Using large language models
Last updated on 2025-12-01 | Edit this page
Estimated time: 120 minutes
Background
Chat assistants like ChatGPT, Gemini and Claude are products widely used today for tasks such as content generation, question answering, research and software development among many others. These products, also known as Large Language Models (LLMs), are based on the Transformer architecture, with several enhancements. It is undeniable that the rapid rise of such models has had quite a disruptive and strong impact. But what are these models exactly? How do they work ‘under the hood’? And how can one use them programmatically, in a responsible and effective way?










Now that we know that dealing with written language means extracting structure from unstructured text (NLP Task), we can understand there is a rationale behind the kind of tasks LLMs could tackle. Every time we prompt a chat model, we are feeding them a very long list of tokens containing a task that needs to be solved. The question that interests us is not whether LLMs are “intelligent” or not (even though that could be a very interesting topic on its own, its not the goal of this course); we will rather focus on using LLMs as yet a new automated tool. And, like any other Machine Learning tool, we are still dealing here with a model that takes an input and delivers an output for that input. The only thing that changed is the complexity of the input-output pairs; and hence, the complexity of validating the outputs increased accordingly.
Our duty as responsible NLP practitioners remains, and we must keep asking the same questions:
- How can I shape the task so I obtain the information I need?
- How do I measure what proportion of the outputs are right?
- How do I know if this will behave as expected with unexpected inputs?
- In short: How do I evaluate my task?
This episode is a gentle introduction to LLMs which aims to equip you with knowledge of the underpinnings of LLMs based on transformers architecture, as well as practical skills to start programmatically working with LLMs in your own projects, without necessarily relying on proprietary products and platforms.
What are Large Language Models (LLMs)?
Large language models (LLMs) are generative transformer-based language models that are trained to interact in a conversational-like manner with humans. The text that they generate are mostly natural language but can, in theory, constitute any sequence of characters and symbols, such as software code. The term Large was appended to the well known Language Model term to highlight the scale on which this architectures are trained. To give an example, BERT in 2018 was considered a big model and had roughly 100 million parameters; GPT-2 in 2019 had 1.5 billion parameters, and GPT-3 was published in 2020 as a model with 175 billion parameters, and so forth.
Since we already learned about the vanilla transformer architecture, in this episode we will focus on the most recent language models, and we will keep calling them LLMs, even though they are not necessarily that large anymore. In this episode we will cover mostly models that have been fine-tuned to be chat assistants, capable of integrating into the text generation a multi-turn interaction.
Given the hype around the field, people keep calling all new models (and some “old models” as well) an LLM or even worse just AI. We will stick here to the term LLM to avoid confusions. Have in mind, however, that especially recent models are being published with the particular goal of reducing parameter size while retaining the performance of the larger models, some of them are even less than 1 billion parameters already! This is good news for the open source engineers and researchers, because such advancements mean we can now make use of the new capabilities of language models in our own local servers, and even our laptops, without needing to pay fees or compromise the privacy of our data and experiments.
Transformers vs. LLMs
To emphasize again, LLMs are also trained using the transformer neural network architecture, including the use of the self-attention mechanism inside the generative Decoder (as discussed in Lesson 3). However, they are three main characteristics that the newest generations of LLMs have:
Scale: there are three dimensions in which current LLMs exceed general transformer language models in terms of scale. The most important one is the number of training parameters (weights) that are used for training models. In current models there are hundreds of billions of parameters up to trillions. The second factor is the amount of training data (raw text sequences) used for training. Current LLMs use snapshots of the internet (upwards of hundreds of terabytes in size) as a base for training and possibly augment this with additional manually curated and artificially generated data. The third factor is the context window a model can handle, this is the amount of tokens a model can see and process at a time; to give perspective, BERT was able to handle 512 input tokens per interaction, whereas some LLMs are already able to process a couple of million tokens at a time. The sheer scale characteristic of LLMs mean that such models require extremely resource-intensive computation to train. State-of-the-art LLMs require multiple dedicated Graphical Processing Units (GPUs) with tens or hundreds of gigabytes of memory to load and train in reasonable time. GPUs offer high parallelisability in their architecture for data processing which makes them more efficient for training these models.
-
Post-training: After training a base language model on textual data, there is an additional step of fine-tuning for enabling conversation in a prompt style of interaction with users, which current LLMs are known for. After the pre-training and neural network training stages we end up with what is called a base model. The base model is a language model which is essentially a token sequence generator optimized for the next token prediction (Language Modelling) task. This model by itself is not suitable for the interaction style we see with current LLMs, which can do things like answer questions, interpret instructions from the user, and incorporate feedback to improve responses in conversations. Post-training additions include:
- Supervised Fine-Tuning (SFT): Training on curated examples of desired input-output pairs to teach instruction-following and helpful responses.
- Reinforcement Learning from Human Feedback (RLHF): Using human preference data to align model outputs with what humans find helpful.
