Workflows and Pipelines
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is a workflow
What does it mean to have a data-driven workflow
How do I implement a workflow
Objectives
Understand the components of a workflow
What is a workflow?
A workflow is a sequence of tasks that are executed to reach a desired goal. Workflows exist for humans to follow (eg, recipes for making pancakes) and for machines to follow (eg, scripts for turning tables into plots). The key features of a workflow are:
- inputs
- activity
- outputs or results
As humans that cook you are probably familiar with the following sort of workflow (e.g, this recipe):

And as an astronomer you can appreciate the following flow-chart, or decision tree, which takes input from an alert service, performs some checks and calculations to determine if action is needed, and results in either action or inaction:
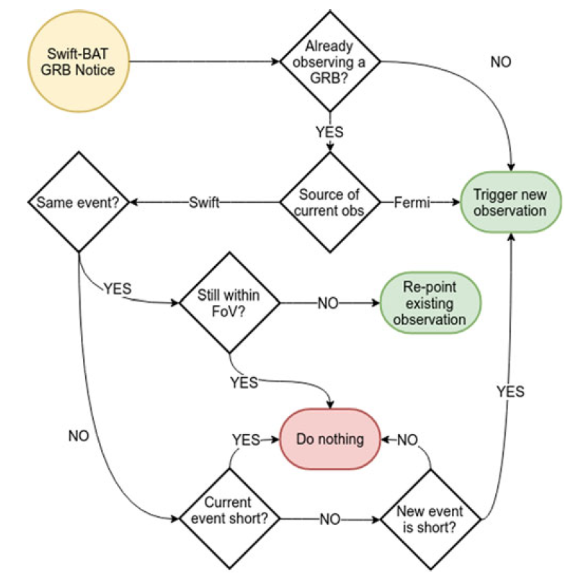
In research we live with a combination of the two types of workflows. We have a high level understanding of the research workflow, for example:
- Exploring what is known
- Formulation of an hypothesis
- Collecting data
- Analyzing data
- Testing hypothesis
- Publishing results
Sadly this high level workflow isn’t automated and each of the steps are rather vague so we need to adapt and refine it for each project. At a low level, there are many tasks that you do in your research that are (very nearly) the same every time you do them, and these are the tasks that you can automate. The end goal of this workshop is to show you how to turn join all of your small automated tasks into larger and larger workflows. However, to begin with we need to start thinking with a workflow mindset.
Developing a workflow mindset
Let’s start with a very generic workflow such as the one below, which takes two data sources as input, does a bunch of (pre)processing of these data, and then generates some science (as indicated by the conical flask).
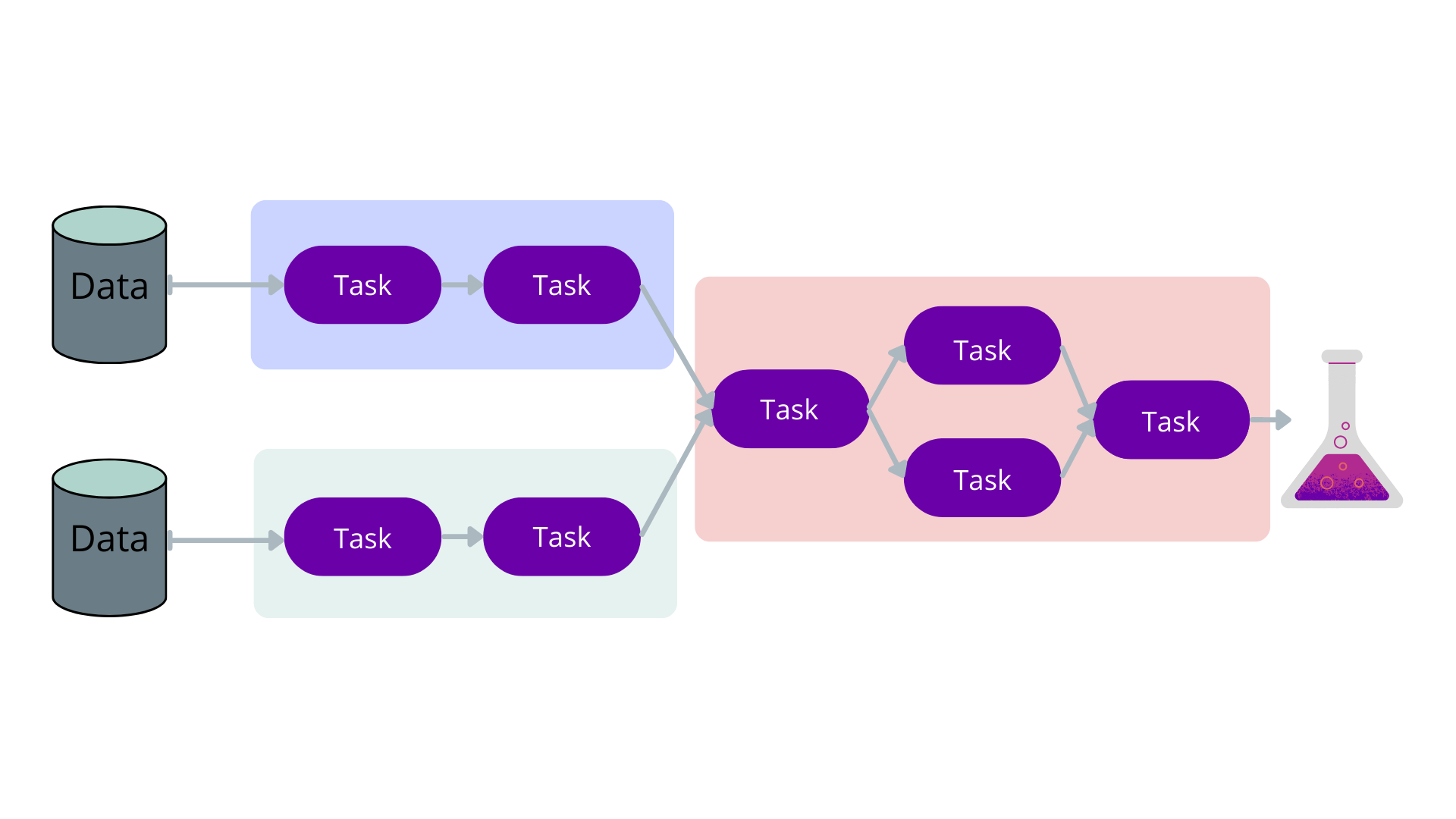
Working with a workflow mindset means we need to identify the following:
- What is the desired output, outcome, or result?
- What information is required to generate this output/outcome/result?
- What actions need to be performed to map (2) to (1)?
