Managing project start and collaborations
Last updated on 2023-09-06 | Edit this page
Overview
Questions
How to set up a computational project?
What main concerns and challenges exist and how to address them?
How to create a project repository for sharing, collaboration and an intention to release?
What extra tools may be used ?
How to manage and oversee tasks and track progress of your projects?
How collaborative practices help ensure code quality, testing and reuse?
What is literate programming and how does it help with early communication, testing and collaboration?
Objectives
Describe best practices for setting a project repository
Build a basis for collaboration and co-creation in team projects
Plan computational reproducibility and project management practices
Make it easy for each contributor to participate, contribute and be recognised for their work
Demonstrate GitHub Project Board to enable project management.
Setting up a Project
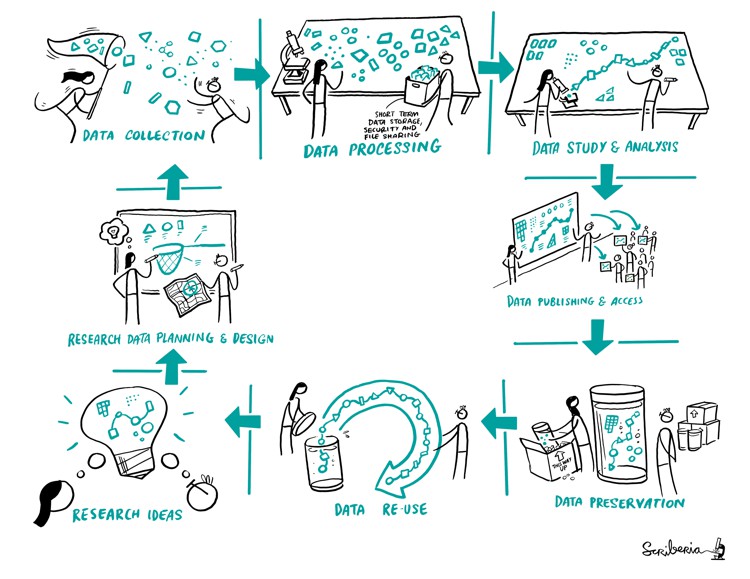
Research Lifecycle. The Turing Way project illustration by Scriberia for The Turing Way Community Shared under CC-BY 4.0 License. Zenodo. http://doi.org/10.5281/zenodo.3332807
A research project starts right with a research idea. We start by communicating that with other researchs in our team. Then come the following steps:
- planning and designing the research work
- describing the research protocols
- deciding how data will be collected
- selecting methods and practices for processing and wrangling data
- conducting our studies and analysis
- publishing all the research objects so everybody can access it
- archiving it to ensure that our research is reusable, meaning, that someone else can go through this whole process of reproducing or building upon our work.
Each of these steps is important for every single researcher, irrespective of their roles in the project. They are usually not taken one after the other, but concomitantly, it is therefore important to plan and take decisions for each of them before the project starts. However, a project lead (such as Principal Investigators, managers and supervisors) have an added responsibility to set up the project in a way that ensures that all members of their research team can work together efficiently at all stages of the project.
With an overarching goal to maintain research integrity and ethical practices from the start, we need to consider reproducibility methods, collaborative approaches and transparent communication processes for the research team as well as the external stakeholders. As project leads, managers and team organisers, it is crucial to be deliberate and clear about the tools and platforms selected for the project, as well as expectations from each contributor from the beginning. Dedicating some time in thinking through and documenting the setup of a project saves time, ensuring successful implementation of research plans at different stages of research. At this stage, you can’t be sure that everything will always go as planned or there will be no unexpected challenges, but it helps prepare in advance for risk management and adapt to changes when needed.
Main Concerns and Challenges
Scientific results and evidence are strengthened if those results can be replicated and confirmed by several independent researchers. This means understanding and documenting the research process, describing what steps are involved, what decisions are made from design to analysis to implementation stages and publishing them for others to validate. Research projects already start with multiple documents such as project proposal, institutional policies and recommendations (including project timeline, data management plan, open access policy, grant requirements and ethical committee recommendations), which should be available to the entire research team at all times. Furthermore, throughout the lifecycle of a project we handle experimental materials such as data and code, refer to different published studies, establish collaboration with others, generate research outputs including figures, graphs and publications, many of which undergo multiple versions. Then there is a general need to document the team’s way of working, different roles and contribution types, project workflows, research process, learning resources and templates (such as for presentation, documentation, project reporting and manuscript) for your research team.
