Structured Metadata: From Markup to JSON
Last updated on 2023-11-16 | Edit this page
Estimated time: 100 minutes

Overview
Questions
- What is semi-structured metadata?
- How do you extract semi-structured metadata from natural language.
- What is the JSON syntax?
Objectives
- Explain the importance of semi-structured metadata for machine readability.
- Understand, read and write basic Markdown / HTML / XML / JSON.
Markup?
Slide set: IntroToInformationTransfer.pdf
Time estimate: 5 min
- With the next episode, we are diving deeper into the topic of structured data and enhancing machine readability of our metadata records.
- So far we have been talking about natural language communication. When the senior doctor gives a status update about a patient’s condition to his colleague, the information is clear. Let’s take this message apart and structure it…
- The message is concerning a subject, namely the specific patient in room 305. It includes a location, the room number and it gives information about the current condition, “unchanged”. Let’s assume that both doctors were machines. Extracting this information from the natural language text wouldn’t be as straightforward…
- And the information needs to be structured in particular ways to make it easily transferrable and accessible for the receiving end. One popular and lightweight format to structure data is JSON, JavaScript Object Notation. We will take an in-depth look at JSON in the upcoming lectures.
Slide set: WhatIsMarkupXmlJson.pdf
Time estimate: 15 min
- The first term that we will come across regularly throughout this lesson is Markup.
- You encounter markup continuously when you read a text. A period, for example, indicates the end of a declarative or imperative sentence, which results in the speaker briefly stopping to talk, if reading out loud. The question mark, on the other hand, declares a question and a speaker will, in many languages, raise their voice before pausing at the end of the sentence. In this sense, the punctuation - or Markup - is not part of the text or information by itself. It rather provides some additional information about the text.
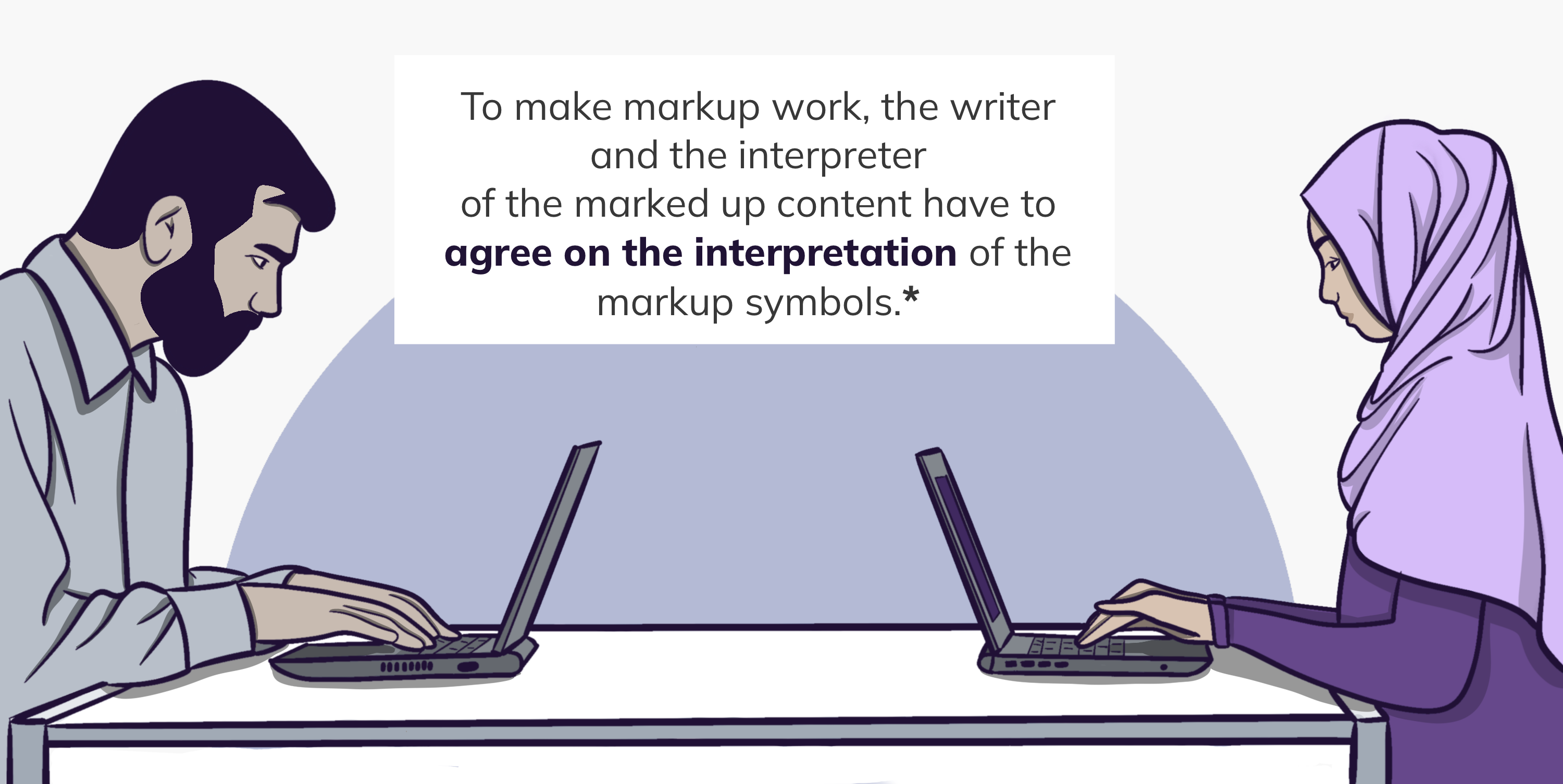
- Essential for functional markup is that the sender, in the case of a text, the writer and the recipient - the reader - agree on the interpretation of the symbols used to markup the text. Shown here is an interrobang, a combination of a question mark and an exclamation point. (You can reactivate the audience by asking them, whether someone is familiar with the definition of the interrobang or if they would know how to interpret it.) The interrobang was proposed in the 1960s as a new punctuation mark to indicate a rhetorical question. As you might have guessed already, the proposal did not come very far.
- Markup can be distinguished into four different types:
- punctuational markup, as seen in the previous examples.
- presentational markup gives information on how the text should be displayed, which includes vertical or horizontal spacing, page breaks, and enumerations of lists. When enclosing text between two asterisks while writing Markdown, a Markdown interpreter will display this text in bold font face.
- descriptive or declarative markup gives information on the type or class the enclosed text belongs to. In this example, the text was enclosed by an H1 opening and closing tag. HTML interpreters will now know, that this sentence is the most important headline on the page, regardless of how it is displayed.
