Introducing Frictionless Data
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What will I learn during this workshop?
What are the tools that I will be using?
How will learning to use Frictionless Data benefit me?
Objectives
Understand the principles of Frictionless Data for tabular datasets.
Understand how Frictionless Data can benefit me.
Have a general understanding of what Frictionless Data can do.
Motivation
To start, why should I use Frictionless Data for my tabular datasets?
What is Frictionless Data?
Frictionless Data is a simple open source toolkit that can be used for creating well described tabular datasets.
Frictionless uses a suite of simple patterns to describe and organize tabular data. This allows Frictionless datasets to be shared and re-used between researchers.
Frictionless Data can also be combined with supporting Frictionless code libraries to build powerful workflows for extracting, transforming and loading data.
Frictionless uses CSV to store data. Each CSV file represents a table having columns and rows. JSON schemas are used to describe data, tables and datasets.
A Frictionless Dataset is distributed as a Frictionless Data Package. A Data Packages is composed of tabular CSV data files and a JSON metadata file. The data package can also include other files in any format such as images, PDFs, video.
Frictionless Data is well described data
Why is creating well described data important?
What is your experience trying to re-use datasets?
- Have you tried to use a dataset but puzzled over the meaning of a data column or a code for a value?
- Was the dataset created by you or someone else?
- Were you confident re-using these datasets, or did you abandon them?
- Have you used datasets that you were confident using? What features of these datasets helped you to re-use them?
Creating well described datasets makes it easier for us and others to re-use them. But what do we mean by a well described dataset?
A well described dataset means a dataset is accompanied by metadata. Metadata is data about the data and can include information such as:
- A data dictionary describing the tables and columns.
- A description of the dataset.
- Information about the temporal and spatial coverage of the data i.e. where and when was the data collected.
- Provenance and technical information about data collection and analysis methods used.
- Conditions for re-using the dataset such as a licence and how it should be acknowledged.
- Keywords to help dataset categorisation and discovery.
- The names of people involved in the creation of the dataset.
Frictionless allows us to capture all this information or metadata using a standard JSON metadata schema.
The Dataset
The data we will be using are based on real agricultural field experiments conducted at Rothamsted Research, UK. The field experiments we will be using are small plot experiments for comparing different varieties of wheat. Wheat variety is therefore our main treatment factor. The experiments are randomised with replication meaning each plot grows one variety of wheat and each variety is grown on multiple plots with varieties allocated to plots at random.
For each plot the yield is recorded and logged to a yields.csv file. Other information for the experiment such as name, harvest area, harvest machine and varieties used is recorded in other CSV files.
The dataset has the following three files:
- experiment.csv
- varieties.csv
- yields.csv
Review the datasets
Open each of these CSV files and explore them.
- What information is stored in each file
- Do you understand the table contents
- Are you confident in re-using this data
What extra information could you provide to make this dataset easier to use for other researchers?
Frictionless Python Module
The Frictionless Python module is used for creating, editing, reading and manipulating Frictionless Data. The module is split into X parts with the following uses: 1.
In the following lessons we will be using the describe functions to create a schema and add metadata to it.
Goals
Over the following lesson episodes we will see how Frictionless Data can be used to support FAIR data, learn how Frictionless data packages are structured and describe tabular datasets and use the Frictionless python libraries to convert our three CSV files into a Frictionless Tabular Data Package.
Key Points
Frictionless can be used to create well described datasets that can be more easily re-used by other researchers.
Metadata is used to describe a dataset.
Frictionless uses a simple JSON syntax for providing structured metadata.
Frictionless Data and FAIR Data
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How does Frictionless Data relate to FAIR Data?
Objectives
Understand how Frictionless Data relates to FAIR data.
What are the FAIR Data Principles
FAIR stands for Findable, Accessible, Interoperable and Reusable and provides an important set of guiding principles for creating reusable datasets. The FAIR data principles are being widely adopted across the research community for improving re-use of datasets
For more information on the FAIR Data Principles visit GO-FAIR.
FAIR has 15 principles and using Frictionless we can meet 10 of them, These are:
- F1. (Meta)data are assigned a globally unique and persistent identifier
- I1. (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation
- I2. (Meta)data use vocabularies that follow FAIR principles
- R1. (Meta)data are richly described with a plurality of accurate and relevant attributes
- R1.1. (Meta)data are released with a clear and accessible data usage license
- R1.2. (Meta)data are associated with detailed provenance
- R1.3. (Meta)data meet domain-relevant community standards
How does Frictionless help us meet the FAIR Data Principles
The Frictionless Data Package Schema provides us with a metadata schema for describing the contents and structure of a data package. The schema uses named properties such as id, name, licences, sources and contributors which capture specific information about a dataset.
