Automated Version Control
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What is version control and why should I use it?
Objectives
Understand the benefits of an automated version control system.
Understand the basics of how Git works.
We’ll start by exploring how version control can be used to keep track of what one person did and when. Even if you aren’t collaborating with other people, automated version control is much better than this situation:

“Piled Higher and Deeper” by Jorge Cham, http://www.phdcomics.com
We’ve all been in this situation before: it seems ridiculous to have multiple nearly-identical versions of the same document. Some word processors let us deal with this a little better, such as Microsoft Word’s Track Changes, Google Docs’ version history, or LibreOffice’s Recording and Displaying Changes.
Version control systems start with a base version of the document and then save just the changes you made at each step of the way. You can think of it as a tape: if you rewind the tape and start at the base document, then you can play back each change and end up with your latest version.

Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes onto the base document and getting different versions of the document. For example, two users can make independent sets of changes based on the same document.

Unless there are conflicts, you can even play two sets of changes onto the same base document.

A version control system is a tool that keeps track of these changes for us and helps us version and merge our files. It allows you to decide which changes make up the next version, called a commit, and keeps useful metadata about them. The complete history of commits for a particular project and their metadata make up a repository. Repositories can be kept in sync across different computers facilitating collaboration among different people.
The Long History of Version Control Systems
Automated version control systems are nothing new. Tools like RCS, CVS, or Subversion have been around since the early 1980s and are used by many large companies. However, many of these are now becoming considered as legacy systems due to various limitations in their capabilities. In particular, the more modern systems, such as Git and Mercurial are distributed, meaning that they do not need a centralized server to host the repository. These modern systems also include powerful merging tools that make it possible for multiple authors to work within the same files concurrently.
Paper Writing
Imagine you drafted an excellent paragraph for a paper you are writing, but later ruin it. How would you retrieve the excellent version of your conclusion? Is it even possible?
Imagine you have 5 co-authors. How would you manage the changes and comments they make to your paper? If you use LibreOffice Writer or Microsoft Word, what happens if you accept changes made using the
Track Changesoption? Do you have a history of those changes?
Key Points
Version control is like an unlimited ‘undo’.
Version control also allows many people to work in parallel.
Setting Up Git
Overview
Teaching: 35 min
Exercises: 0 minQuestions
How do I get set up to use Git?
Objectives
Configure
gitthe first time it is used on a computer.Understand the meaning of the
--globalconfiguration flag.
When we use Git on a new computer for the first time, we need to configure a few things. Below are a few examples of configurations we will set as we get started with Git:
- our name and email address,
- to colorize our output,
- what our preferred text editor is,
- and that we want to use these settings globally (i.e. for every project)
On a command line, Git commands are written as git verb,
where verb is what we actually want to do. So here is how
Dracula sets up his new laptop:
$ git config --global user.name "Vlad Dracula"
$ git config --global user.email "vlad@tran.sylvan.ia"
$ git config --global color.ui "auto"
Please use your own name and email address instead of Dracula’s. This user name and email will be associated with your subsequent Git activity, which means that any changes pushed to GitHub, BitBucket, GitLab or another Git host server in a later lesson will include this information.
Line Endings
As with other keys, when you hit the ‘return’ key on your keyboard, your computer encodes this input. For reasons that are long to explain, different operating systems use different character(s) to represent the end of a line. (You may also hear these referred to as newlines or line breaks.) Because git uses these characters to compare files, it may cause unexpected issues when editing a file on different machines.
You can change the way git recognizes and encodes line endings using the
core.autocrlfcommand togit config. The following settings are recommended:On OS X and Linux:
$ git config --global core.autocrlf inputAnd on Windows:
$ git config --global core.autocrlf trueYou can read more about this issue on this GitHub page.
For these lessons, we will be interacting with GitHub and so the email address used should be the same as the one used when setting up your GitHub account. If you are concerned about privacy, please review GitHub’s instructions for keeping your email address private.
If you elect to use a private email address with GitHub, then use that same email address for the user.email value, e.g. username@users.noreply.github.com replacing username with your GitHub one. You can change the email address later on by using the git config command again.
Dracula also has to set his favorite text editor, following this table:
| Editor | Configuration command |
|---|---|
| Atom | $ git config --global core.editor "atom --wait" |
| nano | $ git config --global core.editor "nano -w" |
| BBEdit (Mac, with command line tools) | $ git config --global core.editor "edit -w" |
| Sublime Text (Mac) | $ git config --global core.editor "subl -n -w" |
| Sublime Text (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/sublime text 3/sublime_text.exe' -w" |
| Sublime Text (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/sublime text 3/sublime_text.exe' -w" |
| Notepad++ (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Notepad++ (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Kate (Linux) | $ git config --global core.editor "kate" |
| Gedit (Linux) | $ git config --global core.editor "gedit --wait --new-window" |
| Scratch (Linux) | $ git config --global core.editor "scratch-text-editor" |
| emacs | $ git config --global core.editor "emacs" |
| vim | $ git config --global core.editor "vim" |
It is possible to reconfigure the text editor for Git whenever you want to change it.
Exiting Vim
Note that
vimis the default editor for many programs. If you haven’t usedvimbefore and wish to exit a session, typeEscthen:q!andEnter.
Git (2.28+) allows configuration of the name of the branch created when you
initialize any new repository. Dracula decides to use that feature to set it to main so
it matches the cloud service he will eventually use.
$ git config --global init.defaultBranch main
Default Git branch naming
Source file changes are associated with a “branch.” For new learners in this lesson, it’s enough to know that branches exist, and this lesson uses one branch.
By default, Git will create a branch calledmasterwhen you create a new repository withgit init(as explained in the next Episode). This term evokes the racist practice of human slavery and the software development community has moved to adopt more inclusive language.In 2020, most Git code hosting services transitioned to using
mainas the default branch. As an example, any new repository that is opened in GitHub and GitLab default tomain. However, Git has not yet made the same change. As a result, local repositories must be manually configured have the same main branch name as most cloud services.For versions of Git prior to 2.28, the change can be made on an individual repository level. The command for this is in the next episode. Note that if this value is unset in your local Git configuration, the
init.defaultBranchvalue defaults tomaster.
The five commands we just ran above only need to be run once: the flag --global tells Git
to use the settings for every project, in your user account, on this computer.
You can check your settings at any time:
$ git config --list
You can change your configuration as many times as you want: just use the same commands to choose another editor or update your email address.
SSH Background and Setup
Before Dracula can connect to a remote repository, he needs to set up a way for his computer to authenticate with GitHub so it knows it’s him trying to connect to his remote repository.
We are going to set up the method that is commonly used by many different services to authenticate access on the command line. This method is called Secure Shell Protocol (SSH). SSH is a cryptographic network protocol that allows secure communication between computers using an otherwise insecure network.
SSH uses what is called a key pair. This is two keys that work together to validate access. One key is publicly known and called the public key, and the other key called the private key is kept private. Very descriptive names.
You can think of the public key as a padlock, and only you have the key (the private key) to open it. You use the public key where you want a secure method of communication, such as your GitHub account. You give this padlock, or public key, to GitHub and say “lock the communications to my account with this so that only computers that have my private key can unlock communications and send git commands as my GitHub account.”
What we will do now is the minimum required to set up the SSH keys and add the public key to a GitHub account.
The first thing we are going to do is check if this has already been done on the computer you’re on. Because generally speaking, this setup only needs to happen once and then you can forget about it.
Keeping your keys secure
You shouldn’t really forget about your SSH keys, since they keep your account secure. It’s good practice to audit your secure shell keys every so often. Especially if you are using multiple computers to access your account.
We will run the list command to check what key pairs already exist on your computer.
ls -al ~/.ssh
Your output is going to look a little different depending on whether or not SSH has ever been set up on the computer you are using.
Dracula has not set up SSH on his computer, so his output is
ls: cannot access '/c/Users/Vlad Dracula/.ssh': No such file or directory
If SSH has been set up on the computer you’re using, the public and private key pairs will be listed. The file names are either id_ed25519/id_ed25519.pub or id_rsa/id_rsa.pub depending on how the key pairs were set up.
Since they don’t exist on Dracula’s computer, he uses this command to create them.
Create an SSH key pair
To create an SSH key pair Vlad uses this command, where the -t option specifies which type of algorithm to use and -C attaches a comment to the key (here, Vlad’s email):
$ ssh-keygen -t ed25519 -C "vlad@tran.sylvan.ia"
Ed25519 algorithm on legacy system
If you are using a legacy system that doesn’t support the Ed25519 algorithm, use: $ ssh-keygen -t rsa -b 4096 -C “your_email@example.com”
Generating public/private ed25519 key pair.
Enter file in which to save the key (/c/Users/Vlad Dracula/.ssh/id_ed25519):
We want to use the default file, so just press Enter.
Created directory '/c/Users/Vlad Dracula/.ssh'.
Enter passphrase (empty for no passphrase):
Now, it is prompting Dracula for a passphrase. Since he is using his lab’s laptop that other people sometimes have access to, he wants to create a passphrase. Be sure to use something memorable or save your passphrase somewhere, as there is no “reset my password” option.
Note: The unix shell won’t show anything when you type in your password, not even placeholders!
Enter same passphrase again:
After entering the same passphrase a second time, we receive the confirmation
Your identification has been saved in /c/Users/Vlad Dracula/.ssh/id_ed25519
Your public key has been saved in /c/Users/Vlad Dracula/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:SMSPIStNyA00KPxuYu94KpZgRAYjgt9g4BA4kFy3g1o vlad@tran.sylvan.ia
The key's randomart image is:
+--[ED25519 256]--+
|^B== o. |
|%*=.*.+ |
|+=.E =.+ |
| .=.+.o.. |
|.... . S |
|.+ o |
|+ = |
|.o.o |
|oo+. |
+----[SHA256]-----+
The “identification” is actually the private key. You should never share it. The public key is appropriately named. The “key fingerprint” is a shorter version of a public key.
Now that we have generated the SSH keys, we will find the SSH files when we check.
ls -al ~/.ssh
drwxr-xr-x 1 Vlad Dracula 197121 0 Jul 16 14:48 ./
drwxr-xr-x 1 Vlad Dracula 197121 0 Jul 16 14:48 ../
-rw-r--r-- 1 Vlad Dracula 197121 419 Jul 16 14:48 id_ed25519
-rw-r--r-- 1 Vlad Dracula 197121 106 Jul 16 14:48 id_ed25519.pub
Copy the public key to GitHub
Now we have a SSH key pair and we can run this command to check if GitHub can read our authentication.
ssh -T git@github.com
The authenticity of host 'github.com (192.30.255.112)' can't be established.
RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? y
Please type 'yes', 'no' or the fingerprint: yes
Warning: Permanently added 'github.com' (RSA) to the list of known hosts.
git@github.com: Permission denied (publickey).
Right, we forgot that we need to give GitHub our public key!
First, we need to copy the public key. Be sure to include the .pub at the end, otherwise you’re looking at the private key.
cat ~/.ssh/id_ed25519.pub
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDmRA3d51X0uu9wXek559gfn6UFNF69yZjChyBIU2qKI vlad@tran.sylvan.ia
Copy and paste in the unix shell
Have you tried to use your usual keyboard hotkeys for Copy and Paste in the Unix shell and found they didn’t work?
If you’re using GitBash in Windows, you can copy and paste using your mouse. Highlight the text you want to copy, then right click and select
copy. Similarly for paste, right click at the prompt and selectpaste.On Windows in GitBash, you can use
ctrl + INSERTto copy andShift + INSERTto paste.For many users on a mac, the
cmd + candcmd + vwork as expected in Terminal.Linux terminals will vary by distro, but try
Shift + ctrl + candShift + ctrl + vin Bash.
Now, going to GitHub.com, click on your profile icon in the top right corner to get the drop-down menu. Click “Settings,” then on the settings page, click “SSH and GPG keys,” on the left side “Account settings” menu. Click the “New SSH key” button on the right side. Now, you can add the title (Dracula uses the title “Vlad’s Lab Laptop” so he can remember where the original key pair files are located), paste your SSH key into the field, and click the “Add SSH key” to complete the setup.
Now that we’ve set that up, let’s check our authentication again from the command line.
$ ssh -T git@github.com
Hi Vlad! You've successfully authenticated, but GitHub does not provide shell access.
Good! This output confirms that the SSH key works as intended. We are now ready to push our work to the remote repository.
Proxy
If the network you are connected to uses a proxy, there is a chance that your last command failed with “Could not resolve hostname” as the error message. To solve this issue, you need to tell Git about the proxy:
$ git config --global http.proxy http://user:password@proxy.url $ git config --global https.proxy http://user:password@proxy.urlWhen you connect to another network that doesn’t use a proxy, you will need to tell Git to disable the proxy using:
$ git config --global --unset http.proxy $ git config --global --unset https.proxy
Password Managers
If your operating system has a password manager configured,
git pushwill try to use it when it needs your username and password. For example, this is the default behavior for Git Bash on Windows. If you want to type your username and password at the terminal instead of using a password manager, type:$ unset SSH_ASKPASSin the terminal, before you run
git push. Despite the name, git usesSSH_ASKPASSfor all credential entry, so you may want to unsetSSH_ASKPASSwhether you are using git via SSH or https.You may also want to add
unset SSH_ASKPASSat the end of your~/.bashrcto make git default to using the terminal for usernames and passwords.
Key Points
Use
git configto configure a user name, email address, editor, and other preferences once per machine.
Creating a Repository
Overview
Teaching: 10 min
Exercises: 0 minQuestions
Where does Git store information?
Objectives
Create a local Git repository.
Once Git is configured, we can start using it. Let’s create a directory for our work and then move into that directory:
$ mkdir planets
$ cd planets
Then we tell Git to make planets a repository—a place where
Git can store versions of our files:
$ git init
If we use ls to show the directory’s contents,
it appears that nothing has changed:
$ ls
But if we add the -a flag to show everything,
we can see that Git has created a hidden directory within planets called .git:
$ ls -a
. .. .git
Git stores information about the project in this special sub-directory. If we ever delete it, we will lose the project’s history.
Next, we will change the default branch to be called main.
This might be the default branch depending on your settings and version
of git.
See the setup episode for more information on this change.
git checkout -b main
Switched to a new branch 'main'
We can check that everything is set up correctly by asking Git to tell us the status of our project:
$ git status
If you are using a different version of git than I am, then then the exact wording of the output might be slightly different.
