Artificial Intelligence (AI) and Machine Learning (ML) in a nutshell
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is a brief history of the field of (AI) and Machine Learning (ML)?
What do we mean by Artificial Intelligence and Machine Learning? How are they defined?
Objectives
Understand Machine Learning as a subfield of AI and name two others
Name four types and machine learning and describe the difference between supervised and unsupervised learning
Describe the difference between a model of data, and a model trained on data
Artificial Intelligence and Machine Learning
The field of Artificial Intelligence has been around since the 1950s (Dartmouth Conference, 1956). It is a broad topic which encompasses a number of sub-fields including but not limited to: Logic, Probability, Knowledge Representation, and Machine Learning.
This figure shows how a system based on Artificial Intelligence might function:
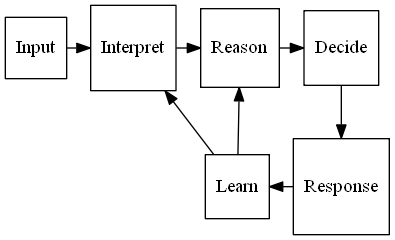
The system accepts an input, performs some inference about what the input represents, performs some reasoning about the inferences made based on prior knowledge, and finally decides on an action.
From logic to learning
The history of Logic stretches all the way back to The Organon of Aristotle (Organon) and was formalised as a mathematical discipline by George Boole in the 19th century (hence the name Boolean Logic). With logic we can write rules to reason about data or make decisions.
- “It is raining therefore I will carry an umbrella”.
Logical rules are based on things being True or False but the world is not so clear cut. Probability lets us add doubt and uncertainty:
- “It might rain today, should I take an umbrella?”.
With logical rules and probability we can solve quite complex tasks, but there are limits:
- “Which paintings in our collection have umbrellas in them?”.
Take a minute to think of how you would describe an umbrella using a set of rules:
- What colour is it?
- What shape is it?
- How big is it?
- What difference does it make if it is up or down?
- Is a parasol an umbrella?
Describing something as intuitively simple as an umbrella is difficult because although we have a rough conceptual idea there isn’t a fixed physical description. Even if you break it into component parts you still need to define them - what is a handle? what is a canopy? It becomes even more complicated if you try to specify the description in a way that a computer can interpret. Thankfully Machine Learning can come to our rescue.
What is Machine learning?
Machine Learning is a set of technologies and methods for finding rules when they are too complex to define. They are systems which find rules, learn, and make predictions from data without being explicitely programmed to do so.
Activity
Which of the following do you think would use Machine Learning?
- a) Counting the number of people in a museum using information from entry and exit barriers.
- b) A search system that looks for images similar to a user submitted sketch.
- c) A system that recommends library books based on what other users have ordered.
- d) A queueing system that spreads people evenly between 5 ticket booths
- e) A program which extracts names from documents by finding all capitalised words and checking them against a list of known names
- f) A system which turns digitised handwritten documents into searchable text
- g) A robot which cleans the vases in a museum without bumping into them or breaking them
Solution
- b, c, f, and g are all examples where machine learning would be needed. The others could all be achieved through simple and easily defined rules.
There are four types of machine learning, and in this lesson we will focus on the first two:
- Supervised - the system is given data that is categorised and labeled and asked to learn by example to make predictions on totally new data it has never seen before
- Unsupervised - given data that has not been categorised and labeled and asked to put it into groups (find patterns) without guidance
- Semi-supervised - a combination of supervised and unsupervised
- Reinforcement - learns about the world by interacting with its environment (example: self-driving cars and AlphaGo)
The primary task of Machine Learning is prediction.
A prediction may be a numerical value: how much will temperature control in the archive cost if we have a hot summer? how many days will library borrowers keep books for? Or it may be a classification or label: which paintings are of animals/architecture/people? which documents should be classified as sensitive?
Note
Predicting a numerical value is known as Regression. The term Regression was coined by Francis Galton in the 19th century to describe a biological phenomenon. The phenomenon was that the heights of descendants of tall ancestors tend to regress down towards a normal average (a phenomenon also known as regression toward the mean). (Regression Analysis).
