Functional Connectivity Analysis
Last updated on 2024-02-17 | Edit this page
Overview
Questions
- How can we estimate brain functional connectivity patterns from resting state data?
Objectives
- Use parcellations to reduce fMRI noise and speed up computation of functional connectivity
Introduction
Now we have an idea of three important components to analyzing neuroimaging data:
- Data manipulation
- Cleaning and confound regression
- Parcellation and signal extraction
In this notebook the goal is to integrate these 3 basic components and perform a full analysis of group data using Intranetwork Functional Connectivity (FC).
Intranetwork functional connectivity is essentially a result of performing correlational analysis on mean signals extracted from two ROIs. Using this method we can examine how well certain resting state networks, such as the Default Mode Network (DMN), are synchronized across spatially distinct regions.
ROI-based correlational analysis forms the basis of many more sophisticated kinds of functional imaging analysis.
Using Nilearn’s High-level functionality to compute correlation matrices
Nilearn has a built in function for extracting timeseries from functional files and doing all the extra signal processing at the same time. Let’s walk through how this is done
First we’ll grab our imports as usual
PYTHON
from nilearn import image as nimg
from nilearn import plotting as nplot
import numpy as np
import pandas as pd
from bids import BIDSLayoutLet’s grab the data that we want to perform our connectivity analysis on using PyBIDS:
PYTHON
#Use PyBIDS to parse BIDS data structure
layout = BIDSLayout(fmriprep_dir,
config=['bids','derivatives'])PYTHON
#Get resting state data (preprocessed, mask, and confounds file)
func_files = layout.get(subject=sub,
datatype='func', task='rest',
desc='preproc',
space='MNI152NLin2009cAsym',
extension='nii.gz',
return_type='file')
mask_files = layout.get(subject=sub,
datatype='func', task='rest',
desc='brain',
suffix="mask",
space='MNI152NLin2009cAsym',
extension='nii.gz',
return_type='file')
confound_files = layout.get(subject=sub,
datatype='func',
task='rest',
desc='confounds',
extension='tsv',
return_type='file')Now that we have a list of subjects to peform our analysis on, let’s load up our parcellation template file
PYTHON
#Load separated parcellation
parcel_file = '../resources/rois/yeo_2011/Yeo_JNeurophysiol11_MNI152/relabeled_yeo_atlas.nii.gz'
yeo_7 = nimg.load_img(parcel_file)Now we’ll import a package from nilearn, called
input_data which allows us to pull data using the
parcellation file, and at the same time applying data cleaning!
We first create an object using the parcellation file
yeo_7 and our cleaning settings which are the
following:
Settings to use:
- Confounds: trans_x, trans_y, trans_z, rot_x, rot_y, rot_z, white_matter, csf, global_signal
- Temporal Derivatives: Yes
- high_pass = 0.009
- low_pass = 0.08
- detrend = True
- standardize = True
PYTHON
from nilearn import input_data
masker = input_data.NiftiLabelsMasker(labels_img=yeo_7,
standardize=True,
memory='nilearn_cache',
verbose=1,
detrend=True,
low_pass = 0.08,
high_pass = 0.009,
t_r=2)The object masker is now able to be used on any
functional image of the same size. The
input_data.NiftiLabelsMasker object is a wrapper that
applies parcellation, cleaning and averaging to an functional image. For
example let’s apply this to our first subject:
PYTHON
# Pull the first subject's data
func_file = func_files[0]
mask_file = mask_files[0]
confound_file = confound_files[0]Before we go ahead and start using the masker that we’ve
created, we have to do some preparatory steps. The following should be
done prior to use the masker object:
- Make your confounds matrix (as we’ve done in Episode 06)
- Drop Dummy TRs that are to be excluded from our cleaning, parcellation, and averaging step
To help us with the first part, let’s define a function to help
extract our confound regressors from the .tsv file for us. Note that
we’ve handled pulling the appropriate
{confounds}_derivative1 columns for you! You just need to
supply the base regressors!
PYTHON
#Refer to part_06 for code + explanation
def extract_confounds(confound_tsv,confounds,dt=True):
'''
Arguments:
confound_tsv Full path to confounds.tsv
confounds A list of confounder variables to extract
dt Compute temporal derivatives [default = True]
Outputs:
confound_mat
'''
if dt:
dt_names = ['{}_derivative1'.format(c) for c in confounds]
confounds = confounds + dt_names
#Load in data using Pandas then extract relevant columns
confound_df = pd.read_csv(confound_tsv,delimiter='\t')
confound_df = confound_df[confounds]
#Convert into a matrix of values (timepoints)x(variable)
confound_mat = confound_df.values
#Return confound matrix
return confound_matFinally we’ll set up our image file for confound regression (as we
did in Episode 6). To do this we’ll drop 4 TRs from both our
functional image and our confounds file. Note that our
masker object will not do this for us!
