Getting Started with Conda
Overview
Teaching: 15 min
Exercises: 5 minQuestions
What is Conda?
Why should I use a package and environment management system as part of my research workflow?
Why use Conda ?
Objectives
Understand why you should use a package and environment management system as part of your (data) science workflow.
Explain the benefits of using Conda as part of your (data) science workflow.
Packages and Environments
Packages
When working with a programming language, such as Python, that can do almost anything, one has to wonder how this is possible. You download Python, it has about 25 MB, how can everthing be included in this small data package. The answer is - it is not. Python, as well as many other programming languages use external libraries or packages for being able to doing almost anything. You can see this already when you start programming. After learning some very basics, you often learn how to import something into your script or session.
Modules, packages, libraries
- Module: a collection of functions and variables, as in a script
- Package: a collection of modules with an init.py file (can be empty), as in a directory with scripts
- Library: a collection of packages with realted functionality
Library/Package are often used interchangeably.
Dependencies
A bit further into your programming career you may notice/have noticed that many packages do not just do everything on their own. Instead, they depend on other packages for their functionality. For example, the Scipy package is used for numerical routines. To not reinvent the wheel, the package makes use of other packages, such as numpy (numerical python) and matplotlib (plotting) and many more. So we say that numpy and matplotlib are dependencies of Scipy.
Many packages are being further developed all the time, generating different versions of packages. During development it may happen that a function call changes and/or functionalities are added or removed. If one package can depend on another, this may create issues. Therefore it is not only important to know that e.g. Scipy depends on numpy and matplotlib, but also that it depends on numpy version >= 1.6 and matplotlib version >= 1.1. Numpy version 1.5 in this case would not be sufficient.
Environments
When starting with programming we may not use many packages yet and the installation may be straightforward. But for most people, there comes a time when one version of a package or also the programming language is not enough anymore. You may find an older tool that depends on an older version of your programming language (e.g. Pyhton 2.7), but many of your other tools depend on a newer version (e.g. Python 3.6). You could now start up another computer or virtual machine to run the other version of the programming language, but this is not very handy, since you may want to use the tools together in a workflow later on. Here, environments are one solution to the problem. Nowadays there are several environment management systems following a similar idea: Instead of having to use multiple computers or virtual machines to run different versions of the same package, you can install packages in isolated environments.
Environment management
An environment management system solves a number of problems commonly encountered by (data) scientists.
- An application you need for a research project requires different versions of your base programming language or different versions of various third-party packages from the versions that you are currently using.
- An application you developed as part of a previous research project that worked fine on your system six months ago now no longer works.
- Code that was written for a joint research project works on your machine but not on your collaborators’ machines.
- An application that you are developing on your local machine doesn’t provide the same results when run on your remote cluster.
An environment management system enables you to set up a new, project specific software environment containing specific Python versions as well as the versions of additional packages and required dependencies that are all mutually compatible.
- Environment management systems help resolve dependency issues by allowing you to use different versions of a package for different projects.
- Make your projects self-contained and reproducible by capturing all package dependencies in a single requirements file.
- Allow you to install packages on a host on which you do not have admin privileges.
Environment management systems for Python
Conda is not the only way; Python for example has many more ways of working with environments:
Package management
A good package management system greatly simplifies the process of installing software by…
- identifying and installing compatible versions of software and all required dependencies.
- handling the process of updating software as more recent versions become available.
If you use some flavor of Linux, then you are probably familiar with the package manager for your
Linux distribution (i.e., apt on Ubuntu, yum on CentOS); if you are a Mac OSX user then you
might be familiar with the Home Brew Project which brings a Linux-like package
management system to Mac OS; if you are a Windows OS user, then you may not be terribly familiar
with package managers as there isn’t really a standard package manager for Windows (although there
is the Chocolatey Project).
