Advanced layer types
Last updated on 2025-01-21 | Edit this page
Overview
Questions
- Why do we need different types of layers?
- What are good network designs for image data?
- What is a convolutional layer?
- How can we use different types of layers to prevent overfitting?
- What is hyperparameter tuning?
Objectives
- Understand why convolutional and pooling layers are useful for image data
- Implement a convolutional neural network on an image dataset
- Use a dropout layer to prevent overfitting
- Be able to tune the hyperparameters of a Keras model
Different types of layers
Networks are like onions: a typical neural network consists of many layers. In fact, the word deep in deep learning refers to the many layers that make the network deep.
So far, we have seen one type of layer, namely the fully connected, or dense layer. This layer is called fully connected, because all input neurons are taken into account by each output neuron. The number of parameters that need to be learned by the network, is thus in the order of magnitude of the number of input neurons times the number of hidden neurons.
However, there are many different types of layers that perform different calculations and take different inputs. In this episode we will take a look at convolutional layers and dropout layers, which are useful in the context of image data, but also in many other types of (structured) data.
1. Formulate / Outline the problem: Image classification
The MLCommons Dollar Street Dataset is a collection of images of everyday household items from homes around the world that visually captures socioeconomic diversity of traditionally underrepresented populations. We use a subset of the original dataset that can be used for multiclass classification with 10 categories. Let’s load the data:
PYTHON
import pathlib
import numpy as np
DATA_FOLDER = pathlib.Path('data/dataset_dollarstreet/') # change to location where you stored the data
train_images = np.load(DATA_FOLDER / 'train_images.npy')
val_images = np.load(DATA_FOLDER / 'test_images.npy')
train_labels = np.load(DATA_FOLDER / 'train_labels.npy')
val_labels = np.load(DATA_FOLDER / 'test_labels.npy')A note about data provenance
In an earlier version, this part of the lesson used a different example dataset. During peer review, the decision was made to replace that dataset due to the way it had been compiled using images “scraped” from the internet without permission from or credit to the original creators of those images. Unfortunately, uncredited use of images is a common problem among datasets used to benchmark models for image classification.
The Dollar Street dataset was chosen for use in the lesson as it contains only images created by the Gapminder project for the purposes of using them in the dataset. The original Dollar Street dataset is very large – more than 100 GB – with the potential to grow even bigger, so we created a subset for use in this lesson.
Dollar Street 10 dataset
The Dollar Street 10 dataset consists of images of 10 different classes, this is the mapping of the categories:
| Category | label |
|---|---|
| day bed | 0 |
| dishrag | 1 |
| plate | 2 |
| running shoe | 3 |
| soap dispenser | 4 |
| street sign | 5 |
| table lamp | 6 |
| tile roof | 7 |
| toilet seat | 8 |
| washing machine | 9 |

2. Identify inputs and outputs
Explore the data
Let’s do a quick exploration of the dimensions of the data:
OUTPUT
(878, 64, 64, 3)The first value, 878, is the number of training images
in the dataset. The remainder of the shape, namely
(64, 64, 3), denotes the dimension of one image. The last
value 3 is typical for color images, and stands for the three color
channels Red, Green,
Blue.
Number of features in Dollar Street 10
How many features does one image in the Dollar Street 10 dataset have?
- A. 64
- B. 4096
- C. 12288
- D. 878
The correct solution is C: 12288
There are 4096 pixels in one image (64 * 64), each pixel has 3 channels (RGB). So 4096 * 3 = 12288.
We can find out the range of values of our input data as follows:
OUTPUT
(0, 255)So the values of the three channels range between 0 and
255. Lastly, we inspect the dimension of the labels:
OUTPUT
(878,)So we have, for each image, a single value denoting the label. To find out what the possible values of these labels are:
OUTPUT
(0, 9)The values of the labels range between 0 and
9, denoting 10 different classes.
3. Prepare data
The training set consists of 878 images of 64x64 pixels
and 3 channels (RGB values). The RGB values are between 0
and 255. For input of neural networks, it is better to have
small input values. So we normalize our data between 0 and
1:
4. Choose a pretrained model or start building architecture from scratch
Convolutional layers
In the previous episodes, we used ‘fully connected layers’ , that
connected all input values of a layer to all outputs of a layer. This
results in many connections, and thus many weights to be learned, in the
network. Note that our input dimension is now quite high (even with
small pictures of 64x64 pixels): we have 12288
features.
Number of parameters
Suppose we create a single Dense (fully connected) layer with 100 hidden units that connect to the input pixels, how many parameters does this layer have?
- A. 1228800
- B. 1228900
- C. 100
- D. 12288
The correct answer is B: Each entry of the input dimensions, i.e. the
shape of one single data point, is connected with 100
neurons of our hidden layer, and each of these neurons has a bias term
associated to it. So we have 1228900 parameters to
learn.
PYTHON
width, height = (64, 64)
n_hidden_neurons = 100
n_bias = 100
n_input_items = width * height * 3
n_parameters = (n_input_items * n_hidden_neurons) + n_bias
n_parametersOUTPUT
1228900We can also check this by building the layer in Keras:
PYTHON
inputs = keras.Input(shape=(n_input_items,))
outputs = keras.layers.Dense(100)(inputs)
model = keras.models.Model(inputs=inputs, outputs=outputs)
model.summary()OUTPUT
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 12288)] 0
dense (Dense) (None, 100) 1228900
=================================================================
Total params: 1228900 (4.69 MB)
Trainable params: 1228900 (4.69 MB)
Non-trainable params: 0 (0.00 Byte)We can decrease the number of units in our hidden layer, but this also decreases the number of patterns our network can remember. Moreover, if we increase the image size, the number of weights will ‘explode’, even though the task of recognizing large images is not necessarily more difficult than the task of recognizing small images.
The solution is that we make the network learn in a ‘smart’ way. The features that we learn should be similar both for small and large images, and similar features (e.g. edges, corners) can appear anywhere in the image (in mathematical terms: translation invariant). We do this by making use of a concept from image processing that predates deep learning.
A convolution matrix, or kernel, is a matrix transformation that we ‘slide’ over the image to calculate features at each position of the image. For each pixel, we calculate the matrix product between the kernel and the pixel with its surroundings. A kernel is typically small, between 3x3 and 7x7 pixels. We can for example think of the 3x3 kernel:
OUTPUT
[[-1, -1, -1],
[0, 0, 0]
[1, 1, 1]]This kernel will give a high value to a pixel if it is on a horizontal border between dark and light areas. Note that for RGB images, the kernel should also have a depth of 3.
