What is Machine Learning good at?
Overview
Teaching: 30 min
Exercises: 10 minQuestions
What are the tasks where machine learning excels?
Objectives
Identify the types of data that machine learning can work with.
Decide when deep learning is an appropriate tool for a machine learning task, and know what its downsides can be.
GLAM data types for Machine Learning
- Tabular Data
- Images (Computer Vision)
- Text (Natural Language Processing)
Classical Machine Learning and Deep Learning
In the previous episoode, most of our machine learning examples dealt with tabular data. There are numerous different algorithms that work with tabular data, and they all have strengths and weaknesses for different tasks and types and sizes of data. (See the for a good overview of which algorithms you can use for a given task).
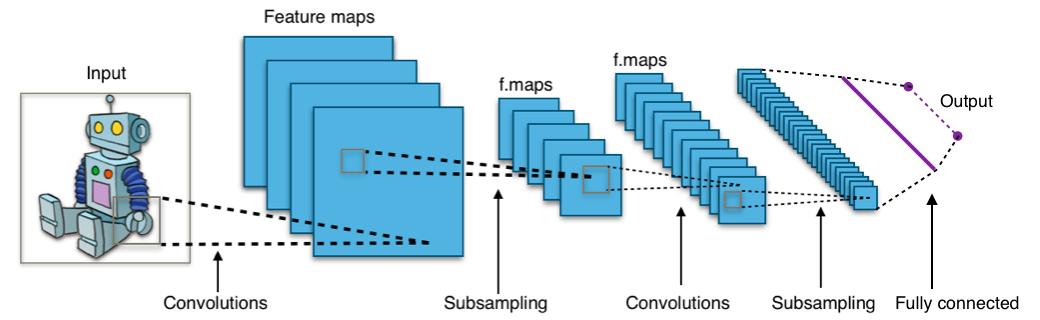
Computer Vision
Computer Vision (often abbreviated to CV) has been around since the early days of AI but has been revolutionised in recent years by so called Deep Learning models. The most common of these models is called a Convolutional Neural Network (CNN) and is capable of identifying complex patterns in images. A convolution is inspired by our own visual system. Imagine you are travelling at high speed and trying to avoid obstacles. Your visual system doesn’t have time to work out the fine details of the objects in front of you, it just needs to detect shapes. Convolutions work in that way too. One convolution may detect horizontal edges, another vertical edges, yet another corners, and so on. They work over very small portions of an image, as little as 3x3 pixel squares. A neural network is a complex machine learning model which we use when we need to go beyond drawing lines between points (although they can do that too). It is built of layers of numbers and data is passed through the layers until an answer of some sort comes out of the other end. In a CNN the first layer find the edges, the second layer starts to find patterns of connected edges, the third layer may start to detect shapes, and we keep going until the final layer when a classification is decided on based on all the patterns found in the image. A Deep Convolutional Neural Network (quite a mouthful) is just the name for a CNN with lots of layers (there can be hundreds). The deeper the network, the more complex features it can identify in an image - from edges, to shapes, to patterns, to textures. However, as we learned in the linear model section, complexity comes at a cost. A deep network may need to see millions of labelled images to perform well, and they can take many hours, days, or even weeks to train.
Tensorflow Playground
You can play with a small neural network and see convolutions in action at Tensorflow Playground. You don’t need to know anything about neural networks, just try things out and see what happens - sometimes even the professionals do that!