# On branch main
#
# Initial commit
#
nothing to commit (create/copy files and use "git add" to track)
Places to Create Git Repositories
Dracula starts a new project,
moons, related to hisplanetsproject. Despite Wolfman’s concerns, he enters the following sequence of commands to create one Git repository inside another:$ cd # return to home directory $ mkdir planets # make a new directory planets $ cd planets # go into planets $ git init # make the planets directory a Git repository $ mkdir moons # make a sub-directory planets/moons $ cd moons # go into planets/moons $ git init # make the moons sub-directory a Git repositoryWhy is it a bad idea to do this? (Notice here that the
planetsproject is now also tracking the entiremoonsrepository.) How can Dracula undo his lastgit init?Solution
Git repositories can interfere with each other if they are “nested” in the directory of another: the outer repository will try to version-control the inner repository. Therefore, it’s best to create each new Git repository in a separate directory. To be sure that there is no conflicting repository in the directory, check the output of
git status. If it looks like the following, you are good to go to create a new repository as shown above:$ git statusfatal: Not a git repository (or any of the parent directories): .gitNote that we can track files in directories within a Git:
$ touch moon phobos deimos titan # create moon files $ cd .. # return to planets directory $ ls moons # list contents of the moons directory $ git add moons/* # add all contents of planets/moons $ git status # show moons files in staging area $ git commit -m "add moon files" # commit planets/moons to planets Git repositorySimilarly, we can ignore (as discussed later) entire directories, such as the
moonsdirectory:$ nano .gitignore # open the .gitignore file in the text editor to add the moons directory $ cat .gitignore # if you run cat afterwards, it should look like this:moonsTo recover from this little mistake, Dracula can just remove the
.gitfolder in the moons subdirectory. To do so he can run the following command from inside the ‘moons’ directory:$ rm -rf moons/.gitBut be careful! Running this command in the wrong directory, will remove the entire git-history of a project you might wanted to keep. Therefore, always check your current directory using the command
pwd.
Key Points
git initinitializes a repository.
Tracking Changes
Overview
Teaching: 20 min
Exercises: 0 minQuestions
How do I record changes in Git?
How do I check the status of my version control repository?
How do I record notes about what changes I made and why?
Objectives
Go through the modify-add-commit cycle for one or more files.
Explain where information is stored at each stage of that cycle.
Distinguish between descriptive and non-descriptive commit messages.
First let’s make sure we’re still in the right directory.
You should be in the planets directory.
$ pwd
If you are still in moons navigate back up to planets
$ cd ..
Let’s create a file called mars.txt that contains some notes
about the Red Planet’s suitability as a base.
We’ll use nano to edit the file;
you can use whatever editor you like.
In particular, this does not have to be the core.editor you set globally earlier. But remember, the bash command to create or edit a new file will depend on the editor you choose (it might not be nano). For a refresher on text editors, check out “Which Editor?” in The Unix Shell lesson.
$ nano mars.txt
Type the text below into the mars.txt file:
Cold and dry, but everything is my favorite color
mars.txt now contains a single line, which we can see by running:
$ ls
mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
If we check the status of our project again, Git tells us that it’s noticed the new file:
$ git status
On branch main
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
mars.txt
nothing added to commit but untracked files present (use "git add" to track)
The “untracked files” message means that there’s a file in the directory
that Git isn’t keeping track of.
We can tell Git to track a file using git add:
$ git add mars.txt
and then check that the right thing happened:
$ git status
On branch main
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: mars.txt
Git now knows that it’s supposed to keep track of mars.txt,
but it hasn’t recorded these changes as a commit yet.
To get it to do that,
we need to run one more command:
$ git commit -m "Start notes on Mars as a base"
[main (root-commit) f22b25e] Start notes on Mars as a base
1 file changed, 1 insertion(+)
create mode 100644 mars.txt
When we run git commit,
Git takes everything we have told it to save by using git add
and stores a copy permanently inside the special .git directory.
This permanent copy is called a commit
(or revision) and its short identifier is f22b25e
(Your commit may have another identifier.)
We use the -m flag (for “message”)
to record a short, descriptive, and specific comment that will help us remember later on what we did and why.
If we just run git commit without the -m option,
Git will launch nano (or whatever other editor we configured as core.editor)
so that we can write a longer message.
Good commit messages start with a brief (<50 characters) summary of changes made in the commit. If you want to go into more detail, add a blank line between the summary line and your additional notes.
If we run git status now:
$ git status
On branch main
nothing to commit, working directory clean
it tells us everything is up to date.
If we want to know what we’ve done recently,
we can ask Git to show us the project’s history using git log:
$ git log
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a base
git log lists all commits made to a repository in reverse chronological order.
The listing for each commit includes
the commit’s full identifier
(which starts with the same characters as
the short identifier printed by the git commit command earlier),
the commit’s author,
when it was created,
and the log message Git was given when the commit was created.
Where Are My Changes?
If we run
lsat this point, we will still see just one file calledmars.txt. That’s because Git saves information about files’ history in the special.gitdirectory mentioned earlier so that our filesystem doesn’t become cluttered (and so that we can’t accidentally edit or delete an old version).
Now suppose Dracula adds more information to the file.
(Again, we’ll edit with nano and then cat the file to show its contents;
you may use a different editor, and don’t need to cat.)
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
When we run git status now,
it tells us that a file it already knows about has been modified:
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")
The last line is the key phrase:
“no changes added to commit”.
We have changed this file,
but we haven’t told Git we will want to save those changes
(which we do with git add)
nor have we saved them (which we do with git commit).
So let’s do that now. It is good practice to always review
our changes before saving them. We do this using git diff.
This shows us the differences between the current state
of the file and the most recently saved version:
$ git diff
diff --git a/mars.txt b/mars.txt
index df0654a..315bf3a 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,2 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
The output is cryptic because
it is actually a series of commands for tools like editors and patch
telling them how to reconstruct one file given the other.
If we break it down into pieces:
- The first line tells us that Git is producing output similar to the Unix
diffcommand comparing the old and new versions of the file. - The second line tells exactly which versions of the file
Git is comparing;
df0654aand315bf3aare unique computer-generated labels for those versions. - The third and fourth lines once again show the name of the file being changed.
- The remaining lines are the most interesting, they show us the actual differences
and the lines on which they occur.
In particular,
the
+marker in the first column shows where we added a line.
After reviewing our change, it’s time to commit it:
$ git commit -m "Add concerns about effects of Mars' moons on Wolfman"
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")
Whoops:
Git won’t commit because we didn’t use git add first.
Let’s fix that:
$ git add mars.txt
$ git commit -m "Add concerns about effects of Mars' moons on Wolfman"
[main 34961b1] Add concerns about effects of Mars' moons on Wolfman
1 file changed, 1 insertion(+)
Git insists that we add files to the set we want to commit before actually committing anything. This allows us to commit our changes in stages and capture changes in logical portions rather than only large batches. For example, suppose we’re adding a few citations to relevant research to our thesis. We might want to commit those additions, and the corresponding bibliography entries, but not commit some of our work drafting the conclusion (which we haven’t finished yet).
To allow for this, Git has a special staging area where it keeps track of things that have been added to the current changeset but not yet committed.
Staging Area
If you think of Git as taking snapshots of changes over the life of a project,
git addspecifies what will go in a snapshot (putting things in the staging area), andgit committhen actually takes the snapshot, and makes a permanent record of it (as a commit). If you don’t have anything staged when you typegit commit, Git will prompt you to usegit commit -aorgit commit --all, which is kind of like gathering everyone for the picture! However, it’s almost always better to explicitly add things to the staging area, because you might commit changes you forgot you made. (Going back to snapshots, you might get the extra with incomplete makeup walking on the stage for the snapshot because you used-a!) Try to stage things manually, or you might find yourself searching for “git undo commit” more than you would like!

Let’s watch as our changes to a file move from our editor to the staging area and into long-term storage. First, we’ll add another line to the file:
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
$ git diff
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity
So far, so good:
we’ve added one line to the end of the file
(shown with a + in the first column).
Now let’s put that change in the staging area
and see what git diff reports:
$ git add mars.txt
$ git diff
There is no output: as far as Git can tell, there’s no difference between what it’s been asked to save permanently and what’s currently in the directory. However, if we do this:
$ git diff --staged
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity
it shows us the difference between the last committed change and what’s in the staging area. Let’s save our changes:
$ git commit -m "Discuss concerns about Mars' climate for Mummy"
[main 005937f] Discuss concerns about Mars' climate for Mummy
1 file changed, 1 insertion(+)
check our status:
$ git status
On branch main
nothing to commit, working directory clean
and look at the history of what we’ve done so far:
$ git log
commit 005937fbe2a98fb83f0ade869025dc2636b4dad5
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:14:07 2013 -0400
Discuss concerns about Mars' climate for Mummy
commit 34961b159c27df3b475cfe4415d94a6d1fcd064d
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:07:21 2013 -0400
Add concerns about effects of Mars' moons on Wolfman
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a base
Word-based diffing
Sometimes, e.g. in the case of the text documents a line-wise diff is too coarse. That is where the
--color-wordsoption ofgit diffcomes in very useful as it highlights the changed words using colors.
Paging the Log
When the output of
git logis too long to fit in your screen,gituses a program to split it into pages of the size of your screen. When this “pager” is called, you will notice that the last line in your screen is a:, instead of your usual prompt.
- To get out of the pager, press
q.- To move to the next page, press the space bar.
- To search for
some_wordin all pages, type/some_wordand navigate through matches pressingn.
Limit Log Size
To avoid having
git logcover your entire terminal screen, you can limit the number of commits that Git lists by using-N, whereNis the number of commits that you want to view. For example, if you only want information from the last commit you can use:$ git log -1commit 005937fbe2a98fb83f0ade869025dc2636b4dad5 Author: Vlad Dracula <vlad@tran.sylvan.ia> Date: Thu Aug 22 10:14:07 2013 -0400 Discuss concerns about Mars' climate for MummyYou can also reduce the quantity of information using the
--onelineoption:$ git log --oneline* 005937f Discuss concerns about Mars' climate for Mummy * 34961b1 Add concerns about effects of Mars' moons on Wolfman * f22b25e Start notes on Mars as a baseYou can also combine the
--onelineoptions with others. One useful combination is:$ git log --oneline --graph --all --decorate* 005937f Discuss concerns about Mars' climate for Mummy (HEAD, main) * 34961b1 Add concerns about effects of Mars' moons on Wolfman * f22b25e Start notes on Mars as a base
Directories
Two important facts you should know about directories in Git.
- Git does not track directories on their own, only files within them. Try it for yourself:
$ mkdir directory $ git status $ git add directory $ git statusNote, our newly created empty directory
directorydoes not appear in the list of untracked files even if we explicitly add it (viagit add) to our repository. This is the reason why you will sometimes see.gitkeepfiles in otherwise empty directories. Unlike.gitignore, these files are not special and their sole purpose is to populate a directory so that Git adds it to the repository. In fact, you can name such files anything you like.
- If you create a directory in your Git repository and populate it with files, you can add all files in the directory at once by:
git add <directory-with-files>
To recap, when we want to add changes to our repository,
we first need to add the changed files to the staging area
(git add) and then commit the staged changes to the
repository (git commit):

Choosing a Commit Message
Which of the following commit messages would be most appropriate for the last commit made to
mars.txt?
- “Changes”
- “Added line ‘But the Mummy will appreciate the lack of humidity’ to mars.txt”
- “Discuss effects of Mars’ climate on the Mummy”
Solution
Answer 1 is not descriptive enough, and answer 2 is too descriptive and redundant, but answer 3 is good: short but descriptive.
Committing Changes to Git
Which command(s) below would save the changes of
myfile.txtto my local Git repository?
$ git commit -m "my recent changes"
$ git init myfile.txt$ git commit -m "my recent changes"
$ git add myfile.txt$ git commit -m "my recent changes"
$ git commit -m myfile.txt "my recent changes"Solution
- Would only create a commit if files have already been staged.
- Would try to create a new repository.
- Is correct: first add the file to the staging area, then commit.
- Would try to commit a file “my recent changes” with the message myfile.txt.
Committing Multiple Files
The staging area can hold changes from any number of files that you want to commit as a single snapshot.
- Add some text to
mars.txtnoting your decision to consider Venus as a base- Create a new file
venus.txtwith your initial thoughts about Venus as a base for you and your friends- Add changes from both files to the staging area, and commit those changes.
Solution
First we make our changes to the
mars.txtandvenus.txtfiles:$ nano mars.txt $ cat mars.txtMaybe I should start with a base on Venus.$ nano venus.txt $ cat venus.txtVenus is a nice planet and I definitely should consider it as a base.Now you can add both files to the staging area. We can do that in one line:
$ git add mars.txt venus.txtOr with multiple commands:
$ git add mars.txt $ git add venus.txtNow the files are ready to commit. You can check that using
git status. If you are ready to commit use:$ git commit -m "Write plans to start a base on Venus"[main cc127c2] Write plans to start a base on Venus 2 files changed, 2 insertions(+) create mode 100644 venus.txt
Author and Committer
For each of the commits you have done, Git stored your name twice. You are named as the author and as the committer. You can observe that by telling Git to show you more information about your last commits:
$ git log --format=fullWhen committing you can name someone else as the author:
$ git commit --author="Vlad Dracula <vlad@tran.sylvan.ia>"Create a new repository and create two commits: one without the
--authoroption and one by naming a colleague of yours as the author. Rungit logandgit log --format=full. Think about ways how that can allow you to collaborate with your colleagues.Solution
$ git add me.txt $ git commit -m "Update Vlad's bio." --author="Frank N. Stein <franky@monster.com>"[main 4162a51] Update Vlad's bio. Author: Frank N. Stein <franky@monster.com> 1 file changed, 2 insertions(+), 2 deletions(-) $ git log --format=full commit 4162a51b273ba799a9d395dd70c45d96dba4e2ff Author: Frank N. Stein <franky@monster.com> Commit: Vlad Dracula <vlad@tran.sylvan.ia> Update Vlad's bio. commit aaa3271e5e26f75f11892718e83a3e2743fab8ea Author: Vlad Dracula <vlad@tran.sylvan.ia> Commit: Vlad Dracula <vlad@tran.sylvan.ia> Vlad's initial bio.
