Managing publication
Last updated on 2023-09-06 | Edit this page
Estimated time 50 minutes
Overview
Questions
- Why should I make my research objects available?
- What open source tools to use for applying data science practices in bioscience?
- How to get your research work cited and invite more contributions to your project?
- How to maintain history of contributions and contributors?
- How should I mention and cite the software or data I am using?
Objectives
- Understand the importance of PID.
- Know how to make data and code citable
- Nudge the use of GitHub/GitLab for open collaboration
- Learn why and how to cite the work of others, as well as your own research output
What and when to publish

While the output of research projects is usually centred around publishing a journal article, this format of science communication and knowledge sharing is increasingly restrictive with the new ways scientific research is conducted. The requirements from journals themselves is also expanding, you are now often asked to upload data sets and code as part of your publication. Releasing data is increasingly a requirement from funding bodies, and outputs from research groups can go beyond a single paper, releasing tools and methods that can be used worldwide.
In general, there are different degrees of openness, depending on what, when and how research outputs are shared. In order to produce outputs that can be shared, one should start preparing for publication at the beginning of a project. This overall course is about getting ready to share code and data in the lab, such that sharing it with the world is only one click away.
What can be released:
- Open Access manuscritps and preprints: Making the story and interpretation of your research freely accessible for maximum use and impact.
- Open Data: Documenting and sharing research data openly for re-use.
- Open Source Software: Documenting research code and routines, and making them freely accessible and available.
- Open Hardware: Documenting designs, materials, and other relevant information related to hardware, and making them freely accessible and available.
- Open Notebooks: An emerging practice, documenting and sharing the experimental process of trial and error.
https://the-turing-way.netlify.app/reproducible-research/open.html
When to release:
- Never: Fully private data and code, unavailable
- Pseudo-open – “available on request”
- Released static output parallel to a research paper
- Release versioned outputs during the research process in Open online repository – CRAN, GitHub
- Open per default: Collaborative, open science tool with ongoing development
- There were a time when researchers were not sharing their discovery at all.
- The publishing industry made it to a “available on request” kind of state.
- Open access publication made it a static released.
- Preprints are released versions.
- blog posts may be considered open per default.
How can it be released
This relates to the license used: what will people be allowed to do with your released research outputs.
Without going into details, different types of outputs should be released using different licenses. Licenses are usually of different forms, giving the rights to use without restriction (public domain), allowing to use as long as the original authors are credited (with attribution). In addition one can restrict re-use the work as long as the new work is released with a similar license (weak copyleft) or the same license (hard copyleft).
Some license also restrict the use to non-commercial use or preventing derivatives.
See https://the-turing-way.netlify.app/reproducible-research/licensing and linked tools for details.
In addition, one should think about where things are released (how long will it be available, how will it be found), and how to indicate how people should credit your work.
Open or Private?
Researchers often worry that they need to hide their code to prevent others stealing it.
“After giving talks about open science I’ve sometimes been approached by skeptics who say, ‘Why would I help out my competitors by sharing ideas and data on these new websites? Isn’t that just inviting other people to steal my data, or to scoop me? Only someone naive could think this will ever be widespread.’ As things currently stand, there’s a lot of truth to this point of view. But it’s also important to understand its limits. What these skeptics forget is that they already freely share their ideas and discoveries, whenever they publish papers describing their own scientific work. They’re so stuck inside the citation-measurement-reward system for papers that they view it as a natural law, and forget that it’s socially constructed. It’s an agreement. And because it’s a social agreement, that agreement can be changed. All that’s needed for open science to succeed is for the sharing of scientific knowledge in new media to carry the same kind of cachet that papers do today”
Nielsen, M. Reinventing Discovery: The New Era of Networked Science. Princeton University Press, 2011.