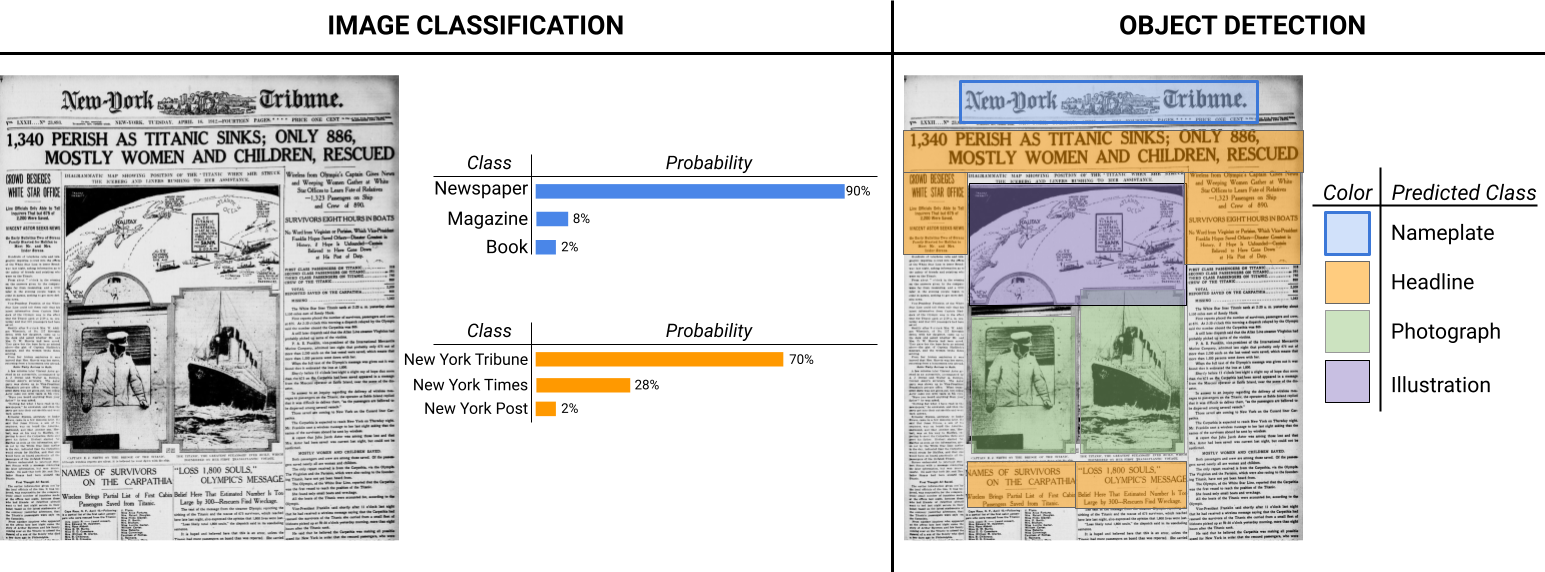
Computer Vision tasks
- Image classification: label images according to a set of categories
- Object detection: identify buildings, people, vehicles or animals in images
Thinking about object detection
At the beginning of the episode we thought about how we might build a set of rules to describe an umbrella. Now we know that with machine learning we can provide an algorithm with images containing umbrellas, and images without umbrellas.
Take a look at pictures labelled as umbrellas in the image collections of the Smithsonian Institute, British Library, and The National Archives (UK).
Now think back to some of the questions we asked earlier:
- Is colour important?
- What compromises do you think you’d have to make if you could only label small amounts of training data?
- The umbrella classifier needs counter examples - pictures without umbrellas - what kind of images would you use for those? [Hint: think of things which might be mistaken for umbrellas]
Activity
Now that you have learned the types of computer vision tasks where machine learning excels, what are some things you might try to do with this image?
Imagine you had overhead views of each tray of bird specimens. How might object detection help speed up digitisation?
Solution

Natural Language Processing
In Computer Vision we started with a grid of numbers which is the way that images are represented in a computer. Machine Learning algorithms need numerical inputs which means that before we can work with text we need to convert it into a numerical form. This means there are two stages to modelling our data, each introducing assumptions about the world which impact the tasks we can accomplish, and the computational and data resource needed to accomplish them.
Stage one is to model the words in our text. The simplest way is to build a vocabulary and then count how many times each word in the vocabulary appears in each document. The vocabulary is generally built from the training corpus because the classifier needs at least one example of each word. In recent years state of the art systems have used a representation of words called word embeddings. Conceptually embeddings are numerical representations of words which allow us to find semantically similar words. This means that if our training corpus contains the words ‘tree’, ‘plant’ and ‘flower’, then applying the model to a document containing the word ‘bush’ will still work even though it wasn’t in the training corpus. Word embeddings are often trained on a very large corpus of documents (e.g. Wikipedia) and made publicly available. While this is convenient it is important to bear in mind that the documents they’re trained on may not be representative of the language encountered in historical documents.
The second stage is to model the language. This doesn’t mean creating a complex linguistic model, but thinking about simplifying assumptions about the text to reduce computational complexity. The simplest language model considers all words in a sentence to be independent of each other.
- Do you think that is a reasonable assumption?