Key Points
git statusshows the status of a repository.Files can be stored in a project’s working directory (which users see), the staging area (where the next commit is being built up) and the local repository (where commits are permanently recorded).
git addputs files in the staging area.
git commitsaves the staged content as a new commit in the local repository.Always write a log message when committing changes.
Exploring History
Overview
Teaching: 25 min
Exercises: 0 minQuestions
How can I identify old versions of files?
How do I review my changes?
How can I recover old versions of files?
Objectives
Explain what the HEAD of a repository is and how to use it.
Identify and use Git commit numbers.
Compare various versions of tracked files.
Restore old versions of files.
As we saw in the previous lesson, we can refer to commits by their
identifiers. You can refer to the most recent commit of the working
directory by using the identifier HEAD.
We’ve been adding one line at a time to mars.txt, so it’s easy to track our
progress by looking, so let’s do that using our HEADs. Before we start,
let’s make a change to mars.txt.
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
An ill-considered change
Now, let’s see what we get.
$ git diff HEAD mars.txt
diff --git a/mars.txt b/mars.txt
index b36abfd..0848c8d 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,3 +1,4 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
+An ill-considered change.
which is the same as what you would get if you leave out HEAD (try it). The
real goodness in all this is when you can refer to previous commits. We do
that by adding ~1 to refer to the commit one before HEAD.
$ git diff HEAD~1 mars.txt
If we want to see the differences between older commits we can use git diff
again, but with the notation HEAD~1, HEAD~2, and so on, to refer to them:
$ git diff HEAD~2 mars.txt
diff --git a/mars.txt b/mars.txt
index df0654a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,4 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity
+An ill-considered change
We could also use git show which shows us what changes we made at an older commit as well as the commit message, rather than the differences between a commit and our working directory that we see by using git diff.
$ git show HEAD~2 mars.txt
commit 34961b159c27df3b475cfe4415d94a6d1fcd064d
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:07:21 2013 -0400
Start notes on Mars as a base
diff --git a/mars.txt b/mars.txt
new file mode 100644
index 0000000..df0654a
--- /dev/null
+++ b/mars.txt
@@ -0,0 +1 @@
+Cold and dry, but everything is my favorite color
In this way,
we can build up a chain of commits.
The most recent end of the chain is referred to as HEAD;
we can refer to previous commits using the ~ notation,
so HEAD~1 (pronounced “head minus one”)
means “the previous commit”,
while HEAD~123 goes back 123 commits from where we are now.
We can also refer to commits using
those long strings of digits and letters
that git log displays.
These are unique IDs for the changes,
and “unique” really does mean unique:
every change to any set of files on any computer
has a unique 40-character identifier.
Our first commit was given the ID
f22b25e3233b4645dabd0d81e651fe074bd8e73b,
so let’s try this:
$ git diff f22b25e3233b4645dabd0d81e651fe074bd8e73b mars.txt
diff --git a/mars.txt b/mars.txt
index df0654a..93a3e13 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,4 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity
+An ill-considered change
That’s the right answer, but typing out random 40-character strings is annoying, so Git lets us use just the first few characters:
$ git diff f22b25e mars.txt
diff --git a/mars.txt b/mars.txt
index df0654a..93a3e13 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,4 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidity
+An ill-considered change
All right! So we can save changes to files and see what we’ve changed—now how can we restore older versions of things? Let’s suppose we accidentally overwrite our file:
$ nano mars.txt
$ cat mars.txt
We will need to manufacture our own oxygen
git status now tells us that the file has been changed,
but those changes haven’t been staged:
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")
We can put things back the way they were
by using git checkout:
$ git checkout HEAD mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
As you might guess from its name,
git checkout checks out (i.e., restores) an old version of a file.
In this case,
we’re telling Git that we want to recover the version of the file recorded in HEAD,
which is the last saved commit.
If we want to go back even further,
we can use a commit identifier instead:
$ git checkout f22b25e mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
$ git status
# On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: mars.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
Notice that the changes are on the staged area.
Again, we can put things back the way they were
by using git checkout:
$ git checkout HEAD mars.txt
Don’t Lose Your HEAD
Above we used
$ git checkout f22b25e mars.txtto revert
mars.txtto its state after the commitf22b25e. If you forgetmars.txtin that command, Git will tell you that “You are in ‘detached HEAD’ state.” In this state, you shouldn’t make any changes. You can fix this by reattaching your head usinggit checkout main
It’s important to remember that
we must use the commit number that identifies the state of the repository
before the change we’re trying to undo.
A common mistake is to use the number of
the commit in which we made the change we’re trying to get rid of.
In the example below, we want to retrieve the state from before the most
recent commit (HEAD~1), which is commit f22b25e:

So, to put it all together, here’s how Git works in cartoon form:

Simplifying the Common Case
If you read the output of
git statuscarefully, you’ll see that it includes this hint:(use "git checkout -- <file>..." to discard changes in working directory)As it says,
git checkoutwithout a version identifier restores files to the state saved inHEAD. The double dash--is needed to separate the names of the files being recovered from the command itself: without it, Git would try to use the name of the file as the commit identifier.
The fact that files can be reverted one by one tends to change the way people organize their work. If everything is in one large document, it’s hard (but not impossible) to undo changes to the introduction without also undoing changes made later to the conclusion. If the introduction and conclusion are stored in separate files, on the other hand, moving backward and forward in time becomes much easier.
Recovering Older Versions of a File
Jennifer has made changes to the Python script that she has been working on for weeks, and the modifications she made this morning “broke” the script and it no longer runs. She has spent ~ 1hr trying to fix it, with no luck…
Luckily, she has been keeping track of her project’s versions using Git! Which commands below will let her recover the last committed version of her Python script called
data_cruncher.py?
$ git checkout HEAD
$ git checkout HEAD data_cruncher.py
$ git checkout HEAD~1 data_cruncher.py
$ git checkout <unique ID of last commit> data_cruncher.pyBoth 2 and 4
Reverting a Commit
Jennifer is collaborating on her Python script with her colleagues and realizes her last commit to the group repository is wrong and wants to undo it. Jennifer needs to undo correctly so everyone in the group repository gets the correct change.
git revert [wrong commit ID]will make a new commit that undoes Jennifer’s previous wrong commit. Thereforegit revertis different thangit checkout [commit ID]becausecheckoutis for local changes not committed to the group repository. Below are the right steps and explanations for Jennifer to usegit revert, what is the missing command?
____ # Look at the git history of the project to find the commit ID
Copy the ID (the first few characters of the ID, e.g. 0b1d055).
git revert [commit ID]Type in the new commit message.
Save and close
Understanding Workflow and History
What is the output of cat venus.txt at the end of this set of commands?
$ cd planets $ nano venus.txt #input the following text: Venus is beautiful and full of love $ git add venus.txt $ nano venus.txt #add the following text: Venus is too hot to be suitable as a base $ git commit -m "Comment on Venus as an unsuitable base" $ git checkout HEAD venus.txt $ cat venus.txt #this will print the contents of venus.txt to the screen1.
Venus is too hot to be suitable as a base2.
Venus is beautiful and full of love3.
Venus is beautiful and full of love Venus is too hot to be suitable as a base4.
Error because you have changed venus.txt without committing the changesSolution
Line by line:
$ cd planetsEnters into the ‘planets’ directory
$ nano venus.txt #input the following text: Venus is beautiful and full of loveWe created a new file and wrote a sentence in it, but the file is not tracked by git.
$ git add venus.txtNow the file is staged. The changes that have been made to the file until now will be committed in the next commit.
$ nano venus.txt #add the following text: Venus is too hot to be suitable as a baseThe file has been modified. The new changes are not staged because we have not added the file.
$ git commit -m "Comment on Venus as an unsuitable base"The changes that were staged (Venus is beautiful and full of love) have been committed. The changes that were not staged (Venus is too hot to be suitable as a base) have not. Our local working copy is different than the copy in our local repository.
$ git checkout HEAD venus.txtWith checkout we discard the changes in the working directory so that our local copy is exactly the same as our HEAD, the most recent commit.
$ cat venus.txt #this will print the contents of venus.txt to the screenIf we print venus.txt we will get answer 2.
Checking Understanding of
git diffConsider this command:
git diff HEAD~3 mars.txt. What do you predict this command will do if you execute it? What happens when you do execute it? Why?Try another command,
git diff [ID] mars.txt, where [ID] is replaced with the unique identifier for your most recent commit. What do you think will happen, and what does happen?
Getting Rid of Staged Changes
git checkoutcan be used to restore a previous commit when unstaged changes have been made, but will it also work for changes that have been staged but not committed? Make a change tomars.txt, add that change, and usegit checkoutto see if you can remove your change.
Explore and Summarize Histories
Exploring history is an important part of git, often it is a challenge to find the right commit ID, especially if the commit is from several months ago.
Imagine the
planetsproject has more than 50 files. You would like to find a commit with specific text inmars.txtis modified. When you typegit log, a very long list appeared, How can you narrow down the search?Recall that the
git diffcommand allow us to explore one specific file, e.g.git diff mars.txt. We can apply a similar idea here.$ git log mars.txtUnfortunately some of these commit messages are very ambiguous e.g.
update files. How can you search through these files?Both
git diffandgit logare very useful and they summarize a different part of the history for you. Is it possible to combine both? Let’s try the following:$ git log --patch mars.txtYou should get a long list of output, and you should be able to see both commit messages and the difference between each commit.
Question: What does the following command do?
$ git log --patch HEAD~3 *.txt
Key Points
git diffdisplays differences between commits.
git checkoutrecovers old versions of files.
Ignoring Things
Overview
Teaching: 5 min
Exercises: 0 minQuestions
How can I tell Git to ignore files I don’t want to track?
Objectives
Configure Git to ignore specific files.
Explain why ignoring files can be useful.
What if we have files that we do not want Git to track for us, like backup files created by our editor or intermediate files created during data analysis? Let’s create a few dummy files:
$ mkdir results
$ touch a.dat b.dat c.dat results/a.out results/b.out
and see what Git says:
$ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.dat
b.dat
c.dat
results/
nothing added to commit but untracked files present (use "git add" to track)
Putting these files under version control would be a waste of disk space. What’s worse, having them all listed could distract us from changes that actually matter, so let’s tell Git to ignore them.
We do this by creating a file in the root directory of our project called .gitignore:
$ nano .gitignore
$ cat .gitignore
*.dat
results/
These patterns tell Git to ignore any file whose name ends in .dat
and everything in the results directory.
(If any of these files were already being tracked,
Git would continue to track them.)
Once we have created this file,
the output of git status is much cleaner:
$ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
The only thing Git notices now is the newly-created .gitignore file.
You might think we wouldn’t want to track it,
but everyone we’re sharing our repository with will probably want to ignore
the same things that we’re ignoring.
Let’s add and commit .gitignore:
$ git add .gitignore
$ git commit -m "Add the ignore file"
$ git status
# On branch main
nothing to commit, working directory clean
As a bonus, using .gitignore helps us avoid accidentally adding to the repository files that we don’t want to track:
$ git add a.dat
The following paths are ignored by one of your .gitignore files:
a.dat
Use -f if you really want to add them.
If we really want to override our ignore settings,
we can use git add -f to force Git to add something. For example,
git add -f a.dat.
We can also always see the status of ignored files if we want:
$ git status --ignored
On branch main
Ignored files:
(use "git add -f <file>..." to include in what will be committed)
a.dat
b.dat
c.dat
results/
nothing to commit, working directory clean
Ignoring Nested Files
Given a directory structure that looks like:
results/data results/plotsHow would you ignore only
results/plotsand notresults/data?Solution
As with most programming issues, there are a few ways that you could solve this. If you only want to ignore the contents of
results/plots, you can change your.gitignoreto ignore only the/plots/subfolder by adding the following line to your .gitignore:
results/plots/If, instead, you want to ignore everything in
/results/, but wanted to trackresults/data, then you can addresults/to your .gitignore and create an exception for theresults/data/folder. The next challenge will cover this type of solution.Sometimes the
**pattern comes in handy, too, which matches multiple directory levels. E.g.**/results/plots/*would make git ignore theresults/plotsdirectory in any root directory.
Including Specific Files
How would you ignore all
.datafiles in your root directory except forfinal.data? Hint: Find out what!(the exclamation point operator) doesSolution
You would add the following two lines to your .gitignore:
*.data # ignore all data files !final.data # except final.dataThe exclamation point operator will include a previously excluded entry.
Ignoring all data Files in a Directory
Given a directory structure that looks like:
results/data/position/gps/a.data results/data/position/gps/b.data results/data/position/gps/c.data results/data/position/gps/info.txt results/plotsWhat’s the shortest
.gitignorerule you could write to ignore all.datafiles inresult/data/position/gps? Do not ignore theinfo.txt.Solution
Appending
results/data/position/gps/*.datawill match every file inresults/data/position/gpsthat ends with.data. The fileresults/data/position/gps/info.txtwill not be ignored.
The Order of Rules
Given a
.gitignorefile with the following contents:*.data !*.dataWhat will be the result?
Solution
The
!modifier will negate an entry from a previously defined ignore pattern. Because the!*.dataentry negates all of the previous.datafiles in the.gitignore, none of them will be ignored, and all.datafiles will be tracked.
Log Files
You wrote a script that creates many intermediate log-files of the form
log_01,log_02,log_03, etc. You want to keep them but you do not want to track them throughgit.
Write one
.gitignoreentry that excludes files of the formlog_01,log_02, etc.Test your “ignore pattern” by creating some dummy files of the form
log_01, etc.You find that the file
log_01is very important after all, add it to the tracked files without changing the.gitignoreagain.Discuss with your neighbor what other types of files could reside in your directory that you do not want to track and thus would exclude via
.gitignore.Solution
- append either
log_*orlog*as a new entry in your .gitignore- track
log_01usinggit add -f log_01
Key Points
The
.gitignorefile tells Git what files to ignore.
Branches
Overview
Teaching: 20 min
Exercises: 0 minQuestions
What are branches?
How can I work in parallel using branches?
Objectives
Understand why branches are useful for:
working on separate tasks in the same repository concurrently
trying multiple solutions to a problem
check-pointing versions of code
Merge branches back into the main branch
So far we’ve always been working in a straight timeline.
However, there are times when we might want to keep
our main work safe from experimental changes we are working on.
