Generative AI in Medical Imaging
Last updated on 2026-05-14 | Edit this page
Overview
Questions
- What is generative AI?
- How can generative AI be safely used in my work?
Objectives
- Showcase practical examples of generative AI applications
- Explore critical considerations regarding the risks and challenges associated with generative AI
Introduction
Generative artificial intelligence (AI) includes technologies that create or generate data. Since the early 2020s, there has been significant attention on large language models (LLMs) like ChatGPT, Copilot, and LLaMA, alongside image generation tools such as Stable Diffusion, Midjourney, and DALL-E. These tools not only create images but can also manipulate styles.
The applications of generative AI span widely across fields like medical imaging, where they hold potential for image interpretation and numerous other tasks. Of particular interest to participants in this course are the capabilities of LLMs to generate code and produce large volumes of synthetic data. Ongoing research continues to explore these capabilities.
Since this lesson was originally created there has been a rise of generative models that are specifically used to create code. The possibilities and ethical concerns for this type of generative AI could comprise an entire workshop in and of itself. There is indeed a course in the carpentries incubator already: https://carpentries-incubator.github.io/software-development-with-genai/.
The safety implications of these technologies, whether used for image or code creation, remain a subject of debate. Depending on the software or model used, data entered into the system may become the property of the software’s creators. It is crucial to exercise caution when inputting sensitive information, such as patient data, into these systems. Understanding where and how data is stored (i.e., whether on your servers or in the cloud) is essential to safeguard privacy and confidentiality.
Mastering the Use of Generative AI Tools
Architectures of Generative AI
Generative AI encompasses models capable of generating new data across various formats: text, images, video, or audio. Several prominent architectures, such as generative adversarial networks (GANs), variational autoencoders, diffusion models, and transformers, achieve this capability. While the technical intricacies of these architectures exceed this course’s scope, understanding their operational principles can illuminate the nature of their outputs. For instance, models treating data as sequential sequences (e.g., pixels or words) predict the next element based on probabilities derived from the training dataset, potentially perpetuating common patterns rather than reflecting absolute truths.
However, using generative algorithms carries inherent risks, including inadvertently embedding biases into both data and algorithms. While humans cannot infer patient ethnicity from body imaging, recent studies demonstrate that certain AI algorithms can leverage correlations in data, introducing potential ethical implications. This represents just one facet of the risks associated with these technologies, which we will further explore in the following safety section.
Safely Leveraging Generative AI
- Never upload non-anonymized sensitive patient data outside your secure servers
- Avoid using sensitive patient data with online tools (e.g., chatGPT, integrated tools like co-pilot, MS Office)
- Be mindful of internet connectivity with your code editors and tools
- Prefer systems that operate locally (on your machine or hospital servers)
- Acknowledge that tools may generate erroneous information (hallucinations)
- Don’t assume code generated by a LLM lacks potential bugs or harmful code
- Address intellectual property and ethical considerations when utilizing generative AI models
- Document model usage thoroughly in academic work, detailing versions and exact applications
- Recognize that the training corpus of such models may introduce biases
Stable Diffusion is an open-source tool widely used for image generation, capable of running locally on your machine. While older versions typically require GPUs, recent builds can run on CPUs, although at a slower pace. For efficient large-scale image generation, utilizing a GPU is recommended to save time.
One historical limitation of older versions of Stable Diffusion, and similar tools, is that the models could be customized with your own datasets, restricting the ability to train or modify it according to specific needs. However there are now methods to fine-tune with custom datasets
Challenge: Assessing the Risks of Local Model Deployment
Can you identify a few risks associated with running a model entirely on your machine?
One significant risk of running any model locally is the potential for malicious code. Since you need to download the model to your machine, there is no guarantee that it will not contain malware. To mitigate this risk, we recommend using open-source models, which allow for community scrutiny and transparency.
Another concern is the environmental impact of model usage. Training and maintaining these models consume considerable resources, including carbon and water. We advise against running models like ChatGPT continuously due to their substantial environmental footprint. Even when operating a model locally, there are inherent risks, such as relying on a smaller training dataset to fit on your machine, which could compromise the model’s quality and performance.
Maximizing the Effectiveness of Generative AI
The output of generative tools is highly dependent on the specific words or images inputted, a process known as prompt engineering.
To create content that balances a dataset for machine learning, start by analyzing the dataset’s balance according to important labels. Then, describe images with these labels and build prompts based on the descriptions of label categories with fewer images. This approach helps focus the model’s use on generating useful outcomes while minimizing risks.
Keep in mind that content generation can be a somewhat stochastic process. Therefore, you may need to experiment with and refine your prompts and even the sequences of prompts to achieve the desired results.
Effective Prompting Tips
- Ensure accuracy in spelling and grammar to avoid misdirection
- Provide clear and detailed prompts
- Explain the context or goal (e.g., “helping my son… can you explain it in a specific way?”)
- Try different wordings to refine results
- Fact-check thoroughly
- First, ask the tool to fact-check its output
- Then, verify using search engines and experts
- Never fully trust references or facts generated by an LLM, seek human-generated content for confirmation
- Clearly indicate if you need a particular format (e.g., bullet points, square images)
- Use prompts like “you are a Python expert” or “you are an expert pathologist” to guide the tool
- For more accurate outputs, fine-tune foundation models with your specific data
- If using genAI to create code specify the language version, and read the code for bugs before commiting it
These tips will help you optimize the quality and relevance of the content generated by AI tools.
Attention to detail in creating prompts is critical. For example, the following image was generated from the misspelling of “X-ray” with a popular AI tool:

While this result is laughable, more subtle mistakes can be harder to identify, especially for those without extensive training in a specific field. Therefore, having a specialist review the generated data is crucial to ensure its validity.
It is also important to remember that the training data for some algorithms is often sourced from the internet, which includes a lot of irrelevant or misleading content. For instance, while there are many cute cat pictures available, there are very few good examples of rare medical conditions like desmoplastic infantile ganglioma. Additionally, using terms like “CAT scan” (historically referring to computer axial tomography) might result in images of cats rather than the intended medical imagery:
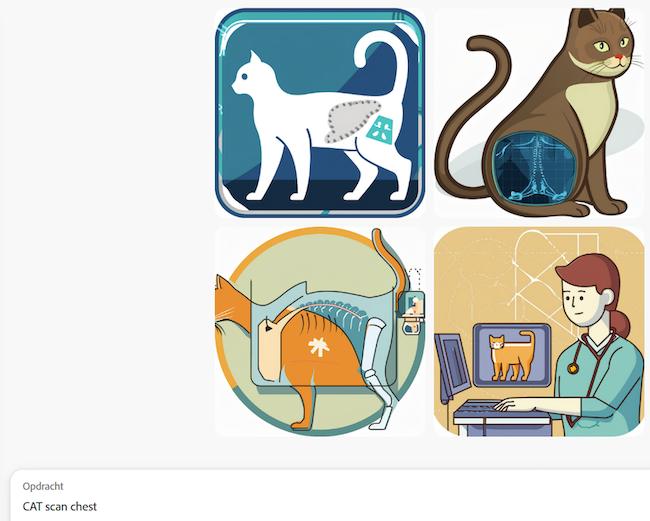
- Generative programs can create synthetic data, potentially enhancing various algorithms
- Generative AI models have inherent limitations
- Running generative AI programs locally on your own server is safer than using programs that send prompts to external servers
- Exercise caution when entering patient data into generative AI programs
- Numerous policies exist to ensure the safe and ethical use of generative AI tools across institutions