If you were formulating a theory of language it would be a bad assumption, as it suggests sentences are random sets of words. However, for many real world machine learning tasks it works quite well. The term bag of words is often used to describe such a model. One way of thinking of this model of language is to imagine writing a review of a book. In front of you are two bags, one marked ‘Positive’ and the other ‘Negative’. If you like the book you will reach into the ‘Positive’ bag for words to use in your review, and if you don’t like it then you choose words from the ‘Negative’ bag. Now a Machine Learning algorithm trying to learn a model for identifying whether reviews are positive or negative is effectively trying to establish which bag the words in the review came from. The reviews containing words like ‘Interesting’, ‘Exciting’, ‘Delightful’ are more likely to be positive, while ‘Boring’ and ‘Uninteresting’ would suggest the negative bag was used. The simplicity of the model allows us to use less training data and would be computationally efficient to build a model.
Of course we know that language is more nuanced than that.
- “The book was not boring at all” - this sentence is positive despite the word ‘boring’ appearing in it.
- “The author’s other books were exciting but this was not” - this sentence is negative despite containing ‘exciting’
In this case we can increase the complexity of our language model to use pairs of words, which would mean ‘not boring’ becomes a feature in the input data. However, remember that whenever we increase complexity we generally need more data.
Modern deep learning models are able to model sentences, or even paragraphs and documents, as strings of related words. This is essential for tasks such as machine translation where word order changes between languages. It is also necessary if we want the machine to make sense of long passages where perhaps the subject of the sentence was mentioned at the beginning but is referred to by a pronoun later on in the document.
- Otto met Nancy at the park. It was a beautiful sunny day and he was looking forward to their picnic together.
The kind of machine learning model needed to make the connection between ‘their’ and ‘Otto and Nancy’ is called a Recurrent Neural Network (RNN). Recurrent just means that it models its inputs as a sequence and is able to make connections between items in the sequence. As always, there is a trade off. Complex deep learning models require a lot of training data, millions of lines of text to perform well. This makes sense because to identify relationships between words it must see examples of words used in different contexts.
Activity
Which of these typical Natural Language Processing tasks do you think requires a complex language model, and which could be achieved with a simpler one.
- Sentiment analysis: Is a sentence positive or negative?
- Machine Translation: converting text in one language, to another
- Spam detection
- Entity extraction: identifying people, places, organisations in text
- Text generation: generating text, maybe a poem, in the style of an author
- Question answering: interpreting a written question and retrieving the answer from a database
Solution
- Sentiment analysis: this can work with bag of words but things like sarcasm are difficult to detect.
- Machine Translation: definitely requires a complex model due to changes in word order, idiomatic phrases that don’t translate well, and translations not being a one to one mapping of words.
- Spam detection: simple models work remarkably well as spam is often full of obvious keywords
- Entity extraction: named entities often fit standard patterns so a simple model works quite well
- Text generation: generating plausible looking text requires a huge amount of training data but not necessarily a complex model. Generating text that makes sense is a much more complex problem.
- Question answering: this can be achieved with a simple model. It is as much about identifying patterns of questions, and depends on how controlled the domain of questions is. For example, answering “What time is the next train to London?” does not require a complex language model.
Computer Vision meets Natural Language Processing
One of the state of the art applications of machine learning seen in cultural heritage at the moment is Handwritten Text Recognition (HTR). The idea is to convert digitised handwritten documents into searchable and machine readable text. To achieve this HTR uses a combination of Computer Vision and Natural Language Processing. A Convolutional Neural Network is used to work out the letter shapes in each word. Since handwriting can be tricky and ambiguous the best it can do is identify possible letters from the shapes it has identified. A Recurrent Neural Network is then used to work out the most likely word. Since it has a sentence level language model it does this by taking into account words in the whole line of text so that it can use context to work out the most likely word. By balancing the prediction of the Computer Vision model with the language model it is still able to output words that were never seen in the training data.
Transfer Learning
In most computer vision classification models, the input image goes through hundreds of layers, which results in a “feature vector” (sometimes referred to as an embedding). This feature vector is then classified into a limited number of classes.
If you want to use your own classes, you can take those vectors that come from a general case model, and re-train the classification step.
You can also “fine-tune” the weights in the previous layers of the model.
Unsupervised Learning with Feature Vectors
You can take feature vectors generated by pre-built models, and calculate distances between them, and produce clusterings.

Key Points
First key point. Brief Answer to questions. (FIXME)