To do this we can use branches to work on separate tasks in parallel
without changing our current branch, main.
We didn’t see it before but the first branch made is called main.
This is the default branch created when initializing a repository and
is often considered to be the “clean” or “working” version of a
repository’s code.
We can see what branches exist in a repository by typing
$ git branch
* main
The ‘*’ indicates which branch we are currently on.
In this lesson, Dracula is trying to run an analysis and doesn’t know if it will be faster in bash or python. To keep his main branch safe he will use separate branches for both bash and python analysis. Then he will merge the branch with the faster script into his main branch.
First let’s make the python branch.
We use the same git branch command but now add the
name we want to give our new branch
$ git branch pythondev
We can now check our work with the git branch command.
$ git branch
* main
pythondev
We can see that we created the pythondev branch but we
are still in the main branch.
We can also see this in the output of the git status command.
$ git status
On branch main
nothing to commit, working directory clean
To switch to our new branch we can use the checkout command
we learned earlier and check our work with git branch.
$ git checkout pythondev
$ git branch
main
* pythondev
Before we used the checkout command to checkout a file from a specific commit
using commit hashes or HEAD and the filename (git checkout HEAD <file>). The
checkout command can also be used to checkout an entire previous version of the
repository, updating all files in the repository to match the state of a desired commit.
Branches allow us to do this using a human-readable name rather than memorizing
a commit hash. This name also typically gives purpose to the set of changes in
that branch. When we use the command git checkout <branch_name>, we are using
a nickname to checkout a version of the repository that matches the most recent
commit in that branch (a.k.a. the HEAD of that branch).
Here you can use git log and ls to see that the history and
files are the same as our main branch. This will be true until
some changes are committed to our new branch.
Now lets make our python script.
For simplicity sake, we will touch the script making an empty file
but imagine we spent hours working on this python script for our analysis.
$ touch analysis.py
Now we can add and commit the script to our branch.
$ git add analysis.py
$ git commit -m "Wrote and tested python analysis script"
[pythondev x792csa1] Wrote and tested python analysis script
1 file changed, 1 insertion(+)
create mode 100644 analysis.py
Lets check our work!
$ ls
$ git log --oneline
As expected, we see our commit in the log.
Now let’s switch back to the main branch.
$ git checkout main
$ git branch
* main
pythondev
Let’s explore the repository a bit.
Now that we’ve confirmed we are on the main branch again.
Let’s confirm that analysis.py and our last commit aren’t in main.
$ ls
$ git log --oneline
We no longer see the file analysis.py and our latest commit doesn’t
appear in this branch’s history. But do not fear! All of our hard work
remains in the pythondev branch. We can confirm this by moving back
to that branch.
$ git checkout pythondev
$ git branch
main
* pythondev
$ ls
$ git log --oneline
And we see that our analysis.py file and respective commit have been
preserved in the pythondev branch.
Now we can repeat the process for our bash script in a branch called
bashdev.
First we must checkout the main branch again. New branches will
include the entire history up to the current commit, and we’d like
to keep these two tasks separate.
$ git checkout main
$ git branch
* main
pythondev
This time let’s create and switch two the bashdev branch
in one command.
We can do so by adding the -b flag to checkout.
$ git checkout -b bashdev
$ git branch
* bashdev
main
pythonndev
We can use ls and git log to see that this branch is
the same as our current main branch.
Now we can make analysis.sh and add and commit it.
Again imagine instead of touching the file we worked
on it for many hours.
$ touch analysis.sh
$ git add analysis.sh
$ git commit -m "Wrote and tested bash analysis script"
[bashdev 2n779ds] Wrote and tested bash analysis script
1 file changed, 1 insertion(+)
create mode 100644 analysis.sh
Lets check our work again before we switch back to the main branch.
$ ls
$ git log --oneline
So it turns out the python analysis.py is much faster than analysis.sh.
Let’s merge this version into our main branch so we can use it for
our work going forward.
Merging brings the changes from a different branch into the current branch.
First we must switch to the branch we’re merging changes into, main.
$ git checkout main
$ git branch
bashdev
* main
pythonndev
Now we can merge the pythondev branch into our current branch
(main). In english, this command could be stated as “git, please
merge the changes in the pythondev branch into the current branch
I’m in”.
$ git merge pythondev
Updating 12687f6..x792csa1
Fast-forward
analysis.py | 0
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 analysis.py
Now that we’ve merged the pythondev into main, these changes
exist in both branches. This could be confusing in the future if we
stumble upon the pythondev branch again.
We can delete our old branches so as to avoid this confusion later.
We can do so by adding the -d flag to the git branch command.
git branch -d pythondev
Deleted branch pythondev (was x792csa1).
And because we don’t want to keep the changes in the bashdev branch,
we can delete the bashdev branch as well
$ git branch -d bashdev
error: The branch 'bashdev' is not fully merged.
If you are sure you want to delete it, run 'git branch -D bashdev'.
Since we’ve never merged the changes from the bashdev branch,
git warns us about deleting them and tells us to use the -D flag instead.
Since we really want to delete this branch we will go ahead and do so.
git branch -D bashdev
Deleted branch bashdev (was 2n779ds).
Key Points
Branches can be useful for developing while keeping the main line static.
Conflicts
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What do I do when my changes conflict?
Objectives
Explain what conflicts are and when they can occur.
Understand how to resolve conflicts resulting from a merge.
As soon as people can work in parallel, they’ll likely step on each other’s toes. This will even happen with a single person: if we are working on a piece of software on both our laptop and a server in the lab, we could make different changes to each copy. Version control helps us manage these conflicts by giving us tools to resolve overlapping changes.
To see how we can resolve conflicts, we must first create one. The
file mars.txt currently looks like this in our planets repository:
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
Let’s create a new branch for discussing Mars’ temperature and checkout that branch.
$ git branch marsTemp
But before we make changes related to Mars’ temperature in the marsTemp
branch, let’s add a line to Mars.txt here in the main branch.
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
I'll be able to get 40 extra minutes of beauty rest
and commit that change to the main branch
$ git add mars.txt
$ git commit -m "Add a line about the daylight on Mars."
[main 5ae9631] Add a line about the daylight on Mars.
1 file changed, 1 insertion(+)
We can then examine the commit history of the main branch.
$ git log --oneline
5ae9631 Add a line about the daylight on Mars.
005937f Discuss concerns about Mars' climate for Mummy
34961b1 Add concerns about effects of Mars' moons on Wolfman
f22b25e Start notes on Mars as a base
Now that we’ve made our changes in the main branch, let’s get to work on our comments about
the temperature in the marsTemp branch.
$ git checkout marsTemp
$ git branch
* marsTemp
main
Let’s make a note in mars.txt about the temperature. Note that when we open
this file the line we added about the daylight on Mars will not be present as
that change is not part of this branch.
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
Yeti will appreciate the cold
Now let’s commit this change to the marsTemp branch
$ git add mars.txt
$ git commit -m "Add a line about the temperature on Mars"
[main 07ebc69] Add a line about the temperature on Mars
1 file changed, 1 insertion(+)
Again, we can look at the history of this branch.
$ git log --oneline
07ebc69 Add a line about the temperature on Mars
005937f Discuss concerns about Mars' climate for Mummy
34961b1 Add concerns about effects of Mars' moons on Wolfman
f22b25e Start notes on Mars as a base
Notice that the commit related to Mars’ daylight is not present as it is part of the
mainbranch, not themarsTempbranch.
Now that we’ve added changes about the temperature
we can merge them into the main branch. First, let’s checkout the
main branch.
$ git checkout main
$ git branch
marsTemp
* main
And then merge the changes from marsTemp into our current branch, main.
$ git merge marsTemp
Auto-merging mars.txt
CONFLICT (content): Merge conflict in mars.txt
Automatic merge failed; fix conflicts and then commit the result.
Review the status of the repository now that we’ve been told merging has resulted in a conflict.
$ git status
On branch main
You have unmerged paths.
(fix conflicts and run "git commit")
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")

Git detects that the changes made in one copy overlap with those made in the other and stops us from trampling on our previous work. It also marks that conflict in the affected file:
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
<<<<<<< HEAD
I'll be able to get 40 extra minutes of beauty rest
=======
Yeti will appreciate the cold
>>>>>>> 07ebc69c450e8475aee9b14b4383acc99f42af1d
Our change—the one at the HEAD of the main branch—is preceded by <<<<<<<.
Git has then inserted ======= as a separator between the conflicting changes
and marked the end of our commit from the marsTemp branch with >>>>>>>.
(The string of letters and digits after that marker
identifies the commit we made in the marsTemp branch.)
It is now up to us to edit this file to remove these markers
and reconcile the changes.
We can do anything we want: keep the change made in the main branch, keep
the change made in the marsTemp branch, write something new to replace both,
or get rid of the change entirely.
Let’s keep both of these statements, as they are both valid regarding the Martian environment.
$ nano mars.txt
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
I'll be able to get 40 extra minutes of beauty rest
Yeti will appreciate the cold
To finish merging,
we add mars.txt to the changes being made by the merge
and then commit:
$ git add mars.txt
$ git status
On branch main
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: mars.txt
$ git commit -m "Merge changes from marsTemp"
[main 2abf2b1] Merge changes from marsTemp
Git keeps track of what we’ve merged with what, so we don’t have to fix things by hand again.
Let’s make another change to the marsTemp branch:
$ git checkout marsTemp
$ echo "The polar caps will probably be Yeti's home" >> mars.txt
$ git add mars.txt
$ git commit -m "A note about Yeti's home"
[main 34avo82] A note about Yeti's home
1 file changed, 1 insertion(+)
And merge that change into main branch
$ git checkout main
$ git merge marsTemp
Updating 12687f6..x792csa1
Fast-forward
mars.txt | 1 +
1 file changed, 1 insertions(+), 0 deletions(-)
There is no conflict and our changes are added automatically
Still seeing a conflict?
This exercise is dependent on how the merge conflict was resolved in our first merge of the marsTemp branch and may still result in a conflict when merging additional commits from the marsTemp branch.
$ cat mars.txt
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidity
I'll be able to get 40 extra minutes of beauty rest
Yeti will appreciate the cold
The polar caps will probably be Yeti's home
We don’t need to merge again because Git knows someone has already done that.
Git’s ability to resolve conflicts is very useful, but conflict resolution costs time and effort, and can introduce errors if conflicts are not resolved correctly. If you find yourself resolving a lot of conflicts in a project, consider these technical approaches to reducing them:
- Pull from upstream more frequently, especially before starting new work
- Use topic branches to separate work, merging to main when complete
- Make smaller more atomic commits
- Where logically appropriate, break large files into smaller ones so that it is less likely that two authors will alter the same file simultaneously
Conflicts can also be minimized with project management strategies:
- Try breaking large files apart into smaller files so that it is less likely that you will be working in the same file at the same time in different branches
- Create branches focused on separable tasks so that your work won’t overlap in files
- Clarify who is responsible for what areas with your collaborators
- Discuss what order tasks should be carried out in with your collaborators so that tasks that will change the same file won’t be worked on at the same time
Create a conflict between branches and resolve it
- Create a new branch off of the main branch
- Make a change to a file in the main branch
- Change to the new branch
- Make a change to the same line in the same file
- Change back to the main branch
- Merge the new branch into the main branch
- Address the resulting conflict in the text editor of your choice
- Add the file containing the conflict and commit conflict resolution to the repository
Solution
# to make sure we're starting in the main branch $ git checkout main # create a new branch, but don't change into it $ git branch new_branch # make a change to the file $ nano mars.txt # add changes in mars.txt to the staging area $ git add mars.txt $ git commit -m "Small change to mars.txt" # switch to the new branch $ git checkout new_branch # make a change to mars.txt on the same line $ nano mars.txt # add changes in mars.txt to the staging area $ git add mars.txt $ git commit -m "Another change to mars.txt" # change back to the main branch $ git checkout main # attempt to merge the branches $ git merge new_branch # address conflicts by removing `<<<`, `===`, and `>>>` lines leaving the desired changes intact $ nano mars.txt $ git add mars.txt $ git commit -m "Resolving conflict in mars.txt."
Key Points
Conflicts occur when files are changed in the same place in two commits that are being merged.
The version control system does not allow one to overwrite changes blindly during a merge, but highlights conflicts so that they can be resolved.
Remotes in GitHub
Overview
Teaching: 45 min
Exercises: 0 minQuestions
How do I share my changes with others on the web?
Objectives
Explain what remote repositories are and why they are useful.
Push to or pull from a remote repository.
Version control really comes into its own when we begin to collaborate with other people. We already have most of the machinery we need to do this; the only thing missing is to copy changes from one repository to another.
Systems like Git allow us to move work between any two repositories. In practice, though, it’s easiest to use one copy as a central hub, and to keep it on the web rather than on someone’s laptop. Most programmers use hosting services like GitHub, Bitbucket or GitLab to hold those main copies; we’ll explore the pros and cons of this in a later episode.
Let’s start by sharing the changes we’ve made to our current project with the world. To this end we are going to create a remote repository that will be linked to our local repository.
1. Create a remote repository
Log in to GitHub, then click on the icon in the top right corner to
create a new repository called planets:
Name your repository “planets” and then click “Create Repository”.
Note: Since this repository will be connected to a local repository, it needs to be empty. Leave “Initialize this repository with a README” unchecked, and keep “None” as options for both “Add .gitignore” and “Add a license.” See the “GitHub License and README files” exercise below for a full explanation of why the repository needs to be empty.