- “Safety” Training: Include so-called guardrails to avoid generating harmful outputs.
- Specialized Capabilities: Often includes training for specific skills like coding, reasoning, or tool use
Generalization: Because of the wide range of post-training tasks they’ve been through, LLMs can be “directly applied” across a wide range of NLP tasks such as summarization, translation, question answering, etc., without necessarily the need for fine-tuning or training separate models for different NLP tasks. They are also capable of calling external tools or follow more complicated instructions that go beyond the next word probabilities.
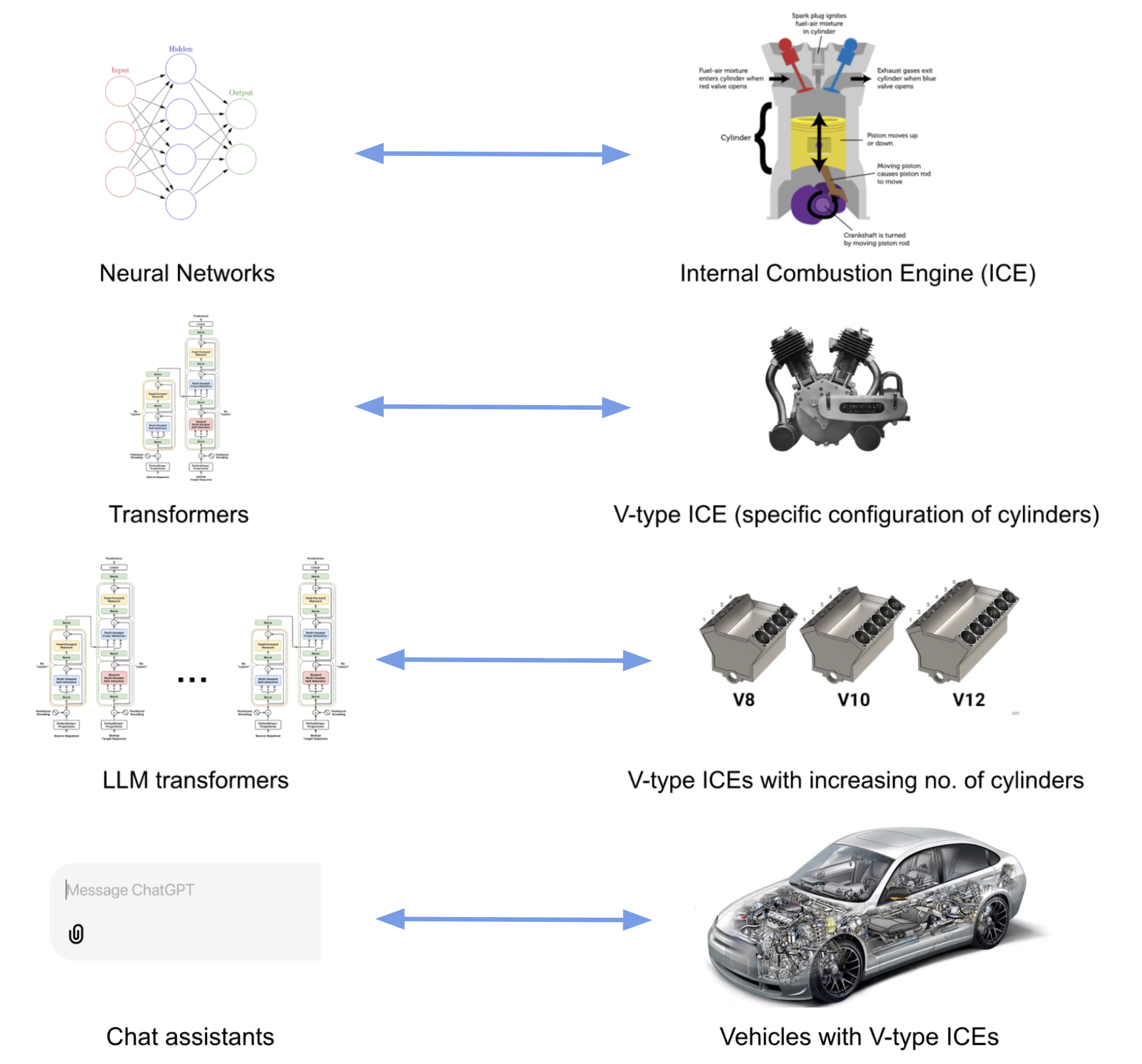
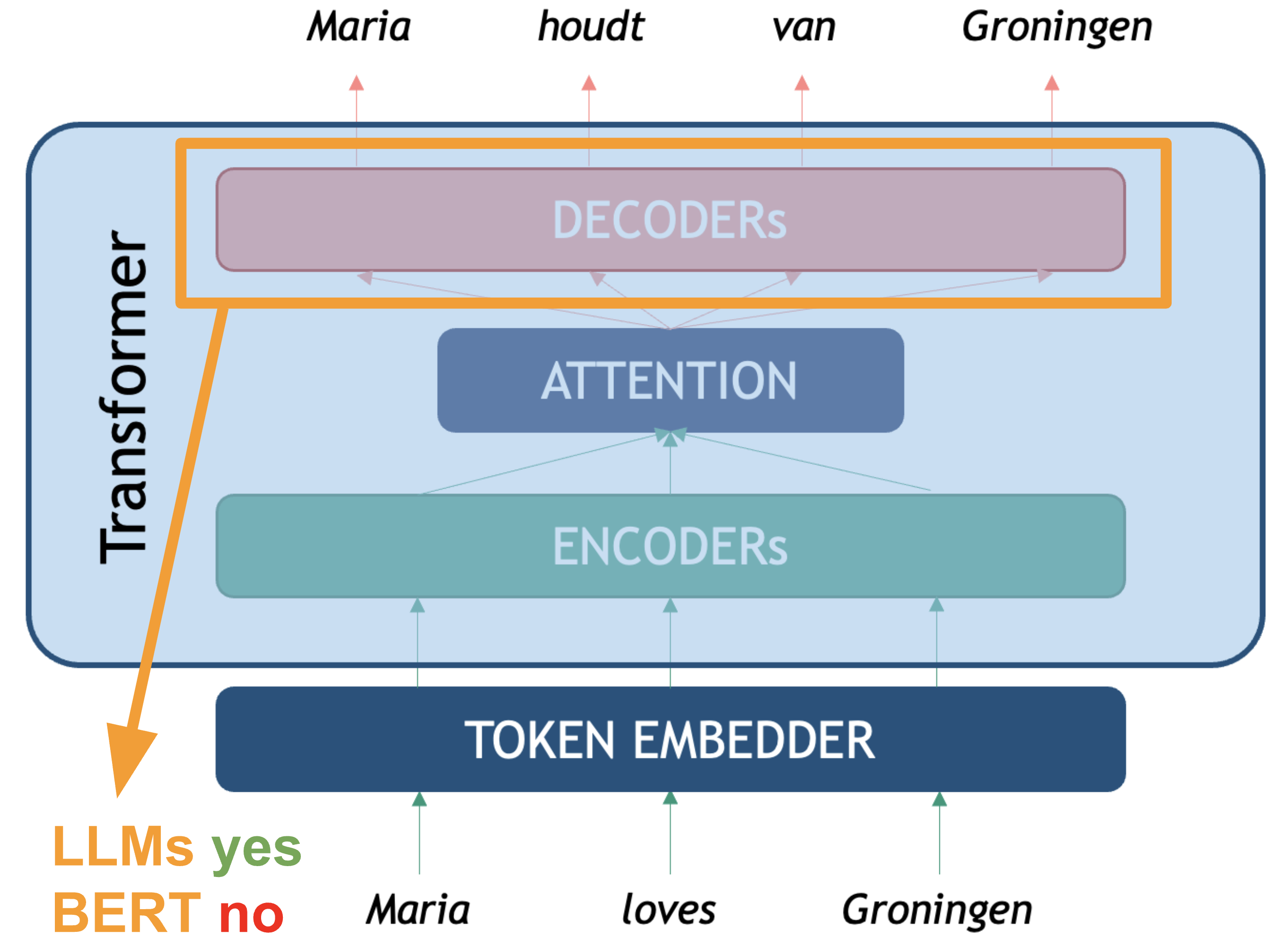
What about the relation between BERT, which we learned about in the
previous episode, and LLMs? Apart from the differences described above,
BERT only makes use of the encoder layer of the transformers
architecture because the goal is on creating token representations
preserving contextual meaning (Embedding Model). There is no generative
component to do something with those representations.
