Cleaning Confounders in your Data with Nilearn
Last updated on 2024-02-17 | Edit this page
Overview
Questions
- How can we clean the data so that it more closely reflects BOLD instead of artifacts
Objectives
- Understand the motivation behind confound/nuisance regression
- Learn how to implement cleaning using nilearn and fmriprep
Introduction
Movement is the enemy of Neuroimagers
Movement is an important problem that we need to deal with in our data. In resting state fMRI movement can induce false correlations between brain regions leading to inaccurate conclusions about brain connectivity. However, there is a unique problem that resting state fMRI faces when dealing with movement:
- In resting state fMRI, we don’t actually ever see the true underlying BOLD signal.
This is un-like task-based fMRI where there is an expectation that we’ll observe a BOLD signal upon event onset - we have some information about what the true underlying BOLD signal might look like. In order to deal with the problem of movement in resting state fMRI we need to model our fMRI signal to be comprised of true brain signal and motion (confounder) signals. We can make estimates about how motion can influence our data then remove it from the recorded signal; the leftover signal is what we estimate the BOLD signal to be.
This process of removing motion-based artifacts from our data is called confound regression, which is essentially fitting a linear model using motion estimates as regressors then subtracting it out from the signal. Hopefully in this process we get a closer estimate of what the actual brain-induced BOLD signal looks like.
In this section we’ll implement confound regression for resting-state data using nilearn’s high-level functionality.
Setting up
Let’s load in some modules as we’ve done before
PYTHON
import os
from nilearn import image as nimg
from nilearn import plotting as nplot
import matplotlib.pyplot as plt
import numpy as np
import nibabel as nib
%matplotlib inlineSetting up our Motion Estimates
The beauty of FMRIPREP is that it estimates a number of motion-related signals for you and outputs it into:
sub-xxxx_task-xxxx_desc-confounds_timeseries.tsv
This is basically a spreadsheet that has columns related to each
motion estimate type and rows for timepoints. We can view these using a
language-python package called pandas.
Let’s pick an fMRI file to clean and pull out the confound tsv that FMRIPREP computed for us:
PYTHON
import bids # assuming pip install pybids was covered earlier
sub = '10788'
fmriprep_dir = '../data/ds000030/derivatives/fmriprep/'
layout = bids.BIDSLayout(fmriprep_dir,validate=False,
config=['bids','derivatives'])PYTHON
func_files = layout.get(subject=sub,
datatype='func', task='rest',
desc='preproc',
space='MNI152NLin2009cAsym',
extension='nii.gz',
return_type='file')
mask_files = layout.get(subject=sub,
datatype='func', task='rest',
desc='brain',
suffix='mask',
space='MNI152NLin2009cAsym',
extension="nii.gz",
return_type='file')
confound_files = layout.get(subject=sub,
datatype='func', task='rest',
desc='confounds',
extension="tsv",
return_type='file')Using pandas we can read in the confounds.tsv file as a
spreadsheet and display some rows:
PYTHON
#Delimiter is \t --> tsv is a tab-separated spreadsheet
confound_df = pd.read_csv(confound_file, delimiter='\t')
print(f"Read {len(confound_df.columns)} confounder items, each {len(confound_df)} TRs.")
print(confound_df.head)Each column in this DataFrame confound_df represents a
specific confound variable that is either estimated directly from head
motion during the functional scan or other noise characteristics that
may capture noise (non grey-matter signal for example). Each row
represents values from a TR/sample. So the number of rows in your
confound_df should match the number of TRs you have in the
functional MR data.