In the following image, we see the effect of such a kernel on the values of a single-channel image. The red cell in the output matrix is the result of multiplying and summing the values of the red square in the input, and the kernel. Applying this kernel to a real image shows that it indeed detects horizontal edges.

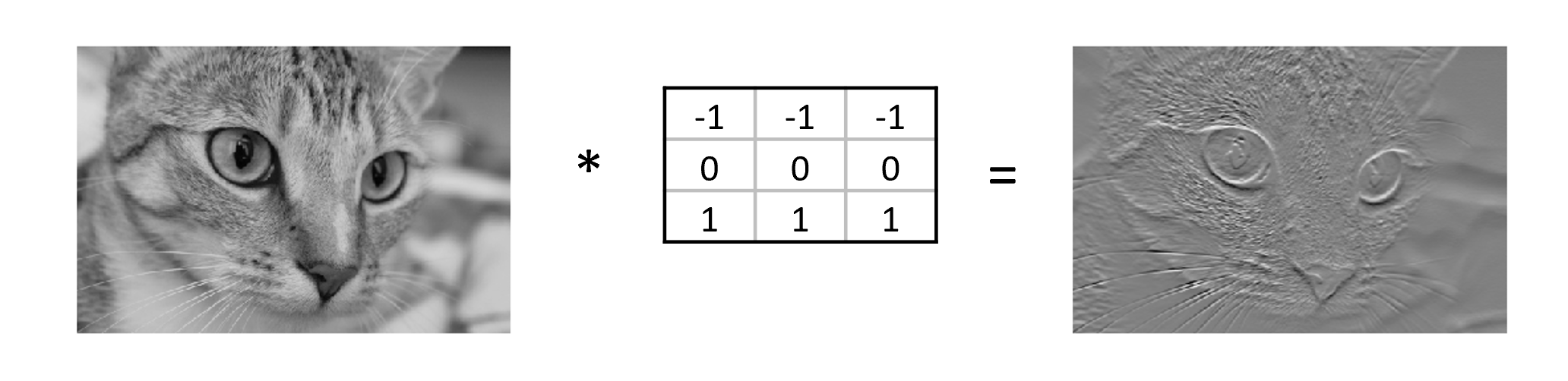
In our convolutional layer our hidden units are a number of convolutional matrices (or kernels), where the values of the matrices are the weights that we learn in the training process. The output of a convolutional layer is an ‘image’ for each of the kernels, that gives the output of the kernel applied to each pixel.
Playing with convolutions
Convolutions applied to images can be hard to grasp at first. Fortunately there are resources out there that enable users to interactively play around with images and convolutions:
- Image kernels explained shows how different convolutions can achieve certain effects on an image, like sharpening and blurring.
- The convolutional neural network cheat sheet shows animated examples of the different components of convolutional neural nets
Border pixels
What, do you think, happens to the border pixels when applying a convolution?
There are different ways of dealing with border pixels. You can ignore them, which means that your output image is slightly smaller then your input. It is also possible to ‘pad’ the borders, e.g. with the same value or with zeros, so that the convolution can also be applied to the border pixels. In that case, the output image will have the same size as the input image.
This callout in the Data Carpentry: Image Processing with Python curriculum provides more detail about convolution at the boundaries of an image, in the context of applying a Gaussian blur.
Number of model parameters
Suppose we apply a convolutional layer with 100 kernels of size 3 * 3 * 3 (the last dimension applies to the rgb channels) to our images of 32 * 32 * 3 pixels. How many parameters do we have? Assume, for simplicity, that the kernels do not use bias terms. Compare this to the answer of the earlier exercise, “Number of Parameters”.
We have 100 matrices with 3 * 3 * 3 = 27 values each so that gives 27 * 100 = 2700 weights. This is a magnitude of 2000 less than the fully connected layer with 100 units! Nevertheless, as we will see, convolutional networks work very well for image data. This illustrates the expressiveness of convolutional layers.
So let us look at a network with a few convolutional layers. We need to finish with a Dense layer to connect the output cells of the convolutional layer to the outputs for our classes.
PYTHON
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.Flatten()(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="dollar_street_model_small")
model.summary()OUTPUT
Model: "dollar_street_model_small"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_8 (InputLayer) [(None, 64, 64, 3)] 0
conv2d_10 (Conv2D) (None, 62, 62, 50) 1400
conv2d_11 (Conv2D) (None, 60, 60, 50) 22550
flatten_6 (Flatten) (None, 180000) 0
dense_14 (Dense) (None, 10) 1800010
=================================================================
Total params: 1823960 (6.96 MB)
Trainable params: 1823960 (6.96 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Convolutional Neural Network
Inspect the network above:
- What do you think is the function of the
Flattenlayer? - Which layer has the most parameters? Do you find this intuitive?
- (optional) This dataset is similar to the often used CIFAR-10 dataset. We can get inspiration for neural network architectures that could work on our dataset here: https://paperswithcode.com/sota/image-classification-on-cifar-10 . Pick a model and try to understand how it works.
- The Flatten layer converts the 60x60x50 output of the convolutional layer into a single one-dimensional vector, that can be used as input for a dense layer.
- The last dense layer has the most parameters. This layer connects every single output ‘pixel’ from the convolutional layer to the 10 output classes. That results in a large number of connections, so a large number of parameters. This undermines a bit the expressiveness of the convolutional layers, that have much fewer parameters.
Search for existing architectures or pretrained models
So far in this course we have built neural networks from scratch, because we want you to fully understand the basics of Keras. In the real world however, you would first search for existing solutions to your problem.
You could for example search for ‘large CNN image classification Keras implementation’, and see if you can find any Keras implementations of more advanced architectures that you could reuse. A lot of the best-performing architectures for image classification are convolutional neural networks or at least have some elements in common. Therefore, we will introduce convolutional neural networks here, and the best way to teach you is by developing a neural network from scratch!
Pooling layers
Often in convolutional neural networks, the convolutional layers are intertwined with Pooling layers. As opposed to the convolutional layer, the pooling layer actually alters the dimensions of the image and reduces it by a scaling factor. It is basically decreasing the resolution of your picture. The rationale behind this is that higher layers of the network should focus on higher-level features of the image. By introducing a pooling layer, the subsequent convolutional layer has a broader ‘view’ on the original image.