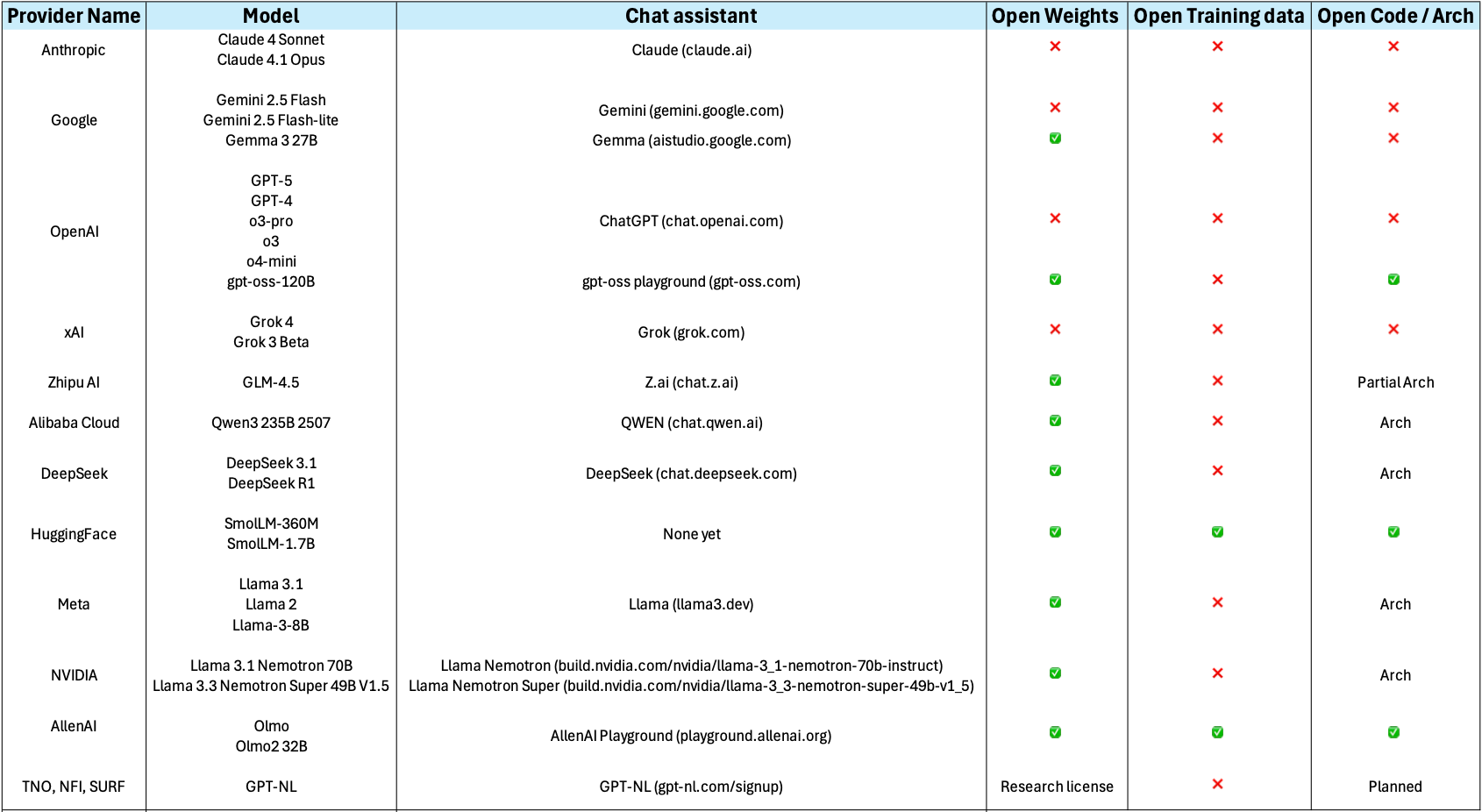
The LLM Taxonomy
Many different LLMs have been, and continue to be, developed. There are both proprietary and open-source varieties. Real open-source varieties should make the whole path of model creation available: inform exactly which data was used to train the model, including filters for data quality; give a detailed explanation of the architecture and hyper-parameters, including the code used to train them, and of course make them free, open and accessible online. Unfortunately completely ope source models are scarce, but the partially open source number models keeps growing. Below is a summary of some relevant LLMs together with their creators, chat assistant interfaces, and proprietary status:
Openness and Licensing Considerations
The spectrum of model availability ranges from fully open to completely proprietary:
Open-weights release the trained model parameters while keeping training code or data proprietary. This allows you to run and fine-tune the model locally but if you don’t have the code used to train the model or information about the architecture used, it limits your ability to fully understand or replicate the training process.
Open training data they release the text data used for pretraining.
Open architecture they publish a paper about the neural network architecture and specific configuration they used for training. Or they release the actual source code they used for pretraining.
Ideally, if you want to use a model for empirical academic research you might decide for models that are completely open in all three of the above facets. Although, open training data is quite rare for available state-of-the-art models.
Commercial/proprietary models like GPT-4, Claude, or Gemini are accessed only through APIs. While often offering superior performance, they provide no access to internal architecture and may have usage restrictions or costs that scale with volume.
Consider your requirements for: - Code modification and customization - Data privacy and control - Commercial usage rights - Research reproducibility - Long-term availability guarantees
Besides considering the openness of the models, there are several families of LLM to consider, which differ not only in training data and scale of parameters but also in training and post-training techniques. Here we show a (non-exhaustive) general list of categories that have branched out from the vanilla generative transformer language models, understanding the difference can also help you choose the proper model.
The two main distinctions of architecture are:
- Embedder LLM (BERT, OpenAI Embed, Cohere Embed, Nomic): these are the “encoder only” LLMs which have been optimized for holding representations that help to compute sentence/paragraph similarities.
- Base Generative LLM (GPT, LLama, GPT3): this is the generative “decoder-only” transformer that is trained to generate the most likely token based on the previous tokens.