- referential markup refers to entities external to the document. On a website, this marked-up sentence would appear as a link and redirect the user to the specified URL, when activated.
- I’m certain all of us have manually marked up a document in one way or another, using a text marker while reading a journal publication or commenting on a manuscript while reviewing it. These markups give information to the human reader: What is important in this text? What information is missing? Markup in computer files, however, is targeting a machine for interpretation. It declares how the content should be formatted or printed, or give additional information on the written words.
- So from now on in this lecture, the term markup will refer to markup that targets computers, mainly descriptive and referential markup.
- Descriptive and referential markup, used rigorously, is a way to make data and natural text more accessible for computer analysis and can provide additional information for the human user as well. But we will come to that in a bit.
- We will first shift our focus to the importance of the interoperability of the data formats that we want to use to document our data and metadata. In the 1980s, roughly 10 years before the birth of the World Wide Web, the internet was already a thing and national and international data networks were emerging fast. This increased the need for standardized data transfer formats to facilitate data exchange and interpretability on various machines in one network. One of the first industry standards for electronic publishing was the “Standard Generalized Markup Language”, or SGML.
- With the implementation of the World Wide Web, HTML - the HyperText Markup Language - became the standard language for web pages and has its roots in SGML. The markup tags of HTML and their interpretation are well-defined. XML - the eXtensible Markup Language - on the other hand, was developed to transfer and store data on the World Wide Web. The tags are arbitrary, descriptive and can be defined by the user. Let’s take a closer look.
- This XML example stores data in form of natural text (point to the two sentences) and a number (highlight the “1”). Each of these data elements is enclosed in a start and end tag. As mentioned before, these tags can be defined arbitrarily, so we state, that the first sentence is the title, the second sentence is a description and the number one represents a word count. We can now introduce a data hierarchy, declaring that all these data elements describe one example. We could now look for the “title” of the “example” and retrieve the data stored between those tags. XML is software- and hardware-independent and still widely used as a data exchange format. Though XML is human-readable, enclosing the data between start and end tags is quite an effort and meddles with the clarity of this format. So we are leaving the realm of markup languages…
- to introduce another data exchange format, which is recommended as a standard from the W3 consortium: JSON. JSON is short for JavaScript Object notation. It is based on the representation for data objects in JavaScript - the main programming language of the Web - and bears all the advantages XML has shown, such as lightweight data exchange, software and hardware independence, and hierarchical structure - with an increased human readability. For the remainder of this lesson, we will learn how to read, write and standardize JSON object literals.