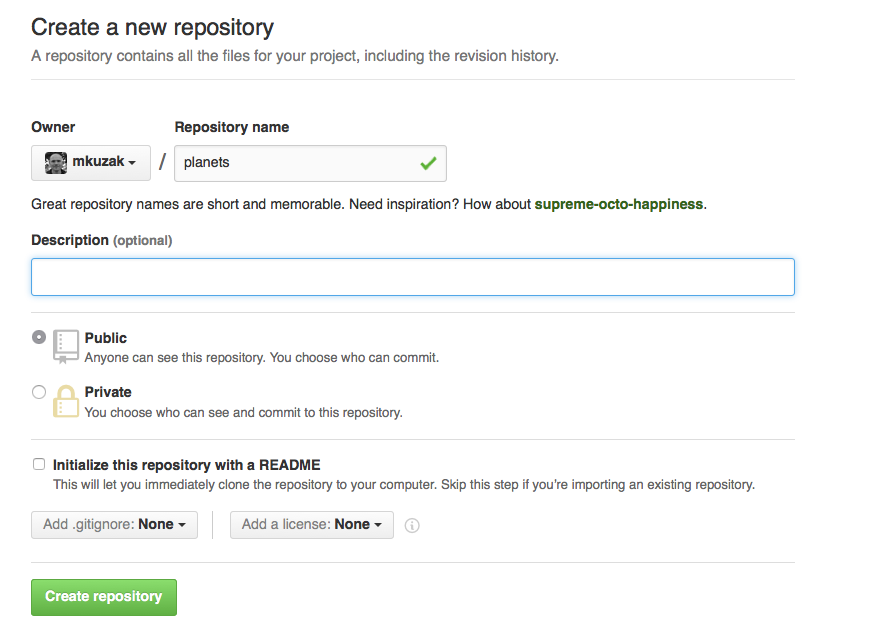
As soon as the repository is created, GitHub displays a page with a URL and some information on how to configure your local repository:
This effectively does the following on GitHub’s servers:
$ mkdir planets
$ cd planets
$ git init
If you remember back to the earlier episode where we added and
committed our earlier work on mars.txt, we had a diagram of the local repository
which looked like this:
Now that we have two repositories, we need a diagram like this:

Note that our local repository still contains our earlier work on mars.txt, but the
remote repository on GitHub appears empty as it doesn’t contain any files yet.
2. Connect local to remote repository
Now we connect the two repositories. We do this by making the GitHub repository a remote for the local repository. The home page of the repository on GitHub includes the URL string we need to identify it:

Click on the ‘SSH’ link to change the protocol from HTTPS to SSH.
HTTPS vs. SSH
We use SSH here because, while it requires some additional configuration, it is a security protocol widely used by many applications. Recall that we set up SSH in the setup episode.

Copy that URL from the browser, go into the local planets repository, and run
this command:
$ git remote add origin git@github.com:vlad/planets.git
Make sure to use the URL for your repository rather than Vlad’s: the only
difference should be your username instead of vlad.
origin is a local name used to refer to the remote repository. It could be called
anything, but origin is a convention that is often used by default in git
and GitHub, so it’s helpful to stick with this unless there’s a reason not to.
We can check that the command has worked by running git remote -v:
$ git remote -v
origin git@github.com:vlad/planets.git (fetch)
origin git@github.com:vlad/planets.git (push)
We’ll discuss remotes in more detail in the next episode, while talking about how they might be used for collaboration.
3. Push local changes to a remote
This command will push the changes from our local repository to the repository on GitHub:
$ git push origin main
Since Dracula set up a passphrase, it will prompt him for it. If you completed advanced settings for your authentication, it will not prompt for a passphrase.
Enumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 8 threads.
Compressing objects: 100% (11/11), done.
Writing objects: 100% (16/16), 1.45 KiB | 372.00 KiB/s, done.
Total 16 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), done.
To https://github.com/vlad/planets.git
* [new branch] main -> main
Proxy
If the network you are connected to uses a proxy, there is a chance that your last command failed with “Could not resolve hostname” as the error message. To solve this issue, you need to tell Git about the proxy:
$ git config --global http.proxy http://user:password@proxy.url $ git config --global https.proxy https://user:password@proxy.urlWhen you connect to another network that doesn’t use a proxy, you will need to tell Git to disable the proxy using:
$ git config --global --unset http.proxy $ git config --global --unset https.proxy
Password Managers
If your operating system has a password manager configured,
git pushwill try to use it when it needs your username and password. For example, this is the default behavior for Git Bash on Windows. If you want to type your username and password at the terminal instead of using a password manager, type:$ unset SSH_ASKPASSin the terminal, before you run
git push. Despite the name, Git usesSSH_ASKPASSfor all credential entry, so you may want to unsetSSH_ASKPASSwhether you are using Git via SSH or https.You may also want to add
unset SSH_ASKPASSat the end of your~/.bashrcto make Git default to using the terminal for usernames and passwords.
Our local and remote repositories are now in this state:

The ‘-u’ Flag
You may see a
-uoption used withgit pushin some documentation. This option is synonymous with the--set-upstream-tooption for thegit branchcommand, and is used to associate the current branch with a remote branch so that thegit pullcommand can be used without any arguments. To do this, simply usegit push -u origin mainonce the remote has been set up.
We can pull changes from the remote repository to the local one as well:
$ git pull origin main
From https://github.com/vlad/planets
* branch main -> FETCH_HEAD
Already up-to-date.
Pulling has no effect in this case because the two repositories are already synchronized. If someone else had pushed some changes to the repository on GitHub, though, this command would download them to our local repository.
GitHub GUI
Browse to your
planetsrepository on GitHub. Under the Code tab, find and click on the text that says “XX commits” (where “XX” is some number). Hover over, and click on, the three buttons to the right of each commit. What information can you gather/explore from these buttons? How would you get that same information in the shell?Solution
The left-most button (with the picture of a clipboard) copies the full identifier of the commit to the clipboard. In the shell,
git logwill show you the full commit identifier for each commit.When you click on the middle button, you’ll see all of the changes that were made in that particular commit. Green shaded lines indicate additions and red ones removals. In the shell we can do the same thing with
git diff. In particular,git diff ID1..ID2where ID1 and ID2 are commit identifiers (e.g.git diff a3bf1e5..041e637) will show the differences between those two commits.The right-most button lets you view all of the files in the repository at the time of that commit. To do this in the shell, we’d need to checkout the repository at that particular time. We can do this with
git checkout IDwhere ID is the identifier of the commit we want to look at. If we do this, we need to remember to put the repository back to the right state afterwards!
Uploading files directly in GitHub browser
Github also allows you to skip the command line and upload files directly to your repository without having to leave the browser. There are two options. First you can click the “Upload files” button in the toolbar at the top of the file tree. Or, you can drag and drop files from your desktop onto the file tree. You can read more about this on this GitHub page
GitHub Timestamp
Create a remote repository on GitHub. Push the contents of your local repository to the remote. Make changes to your local repository and push these changes. Go to the repo you just created on GitHub and check the timestamps of the files. How does GitHub record times, and why?
Solution
GitHub displays timestamps in a human readable relative format (i.e. “22 hours ago” or “three weeks ago”). However, if you hover over the timestamp, you can see the exact time at which the last change to the file occurred.
Push vs. Commit
In this episode, we introduced the “git push” command. How is “git push” different from “git commit”?
Solution
When we push changes, we’re interacting with a remote repository to update it with the changes we’ve made locally (often this corresponds to sharing the changes we’ve made with others). Commit only updates your local repository.
GitHub License and README files
In this episode we learned about creating a remote repository on GitHub, but when you initialized your GitHub repo, you didn’t add a README.md or a license file. If you had, what do you think would have happened when you tried to link your local and remote repositories?
Solution
In this case, we’d see a merge conflict due to unrelated histories. When GitHub creates a README.md file, it performs a commit in the remote repository. When you try to pull the remote repository to your local repository, Git detects that they have histories that do not share a common origin and refuses to merge.
$ git pull origin mainwarning: no common commits remote: Enumerating objects: 3, done. remote: Counting objects: 100% (3/3), done. remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (3/3), done. From https://github.com/vlad/planets * branch main -> FETCH_HEAD * [new branch] main -> origin/main fatal: refusing to merge unrelated historiesYou can force git to merge the two repositories with the option
--allow-unrelated-histories. Be careful when you use this option and carefully examine the contents of local and remote repositories before merging.$ git pull --allow-unrelated-histories origin mainFrom https://github.com/vlad/planets * branch main -> FETCH_HEAD Merge made by the 'recursive' strategy. README.md | 1 + 1 file changed, 1 insertion(+) create mode 100644 README.md
Key Points
A local Git repository can be connected to one or more remote repositories.
git pushcopies changes from a local repository to a remote repository.
git pullcopies changes from a remote repository to a local repository.
Pull Requests
Overview
Teaching: 60 min
Exercises: 15 minQuestions
What are pull requests for?
How can I make a pull request?
Objectives
Define the terms fork, clone, origin, remote, upstream
Understand how to make a pull request and what they are useful for
Pull requests are a great way to collaborate with others using github. Instead of making changes directly to a repository you can suggest changes to a repo. This can be useful if you don’t have permission to modify a repository directly or you want someone else to review your changes.
For this lesson we will be working on the countries repository together.
Open the github link for the countries repo provided by the instructor
in your browser window.
Repo owner differences
You may have noticed that the
countriesrepo in this lesson’s pictures is owned by the ‘McMahonLab’ organization and this doesn’t match the address you were given. This is to be expected because this will differ depending on what organization your instructor used to setup thecountriesrepo.You will also see your username where the ‘sstevens2’ is in the pictures.
Once at the countries repo, click the Fork button which can be found
in the upper right hand conner of the window.
Forking the repository makes us each our own copy of the repo in our github
account which we can edit.
Next we need to get this repo on our local computer and setup connections from our computer to both our forked version and the authoritative version we forked it from.
First we will clone the repo from our forked version. The clone command does two things:
- Copies the repo to your local computer
- Sets up a remote called ‘origin’ between your computer and the github repo
Copy the web address for your forked version of repo (from the web address line or click ‘Clone and download’ and copy that).
In terminal or Gitbash, navigate to a folder you’d like to hold this repo,
we will place it on our Desktop.
Once there you can use the clone command with the link you copied as the first argument.
$ cd ~/Desktop
$ git clone https://github.com/USERNAME/countries.git
Why does the command above say ‘USERNAME’?
So that we can’t copy the command above and accidentally clone someone else’s version of countries to our computer, the command above uses the placeholder ‘USERNAME’ where you should put your own username if your copied from above instead of copying the link from your browser and pasting it into the command.
Cloning into 'countries'...
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 6 (delta 0), pack-reused 0
Unpacking objects: 100% (6/6), done.
Next we will set up a connection or remote to the authoritative repository (the original version given to you by your instructor). In your browser, you can go back this repo by clicking on the link that says ‘forked from’ in the upper left hand corner, under your username and repo name.
Copy the web address for this repo (from the web address line or click the ‘clone and download’ and copy that).
Then back in your terminal, navigate into the cloned repo and add the remote connection to this repository. For this command we must give the remote a different nickname, where our original remote is ‘origin’ this new remote will be called ‘upstream’. You could give it a different nickname but ‘upstream’ is a common nickname for the authoritative repository.
$ cd countries
$ git remote add upstream https://github.com/INSTRUCTOR-GIVEN/countries.git
If you tried copying the command above…
You will have to replace ‘INSTRUCTOR-GIVEN’ with the site your instructor indicated at the beginning of this lesson. This will vary depending on how your instructor set up for this lesson.
At anytime you can see the remote connections your repo has using the following command:
$ git remote -v
origin https://github.com/USERNAME/countries.git (fetch)
origin https://github.com/USERNAME/countries.git (push)
upstream https://github.com/INSTRUCTOR-GIVEN/countries.git (fetch)
upstream https://github.com/INSTRUCTOR-GIVEN/countries.git (push)
Now that we have this setup done we will be able to suggest changes to this repo using a pull request. Each person will add a new file with info about a new country in it.
The instructor will now add a single file to the repository containing information about the the United States.
Next, we will update our local version of the repo to include the new file.
We use a command called pull to bring these changes to our local repository.
We must specify the remote and branch we want to pull from, in this case the
upstream remote’s main branch.
$ git pull upstream main
Now your local version of the repo is updated but our forked version of the
repo is not yet up to date.
You can reload your fork in github and see it does not contain the new
united_states.txt file.
Now we need to update our forked version.
To do so we can push the changes in our local version to the main branch of our fork,
called ‘origin’.
$ git push origin main
Now let’s each add a new country to the repository.
First let’s make a new branch to work on. This will keep our ‘main’ version
in sync with the authoritative version of the repository.
We can name our branch descriptively after the country we will be adding.
Mine will be addFrance since I’ll be working with France.
Please pick a different country and shout it out (or add it to the etherpad)
so no one else chooses the same one.
We will create the branch and switch into in one step
as we learned earlier in the branching lesson.
$ git checkout -b addFrance
Switched to a new branch 'addFrance'
Finally before we proceed to adding the new file, we will double check that we are on the right branch.
$ git branch
* addFrance
main
Next we will copy united_states.txt and change the name to the name of our chosen country.
Then we can use nano to edit the contents to reflect the info of your chosen country.
Hint: You may need to do some internet searching to fill in the information.
$ cp united_states.txt france.txt
$ nano france.txt
$ cat france.txt
Population: 66,991,000
Capital: Paris
Next let’s add and commit the changes to the repo.
$ git add france.txt
$ git commit -m "Added file on france"
[addFrance 79a312a] Added file on france
1 file changed, 2 insertions(+), 2 deletions(-)
In some cases we may not have permission to push changes directly to the
upstream/authoritative repo or we might like our changes to be reviewed regardless
of permissions, so we’ll create a pull request.
A pull request is a request for a member of the upstream repository to pull
our changes into the upstream repository from a fork, allowing them to request further
changes/improvements and make comments on the changes before doing so.
In order to create a pull request, we must push our new branch containing the
changes we’d like to submit to the remote linked to our fork, origin, on GitHub.
$ git push origin addFrance
Counting objects: 4, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 783 bytes | 0 bytes/s, done.
Total 4 (delta 3), reused 0 (delta 0)
remote: Resolving deltas: 100% (3/3), completed with 3 local objects.
To https://github.com/USERNAME/countries.git
2037539..79a312a addFrance -> addFrance
Next go to your forked github version of the repo and reload the page. You won’t see the new file added in the list of files but you will see that you recently pushed a new branch to the repository.

If you wish to view your new branch you can click on the ‘Branch’ drop down menu and select that branch.
Then you should be able to view the files and commits in that branch.
Github already suspects that we are going to want to make a pull request so we can click the ‘Compare & pull request’ button to start a new pull request.
The base fork should be the upstream/authoritative version’s main branch and then the head fork should be the new branch of our fork. You can add more information into the comment section if there is anything you’d like to add for the person who reviews your suggestion. Then you can click the ‘create pull request button’ to submit the pull request.