PYTHON
#Load functional image
tr_drop = 4
func_img = nimg.load_img(func_file)
#Remove the first 4 TRs
func_img = func_img.slicer[:,:,:,tr_drop:]
#Use the above function to pull out a confound matrix
confounds = extract_confounds(confound_file,
['trans_x','trans_y','trans_z',
'rot_x','rot_y','rot_z',
'global_signal',
'white_matter','csf'])
#Drop the first 4 rows of the confounds matrix
confounds = confounds[tr_drop:,:] Using the masker
Finally with everything set up, we can now use the masker to perform our:
- Confounds cleaning
- Parcellation
- Averaging within a parcel All in one step!
PYTHON
#Apply cleaning, parcellation and extraction to functional data
cleaned_and_averaged_time_series = masker.fit_transform(func_img,confounds)
cleaned_and_averaged_time_series.shapeOUTPUT
(147,43)Just to be clear, this data is automatically parcellated for you, and, in addition, is cleaned using the confounds you’ve specified already!
The result of running masker.fit_transform is a matrix
that has:
- Rows matching the number of timepoints (148)
- Columns, each for one of the ROIs that are extracted (43)
But wait!
We originally had 50 ROIs, what happened to 3 of
them? It turns out that masker drops ROIs that are empty
(i.e contain no brain voxels inside of them), this means that 3 of our
atlas’ parcels did not correspond to any region with signal! To see
which ROIs are kept after computing a parcellation you can look at the
labels_ property of masker:
OUTPUT
[1, 2, 4, 5, 6, 7, 8, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 33, 34, 35, 36, 37, 38, 40, 41, 42, 43, 44, 45, 46, 47, 49]
Number of labels 43This means that our ROIs of interest (44 and 46) cannot be accessed using the 44th and 46th columns directly!
There are many strategies to deal with this weirdness. What we’re
going to do is to create a new array that fills in the regions that were
removed with 0 values. It might seem a bit weird now, but
it’ll simplify things when we start working with multiple subjects!
First we’ll identify all ROIs from the original atlas. We’re going to
use the numpy package which will provide us with functions
to work with our image arrays:
PYTHON
import numpy as np
# Get the label numbers from the atlas
atlas_labels = np.unique(yeo_7.get_fdata().astype(int))
# Get number of labels that we have
NUM_LABELS = len(atlas_labels)
print(NUM_LABELS)OUTPUT
50Now we’re going to create an array that contains:
- A number of rows matching the number of timepoints
- A number of columns matching the total number of regions
PYTHON
# Remember fMRI images are of size (x,y,z,t)
# where t is the number of timepoints
num_timepoints = func_img.shape[3]
# Create an array of zeros that has the correct size
final_signal = np.zeros((num_timepoints, NUM_LABELS))
# Get regions that are kept
regions_kept = np.array(masker.labels_)
# Fill columns matching labels with signal values
final_signal[:, regions_kept] = cleaned_and_averaged_time_series
print(final_signal.shape)It’s a bit of work, but now we have an array where:
- The column number matches the ROI label number
- Any column that is lost during the
masker.fit_transformis filled with0values!
To get the columns corresponding to the regions that we’ve kept, we
can simply use the regions_kept variable to select columns
corresponding to the regions that weren’t removed:
This is identical to the original output of
masker.fit_transform
This might seem unnecessary for now, but as you’ll see in a bit, it’ll come in handy when we deal with multiple subjects!d
Calculating Connectivity
In fMRI imaging, connectivity typically refers to the correlation of the timeseries of 2 ROIs. Therefore we can calculate a full connectivity matrix by computing the correlation between all pairs of ROIs in our parcellation scheme!
We’ll use another nilearn tool called
ConnectivityMeasure from nilearn.connectome.
This tool will perform the full set of pairwise correlations for us
Like the masker, we need to make an object that will calculate connectivity for us.
Try using SHIFT-TAB to see what options you can put into
the kind argument of ConnectivityMeasure
Then we use correlation_measure.fit_transform() in order
to calculate the full correlation matrix for our parcellated data!
PYTHON
full_correlation_matrix = correlation_measure.fit_transform([cleaned_and_averaged_time_series])
full_correlation_matrix.shapeNote that we’re using a list [final_signal], this is
because correlation_measure works on a list of
subjects. We’ll take advantage of this later!
The result is a matrix which has:
- A number of rows matching the number of ROIs in our parcellation atlas
- A number of columns, that also matches the number of ROIs in our parcellation atlas
You can read this correlation matrix as follows:
Suppose we wanted to know the correlation between ROI 30 and ROI 40
- Then Row 30, Column 40 gives us this correlation.