All the next ones are basically “post-trained” (SFT + RLHF) generative models with a different focus. These are not hard categories, but you will most likely encounter the concepts everywhere in the Web:
Domain-specific LLM: a base model fine-tuned with specialized data like medical papers or legal cases and with RLHF. Could also be specialized on Question-Answering datasets, etc…
LLM-Instruct (Claude, Llama-Instruct): these are the LLMs that have been fine-tuned with step-by-step human instructions to follow user instructions
Reasoning/Thinking LLM (Cohere Command-R, OpenAI o1, Gemini 2.5, …): these models have been post-trained to generate “thinking tokens” in between, before providing the final answer to the user, with the aim of improving complex task solving capabilities. This ones can also give structured output, like JSON.
Tool Augmented LLMs (GPT4): these models have been post-trained for calling external tools like Web Search, API calls, Execute code, etc… and then generate a final answer (token output) integrating the tools’ results.
Interacting with an LLM
Before exploring how we can invoke LLMs programmatically to solve the
kinds of tasks above, let us setup and load our first LLM. We will keep
using the transformers library, just as with the BERT
examples.
Load and setup the model (LLM)
Let’s load a open source lightweight
SmolLM2-135M-Instruct, as you might have guessed it is a
model with 135M parameters which has been fine-tuned for following
instructions, therefore you can use it as a chat assistant:
PYTHON
# We'll use SmolLM-135M - an open, small, fast model
model_name = "HuggingFaceTB/SmolLM2-135M-Instruct" # fine-tuned assistant model
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Check if model is loaded correctly
print(f"Model loaded! It has {model.num_parameters():,} parameters")Basic Text Generation
Let’s perform inference with the LLM to generate some text.
PYTHON
# We Build pipeline as usual, this time the task is `text_generation` (a decoder model)
llm = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "Where is Groningen located?"
# We can first look at how the text is also being converted into a sequence of tokens before generating
print(tokenizer(prompt))
print(tokenizer.convert_ids_to_tokens(tokenizer(prompt)["input_ids"]))This gives the following output:
{'input_ids': [9576, 314, 452, 992, 45670, 3807, 47], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
['Where', 'Ġis', 'ĠG', 'ron', 'ingen', 'Ġlocated', '?']Now we ask the pipeline to generate the tokens to complete the given
input. Remember that the pipeline post-processes the output token for us
and shows us the text string under generated_text
field:
This is not a fully deterministic output, so the content of the
response will vary, but the structure is always the same: a python list,
containing as first element a dictionary. The keys of the dictionary can
vary depending on the parameters given to the pipeline, but it will
always have at least the key generated_text which gives you
the models output in the form of a python string:
[{'generated_text': 'Where is Groningen located?\nGroningen is a municipality in the province of Drenthe in the North Holland region of the Netherlands. As of the 2011 census, the municipality had a population of 122,683.\nWhat is the name of the river that connects Groningen to Utrecht?'}]We can obtain only the text if we extract it directly:
Note that the model “repeats” the question before completing it with the answer. This happens because in reality the LLM is a Transformer Decoder, which tokenizes your prompt, processes it token by token, and then keeps generating new tokens. Because the model was trained to act as an assistant in a conversation, the most likely tokens that follow a questions are an answer to that question. But it is possible that the model does not reply at all.
Multi-turn Conversation Generation
When dealing with these kind of assistant LLMs it is a better practice to look at the input as a conversation. A conversation can be defined as a list of messages that the pipeline knows how to internally tokenize and generate a better answer given the context provided:
PYTHON
messages = [
{"role": "system", "content": "You are a helpful assistant. Give short straight answers" },
{"role": "user", "content": "Where is Groningen located?" },
]
response = llm(messages, return_full_text=False)[0]["generated_text"]
print(response)This method makes it more likely to get an answer every time the model is executed. Remember this is not completely deterministic, so you can run it several times. (Spoiler: Expect several falsehoods to be stated in the generations). You should get something like:
Groningen is located in the northwest corner of the Netherlands.We set the return_full_text=False flag to False to get
the response as a string. This parameter is by default set to True and
in that case it will return the whole conversation so you can keep using
the history for posterior interactions if you want to:
PYTHON
messages = [
{"role": "system", "content": "You are a helpful assistant. Give short straight answers" },
{"role": "user", "content": "Where is Groningen located?" },
]
response = llm(messages)[0]["generated_text"]
print(response)This gives a multi-turn conversation as a list of string messages, such as:
PYTHON
[{
'role': 'system',
'content': 'You are a helpful assistant. Give short straight answers'
},
{
'role': 'user',
'content': 'Where is Groningen located?'
},
{
'role': 'assistant',
'content': 'Groningen is located in the northern part of the Netherlands.'
}]You may have noticed there are three main roles that
most LLMs recognize in an interaction:
- System: This role is normally only used once at the beginning of an interaction, it contains the general prompting strategies (instructions) that your model should follow. Think of it as the user manual (where you explain what the task is) that the LLM will read before performing the actual task. This is where prompt engineering happens.