In the following section we will see how we can use the schema to meet specific FAIR data principles.
F1. (Meta)data are assigned a globally unique and persistent identifier
The Frictionless Data Package schema has a recommended property called id reserved for globally unique identifiers. An example of a globally unique identifier might be a DOI.
I1. (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
The Frictionless Data Package Schema uses the JSON format to store metadata and CSV to store data. Both JSON and CSV are standard and accessible text based formats using standard formats to represent metadata and data.
I2. (Meta)data use vocabularies that follow FAIR principles
Frictionless allows us to annotate data using controlled vocabularies that also follow FAIR principles.
R1. (Meta)data are richly described with a plurality of accurate and relevant attributes
It is much easier for researchers to re-use data if they can understand a dataset and make a decision whether or not it is useful for them. To help the researcher make this decision you should metadata that richly describe the data. Here plurality means including as much information as possible so that a researcher can confidently re-use the data. The Frictionless Data Package Schema provides standard metadata properties which allows us to provide rich metadata for a dataset.
R1.1. (Meta)data are released with a clear and accessible data usage license
The Frictionless Data Package Schema has a property called licences which allows us include a licence outlining the conditions under which the dataset can be re-used. For example a Creative Commons Attribution Licence could be applied to indicate users must credit the dataset in any publications which use it.
R1.2. (Meta)data are associated with detailed provenance
The Frictionless Data Package Schema has a property called sources which allows us to identify other sources of data. This can be used to show provenance of the data. We can also use other schema properties to provide text information about the provenance of the data, such as location and timing of data collection.
R1.3. (Meta)data meet domain-relevant community standards
Although the Frictionless Data Package Schema defines several standard metadata properties these are very general. Frictionless allows us to add other properties for describing the dataset. For example, we could use agreed community properties such as temporal and location to describe the time and place that a dataset was generated.
In future lessons we will see where Frictionless data is used to support these FAIR data principles.
Key Points
Frictionless Datasets are described by metadata using a standard schema.
Providing good metadata to describe a dataset makes it easier for other researchers to understand and re-use the data.
The FAIR data principles are a set of guidelines for creating findable, accessible, interoperable and re-useable datasets.
Using Frictionless Data can help you create datasets that meet many of the FAIR Data Principles.
Frictionless Tables
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is a Frictionless Table Schema?
How can I create and edit a Frictionless Table Schema?
Objectives
Learn the Frictionless Table Schema and how it is used to describe a tabular dataset.
Import a table and infer metadata about it using Python.
Understand the Field Descriptor options for describing table fields.
Use Python to edit the Field Descriptors for fields in our dataset.
In this lesson we will be working with the Frictionless Python module and CSV (comma separated) data files. Each CSV file represents a table in our dataset. For each file, the first row is the header row and provides the names of the table fields. All following rows are data.
Introducing the Frictionless Table Schema
The Frictionless Table Schema is a simple format for describing a table using JSON. The schema has properties for describing information about the table and an array property listing the tables fields.
Why do we need the Table Schema?
While CSV is a simple and effective way for providing tabular data, it only tells us the name of a field. To use the table we might need to know other information, or metadata, about the fields such as the fields data type, i.e. is it text, an integer, a decimal or a date. The Frictionless Table Schema allows us to provide this metadata for the tables fields.
Providing additional metadata for our tables means we can improve them in three important ways:
- We can provide validation rules for quality checking the data.
- We can provide additional information to describe the fields and data. This makes it easier to re-use the data.
- We can add semantic annotations to fields to improve their interoperability with other datasets.
FAIR Data Principle
Providing additional metadata to describe our tables helps us to meet FAIR data principles for reuse of data.
Discussion
What other information could you provide to describe fields in a table?
Describing our first table
We are going to use the Frictionless Python module to describe our first CSV table.
Start Python or a new Jupyter Notebook and import the Frictionless module’s describe function. As we’ll be working with JSON and Python dictionary data structures we will also import the PrettyPrinter module to return more readable dictionary data.
from frictionless import describe
import pprint
pp = pprint.PrettyPrinter(depth=4)
Next we’ll describe the yields.csv file using the describe function to generate a Frictionless table schema and print the results.
yields_schema = describe("data/yields.csv")
pp.pprint(yields_schema)
This should output the following JSON table schema.