https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3000246
Making your research object citable
Getting a doi
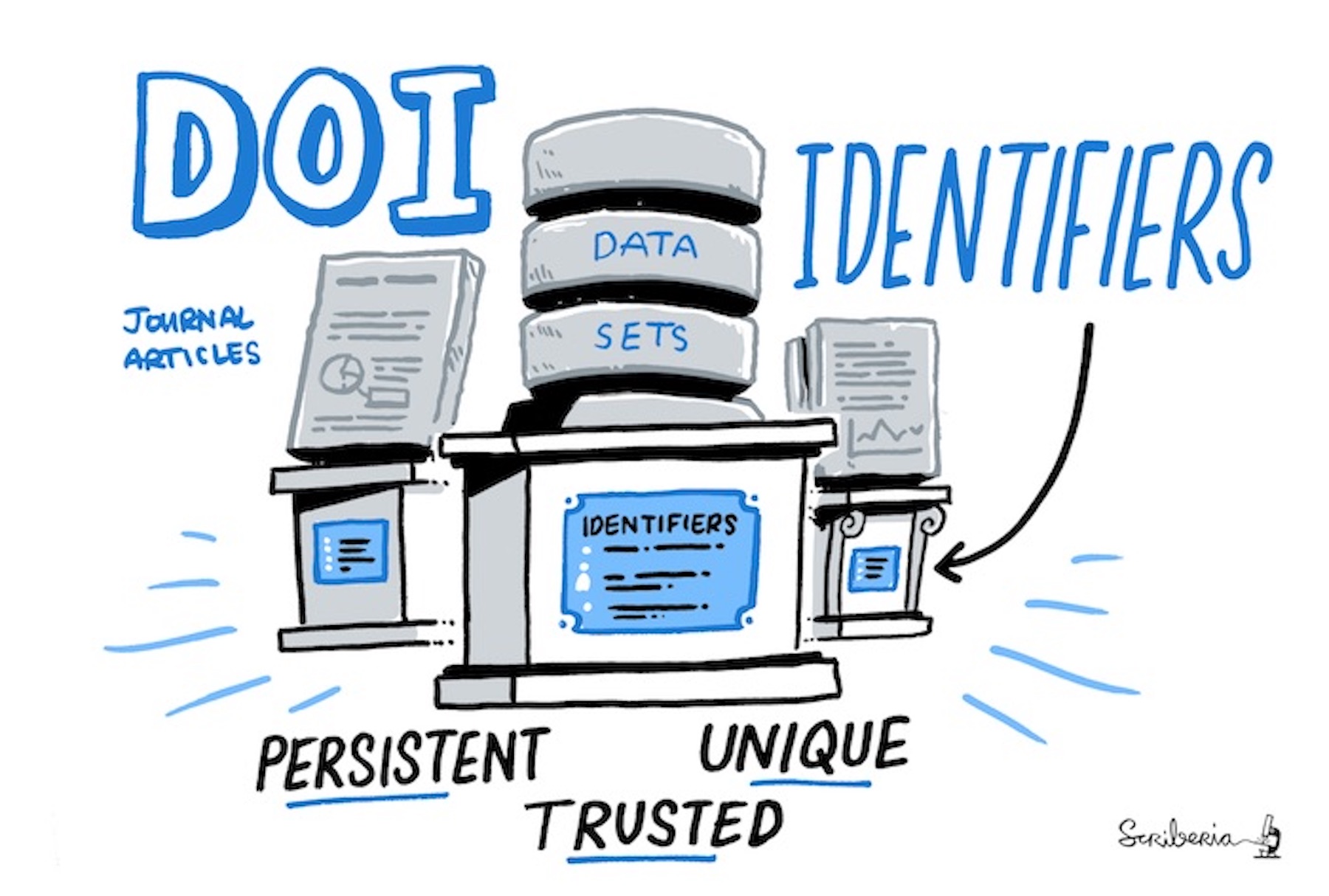
Digital Object Identifiers or DOIs are persistent, unique and trusted. The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807.
DOIs are alphanumerical unique and persistent identifiers with a permanent web address for different research objects that can be cited by you and other researchers. Each pre-print and publication is published with a DOI, but independent of the paper, different research objects can be published online on servers that offer DOIs at any stage of your research.
Repositories usually collect the citation information before providing a DOI, so that the metadata associated with the DOI is indexed. Necessary information includes a title and a list of authors.
You may want to read the Making Research Objects Citable chapter in The Turing Way Guide to Communication.
Authors and contributors
In order to get correct metadata, give credits to all contributors and actually have the rights to make things public, you need to collect information and agreements from all authors. As usual, it is best to get it as soon as possible in the research process; and as usual you may well have postponed it until the latest moment.
It is advisable to use a spreadsheet to collect information (names, affiliation, orcid number). The Tenzing spreadsheet can be used, as it will allow the program to create author list automatically from the spreadsheet, as well as collect information on each author contribution.
Callout
It might be particularly important to credit all people who have indeed participated in the research. The use of a contribution statement in the paper (see https://tenzing.club) or contribution section in the repository readme can be useful (see https://allcontributors.org).