Operating system package management tools are great but these tools actually solve a more general problem than you often face as a (data) scientist. As a (data) scientist you typically use one or two core scripting languages (i.e., Python, R, SQL). Each scripting language has multiple versions that can potentially be installed and each scripting language will also have a large number of third-party packages that will need to be installed. The exact version of your core scripting language(s) and additional, third-party packages will also probably change from project to project.
Package management systems for Python
Also here, Conda is not the only way; Python for example has many more ways of working with packages:
Why should I use a package and environment management system?
Installing software is hard. Installing scientific software is often even more challenging. In order to minimize the burden of installing and updating software (data) scientists often install software packages that they need for their various projects system-wide.
Installing software system-wide has a number of drawbacks:
- It can be difficult to figure out what software is required for any particular research project.
- It is often impossible to install different versions of the same software package at the same time.
- Updating software required for one project can often “break” the software installed for another project.
Put differently, installing software system-wide creates complex dependencies between your research projects that shouldn’t really exist!
Rather than installing software system-wide, wouldn’t it be great if we could install software separately for each research project?
Discussion
What are some of the potential benefits from installing software separately for each project? What are some of the potential costs?
Solution
You may notice that many of the potential benefits from installing software separately for each project require the ability to isolate the projects’ software environments from one another (i.e., solve the environment management problem). Once you have figured out how to isolate project-specific software environments, you will still need to have some way to manage software packages appropriately (i.e., solve the package management problem).
What I hope you will have taken away from the discussion exercise is an appreciation for the fact that in order to install project-specific software environments you need to solve two complementary challenges: environment management and package management.
Conda
From the official Conda documentation. Conda is an open source package and environment management system that runs on Windows, Mac OS and Linux.
- Conda can quickly install, run, and update packages and their dependencies.
- Conda can create, save, load, and switch between project specific software environments on your local computer.
