Content from Project management, data science
Last updated on 2023-09-06 | Edit this page
Estimated time 45 minutes
Overview
Questions
- What are the benefits of using data science skills in research project management?
- What are common challenges for research teams and research project management?
Objectives
Understanding what project management and data science entail.
Knowing the next steps to take after this workshop.
In this introduction, we will have an overview of what is meant with project management. Because we will use data science principles to tackle the question of open and reproducible research, we will also define what data science is. Reproducibility is introduced later in the course, while we expect participants to be quire knowledgable in open research. One can refer to the additional content if openness needs a definition.
Project Management in a research context
Discussion
What defines a research project ? What makes two projects in a lab different?
The answer may vary with domain and lab culture, but the main components are very similar to what defines one research publication:
- The vision or specific research question
- The team: different people may be involved inside and outside the lab
- The funding source
- The methods used
Different types of experiments can be part of the same project.
As lab resources are often pooled between project, this means that lab and project management are linked, while being independent.
The research workflow, also known as the research cycle, usually starts with a research idea, via a literature search on what is already known on the subject, to data collection and analysis, to writing, publishing, and the final assessment of a study. Each of these steps in a given research project involves aspects of project management that such as planning, coordination, execution and monitoring of the team, resources (budgets, materials, equipment), and timeliness according to schedule.
Project Design and Planning
It involves defining the project plan which includes the scope, objectives, milestones, and deliverables within the available timeline.
This includes the creation of a timetable or Gantt chart usually created during the grant application.
A great way to visualise the project plan is the Gantt chart, a horizontal bar chart on a time scale, reflecting all of a project’s components, dependencies, and responsibilities. GanttProject and GNOME Planner are two open-source project management applications that allow you to visualise your project plan in a Gantt chart.
Resource Management
It includes managing the budget, allocation of funds to each step over time, and ensuring that deliverables and objectives will be met within the available timeframe.
Team Management
It is the task of making people work together. It includes the definition of the responsibilities for every team member on specific steps and aspects of the research project, task assignments, progress monitoring, and team efficiency measures to thus produce results. It is core in meeting the objectives and goals of a research project.
Research teams often work remotely with team members being located in different parts of the world, and therefore need tools that allow for real-time collaboration, as well as access to process documentation, files, and data to all team members at any given time.
Data Management
The core of every research project, including the collection, organisation, analysis, and secure storing of research data. A Data Management Plan (DMP) is increasingly a necessary component of the project design process and in research proposals, and describes in detail how and where the collected research will be recorded, stored securely, and made accessible for analysis and reuse. Furthermore, the F.A.I.R. Data Principles are equally important to comply with to make research data human- as well as machine-readability to ensure they are findable, accessible, interoperable and reusable, and thus FAIR. We will discuss FAIR data in more detail in episode XX.
Communication and Reporting
Effective communication among team members and project stakeholders (project partners, funders, librarians, publishers, …) to keep everyone updated on the project’s progress. A key component here is the strategic documentation and reporting of the methodologies and any adjustments along the execution of the project. Electronic Lab Notebooks (ELNs) provide a certain amount of interoperability between systems to automate some of the documentation processes, thereby making it easier and more efficient to comply with the FAIR principles.
- ELNs
- Progress reports
Risk Management
It is an assessment and documentation of any foreseeable events that might arise and interfere with the success of the project. and adaption With a S.W.O.T. Analysis as part of the project plan, it is possible to describe strengths and weaknesses of the project idea, and also opportunities and threats that might impact the project through external factors. A thorough risk assessment allows you to make contingency plans to address any challenges or issues should they occur.
Monitoring and Evaluation
Monitoring and Evaluation involves ensuring quality control throughout the execution of the project and the adherence to research policies and procedures, lessons learned and conclusions that can be drawn from the results.
Dissemination
Making research results Findable, Accessible, Interoperable, and Reusable (see again the [F.A.I.R. principles[(https://www.go-fair.org/fair-principles/)) is key to the dissemination plan of a research project. Datasets and code should be archived in standardised repositories (see re3data.org for lists of region- and discipline-specific as well as generalist repositories you can use).
Testimonial
I often manage projects where I do not have decision power. My work usually starts by making sure decisions are taken and documented. The documentation is very important, because the implementation of the decision often requires me to remind people of their decision. Indeed, during the rest of the project, my role consist in monitoring progresses and remind people of the objectives, such that specific work is done at the right time. For instance, a team may well aim for publishing data at the start of a project, but this objective will not be met unless a specific workflow is implemented at the start of the project. My work is then to make sure the researchers are aware of the problems and that they do not take shortcuts that go against the long term objectives.
As a project manager, one needs to make sure the resources are sufficient to achieve the goals set in the plan. In research, it often consists in making sure the people are indeed working toward the goal and are not investing their time to other projects or other objectives of the lab. This is particularly important when short term individual incentives are not aligned with the project long term vision. For instance, data management is primordial in team science, but, too often, data collector cannot recognize its importance.
Project Management tools overview
Several digital project management tools exist that facilitate the remote coordination and management of research teams with their projects. Widely used proprietary examples include Trello, Asana, ClickUp, Notion, and Zoho Projects. Each of these has a different set of features, and all of them work with a Kanban board for process documentation.
Kanboard, WeKan, Open project, and Taiga are examples of open-source project management software that contain Kanban boards.
What is data science
Over the last decade, several tools, methods and training resources have been developed for early career researchers to learn about and apply data science skills in biomedicine. This is often referred to as biomedical data science, with the following definition.
Testimonial
Biosciences and biomedical researchers regularly combine mathematics and computational methods to interpret experimental data. The term “data science” describes expertise associated with taking (usually large) data sets and annotating, cleaning, organizing, storing, and analyzing them for the purposes of extracting knowledge. […] The terms “biomedical data science” and “biomedical data scientist” […] connote activities associated with the creation and application of methods to new and large sources of biological and medical data aimed at converting them into useful information and knowledge. They also connote technical activities that are data-intensive and require special skills in managing the large, noisy, and complex data typical of biology and medicine. They may also imply the application of these technologies in domains where their collaborators previously have not needed data-intensive computational approaches.
-- Russ B. Altman and Michael Levitt (2018). Annual Review of Biomedical Data Science
In contrast to the definition above (and as will be explained in the next chapters), we think research which is not data intensive would also gain in applying data science principles. However, to ensure that data science approaches are appropriately applied in domain research, such as in biosciences, there is a need to also engage and educate scientific group leaders and researchers in project leadership roles on best practices. Computational methods might indeed be as complex as a neural network, but even statistical tests and producing figures for a publication require data science and coding methods.
Researcher use data science skills to apply computation techniques and reproducible data analyses approaches to their research questions. In order to apply these tools, researcher first need to understand and apply the building blocks of data science, especially research data management, collaborative working and project management.