Picking your Confounds
The choice of which confounds to use in functional imaging analysis is a source of large debate. We recommend that you check out these sources for a start:
- https://www.sciencedirect.com/science/article/pii/S1053811917302288#f0005
- https://www.sciencedirect.com/science/article/pii/S1053811917302288 For now we’re going to replicate the pre-processing (mostly) from the seminal Yeo1000 17-networks paper: https://www.ncbi.nlm.nih.gov/pubmed/21653723
The Yeo 2011 Pre-processing schema
Confound regressors
- 6 motion parameters (trans_x, trans_y, trans_z, rot_x, rot_y, rot_z)
- Global signal (global_signal)
- Cerebral spinal fluid signal (csf)
- White matter signal (white_matter)
This is a total of 9 base confound regressor variables. Finally we add temporal derivatives of each of these signals as well (1 temporal derivative for each), the result is 18 confound regressors.
Temporal Derivatives are the changes in values across 2 consecutive samples. It represents change in signal over time. For example, when dealing with the confound variable “X”, which represents motion along the “trans_x” direction, the temporal derivative represents velocity in the X direction.
Low/High pass filtering
- Low pass filtering cutoff: 0.08
- High pass filtering cutoff: 0.009
Low pass filters out high frequency signals from our data. fMRI signals are slow evolving processes, any high frequency signals are likely due to noise High pass filters out any very low frequency signals (below 0.009Hz), which may be due to intrinsic scanner instabilities
Drop dummy TRs
During the initial stages of a functional scan there is a strong signal decay artifact, thus the first 4ish or so TRs are very high intensity signals that don’t reflect the rest of the scan. Therefore we drop these timepoints.
Censoring + Interpolation (leaving out)
Censoring involves removal and interpolation of high-movement frames from the fMRI data. Interpolation is typically done using sophisticated algorithms much like Power et al. 2014.
We won’t be using censoring + interpolation since its fairly complicated and would take up too much time
Setting up Confound variables for regression
Computing temporal derivatives for confound variables
First we’ll select our confound variables from our dataframe. You can do this by specifying a list of confounds, then using that list to pull out the associated columns
PYTHON
# Select confounds
confound_vars = ['trans_x','trans_y','trans_z',
'rot_x','rot_y','rot_z',
'global_signal',
'csf', 'white_matter']Next we need to get derivatives for each of these columns. Luckily fMRIPrep provides this for us. Derivative columns are denoted as the following:
- {NAME_OF_COLUMN}_derivative1
Since typing is alot of work, we’ll use a for-loop instead to pick
the derivatives for our confound_vars:
PYTHON
# Get derivative column names
derivative_columns = ['{}_derivative1'.format(c) for c
in confound_vars]
print(derivative_columns)Now we’ll join these two lists together:
Finally we’ll use this list to pick columns from our confounds table
What the NaN???
As you might have noticed, we have NaN’s in our confound dataframe. This happens because there is no prior value to the first index to take a difference with, but this isn’t a problem since we’re going to be dropping 4 timepoints from our data and confounders anyway!
Dummy TR Drop
Now we’ll implement our Dummy TR Drop. Remember this means that we are removing the first 4 timepoints from our functional image (we’ll also have to do this for our first 4 confound timepoints!):
PYTHON
#First we'll load in our data and check the shape
raw_func_img = nimg.load_img(func_file)
raw_func_img.shapeRecall that the fourth dimension represents frames/TRs(timepoints). We want to drop the first four timepoints entirely, to do so we use nibabel’s slicer feature. We’ll also drop the first 4 confound variable timepoints to match the functional scan
OUTPUT
(65, 77, 49, 148)Applying confound regression
Now we’d like to clean our data of our selected confound variables. There are two ways to go about this:
- If you have nilearn version 0.5.0 or higher use
nilearn.image.clean_img(image,confounds,…) - If you want full control over specific parts of the image you’re
cleaning use
nilearn.signal.clean(signals,confounds,…)
The first method is probably most practical and can be done in one line given what we’ve already set-up. However, in cases of very large datasets (HCP-style), the second method might be preferable for optimizing memory usage.
First note that both methods take an argument confounds.