- User: also referred sometimes as Human, includes all messages human generated in the dialogue are given the user role. In a multi-turn dialogue, each utterance you submit will be given the user role, to distinguish them from the automatically generated sequences. These are questions submitted ot the model, or input instances for which you expect an output.
- Assistant: All messages automatically generated based on the model text generation capabilities, these are the model outputs.
Different models might recognize also other roles, but these are the core ones. You can always pass directly a text prompt, even if you do only one-turn interactions with the LLMs (which many times is the recommended option to avoid biasing model responses based on previous ones), but it a good practice to follow these roles since the start, to make your code more scalable. These roles are internally translated into special tokens and processed together as a single sequence. See a tiktokenizer example for GPT-4o
Hyperparameters for Text Generation
Besides the existence of roles, the pipeline() method
has several hyper-parameters (function arguments) for that help us
control better how the text-generation task will be done.
These are some of the most common:
max_new_tokens: sets maximum number of tokens (roughly words/word pieces) that the model will generate in total. It’s a hard limit - generation stops when this limit is reached, even mid-sentence. Useful for controlling cost / time. The more tokens you need to generate for an answer the more time it takes. LLMs called through paid APIs often charge per a set number of tokens (e.g. $0.008 per 1000 tokens).
temperature: positive float value that controls the randomness/creativity of the model’s token selection during generation. The model predicts probabilities for each possible next token, temperature modifies these probabilities before making the final choice. 0.0: Completely deterministic - always picks the most likely token; 1.0+: More random, and “creative”, but potentially less coherent.
do_sample: when do_sample=True, the model generates text by sampling from the probability distribution of possible next tokens. If do_sample=False, the model uses greedy decoding (always picking the most likely next token), which makes the output more deterministic but often repetitive.
top_k: This is a sampling strategy called Top-K sampling. Instead of considering all possible next tokens, the model looks at the k most likely tokens (based on their probabilities) and samples only from that reduced set. If top_k=50, the model restricts its choices to the top 50 most probable words at each step.
Challenge
Take 10 minutes to play with the hyper-parameters and observe how they affect outputs, even though you are using exactly the same model every time. Try different prompts, messages and values and see if the outputs match your intuitions. You can manipulate the values explicitly in the pipeline such as:
PYTHON
messages = [
{"role": "system", "content": "You are a helpful assistant. Only tell me 'yes' or 'no' and a one-sentence explanation for your answer." },
{"role": "user", "content": "Is NLP the best research field?" },
]
response = llm(messages, max_new_tokens=100, do_sample=True, top_k=5, temperature=0.7)[0]["generated_text"]Some aspects to discuss:
-
What did you notice about the models’ responses?
- Were they always accurate? Always coherent?
- How did different prompts affect the quality?
-
Temperature Effects:
- What happened when temperature was low (e.g. 0.0 or 0.1) vs. high (e.g. 1.2)?
- Under which circumstances would you want more random / creative responses vs. consistent responses?
-
Max Length Effects:
- Did you notice a difference in speed of responses when adjusting the max_length parameter?
Prompting to Solve NLP Tasks
Now we will link some of the fundamentals we learned earlier with the usage of LLMs. As mentioned before, we can consider the LLM as a component that given an input provides an output, thus we can evaluate it as any other Machine Learning classifier. We will re-visit the task of Sentiment Analysis to see how we can shape the task to make the generative model provide the outputs we need.
But before doing that, we will take the opportunity to introduce Ollama, an open-source tool that allows you to run LLMs locally on your own computer, instead of having to call remote services such as OpenAI, Gemini, etc. Ollama lets you download and execute some of the most popular (semi-)open source models, including embedding models (Encoder-based) and generative models (Chat-Assistants), “thinking” models, etc… Take a look at the whole list. Consider that the size of the models you can download and effectively use will depend on how powerful your laptop is. You can use Ollama as a standalone application in Windows/Mac/Linux, but you can also call its local API using python so you can integrate the LLMs into your scripts.
We will use Ollama through the langchain interface to give you the opportunity to also get to know this popular python library. Using Langchain allows you to write a single piece of code and be flexible to use many closed and open source models and even get production-level code with minimal modifications, so it is nice to try it. This is a very complex library and we will only cover the basics to give you a head start. We are going to test the llama3.2:1b model which you can download in the Ollama interface, or also from your terminal by running:
Let’s see how does the langchain code looks to get
exactly the same kind of interaction as with the HuggingFace code.