Slide set: JsonStepByStep.pdf
Time estimate: 7 min
- Let’s have a closer look at the structure and syntax of JSON object literals.
- In this example we have a JSON object, which describes a person named John.
- Objects are enclosed in curly braces.
- Within these objects, data entities are stored in key-value pairs.
- Keys are always of the data type “string”
- Data values can be given as one of the following data types. They can be given as…
- strings.
- String values can contain any kind of characters and are typically enclosed in double quotes. Each string, no matter how long it is, will be interpreted as a single value.
- Numbers…
- can be either integers or floats.
- Booleans…
- Boolean values in JSON have one of two possible values. It is either true or false.
- Null…
- Assigning the data type NULL does not mean the same as zero but
rather that no value was assigned to this variable. You might be
familiar with other representations, such as NA or nan. If you read a
JSON object into Python, for example, NULL will be parsed as
None. - Values in JSON can also be arrays. For example, John has two parents, Anna and Michael.
- An array is a collection of multiple elements and can be understood as a list of values. The data elements within an array can have the same data type or vary in their data types.
- Last but not least, a value can be another object. John has a pet and the value of the key “pet” is an object describing John’s dog Brutus.
- Again, an object contains key-value pairs. These key-value pairs are separated by commas and enclosed by curly braces.
- The separation of data entities by commas in a JSON object literal is crucial.
- JSON is not sensitive to indentations and line breaks. However, indentation and line breaks can significantly increase the human readability of the JSON object literal. Now let’s compare the JSON representation of this object with its XML representation…
- Both representations contain the same information. In XML the data
value is stored between start and end tags, whereas in JSON, the value
is assigned to a property and separated from other entries with a comma.
Both representations allow for hierarchical data storage as seen for the
description of John’s pet. In JSON this is done by nesting objects, in
XML the data entries are enclosed by
<pet>tags. A difference can be seen in the representation for John’s parents. Whereas an array is given in the JSON object literal, comparable lists do not exist in XML. Here the parents’ names are enclosed individually with the same start and end tags. - Besides XML and JSON, the third widely used standard data exchange format is YAML. JSON and YAML can be parsed into one another.
- (Allow some time for questions.)
Markup is not part of the natural language or content of the text but tells something about it 1, 2. By “marking up” a text document additional information on the structure, formatting and relationships within the document can be given. A familiar example are the annotations left by a teacher in a student’s assay with a red pen.2 In order to make Markup work, it is essential, that it follows determined rules, that are understood by the entity marking up the document and the interpreter alike. Markup languages in the digital context establish sets of rules that allow the machine to interpret the building blocks of the document. Some categories of markup are:
Punctuational markup is placing periods, question marks, or similar punctuations at the end of sentences. It gives clues about intonations.
This is a question?Presentational markup is mainly about style.
Descriptive or declarative markup declares what an element is; e. g. a member of a particular type or class like a:
If design rules for headlines change, the document structure remains intact and is still in line with the authors’ original intention.
Referential markup refers to entities external to
the document and may be replaced by those entities during processing.
The World Wide Web markup language HTML
(HyperText Markup
Language) e.g. uses the anchor <a>
tag for hypertext references (hyperlinks) or <img>
for images.
Callout
Rigorous markup can make text (character strings) more accessible for computer analysis.
SGML (Standard Generalized Markup Language) was one of the first industry standards for electronic publishing – a meta-language for generalized, descriptive markup languages – first accepted as an ISO standard in 1986. Both, HTML (1989) and XML (1998) are based on SGML.3
HTML (HyperText Markup Language) is the standard markup language for web pages.
XML
The main purpose of XML (eXtensible
Markup Language) is the
transfer and storage of arbitrary data on the World Wide Web.
XML is software- and hardware-independent. It is considered
human-readable and allows for hierarchical (tree-like) structures. Data
elements are wrapped in start <...> and end
</...> “tags”. XML tags can be customized by the
author of the document, its markup is therefore not limited to a set of
rules but extensible.4
JSON
JSON (JavaScript Object Notation) is not a markup language. It is a lightweight, human-readable, hierarchical format to store and transport data.5 JSON syntax is inspired by JavaScript object notation.6 Like XML, JSON is software- and hardware-independent.