- Although Conda was created for Python programs, Conda can package and distribute software for any language such as R, Ruby, Lua, Scala, Java, JavaScript, C, C++, FORTRAN.
Conda as a package manager helps you find and install packages. If you need a package that requires a different version of Python, you do not need to switch to a different environment manager, because Conda is also an environment manager. With just a few commands, you can set up a totally separate environment to run that different version of Python, while continuing to run your usual version of Python in your normal environment.
Conda vs. Miniconda vs. Anaconda
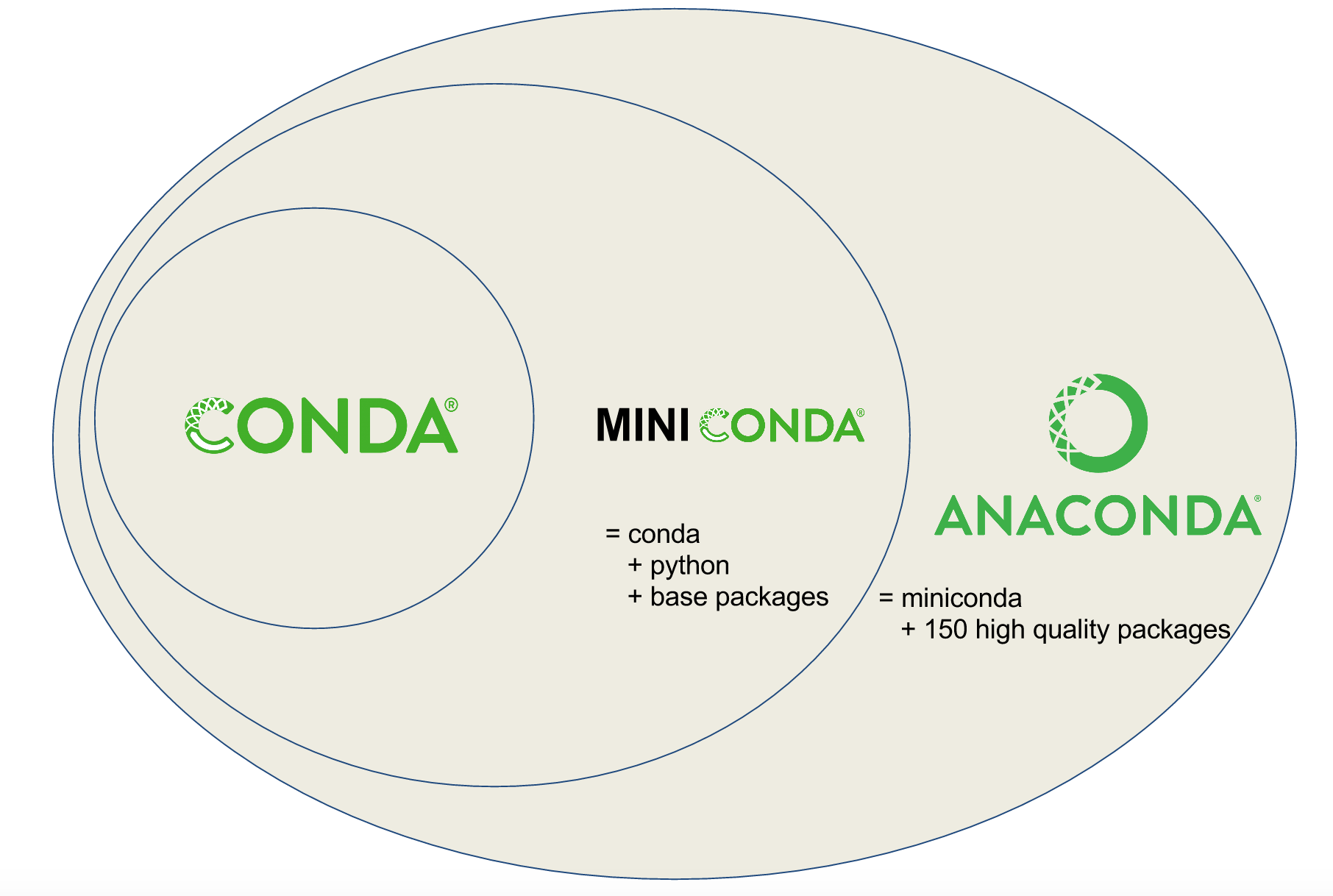
Users are often confused about the differences between Conda, Miniconda, and Anaconda. Conda is a tool for managing environments and installing packages. Miniconda combines Conda with Python and a small number of core packages; Anaconda includes Miniconda as well as a large number of the most widely used Python packages.
Why use Conda?
Whilst there are many different package and environment management systems that solve either the package management problem or the environment management problem, Conda solves both of these problems and explicitly targeted at (data) science use cases.
- Conda provides prebuilt packages, avoiding the need to deal with compilers, or trying to work out how exactly to set up a specific tool. Fields such as Astronomy use conda to distribute some of their most difficult-to-install tools such as IRAF. TensorFlow is another tool where to install it from source is near impossible, but Conda makes this a single step.
- Conda is cross platform, with support for Windows, MacOS, GNU/Linux, and support for multiple hardware platforms, such as x86 and Power 8 and 9. In future lessons we will show how to make your environment reproducible (reproducibility being one of the major issues facing science), and Conda allows you to provide your environment to other people across these different platforms.
- Conda allows for using other package management tools (such as
pip) inside Conda environments, where a library or tools is not already packaged for Conda (we’ll show later how to get access to more conda packages via channels).
Additionally, Anaconda provides commonly used data science libraries and tools, such as R, NumPy, SciPy and TensorFlow built using optimised, hardware specific libraries (such as Intel’s MKL or NVIDIA’s CUDA), which provides a speedup without having to change any of your code.
Key Points
Conda is a platform agnostic, open source package and environment management system.
Using a package and environment management tool facilitates portability and reproducibility of (data) science workflows.
Conda solves both the package and environment management problems and targets multiple programming languages. Other open source tools solve either one or the other, or target only a particular programming language.
Anaconda is not only for Python