{'encoding': 'utf-8',
'format': 'csv',
'hashing': 'md5',
'name': 'yields',
'path': 'data/yields.csv',
'profile': 'tabular-data-resource',
'schema': {'fields': [{'name': 'plot_no', 'type': 'integer'},
{'name': 'expt_id', 'type': 'string'},
{'name': 'h_Date', 'type': 'string'},
{'name': 'col_y', 'type': 'integer'},
{'name': 'col_x', 'type': 'integer'},
{'name': 'variety', 'type': 'string'},
{'name': 'grain_weight', 'type': 'number'}]},
'scheme': 'file'}
If we look at the output we can see the Frictionless describe function has automatically inferred basic table and field metadata, such as the name and relative path of the file and all table fields. The describe function also samples the data rows to infer the data type for each field.
Exercise
Challenge: Describe the varieties and experiments files
Using the code for describing the yields.csv to describe varieties.csv and experiments.csv. Assign the resulting table schemas to variables called varieties_schema and experiments_schema respectively.
Solution
varieties_schema = describe("data/varieties.csv") experiments_schema = describe("data/experiments.csv")
Improving field descriptions
We have seen the Frictionless describe function generates a basic definition for each of our fields by assigning a name and data type. This is a good start for describing our tables, but it doesn’t provide enough information to make the data usable. For example what are the units for grain_weight and what do col_x and row_y mean?
We can use Python to edit the table schema to improve our metadata. We will do this by adding extra field descriptors to the table schema.
Field Descriptors
The Frictionless Table Schema uses Field Descriptors to provide additional information for a field.
| Descriptor | How to use it | Example |
|---|---|---|
| name | The name must match a field name in the data table | hrv_date |
| title | A human readable title for the field. | Harvest date |
| description | A more detailed description of the field. | The date on which the crop was harvested. |
| type | The data type for the field. | date |
| format | The format for the field data | YYYY-MM-DD |
| rdfType | This is rich type or semantic type. It should be a URI for a term from a controlled vocabulary | http://purl.obolibrary.org/obo/TO_0000396 |
| constraints | This is used to constrain the values in a field and is used for validation | required |
In the table schema, using the hrv_date field example above would give the following JSON definition:
{
'name': 'hrv_date',
'title': 'Harvest date',
'description': 'The date on which the crop was harvested.',
'type': 'date',
'format': 'YYYY-MM-DD'
'rdfType': 'http://purl.obolibrary.org/obo/TO_0000396',
'constraints': {'required': True}
}
Read the Frictionless Field Descriptors documentation for an in-depth description of the field descriptors.
FAIR Data Principle
Using the rdfType helps to improve interoperability of our dataset by annotating the field using a term or concept from a community vocabulary. In the above example we have used the Trait Ontology term for Harvest Date. This means we can more confidently link the data to other datasets that are similarly annotated, evern if the fields have different names.
Adding field descriptors to the table schema
In python we will start adding a title and description
yields_schema.schema.get_field("plot_no").title = "Plot Number"
yields_schema.schema.get_field("plot_no").description = "A unique identifer for the plot"
yields_schema.schema.get_field("expt_id").title = "Experiment Code"
yields_schema.schema.get_field("expt_id").description = "Institute standard code for a field experiment"
yields_schema.schema.get_field("h_date").title = "Harvest Date"
yields_schema.schema.get_field("h_date").description = "Date on which the plot was harvested"
pp.pprint(yields_schema)
{'encoding': 'utf-8',
'format': 'csv',
'hashing': 'md5',
'name': 'yields',
'path': 'data/yields.csv',
'profile': 'tabular-data-resource',
'schema': {'fields': [{'description': 'A unique identifer for the plot.',
'name': 'plot_no',
'title': 'Plot Number',
'type': 'integer'},
{'description': 'Institute standard code for a field experiment.',
'name': 'expt_id',
'title': 'Experiment Code',
'type': 'string'},
{'description': 'Date on which the plot was harvested.',
'name': 'h_date',
'title': 'Harvest Date',
'type': 'string'},
{'name': 'col_y', 'type': 'integer'},
{'name': 'col_x', 'type': 'integer'},
{'name': 'variety', 'type': 'string'},
{'name': 'grain_weight', 'type': 'number'}]},
'scheme': 'file'}
Exercise
Challenge: Add field descriptors for the varieties and experiments tables
Using the code for adding field descriptors to the yields table as an example, use the information below to add field descriptors to the experiments table schema.