PYTHON
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="llama3.2:1b",
temperature=0.7,
num_predict=100, # Same as max_new_tokens
top_k=5, # Only consider the first 5 most likely tokens
top_p=0.9 # Just consider next tokens form the top_p most likely options. Similar to do_sample
)
# Define messages in LangChain format
messages = [
("system", "You are a helpful assistant. Give short straight answers"),
("human", "Where is Groningen located?"),
]
# Get response
response = llm.invoke(messages)
# Show the Response object (includes useful metadata stats)
print(response)
# Show content only
print(response.content)Example: Sentiment Analysis
Let us now try the sentiment analysis task to see how well different models (with different number of parameters perform). Consider the following set of lines from product reviews:
Product reviews:
- I love this movie! It was absolutely fantastic and made my day. positive
- This product is terrible. I hate everything about it. negative
- Nothing says quality like a phone that dies after 20 minutes. negative
- The movie was dark and depressing — exactly what I was hoping for. positive
- The food was delicious, but the service was painfully slow. mixed
Set the prompt for this as (substitute the above sentences for text each time):
Classify the sentiment of the following text as either POSITIVE or NEGATIVE. Text: "{text}"
Examine the results afterwards to see which models correctly classified them and which didn’t.
PYTHON
sentiment_llm = ChatOllama(
model="llama3.2:1b",
temperature=0, # Want to be as deterministic as possible
num_predict=10, # Keep the answer very short
top_k=1, # Only consider the next most likely token (Greedy)
)
sentiment_texts = [
"I love this movie! It was absolutely fantastic and made my day.",
"This product is terrible. I hate everything about it.",
"Nothing says quality like a phone that dies after 20 minutes.",
"The movie was dark and depressing — exactly what I was hoping for.",
"The food was delicious, but the service was painfully slow."
]
general_prompt = "Classify the sentiment of the following text as either POSITIVE or NEGATIVE. Just return the label, nothing else!"
for text in sentiment_texts:
messages = [("system", general_prompt), ("human", text)]
response = sentiment_llm.invoke(messages)
print(f"Example: {text}")
print(f"Response: {response.content}")
print("------")Challenge
Apply the classifier to the data/sentiment_film_data.tsv
dataset. Evaluate it using the classification report from scikit-learn.
you can reuse the code from lesson 3. 1. How does the performance
compare to the BERT-based classifier? 2. Can you tweak the prompt to
improve the results?
Here the code to do the same excercise as lesson 3 but with the generative approach:
PYTHON
from sklearn.metrics import classification_report
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
def show_confusion_matrix(y_true, y_pred, labels=None):
ConfusionMatrixDisplay.from_predictions(y_true, y_pred, display_labels=labels, cmap='Blues')
plt.show()
def load_data(filename):
with open(filename, 'r') as f:
lines = f.readlines()[1:] # skip header
sentences, labels = zip(*(line.strip().split('\t') for line in lines))
return list(sentences), list(labels)
sentiment_llm = ChatOllama(
model="llama3.2:1b",
temperature=0, # Want to be as deterministic as possible
num_predict=10, # Keep the answer very short
top_k=1, # Only consider the next most likely token (Greedy)
)
sentences, y_true = load_data('data/sentiment_film_data.tsv')
y_pred = []
prompt = "Classify the sentiment of the following text as POSITIVE, NEGATIVE or NEUTRAL. Just return the label, nothing else!"
for sent in sentences:
messages = [("system", prompt), ("human", sent)]
response = sentiment_llm.invoke(messages)
print(sent, response.content)
y_pred.append(response.content.lower())
print(classification_report(y_true, y_pred))
show_confusion_matrix(y_true, y_pred)Report:
OUTPUT
precision recall f1-score support
negative 0.50 1.00 0.67 23
neutral 0.43 0.08 0.14 37
positive 0.70 0.82 0.76 40
accuracy 0.59 100
macro avg 0.54 0.64 0.52 100
weighted avg 0.55 0.59 0.51 100Key Takeaways
- LLMs are generative models - they predict the next most likely tokens
- Prompts matter - the way you ask affects what you get
- Hyper-parameters control behavior - temperature, max_length, etc. tune the output
- Models have limitations - they can be wrong, inconsistent, or biased
- Size vs Speed trade-off - smaller models are faster but less capable
Drawbacks and Biases with LLMs
This section will examine some important behavior or characteristics of LLMs that should be taken into account when using them. Most of these behaviors are a consequence of:
- The Transformer network architecture itself and the assumptions that are made when processing text, as early as the tokenization step.
- The huge amount of data that was fed to these models, since quantity was preferred over quality, they have inherited a lot of undesired information including misinformation, hate-speech, pornography, artificially generated (noisy) data etc…
- The post-training step, which was meant to impose guardrails and avoid undesired behavior, also imposes intentional or indirect bias in the manner in which data was labeled, pushing cultural pre-conceptions and human biases and labeling errors to be the “preferred answers”.
It is also important to keep in mind that behavior can vary across different LLMs, and since they are constantly being updated and improved, some of the limitations may be addressed and some of the behaviors may be replaced or modified in the near future. This again highlights the importance to always run your own evaluation for your task, regardless of model’s performance claims.
Let’s take a look at some unexpected behaviors. We load the Ollama model to run the experiments:
Hallucinations
Hallucination in LLMs refers to the generation of content that is factually incorrect, nonsensical, or not grounded in any specific factual source. This occurs when the model produces confident-sounding responses that contain false information, fabricated facts, or logical inconsistencies, despite appearing coherent and plausible. Confabulation is another term for hallucination in LLMs.