How to apply data science in biology. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
Testimonial
In some instances, it has been argued that “data science” simply rebrands existing fields like statistics or computer science. Our view is that data science has gained traction as an overarching term due to increased data availability and complexity; development of computational methods; advances in computational infrastructure; growing concerns about scientific rigor and the reproducibility of research findings; and a recognition that new advances will result from interdisciplinary research and collaboration. These trends are not unique to data science, but their integration and consolidation under a single term, however broad, reflects an understanding of their interconnectedness and is a real shift in the scientific landscape
- Goldsmith, J., Sun, Y., Fried, L. P., Wing, J., Miller, G. W., & Berhane, K. (2021). The Emergence and Future of Public Health Data Science. Public Health Reviews, 42. doi: 10.3389/phrs.2021.1604023
With new technologies supporting the generation of large-scale data as well as successful applications of data science, Machine Learning (ML) and Artificial Intelligence (AI) in biomedicine and related fields have recently shown huge potential to transform the way we conduct research. Recent groundbreaking research utilising AI technologies in biomedicine has led to an enormous interest among researchers in data science, ML and AI approach to extract useful insights from big data, make new discoveries and address biological questions. As pictured below, in order to apply these tools, researcher first need to understand and apply the building blocks of data science, especially research data management, collaborative working and project management.
Discussion
In what aspects of your projects do you already apply computational and statistical approaches?
Do you consider data science relevant for your project? Why/Why not?
To what extent do you apply data science practices in your research projects? (A) Not yet, (B) Sometimes, (C) In most projects, (D) In every project.
The Data Science for Biomedical Scientists project helps address this need in training by equipping experimental biomedical scientists with essential computational skills. In all the resources developed within this project, we consistently emphasise how computational and data science approaches can be applied while ensuring reproducibility, collaboration and transparent reporting.
In this training material for learning how to manage computational projects, we discuss essential practices for computational reproducibility required for carrying out meaningful analyses of research datasets through data exploration, processing, visualisation and communication. We present unfamiliar and complex topics from computation and data science to biologists by providing examples and recommendations from their fields. The goal is to enable effective management and sharing of their computational projects. We therefore encourage you to go through this training material before taking our second workshop, more focused in AI and Data Science.
Project management in open and reproducible projects
This course aims at giving an overview of project management techniques particularly useful for open and reproducible computational project. This means we will not talk much about risk assessment, and resource management, but focus on team and data management. This has of course repercussion in the project design and planning, the communication and reporting strategy, and monitoring and quality control is at the core of the code management topic.
In this course, we will also present some software that may help to share project management tasks and results in a distributed team.
Some References and resources
General guides
- A Quick Guide to Organizing Computational Biology Projects Noble WS (2009) A Quick Guide to Organizing Computational Biology Projects. PLOS Computational Biology 5(7): e1000424. https://doi.org/10.1371/journal.pcbi.1000424
- Seddighi, M, Allanson, D, Rothwell, G, Takrouri, K. Study on the use of a combination of IPython Notebook and an industry-standard package in educating a CFD course. Comput Appl Eng Educ. 2020; 28: 952– 964. https://doi.org/10.1002/cae.22273
- Mendez, K.M., Pritchard, L., Reinke, S.N. et al. Toward collaborative open data science in metabolomics using Jupyter Notebooks and cloud computing. Metabolomics 15, 125 (2019). https://doi.org/10.1007/s11306-019-1588-0
- The Good Research Code Handbook by Patrick Mineault.
- Guides to Better Science by British Ecological Society.
Relevant turing way chapters
-
The Turing Way. The Turing Way Community. (2021). The Turing Way: A handbook for reproducible, ethical and collaborative research (1.0.1). Zenodo. DOI: 10.5281/zenodo.5671094
Open Life Science training and Mentoring Programme. Batut, Bérénice, Yehudi, Yo, Sharan, Malvika, Tsang, Emmy, & Open Life Science Community. (2021). Open Life Science - Training and Mentoring programme - Website release 2019-2021 (1.0.0). Zenodo. DOI: 10.5281/zenodo.5636584
What is a Registered Report? by JMIR, referencing to Registered Reports by Center for Open Science
Content from Course content and motivation
Last updated on 2023-09-06 | Edit this page
Estimated time 20 minutes
Overview
Questions
- How does this training relate to your work?
- What are the benefits of using data science skills in research project management?
- What are common challenges for research teams and research project management?
Objectives
- Understanding the scope and structure of this course.
- Contextualising computational project management for biomedicine and life science research.
- Knowing the next steps to take after this workshop.
Overview of this training material
This chapter gives you an overview of the topics of this course. It also corresponds to specificity of data science work. They are not treated in the same order as indicated here.
This program will teach you best practices in data science project management and how to appyly them to research project. This material will help you to manage a research project that comprise some online collaborative working, has a relatively big team, where people have complementary skills, use coding or programming, as well as the reuse of code, and last but not least, aim at producing a reproducible analysis, as is pictured below.
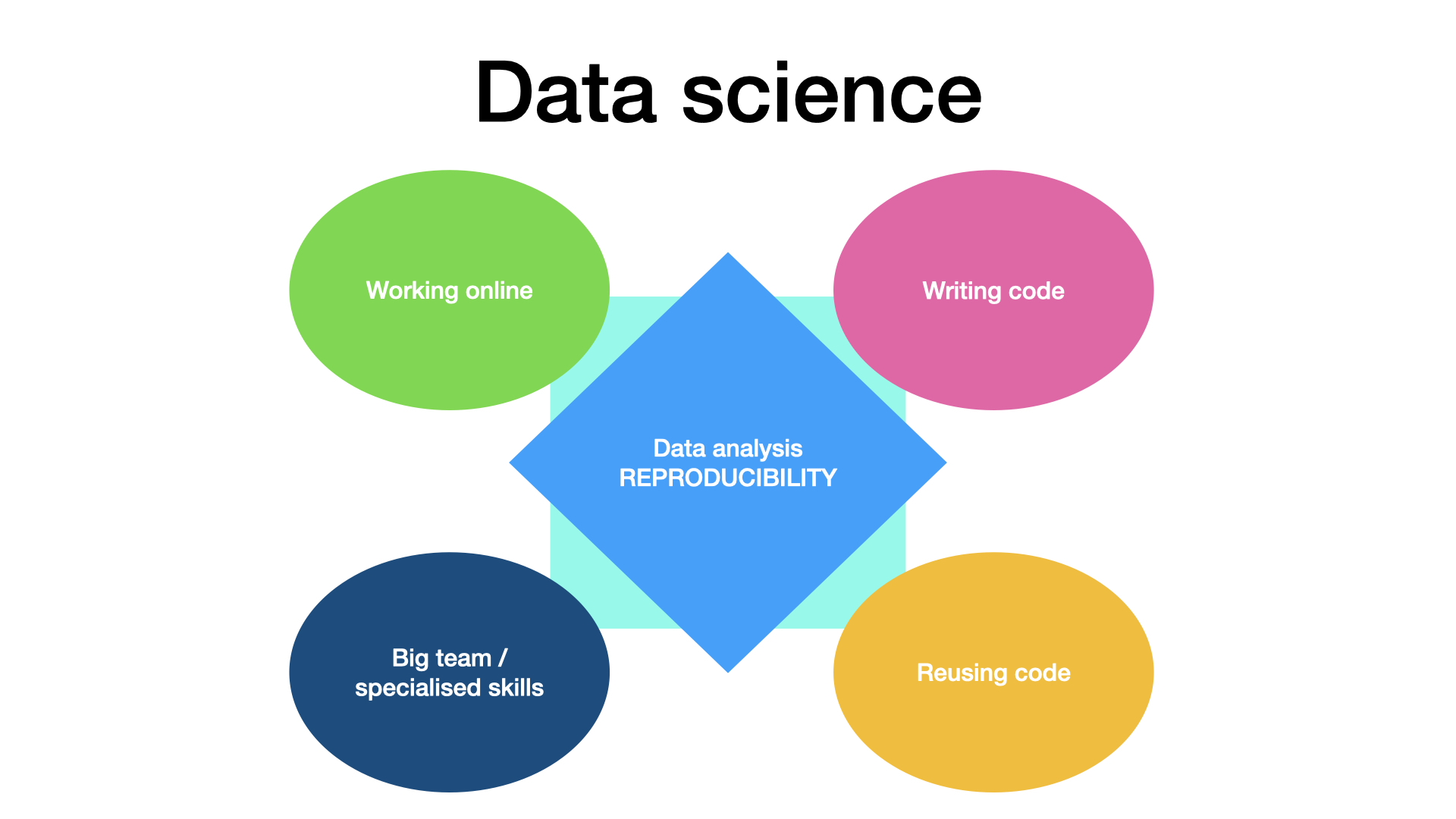
Here we give an short overview of the topics that will be covered in this course. Note that the course episode split follows a different logic, and you will find training linked to each five of these data science specifics in most episodes.
Team and data science
The principles taught in this course can be applied to any research project. It will help project manager to work with online tools, with people with specialised skillsets, and with a project involving some code writing and code reuse. The goal is to produce a reproducible data analysis in modern research context.
It requires some specific and some non-specific project management actions. This course covers a large panel of action to perform before, during and after the project is conducted.
Online work
When part of the work happens online, it becomes very easy to loose track of what documents are where, what tools were used (by whom), and who is doing what. Discussions are also more difficult to organise and meetings are more complex to drive. In this course, we will look at different elements that make this work easier.
Af first, there should be one entry point for the project, where
every team member can find the main documentation as well as links to
other documents and data. This starts with setting
one main URL when setting up the project, as well as using
good readme files and templates. The information needs to be updated
during the project and shared with the whole team.
The use of online project management tool (like kaban boards for todo list) can also help members of the team to coordinate their work, and follow their achievements.
Team science
Because teams can be big, and quite heterogeneous in terms of skills (especially computer and programming skills), it is important to follow best practice of team building.
In particular, one should set reasonable goals and milestones for the project, and document them in the main documentation. It is also important that every team member knows what his part is, and that the work is well distributed.
One should make sure every team member is able to use the communication tools set for the team, and take particular care of the organisation of meetings. Data and code should be documented (and this documentation work should be fostered), such that every team member can follow and reuse the work of the other team members.
Coding
When data analysis is done via a programming language, things become mostly easier, but this facility has some drawbacks, as well as some effects on data management practice.
First, a data analysis workflow will now start with the computer reading the raw data. This means that the choice of the data format for the raw data may change, and that manually gathered data should be (easily) computer readable. This is particularly important for spreadsheets, as a lot of time can be saved by designing the spreadsheet in a tidy format.
Second, statistical analysis and data representation in figures will now be much easier to perform, making p-hacking and harking practices very easy to do, even involuntarily. Researcher have to actively make sure their analysis is not flawed.
Third, making errors in the code may have larger effects than making error in a manual analysis. However, errors are easier to spot (doing code reviews and tests) and when the code is corrected, the results are immediately corrected, too.
Code/data publication and reuse
Very soon in a research project, writing code consist mostly of taking code written by someone else and applying it (with some tweaks sometimes) to one own data. We will look at ways to find relevant code, make sure it can be trusted, make sure you can legally use it, and ways to cite it (to give recognition the initial software engineer deserves).
In addition, code written in the project will probably be reused, too. We will look into best practices to make this reuse easier, both in how the code is written (modularity, documentation, tests) and in how the code is shared (license, repository, version control, release, users instruction, developers instructions).
Reproducibility
At the core of data science, the analysis reproducibiliy is both a goal and a huge advantage (in terms of research transparency, trustworthiness and work efficiency). The use of code is not enough to get a reproducible analysis, one needs to have access to both the code and the data used to produce the research result, a concept called provenance. This may not be trivial, especially if several version of the code and of the data exist.
In this course, we will have a strong emphasis on version control, while we will introduce the concepts (and some tools) of provenance, as well as literate programming (reproducible reports and executable papers), where the code, the figure and explanatory text are bound in the same file.
Your research project is a computational project.
This chapter about motivation can be used to convince people to sign up to the course. It can also be used as a small starter for each lessons.
As a researcher, you are likely to use some sort of computational tools to process, analyse, and visualise data. You are also likely to work on your project with other members of the lab, and the success of your work may well depend on your interactions with your peers. In that sense any research project can be defined as a collaborative, computational project.
We all may have dfferent research and data science expertise. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
Contents of this training material introduces methods and concepts to manage individuals and teams working on any computational project, which in the current era is literally all research projects. It is not about learning how to write code, but building a foundational understanding for computational methods that could be applied to your research. Furthermore, this training will provide guidance for facilitating collaboration and data analysis using tools like research data management, version control or code review.
We acknowledge the data science knowledge will vary. Nonetheless, we believe that the data science skills you will learn in this training will make your research process better. In the following sections, we will detail what we mean by “better”.
How data science will improve your research ?
Data science makes research flourish. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
It is mostly about being efficient
Data science brings some structure in how data is collected, processed and analysed, making it easier to collaborate on a project, to publish extra research outputs and leveraging some extra potential your data may have. In the past, it helped me drive new hypotheses, detect problems with the research design early, and reduce the sample size needed to drive a solid conclusion. Eventually, it made my research more robust and trustworthy. But in the end, my real motivation is efficiency: very soon, the time I invested in learning and applying data science in my research was recovered multiple times when a manuscript had to be written (and re-written).
There are different ways to organise the different foreseen improvement, we decided here to start with improvement in the final result, improvement in the research process, and finally aspects of community building.
Using code for nicer paper
Powerful statistics
The most advanced statistical methods (like machine learning) are first developed in programming environment, and they are often difficult or impossible to implement in statistical software. In addition, some of the less advanced statistical methods requires intensive data processing that makes it very difficult to apply outside a coding environment.
Examples
- logarithmic.net/langevitour/2022-useR/#2 to explore orthonormal projections of high dimensional data.
- Results of water maze behavioural tests are better analysed using a survival analysis than an Analysis of variance (ANOVA). However, the data obtained via video analysis software is often not fitted for that analysis and needs to be transformed. Doing transformations by hand is time consuming and is likely to introduce errors.
Example’s references
- See Jahn-Eimermacher, A., Lasarzik, I., & Raber, J. (2011). Statistical analysis of latency outcomes in behavioral experiments. Behavioural Brain Research, 221(1), 271–275. doi: 10.1016/j.bbr.2011.03.007
- For water maze experiment analysis, see: Maugard, M., Doux, C., & Bonvento, G. (2019). A new statistical method to analyze Morris Water Maze data using Dirichlet distribution. F1000Research, 8(1601), 1601. doi: 10.12688/f1000research.20072.2.
Informative (and inclusive) figures
Once you start using code for analysing your data, it will become much easier to do complex and informative visualisation. This often includes way to visualise and label single data points, or use visualisation on several dimensions (producing moving gifs of a 3D scatterplot for instance).
One can also automate the figure design choice, so that all figures look similar. Similarly, the production of several version of the same figure is very easy. For example, one can use different color pallette, one using the palette usually used in the field (the one your supervisor wants to see), and one for color-blind readers.
Single flights from different bees.
See a good example of data representation in differen format single flights from different bees shown in supplemnentary data: Menzel, R., Greggers, U., Smith, A., Berger, S., Brandt, R., Brunke, S., …Watzl, S. (2005). Honey bees navigate according to a map-like spatial memory. Proceedings of the National Academy of Sciences of the United States of America, 102(8), 3040. doi: 10.1073/pnas.0408550102
Reproducible analysis
Good scientific practices are aiming at securing the robustness and reproducibility of the scientific endeavour. As a researcher, assuring computational reproducibility of your results is a relatively easy step in making your research more robust.
What to expect in your reproducibility journey. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
The reproducibility of an experiment not only requires a detailed description of the methods and reagents used, but also a detailed description of the analysis performed. The ultimate description of the analysis is to provide all elements necessary for reproducing the analysis (computational reproducibility). This includes the data and the code used to analyse it (in a form that can be reused in a different computational environment).
Callout
In practice, sometimes one may not be able to provide all elements openly (for instance, some medical data cannot be shared openly for privacy reasons) for everyone to be able to reproduce all the results. But co-workers (and maybe reviewers) should be able to reproduce the analysis (e.g., on anonymized data).
The emergence of reproducible reports is another aspect of computer reproducibility. Literate programming using Jupyter notebooks, Rmarkdown, stencila or quarto (tools that can usually use Python, R, or Julia) is indeed growing in popularity. These tools allow you to show data and analysis side by side, with written explanations and interactive visualisations. These outputs can not only be used as blog posts, or lab reports, but can also be published as an enhanced publication, a concept called executable research articles: https://gmaciocci.medium.com/list/the-evolution-of-executable-research-articles-823e42a9fa60
Diversifying research outputs
While the main recognition currency in academia is still (first) authorship in peer reviewed publication, new scientometrics are developed to recognize publication of other research outputs. In particular, datasets and software publication are officially reviewed in the evaluation of certain grant, for example for the Marie-curie european program. Data science principles will make it easier to publish datasets, software, reagents or hardware you are anyway producing during the research process.
Computational tools you produce in your lab can be released as open source software and credit will be given globally. This may also be true for hardware you design (this aspect will not be discussed in this training) or datasets you collect.
Improved Research Process
Data quality
Did you know that manually copy-pasting data is one of the primary source of data corruption ? Combining datasets or processing data (such as cleaning or transforming into different formats), can therefore be best achieved using code. The process is not only safer, but it is often faster.
Another underevaluated issue is the amount of data you will collect. The more data you have the more sophisticated tools and workflows you may need. It is also more likely that your data (or code) gets corrupted, mixed up, outdated, or lost. In particular, when something goes wrong during the experiment, code might be used to create warnings, so that the setup or protocol may be modified on the fly or between sessions.
Reproducibility and automation
While we already mentioned the advantage of reproducibile analysis for the quality of the research, we did not mention how useful this is during the research. With reproducible analysis, it is effortless to run a new dataset in the analysis workflow, it becomes possible to explore the data at a single experiment level, which may enable new hypotheses, or spot issues that were not foreseen in the experimental design. It makes also certain that difference in the figures are due to difference in the dataset, not any manual processing of the data one may have forgotten to docuzment.
Collaborative working
Within science teams, group work is critical for experimental design and implementation. In addition, there are rapid developments in how scientific results and methods are shared, and collaborations have never been more global or rapid. This means that several people will likely be working with the same data files.
Data science allows for the management of how one or multiple people work on the same project (as well as the same code). It requires different skillsets than those taught in traditional science courses or a typical coding class.
Who can add to your research?
Facilitating communication and sharing will make it easier for your colleagues to help you. Can you think of people who can help you in your research, directly in your lab or at your institution ? Would it help for them to have access to your data? How could they participate, and how can you give them credit?
It is very interesting to consider your future self as one collaborator in your project. Anything you may forget in the next three to five years should be documented, if you want your future self to be able to (re-)analyse the data you are collecting. Indeed, the advantage of working collaboratively in a project can indeed be translated directly in a project you drive mostly alone.
Efficiency
Callout
The time invested in your data and code will be paid multiple times by the efficiency improvement in your workflow, if that investment is done early in the project. Because one can consider your past self as one of your collaborator, the advantage of working collaboratively in a project can indeed be translated directly in a project you drive mostly alone.
At this point, you may be convinced that the extra work of designing your project using data science principles will be worth it. But here comes the best argument of all: in the end you will save time. Early time saving comes because your future self and collaborators will be able to find all your data, reuse and modify your code, and understand your research faster.
This applies directly to the example of working on article revisions - will you still remember all the analysis details and data nuances when your papers comes back with a request for major changes? For instance, if a colleague cannot find what data goes with which figures, there are high chances that you will also be unable to find it three years from now. In addition, itt is not uncommon to modify the design of the figures multiple times (sometimes back and forth), often modifying all figures at once.
Redoing all figures in minutes
Once a reviewer ask me to overlay individual data points onto all our 5 boxplots figures. The project was an old one, and I had not touched the data for years. Finding the right data and redo the all 5 figures would usually take ages using SPSS or excel. But since I used code, I had all figures 15 minutes later. (Note, after seeing the new figures, the reviewer agreed that the original version was better).
Later on in the project, community advantages are coming in. Data and code reusability is not only a mark of research transparency and robustness, it also means you can reuse your own code and data. It also means you can reuse code and data produced by other researchers.
The snow ball effect may be huge, and the objective of this course is to allow you to do better science in less time
Invest in data science
As an example it was estimated that research data management takes about 5% of your time, on the other hand, time lost due to poor data management is estimated to be 15%. See reference: Lowndes, J. S. S., Best, B. D., Scarborough, C., Afflerbach, J. C., Frazier, M. R., O’Hara, C. C., Halpern, B. S. (2017). Our path to better science in less time using open data science tools. Nature Ecology & Evolution, 1(0160), 1–7. doi: 10.1038/s41559-017-0160
Team and community building
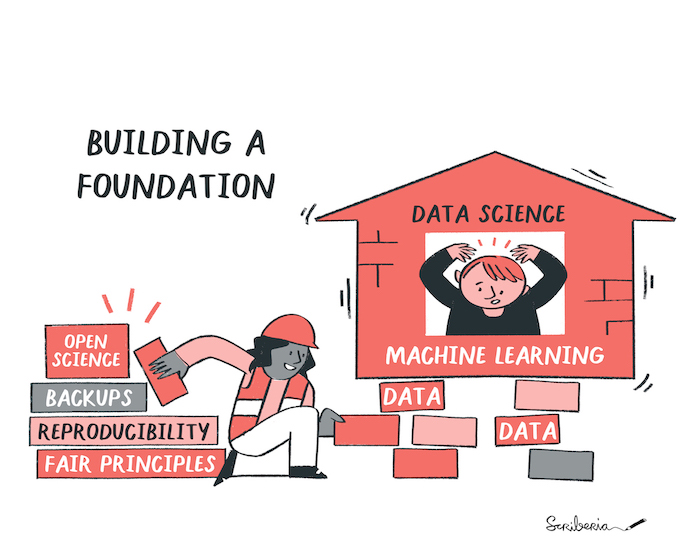
Data science foundations. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
Data science tools will make it easier not only to collaborate with researchers in your lab, but also with researchers outside of your lab, or even with non-researchers (citizen science or software professionals). These may bring valuable expertise in the project. Being part of a collaborative community will also create impact beyond citations and papers, something which starts to be valued by funding agencies, and which make research more fun, valued and interesting.
We may also add to the pot that creating a network around your research is a critical aspect of building a career in academia. Being known as a good and skilled collaborator can open doors to many opportunities.
A journey starts
You step into the Road, and if you don’t keep your feet, there is no knowing where you might be swept off to.
J.R.R. Tolkien, The Lord of the Rings
This training will give you some starting points, but implementating data science principles is a long and always renewed process. But you do not need to do it all at once, and you do not need to do it alone.
After the training, do not hesitate to join (or create) a community of like-minded researchers where you live (there are always some if you look). In addition, there may be people at your institution whose job is to help you. Look for data steward or data managers, research data engineers, IT support, open science büros at your institution and be pro-active contacting them. There are also almost endless online resources and helpful communities. For instance, The Turing Way guide for data science and research provides several detailed chapters to cover topics across reproducibility, project design, collaboration, communication, research ethics and community building.
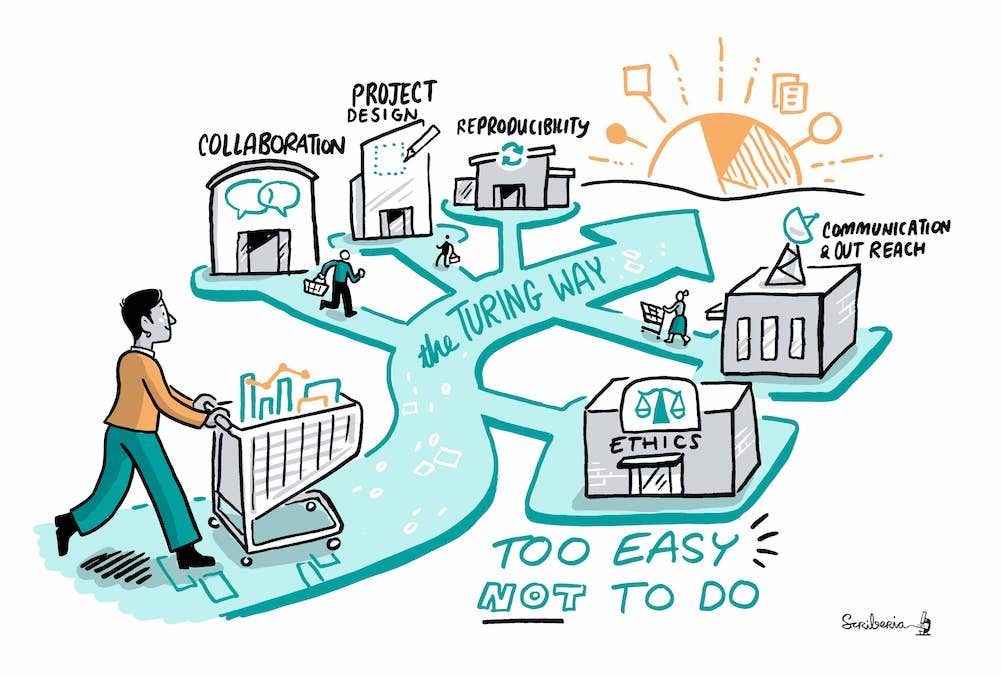
The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
Keypoints
The course provides an introduction to Managing Open and Reproducible Computational Projects to senior biomedical researchers, in order to equip them with tools and techniques to generate and document and manage complex reproducible computational projects.
Without going into underlying technical details, the contents provide a general overview and present selected relevant biomedical case studies.
Content from Ensuring reproducibility
Last updated on 2023-09-06 | Edit this page
Estimated time 25 minutes
Overview
Questions
How to build reproducible analysis?
how to deal with dependencies?
What is version control?
Why using git ?
How is version control system relevant for biomedical research?
Objectives
- Understand the different concepts related to reproducibility.
- Learn about methods to capture reproducible research environments.
- Understand the concept of provenance and version control.
- Understand the power and pitfalls of Git
What is computer reproducibility
Documentation as a guiding light for people who may feel lost otherwise. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
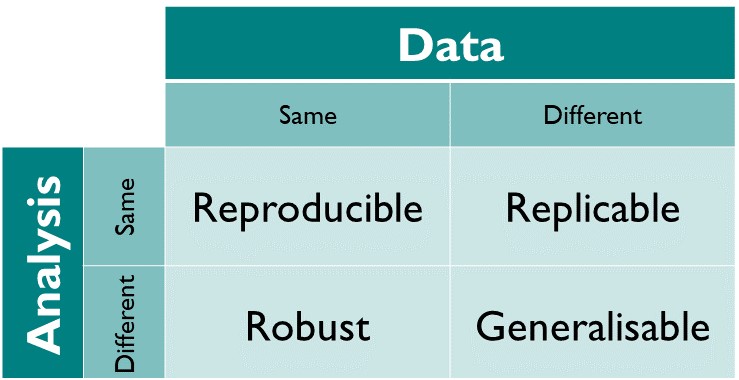
The different dimensions of reproducible research described in the matrix above have the following definitions directy taken from The Turing Way Guide to Reproducible Research (see the oveview chapter):
- Reproducible: A result is reproducible when the same analysis steps performed on the same dataset consistently produces the same answer.
- Replicable: A result is replicable when the same analysis performed on different datasets produces qualitatively similar answers.
- Robust: A result is robust when the same dataset is subjected to different analysis workflows to answer the same research question (for example one pipeline written in R and another written in Python) and a qualitatively similar or identical answer is produced. Robust results show that the work is not dependent on the specificities of the programming language chosen to perform the analysis.
- Generalisable: Combining replicable and robust findings allow us to form generalisable results. Note that running an analysis on a different software implementation and with a different dataset does not provide generalised results. There will be many more steps to know how well the work applies to all the different aspects of the research question. Generalisation is an important step towards understanding that the result is not dependent on a particular dataset nor a particular version of the analysis pipeline.
Provenance and reproducibility
In order to make results reproducible, one needs to access and reuse the data and the code used to produce the analysis. Since both code and data may evolve over time (errors may be found, variables may be changed), it is important to link the figure created with a specific version of the code and the data, this is called keeping provenance information.
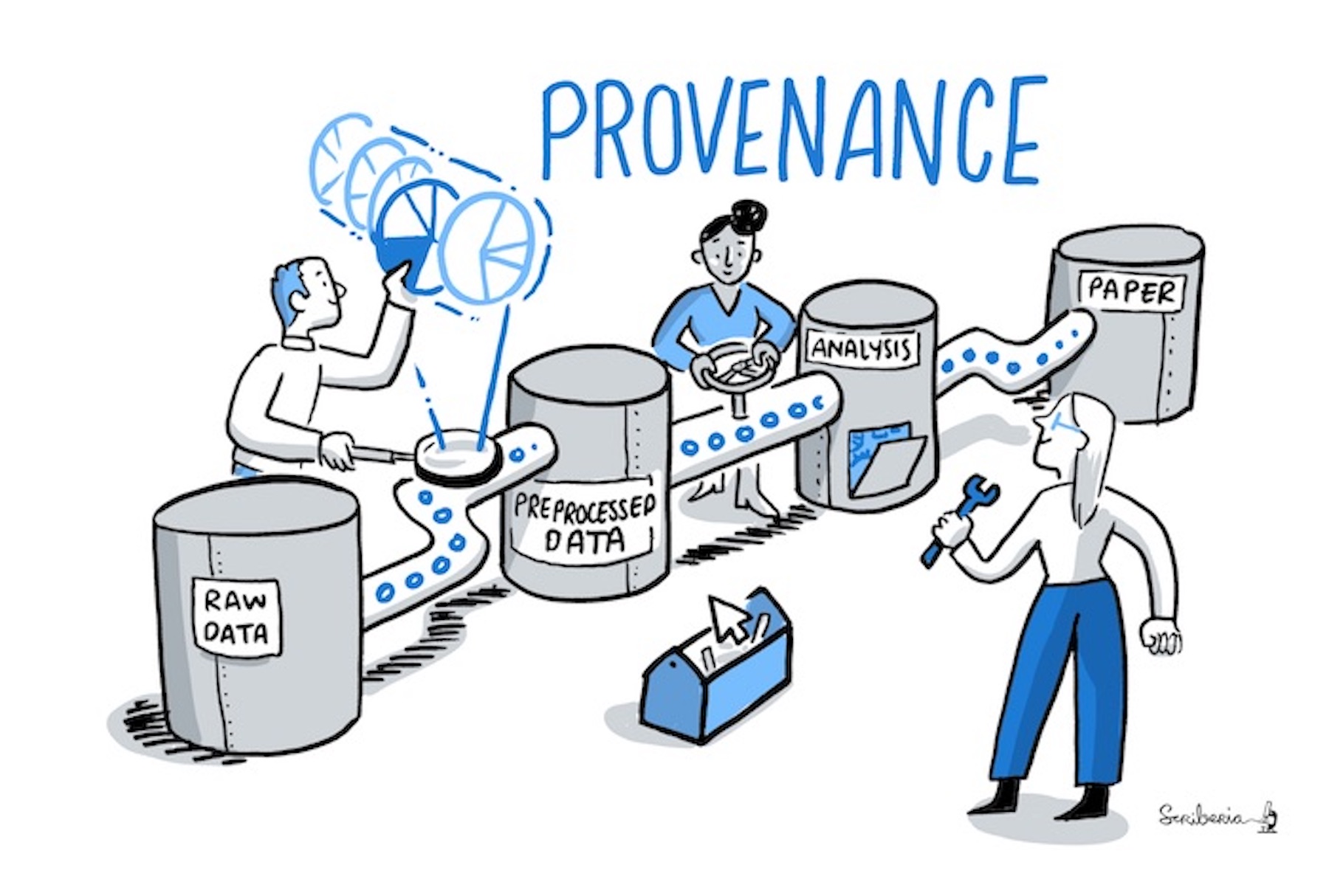
Long term reproducibility
Both data and software should be in a form where the analysis can run on a different hardware. Because software evolve quite rapidly, it may be difficult to have the analysis run years after its creation, because the dependencies will have evolve and may not be compatible with the old code anymore.
It is therefore important to know what version of the dependencies were used. In practices, there are specific tools to record dependencies, and for complex code, it is preferable to use countainers. Containers are specific piece of software that “contain” all the information and dependences needed to run a code.
Alternatively, one can aim at robustness and document the analysis enough such that adapting the code to a new computer environment is easy. This may be a easier workflow for simple analysis.
Thinking about which software, tools and platforms to use will greatly affect how you analyse and process data, as well as how you share your results for computational reproducibility. The idea is to facilitate others in recreating the setup process necessary to reproduce your research.
Some tools that can be used to enable these are the following:
- Dependency managers such as Conda keep dependencies updated and make sure the same version of dependencies used in the development environments are also used when reproducing a result.
- Containers such as Docker is a way to create computational environments with configurations required for developing, testing and using research software isolated/independent from other applications.
- Literate Programming using Jupyter Notebook is an extremely powerful way to use a web-based online interactive computing environment to execute code and script while adding notes and additional information about the application.
Reproducible Research Environment
Researchers’ working environments evolve as they update software, install new software, and move to different computers. If the project environment is not captured and the researchers need to return to their project after months or years (as is common in research), they will be unable to do so confidently.
This includes features of hardware (such as the numbers of cores in any CPUs) and features of the software (such as the operating system, programming languages, supporting packages, other pieces of installed software, along with their versions and configurations).
To learn more about how to create a reproducible environment, the chapter on Reproducible Environments in The Turing way is a good place to start.
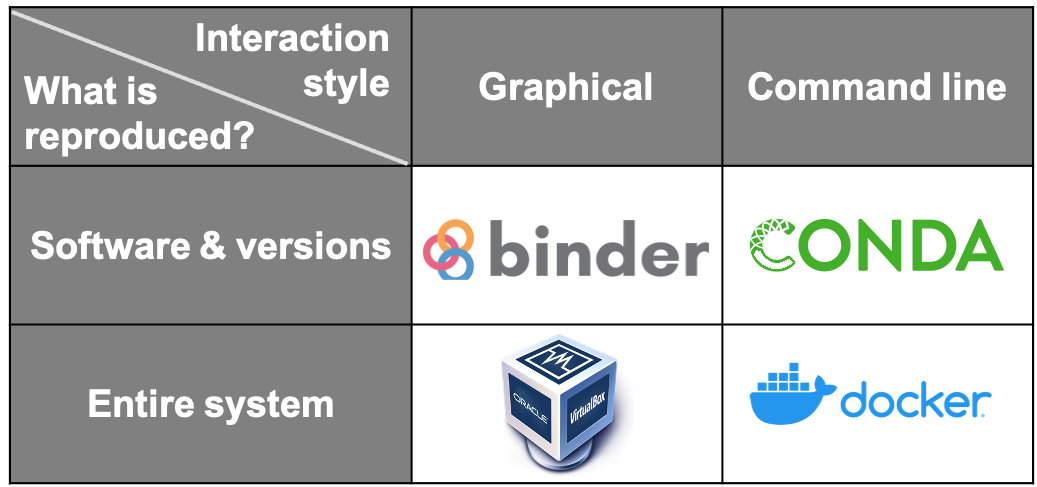
There are several ways of capturing computational environments. The major ones covered in this chapter will be Package Management Systems, Binder, Virtual Machines, and Containers. Each has its pros and cons, and the most appropriate option for you will depend on the nature of your project. They can be broadly split into two categories: those that capture only the software and its versions used in an environment (Package Management Systems), and those that replicate an entire computational environment - including the operating system and customised settings (Virtual Machines and Containers).
Another way these can be split is by how the reproduced research is presented to the reproducer. Using Binder or a Virtual Machine creates a much more graphical, GUI-type result. In contrast, the outputs of Containers and Package Management Systems are more easily interacted with via the command line. Please read more about each of these concepts and their practice use, please visit Capturing Computational Environments in The Turing Way.
Maintaining History through Version Control