For contributors who will not be in the author list of the main paper, one can make them authors of the published dataset/code, and/or add them in the aknowledgements. The first solution has the advantage to be sent to orcid (if people have an orcid account) such that the contribution is more visible and measurable.
Citation File Format
The Citation File Format provides citation metadata, for software or datasets, in plaintext files that are easy to read by both humans and machines.
Adding a CITATION.cff file to your folder means it can
be cited when others use it, increasing recognition for your work and
your research project’s impact.
See more at The Turing Way: CITATION.cff
https://the-turing-way.netlify.app/_images/software-credit.jpg
{kind=link}
Citable data
Data is best published in domain specific repositories. Look for a data repository at https://www.re3data.org.
Costs associated with data publication can be important, so it is best to plan ahead, so you are sure you have the resources needed. Whether the raw or some derived data should be published openly will depend on costs and may depend on legislations.
See https://the-turing-way.netlify.app/communication/citable.html for details.
Some of these servers are Zenodo, FigShare, Data Dryad (for data), Open Grants (for grant proposals) and Open Science Framework (OSF) (for different components of an open research project). It allows you to show connections between different parts of research as well as cite different objects from your work independently.
When working on GitHub for instance, you can connect the project repository with Zenodo to get a DOI for your repository. The Citation File Format, then lets you provide citation metadata, for software or datasets, in plaintext files that are easy to read by both humans and machines.
Citable Code
For computational projects, releasing your work in an open repository
has parallels with publications.
While it is possible to cite software from GitHub (see below using a
Citation File Format file), it is better to cite an archived version of
the software (a code release). You can release code and data associated
with a research article as a series of files/folders. You could for
example bundle folders into a .zip file and upload it to
Zenodo.
The possibility to get integration with zenodo from GitHub or GitLab, makes it easy to get DOIs for each version of the software. These automated archive of release may even read the CITATION.cff file to create metadata. This is explained in more detail in the Turing way book at https://the-turing-way.netlify.app/communication/citable/citable-cite.tml

Zenodo is a general-purpose open-access repository developed under the European OpenAIRE program and operated by CERN. It allows researchers to deposit research papers, data sets, research software, reports, and any other research related digital artefacts.
Uploads to Zenodo are:
- Safe — your research is stored safely for the future in CERN’s Data Centre for as long as CERN exists.
- Trusted — built and operated by CERN and OpenAIRE to ensure that everyone can join in Open Science.
- Citeable — every upload is assigned a Digital Object Identifier (DOI), to make them citable and trackable. No waiting time — Uploads are made available online as soon as you hit publish, and your DOI is registered within seconds.
- Open or closed — Share e.g. anonymized clinical trial data with only medical professionals via our restricted access mode.
- Versioning — Easily update your dataset with our versioning feature.
- GitHub integration — Easily preserve your GitHub repository in Zenodo.
- Usage statistics — All uploads display standards compliant usage statistics
This goes in more details about collaborative code, it may be useful if collaboration is the main topic of your workshop.
Collaborative Open Code

Downloading code and data files from Zenodo or other open access repositories can be useful when someone wants to review your the final outcome of your computational work. However, with an open GitHub repository, sharing code becomes much more collaborative and in real-time.
Uploading code in progress to an open GitHub Repo is the best and most well-used method for programming collaboration.
As you develop a tool or methodology, users have the ability to use your code while it is a work in progress and others can contribute or add features.

When using specifically R, you could release R packages on CRAN where anyone can then download and use you code.
Citing others
You should cite research objects directly in the paper in places where it is relevant. This is a commonly practiced way of citing publications and is valid for citing other research components like data, hardware and software.
A citation includes the following information: - Author - Title - Year of publication - Publisher (for data, this is often the data repository where it is housed) - Version (if indicated) - Access information (a URL or DOI)
You should use a citation manager to collect and use this information, zotero is the free and open source software option.
If the author of the research object did not provide a easy way to collect the information, try to contact them. You can refer them to the [turing way chapter] (https://the-turing-way.netlify.app/communication/citable.html) , which is also a source for this course.
Citing yourself
Make your research objects are citable, as described later. Then do not forget to insert citation of these research objects in your own papers. Provide data, software and hardware availability statement, for example:
The data/software/harware that support the findings will be available in [repository name] at [URL / DOI] following a [6 month] embargo from the date of publication, to allow for the commercialization of research findings.”
Note that you can often reserve a DOI without publishing your data and code, if you want for the paper to come out first.