PYTHON
chatbot = ChatOllama(
model="llama3.2:1b",
temperature=0,
num_predict=500,
top_p=0.9
)
halluc_prompt = "Who is Railen Ackerby?"
response = chatbot.invoke(halluc_prompt)
print(response.content)Railen Ackerby is a made up name. Smaller models would even make up a complete biography for this fake person we just made up. Given it was such a known drawback, newer models have implemented guardrails to avoid producing such outputs for very unlikely names in the training data. The interesting hallucination actually happens even on top of such guardrail, because at least llama3.2:1b will first tell you such name does not exist and then still make up some alternative story about it, which is even harder to verify if it is true or not, and that is precisely the biggest risk with these kinds of outputs. Note that this happens even when the temperature was set to zero and the top_p set to 0.9, which supposedly make more truthful answers.
Non-determinism
By now we know that setting the temperature to 0.0 will get us the same answer if we run the experiment under the same circumstances. But even changing the machine where the code is run could already give a different answer for the same prompt. Moreover, setting the temperature to 0.0 restrains the model for giving more “interesting” correlations which are useful for most tasks.
Biases and fairness
LLMs can be biased towards certain stereotypes represented in the pretraining data. Let’s look again at an example of gender bias. E.g., stereotype of nurses usually being female.
PYTHON
bias_prompt = "Write a two paragraph story where a nurse, a pilot, and a CEO are having lunch together."
response = chatbot.invoke(bias_prompt)
print(response.content)If this example works, a short story should be generated by the LLM about a nurse and most likely it will be a female nurse, either marked by usage of words such as “she” and “her” to reveal gender or even giving her a name. We never gave any gender explicitly to the model. In our example we got the following story:
OUTPUT
As the sun shone down on the bustling airport, Nurse Emma sat across from Pilot Jack at a small café, sipping on a cup of coffee. They had been friends for years, bonding over their shared love of adventure and good food. Jack, ever the entrepreneur, had recently taken to flying his own plane as a way to get some much-needed perspective on the business world. Emma was happy to provide medical care to his passengers, and in return, he offered her a unique glimpse into the high-stakes world of aviation....Another common case is asking for apparently equivalent facts about different entities. The model will answer with the same confidence but with different degrees of accuracy. For example:
PYTHON
# Hint: John Adams (1797 - 1801)
biased_prompt = "Who was the second president of the United States?"
response = chatbot.invoke(biased_prompt)
print(response.content)OUTPUT
The second president of the United States was John Adams. He served from 1797 to 1801, succeeding George Washington.we get a factually correct and confident answer. Let’s try exactly the same question for a different country:
PYTHON
# Hint: Vicente Guerrero (April 1829 - December 1829)
biased_prompt = "Who was the second president of Mexico?"
response = chatbot.invoke(biased_prompt)
print(response.content)we got his answer:
OUTPUT
The second president of Mexico was Antonio López de Santa Anna. He served from 1833 to 1835 and again from 1838 to 1841.Initially we see the same confident syntax to answer the question, but it is factually incorrect. The results of course will vary per model and configuration of prompts. But beware that prompts that involve the anglosphere (Anglo American World) in particular will be more accurately responded, whereas the more you deviate from the “western standards” the less accuracy you will get. In the case of Mexico it is particularly disappointing as even the English Wikipedia page has that information in a prominent place.
Outdated Knowledge
Another common drawback is that models have a cut-off training date. Again, guardrails are supposed to be in place and they do seem to work for obvious cases:
PYTHON
outdated_prompt = "Who is the president of the United States?"
response = chatbot.invoke(outdated_prompt)
print(response.content)with the following output:
OUTPUT
As of my last update in 2023, the President of the United States is Joe Biden. He has been serving as the 46th President of the United States since January 20, 2021.The model warns us that its latest data is from 2023. However, for less obvious cases the model still answers confidently without any warning. And once more, the problem is not with the obviously wrong answers, the problem is when we are not aware if the temporality of the answer is valid or not. For example:
PYTHON
outdated_prompt = "When was the last time Argentina won the World Cup?"
response = chatbot.invoke(outdated_prompt)
print(response.content)We got this output, which is incorrect since Argentina won again in 2024. This time the model doesn’t warn us:
OUTPUT
Argentina has not won the FIFA World Cup since 1986, when they defeated West Germany 3-2 in a penalty shootout after the game ended 0-0.- We learned how are so called LLMs different from the first generation of Transformers
- There are different kinds of LLMs and understanding their differences and limitations are a key aspect for choosing the best model for your case
- We learned how to use HuggingFace pipeline with SmolLMv2, an open source model.
- We learned how to use Ollama to run conversational models in our laptop
- Classification tasks can be done using generative models if we define the prompt in a careful way
- Hidden biases will always be present when using LLMs, we should be aware of those before we draw conclusions from the outputs.