Version control allows tracking of history and go back to different versions as needed. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
Practices and recommendations described in this lesson are applicable to all areas of biomedical research. What can be considered slightly different in computational projects is that every object required to carry out the research exists in digital form: starting from research workflow, data, software, analysis processes, outcomes as well as how researchers involved in the project communicate with each other. This means that research objects and workflows can be organised and maintained without losing its provenance or missing knowledge of how each of these objects is connected in the context of your project.
Versioning Every Research Object
Management of changes or revisions to any type of information made in a file or project is called versioning. Version Control Systems (VCS) are platforms and technical tools that allow the recording of any changes made over time in a file or research object. All collaborators on a research project can track file history, review changes made, track and fix errors when they appear, and revert or go back to earlier versions. It is therefore easy to monitor contributions and give appropriate credit to all contributors.
Different VCS can be used through a program with web browser-based applications (such as Google Docs for documents) and more dynamically for code and all kinds of data through command-line tools (such as Git) and their integration into the graphical user interface (Visual Studio Code editor, Git-gui and gitkraken). The practice of versioning is particularly important to allow non-linear or branched development of different parts of the project, testing a new feature, debugging and error or reusing code from one project to different data by different contributors.
GitLab, GitHub, or BitBucket are online platforms that allow version-controlled projects online and allow multiple collaborators to participate. Different members can download a copy of the online repository (most recent version), make changes by adding their contributions locally on their computer and push the changes to GitLab/GitHub/BitBucket (a new version!) allowing others to build on the new development.
Read All you need to know about Git, GitHub & GitLab on Towards Data Science and version control in The Turing way for more details on workflow, technical details of using git and versioning large datasets.
Basics of Version Control
We have all seen a simple file versioning approach where different versions of a file are stored with a different name. Often, files are getting a number suffix that grows with the version number (v001 to v999 for example). When many version exists, it is useful to store old version in a subfolder and keep a record of what has changed in each version. Git is a tool that automates that process. As explained below, Git uses repositories to handle collaborative working, but is not a real-time collaborative tool.
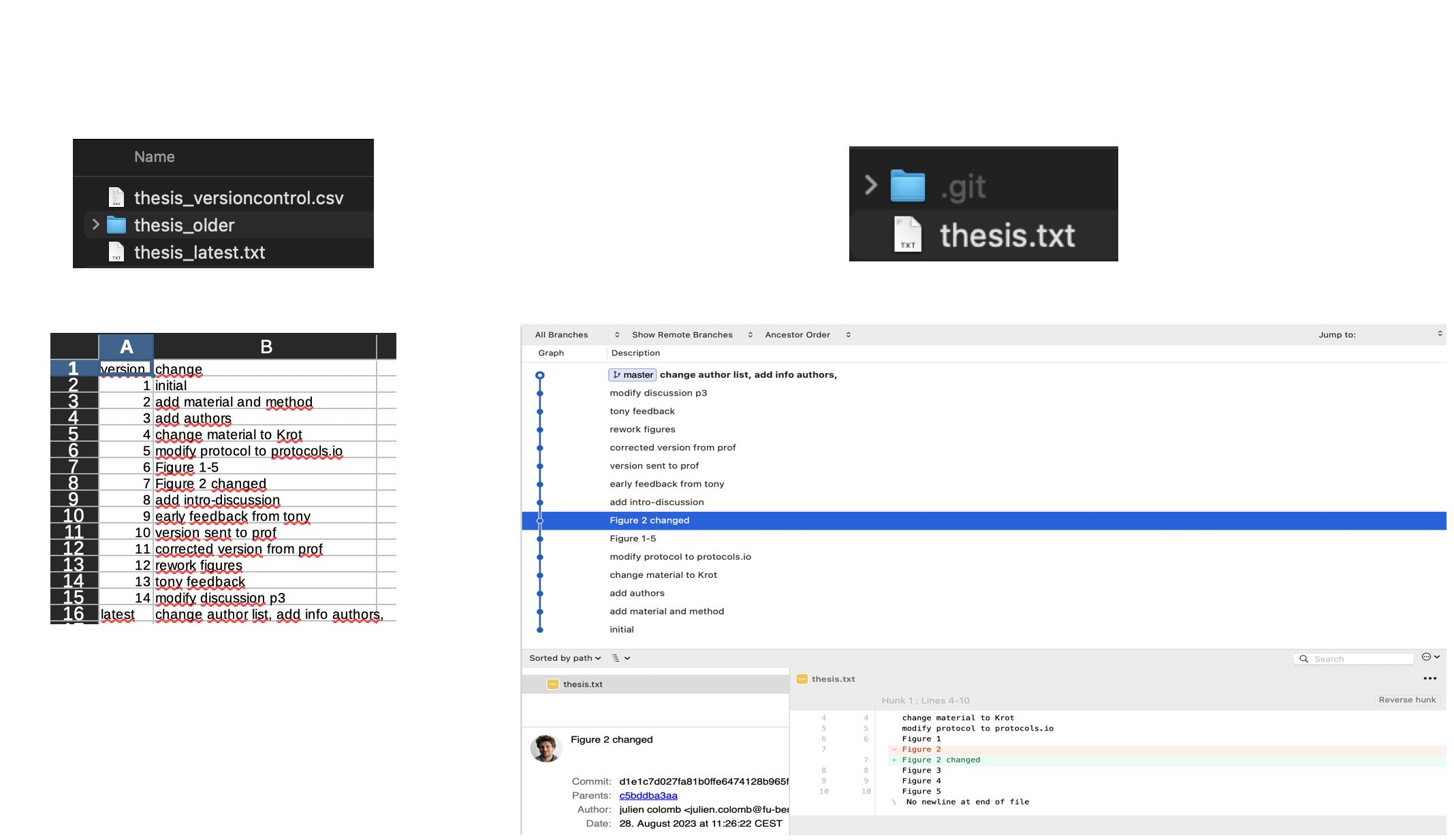
Tools such as Google Drive and Microsoft Teams offer platforms to share and edit files with others in real-time, collaboratively. More sophisticated VCS exists within tools like Google docs or HackMD. These allow collaborators to update files while storing each version in its version history (we will discuss this in detail). Advanced VCS such as Git and Mercurial provide much more powerful tools to maintain versions in local files and share them with others.
Web-based Git repository hosting services like GitLab and GitHub facilitate online collaborations in research projects by making changes available online more frequently, as well as enabling participation within a common platform from colleagues who don’t code. With the help of comments and commit messages, each version can be annotated with the changes it contains compared to the previous versions. This is helpful when we share our analysis (not only data), and make it auditable and reproducible - in accordance with good scientific practice. In the next chapters, we will discuss version control for different research objects.
You can read more details in Version Control and Getting Started With GitHub chapters in The Turing Way.
Git, data and provenance
As explained in The Turing Way ebook, Git does not work well for large or many files, and therefore are not well suited for large datasets, presentations or posters. In order to keep these under Git version control, it is often necessary to use e.g. Git-annex and submodules. DataLad is a great tool to use on top of git to manage and collaborate on large datasets.
Git and contribution record
By using Git for version control, the system will record what was changed by whom in a repository. This may facilitate the record of contributions, but one needs to be aware of the technical bias it creates (importance of contributions cannot be recorded by size or number of commits, less technical contributors will have less Git contribution). The Contributor Roles Taxonomy CRediT is a good way to specify and acknowledge contribution by the people involved and can be easily used with the web-based app and R package tenzing .
Keypoints
Git is a software developed to facilitate version control of text files
Version controlled repositories help record different contributions and contributor information openly.
Discussion
Which of the reproducible research principles are you already implementing in your work and how?
How do you currently version control your projects? What changes will you introduce to ensure fair credit and citation of your and your team’s work?
What are other measures to ensure reproducibility in your research documentation and that of your team?”
Content from Managing project start and collaborations
Last updated on 2023-09-06 | Edit this page
Estimated time 75 minutes
Overview
Questions
How to set up a computational project?
What main concerns and challenges exist and how to address them?
How to create a project repository for sharing, collaboration and an intention to release?
What extra tools may be used ?
How to manage and oversee tasks and track progress of your projects?
How collaborative practices help ensure code quality, testing and reuse?
What is literate programming and how does it help with early communication, testing and collaboration?
Objectives
Describe best practices for setting a project repository
Build a basis for collaboration and co-creation in team projects
Plan computational reproducibility and project management practices
Make it easy for each contributor to participate, contribute and be recognised for their work
Demonstrate GitHub Project Board to enable project management.
Setting up a Project
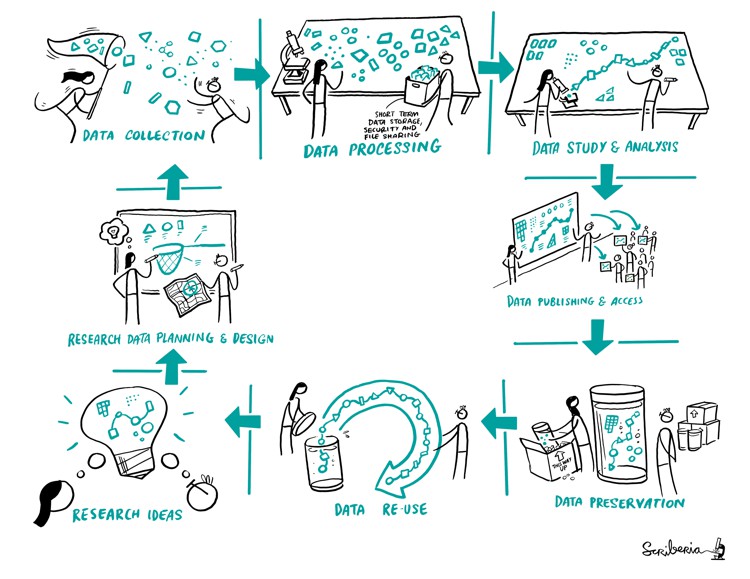
Research Lifecycle. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
A research project starts right with a research idea. We start by communicating that with other researchs in our team. Then come the following steps:
- planning and designing the research work
- describing the research protocols
- deciding how data will be collected
- selecting methods and practices for processing and wrangling data
- conducting our studies and analysis
- publishing all the research objects so everybody can access it
- archiving it to ensure that our research is reusable, meaning, that someone else can go through this whole process of reproducing or building upon our work.
Each of these steps is important for every single researcher, irrespective of their roles in the project. They are usually not taken one after the other, but concomitantly, it is therefore important to plan and take decisions for each of them before the project starts. However, a project lead (such as Principal Investigators, managers and supervisors) have an added responsibility to set up the project in a way that ensures that all members of their research team can work together efficiently at all stages of the project.
With an overarching goal to maintain research integrity and ethical practices from the start, we need to consider reproducibility methods, collaborative approaches and transparent communication processes for the research team as well as the external stakeholders. As project leads, managers and team organisers, it is crucial to be deliberate and clear about the tools and platforms selected for the project, as well as expectations from each contributor from the beginning. Dedicating some time in thinking through and documenting the setup of a project saves time, ensuring successful implementation of research plans at different stages of research. At this stage, you can’t be sure that everything will always go as planned or there will be no unexpected challenges, but it helps prepare in advance for risk management and adapt to changes when needed.
Main Concerns and Challenges
Scientific results and evidence are strengthened if those results can be replicated and confirmed by several independent researchers. This means understanding and documenting the research process, describing what steps are involved, what decisions are made from design to analysis to implementation stages and publishing them for others to validate. Research projects already start with multiple documents such as project proposal, institutional policies and recommendations (including project timeline, data management plan, open access policy, grant requirements and ethical committee recommendations), which should be available to the entire research team at all times. Furthermore, throughout the lifecycle of a project we handle experimental materials such as data and code, refer to different published studies, establish collaboration with others, generate research outputs including figures, graphs and publications, many of which undergo multiple versions. Then there is a general need to document the team’s way of working, different roles and contribution types, project workflows, research process, learning resources and templates (such as for presentation, documentation, project reporting and manuscript) for your research team.
If not planned in advance, these different kinds of information related to the project can become challenging to record, manage or retrieve – costing precious time of everyone involved and negatively affecting collaborative work in your research team.
A good start
In addition to ensuring effective development and collaboration during the lifetime of the project, a well-organised project also ensures sustainability and reusability of research for both the developers and future users more dynamically. But it all comes to implement the tools planned in the setting up phase. One may need to iteratively modify the plan and include different tools if the team changes or grow. This aspect is discussed in detail in the Research Data Management episode.
Challenge
- Create a project on GitHub
- Create a Github account at https://github.com
- Go to https://github.com/tonic-team/Tonic-Research-Project-Template/
- Click
Use this templateand follow instructions.
NB: You can use that template on other git platforms.
Change the
reamde.mdfile directly on the browser: enter information about the project, commit with a message. Enter information about the team (roles and responsabilities), commit with a second message.Look at the history of the readme.md file, understand the need for good commit messages.
Keypoints
- Shared repository with well structured and organised files are crucial for starting a project
- Documentation is as important as data and code to understand the different aspects of the project and communicate about the research.
- Licencing and open science practices allow proper use and reuse of all research objects, hence should be applied in computational research from the start.
In order to indroduce kanbans, one can use different tools. We used miro to both collect feedback and introduce kanbans. Then we had a practical section with a mix of demo and hands-on using https://next.forgejo.org/. We choose that tool because it is a particularly not well known open source alternative.
Project Management Tools
In the previous chapters, we have already discussed practices that enable the effective management of projects in:
- setting up shared resources;
- defining the vision, mission and roadmap of your project;
- managing data and other research-related resources; and
- versioning and tracking progress.
It is important to communicate tasks and responsibilities to different stakeholders of the project. However, what is even more important is to allow all members to understand where in the entire project their tasks fit and how they can track the progress of the entire project.
Gantt charts
Gantt charts are timeline views of the project plan. It defines which task should be done (and finished) at which time (and by whom). Some advanced tools allows to visualise dependencies between tasks. It is an important tool to stay on track or redefine priorities when milestones are not met in time.
Kanban
Kanban provide a visual overview of the tasks, their status (to do, in progress, done) and the people responsible for them in a columnar form. While physical boards and post-it (of different colors and forms) are often used, these tasks can be visualised on a digital board where different columns can present different statuses, different task groups or priorities.
It is also a tool to focus the work on a few tasks. Indeed the “in progress” tab should only contain 1-3 elements per team member, so that one finish one task before starting a new one. Kanban can also be used to communicate what is in progress to other team members and coordinate the work.
Some tools that are popular among research community is Asana, Trello, Todoist and Notion.
The majorities of Git repositories have advanced features like embedded kanban systems, allowing some automation of cards movement and links between task management and data storage.
Git repositories for Project Management
Similar features on GitHub, GitLab, Codeberg or GIN can be used for project management. The following section takes GitHub as an example, but most of this can be applied in other platforms.
Issue is a GitHub integrated feature that allows everyone to track the progress on GitHub. Similar to a ‘To-Do List’, issues can be anything from a project milestone (releasing an R package, submitting to an online data repository, a working simulation) but also specific issues with code (fixing a bug, adding a function, updating tests).
Based on the tasks described in an issue, your collaborators can address them and save or ‘commit’ changes in their local copy of the repository. Local changes then can be ‘pushed’ to the repository on GitHub for ‘review’ via the Pull Request feature. Once a pull request is opened, different collaborators can discuss and review the potential changes and add follow-up commits before those changes are ‘merged’ into the main repository.
Project boards are kanban-like features on GitHub that help you visualise (list of tasks), categorise (in columns) and prioritise (drag/move around) different tasks. A collection of project boards can be created for a different set of tasks, comprehensive roadmaps, or even release checklists. By linking issues and Pull Requests, project boards can create workflows. The Project board shows metadata for issues and pull requests, like labels, assignees, the status, and who opened it. Additional notes within columns can be added as task reminders, references to issues and pull requests from any repository on GitHub.com, or to add information related to the project board. This Kanban board feature can be very helpful in getting a snapshot of multiple research projects within a team/lab and tracking what multiple people are currently working on. You can read more about Project Board in GitHub Documentation.
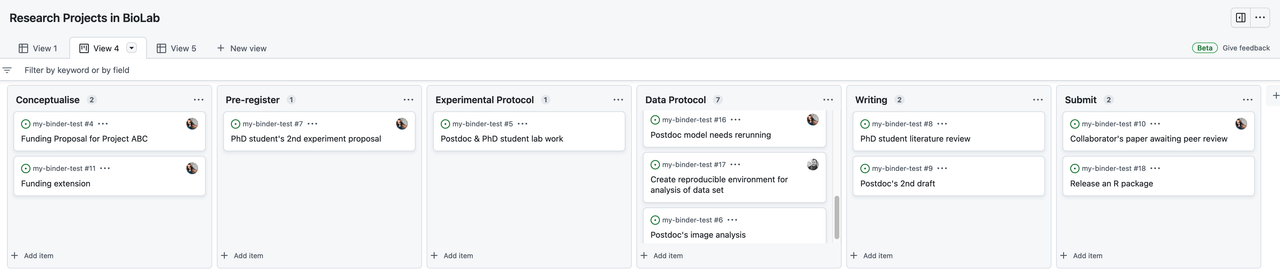
An example is Kanban for researcher project management. GitHub boards can be given any name.
Within Github, the Projects Tab can provide a board with cards to organise issues collaboratively. If a team is already working within Github, this can be beneficial as everything remains in the same place. “Issues” can be used as a record of ToDos or others flagging up bugs and features that need to be addressed. They can be attached to particular repos and assigned to people.
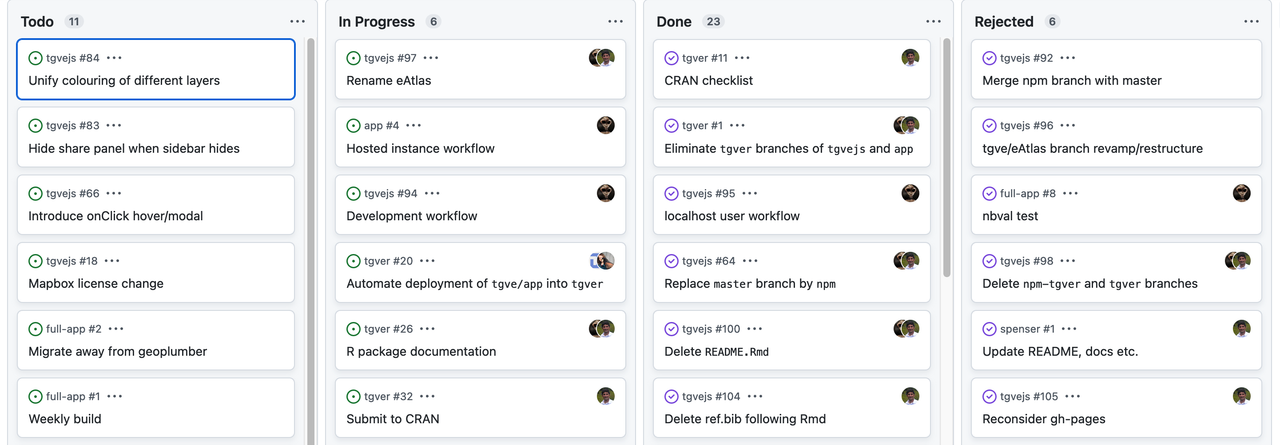 A traditional Kanban for a collaborative computational project.
Keeping track of bugs and what everyone is working on.
A traditional Kanban for a collaborative computational project.
Keeping track of bugs and what everyone is working on.
The Kanban board can be modified to whatever layout or structure makes sense to you. This example uses the concept to publication/release pipeline.
Github also allows different summary views for collaborative issues across multiple repos, which can be helpful for organising larger teams.
Author: Lydia France (Junior Data Scientist, The Alan Turing Institute, UK)
Similar walkthrough can be done with https://next.forgejo.org (Codeberg-like test platform). Lecturer prepare a repository with a readme, a project and one issue. Fake user should be added to the platform before the course, so that people do not have to register, and users are added as collaborators on the repository.
- create an issue “adding myself to the participant list”
- assign it to the project
- move it in the board view
- assign someone, add a label, add a milestone.
- modify readme file, commit change with a new branch.
Collaborating on Computational Projects
Much research is now collaborative and a shared code repository can be effectively used to enable collaboration at all stages of code development at the analysis and implementation stage.
Later in this material, we will go through best practices in code writing, testing, reviews and modularity, which help achieving computational reproducibility. Before that, we will look at ways to foster documentation of the work, and how research data management is necessary for efficient collaboration and reproducible research.
Document collaborations
It is important to document who does what in a project, such that credit can be fairly attributed. This starts at day one, when roles and responsibilities are set, but needs to be often updated as the roles may change during the project. In large team, this may be an essential part of growing a community, especially if one does recognize roles usually overseen in the research environment.
The tenzing spreadsheet (https://tenzing.club) will allow to present the contribution in publications and may be a good tool to start the collection of contribution. A lot of open source project, like The turing way, are using a bot (https://allcontributors.org, works only on GitHub) to collect and show several contribution types.
Challenge
- Go to your research repository created in the setup chapter
- Open one issue, assign one person and a milestone. For instance
write a data management planmilestone in 6 months. - add to do to the issue (optional)
- Use the project board to move the issue inside the board, move it to a different column.
Keypoints
- Make group leaders familiar with practices that are crucial for their teams to develop reproducible code.
- Encourage researchers to think about code reproducibility through quality check, testing, sharing their code as well as a research environment.
- Introduce Continuous Integration for automating the testing process.
Discussion
What measures described in this session are meant to make research more reproducible, what measures are meant to facilitate team work. How does the different measures interact ?
Making interaction measure is also making the research more reproducible. Indeed most of the reusability of the data and code can be best tested when several people interact on a project. Documenting for a current collaborator helps a lot to make sure documentation will be enough for new collaboratory coming in the project later on.
Content from Managing Data
Last updated on 2023-09-06 | Edit this page
Estimated time 50 minutes
Overview
Questions
- What is considered research data?
- How to start building a research data management plan?
- What is FAIR principles for data management?
- Why care about documentation and metadata standards?
Objectives
- Describe research data management (RDM)
- Explain FAIR principles and practices for RDM
- Introduce data storage and organisation plan
- Discuss documentation and metadata practices
- Overview of best practices for spreadsheet design
Research Data Management
Research data management is a huge topic here, because only well managed data can be well analysed and can be usefully shared with the community. It raises concerns and challenges, but also opportunities. It represents about 5% of the time in a research project. Some estimate that it can save up (on average) about 15% of the research time (less time lost due to data loss, fewer errors in the data, automated analysis, data and analysis code reuse).
Invest in data management because:
- Managing your data allows you to always find your data and ensure the quality of scientific practice or research.
- Storing your data properly and backing up regularly prevents data loss.
- It can help with recognition for all research outputs.
- It stimulates collaboration with others, who will find it easier to understand and reuse your data.
- RDM is cost/time efficient, as you will always be able to find and use your data.
Need to consider standard file formats for future use of data!
Electron Microscope Facility in our institute has produced around 5 petabytes (5,000,000 GB) of data since the institute opening. These files are stored safely and privately, and have not been standardised. As a result they are in danger of being lost forever, stored but never used. With metadata, this could form a transformative training data set for machine learning tools and possibly lead to new discoveries and insights. Creating Alpha Fold and other machine learning/AI tools you need large data sets. Meta data allows data to be future proofed for further research and even innovative research not currently possible.
Overview of Research Data Management
Research Data Management (RDM) covers how research data can be stored, described and reused. Data here is used as a generic term to encompass all digital objects. RDM is a vital part of enabling reproducible research. RDM ensures efficiency in research workflows, and also greater reach and impact, as data become FAIR (Findable, Accessible, Interoperable and Reusable).
Data should be stored in multiple locations and backed up regularly to prevent loss or data corruption. It is also important to consider the whole life cycle of the data (especially making collected data computer readable) when designing data management plan and tasks.
Clearly describing data using documentation and metadata ensures that others know how to access, use and reuse your data, and also enable conditions for sharing and publishing data to be outlined.
The Research Data Lifecycle - A Model for Data Management
Research data often follows a ‘lifecycle’ that follows the research project as it evolves. This model provides a sound basis on which to plan for research data management, from data creation at the start of a research project, through to publishing and sharing research at the end of the project, and archiving any research data for the long-term and future re-use once the project has ended.
The research data lifecycle involves data creation, data use, data publication and sharing, data archiving, and data re-use or destruction. However, data have a longer lifespan than the research project that creates them. In a Data Management Plan, you can structure how you will manage and share your research data.
Data Management Plan
A Data Management Plan (DMP), or Output Management Plan, is a document that describes how your research outputs will be generated, stored, used and shared within your project. A DMP is a living document, which can be updated throughout the research project as needed.
A Data Management Plan is a roadmap for you to manage your data efficiently and securely. This can prevent data loss or breaches. Planning ahead on how to manage your data consistently can save you time later on!
A Data Management Plan should provide information on five main topics
- Roles and Responsibilities for the management of the data and code to help prevent confusion/miscommunication later in the project. Please check the DMP recommendations and requirements library research support team of your institute and the website of your funder. You can check if your funder or institute has a DMP template using DMPonline.
- A list of types, standards and formats for data, documentation and metadata (discussed later) should allow team members to understand to comply with the recommendations from the start of the project.
- A distinction can be described in the plan separately for different data types such as raw (primary), processed and ready to use (finalised to publish) datasets.
- All types of data will have to be described to be placed into context by using metadata and adequate documentation which will allow anyone in your team to interpret the data in the future.
- Data storage and backup procedures should be assessed for each project and established depending on the institutional requirements, associated costs and recommended format from your field. We will diuscuss this in detail later in this lesson.
- Preservation of the research outputs can be managed differently based on if they can be made publicly available or not. Personal data or research outputs needed to apply for patents cannot be publicly shared but they still have to be preserved for several years, depending on the policies of your country, institute and funder. Learn more about this in detail in Sharing and Archiving Data chapter in The Turing Way.
- Reuse of your research outputs should be ensured by selecting licenses for different components of your research when you make your output available on a repository (see the Licensing subchapters on data and software for more information). A dedicated document (such as a README file) is recommended for describing research outputs into context. UK Data Service has provided a Data Management Checklist to help cover different aspects of the DMP.
Plan for reproducible research
When planning a reproducible analysis, your data management plan will change. Because you want to avoid any manual wrangling of the data (copy-paste, analysis in excel, …), you need to take particular care of the format of the raw data, making it if possible computer readable with the programming language you will be using. Keep the raw data as raw as possible so that errors can be avoided and calculations can be changed. Also when a software provide you with both raw data and pre-analysed data, you should consider early which file you will be using in your analysis (in most cases, using the raw data will make your analysis more robust and easier to reuse for other researchers). Also information may be lost when transforming the raw data, so make new versions and keep the original file safe.
Who writes a Data Management Plan ?
At best, the whole team should participate in the planning. It is often good to have some specialist who knows what are the backup and publication pathways at the institution or in the research domain. Only the data collectors will know details about the data, though. The data analysts need to be involved to make sure the data is relatively easy to analyse In addition, the researchers will have to implement the plan, so they need to be aware and to agree with it.
Callout
When the data is meant to be open, researchers with different questions and needs may try to analyse the data in unexpected ways. These researchers will not be there at the Data management plan stage and the researchers will probably not have included their needs.
A way to make the data the most useful is to take the FAIR principles into account, keep the raw data raw, and add metadata. A critical metadata component in this case is a contact person, who may be able to explain the data and its analysis to new researchers.
Defining Data
Data are objects that you use and produce during your research life cycle, encompassing data sets, software, code, workflow, models, figures, tables, images and videos, interviews, articles. Data are your research asset. A good way of thinking about what might be classed as data that needs to be managed is to ask yourself the questions:
- What is the information that I need to use and write about in my paper or book?
- What information would I need to back up my conclusions?
- What information is needed by others to understand and possibly replicate the research that I have done? This information is your data.
Best to record the height and weight of the subject. These are more raw forms of the data.
- This is the information the recording devices will give so errors are avoided.
- the BMI may not be the best measure in the future, weight + height is more informative than the BMI.
Using spreadsheets
Here we made a special section on spreadsheets design and management, because most data analysis nightmares (and time waste) are due to bad spreadsheet design.
More information is available in the extra content of this course. Please refer to the Data Carpentry Ecology Lesson and The Turing Way chapter for managing data in spreadsheet for best practices.
Spreadsheets, such as Microsoft Excel files, google sheets, and their Open Source alternative (for instance) LibreOffice, are commonly used by wet-lab experimentalists to collect, store, manipulate, analyse, and share research data. Spreadsheets are convenient and easy-to-use tools for organising information into an easy to write and easy to read forms for humans. However, one should use them with caution, as the use of an inappropriate spreadsheet is a major cause of mistakes in the data analysis workflow.
As a project manager, it is important to see that spreadsheet are only used to collect information, but that manipulation and analysis are made in a programming environment. This also means that the information should be understandable by humans, and readable by machines.
This includes:
- Only one table per spreadsheets
- Spreadsheet are stored as .csv or .tsv files (no color, no merging cells)
- Spreadsheet can be read by the programming language in use (they are tidy)
- At best, there is an automatic validation tool is run on the spreadsheet.
- New data should lead to new rows (and not new columns).