If not planned in advance, these different kinds of information related to the project can become challenging to record, manage or retrieve – costing precious time of everyone involved and negatively affecting collaborative work in your research team.
A good start
In addition to ensuring effective development and collaboration during the lifetime of the project, a well-organised project also ensures sustainability and reusability of research for both the developers and future users more dynamically. But it all comes to implement the tools planned in the setting up phase. One may need to iteratively modify the plan and include different tools if the team changes or grow. This aspect is discussed in detail in the Research Data Management episode.
Challenge
- Create a project on GitHub
- Create a Github account at https://github.com
- Go to https://github.com/tonic-team/Tonic-Research-Project-Template/
- Click
Use this templateand follow instructions.
NB: You can use that template on other git platforms.
Change the
reamde.mdfile directly on the browser: enter information about the project, commit with a message. Enter information about the team (roles and responsabilities), commit with a second message.Look at the history of the readme.md file, understand the need for good commit messages.
Keypoints
- Shared repository with well structured and organised files are crucial for starting a project
- Documentation is as important as data and code to understand the different aspects of the project and communicate about the research.
- Licencing and open science practices allow proper use and reuse of all research objects, hence should be applied in computational research from the start.
Project Management Tools
In the previous chapters, we have already discussed practices that enable the effective management of projects in:
- setting up shared resources;
- defining the vision, mission and roadmap of your project;
- managing data and other research-related resources; and
- versioning and tracking progress.
It is important to communicate tasks and responsibilities to different stakeholders of the project. However, what is even more important is to allow all members to understand where in the entire project their tasks fit and how they can track the progress of the entire project.
Gantt charts
Gantt charts are timeline views of the project plan. It defines which task should be done (and finished) at which time (and by whom). Some advanced tools allows to visualise dependencies between tasks. It is an important tool to stay on track or redefine priorities when milestones are not met in time.
Kanban
Kanban provide a visual overview of the tasks, their status (to do, in progress, done) and the people responsible for them in a columnar form. While physical boards and post-it (of different colors and forms) are often used, these tasks can be visualised on a digital board where different columns can present different statuses, different task groups or priorities.
It is also a tool to focus the work on a few tasks. Indeed the “in progress” tab should only contain 1-3 elements per team member, so that one finish one task before starting a new one. Kanban can also be used to communicate what is in progress to other team members and coordinate the work.
Some tools that are popular among research community is Asana, Trello, Todoist and Notion.
The majorities of Git repositories have advanced features like embedded kanban systems, allowing some automation of cards movement and links between task management and data storage.
Git repositories for Project Management
Similar features on GitHub, GitLab, Codeberg or GIN can be used for project management. The following section takes GitHub as an example, but most of this can be applied in other platforms.
Issue is a GitHub integrated feature that allows everyone to track the progress on GitHub. Similar to a ‘To-Do List’, issues can be anything from a project milestone (releasing an R package, submitting to an online data repository, a working simulation) but also specific issues with code (fixing a bug, adding a function, updating tests).
Based on the tasks described in an issue, your collaborators can address them and save or ‘commit’ changes in their local copy of the repository. Local changes then can be ‘pushed’ to the repository on GitHub for ‘review’ via the Pull Request feature. Once a pull request is opened, different collaborators can discuss and review the potential changes and add follow-up commits before those changes are ‘merged’ into the main repository.
Project boards are kanban-like features on GitHub that help you visualise (list of tasks), categorise (in columns) and prioritise (drag/move around) different tasks. A collection of project boards can be created for a different set of tasks, comprehensive roadmaps, or even release checklists. By linking issues and Pull Requests, project boards can create workflows. The Project board shows metadata for issues and pull requests, like labels, assignees, the status, and who opened it. Additional notes within columns can be added as task reminders, references to issues and pull requests from any repository on GitHub.com, or to add information related to the project board. This Kanban board feature can be very helpful in getting a snapshot of multiple research projects within a team/lab and tracking what multiple people are currently working on. You can read more about Project Board in GitHub Documentation.