experiments
field name title description expt_code Experiment Code A unique institute standard code for a field experiment. harvest_machine Harvest machine Type of machine used to harvest plots. harvest_width Harvest Width Width of the area harvested in metres. harvest_length Harvest Length Length of the area harvested in metres. Solution
experiments_schema.schema.get_field("expt_code").title = "Experiment Code" experiments_schema.schema.get_field("expt_code").description = "A unique Institute standard code for a field experiment." experiments_schema.schema.get_field("harvest_machine").title = "Harvest machine" experiments_schema.schema.get_field("harvest_machine").description = "Type of machine used to harvest plots." experiments_schema.schema.get_field("harvest_width").title = "Harvest Width" experiments_schema.schema.get_field("harvest_width").description = "Width of the area harvested in metres." experiments_schema.schema.get_field("harvest_length").title = "Harvest Length" experiments_schema.schema.get_field("harvest_length").description = "Length of the area harvested in metres." pp.pprint(experiments_schema){ 'encoding': 'utf-8', 'format': 'csv', 'hashing': 'md5', 'name': 'experiments', 'path': 'data/experiments.csv', 'profile': 'tabular-data-resource', 'schema': {'fields': [{'description': 'A unique Institute standard code for a field experiment.', 'name': 'expt_code', 'title': 'Experiment Code', 'type': 'string'}, {'description': 'Type of machine used to harvest plots.', 'name': 'harvest_machine', 'title': 'Harvest machine', 'type': 'string'}, {'description': 'Width of the area harvested in metres.', 'name': 'harvest_width', 'title': 'Harvest Width', 'type': 'number'}, {'description': 'Length of the area harvested in metres.', 'name': 'harvest_length', 'title': 'Harvest Length', 'type': 'integer'}, {'name': 'expt_name', 'type': 'string'}, {'name': 'site', 'type': 'string'}]}, 'scheme': 'file'}
Adding constraint field descriptors to the table schema
We can also add constraint field descriptors to our table schema. Constraints are used to validate and quality check the data, for example, by checking numeric fields are within a certain range.
Frictionless define the following field constraints
| Constraint name | type | usage |
|---|---|---|
| required | True or False | Indicates the field must have a value. |
| unique | True or False | Indicates all values in the field must be unique and not repeated. |
| minLength | integer | A number indicating the minimum length for text. |
| maxLength | integer | A number indicating the maximum length for text. |
| minimum | integer | A number indicating the minimum value for a number or date. |
| maximum | integer | A number indicating the maximum value for a number or date. |
| pattern | string | A regular expression defining the format of allowed values. For example experiment codes must follow a specified institute format. |
| enum | array | A list of allowed values. All values in a field must be from this list. |
Constraint properties can be added to fields in the same way that we have just edited the title and description properties for experiments table schema.
Exercise
Challenge: Complete the code to add additional constraints
Complete the code so that:
- Experiment code is unique.
- Site must be from the list ‘Brooms Barn’, ‘Rothamsted’, ‘Woburn’.
- Harvest width must be between 1 and 2 m.
- Harvest length must be between 1 and 10 m.
experiments_schema.schema.get_field("expt_code").constraints["unique"] = _________ experiments_schema.schema.get_field("site").constraints["_________"] = ["Brooms Barn","Rothamsted",_________] experiments_schema.schema.get_field("harvest_width").constraints["minimum"] = _________ experiments_schema.schema.get_field("harvest_width").constraints[""] = 2 _________.schema.get_field(_________).constraints[_________] = _________ _________.schema.get_field(_________).constraints[_________] = _________ pp.pprint(_________)Solution
experiments_schema.schema.get_field("expt_code").constraints["unique"] = True experiments_schema.schema.get_field("site").constraints["enum"] = ["Brooms Barn","Rothamsted","Woburn"] experiments_schema.schema.get_field("harvest_width").constraints["minimum"] = 1 experiments_schema.schema.get_field("harvest_width").constraints["maximum"] = 2 experiments_schema.schema.get_field("harvest_length").constraints["minimum"] = 1 experiments_schema.schema.get_field("harvest_length").constraints["maximum"] = 10 pp.pprint(experiments_schema){ 'encoding': 'utf-8', 'format': 'csv', 'hashing': 'md5', 'name': 'experiments', 'path': 'data/experiments.csv', 'profile': 'tabular-data-resource', 'schema': {'fields': [{'constraints': {'unique': True}, 'description': 'A unique Institute standard code for a field experiment.', 'name': 'expt_code', 'title': 'Experiment Code', 'type': 'string'}, {'description': 'Type of machine used to harvest plots.', 'name': 'harvest_machine', 'title': 'Harvest machine', 'type': 'string'}, {'constraints': {'maximum': 2, 'minimum': 1}, 'description': 'Width of the area harvested in metres.', 'name': 'harvest_width', 'title': 'Harvest Width', 'type': 'number'}, {'constraints': {'maximum': 10, 'minimum': 1}, 'description': 'Length of the area harvested in metres.', 'name': 'harvest_length', 'title': 'Harvest Length', 'type': 'integer'}, {'name': 'expt_name', 'type': 'string'}, {'constraints': {'enum': ['Brooms Barn', 'Rothamsted', 'Woburn']}, 'name': 'site', 'type': 'string'}]}, 'scheme': 'file'}
Handling missing values
If our dataset has missing values we can use the Frictionless Table Schema to define how missing values are represented in the data. For example in the yields table missing yield data is represented in the grain_weight field by an *. However, the grain_weight field is defined in the schema as a number, therefore to prevent the Frictionless validator throwing an error, because * is not a number, we need to indicate the special meaning of *.
