Attacks
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How can models be intentionally mislead?
Objectives
Understand the concept of adversarial attacks.
Manipulation of models
It is important to be aware that models are susceptible to manipulation by targeted attacks. A model is susceptible to attack if it can be manipulated to produce an unexpected output. Currently most examples of models being mislead are theoretical - and often humourous - but this is likely to change as the stakes increase. These examples also demonstrate the fragility of models. It is not difficult to see how an algorithm-led system could reach an incorrect decision simply due to an unusual event.
Adversarial attacks
One common method for attack is to alter input data to intentionally cause misclassification. Researchers at Google, for example, demonstrated that they could generate a sticker that could trick a machine learning model into confusing a picture of a banana with a toaster.
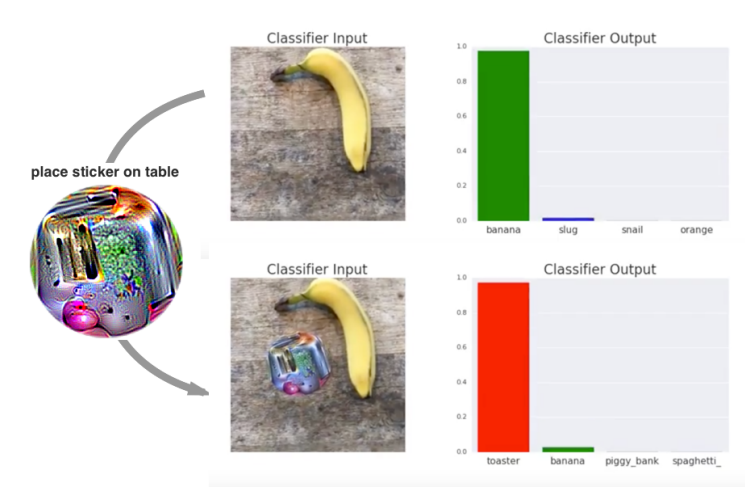
While the “adversarial patch” requires significant effort to fool the algorithm, researchers at OpenAI discovered that their image classification model could be fooled by nothing more than a pen and paper. They announced that a model that they had developed for classifying images would “respond to the same concept whether presented literally, symbolically, or conceptually. As a result, they demonstrated some surprising results in the application of the model.
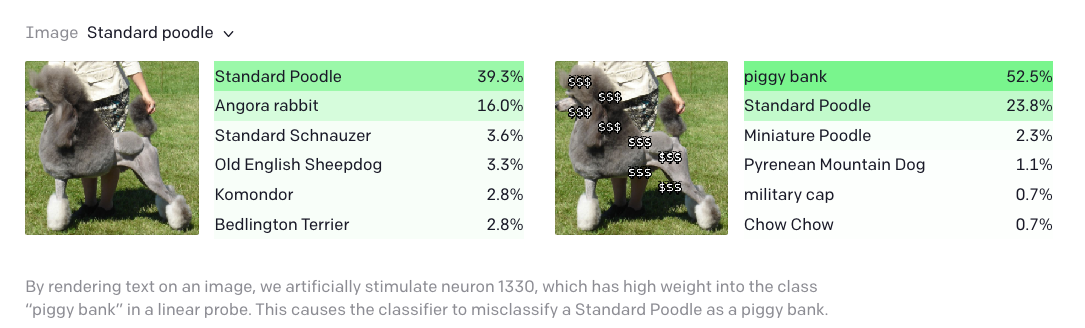
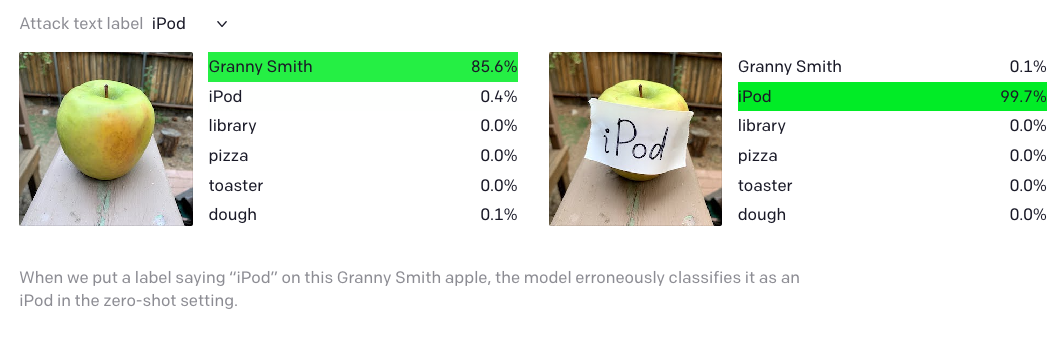
Key Points
Models are susceptible to manipulation.