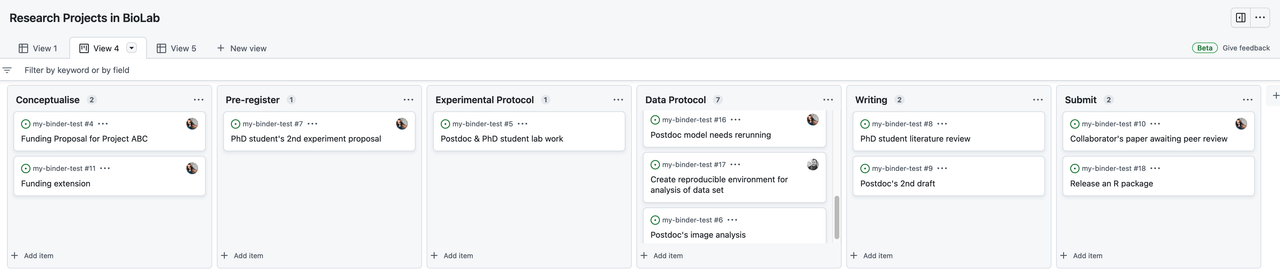
An example is Kanban for researcher project management. GitHub boards can be given any name.
Within Github, the Projects Tab can provide a board with cards to organise issues collaboratively. If a team is already working within Github, this can be beneficial as everything remains in the same place. “Issues” can be used as a record of ToDos or others flagging up bugs and features that need to be addressed. They can be attached to particular repos and assigned to people.
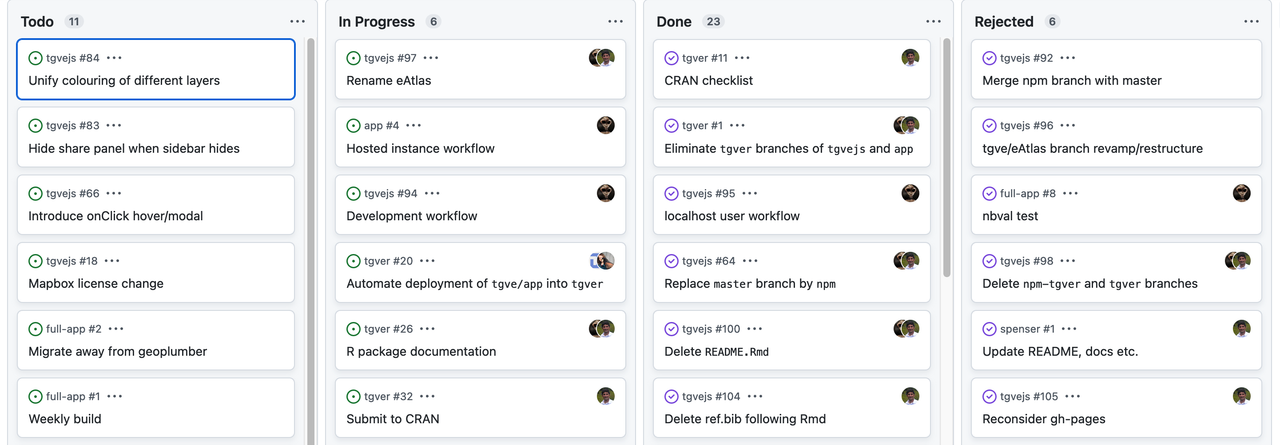 A traditional Kanban for a collaborative computational project.
Keeping track of bugs and what everyone is working on.
A traditional Kanban for a collaborative computational project.
Keeping track of bugs and what everyone is working on.
The Kanban board can be modified to whatever layout or structure makes sense to you. This example uses the concept to publication/release pipeline.
Github also allows different summary views for collaborative issues across multiple repos, which can be helpful for organising larger teams.