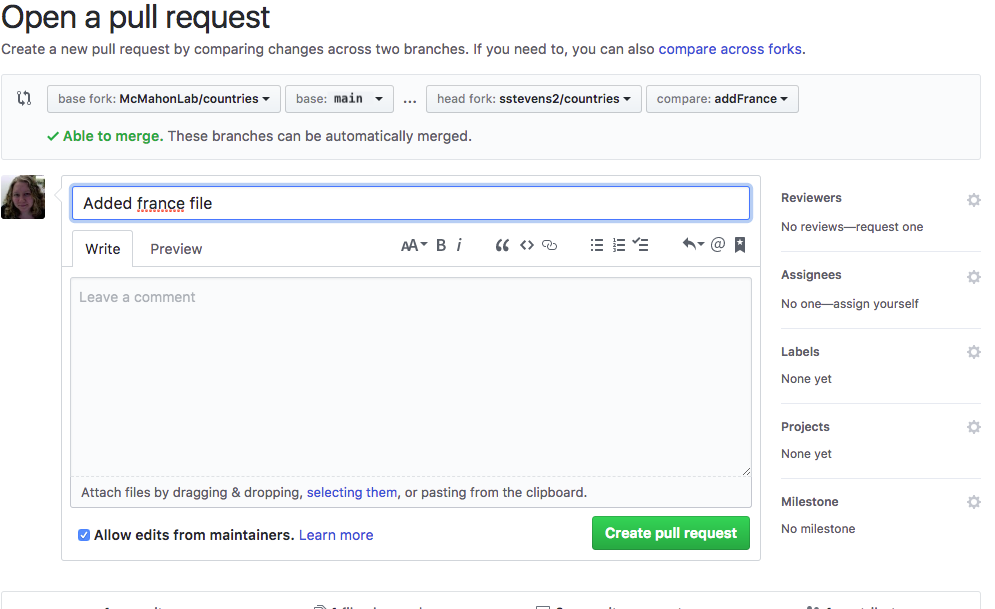
Now someone with privileges to the upstream repo can review it, give comments and suggestions, and merge it into the upstream version. In our pull request they can see any messages we left or click and look at the commits that were made and see the files changed.
Our collaborator reviewing the pull request noticed that we forgot to add the largest city so let’s add it and update our pull request.
$ nano france.txt
$ cat france.txt
Population: 66,991,000
Capital: Paris
Largest City: Paris
Next we will add and commit these changes. Then we can push them to our fork of the repo.
$ git add france.txt
$ git commit -m "Added largest city to france file"
$ git push origin addFrance
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 387 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/USERNAME/countries.git
31aa2e3..609acfe addFrance -> addFrance
If we reload the pull request, we’ll see that the new commit was added to the pull request and the changes have been automatically updated. New commits pushed to the same branch are included in the previous pull request. If you want to suggest changes separately you need to make separate branches but if you want the changes to be considered together you should put them in the same branch.
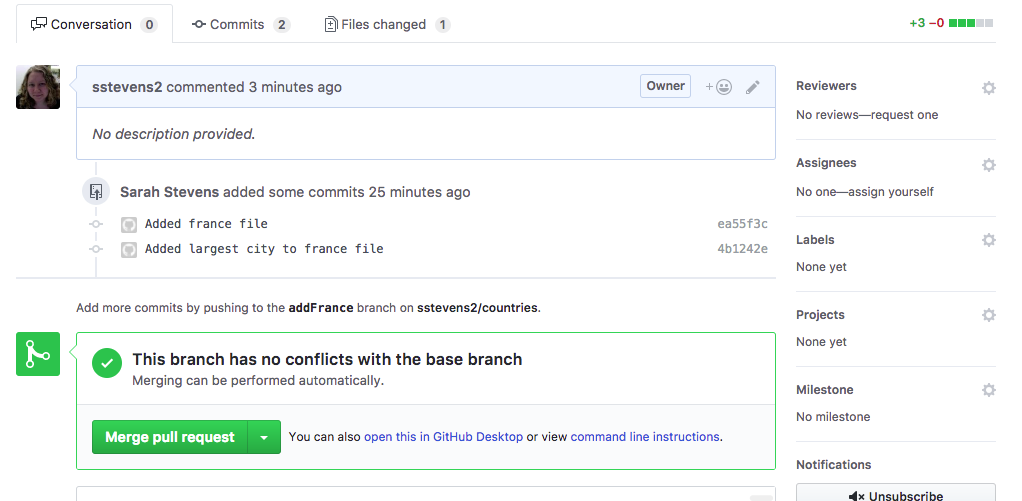
When working with others we might encounter the conflicts, which we learned about earlier in branches. Let’s practice resolving conflicts when working collaboratively.
We will continue to work in the addFrance branch from before and check we are
in that branch before we start.
$ git branch
* addFrance
main
Next we will each add our country to the existing README.md file in the repository in the line directly following the Countries: line.
$ nano README.md
$ cat README.md
# countries
Sandbox for learning PR's in Software Carpentry workshop
Countries:
France
Next we need to add, commit, and push these requests to our existing pull request.
$ git add README.md
$ git commit -m "Added France to list of countries in README"
[addFrance 66d7ebf] Added France to list of countries in README
1 file changed, 1 insertions(+), 1 deletions(-)
$ git push origin addFrance
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 376 bytes | 0 bytes/s, done.
Total 3 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/USERNAME/countries.git
609acfe..66d7ebf addFrance -> addFrance
Now if we reload the page we had a pull request we notice that our addFrance
branch is conflicting with upstream’s main branch.
This is because someone else edited the same line of the README.md file by
adding ‘United States’ where we added ‘France’.
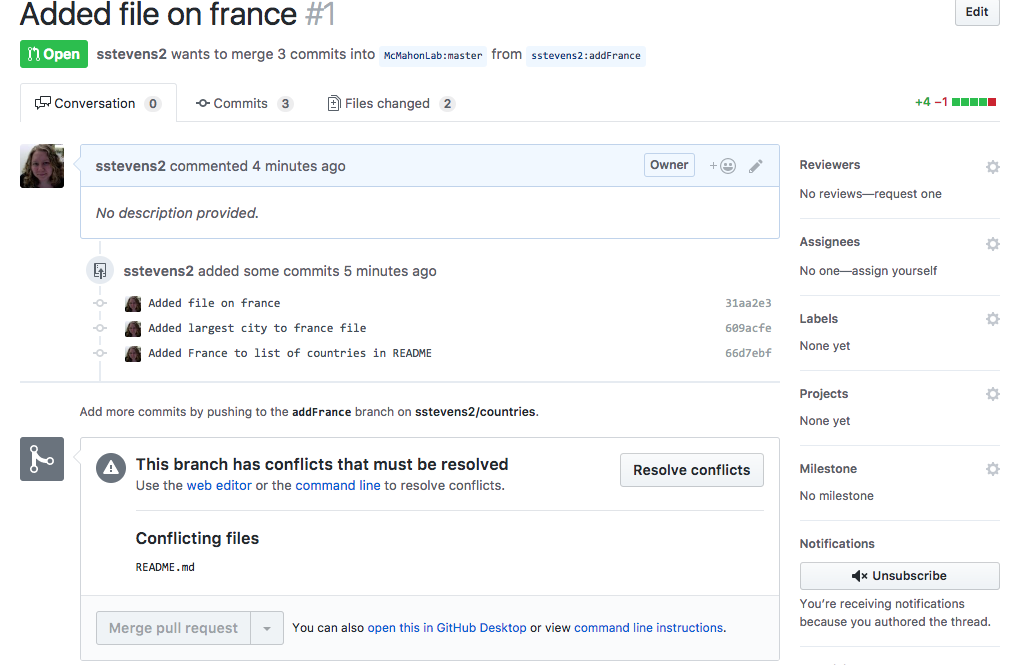
In this case, it is possible to resolve this conflict in github by clicking the ‘Resolve Conflicts’ button. However, we will reuse the skills we learned earlier to resolve this conflict locally, as we did in our branching conflict.
First we need to pull down the changes from upstream’s main branch into our
addFrance branch.
$ git pull upstream main
From https://github.com/McMahonLab/countries
* branch main -> FETCH_HEAD
Auto-merging README.md
CONFLICT (content): Merge conflict in README.md
Automatic merge failed; fix conflicts and then commit the result.
From the conflict error message we can see the conflict is in README.md or by running git status and seeing the ‘both modified’ status.
$ git status
On branch addFrance
You have unmerged paths.
(fix conflicts and run "git commit")
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
Now we will resolve the conflict by editing the README.md file to contain both
‘United States’ and ‘France’ and none of the additional lines git added to
indicate conflict
$ nano README.md
$ cat README.md
# countries
Sandbox for ComBEE github workshop on PR's
Countries:
France
United States
Then we add and commit our resolved conflict.
$ git add README.md
$ git commit -m "Resolved conflict in readme w two countries"
[addFrance 912317b] Resolved conflict in readme w two countries
Finally we can update the pull request by pushing these changes to our github fork of the repository.
$ git push origin addFrance
git push origin addFrance
Counting objects: 6, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 732 bytes | 0 bytes/s, done.
Total 6 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 1 local object.
To https://github.com/USERNAME/countries.git
66d7ebf..912317b addFrance -> addFrance
Now if we reload our browser we will see that the new commit is in the pull request and it has no conflicts with the base branch.
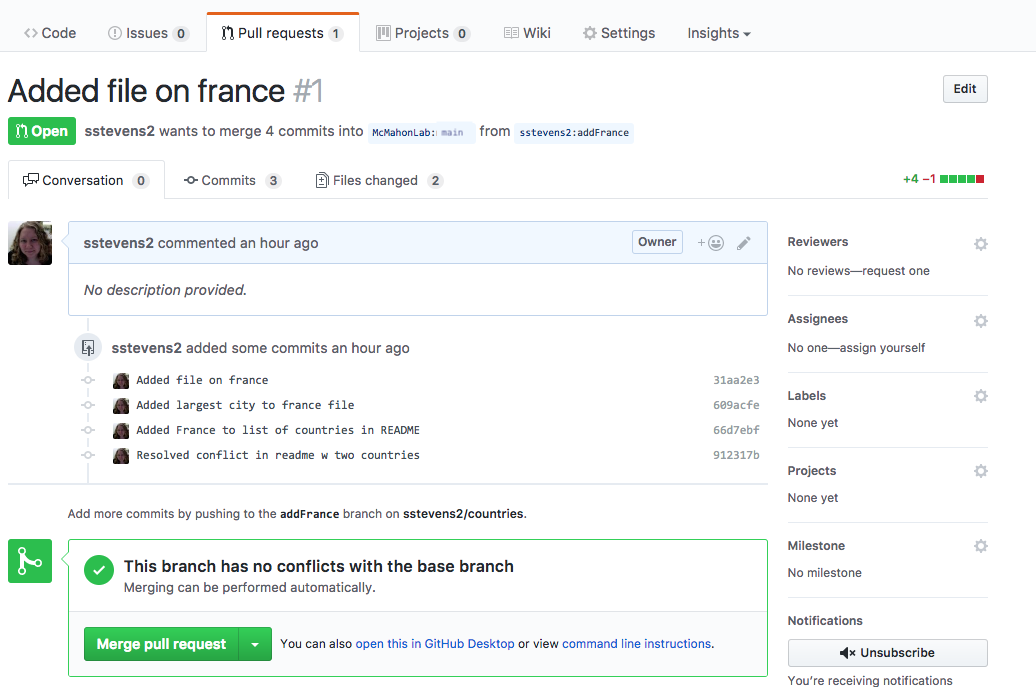
Now the owner/administrator/manager of the authoritative repo can review our pull requests and decide to incorporate them.
Add new country file and make additional PR
- Starting in the main branch make a new branch
- Copy other country file into a new country
- Edit the file to include info on the new country
- Add and commit this new file
- Push the new changes to github
Solution
$ git checkout main $ git checkout -b addItaly $ cp united_states.txt italy.txt $ nano italy.txt #Add the right info into the file $ git add italy.txt $ git commit -m "Added file on Italy" $ git push origin addItaly
Key Points
Pull requests suggest changes to repos where you don’t have privileges
Open Science
Overview
Teaching: 5 min
Exercises: 5 minQuestions
How can version control help me make my work more open?
Objectives
Explain how a version control system can be leveraged as an electronic lab notebook for computational work.
The opposite of “open” isn’t “closed”. The opposite of “open” is “broken”.
— John Wilbanks
Free sharing of information might be the ideal in science, but the reality is often more complicated. Normal practice today looks something like this:
- A scientist collects some data and stores it on a machine that is occasionally backed up by her department.
- She then writes or modifies a few small programs (which also reside on her machine) to analyze that data.
- Once she has some results, she writes them up and submits her paper. She might include her data—a growing number of journals require this—but she probably doesn’t include her code.
- Time passes.
- The journal sends her reviews written anonymously by a handful of other people in her field. She revises her paper to satisfy them, during which time she might also modify the scripts she wrote earlier, and resubmits.
- More time passes.
- The paper is eventually published. It might include a link to an online copy of her data, but the paper itself will be behind a paywall: only people who have personal or institutional access will be able to read it.
For a growing number of scientists, though, the process looks like this:
- The data that the scientist collects is stored in an open access repository like figshare or Zenodo, possibly as soon as it’s collected, and given its own Digital Object Identifier (DOI). Or the data was already published and is stored in Dryad.
- The scientist creates a new repository on GitHub to hold her work.
- As she does her analysis, she pushes changes to her scripts (and possibly some output files) to that repository. She also uses the repository for her paper; that repository is then the hub for collaboration with her colleagues.
- When she’s happy with the state of her paper, she posts a version to arXiv or some other preprint server to invite feedback from peers.
- Based on that feedback, she may post several revisions before finally submitting her paper to a journal.
- The published paper includes links to her preprint and to her code and data repositories, which makes it much easier for other scientists to use her work as starting point for their own research.
This open model accelerates discovery: the more open work is, the more widely it is cited and re-used. However, people who want to work this way need to make some decisions about what exactly “open” means and how to do it. You can find more on the different aspects of Open Science in this book.
This is one of the (many) reasons we teach version control. When used diligently, it answers the “how” question by acting as a shareable electronic lab notebook for computational work:
- The conceptual stages of your work are documented, including who did what and when. Every step is stamped with an identifier (the commit ID) that is for most intents and purposes unique.
- You can tie documentation of rationale, ideas, and other intellectual work directly to the changes that spring from them.