We can provide multiple missing value codes, so missing values are added to schema as an array. For example, the following code sets zero-length strings and * as allowed missing values for our yields table.
yields_schema.schema.missing_values = ["","*"]
pp.pprint(yields_schema)
{'encoding': 'utf-8',
'format': 'csv',
'hashing': 'md5',
'name': 'yields',
'path': 'data/yields.csv',
'profile': 'tabular-data-resource',
'schema': {'fields': [{'description': 'A unique identifer for the plot',
'name': 'plot_no',
'title': 'Plot Number',
'type': 'integer'},
{'description': 'Institute standard code for a field '
'experiment',
'name': 'expt_id',
'title': 'Experiment Code',
'type': 'string'},
{'description': 'Date on which the plot was harvested',
'name': 'h_date',
'title': 'Harvest Date',
'type': 'string'},
{'name': 'col_y', 'type': 'integer'},
{'name': 'col_x', 'type': 'integer'},
{'name': 'variety', 'type': 'string'},
{'name': 'grain_weight', 'type': 'number'}],
'foreignKeys': [{'fields': 'variety',
'reference': {'fields': 'variety',
'resource': 'varieties'}},
{'fields': 'expt_code',
'reference': {'fields': 'expt_code',
'resource': 'experiments'}}],
'missingValues': ['', '*'],
'primaryKey': 'plot_no'},
'scheme': 'file'}
Adding a table description
We have added descriptions to our table fields using the Field Descriptor, but we haven’t added a description for the table. We can do this using the Tabular Data Resource description property.
For example adding a description to the yields table:
yields_schema.description = "The yields table contains raw plot yields for each experiment plot"
pp.pprint(yields_schema)
Key Points
The Frictionless Table Schema allows us to describe metadata for a table using JSON.
The Frictionless python module
describefunction is used to import a file as a table and infer information about it.Using the Frictionless python module we can edit the Table Schema’s Field Descriptors.
Frictionless Tables - Primary and Foreign Keys
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How can I create or show relationships between tables in my dataset?
Objectives
Identify primary key columns.
Add a foreign key to create a relationship with another table.
So far we have used the Frictionless Data Table Schema to add metadata to the fields in our dataset table. Using the table schema we can also define primary and foreign key relationships between the tables in our dataset, similar to an SQL database.
The primary key is a field which uniquely identifies every record in a table. The foreign key is a field in one table that refers to a primary key in another table.
The following diagram shows how our three tables are related to each other.
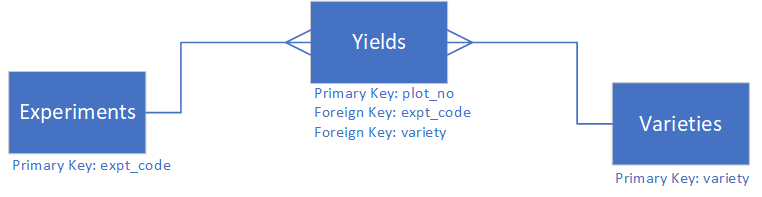
Adding Primary Keys
Using the Frictionless Python module we can add a primary key to a table schema. For example in the yields table, plot_no is the unique identifier for each record so we can make this the primary key.
yields_schema.schema.primary_key = "plot_no"
pp.pprint(yields_schema)
We now have plot_no identified as the primary key in the JSON schema for the yields table.