- Row 40, Column 40 can also give us this correlation
This is because the correlation of \(A --> B = B --> A\)
NOTE: Remember we were supposed to lose 7 regions
from the masker.fit_transform step. The correlations for
these regions will be 0!
Let’s try pulling the correlation for ROI 44 and 46!
Note that it’ll be the same if we swap the rows and columns!
Exercise
Apply the data extract process shown above to all subjects in our subject list and collect the results. Your job is to fill in the blanks!
PYTHON
# First we're going to create some empty lists to store all our data in!
ctrl_subjects = []
schz_subjects = []
# We're going to keep track of each of our subjects labels here
# pulled from masker.labels_
labels_list = []
# Get the number of unique labels in our parcellation
# We'll use this to figure out how many columns to make (as we did earlier)
atlas_labels = np.unique(yeo_7.get_fdata().astype(int))
NUM_LABELS = len(atlas_labels)
# Set the list of confound variables we'll be using
confound_variables = ['trans_x','trans_y','trans_z',
'rot_x','rot_y','rot_z',
'global_signal',
'white_matter','csf']
# Number of TRs we should drop
TR_DROP=4
# Lets get all the subjects we have
subjects = layout.get_subjects()
for sub in subjects:
#Get the functional file for the subject (MNI space)
func_file = layout.get(subject=??,
datatype='??', task='rest',
desc='??',
space='??'
extension="nii.gz",
return_type='file')[0]
#Get the confounds file for the subject (MNI space)
confound_file=layout.get(subject=??, datatype='??',
task='rest',
desc='??',
extension='tsv',
return_type='file')[0]
#Load the functional file in
func_img = nimg.load_img(??)
#Drop the first 4 TRs
func_img = func_img.slicer[??,??,??,??]
#Extract the confound variables using the function
confounds = extract_confounds(confound_file,
confound_variables)
#Drop the first 4 rows from the confound matrix
confounds = confounds[??]
# Make our array of zeros to fill out
# Number of rows should match number of timepoints
# Number of columns should match the total number of regions
fill_array = np.zeros((func_img.shape[??], ??))
#Apply the parcellation + cleaning to our data
#What function of masker is used to clean and average data?
time_series = masker.fit_transform(??,??)
# Get the regions that were kept for this scan
regions_kept = np.array(masker.labels_)
# Fill the array, this is what we'll use
# to make sure that all our array are of the same size
fill_array[:, ??] = time_series
#If the subject ID starts with a "1" then they are control
if sub.startswith('1'):
ctrl_subjects.append(fill_array)
#If the subject ID starts with a "5" then they are case (case of schizophrenia)
if sub.startswith('5'):
schz_subjects.append(fill_array)PYTHON
# First we're going to create some empty lists to store all our data in!
pooled_subjects = []
ctrl_subjects = []
schz_subjects = []
#Which confound variables should we use?
confound_variables = ['trans_x','trans_y','trans_z',
'rot_x','rot_y','rot_z',
'global_signal',
'white_matter','csf']
for sub in subjects:
#Get the functional file for the subject (MNI space)
func_file = layout.get(subject=sub,
datatype='func', task='rest',
desc='preproc',
extension="nii.gz",
return_type='file')[0]
#Get the confounds file for the subject (MNI space)
confound_file=layout.get(subject=sub, datatype='func',
task='rest',
desc='confounds',
extension='tsv',
return_type='file')[0]
#Load the functional file in
func_img = nimg.load_img(func_file)
#Drop the first 4 TRs
func_img = func_img.slicer[:,:,:,tr_drop:]
#Extract the confound variables using the function
confounds = extract_confounds(confound_file,
confound_variables)
#Drop the first 4 rows from the confound matrix
#Which rows and columns should we keep?
confounds = confounds[tr_drop:,:]
#Apply the parcellation + cleaning to our data
#What function of masker is used to clean and average data?
time_series = masker.fit_transform(func_img,confounds)
#This collects a list of all subjects
pooled_subjects.append(time_series)
#If the subject ID starts with a "1" then they are control
if sub.startswith('1'):
ctrl_subjects.append(time_series)
#If the subject ID starts with a "5" then they are case (case of schizophrenia)
if sub.startswith('5'):
schz_subjects.append(time_series)The result of all of this code is that:
- Subjects who start with a “1” in their ID, are controls, and are
placed into the
ctrl_subjectslist - Subjects who start with a “2” in their ID, have schizophrenia, and
are placed into the
schz_subjectslist
What’s actually being placed into the list? The cleaned, parcellated
time series data for each subject (the output of
masker.fit_transform)!
A helpful trick is that we can re-use the
correlation_measure object we made earlier and apply it to
a list of subject data!