Let’s put it into practice. We compose a Convolutional network with two convolutional layers and two pooling layers.
PYTHON
def create_nn():
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.MaxPooling2D((2, 2))(x) # a new maxpooling layer
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x) # a new maxpooling layer (same as maxpool)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x) # a new Dense layer
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="dollar_street_model")
return model
model = create_nn()
model.summary()OUTPUT
Model: "dollar_street_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 64, 64, 3)] 0
conv2d_2 (Conv2D) (None, 62, 62, 50) 1400
max_pooling2d (MaxPooling2 (None, 31, 31, 50) 0
D)
conv2d_3 (Conv2D) (None, 29, 29, 50) 22550
max_pooling2d_1 (MaxPoolin (None, 14, 14, 50) 0
g2D)
flatten_1 (Flatten) (None, 9800) 0
dense_2 (Dense) (None, 50) 490050
dense_3 (Dense) (None, 10) 510
=================================================================
Total params: 514510 (1.96 MB)
Trainable params: 514510 (1.96 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________5. Choose a loss function and optimizer
We compile the model using the adam optimizer (other optimizers could also be used here!). Similar to the penguin classification task, we will use the crossentropy function to calculate the model’s loss. This loss function is appropriate to use when the data has two or more label classes.
Remember that our target class is represented by a single integer,
whereas the output of our network has 10 nodes, one for each class. So,
we should have actually one-hot encoded the targets and used a softmax
activation for the neurons in our output layer! Luckily, there is a
quick fix to calculate crossentropy loss for data that has its classes
represented by integers, the
SparseCategoricalCrossentropy() function. Adding the
argument from_logits=True accounts for the fact that the
output has a linear activation instead of softmax. This is what is often
done in practice, because it spares you from having to worry about
one-hot encoding.
6. Train the model
We then train the model for 10 epochs:
7. Perform a Prediction/Classification
Here we skip performing a prediction, and continue to measuring the performance. In practice, you will only do this step once in a while when you actually need to have the individual predictions, often you know enough based on the evaluation metric scores. Of course, behind the scenes whenever you measure performance you have to make predictions and compare them to the ground truth.
8. Measure performance
We can plot the training process using the history:
PYTHON
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
def plot_history(history, metrics):
"""
Plot the training history
Args:
history (keras History object that is returned by model.fit())
metrics(str, list): Metric or a list of metrics to plot
"""
history_df = pd.DataFrame.from_dict(history.history)
sns.lineplot(data=history_df[metrics])
plt.xlabel("epochs")
plt.ylabel("metric")
plot_history(history, ['accuracy', 'val_accuracy'])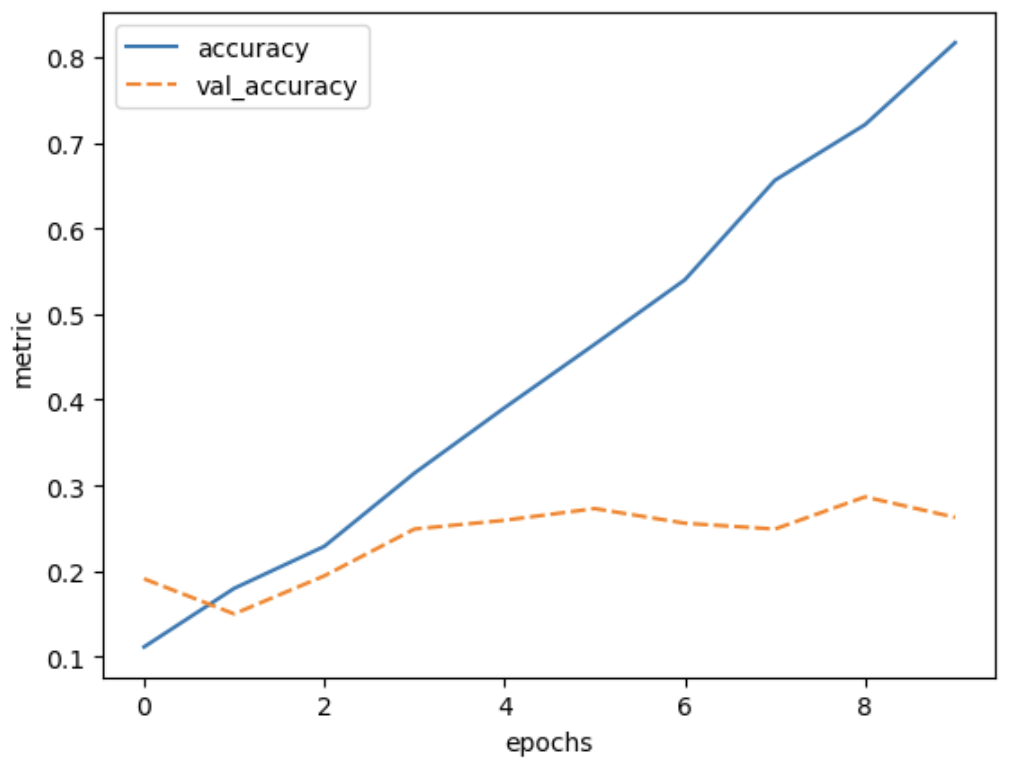
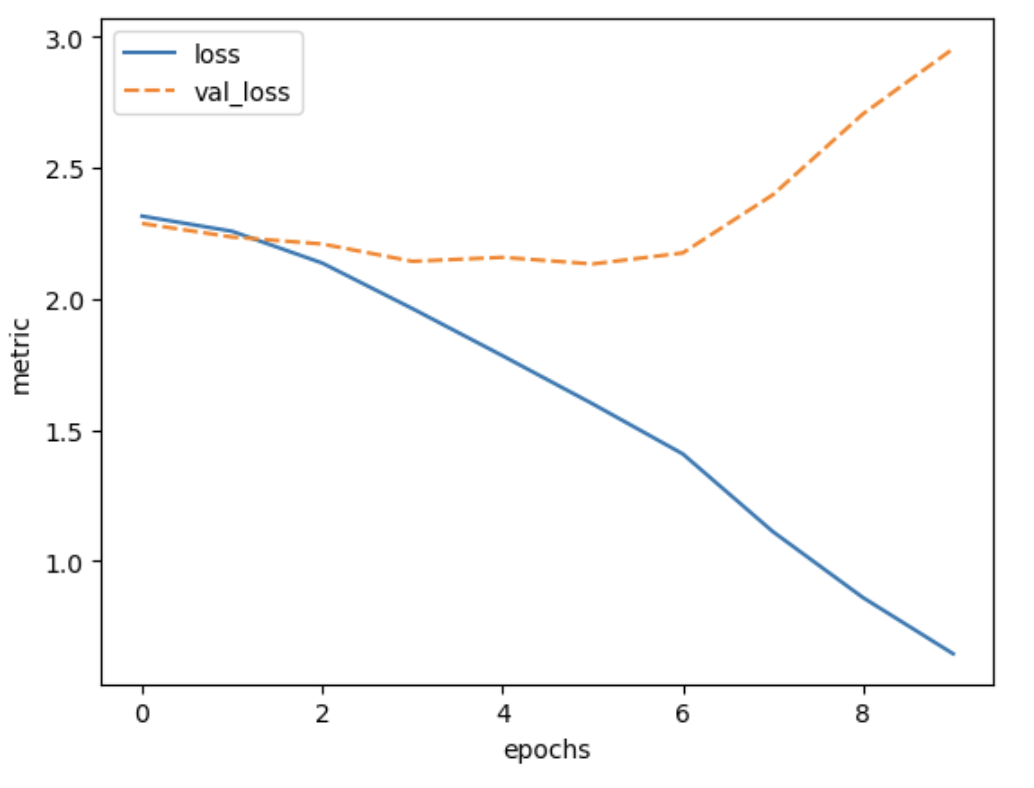
It seems that the model is overfitting a lot, because the training accuracy increases, while the validation accuracy stagnates. Meanwhile, the training loss keeps decreasing while the validation loss actually starts increasing after a few epochs.