{'encoding': 'utf-8',
'format': 'csv',
'hashing': 'md5',
'name': 'yields',
'path': 'data/yields.csv',
'profile': 'tabular-data-resource',
'schema': {'fields': [{'description': 'A unique identifer for the plot',
'name': 'plot_no',
'title': 'Plot Number',
'type': 'integer'},
{'description': 'Institute standard code for a field '
'experiment',
'name': 'expt_id',
'title': 'Experiment Code',
'type': 'string'},
{'description': 'Date on which the plot was harvested',
'name': 'h_date',
'title': 'Harvest Date',
'type': 'string'},
{'name': 'col_y', 'type': 'integer'},
{'name': 'col_x', 'type': 'integer'},
{'name': 'variety', 'type': 'string'},
{'name': 'grain_weight', 'type': 'number'}],
'primaryKey': 'plot_no'},
'scheme': 'file'}
Exercise
Challenge: Add primary keys to the experiments and varieties table schemas.
Using the code for adding a primary key to the yields table as an example add primary keys to the experiments and varieties table schemas. The primary key for the varieties table is variety and for the experiments table is expt_code
Solution
varieties_schema.schema.primary_key = "variety" experiments_schema.schema.primary_key = "expt_code"
Adding Foreign Keys
With the primary keys defined we can now add foreign keys to the yields table. To add a foreign key we need to pass a JSON string which defines the table and field being referenced.
The JSON specifies the foreign key field for the table and the referenced table and its primary key field using the following syntax:
{
"fields": "FOREIGN-KEY-FIELD-NAME",
"reference": {
"resource": "REFERENCED-TABLE-NAME",
"fields": "REFERENCED-TABLE-PRIMARY-KEY-NAME"
}
}
Exercise
Challenge: Add foreign keys to the yields table schema.
Complete the following code to make variety and expt_code foreign keys in the yields table schema. Remember, variety reference the varieties table schema and expt_code references the experiments table schema. Note we add the keys to the schema as an array.
f_keys = [] f_keys.append({ "fields": "variety", "reference": { "resource": "varieties", "fields": "variety" } }) f_keys.append({ "fields": "______", "reference": { "resource": "______", "fields": "______" } }) yields_schema.schema.foreign_keys = f_keys pp.pprint(yields_schema)Solution
f_keys = [] f_keys.append({ "fields": "variety", "reference": { "resource": "varieties", "fields": "variety" } }) f_keys.append({ "fields": "expt_code", "reference": { "resource": "experiments", "fields": "expt_code" } }) yields_schema.schema.foreign_keys = f_keys pp.pprint(yields_schema){'encoding': 'utf-8', 'format': 'csv', 'hashing': 'md5', 'name': 'yields', 'path': 'data/yields.csv', 'profile': 'tabular-data-resource', 'schema': {'fields': [{'description': 'A unique identifer for the plot', 'name': 'plot_no', 'title': 'Plot Number', 'type': 'integer'}, {'description': 'Institute standard code for a field ' 'experiment', 'name': 'expt_id', 'title': 'Experiment Code', 'type': 'string'}, {'description': 'Date on which the plot was harvested', 'name': 'h_date', 'title': 'Harvest Date', 'type': 'string'}, {'name': 'col_y', 'type': 'integer'}, {'name': 'col_x', 'type': 'integer'}, {'name': 'variety', 'type': 'string'}, {'name': 'grain_weight', 'type': 'number'}], 'foreignKeys': [{'fields': 'variety', 'reference': {'fields': 'variety', 'resource': 'varieties'}}, {'fields': 'expt_code', 'reference': {'fields': 'expt_code', 'resource': 'experiments'}}], 'primaryKey': 'plot_no'}, 'scheme': 'file'}
Key Points
Frictionless allows you to define table fields as primary keys and foreign keys and create relationships between them
Frictionless Data Package
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is a Frictionless Data Package?
How can I create a Frictionless Data Package?
What can I do with a Frictionless Data Package?
Objectives
Learn the Frictionless Data Package Schema and how it is used to describe a dataset.
Add data tables to a data package.
Edit data package metadata.
Validate the data package.
FIXME
Key Points
First key point. Brief Answer to questions. (FIXME)
Transforming Frictionless Data
Overview
Teaching: 0 min
Exercises: 0 minQuestions
.to do
Objectives
.to do
Key Points
.to do