- You can refer to what you used in your research to obtain your computational results in a way that is unique and recoverable.
- With a distributed version control system such as Git, the version control repository is easy to archive for perpetuity, and contains the entire history.
Making Code Citable
Anything that is hosted in a version control repository (data, code, papers, etc.) can be turned into a citable object. You’ll learn how to do this in lesson 12: Citation.
How Reproducible Is My Work?
Ask one of your labmates to reproduce a result you recently obtained using only what they can find in your papers or on the web. Try to do the same for one of their results, then try to do it for a result from a lab you work with.
How to Find an Appropriate Data Repository?
Surf the internet for a couple of minutes and check out the data repositories mentioned above: Figshare, Zenodo, Dryad. Depending on your field of research, you might find community-recognized repositories that are well-known in your field. You might also find useful these data repositories recommended by Nature. Discuss with your neighbor which data repository you might want to approach for your current project and explain why.
Key Points
Open scientific work is more useful and more highly cited than closed.
Licensing
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What licensing information should I include with my work?
Objectives
Explain why adding licensing information to a repository is important.
Choose a proper license.
Explain differences in licensing and social expectations.
When a repository with source code, a manuscript or other creative
works becomes public, it should include a file LICENSE or
LICENSE.txt in the base directory of the repository that clearly
states under which license the content is being made available. This
is because creative works are automatically eligible for intellectual
property (and thus copyright) protection. Reusing creative works
without a license is dangerous, because the copyright holders could
sue you for copyright infringement.
A license solves this problem by granting rights to others (the licensees) that they would otherwise not have. What rights are being granted under which conditions differs, often only slightly, from one license to another. In practice, a few licenses are by far the most popular, and choosealicense.com will help you find a common license that suits your needs. Important considerations include:
- Whether you want to address patent rights.
- Whether you require people distributing derivative works to also distribute their source code.
- Whether the content you are licensing is source code.
- Whether you want to license the code at all.
Choosing a license that is in common use makes life easier for contributors and users, because they are more likely to already be familiar with the license and don’t have to wade through a bunch of jargon to decide if they’re ok with it. The Open Source Initiative and Free Software Foundation both maintain lists of licenses which are good choices.
This article provides an excellent overview of licensing and licensing options from the perspective of scientists who also write code.
At the end of the day what matters is that there is a clear statement as to what the license is. Also, the license is best chosen from the get-go, even if for a repository that is not public. Pushing off the decision only makes it more complicated later, because each time a new collaborator starts contributing, they, too, hold copyright and will thus need to be asked for approval once a license is chosen.
Can I Use Open License?
Find out whether you are allowed to apply an open license to your software. Can you do this unilaterally, or do you need permission from someone in your institution? If so, who?
What licenses have I already accepted?
Many of the software tools we use on a daily basis (including in this workshop) are released as open-source software. Pick a project on GitHub from the list below, or one of your own choosing. Find its license (usually in a file called
LICENSEorCOPYING) and talk about how it restricts your use of the software. Is it one of the licenses discussed in this session? How is it different?
Key Points
People who incorporate General Public License (GPL’d) software into their own software must make their software also open under the GPL license; most other open licenses do not require this.
The Creative Commons family of licenses allow people to mix and match requirements and restrictions on attribution, creation of derivative works, further sharing, and commercialization.
People who are not lawyers should not try to write licenses from scratch.
Citation
Overview
Teaching: 2 min
Exercises: 0 minQuestions
How can I make my work easier to cite?
Objectives
Make your work easy to cite
You may want to include a file called CITATION or CITATION.txt
that describes how to reference your project;
the one for Software
Carpentry
states:
To reference Software Carpentry in publications, please cite both of the following:
Greg Wilson: "Software Carpentry: Getting Scientists to Write Better
Code by Making Them More Productive". Computing in Science &
Engineering, Nov-Dec 2006.
Greg Wilson: "Software Carpentry: Lessons Learned". arXiv:1307.5448,
July 2013.
@article{wilson-software-carpentry-2006,
author = {Greg Wilson},
title = {Software Carpentry: Getting Scientists to Write Better Code by Making Them More Productive},
journal = {Computing in Science \& Engineering},
month = {November--December},
year = {2006},
}
@online{wilson-software-carpentry-2013,
author = {Greg Wilson},
title = {Software Carpentry: Lessons Learned},
version = {1},
date = {2013-07-20},
eprinttype = {arxiv},
eprint = {1307.5448}
}
More detailed advice, and other ways to make your code citable can be found in here and in:
Smith AM, Katz DS, Niemeyer KE, FORCE11 Software Citation Working Group. (2016) Software citation principles. PeerJ Computer Science 2:e86 https://doi.org/10.7717/peerj-cs.86
There is also an @software{…
BibTeX entry type in case
no “umbrella” citation like a paper or book exists for the project you want to
make citable.
Key Points
Add a CITATION file to a repository to explain how you want your work cited.
Hosting
Overview
Teaching: 10 min
Exercises: 0 minQuestions
Where should I host my version control repositories?
Objectives
Explain different options for hosting scientific work.
The second big question for groups that want to open up their work is where to host their code and data. One option is for the lab, the department, or the university to provide a server, manage accounts and backups, and so on. The main benefit of this is that it clarifies who owns what, which is particularly important if any of the material is sensitive (i.e., relates to experiments involving human subjects or may be used in a patent application). The main drawbacks are the cost of providing the service and its longevity: a scientist who has spent ten years collecting data would like to be sure that data will still be available ten years from now, but that’s well beyond the lifespan of most of the grants that fund academic infrastructure.
Another option is to purchase a domain and pay an Internet service provider (ISP) to host it. This gives the individual or group more control, and sidesteps problems that can arise when moving from one institution to another, but requires more time and effort to set up than either the option above or the option below.
The third option is to use a public hosting service like GitHub, GitLab,or BitBucket. Each of these services provides a web interface that enables people to create, view, and edit their code repositories. These services also provide communication and project management tools including issue tracking, wiki pages, email notifications, and code reviews. These services benefit from economies of scale and network effects: it’s easier to run one large service well than to run many smaller services to the same standard. It’s also easier for people to collaborate. Using a popular service can help connect your project with communities already using the same service.
As an example, Software Carpentry is on GitHub where you can find the source for this page. Anyone with a GitHub account can suggest changes to this text.
GitHub repositories can also be assigned DOIs, by connecting its releases to
Zenodo. For example,
10.5281/zenodo.57467 is the DOI that has
been “minted” for this introduction to Git.
Using large, well-established services can also help you quickly take advantage of powerful tools. One such tool, continuous integration (CI), can automatically run software builds and tests whenever code is committed or pull requests are submitted. Direct integration of CI with an online hosting service means this information is present in any pull request, and helps maintain code integrity and quality standards. While CI is still available in self-hosted situations, there is much less setup and maintenance involved with using an online service. Furthermore, such tools are often provided free of charge to open source projects, and are also available for private repositories for a fee.
Institutional Barriers
Sharing is the ideal for science, but many institutions place restrictions on sharing, for example to protect potentially patentable intellectual property. If you encounter such restrictions, it can be productive to inquire about the underlying motivations and either to request an exception for a specific project or domain, or to push more broadly for institutional reform to support more open science.
Can My Work Be Public?
Find out whether you are allowed to host your work openly on a public forge. Can you do this unilaterally, or do you need permission from someone in your institution? If so, who?
Where Can I Share My Work?
Does your institution have a repository or repositories that you can use to share your papers, data and software? How do institutional repositories differ from services like arXiV, figshare, GitHub or GitLab?
Key Points
Projects can be hosted on university servers, on personal domains, or on public forges.
Rules regarding intellectual property and storage of sensitive information apply no matter where code and data are hosted.
Using Git from RStudio
Overview
Teaching: 10 min
Exercises: 0 minQuestions
How can I use Git with RStudio?
Objectives
Understand how to use Git from RStudio.
Since version control is so useful when developing scripts, RStudio has built-in integration with Git. There are some more obscure Git features that you still need to use the command-line for, but RStudio has a nice interface for most common operations.
RStudio let’s you create a project associated with a given directory. This is a way to keep track of related files. One of the way to keep track of them is via version control! To get started using RStudio for version control, let’s make a new project:
This will pop up a window asking us how we want to create the project. We have some options here. Let’s say that we want to use RStudio with the planets repository that we already made. Since that repository lives in a directory on our computer, we’ll choose “existing directory”:
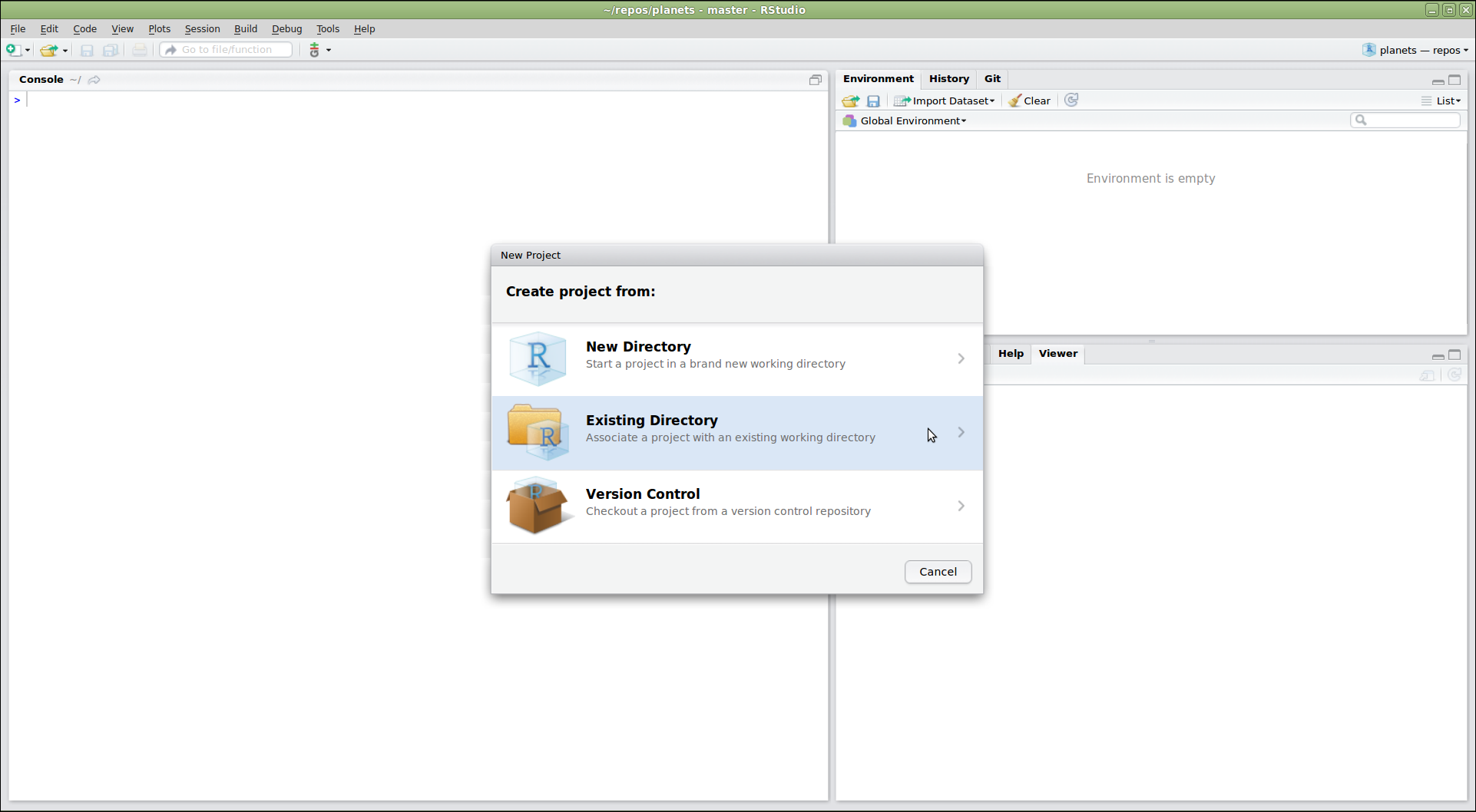
Do You See a “Version Control” Option?
Although we’re not going to use it here, there should be a “version control” option on this menu. That is what you would click on if you wanted to create a project on your computer by cloning a repository from GitHub. If that option is not present, it probably means that RStudio doesn’t know where your Git executable is. See this page for some debugging advice. Even if you have Git installed, you may need to accept the XCode license if you are using macOS.