Comparison with a network with only dense layers
How does this simple CNN compare to a neural network with only dense layers?
We can define a neural network with only dense layers:
PYTHON
def create_dense_model():
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Flatten()(inputs)
x = keras.layers.Dense(50, activation='relu')(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)
return keras.models.Model(inputs=inputs, outputs=outputs,
name='dense_model')
dense_model = create_dense_model()
dense_model.summary()OUTPUT
Model: "dense_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) [(None, 64, 64, 3)] 0
flatten_5 (Flatten) (None, 12288) 0
dense_11 (Dense) (None, 50) 614450
dense_12 (Dense) (None, 50) 2550
dense_13 (Dense) (None, 10) 510
=================================================================
Total params: 617510 (2.36 MB)
Trainable params: 617510 (2.36 MB)
Non-trainable params: 0 (0.00 Byte)As you can see this model has more parameters than our simple CNN, let’s train and evaluate it!
PYTHON
compile_model(dense_model)
history = dense_model.fit(train_images, train_labels, epochs=20,
validation_data=(val_images, val_labels))
plot_history(history, ['accuracy', 'val_accuracy'])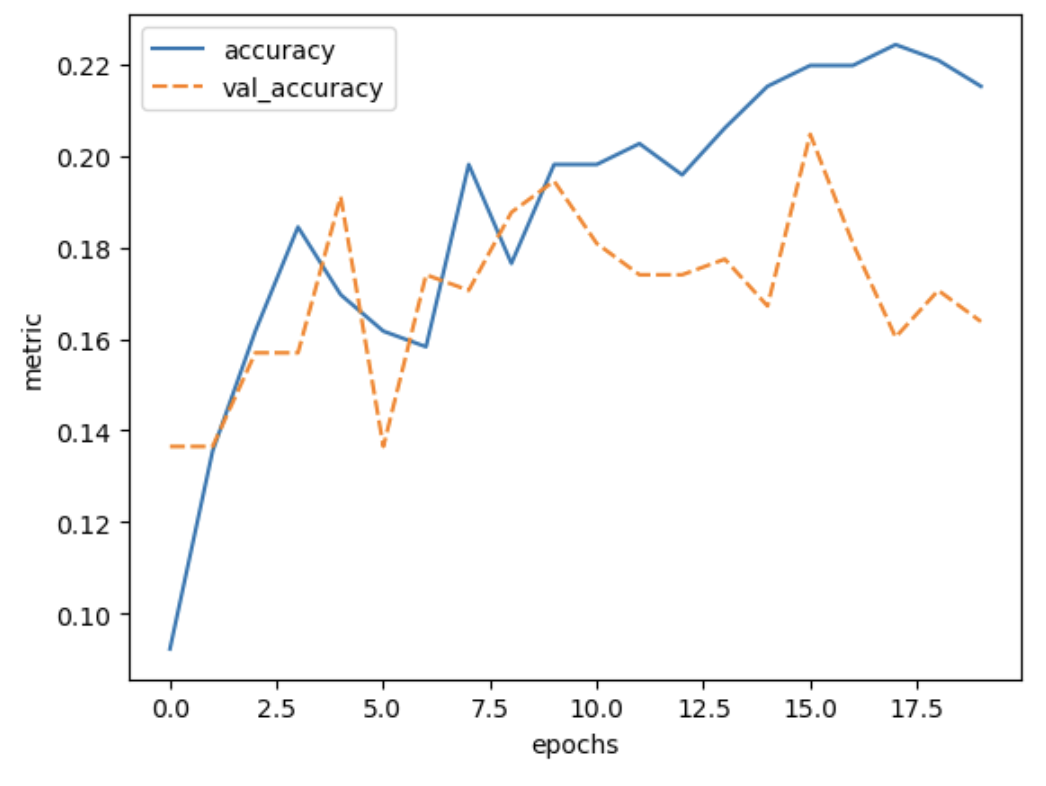
As you can see the validation accuracy only reaches about 18%, whereas the CNN reached about 28% accuracy.
This demonstrates that convolutional layers are a big improvement over dense layers for these kind of datasets.
9. Refine the model
Network depth
What, do you think, will be the effect of adding a convolutional
layer to your model? Will this model have more or fewer parameters? Try
it out. Create a model that has an additional
Conv2d layer with 50 filters and another MaxPooling2D layer
after the last MaxPooling2D layer. Train it for 10 epochs and plot the
results.