This is a matrix:
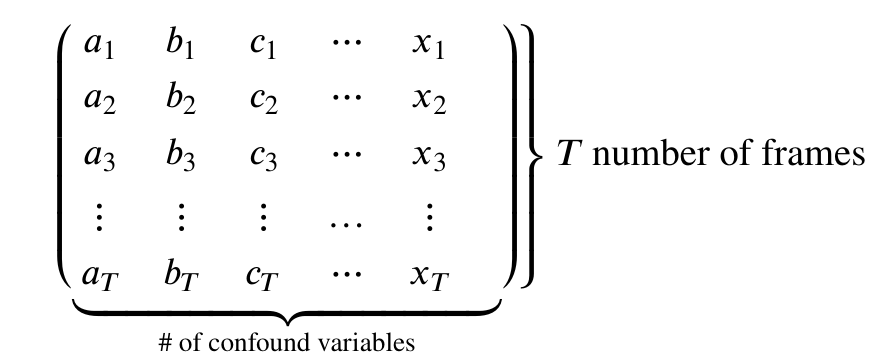
Therefore our goal is to take our confound matrix and work it into a matrix of the form above. The end goal is a matrix with 147 rows, and columns matching the number of confound variables (9x2=18)
Luckily this is a one-liner!
PYTHON
confounds_matrix = drop_confound_df.values
#Confirm matrix size is correct
confounds_matrix.shapeLet’s clean our image!
Using nilearn.image.clean_img
First we’ll describe a couple of this function’s important arguments. Any argument enclosed in [arg] is optional
nilearn.image.clean_img(image,confounds,[low_pass],[high_pass],[t_r],[mask_img],[detrend],[standardize])
Required:
-
image: The functional image (func_img) -
confounds: The confound matrix (confounds)
Optional:
-
low_pass: A low pass filter cut-off -
high_passA high pass filter cut-off -
t_r: This is required if using low/high pass, the repetition time of acquisition (imaging metadata) -
mask_imgApply a mask when performing confound regression, will speed up regression -
detrend: Remove drift from the data (useful for removing scanner instability artifacts) [default=True] -
standardize: Set mean to 0, and variance to 1 –> sets up data for statistical analysis [default=True]
What we’re using:
The Repetition Time of our data is 2 seconds, in addition since we’re replicating (mostly) Yeo 2011’s analysis:
- high_pass = 0.009
- low_pass = 0.08
- detrend = True
- standardize = True
In addition we’ll use a mask of our MNI transformed functional image
( mask ) to speed up cleaning
PYTHON
#Set some constants
high_pass= 0.009
low_pass = 0.08
t_r = 2
#Clean!
clean_img = nimg.clean_img(func_img,confounds=confounds_matrix,detrend=True,standardize=True,
low_pass=low_pass,high_pass=high_pass,t_r=t_r, mask_img=mask_file)
#Let's visualize our result! Doesn't really tell us much, but that's the data we're using for analysis!
nplot.plot_epi(clean_img.slicer[:,:,:,50])
before_figure = nplot.plot_carpet(clean_img, mask, t_r=t_r)
after_figure = nplot.plot_carpet(func_img, mask, t_r=t_r)Done!
Hopefully by now you’ve learned what confound regression is, and how to perform it in nilearn using 2 different methods. We’d like to note that there are many more methods to perform confound regression (simultaneous signal extraction + confound regression for example) but all those methods fundamentally rely on what you’ve done here.
In addition, performing confound regression on functional volumes, is also not the only way to do data cleaning. More modern methods involve applying confound regression on functional surfaces, however, those methods are too advanced for an introductory course to functional data analysis and involve tools outside of python.
If you’re interested in surface-based analysis we recommend that you check out the following sources:
- https://edickie.github.io/ciftify/#/
- https://www.humanconnectome.org/software/connectome-workbench
- The minimal preprocessing pipelines for the Human Connectome Project
The section below is optional and is a more advanced
dive into the underlying mechanics of how nilearn.clean_img
works:
- Nuisance regression is an attempt to make sure your results aren’t driven by non-brain signals
- With resting state, we don’t actually ever know the true signal - we can only attempt to estimate it