Explainability
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is explainability?
Is explainability necessary?
Objectives
Understand the concepts of explainability and interpretability.
Understand how saliency maps can help us to explain a model.
Interpretability and explainability
“Interpretable” and “explainable” are terms that are often used interchangeably to describe the characteristic of a machine learning model to be understood. In recent literature, however, interpretable is perhaps more often used to refer to models with limited complexity and predictable behaviour. For example, a decision tree may be inherently interpretable:
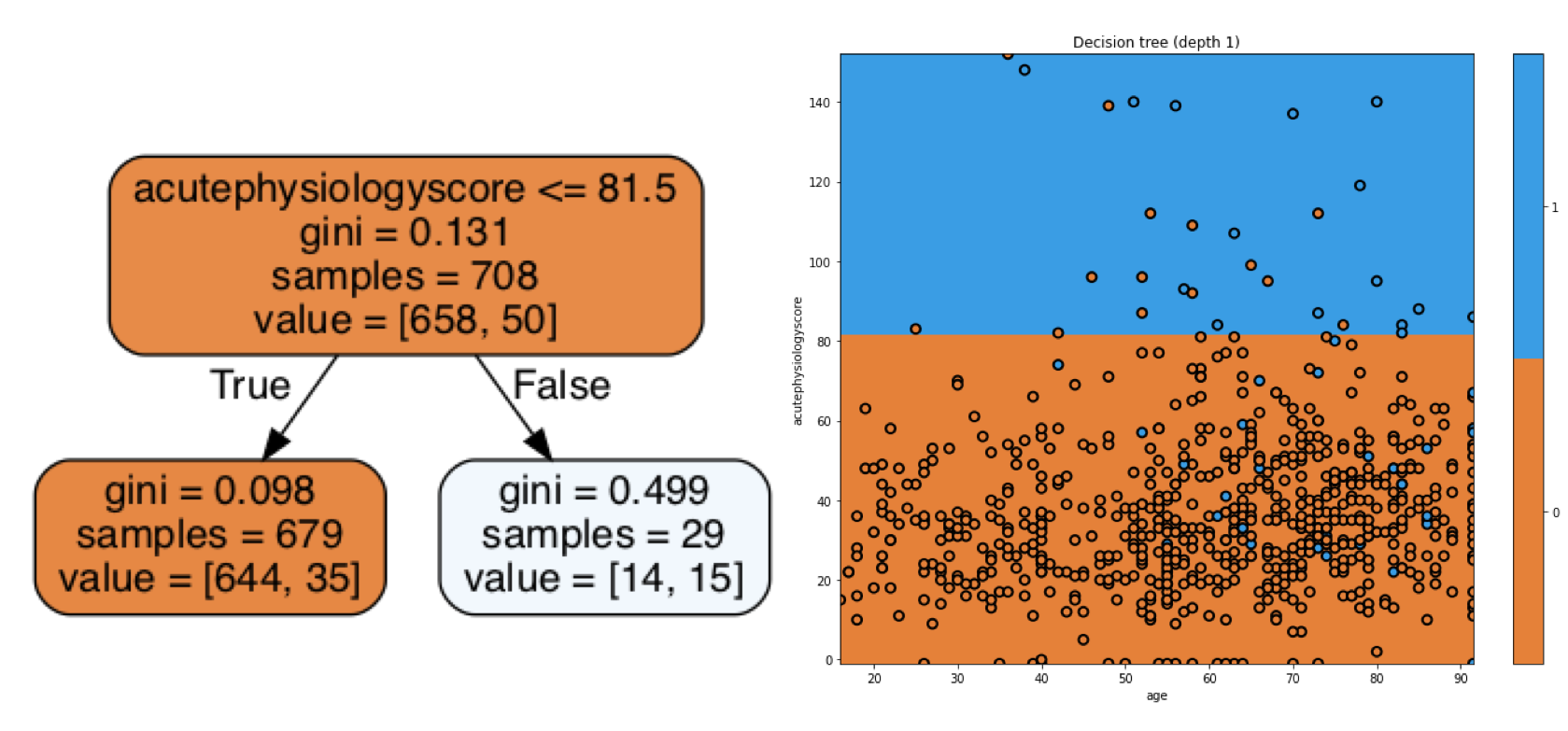
If we can look at our model and predict what will happen to our prediction if input values change, then we can say that the model is interpretable. Often, however, data and models are too complex and high-dimensional to be easily understood. They cannot be explained by a simple relationship between inputs and outputs.