File names and folder structure
While some structure may be given during the project setup, one should keep track of the sub-structure added, make sure the files are saved in the correct folder. In addition, one should make sure that file names are chosen carefully. Indeed, the file name is the first encounter with a file and making names informative can save a lot of time especially when searching for a specific file. File names should be both human and computer readable (conveying information about the file content, in a way a computer can extract it.)
It is important to have written conventions that are easy to find. turingway chapter
While the standard is 1931-03-01 (YYYY-MM-DD), excel will transform this into a number, the only safe way to deal with dates in Excel is to have 3 columns.
Callout
Naming files tips:
- names should be unique in a project
- file location should not be needed to understand what the file is about
- as short as possible, as long as necessary
- avoid abbreviation if possible, document them well otherwise.
- when using dates, use ISO format: yyyy-mm-dd (yyyymmdd can work too)
- no special characters (no space) in filenames, use - or _
- use only lowercase or be very careful (linux versus other systems)
Documentation and Metadata
Having data available is of no use if it cannot be understood. Therefore research data should always include consistent documents and metadata.
Data documentation provides contexts and full description about the data. It allows your collaborators, colleagues and future you to understand what has been done and why. Ideally written in clear and plain language, documentation describes data with sufficient information such as source, strengths, weaknesses, and analytical limitations of the data allowing users to make informed decisions when using it.
Without metadata to provide provenance and context, the data can’t be used effectively. Metadata is information about the data, descriptors that facilitate cataloguing data and data discovery. Often, metadata are intended for machine reading. When data is submitted to a trusted data repository, the machine-readable metadata is generated by the repository. If the data is not in a repository a text file with machine-readable metadata can be added as part of the documentation.
- The type of research and the nature of the data also influence what kind of documentation is necessary. It is best practice to use recognised community metadata standards to make it easier for datasets to be combined.
- The level of documentation and metadata will vary according to the project type and the range of stakeholders, including the future users.
- Examples of documentation may include items like data dictionaries or codebooks, protocols, logbooks or lab journals, README files, research logs, analysis syntax, algorithms and code comments.
- Variables should be defined and explained using data dictionaries or codebooks.
- Data should be stored in logical and hierarchical folder structures, with a README file used to describe the structure.
REMBI: Example of metadata in bioimaging data
REMBI: Recommended Metadata for Biological Images—enabling reuse of microscopy data in biology, Sarkans, U., Chiu, W., Collinson, L., Darrow, M. C., Ellenberg, J., Grunwald, D., …Brazma, A. (2021). Nature Methods, 18(12), 1418–1422. doi: 10.1038/s41592-021-01166-8
Bioimaging data have significant potential for reuse, but unlocking this potential requires systematic archiving of data and metadata in public databases. Cryo-EM and cryo-ET have proven to be powerful tools for determining high-resolution structures of biological matter and examining the functional cellular context of macromolecular complexes.
REMBI is a draft metadata guidelines to begin addressing the needs of diverse communities within light and electron microscopy. The current version of REMBI, including examples from the fields covered by the three working groups is shared online via http://bit.ly/rembi_v1.
Data Storage, Organisation and Backup Procedures