HINT: The model definition that we used previously needs to be adjusted as follows:
PYTHON
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
# Add your extra layers here
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)We add an extra Conv2D layer after the second pooling layer:
PYTHON
def create_nn_extra_layer():
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x) #
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x) # extra layer
x = keras.layers.MaxPooling2D((2, 2))(x) # extra layer
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="dollar_street_model")
return model
model = create_nn_extra_layer()With the model defined above, we can inspect the number of parameters:
OUTPUT
Model: "dollar_street_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 64, 64, 3)] 0
conv2d_4 (Conv2D) (None, 62, 62, 50) 1400
max_pooling2d_2 (MaxPoolin (None, 31, 31, 50) 0
g2D)
conv2d_5 (Conv2D) (None, 29, 29, 50) 22550
max_pooling2d_3 (MaxPoolin (None, 14, 14, 50) 0
g2D)
conv2d_6 (Conv2D) (None, 12, 12, 50) 22550
max_pooling2d_4 (MaxPoolin (None, 6, 6, 50) 0
g2D)
flatten_2 (Flatten) (None, 1800) 0
dense_4 (Dense) (None, 50) 90050
dense_5 (Dense) (None, 10) 510
=================================================================
Total params: 137060 (535.39 KB)
Trainable params: 137060 (535.39 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
The number of parameters has decreased by adding this layer. We can see that the extra layers decrease the resolution from 14x14 to 6x6, as a result, the input of the Dense layer is smaller than in the previous network. To train the network and plot the results:
PYTHON
compile_model(model)
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(val_images, val_labels))
plot_history(history, ['accuracy', 'val_accuracy'])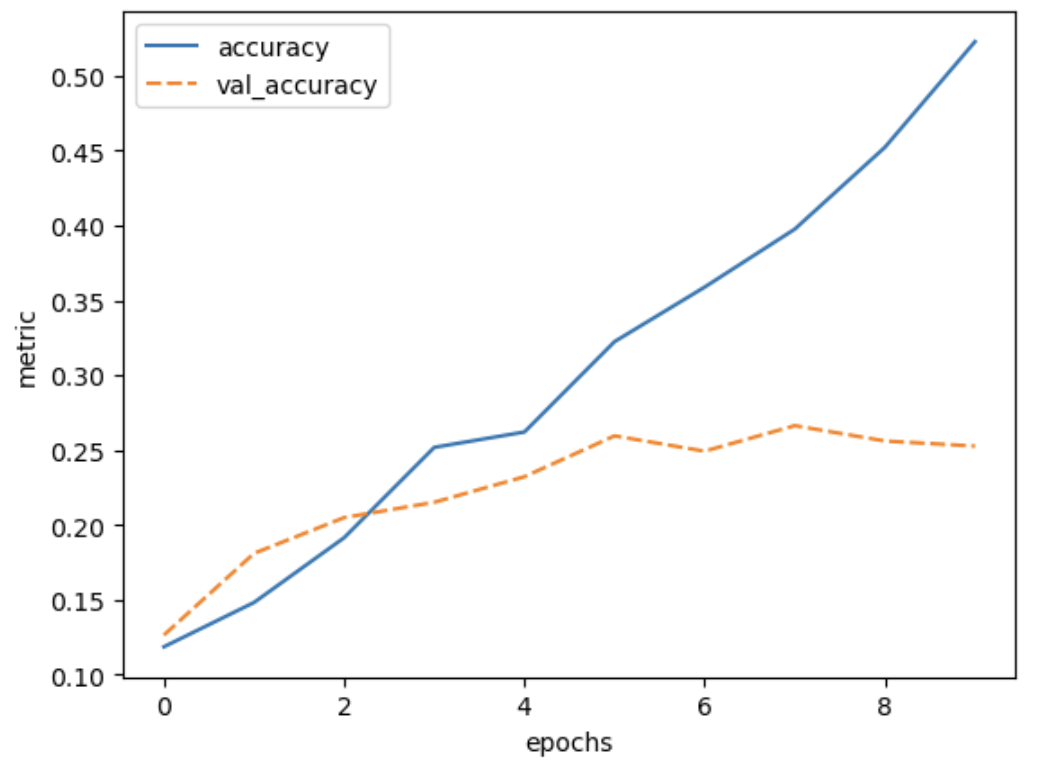
Other types of data
Convolutional and Pooling layers are also applicable to different types of data than image data. Whenever the data is ordered in a (spatial) dimension, and translation invariant features are expected to be useful, convolutions can be used. Think for example of time series data from an accelerometer, audio data for speech recognition, or 3d structures of chemical compounds.
Why and when to use convolutional neural networks
- Would it make sense to train a convolutional neural network (CNN) on the penguins dataset and why?
- Would it make sense to train a CNN on the weather dataset and why?
- (Optional) Can you think of a different machine learning task that would benefit from a CNN architecture?
- No that would not make sense. Convolutions only work when the features of the data can be ordered in a meaningful way. Pixels for example are ordered in a spatial dimension. This kind of order cannot be applied to the features of the penguin dataset. If we would have pictures or audio recordings of the penguins as input data it would make sense to use a CNN architecture.
- It would make sense, but only if we approach the problem from a different angle then we did before. Namely, 1D convolutions work quite well on sequential data such as timeseries. If we have as our input a matrix of the different weather conditions over time in the past x days, a CNN would be suited to quickly grasp the temporal relationship over days.
- Some example domains in which CNNs are applied:
- Text data
- Timeseries, specifically audio
- Molecular structures
Dropout
Note that the training loss continues to decrease, while the validation loss stagnates, and even starts to increase over the course of the epochs. Similarly, the accuracy for the validation set does not improve anymore after some epochs. This means we are overfitting on our training data set.
Techniques to avoid overfitting, or to improve model generalization, are termed regularization techniques. One of the most versatile regularization technique is dropout (Srivastava et al., 2014). Dropout means that during each training cycle (one forward pass of the data through the model) a random fraction of neurons in a dense layer are turned off. This is described with the dropout rate between 0 and 1 which determines the fraction of nodes to silence at a time.