Imagine you want to go on holiday next month. Imagine! You would like to know what the temperature will be on a small island that has no weather information. To do this you find the following information about other countries around the world: latitude, longitude, month, average temperature. Now you can use a machine learning technique called Regression to predict the temperature at your potential destination using its lat/lon and the month. This is a prediction task.
An alternative approach would be to make a list of destinations you like, and those you don’t like. Gather the same information of lat/lon, month and temperature for a sample of countries, but this time add a ‘Yes’ or ‘No’ for whether you like them or not. You can now choose one of many machine learning classification algorithms to label the rest of the world’s countries Yes or No. This is a binary (there are two categories) classification task.
Supervised vs unsupervised learning
The previous example was of supervised learning. In the supervised scenario a set of labelled examples are passed to a machine learning classifier which learns to identify relationships between features of the data and the labels, or a numerical output. The table shows some examples of features and labels for some supervised learning tasks:
| Task | Application | Features | Output | Example learned relationship |
|---|---|---|---|---|
| Classification | Sentiment analysis | Words in a sentence | ‘Positive’ or ‘Negative’ | ‘glad’ or ‘happy’ weighted towards ‘Positive’ label |
| Classification | Seasonal paintings | Images of paintings | ‘Spring’,’Summer’,’Autumn’,’Winter’ | Red leaves more predictive of Autumn label |
| Prediction | Child height estimate | Age of child | number in centimetres | Height increases as age increases |
Unsupervised learning is not given any examples. Instead a target is suggested and the algorithm groups the data based on that target. The target is usually the number of groups wanted, and the algorithm will place data points into each group in order to maximum the similarity of group members. The following activity aims to give you an intuition for clustering, a commonly used form of unsupervised learning.
Activity
Imagine there are 6 people in a workshop and you need to split them evenly between 2 tables based on the similarity of their interests. Their interests are listed below in order of preference. How would you divide them into 2 tables with 3 people on each table?
- Person A - politics, sport, nature
- Person B - walking, cooking, quiz shows
- Person C - baking, sewing, athletics
- Person D - newspapers, biographies, history
- Person E - football, rugby, cricket
- Person F - fine dining, pub quizzes, bird watching
Solution
There isn’t a right answer to this challenge. In fact an algorithm with no other information other than the words above would probably distribute them randomly. To perform the task it would need further information that could provide semantic relationships between the words. That may it could establish that sport is similar to football, rugby and cricket, and fine dining and cooking are related. Without that information they are just meaningless strings to a computer. You should have seen that there are multiple solutions and when using unsupervised methods you have little influence over which is chosen.
Each paradigm has its advantages and disadvantages. Unsupervised learning is a straightforward way of identifying clusters of similar records in a set of data making it ideal for gaining a high level view of a new dataset. However, choosing the right number of clusters can be difficult and there is no way to control the criteria for how clusters are formed. In the above exercise we saw a number of types of activity (physical, food related, current affairs, natural world), with some possibly fitting into two categories. In supervised learning we define the categories in advance giving us control over the outputs. The downside is the cost of labelling our data. Consider the effort involved in the following tasks:
- Transcribing 100 pages of handwritten medieval documents
- Tagging each of 10000 images if they contain an umbrella
- Linking together daily visitor data with weather data currently held on someone else’s website
Activity
Fill in the blanks with either “Supervised Learning”, “Unsupervised Learning”, “Prediction” or “Classification”
- Estimating how much money a customer will spend in the museum shop is a _____ task
- A program to decide if a customer is a ‘big spender’ or a ‘browser’ would use a _____ algorithm
- Identifying four types of library visitor is an example of _____
- _____ requires labelled examples
Solution
- Estimating how much money a customer will spend in the museum shop is a Prediction task
- A program to decide if a customer is a ‘big spender’ or a ‘browser’ would use a Classification algorithm
- Identifying four types of library visitor is an example of Unsupervised Learning
- Supervised Learning requires labelled examples
Key Points
Machine Learning is a subfield of AI which identifies patterns in data
Supervised learning algorithms learn by example
Unsupervised learning algorithms put data into groups of similar objects or records