Data loss can be catastrophic for your research project and can happen often. You can prevent data loss by picking suitable storage solutions and backing your data up frequently.
- Most institutions will provide a network drive that you can use to store data.
- Portable storage media such as memory sticks (USB sticks) are more risky and vulnerable to loss and damage.
- Cloud storage provides a convenient way to store, backup and retrieve data. You should check terms of use before using them for your research data.
Especially if you are handling personal or sensitive data, you need to ensure the cloud option is compliant with any data protection rules the data is bound by. To add an extra layer of security, you should encrypt devices and files where needed. Your institution might provide local storage solutions and policies or guidelines restricting what you can use. Thus, we recommend you familiarise yourself with your local policies and recommendations.
Note
- Some concepts discussed in the previous chapter such as setting up project repository, version controlling, pre-registration, and licensing apply to this point.
- Also consider FAIR practices, data organisation and handling sensitive data practices, as well as metadata and documentation that are discussed below.
Backups
To avoid losing your data, you should follow good backup practices.
- You should have 2 or 3 copies of your files, stored on
- at least 2 different storage media,
- in different locations.
The more important the data and the more often the datasets change, the more frequently you should back them up. If your files take up a large amount of space and backing up all of them proves to be challenging or expensive, you may want to create a set of criteria for when you back up the data. This can be part of your data management plan (DMP).
When you are ready to release the data to the wider community, you can also search for the appropriate databases and repositories in FAIRsharing, according to your data type, and type of access to the data. Learn more about this in The Turing Way chapter on sharing and archiving Data.
The FAIR Principles
The FAIR guiding principles for scientific data management and stewardship are guidelines to improve the Findability, Accessibility, Interoperability and Reusability of digital assets; all of which support research reproducibility. The FAIR principles facilitate the availability of research data so that others can reuse data.
FAIR data should be:
- Findable: The first step in (re)using data is to find them! Descriptive metadata (information about the data such as keywords) are essential.
- Accessible: Once the user finds the data and software they need to know how to access it. Data could be openly available but it is also possible that authentication and authorisation procedures are necessary.
- Interoperable: Data needs to be integrated with other data and interoperate with applications or workflows.
- Reusable: Data should be well-described so that they can be used, combined, and extended in different settings.
Making data ‘FAIR’ is not the same as making it ‘open’. Accessible means that there is a procedure in place to access the data. Data should be as open as possible, and as closed as necessary. It is also important to say that the FAIR principles are aspirational: they do not strictly define how to achieve a state of FAIRness, but rather describe a continuum of features, attributes, and behaviours that will move a digital resource closer to that goal. Even though the FAIR principles have been defined to allow machines to find and use digital objects automatically, they improve the reusability of data by humans as well. The capacity of computational systems to find, access, interoperate, and reuse data, with minimal human intervention, is essential in today’s data-driven era.
You can find a more detailed overview of the FAIR principles by GO FAIR of what the FAIR principles recommend.
Summary of “FAIR - How To”
We have provided an additional lesson to discuss the How-Tos of FAIR principles in the context of data and software. See FAIR How-To for data and software for detail.
- Reference: E. L.-Gebali, S. (2022). BOSSConf_2022_Research_Data_Management. Zenodo. doi: 10.5281/zenodo.6490583
- Deposit your data where others can find it, keep in mind where your peers can find it, such as, field specific repository and give it a stable unique identifier (PID).
- Make your data & metadata accessible via standard means such as http/API.
- Create metadata and explain in detail what this data is about, never assume people know!
- Deposit metadata with PID and make it available with/out data i.e. in case data itself is heavily protected.
- Include information on ownership, provenance and citation.
- Outline what the reusers of your data are/not allowed to do, use clear license. Commonly used licenses like MIT or Creative Commons (keep in mind funders requirements).
- Specify access conditions, if authentication or authorization is required.
- Describe your data in a standardized fashion using agreed terminology and vocabulary.
- Share the data in preferred & open file formats.
- Start the process early on!
A Note on Personal or Sensitive Data
Personal data is information about living people who can be identified using the data that you are processing, either directly or indirectly. A person’s name, address or Social Security number, as well as, racial/ethnic identity, political opinions, religious/philosophical beliefs, trade union membership, genetic and biometric data, physical or mental health, and sexual orientation are some examples of personal data. Indirect identifiers include health, economic, cultural or social characteristics. Especially when a certain combination of these identifiers can be used to identify a person, care must be taken to manage the data properly.
There are various policies in place in different countries to protect the rights of individuals over their personal data. For instance, in the European Union and the UK the GDPR (General Data Protection Regulation) applies to the processing of personal data and may require researchers to carry out a Data Protection Impact Assessment (DPIA). Processing means doing anything with a person’s information, including collection, storage, analysis, sharing, deletion and destruction. Please review the national/institutional policies that apply to your research to ensure that you are up to date with the requirements of managing sensitive data. Please read Personal data management, informed consent, Research Ethics Committees Processes and Open Data sections in The Turing Way for further details.
Acknowledgement
- This episode is a reuse of The Turing Way chapter on Research Data Management.
- Among many authors, reviewers and contributors, we thanks Esther Plomp (Data Steward at TU Delft) for maintaining this chapter in The Turing Way Guide for Research Data Management.
- Please cite The Turing Way as: The Turing Way Community. (2021). The Turing Way: A handbook for reproducible, ethical and collaborative research (1.0.1). Zenodo. https://doi.org/10.5281/zenodo.5671094
Keypoints
- Data management plan is produced by the whole team.
- All information is present and digitalised
- Raw data is raw
- Spreadsheets are tidy, validated and in text format (.tsv)
- Data is safe (backup)
- Data is FAIR (findable, accessible, interoperable and reusable)
- Data can be opened and analysed in a programming language
Content from Managing code
Last updated on 2023-09-06 | Edit this page
Estimated time 50 minutes
Overview
Questions
What is the role of data wrangling?
What is literate programming?
How to use data visualisation for insight and communication?
What are the main objectives and best practices for testing and reviewing code?
When can continuous integration help?
Objectives
- Understand the basics of coding
- Understand the advantages of modular code
- How to foster good practices:
- using code review
- using tests
- Discuss the importance of code quality, modular programming, and code testing for reusable error-free code.
- Encourage researchers to combine code with documentation to communicate their work.
Basics of coding
As a project manager, you do not need to code or know how coding works. However, it is important to understand the data workflow and foster documentation, as well as coding best practices, such that you can understand the analysis.
This chapter gives a small introduction into coding and data analysis workflow, code modularity, and then how foster good code with tests and review.
Analysis workflow
A usual workflow involves some data processing, before the actual analysis can be done. Statistical analysis and figure production should be decided before the data is looked at to prevent harking. Explorative analysis (looking for correlation and interpretation of the results) can be done anytime, as long as no hypothesis is rejected from that analysis.