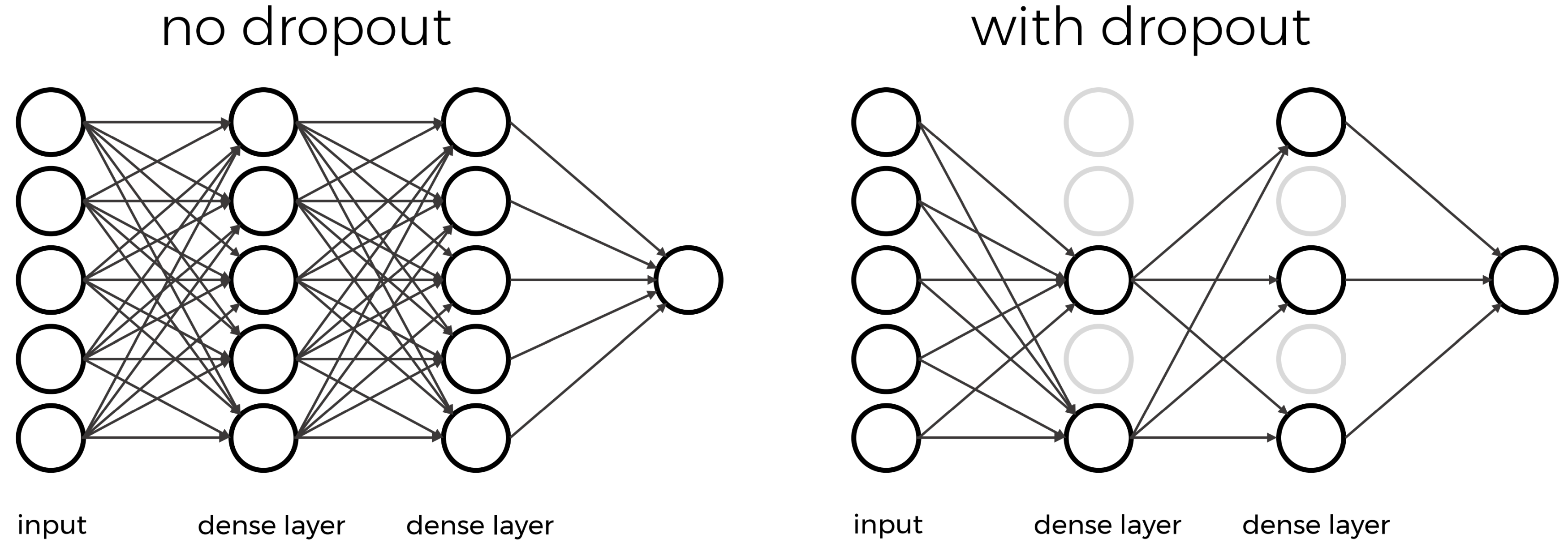
The intuition behind dropout is that it enforces redundancies in the network by constantly removing different elements of a network. The model can no longer rely on individual nodes and instead must create multiple “paths”. In addition, the model has to make predictions with much fewer nodes and weights (connections between the nodes). As a result, it becomes much harder for a network to memorize particular features. At first this might appear a quite drastic approach which affects the network architecture strongly. In practice, however, dropout is computationally a very elegant solution which does not affect training speed. And it frequently works very well.
Important to note: Dropout layers will only randomly silence nodes during training! During a prediction step, all nodes remain active (dropout is off). During training, the sample of nodes that are silenced are different for each training instance, to give all nodes a chance to observe enough training data to learn its weights.
Let us add a dropout layer after each pooling layer towards the end of the network that randomly drops 80% of the nodes.
PYTHON
def create_nn_with_dropout():
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(0.8)(x) # This is new!
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(0.8)(x) # This is new!
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(0.8)(x) # This is new!
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="dropout_model")
return model
model_dropout = create_nn_with_dropout()
model_dropout.summary()OUTPUT
Model: "dropout_model"
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ input_layer_4 (InputLayer) │ (None, 64, 64, 3) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_6 (Conv2D) │ (None, 62, 62, 50) │ 1,400 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_4 (MaxPooling2D) │ (None, 31, 31, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 31, 31, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_7 (Conv2D) │ (None, 29, 29, 50) │ 22,550 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_5 (MaxPooling2D) │ (None, 14, 14, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_1 (Dropout) │ (None, 14, 14, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_8 (Conv2D) │ (None, 12, 12, 50) │ 22,550 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_6 (MaxPooling2D) │ (None, 6, 6, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_2 (Dropout) │ (None, 6, 6, 50) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_4 (Flatten) │ (None, 1800) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_8 (Dense) │ (None, 50) │ 90,050 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_9 (Dense) │ (None, 10) │ 510
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 137060 (535.39 KB)
Trainable params: 137060 (535.39 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
We can see that the dropout does not alter the dimensions of the image, and has zero parameters.
We again compile and train the model.
PYTHON
compile_model(model_dropout)
history = model_dropout.fit(train_images, train_labels, epochs=20,
validation_data=(val_images, val_labels))And inspect the training results:
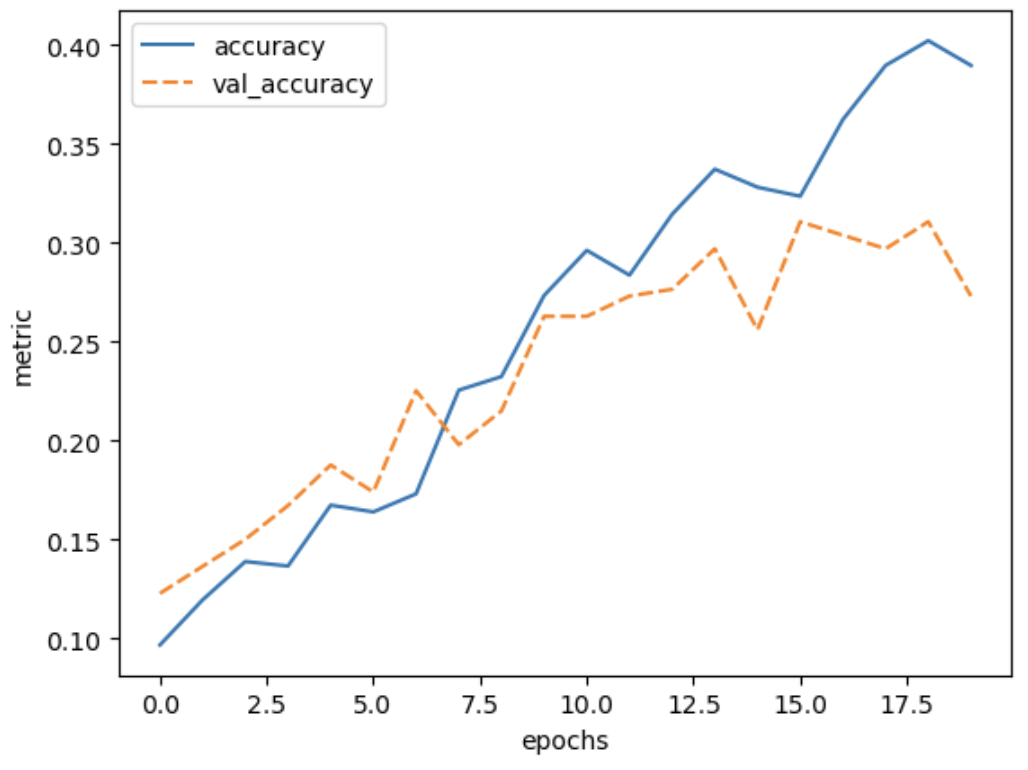
Now we see that the gap between the training accuracy and validation accuracy is much smaller, and that the final accuracy on the validation set is higher than without dropout.
