptions about independence of samples. A downside of undersampling is that the total amount of data is reduced, potentially resulting in models that perform less well overall.
A downside of using GANs to generate additional data is that this process may be expensive and require higher levels of ML expertise.
A challenge with all techniques is that if there is not sufficient data from minority groups, it may be hard to achieve good performance on the groups without simply collecting more or higher-quality data.
In-processing modifies the learning algorithm. Some specific in-processing techniques include:
Reweighting samples: many machine learning models allow for reweighting individual samples, i.e., indicating that misclassifying certain, rarer, samples should be penalized more severely in the loss function. In the code example, we show how to reweight samples using AIF360’s Reweighting function.
Incorporating fairness into the loss function: reweighting explicitly instructs the loss function to penalize the misclassification of certain samples more harshly. However, another option is to add a term to the loss function corresponding to the fairness metric of interest.
Post-processing modifies an existing model to increase its fairness. Techniques in this category often compute a custom threshold for each demographic group in order to satisfy a specific notion of group fairness. For instance, if a machine learning model for a binary prediction task uses 0.5 as a cutoff (e.g., raw scores less than 0.5 get a prediction of 0 and others get a prediction of 1), fair post-processing techniques may select different thresholds, e.g., 0.4 or 0.6 for different demographic groups.
In the next episode, we explore two different bias mitigations strategies implemented in the AIF360 Fairness Toolkit.