Bagging
Overview
Teaching: 20 min
Exercises: 10 minQuestions
“Bagging is the shortened name for what?”
How can bagging improve model performance?
Objectives
Train a set of models using bagging.
Visualise the decision boundaries.
Bootstrap aggregation (“Bagging”)
Bootstrap aggregation, or “Bagging”, is another form of ensemble learning.
With boosting, we iteratively changed the dataset to have new trees focus on the “difficult” observations. Bagging involves the same approach, except we don’t selectively choose which observations to focus on, but rather we randomly select subsets of data each time.
Boosting aimed to iteratively improve our overall model with new trees. With bagging, we now build trees on what we hope are independent datasets.
Let’s take a step back, and think about a practical example. Say we wanted a good model of heart disease. If we saw researchers build a model from a dataset of patients from their hospital, we might think this would be sufficient. If the researchers were able to acquire a new dataset from new patients, and built a new model, we’d be inclined to feel that the combination of the two models would be better than any one individually.
This is the scenario that bagging aims to replicate, except instead of actually going out and collecting new datasets, we instead use “bootstrapping” to create new sets of data from our current dataset. If you are unfamiliar with bootstrapping, you can treat it as magic for now (and if you are familiar with the bootstrap, you already know that it is magic).
Let’s take a look at a simple bootstrap model.
np.random.seed(321)
clf = tree.DecisionTreeClassifier(max_depth=5)
mdl = ensemble.BaggingClassifier(base_estimator=clf, n_estimators=6)
mdl = mdl.fit(x_train.values, y_train.values)
fig = plt.figure(figsize=[12,6])
for i, estimator in enumerate(mdl.estimators_):
ax = fig.add_subplot(2,3,i+1)
txt = 'Tree {}'.format(i+1)
glowyr.plot_model_pred_2d(estimator, x_train, y_train, title=txt)
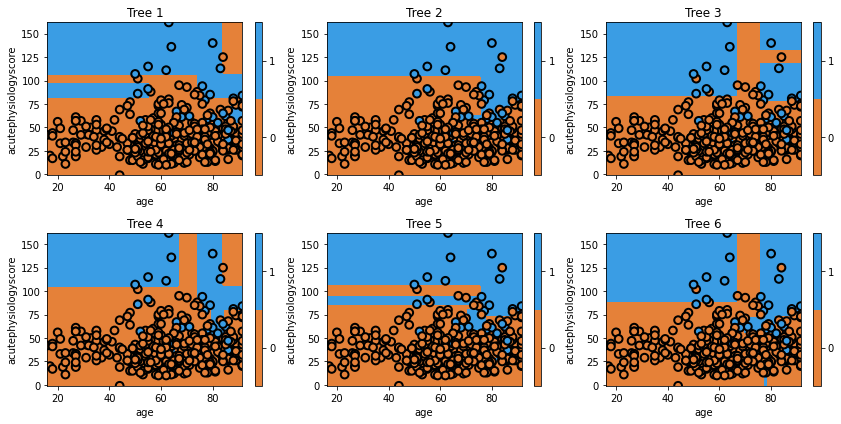
We can see that each individual tree varies considerably. This is a result of using a random set of data to train the classifier.
# plot the final prediction
plt.figure(figsize=[8,5])
txt = 'Bagged tree (final decision surface)'
glowyr.plot_model_pred_2d(mdl, x_train, y_train, title=txt)
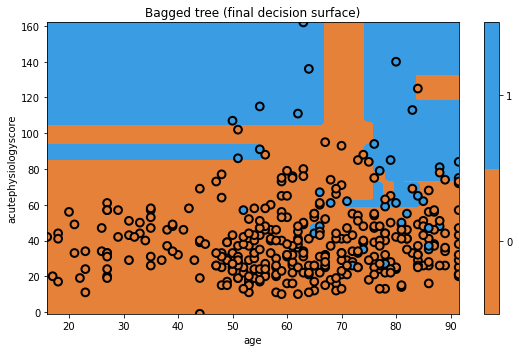
Not bad! Of course, since this is a simple dataset, we are not seeing that many dramatic changes between different models. Don’t worry, we’ll quantitatively evaluate them later.
Next up, a minor addition creates one of the most popular models in machine learning.
Key Points
“Bagging” is short name for bootstrap aggregation.
Bootstrapping is a data resampling technique.
Bagging is another method for combining multiple weak learners to create a strong learner.