For these complex models there is typically a focus on attempting to dissect the model’s decision making procedure. This insights lead us to explainability: our ability to gaze into a complex model and explain its behaviour.
The necessity of interpretability and explainability
If a model is making a prediction, many of us would like to know how the decision was reached. With this understanding, we gain trust. Doshi-Velez and Kim suggest that interpretablity (/explainablity) can assist in ascertaining presence of desired features such as fairness, privacy, reliability, robustness, causality, usability and trust:
- Fairness: that groups are not discriminated against.
- Privacy: that sensitive information is not revealed.
- Reliability and robustness: that models reach certain levels of performance despite parameter or input variation.
- Causality: that predicted changes in output due to a perturbation will occur as expected.
- Usability: that methods provide information that assist users to accomplish a task.
In machine learning in health, it has been argued that explainable AI is necessary to gain trust with the health-care workforce, provide transparency into decision making processes, and to mitigate bias. As a counterpoint, Ghassemi and colleagues argue that urrent explainability methods are unlikely to achieve these goals for patient-level decision support.
Instead, they advocate for “rigorous internal and external validation of AI models as a more direct means of achieving the goals often associated with explainability”, and “caution against having explainability be a requirement for clinically deployed models”.
Saliency maps
Saliency maps - and related approaches - are popular form of explainability for imaging models. Saliency maps use color to illustrate the extent to which a region of an image contributes to a given decision. For example, when building neural network models to predict lung conditions (pleural effusion) we can see the model pays particular attention to certain areas of an image.
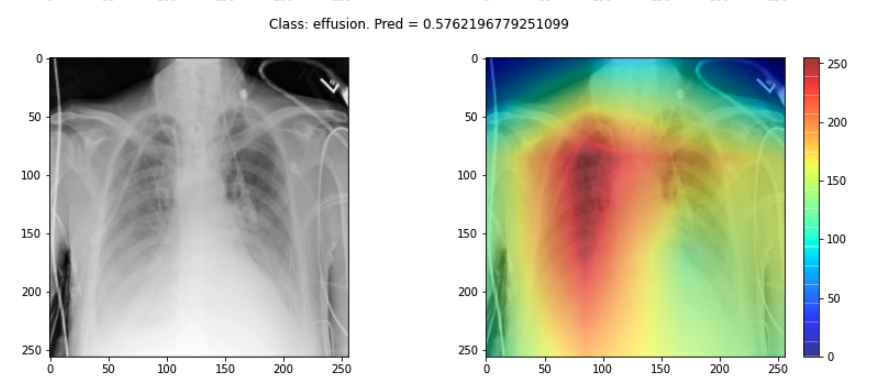
While saliency maps may be useful, they are also known to be problematic in many cases. Displaying a region of importance leaves us to decide what the explanation might be. The human tendency is to assume that the feature we would find important is the one that was used (this is an example of a famously harmful cognitive error called confirmation bias).
This problem is well summarised by computer scientist Cynthia Rudin: “You could have many explanations for what a complex model is doing. Do you just pick the one you ‘want’ to be correct? The ability of localisation methods to mislead human users is compellingly demonstrated by Adebayo and colleagues, who show that even untrained networks can produce saliency maps that appear reassuring.
Explainability of machine learning models
The requirement for explainability is even making its way into legal governance. The European Union General Data Protection (GDPR)) for example, states that “[the data subject should have] the right … to obtain an explanation of the decision reached”.
If our doctor or nurse recommends paracetamol (acetaminophen) for pain management, most of us would accept the suggestion without question. This is despite the action of paracetamol at a molecular level being unclear. Are we holding machine learning models to a higher standard than humans?
Key Points
The importance of explainability is a matter of debate.
Saliency maps highlight regions of data that most strongly contributed to a decision.