- (meta)data elements are defined in key/value pairs
- keys are of data type
string(in quotes) - values must be of data type
string,number,boolean,arrayorobject - elements are separated by commas
- curly braces hold
objects - square brackets hold
arrays - in-line commenting is not supported
JSON
{
"key":"value",
"aString":"string",
"anInteger":5,
"aFloat":0.5,
"aBoolean":true,
"anArray": ["item1", "item2", "item3"],
"anObject": {
"key1":"value1",
"key2":"value2",
"key3":"value3"
}
}Callout
Data exchange formats such as XML or JSON can be read and processed not only by humans but also by computers. Structured (meta)data is key to enable machine-readability.
Slide set: Challenge23Introduction.pdf
Time estimate: 3 min
- In the following challenges, we will apply what we have learned in the lectures so far to our example dataset.
- You have inspected the data and realized quite rapidly, that you need more information on the data to make sense of it. So you ask your collaborators for additional meta-information.
- They reply by sending you a README-style metadata file.
- However, your funding agency requires that you upload every dataset in your project to their public repository and attach a structured metadata record.
- In challenge 2, you will review the README-style metadata record and highlight all the information that you deem relevant to understand the data and reproduce the experiment.
- In challenge 3, you will then take this information and transform it into a JSON object literal.
- (The challenges are designed as group challenges. We like to add a slide here, on which we list the randomized groups and give additional technical and administrative information.)
The following challenges 2 & 3 will be processed consecutively in groups of 4 - 6 learners.
Total time: 35 min
Implementation:
Prepare shared notes documents
for each group of learners attending the lesson. We have good
experiences with copying the challenges into the documents and adding
space for collaborative working on the tasks.
Try to be present
with as many instructors as there are break-out rooms to moderate the
discussions and answer questions.
Shared notes:
You can find an example Markdown
file for the group handouts HERE.
This document is optimized for use in a Hedgedoc document.
Challenge 2: Identify metadata in README.txt
You cannot make sense of the data you got from your collaborators. You ask them for supplemental information and they send you the following README file (see below).
- Read the README carefully.
- In the group, discuss, decide and prioritize which information in the text are relevant experimental metadata.
-
Mark up the relevant information. In markdown you
can mark up the respective words with “==”.
Example:==This text will be highlighted==
You can download the README as TXT file here: README_exampleDataObject.txt
README_exampleDataObject.txt
This README file describes the data in trainingObject.csv
The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster "Flight of the Bat" in Gotham City.
The data was collected by Bruce Wayne and Selina Kyle (Institute for Vigilance and Nightly Motion -- Justice League) on 2022-02-28 in Gotham City, New Jersey.
The test person (male) is 5'11 tall and weighs 187 lbs.
The test person strapped the recording device (iPhone X) with a running armband to their left upper arm and activated the biomechanical acceleration and scream detection of the application "Physics Toolbox Suite" by Vieyra Software.
- "t" describes the ride time at which measurements were taken upon activating the recording in seconds.
- "ax" describes the biomechanical acceleration of the test person on the x axis in m/s².
- "ay" describes the biomechanical acceleration of the test person on the y axis in m/s².
- "az" describes the biomechanical acceleration of the test person on the z axis in m/s².
- "scr" is a boolean indicating a detected scream of the test person.This README describes the data in trainingObject.csv
The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster “Flight of the Bat” in Gotham City.
The data was collected by Bruce Wayne and Selina Kyle (Institute for Vigilance and Nightly Motion - Justice League) on 2022-02-28 in Gotham City, New Jersey.
The test person (male) is 5’11’’ tall and weighs 187 lbs.
The test person strapped the recording device (iPhone X) with a running armband to the left upper arm and activated the biomechanical acceleration and scream detection of the application Physics Toolbox Suite by Vieyra Software. During the ride, the test person was instructed to firmly hold on to the safety handles in order to avoid excessive movement of the arm. The test person was seated in row 10 on the outer left (seat 37).
“t” describes the ride time at which measurements were taken upon activating the recording in seconds. “ax” describes the biomechanical acceleration of the test person on the x axis in m/s². “ay” describes the biomechanical acceleration of the test person on the y axis in m/s². “az” describes the biomechanical acceleration of the test person on the z axis in m/s². “scr” is a boolean indicating a detected scream of the test person.