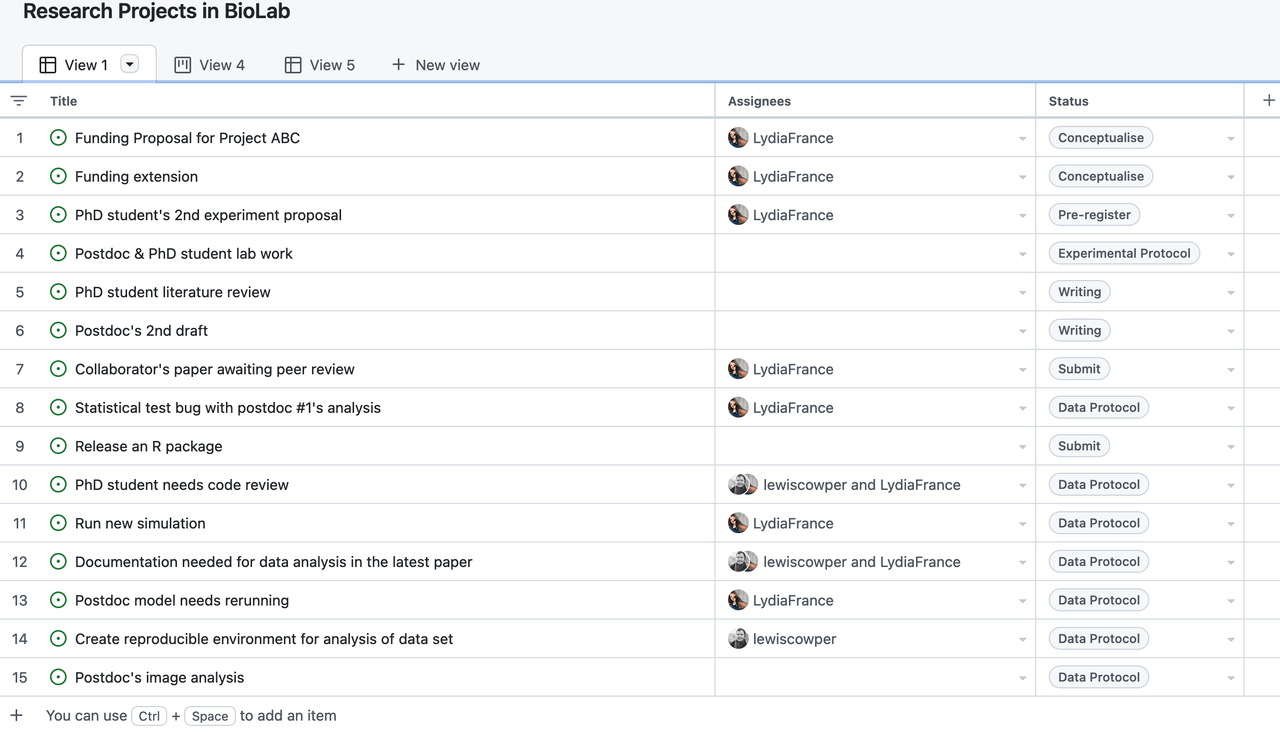
Author: Lydia France (Junior Data Scientist, The Alan Turing Institute, UK)
Similar walkthrough can be done with https://next.forgejo.org (Codeberg-like test platform). Lecturer prepare a repository with a readme, a project and one issue. Fake user should be added to the platform before the course, so that people do not have to register, and users are added as collaborators on the repository.
- create an issue “adding myself to the participant list”
- assign it to the project
- move it in the board view
- assign someone, add a label, add a milestone.
- modify readme file, commit change with a new branch.
Collaborating on Computational Projects
Much research is now collaborative and a shared code repository can be effectively used to enable collaboration at all stages of code development at the analysis and implementation stage.
Later in this material, we will go through best practices in code writing, testing, reviews and modularity, which help achieving computational reproducibility. Before that, we will look at ways to foster documentation of the work, and how research data management is necessary for efficient collaboration and reproducible research.
Document collaborations
It is important to document who does what in a project, such that credit can be fairly attributed. This starts at day one, when roles and responsibilities are set, but needs to be often updated as the roles may change during the project. In large team, this may be an essential part of growing a community, especially if one does recognize roles usually overseen in the research environment.
The tenzing spreadsheet (https://tenzing.club) will allow to present the contribution in publications and may be a good tool to start the collection of contribution. A lot of open source project, like The turing way, are using a bot (https://allcontributors.org, works only on GitHub) to collect and show several contribution types.
Challenge
- Go to your research repository created in the setup chapter
- Open one issue, assign one person and a milestone. For instance
write a data management planmilestone in 6 months. - add to do to the issue (optional)
- Use the project board to move the issue inside the board, move it to a different column.
Keypoints
- Make group leaders familiar with practices that are crucial for their teams to develop reproducible code.
- Encourage researchers to think about code reproducibility through quality check, testing, sharing their code as well as a research environment.
- Introduce Continuous Integration for automating the testing process.
Discussion
What measures described in this session are meant to make research more reproducible, what measures are meant to facilitate team work. How does the different measures interact ?
Making interaction measure is also making the research more reproducible. Indeed most of the reusability of the data and code can be best tested when several people interact on a project. Documenting for a current collaborator helps a lot to make sure documentation will be enough for new collaboratory coming in the project later on.