Next, RStudio will ask which existing directory we want to use. Click “browse” to navigate to the correct directory on your computer, then click “create project”:
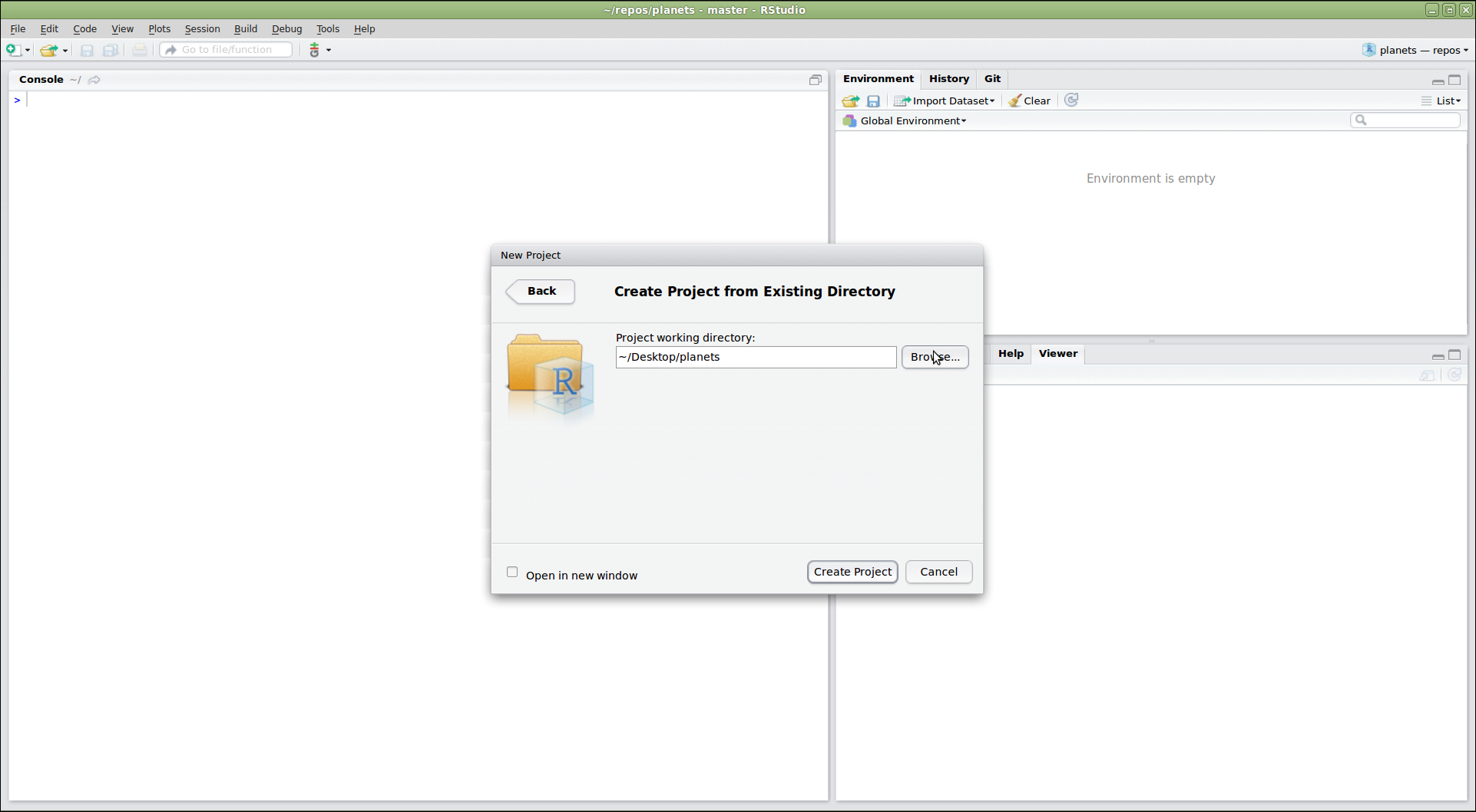
Ta-da! Now you have an R project containing your repository. Notice the vertical “Git” menu that is now on the menu bar. This means RStudio has recognized that this directory is a git repository, so it’s giving you tools to use Git:
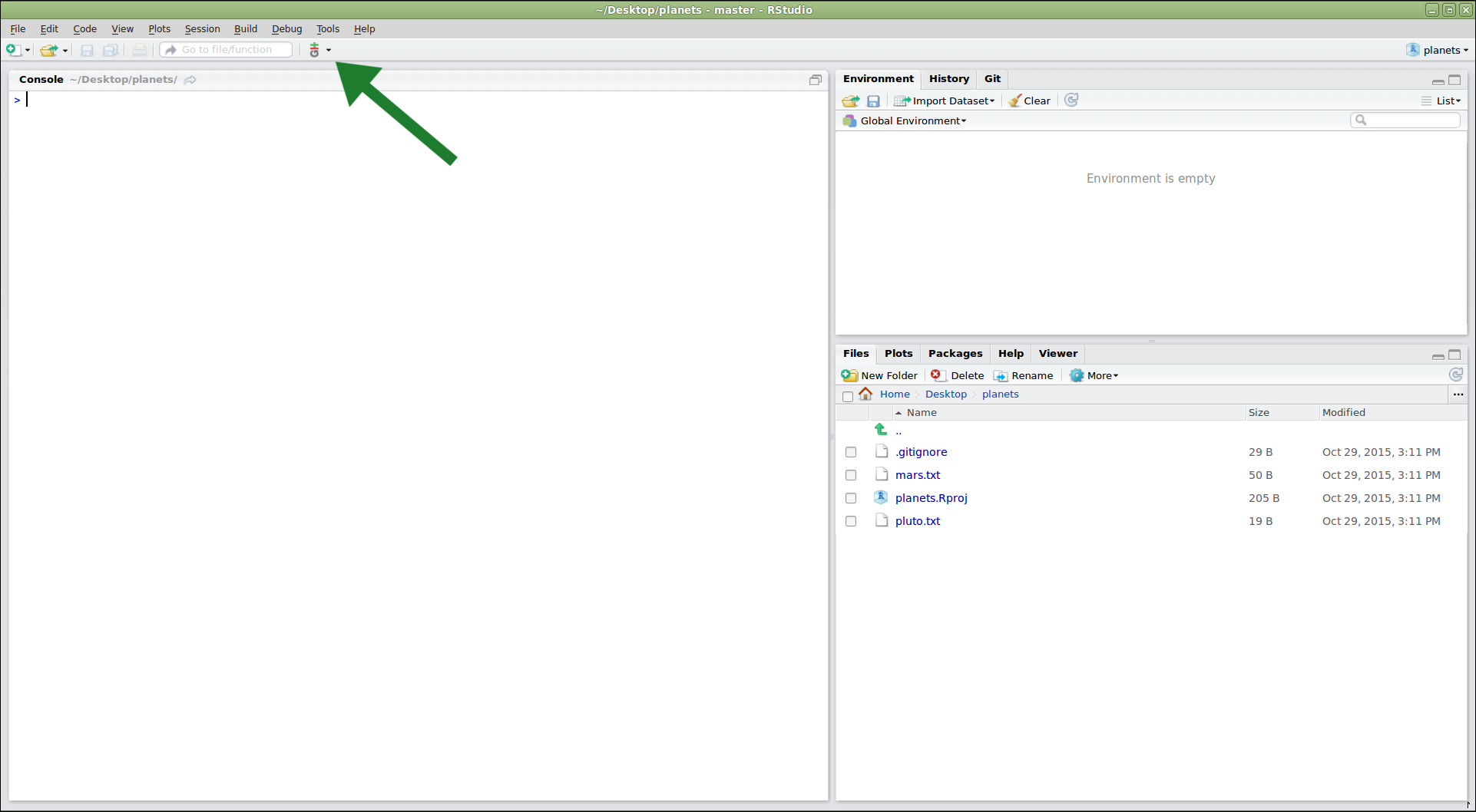
To edit the files in your repository, you can click on them from the panel in the lower right. Let’s add some more information about Pluto:
Once we have saved our edited files, we can also use RStudio to commit these changes. Go to the git menu and click “commit”:
This will bring up a screen where you can select which files to commit (check the boxes in the “staged” column) and enter a commit message (in the upper right). The icons in the “status” column indicate the current status of each file. You can also see the changes to each file by clicking on its name. Once everything is the way you want it, click “commit”:
You can push these changes by selecting “push” from the Git menu. There are also options there to pull from a remote version of the repository, and view the history:
Are the Push/Pull Commands Grayed Out?
If this is the case, it generally means that RStudio doesn’t know the location of any other version of your repository (i.e. the one on GitHub). To fix this, open a terminal to the repository and enter the command:
git push -u origin main. Then restart RStudio.
If we click on “history”, we can see a pretty graphical version of what
git log would tell us:
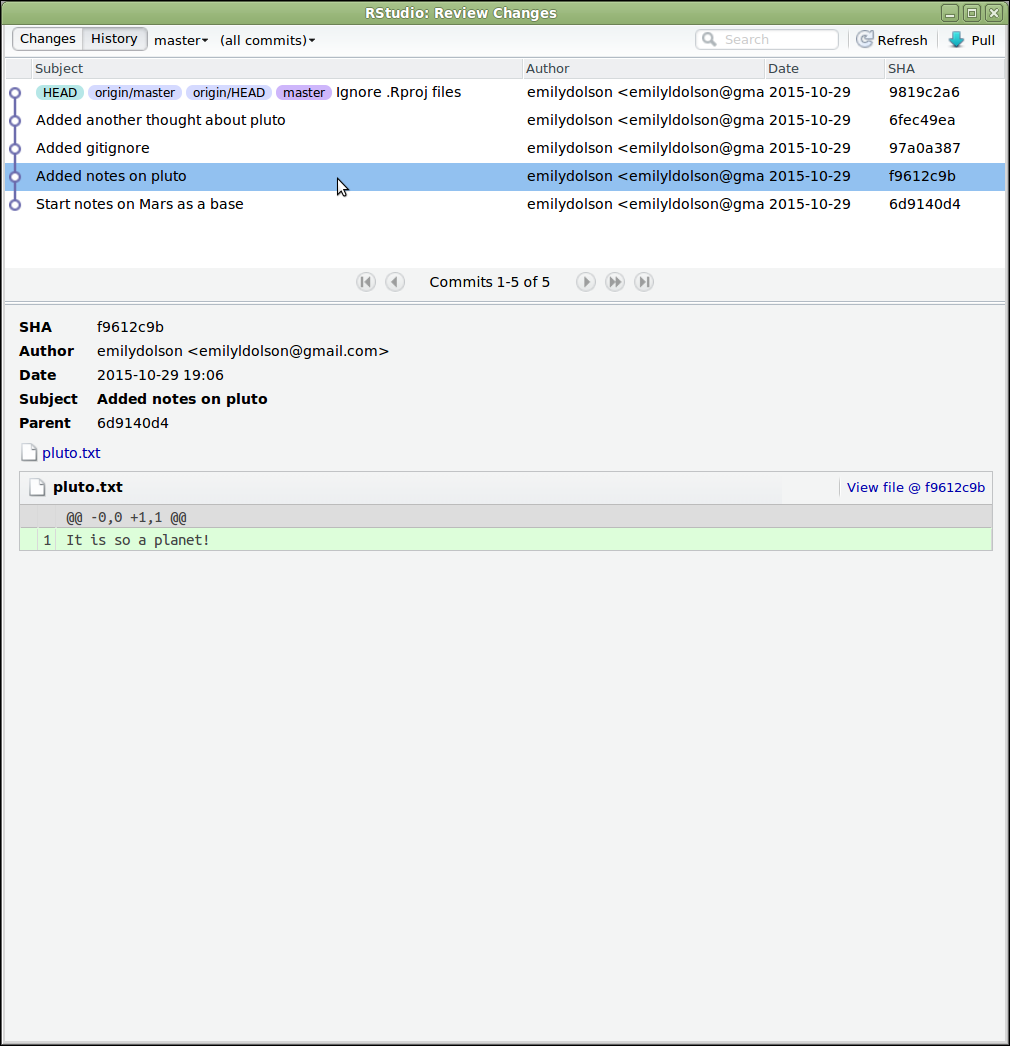
RStudio creates some files that it uses to keep track of your project. You
generally don’t want to track these, so adding them to your .gitignore file
is a good idea:
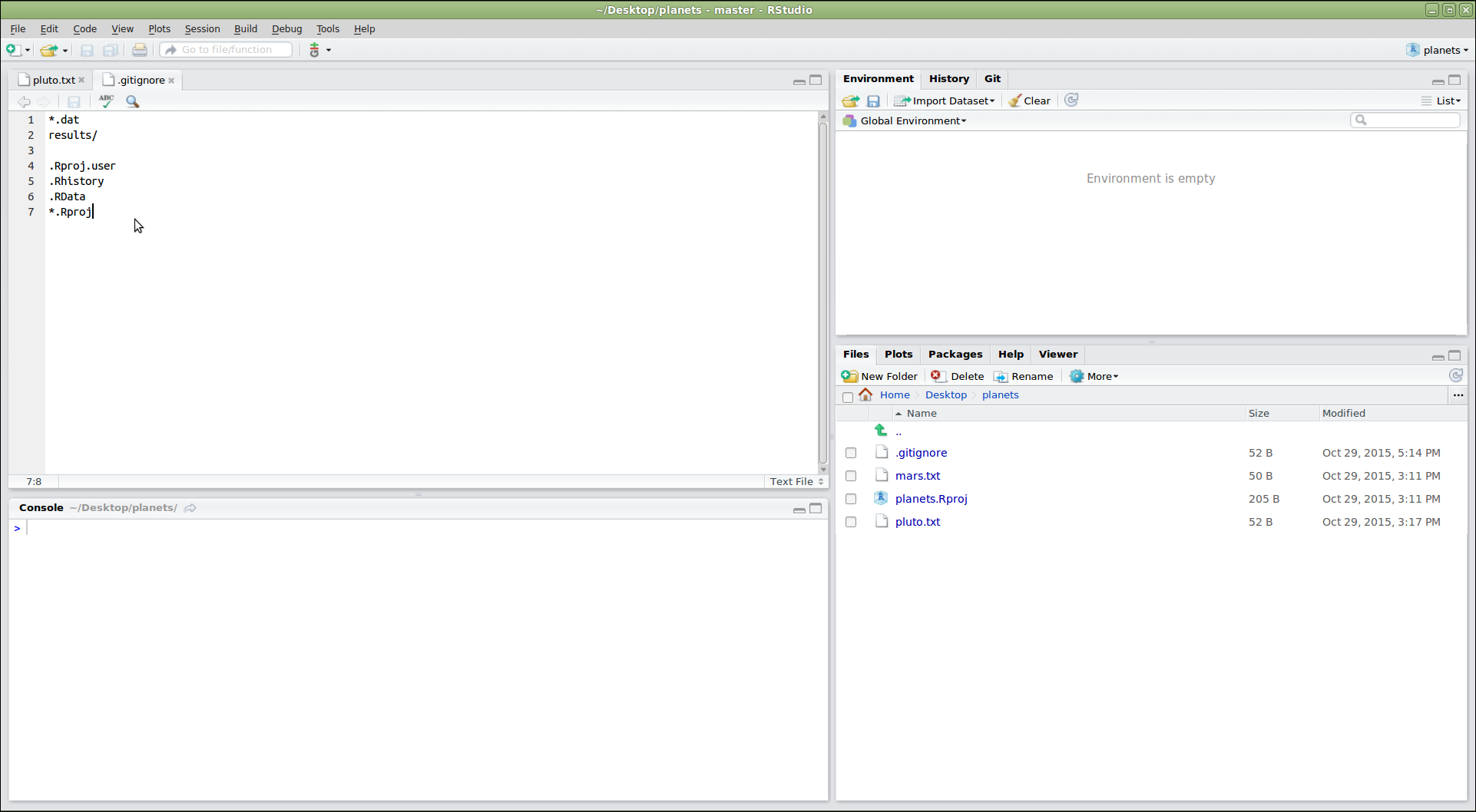
There are many more features buried in the RStudio git interface, but these should be enough to get you started!
Key Points
Create an RStudio project