General Lesson Information
Last updated on 2023-11-16 | Edit this page
Overview
| Title | Fundamentals of Scientific Metadata: Why Context Matters |
| Event format | webinar / workshop |
| Environment | online, makes use of breakout rooms (not adjusted/tested in physical setting yet) |
| Scientific discipline | generic |
| Level | beginner |
| Target group | PhD candidates and early career postdocs, little prior knowledge of metadata (annotation), RDM - Bloom Level 1 / 2, participants do not know each other |
| Duration | 430 min learning time, 4 breaks of 15 min |
| Group size | 15 (recommended for 2 - 3 instructors) |
| Prior knowledge | none |
| Required equipment | text editor, web browser |
| License | https://creativecommons.org/licenses/by/4.0/ |
| Creators | See citation file |
thank you for your interest in our training course “Fundamentals of Scientific Metadata”.
On this page, we would like to give you a brief overview of the course material. Detailed teaching instructions can be found in the instructor guide.
This lesson was designed to be taught on two consecutive days, spanning 4 hours a day. A detailed schedule is included in the instructor guide.
Instructor Guide
In the instructor guide, we will provide you with all the detailed information on lesson structure and schedule, additional content, and recommendations necessary to teach this lesson.
Also included in the instructor guide, you can find
talking points for lectures, challenges, live coding and
other content. Lecture talking points contain download links for the
accompanying slide sets. Of course, you are free to use your own slides
and take our talking points as a guideline. All of these
Talking points can also be found in the instructor notes of
the individual episodes.
Examples of talking points: (Additional information for instructors is written in italics)
Group Challenges and Handouts
The challenges 2 - 4 are designed as group work challenges. Challenge 5 can be tackled in a group or individually. We recommend group sizes of 4 - 6 learners that work together in breakout rooms and one instructor or teaching support per group. For these challenges, we prepare handouts for each group in Markdown-based shared documents (e.g. HedgeDoc). These handouts allow for immediate and collaborative work on the challenges. Pre-defined code blocks can be used to collect and discuss the results.
Group handout Markdown: exampleGroupHandout.md (optimised for HedgeDoc)

Example Data
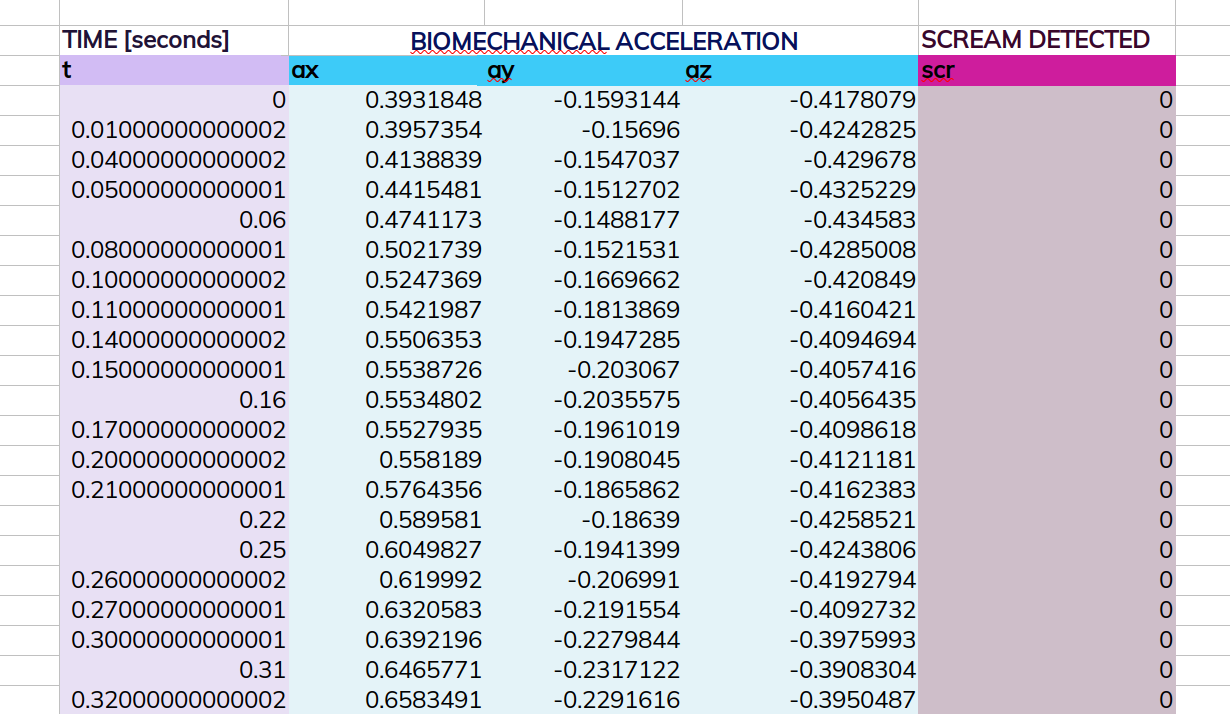
The lesson starts by introducing a barely annotated dataset, which operates as the base of the whole lesson. Throughout the episodes, the learners will gradually be supplied with more information about this dataset, annotate it with the given information and continuously improve the accompanying metadata to improve its findability, accessibility, interoperability and reusability.
This lesson was designed for a heterogeneous group of learners from diverse research areas. Hence, we decided to use a dataset that is unlikely to appear in the scientific context, yet has the possibility to be applied as such.
The attached dataset holds information on the biomechanical acceleration of a human body experienced througout the ride of the roller coaster “Colossus” at Thorpe Park, Surrey, England (you can find more information here).
We added variable names, transformed the time values and added a mock “scream detected” variable with boolean values based on this onride video.
Example dataset: exampleDataObject.csv
Learning Objectives
Our learning objectives follow the model of Bloom et al. (1956) and use the measurable verbs proposed by Stanny et al. (2016).
Episode 0: Housekeeping
In the Instructor guide, we included sections labelled “Episode 0: Housekeeping”. These sections are not directly related to the lesson subject, but are important (to us) for the overall teaching experience. Episode 0 sections include activities like learner warm-ups and feedback and can be found in the detailed lesson schedule.
Lightning Talk
We had very good experiences closing the lesson with a lightning talk that either focuses on the application of structured metadata in research, gives an insight into data annotation with metadata in practice, or demonstrates a recent (scientific) software development in the metadata field. For this section, we usually invite an external speaker and assign 45 min including discussions to the schedule of day 2.
In our 2 day approach, we end at lunchtime on the second day, which allows for extra time for discussions with the speaker. The lightning talk so far got great feedback from the learners.
Get in Touch
You want to contribute to this lesson? Please open an issue in this
lesson’s Github repository:
Github Repository
You want to share your experiences
or have questions on this lesson? You can get in touch with the creators
and maintainers by mail:
HMC@fz-juelich.de
For more information on the Helmholtz Metadata
Collaboration (HMC) visit our homepage:
helmholtz-metadaten.de
We are always happy to connect with fellow instructors, researchers and metadata enthusiasts!