Vary dropout rate
- What do you think would happen if you lower the dropout rate? Try it out, and see how it affects the model training.
- You are varying the dropout rate and checking its effect on the model performance, what is the term associated to this procedure?
1. Varying the dropout rate
The code below instantiates and trains a model with varying dropout rates. You can see from the resulting plot that the ideal dropout rate in this case is around 0.9. This is where the val loss is lowest.
Note that it can take a while to train these 6 networks.
PYTHON
def create_nn_with_dropout(dropout_rate):
inputs = keras.Input(shape=train_images.shape[1:])
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(inputs)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(dropout_rate)(x)
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(dropout_rate)(x)
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.Dropout(dropout_rate)(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="dropout_model")
return model
early_stopper = keras.callbacks.EarlyStopping(monitor='val_loss', patience=5)
dropout_rates = [0.2, 0.4, 0.6, 0.8, 0.9, 0.95]
val_losses = []
for dropout_rate in dropout_rates:
model_dropout = create_nn_with_dropout(dropout_rate)
compile_model(model_dropout)
model_dropout.fit(train_images, train_labels, epochs=30,
validation_data=(val_images, val_labels),
callbacks=[early_stopper]
)
val_loss, val_acc = model_dropout.evaluate(val_images, val_labels)
val_losses.append(val_loss)
loss_df = pd.DataFrame({'dropout_rate': dropout_rates, 'val_loss': val_losses})
sns.lineplot(data=loss_df, x='dropout_rate', y='val_loss')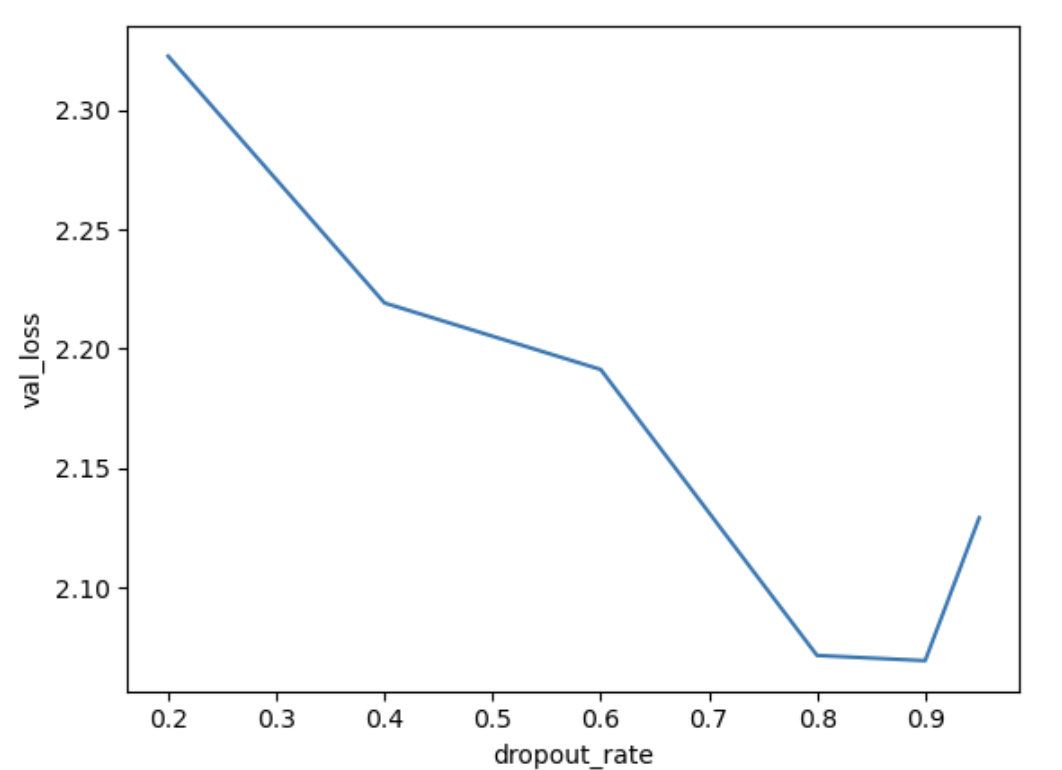
Hyperparameter tuning
Recall that hyperparameters are model configuration settings that are
chosen before the training process and affect the model’s learning
behavior and performance, for example the dropout rate. In general, if
you are varying hyperparameters to find the combination of
hyperparameters with the best model performance this is called
hyperparameter tuning. A naive way to do this is to write a for-loop and
train a slightly different model in every cycle. However, it is better
to use the keras_tuner package for this.
Let’s first define a function that creates a neuronal network given 2 hyperparameters, namely the dropout rate and the number of layers:
PYTHON
def create_nn_with_hp(dropout_rate, n_layers):
inputs = keras.Input(shape=train_images.shape[1:])
x = inputs
for layer in range(n_layers):
x = keras.layers.Conv2D(50, (3, 3), activation='relu')(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(dropout_rate)(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation='relu')(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="cifar_model")
return modelNow, let’s find the best combination of hyperparameters using grid search. Grid search is the simplest hyperparameter tuning strategy, you test all the combinations of predefined values for the hyperparameters that you want to vary.
For this we will make use of the package keras_tuner, we
can install it by typing in the command line:
Note that this can take some time to train (around 5 minutes or longer).