Data (pre-)processing
Code that cleans and processes data (processing code) provides the very beginning of the data analysis pipeline: starting with raw data and resulting in processed data. When the data was not collected in a computer readable format, or when metadata is missing, this step can be the most time consuming of all.
Data wrangling involves cleaning data so it can be easily read and analysed by machines. It can also involve integration, extraction, removing missing points, and anything that makes data useable and functional. Regardless of the methods, the code involved with data cleaning steps should be carefully documented so that the steps involved can be repeated from raw data to cleaned data.
Data wrangling—also called data cleaning, data remediation, or data munging—refers to a variety of processes designed to transform raw data into more readily used formats. The exact methods differ from project to project depending on the data you’re leveraging and the goal you’re trying to achieve.
Some examples of data wrangling include:
- Merging multiple data sources into a single dataset for analysis,
- Identifying gaps in data (for example, empty cells in a spreadsheet) and either filling or deleting them,
- Deleting data that’s either unnecessary or irrelevant to the project you’re working on,
- Identifying extreme outliers in data and either explaining the discrepancies or removing them so that analysis can take place.
Data wrangling can be a manual or automated process. In scenarios where datasets are exceptionally large, automated data cleaning becomes a necessity.
Cleaning data means it can be easily read and analysed by machines and used in analysis pipelines. It can involve changing labels, subsetting, integration, extraction, removing missing points, and anything that makes data usable and functional.
Regardless of the methods, the code involved in data cleaning steps should be carefully documented so that the steps involved can be repeated from raw data to clean data. When reviewing this type of code, consider whether the steps involved are readable and in the correct order. Especially, when filtering data out, this should be consistent and indicated in the main method description.
Data visualisation, Analysis and Statistics
Visualising data before designing the data analysis is a form of harking, as you will cherry pick your data (filtering some data out) or cherry pick an analysis (what looks promising). You should always design your analysis before visualising the data, or use visualised data as training data, not included in the final analysis.
With readable, clean, processed data, the next stage of the data pipeline is analysis.
Depending on your computational project, this may involve elaborate and complex analyses, modelling, simulation, and even machine learning. However, even if this step is just running a single statistics test, keeping the code documented and modular in clearly defined steps is key.
Here is an example of applying a Butterworth filter to some data in Python. The specifics don’t matter, you can consider this code pseudocode for any kind of analysis step.
genomeProject/analysis/01_butterworth_filter.py
#### 01_butterworth_filter, v1.0
##this code read processed data and apply a low pass filter,
## the output variable is called filtered_data
# Import dependencies
import numpy as np
from scipy.signal import butter,filtfilt
# (A) Read processed data from file
df = pd.read_csv('genomeProject/data/220103_GenomicData_processed.csv')
# (B) Defining filter parameters
T = 5.0 # Sample Period
fs = 30.0 # sample rate, Hz
cutoff = 2 # desired cutoff frequency of the filter, Hz
nyq = 0.5 * fs # Nyquist Frequency
order = 2 # quadratic
n = int(T * fs) # total number of samples
# (C) Define the Butterworth Filter Function
def butter_lowpass_filter(data, cutoff, fs, order):
normal_cutoff = cutoff / nyq
# Get the filter coefficients
b, a = butter(order, normal_cutoff, btype='low', analog=False)
filtered_data = filtfilt(b, a, data)
return filtered_data
# (D) Apply Butterworth Filter Function to the data
filtered_data = butter_lowpass_filter(df, cutoff, fs, order)
Challenge
genomeProject/analysis/01_bf.py
import numpy as np
from scipy.signal import butter,filtfilt
df = pd.read_csv('genomeProject/data/220103_GenomicData_processed.csv')
normc = 2 / 15
b, a = butter(2, normc, btype='low', analog=False)
filtered_data = filtfilt(b, a, df)
The code above will give the same result, why is the first one better on the long run ?
- easier to read for non-coders
- commented
- variables easy to change
- better names
- function reusable + possibility to write tests
- the processed data is read into the script. Next, (B) the fixed
parameters are set and named with comments. These fixed numbers are
saved as variables with names. In (C) the filter itself is written as a
Python Function, which means it can be called multiple times throughout
the script. Because the parameters are not written into the function
directly (so it doesn’t say
b, a = butter(2, 15,btype='low', analog=False)but instead uses variables) this code is reusable without having to paste and edit the numbers every time you apply a function.
You can also call this function in other scripts. It can make sense to produce a file with the functions inside that can be imported into different scripts in case other projects also have similar methods. This is known as a package or library. This means altering a function doesn’t mean searching across every file on every project and changing it dozens of times.
Case Study
A postdoc wrote a helpful series of functions for data analysis with neurophysiology recordings. The postdoc wrote them as reuseable, and so two PhD students copied and pasted these blocks of code into their code and used it to analyse the data for their projects.
The postdoc later discovers a better way of writing the functions. One PhD student also wants to change the method and so has to search through his files to replace the code. The other PhD student wants the old method in some files and the new method in others, and so does not change all of them. It is therefore complex to follow the differences in the methods across the projects, and this is very open to errors in typos.
Instead, the postdoc could have saved his functions in the lab’s private repo which becomes the master copy and students pull from this. With the functions saved in a library, the PhD students can import them into their scripts. Now when the postdoc changes the functions and saves them to the repo, PhD students can choose to update their version of the functions. The students should document which version they have used.
The output of the analysis code may be statistics results that are reported in a paper, and therefore the steps required to reproduce them are critically important.
Figures for Communicating Results
When working with data sets,
ggplot(in R) ormatplotlib/seaborn(in Python) libraries provide attractive figures that can be produced very quickly. Visualising data should not not wait for the point of publication, and can be used to explore data from the start, and also illustrate methodology. This is particularly valuable in Jupyter Notebooks. Code to produce figures should be literate, functional, reuseable in the same way as data cleaning and analysis code. That way future visualisations can be easily updated or reused.
With the analysis complete, data visualisation is usually used to communicate results. The code used to produce figures is often the next step in the data pipeline.
For publications or posters, well-constructed figures improve science communication and help improve the impact of your research. Being able to produce multipanel figures with annotations and different colour schemes is complex but one of the advantages of learning a data science language.
It is therefore worth taking the time for researchers to learn the technical skills in R, Python, or another language to produce visualisations. Producing figures in Excel is limiting and often frustrating, particularly as there are only limited options in layout and type of figure.

Exploring constraints on a wetland methane emission ensemble (WetCHARTs) using GOSAT observations, Parker et al 2020

Spatial transcriptome profiling by MERFISH reveals subcellular RNA compartmentalization and cell cycle-dependent gene expression, Xia et al 2019 https://www.pnas.org/doi/10.1073/pnas.1912459116
These figures are more than just visualising data, they’re about
communication and require adjusting the styles and formats within
ggplot or matplotlib or other libraries.
As before, any code used to produce visualisations should be reproducible and literate. Often in peer review figures need to be adjusted or altered, and having the code to do so makes the process much simpler.
It is usually cleaner to keep data visualisation code separate from analysis, just to keep a code base organised and modular.
Accessibility
- For simple figures, using shaded vs unshaded and single colour is best when considering publications may be printed in black and white
- Colours should be colourblind friendly, resources are available for this.

- If using a colour map, avoid the standard rainbow. Other rainbows like viridis colour maps can be downloaded. The brightness varies across the rainbow which leads to visual artefacts that do not exist:

The transition between greens to yellow and red are more prominent than the transitions between greens and blues, making stark boundaries that do not exist. A rainbow with equal brightness solves the problem.
Sisneros et al (2016) Chasing Rainbows: A Color-Theoretic Framework for Improving and Preserving Bad Colormaps. https://doi.org/10.1007/978-3-319-50835-1_36
Also one should keep readability in mind with text size/font and similar considerations
- Data Visualisation as a tool
Statistical analysis
Selection of appropriate statistical method is very important step in analysis of data. A wrong selection of the statistical method not only creates some serious problem during the interpretation of the findings but also affects the conclusion of the study. In statistics, for each specific situation, statistical methods are available to analysis and interpretation of the data. To select the appropriate statistical method, one need to know the assumption and conditions of the statistical methods, so that proper statistical method can be selected for data analysis. Other than knowledge of the statistical methods, another very important aspect is nature and type of the data collected and objective of the study because as per objective, corresponding statistical methods are selected which are suitable on given data. Incorrect statistical methods can be seen in many conditions like use of unpaired t-test on paired data or use of parametric test for the data which does not follow the normal distribution, etc., Two main statistical methods are used in data analysis: descriptive statistics, which summarizes data using indexes such as mean, median, standard deviation and another is inferential statistics, which draws conclusions from data using statistical tests such as student’s t-test, ANOVA test, and many others
Statistics goes outside the scope of this course.
Coding best practices
The order of a script is usually:
- main comments on the script function and goals
- importing all dependencies
- reading inputs, naming outputs
- listing all variables
The latter element is particularly important. Variables are often a decision taken (for instance it could be some threshold value used for filtering data out, a type of low-pass filter used, or a time window that sub-set the data). Defining them at the start of the code makes it easier to change and spot.
In practice, your figure and analysis may well depend on the version of the data, code and these variables, so it is often interesting to include this information into the output of the code. This may take the form of a pdf file, with the figure on the first page, and a table of variables and metadata on the following pages.
Literate Programming
Literate programming is about comments and documentation and telling other humans what is happening in your pipeline. Depending on the scale of your computational projects, you may use one or multiple of these options:
- Inline comments when writing code (directly written in the script file)
- A README file describing what your code does
- An online documentation as a user and developer guide with step-by-step explanation
- Quarto/RMarkdown or Jupyter Notebook
Most of these files can be written in Markdown.
Often, literate programming refers to these notebooks form, where the documentation and the code are integrated in one file, which produce one output (html of pdf most of the time).
This course can be thought as a literate programming content. Its source is markdown and Rmarkdown files, its output is a pdf.
Resources for taking this to next level
- https://the-turing-way.netlify.app/collaboration/new-community.html
- Data Visualisation as a tool
Modular Programming (Functions)
Applying methods from one person’s work and applying it to another problem can take weeks, if not months, of work. Applying methods from publications is even harder: static PDF files can’t describe the lines of code and data that lead to those discoveries. This is an increasingly important problem in the face of growing mistrust in science, and a reproducibility crisis plaguing the sciences.
Instead, functional programming is about writing code that works as modular steps. Each step is clearly commented on and carefully produced so that it can be reused in different contexts. Often when you are analysing data, you need to repeat the same task many times. For example, you might have several files that all need loading and clean in the same way, or you might need to perform the same analysis for multiple species or parameters. Rather than copying and pasting, writing a function and calling that function leads to fewer errors and confusion overall.
We can think of this on a broad scale, say one student’s computational work has the following steps, where blue shows data cleaning, and yellow the analysis and statistics.

