A Better Look at the GPU
Last updated on 2026-06-02 | Edit this page
Overview
Questions
- “How does a GPU work?”
Objectives
- “Understand how the GPU is organized.”
- “Understand the building blocks of the general GPU programming model.”
So far we have learned how to replace calls to NumPy and SciPy functions to equivalent ones running on the GPU using CuPy, and how to run some of our own Python functions on the GPU using Numba. This was possible even without much knowledge of how a GPU works. In fact, the only thing we mentioned in previous episodes about the GPU is that it is a device specialized in running parallel workloads, and that it is its own system, connected to our main memory and CPU by some kind of bus.
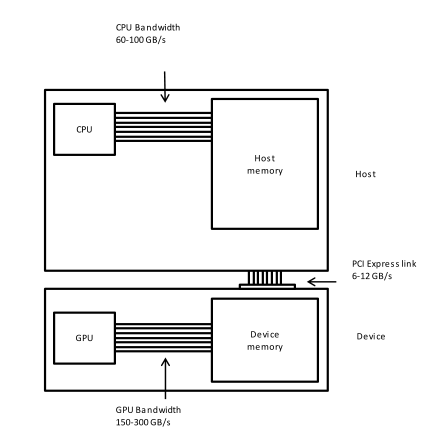
However, before moving to a programming language designed especially for GPUs, we need to introduce some concepts that will be useful to understand the next episodes.
The GPU, a High Level View at the Hardware
We can see the GPU like a collection of processors, sharing some common memory, akin to a traditional multi-processor system. Each processor executes code independently of the others, and internally it has tens to hundreds of cores, and some private memory space; in some GPUs the different processors can even execute different programs. The cores are often grouped in groups, and each group executes the same code, instruction by instruction, in the same order and at the same time. All cores have access to the processor’s private memory space.
How Programs are Executed
Let us assume we are sending our code to the GPU for execution; how is the code being executed by the different processors? First of all, we need to know that each processor will execute the same code. As an example, we can look back at some code that we executed on the GPU using Numba, like the following snippet.
PYTHON
import numba as nb
@nb.vectorize(['int32(int32)'], target='cuda')
def check_prime_gpu(num):
for i in range(2, (num // 2) + 1):
if (num % i) == 0:
return 0
return numWe did not need to write a different check_prime_gpu
function for each processor, or core, on the GPU; actually, we have no
idea how many processors and cores are available on the GPU we just used
to execute this code!
So we can imagine that each processors receives its copy of the
check_prime_gpu function, and executes it independently of
the other processors. We also know that by executing the following
Python snippet, we are telling the GPU to execute our function on all
numbers between 0 and 100000.
So each processor will get a copy of the code, and one subset of the numbers between 0 and 10000. If we assume that our GPU has 4 processors, each of them will get around 2500 numbers to process; the processing of these numbers will be split among the various cores that the processor has. Again, let us assume that each processor has 8 cores, divided in 2 groups of 4 cores. Therefore, the 2500 numbers to process will be divided inside the processors in sets of 4 elements, and these sets will be scheduled for execution on the 2 groups of cores that each processor has available. While the processors cannot communicate with each other, the cores of the same processor can; however, there is no communication in our example code.
While so far in the lesson we had no control over the way in which the computation is mapped to the GPU for execution, this is something that we will address soon.
Different Memories
Another detail that we need to understand is that GPUs have different memories. We have a main memory that is available to all processors on the GPU; this memory, as we already know, is often physically separate from the CPU memory, but copies to and from are possible. Using this memory we can send data to the GPU, and copy results back to the CPU. This memory is not coherent, meaning that there is no guarantee that code running on one GPU processor will see the results of code running on a different GPU processor.
Internally, each processor has its own memory. This memory is faster than the GPU main memory, but smaller in size, and it is also coherent, although we need to wait for all cores to finish their memory operations before the results produced by some cores are available to all other cores in the same processor. Therefore, this memory can be used for communication among cores.
Finally, each core has also a very small, but very fast, memory, that is used mainly to store the operands of the instructions executed by each core. This memory is private, and cannot generally be used for communication.