PYTHON
import keras_tuner
hp = keras_tuner.HyperParameters()
def build_model(hp):
# Define values for hyperparameters to try out:
n_layers = hp.Int("n_layers", min_value=1, max_value=2, step=1)
dropout_rate = hp.Float("dropout_rate", min_value=0.2, max_value=0.8, step=0.3)
model = create_nn_with_hp(dropout_rate, n_layers)
compile_model(model)
return model
tuner = keras_tuner.GridSearch(build_model, objective='val_loss')
tuner.search(train_images, train_labels, epochs=20,
validation_data=(val_images, val_labels))OUTPUT
Trial 6 Complete [00h 00m 19s]
val_loss: 2.086069345474243
Best val_loss So Far: 2.086069345474243
Total elapsed time: 00h 01m 28sLet’s have a look at the results:
OUTPUT
Results summary
Results in ./untitled_project
Showing 10 best trials
Objective(name="val_loss", direction="min")
Trial 0005 summary
Hyperparameters:
n_layers: 2
dropout_rate: 0.8
Score: 2.086069345474243
Trial 0000 summary
Hyperparameters:
n_layers: 1
dropout_rate: 0.2
Score: 2.101102352142334
Trial 0001 summary
Hyperparameters:
n_layers: 1
dropout_rate: 0.5
Score: 2.1184325218200684
Trial 0003 summary
Hyperparameters:
n_layers: 2
dropout_rate: 0.2
Score: 2.1233835220336914
Trial 0002 summary
Hyperparameters:
n_layers: 1
dropout_rate: 0.8
Score: 2.1370232105255127
Trial 0004 summary
Hyperparameters:
n_layers: 2
dropout_rate: 0.5
Score: 2.143627882003784Hyperparameter tuning
1: Looking at the grid search results, select all correct statements:
- A. 6 different models were trained in this grid search run, because there are 6 possible combinations for the defined hyperparameter values
- B. 2 different models were trained, 1 for each hyperparameter that we want to change
- C. 1 model is trained with 6 different hyperparameter combinations
- D. The model with 2 layer and a dropout rate of 0.5 is the best model with a validation loss of 2.144
- E. The model with 2 layers and a dropout rate of 0.8 is the best model with a validation loss of 2.086
- F. We found the model with the best possible combination of dropout rate and number of layers
2 (Optional): Perform a grid search finding the best combination of the following hyperparameters: 2 different activation functions: ‘relu’, and ‘tanh’, and 2 different values for the kernel size: 3 and 4. Which combination works best?
Hint: Instead of hp.Int you should now
use hp.Choice("name", ["value1", "value2"]) to use
hyperparameters from a predefined set of possible values.
1:
- A: Correct, 2 values for number of layers (1 and 2) are combined with 3 values for the dropout rate (0.2, 0.5, 0.8). 2 * 3 = 6 combinations
- B: Incorrect, a model is trained for each combination of defined hyperparameter values
- C: Incorrect, it is important to note that you actually train and test different models for each run of the grid search
- D: Incorrect, this is the worst model since the validation loss is highest
- E: Correct, this is the best model with the lowest loss
- F: Incorrect, it could be that a different number of layers in combination with a dropout rate that we did not test (for example 3 layers and a dropout rate of 0.6) could be the best model.
2 (Optional):
You need to adapt the code as follows:
PYTHON
def create_nn_with_hp(activation_function, kernel_size):
inputs = keras.Input(shape=train_images.shape[1:])
x = inputs
for layer in range(3):
x = keras.layers.Conv2D(50, (kernel_size, kernel_size), activation=activation_function)(x)
x = keras.layers.MaxPooling2D((2, 2))(x)
x = keras.layers.Dropout(0.2)(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(50, activation=activation_function)(x)
outputs = keras.layers.Dense(10)(x)
model = keras.Model(inputs=inputs, outputs=outputs, name="cifar_model")
return model
hp = keras_tuner.HyperParameters()
def build_model(hp):
kernel_size = hp.Int("kernel_size", min_value=3, max_value=4, step=1)
activation = hp.Choice("activation", ["relu", "tanh"])
model = create_nn_with_hp(activation, kernel_size)
compile_model(model)
return model
tuner = keras_tuner.GridSearch(build_model, objective='val_loss', project_name='new_project')
tuner.search(train_images, train_labels, epochs=20,
validation_data=(val_images, val_labels))OUTPUT
Trial 4 Complete [00h 00m 25s]
val_loss: 2.0591845512390137
Best val_loss So Far: 2.0277602672576904
Total elapsed time: 00h 01m 30sLet’s look at the results:
OUTPUT
Results summary
Results in ./new_project
Showing 10 best trials
Objective(name="val_loss", direction="min")
Trial 0001 summary
Hyperparameters:
kernel_size: 3
activation: tanh
Score: 2.0277602672576904
Trial 0003 summary
Hyperparameters:
kernel_size: 4
activation: tanh
Score: 2.0591845512390137
Trial 0000 summary
Hyperparameters:
kernel_size: 3
activation: relu
Score: 2.123767614364624
Trial 0002 summary
Hyperparameters:
kernel_size: 4
activation: relu
Score: 2.150160551071167A kernel size of 3 and tanh as activation function is
the best tested combination.
Grid search can quickly result in a combinatorial explosion because
all combinations of hyperparameters are trained and tested. Instead,
random search randomly samples combinations of
hyperparemeters, allowing for a much larger look through a large number
of possible hyperparameter combinations.
Next to grid search and random search there are many different hyperparameter tuning strategies, including neural architecture search where a separate neural network is trained to find the best architecture for a model!
10. Share model
Let’s save our model
Conclusion and next steps
How successful were we with creating a model here? With ten image classes, and assuming that we would not ask the model to classify an image that contains none of the given classes of object, a model working on complete guesswork would be correct 10% of the time. Against this baseline accuracy of 10%, and considering the diversity and relatively low resolution of the example images, perhaps our last model’s validation accuracy of ~30% is not too bad. What could be done to improve on this performance? We might try adjusting the number of layers and their parameters, such as the number of units in a layer, or providing more training data (we were using only a subset of the original Dollar Street dataset here). Or we could explore some other deep learning techniques, such as transfer learning, to create more sophisticated models.
Key Points
- Convolutional layers make efficient reuse of model parameters.
- Pooling layers decrease the resolution of your input
- Dropout is a way to prevent overfitting