PYTHON
ctrl_correlation_matrices = correlation_measure.fit_transform(ctrl_subjects)
schz_correlation_matrices = correlation_measure.fit_transform(schz_subjects)At this point, we have correlation matrices for each subject across two populations. The final step is to examine the differences between these groups in their correlation between ROI 43 and ROI 45.
Visualizing Correlation Matrices and Group Differences
An important step in any analysis is visualizing the data that we have. We’ve cleaned data, averaged data and calculated correlations but we don’t actually know what it looks like! Visualizing data is important to ensure that we don’t throw pure nonsense into our final statistical analysis
To visualize data we’ll be using a python package called
seaborn which will allow us to create statistical
visualizations with not much effort.
We can view a single subject’s correlation matrix by using
seaborn’s heatmap function:
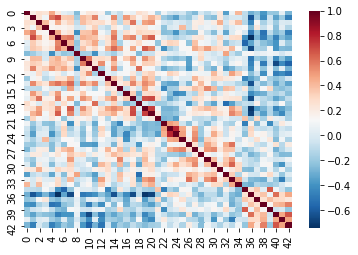
Recall that cleaning and parcellating the data causes some ROIs to
get dropped. We dealt with this by filling an array of zeros
(fill_array) only for columns where the regions are kept
(regions_kept). This means that we’ll have some correlation
values that are 0!
This is more apparent if we plot the data slightly differently. For demonstrative purposes we’ve:
- Taken the absolute value of our correlations so that the 0’s are the darkest color
- Used a different color scheme
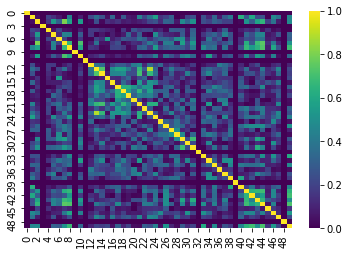
The dark lines in the correlation matrix correspond to regions that were dropped and therefore have 0 correlation!
We can now pull our ROI 44 and 46 by indexing our list of correlation matrices as if it were a 3D array (kind of like an MR volume). Take a look at the shape:
This is of form:
ctrl_correlation_matrices[subject_index, row_index,
column_index]
Now we’re going to pull out just the correlation values between ROI 43 and 45 across all our subjects. This can be done using standard array indexing:
PYTHON
ctrl_roi_vec = ctrl_correlation_matrices[:,43,45]
schz_roi_vec = schz_correlation_matrices[:,43,45]Next we’re going to arrange this data into a table. We’ll create two
tables (called dataframes in the python package we’re using,
pandas)
PYTHON
#Create control dataframe
ctrl_df = pd.DataFrame(data={'dmn_corr':ctrl_roi_vec, 'group':'control'})
ctrl_df.head()PYTHON
# Create the schizophrenia dataframe
scz_df = pd.DataFrame(data={'dmn_corr':schz_roi_vec, 'group' : 'schizophrenia'})
scz_df.head()The result is:
ctrl_dfa table containing the correlation value for each control subject, with an additional column with the group label, which is ‘control’scz_dfa table containing the correlation value for each schizophrenia group subject, with an additional column with the group label, which is ‘schizophrenia’
For visualization we’re going to stack the two tables together…
PYTHON
#Stack the two dataframes together
df = pd.concat([ctrl_df,scz_df], ignore_index=True)
# Show some random samples from dataframe
df.sample(n=3)Finally we’re going to visualize the results using the python package
seaborn!
PYTHON
#Visualize results
# Create a figure canvas of equal width and height
plot = plt.figure(figsize=(5,5))
# Create a box plot, with the x-axis as group
#the y-axis as the correlation value
ax = sns.boxplot(x='group',y='dmn_corr',data=df,palette='Set3')
# Create a "swarmplot" as well, you'll see what this is..
ax = sns.swarmplot(x='group',y='dmn_corr',data=df,color='0.25')
# Set the title and labels of the figure
ax.set_title('DMN Intra-network Connectivity')
ax.set_ylabel(r'Intra-network connectivity $\mu_\rho$')
plt.show()Although the results here aren’t significant they seem to indicate that there might be three subclasses in our schizophrenia group - of course we’d need a lot more data to confirm this! The interpretation of these results should ideally be based on some a priori hypothesis!
Congratulations!
Hopefully now you understand that:
- fMRI data needs to be pre-processed before analyzing
- Manipulating images in python is easily done using
nilearnandnibabel - You can also do post-processing like confound/nuisance regression
using
nilearn - Parcellating is a method of simplifying and “averaging” data. The type of parcellation reflect assumptions you make about the structure of your data
- Functional Connectivity is really just time-series correlations between two signals!
- MR images are essentially 3D arrays where each voxel is represented by an (i,j,k) index
- Nilearn is Nibabel under the hood, knowing how Nibabel works is key to understanding Nilearn