Another student can take reuse the data cleaning and initial visualisation steps because her data was from the same source and is in the same format. She can later add her own model:

On the micro-scale, functional programming ensures that each code file itself is comprised of modular blocks, whether for data processing, analysis pipeline, simulation and so on. Depending on your programming language, these may be used as a package or a library or saved in files that are available for installation. Just the same as the diagram above, making sure functions are robust and reuseable means they can be shared throughout different workflows and for different projects.
Training in functional programming is usually an excellent pre-requisite for members of your lab.
A first step can be to draw out and create diagrams to plan code before starting and identifying the modular steps involved. This does not require technical knowledge of a language and is, therefore, a great exercise for direct supervision. You can find practical details on reproducible code in the Guides to Better Science by British Ecological Society.
Code Testing
You should not skip writing tests because you are short on time, you should write tests because you are short on time.
 The Turing Way project illustration by Scriberia. Used under a CC-BY
4.0 licence. DOI: 10.5281/zenodo.3332807.
The Turing Way project illustration by Scriberia. Used under a CC-BY
4.0 licence. DOI: 10.5281/zenodo.3332807.
Writing a test to prove things work right now is useless (duh, you know what use case you designed it for, of course it will work). Defending your project against the future idiot who is going to f things up (most likely yourself) is the right attitude and will lead to proper tests. Love it! https://mstdn.social/@flip1/108951972043173555
It is very, very easy to make mistakes when coding. A single wrong use of a character can cause a program’s output to be entirely wrong. Missing one data point, writing plus instead of minus symbol or using feet instead of meters might be a genuine human mistake, but in research, the results can be catastrophic. Careers can be damaged/ended, vast sums of research funds can be wasted, and valuable time may be lost exploring incorrect avenues. This is why code testing is vital.
Testing is a learned skill that needs to become a part of working on/improving a project. After changing their code, researchers should always check that their changes or fixes have not broken anything. It also helps deciding when dependencies can be updated. There are several different kinds of testing and each has best practices specific to them.
A few important testing types
- Smoke testing: Very brief initial checks that ensure the basic requirements required to run the project hold. If these fail there is no point in proceeding to additional levels of testing until they are fixed.
- Unit testing: A level of the software testing process where individual units of a software are tested. The purpose is to validate that each unit of the software performs as designed.
- Integration testing: A level of software testing where individual units are combined and tested as a group. The purpose of this level of testing is to expose faults in the interaction between integrated units.
- System testing: A level of the software testing process where a complete, integrated system is tested. The purpose of this test is to evaluate whether the system as a whole gives the correct outputs for given inputs.
No matter the type of testing you use, general guidance is to start by writing any test and make a habit of running tests often.
- Make improvements where you can, and do your best to include tests with new code you write even if it’s not feasible to write tests for all the code that’s already written.
- Make the cases you test as realistic as possible. If for example, you have dummy data to run tests on you should make sure that data is as similar as possible to the actual data. If your actual data is messy with a lot of null values, so should your test dataset be.
There are tools available to make writing and running tests easier, these are known as testing frameworks. Find one you like, learn about the features it offers, and make use of them.
Writing tests typically encourage researchers to write cleaner, more modular code as such code is far easier to write tests for, leading to an improvement in code quality. As well as advantaging individual researchers testing also benefits research as a whole. It makes research more reproducible by answering the question “how do we even know this code works”. To gain an in-depth understanding of different kinds of tests, please see Code Testing chapter in The Turing Way.
Code Review
Testimonial
The most difficult part of writing code is always to make it understandable to other people, including yourself a few months down the track. There’s certainly no shame in finding out that your code wasn’t as easy to understand or use as you’d hoped, so don’t take it personally when it happens (which it always does, at least in my experience), but treat it as an opportunity to improve.
Fernando Perez, Code reviews: the lab meeting for code
A simple objective of the review process is to catch bugs and elementary errors that might have been missed during the development phase. Code review can also help improve the overall quality while ensuring that code is readable and easy to understand. As a group leader, you can also make sure code is functional and literate as early as possible, and encourage your students to avoid messy “good enough” code that causes chaos later.
Code review is often done in pairs, with each reviewer also having some of their code reviewed by their partner. Doing this can help programmers to see and discuss issues and alternative approaches to tasks, and to learn new tips and tricks.

The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807.
There are different methods for code review.
Synchronous - Pair Programming
Helping the student go through their scripts, catch errors and debug side by side
- The PI sits down with her PhD student who has been writing a function for cleaning bioinformatics data.
- The PI knows Python well and takes the opportunity to discuss code while helping their student organise the code better.
- The student shows the PI some odd errors and so they run some tests with expected outcomes to find what the problem is and solve it.
- The PhD student learns and applies to test practices to help make code robust.
The problem with synchronous coding sessions is making time for it and whether or not the supervisor has experience with the specific language.
Synchronous - Group Code Tour or Informal Walkthroughs
Narrating code and software steps
The researcher may present their pipeline to describe the logical steps using documentation, pseudocode, or describing how to run the code.
- A postdoc has been working on some analysis that provides statistics results that he hopes to publish soon. During a lab meeting, the postdoc presents the steps of the analysis code as logical steps.
- The lines of code are shown for those in the meeting that know R, but the postdoc explains the steps verbally as well for those who don’t understand R.
- The group discuss and provides comments on the choices and order of the analysis pipeline, a PhD student notices a jump in logic that wasn’t picked up previously, and an advanced R user in the lab makes suggestions about making some parts run faster.
These sessions do not rely on everyone knowing the language, and it is the responsibility of the coder to present their work clearly and logically for everyone to follow. Group discussions can be very informative for everyone involved and put the analysis under scrutiny.
Suggestions for the meeting leader
- Keep it a safe environment, i.e. make sure chastising is relatively gentle even when deserved (but do point out when code doesn’t meet the required standard – frame it as a learning experience though).
- Make sure there’s a core of vocal participants so it isn’t always you.
- Make it clear when you’re presenting yourself that your code isn’t perfect, point out some of those imperfections yourself if the audience is slow to do so, and do present yourself.
- Patiently explain when things are not wrong but just stylistic differences (but make it clear that some styles are bad, often helpful e.g. asking people to guess what a function returns from its name).
Shared by Rob Knight with Fernando Perez in the post Code reviews: the lab meeting for code
Asynchronous - I’ll get back to you on that
Making sure everyone is free at the same time for a lab meeting can be challenging. Hence, asynchronous code review practices are more suitable for busy supervisors or collaborators in different time zones.
The asynchronous review process allows others to run the code themselves using a reproducible environment, or simply reads through the scripts and share their feedback asynchronously.
Consider a scenario:
A postdoc has created a model in Python and creates a Binder with all the dependencies necessary. She sends the file to her supervisor who can run the code within her browser, no installation is required. The supervisor can then run the code herself to review it and check the individual parts over the next week. The supervisor adds a commented version of the script to the postdoc’s repo with a merge request.
Reviewing code in small chunks incrementally as the project is developing can help make the code review process a lot more efficient. Asynchronous feedback removes the time pressure but can be easily forgotten!
Testimonial
Reviewing more than 400 lines of code (LoC) can have an adverse impact on your ability to find bugs, and in fact, most are found in the first 200 lines. - Recommendation from Code Review at Cisco Systems
5 code review best practices. Work Life by Atlassian, Usman Ghani
Multiple people can also review the code asynchronously.
Callout
Turing Way: Recommendations for Code Reviewing
Unlike traditional, “academic-style” peer review, most code review systems have several advantages: they’re rarely anonymous, they’re public-facing, and without the broker of an editor, contact between reviewer and reviewee can be direct and rapid. This means code review is typically a fast, flexible, and interactive process.
Commit changes: uploading snapshots when the code changes. The history of all changes are therefore saved and can be reverted.

Branching: keep a version of the code separate while making experimental changes or keeping track of collaborative work. Can try out new functionality or edit in parallel without impacting the code base.
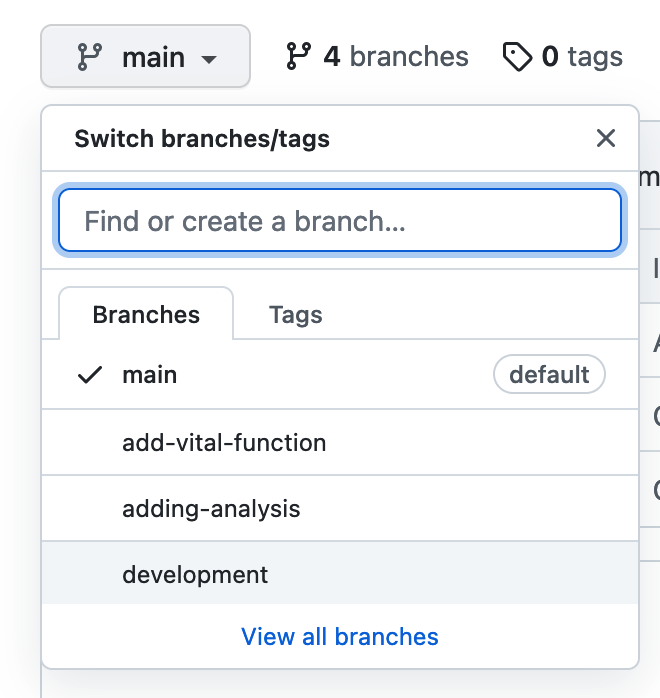
Pull Request: Bring the changes made on a branch over to the main code base. Can be used to request a code review (see Reviewers on the right panel)
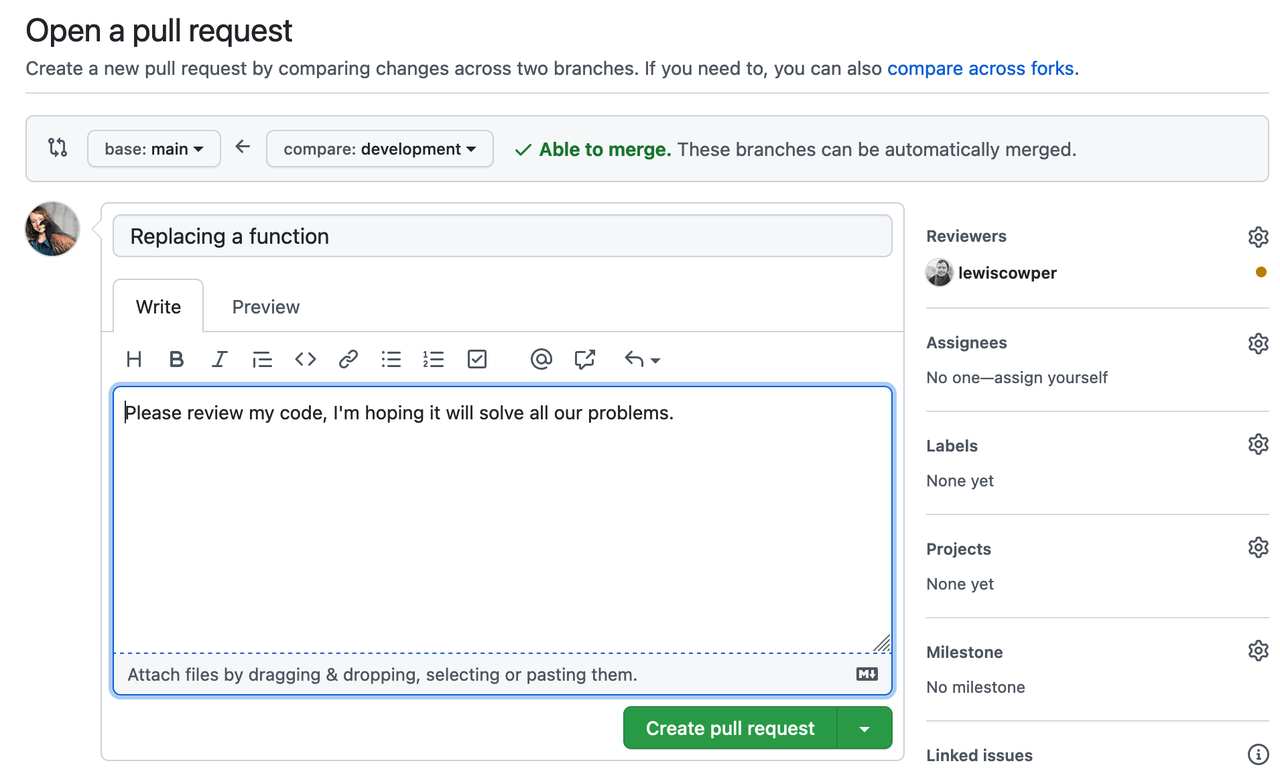
Review: A pull request can be reviewed and commented on.
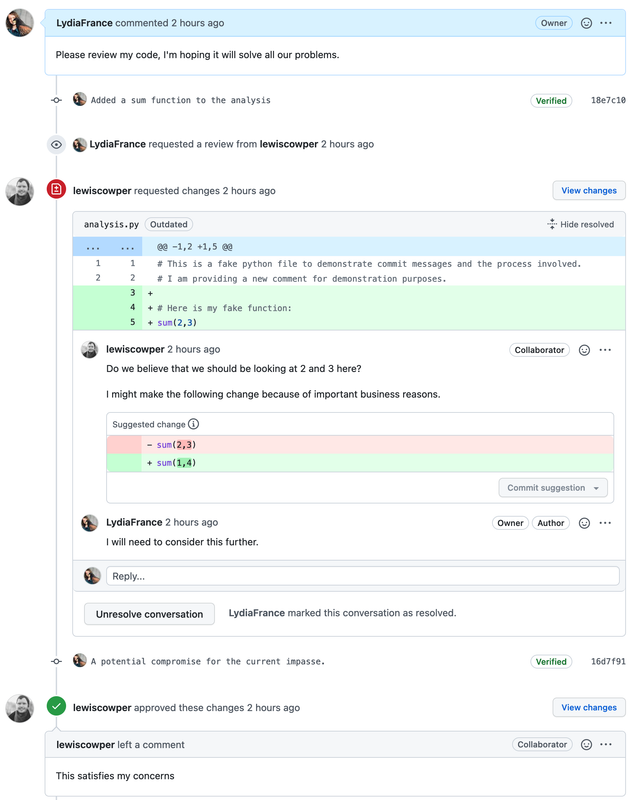
Author: Lydia France (Junior Data Scientist, The Alan Turing Institute, UK)
Reviewing is not about creating more work, nor the PI rewriting everything
Instead, it is just another part of peer review and accountability within the scientific process. It is also an opportunity for everyone to learn better practices from each other, and solve issues that have plagued one person for weeks!
Callout
Scientists are very aware that their understanding of code dissipates over time and that this is a large hidden cost. Equally, they suspect that they spend a lot of time reinventing wheels. They may not know how code review will help with that, but they hope that it will.
One of the mentors expected scientists to overhaul complete code bases. The advice from one mentor was cogent: if you check the docstring and write a test every time you touch a method, the code improvements will accumulate over time with minimal effort.
Someone who isn’t intimately involved with your project should understand from the module documentation and the comments what you are trying to do, what approach you’re taking, and why they should expect it to work.
Take some time to prepare a presentation about your code that will answer the above questions even for someone who hasn’t read the code. You’re more likely to get useful feedback, rather than nitpicking about syntax, if the audience can see the big picture.
Keep it a safe environment, i.e. make sure chastising is relatively gentle even when deserved (but do point out when code doesn’t meet the required standard – frame it as a learning experience though).
Marian Petre and Greg Wilson. “Code review for and by scientists: preliminary findings.” (2014).
For further considerations in code review, please read Code Reviewing Process chapter in The Turing Way.
What to look for during Code Review
Reviewing code makes a big difference. Knowledge of the language is not always necessary!
These are very common, everyone does this.
Bugs/Potential bugs
- Repetitive code
- Code saying one thing, documentation saying another
- Off-by-one errors
- Making sure each function does one thing only
- Lack of tests and sanity checks for what different parts are doing
- Magic numbers (a number hardcoded in the script)
Unclear, messy code
- Bad variable/method names
- Inconsistent indentation
- The order of the different steps
- Too much on one line
- Lack of comments and signposting
Fragile and non-reusable code
- Tailor-made and manual steps
- Only works with the given data
Modified from What to look for when code reviewing
Benefits of Code Review
Testimonial
In a group of 11 programs developed by the same group of people, the first 5 were developed without reviews. The remaining 6 were developed with reviews. After all the programs were released to production, the first 5 had an average of 4.5 errors per 100 lines of code. The 6 that had been inspected had an average of only 0.82 errors per 100. Reviews cut the errors by over 80 percent.
Code Complete by Steve McConnell
The main benefit is finding problems, and finding them early enough that there aren’t frustrating consequences. The penalty for finding a bug once all the figures have been produced and conclusions drawn, or, worst-case scenario, after a publication, is much higher than the penalty for taking the time to review.
For a group leader, the benefits include:
- Better understanding of the projects
- More maintainable and better-documented code that is easy to understand and modify
- Better insight into any problems with data
- Earlier visibility of quality issues
- Group reviews reduce the work burden
- More robust analysis pipelines that can be reused and modified
- High-quality code that can be released
Important things to bear in mind:
Code reviews should not be used to evaluate individuals and their skill levels. An open and safe environment where revealing mistakes and errors should not come with penalties or shame. Code reviews should also be done early and often, to normalise this practice in the research team.
In their book Peer Reviews in Software: A Practical Guide, Karl E. Wiegers says:
The temptation to perfect the product before you allow another pair of eyes to see it. This is an ego-protecting strategy: you won’t feel embarrassed about your mistakes if no one else sees them. …review [is not] a seal of approval but rather in-process quality-improvement activity. Such reluctance has several unfortunate consequences. If your work isn’t reviewed until you think it’s complete, you are psychologically resistant to suggestions for changes.
If the program runs, how bad can it be? You are likely to rationalise away possible bugs because you believe you’ve finished and you’re eager to move on to the next task. Relying on your own desk checking and unit testing ignores the greater efficiency of a peer review for finding many defects*
Group Code Writing
As well as reviewing specific scripts and analyses written by a single individual, can be very beneficial to solving programming problems as a team. Setting aside an afternoon to work as a group will help teach less experienced members of the group and more efficiently solve very difficult problems.
Groups of people working on a specific problem are often known as “Hackathons” in programming. These can last multiple days (hopefully with downtime!). With very large groups, people can work in pairs or small groups with delegated parts of the problem to solve and regularly meet back together to discuss and evaluate. If there is a complex solution in computational methods that most people in the group need, it makes sense to find it together.
Similarly, documentation sprints are useful to dedicate time to regularly bring a codebase to a good minimum standard. Splitting the task across the team as an event, creating documentation and working examples for code repos and releasing it can help others use your computational methods and tools to increase the impact of your work. Having regularly updated documentation also reduces onboarding time for new members picking up the shared methods in the lab.
Group work shares the burden and allows knowledge exchange and support within the team.
Continuous integration
Continuous Integration (CI) is the practice of integrating changes to a project made by individuals into a main, shared version frequently (usually multiple times per day). CI is also typically used to identify any conflicts and bugs that are introduced by changes, so they are found and fixed early, minimising the effort required to do so. Running tests regularly also saves humans from needing to do it manually. By making users aware of bugs as early as possible researchers (if the project is a research project) do not waste a lot of time doing work that may need to be thrown away, which may be the case if tests are run infrequently and results are produced using faulty code. There are many CI service providers, such as GitHub Actions that come with their own advantages and disadvantages.
 The Turing Way
project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI:
10.5281/zenodo.3332807.
The Turing Way
project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI:
10.5281/zenodo.3332807.
To learn more about different CI tools and how to use them, please read the Continuous Integration chapter in The Turing Way.
References
- The Turing Way Community. (2021). The Turing Way: A handbook for reproducible, ethical and collaborative research (1.0.1). Zenodo. https://doi.org/10.5281/zenodo.5671094. Code Reviewing Process Chapter.
- Fernando Perez, Code reviews: the lab meeting for code
Keypoints
- There are many benefits of code review and this should be implemented and practised in research team culture as early and as frequently as possible.
- Synchronous code review creates opportunities for researchers to get feedback and learn from others in real-time.
- Asynchronous code review is a good practice when working with busy researchers or collaborators in different time zones.
Content from Managing publication
Last updated on 2023-09-06 | Edit this page
Estimated time 50 minutes
Overview
Questions
- Why should I make my research objects available?
- What open source tools to use for applying data science practices in bioscience?
- How to get your research work cited and invite more contributions to your project?
- How to maintain history of contributions and contributors?
- How should I mention and cite the software or data I am using?
Objectives
- Understand the importance of PID.
- Know how to make data and code citable
- Nudge the use of GitHub/GitLab for open collaboration
- Learn why and how to cite the work of others, as well as your own research output
What and when to publish