Challenge 3: Write JSON metadata record
You have manually marked up the relevant information in the README. However, your project requires you to provide metadata in the form of a machine-readable JSON metadata record. The project provides you with a simple example JSON object (remember, that curly braces hold objects):
- Based on the information identified in the README, write a structured, descriptive JSON object.
- Collaboratively, find suitable keys to your values.
- You may want to use some JSON formatter web service to check and beautify (lint) your output.
Keep in mind, that values in JSON must be one of the following data types:
- a string
"" - a number
42 - a boolean
True - null
null - an array
[] - an object
{}
Example:
This is just one (of many) valid solutions.
JSON
{
"fileName": "trainingObject.csv",
"abstract": "The data describes the biomechanical acceleration and screams detected of a test person during the ride of the roller coaster \"Flight of the Bat\" in Gotham City.",
"format": "text/csv",
"date": "2022-02-28",
"creator": [
{
"creatorName": "Bruce Wayne",
"creatorAffiliation": "Institute for Vigilance and Nightly Motion - Justice League"
},
{
"creatorName": "Selina Kyle",
"creatorAffiliation": "Institute for Vigilance and Nightly Motion - Justice League"
}
],
"experimentalParameters": {
"testRide": {
"rideName": "Flight of the Bat",
"location": "Gotham City, New Jersey",
"rideType": "roller coaster"
},
"testPerson": {
"sex": "male",
"height": 180
},
"recording": {
"testDevice": "iPhone X",
"testDeviceFixture": "left upper arm",
"testApp": "Physics Toolbox Suite by Vieyra Software"
}
},
"columns": [
{
"columnName": "t",
"columnDescription": "ride time at which measurements were taken upon activating the recording in seconds",
"dataType": "number",
"columnUnit": "sec"
},
{
"columnName": "ax",
"columnDescription": "biomechanical acceleration of the test person on the x axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "ay",
"columnDescription": "biomechanical acceleration of the test person on the y axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "az",
"columnDescription": "biomechanical acceleration of the test person on the z axis in m/s²",
"dataType": "number",
"columnUnit": "m/s²"
},
{
"columnName": "scr",
"columnDescription": "boolean indicating a detected scream of the test person",
"dataType": "boolean",
"columnUnit": "1"
}
]
}We recommend a 15 min break at this point.
You
can use this time to set up the plenary discussion.
Time: 20 min
Implementation:
Display the final JSON object
literals of the different groups next to each other. Allow for some
time, so that the learners can compare the different results and
identify similarities and differences.
Objective:
At this point, the learners should
experience some form of frustration - the metadata is now structured and
machine-readable, yet interoperability and reusability haven’t been
achieved. This frustration is relieved in the next episode
“Enabling Technolgy & Standards”, when schemas and
standards are introduced.
Leading questions:
- What was easy while generating the structured metadata record?
- What was hard? Which points were intensely discussed in the group?
- How did you decide, which information are relevant metadata?
- Which differences do you see between the different JSON metadata records?
- How do you feel after comparing the results?
Creator’s recommendation:
While moderating the
discussion, pay attention to and highlight the following characteristics
of the created JSON object literals:
- (if done correctly) all JSON object literals are valid, functional and machine-readable
- representation of key strings (e.g. camel case vs. snake case, capitalization)
- structure of the JSON object literal (e.g. nested objects vs. flat structure)
- value representation
Plenary result discussion
- What was easy while generating the structured metadata record?
- What was hard? Which points were intensely discussed in the group?
- Which differences do you see between the different JSON metadata records?
- How do you feel after comparing the results?
Key Points
- Markup languages add information to a text that is separated from the content.
-
XMLandJSONare lightweight, hierarchical file formats to store and transfer data. -
XMLandJSONare human readable, software- and hardware-independent
James H. Coombs et al. (November 1987). Markup Systems and the Future of Scholarly Text Processing. Communications of the ACM 30. http://xml.coverpages.org/coombs.html#Note1↩︎
Cynthia Zender (2005). Markup 101: Markup Basics. SAS Institute. https://www.lexjansen.com/pharmasug/2005/Tutorials/tu12.pdf↩︎
XML Tutorial. (C) 1999-2022. Refsnes Data, W3Schools. https://www.w3schools.com/xml/↩︎
ECMA-404 - ECMA International. (2021, February 4). Ecma International. https://www.ecma-international.org/publications-and-standards/standards/ecma-404/↩︎
JSON Introduction. (C) 1999-2022. Refsnes Data, W3Schools. https://www.w3schools.com/js/js_json_intro.asp↩︎