While the output of research projects is usually centred around publishing a journal article, this format of science communication and knowledge sharing is increasingly restrictive with the new ways scientific research is conducted. The requirements from journals themselves is also expanding, you are now often asked to upload data sets and code as part of your publication. Releasing data is increasingly a requirement from funding bodies, and outputs from research groups can go beyond a single paper, releasing tools and methods that can be used worldwide.
In general, there are different degrees of openness, depending on what, when and how research outputs are shared. In order to produce outputs that can be shared, one should start preparing for publication at the beginning of a project. This overall course is about getting ready to share code and data in the lab, such that sharing it with the world is only one click away.
What can be released:
- Open Access manuscritps and preprints: Making the story and interpretation of your research freely accessible for maximum use and impact.
- Open Data: Documenting and sharing research data openly for re-use.
- Open Source Software: Documenting research code and routines, and making them freely accessible and available.
- Open Hardware: Documenting designs, materials, and other relevant information related to hardware, and making them freely accessible and available.
- Open Notebooks: An emerging practice, documenting and sharing the experimental process of trial and error.
https://the-turing-way.netlify.app/reproducible-research/open.html
When to release:
- Never: Fully private data and code, unavailable
- Pseudo-open – “available on request”
- Released static output parallel to a research paper
- Release versioned outputs during the research process in Open online repository – CRAN, GitHub
- Open per default: Collaborative, open science tool with ongoing development
- There were a time when researchers were not sharing their discovery at all.
- The publishing industry made it to a “available on request” kind of state.
- Open access publication made it a static released.
- Preprints are released versions.
- blog posts may be considered open per default.
How can it be released
This relates to the license used: what will people be allowed to do with your released research outputs.
Without going into details, different types of outputs should be released using different licenses. Licenses are usually of different forms, giving the rights to use without restriction (public domain), allowing to use as long as the original authors are credited (with attribution). In addition one can restrict re-use the work as long as the new work is released with a similar license (weak copyleft) or the same license (hard copyleft).
Some license also restrict the use to non-commercial use or preventing derivatives.
See https://the-turing-way.netlify.app/reproducible-research/licensing and linked tools for details.
In addition, one should think about where things are released (how long will it be available, how will it be found), and how to indicate how people should credit your work.
Open or Private?
Researchers often worry that they need to hide their code to prevent others stealing it.
“After giving talks about open science I’ve sometimes been approached by skeptics who say, ‘Why would I help out my competitors by sharing ideas and data on these new websites? Isn’t that just inviting other people to steal my data, or to scoop me? Only someone naive could think this will ever be widespread.’ As things currently stand, there’s a lot of truth to this point of view. But it’s also important to understand its limits. What these skeptics forget is that they already freely share their ideas and discoveries, whenever they publish papers describing their own scientific work. They’re so stuck inside the citation-measurement-reward system for papers that they view it as a natural law, and forget that it’s socially constructed. It’s an agreement. And because it’s a social agreement, that agreement can be changed. All that’s needed for open science to succeed is for the sharing of scientific knowledge in new media to carry the same kind of cachet that papers do today”
Nielsen, M. Reinventing Discovery: The New Era of Networked Science. Princeton University Press, 2011.
https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3000246
Making your research object citable
Getting a doi
Digital Object Identifiers or DOIs are persistent, unique and trusted. The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807.
DOIs are alphanumerical unique and persistent identifiers with a permanent web address for different research objects that can be cited by you and other researchers. Each pre-print and publication is published with a DOI, but independent of the paper, different research objects can be published online on servers that offer DOIs at any stage of your research.
Repositories usually collect the citation information before providing a DOI, so that the metadata associated with the DOI is indexed. Necessary information includes a title and a list of authors.
You may want to read the Making Research Objects Citable chapter in The Turing Way Guide to Communication.
Authors and contributors
In order to get correct metadata, give credits to all contributors and actually have the rights to make things public, you need to collect information and agreements from all authors. As usual, it is best to get it as soon as possible in the research process; and as usual you may well have postponed it until the latest moment.
It is advisable to use a spreadsheet to collect information (names, affiliation, orcid number). The Tenzing spreadsheet can be used, as it will allow the program to create author list automatically from the spreadsheet, as well as collect information on each author contribution.
Callout
It might be particularly important to credit all people who have indeed participated in the research. The use of a contribution statement in the paper (see https://tenzing.club) or contribution section in the repository readme can be useful (see https://allcontributors.org).
For contributors who will not be in the author list of the main paper, one can make them authors of the published dataset/code, and/or add them in the aknowledgements. The first solution has the advantage to be sent to orcid (if people have an orcid account) such that the contribution is more visible and measurable.
Citation File Format
The Citation File Format provides citation metadata, for software or datasets, in plaintext files that are easy to read by both humans and machines.
Adding a CITATION.cff file to your folder means it can
be cited when others use it, increasing recognition for your work and
your research project’s impact.
See more at The Turing Way: CITATION.cff
https://the-turing-way.netlify.app/_images/software-credit.jpg
{kind=link}
Citable data
Data is best published in domain specific repositories. Look for a data repository at https://www.re3data.org.
Costs associated with data publication can be important, so it is best to plan ahead, so you are sure you have the resources needed. Whether the raw or some derived data should be published openly will depend on costs and may depend on legislations.
See https://the-turing-way.netlify.app/communication/citable.html for details.
Some of these servers are Zenodo, FigShare, Data Dryad (for data), Open Grants (for grant proposals) and Open Science Framework (OSF) (for different components of an open research project). It allows you to show connections between different parts of research as well as cite different objects from your work independently.
When working on GitHub for instance, you can connect the project repository with Zenodo to get a DOI for your repository. The Citation File Format, then lets you provide citation metadata, for software or datasets, in plaintext files that are easy to read by both humans and machines.
Citable Code
For computational projects, releasing your work in an open repository
has parallels with publications.
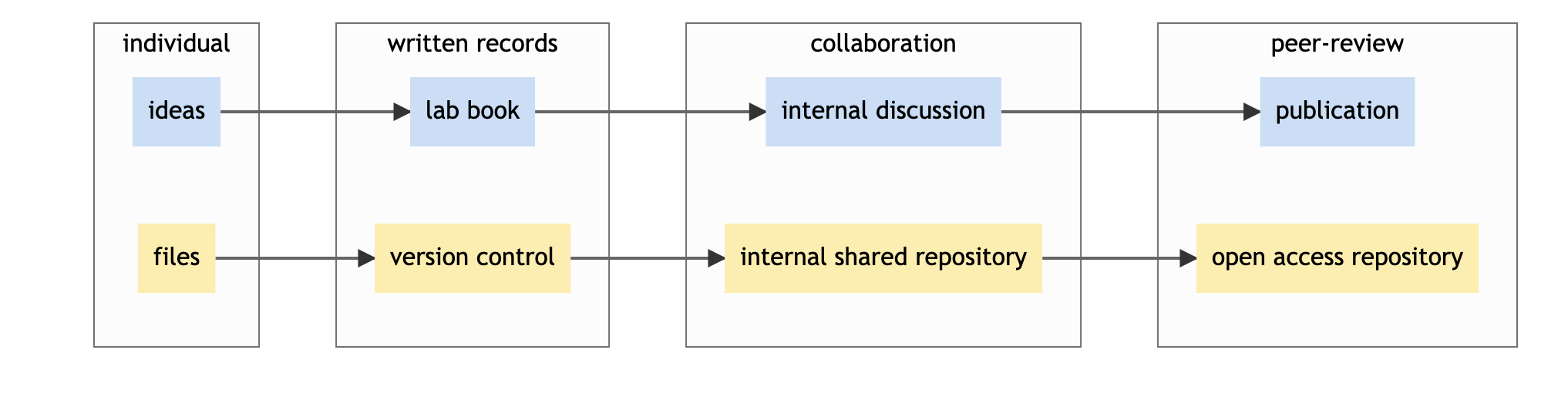
While it is possible to cite software from GitHub (see below using a
Citation File Format file), it is better to cite an archived version of
the software (a code release). You can release code and data associated
with a research article as a series of files/folders. You could for
example bundle folders into a .zip file and upload it to
Zenodo.
The possibility to get integration with zenodo from GitHub or GitLab, makes it easy to get DOIs for each version of the software. These automated archive of release may even read the CITATION.cff file to create metadata. This is explained in more detail in the Turing way book at https://the-turing-way.netlify.app/communication/citable/citable-cite.tml

Zenodo is a general-purpose open-access repository developed under the European OpenAIRE program and operated by CERN. It allows researchers to deposit research papers, data sets, research software, reports, and any other research related digital artefacts.
Uploads to Zenodo are:
- Safe — your research is stored safely for the future in CERN’s Data Centre for as long as CERN exists.
- Trusted — built and operated by CERN and OpenAIRE to ensure that everyone can join in Open Science.
- Citeable — every upload is assigned a Digital Object Identifier (DOI), to make them citable and trackable. No waiting time — Uploads are made available online as soon as you hit publish, and your DOI is registered within seconds.
- Open or closed — Share e.g. anonymized clinical trial data with only medical professionals via our restricted access mode.
- Versioning — Easily update your dataset with our versioning feature.
- GitHub integration — Easily preserve your GitHub repository in Zenodo.
- Usage statistics — All uploads display standards compliant usage statistics
This goes in more details about collaborative code, it may be useful if collaboration is the main topic of your workshop.
Collaborative Open Code

Downloading code and data files from Zenodo or other open access repositories can be useful when someone wants to review your the final outcome of your computational work. However, with an open GitHub repository, sharing code becomes much more collaborative and in real-time.
Uploading code in progress to an open GitHub Repo is the best and most well-used method for programming collaboration.
As you develop a tool or methodology, users have the ability to use your code while it is a work in progress and others can contribute or add features.

When using specifically R, you could release R packages on CRAN where anyone can then download and use you code.
Citing others
You should cite research objects directly in the paper in places where it is relevant. This is a commonly practiced way of citing publications and is valid for citing other research components like data, hardware and software.
A citation includes the following information: - Author - Title - Year of publication - Publisher (for data, this is often the data repository where it is housed) - Version (if indicated) - Access information (a URL or DOI)
You should use a citation manager to collect and use this information, zotero is the free and open source software option.
If the author of the research object did not provide a easy way to collect the information, try to contact them. You can refer them to the [turing way chapter] (https://the-turing-way.netlify.app/communication/citable.html) , which is also a source for this course.
Citing yourself
Make your research objects are citable, as described later. Then do not forget to insert citation of these research objects in your own papers. Provide data, software and hardware availability statement, for example:
The data/software/harware that support the findings will be available in [repository name] at [URL / DOI] following a [6 month] embargo from the date of publication, to allow for the commercialization of research findings.”
Note that you can often reserve a DOI without publishing your data and code, if you want for the paper to come out first.
Content from Conclusion and feedback
Last updated on 2023-09-06 | Edit this page
Estimated time 15 minutes
Overview
Questions
- What are the most important take home messages?
Objectives
- Overview of what has been learned
- consolidation of learning
Feedback, questions