Initially we start with a high level workflow with not much detail, but as we start to refine our goals, we refine our inputs. This in turn means that we need to have a better idea of how we map our inputs to outputs, which in turn may require that we rethink our goals or add additional input requirements.
Describe a workflow
Think about some research work that you have done, are doing, or plan to do and:
- Describe the desired outcome/output/result
- Describe the information/data/resources that you think you might need
Draw a three stage diagram which has a single box as your “task”.
Now think about how you can break this box into smaller linked pieces such that you have a more detailed map of how to get from inputs to outputs.
Share your thoughts in the etherpad.
Example
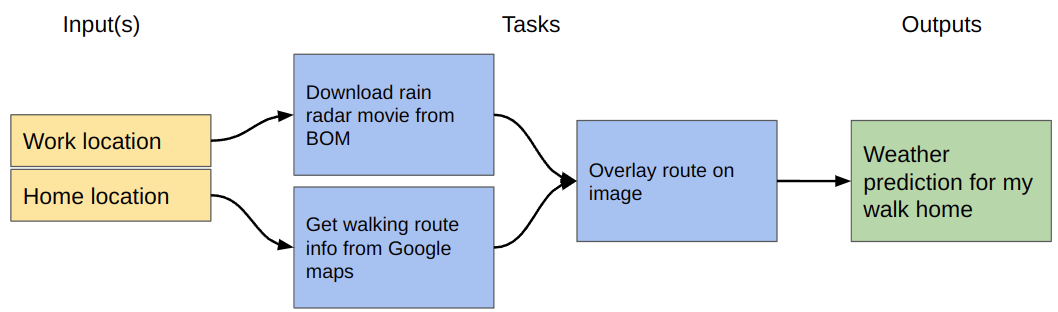
Initial plan - make a map of my path home with weather info so I know if I should take a coat/umbrella.
Thinking a bit more about the data that I need and what is readily available I refine my inputs, and make some more detailed tasks about fetching existing data. Similarly, I refine my outputs because I realize that an animated rain map would be more useful than a static one. My plan is now:
Take some time to make make a workflow for yourself, and then share with people near you. Use a fancy drawing program if you like but
PaperPencilV1.0will also work just fine.
Follow the arrows
In the figures that we have been viewing, there are arrows that link inputs to tasks, tasks to other tasks, and tasks to outputs. What do these arrows represent to you?
Are they:
- an indication of precedent / order / dependency
- the flow of information / data / files
If you said (1) then could can you determine what information needs to be passed between the different stages and in what format?
Do the diagrams produced by people answering (1) differ from those produced by people answering (2)?
Share your thoughts in the etherpad.
If you answered (2) in the above discussion then you are thinking about a data-driven workflow. In a data-driven workflow each of our tasks takes input data and transforms it to produce output which is then passed to the next task. The ordering of tasks is implicit in the input/output chain that is specified.
We can plan the work done based on either given inputs or the required outputs:
- Input driven:
- Start at the known inputs,
- Transforming them into outputs which are then fed to the next task,
- Repeating until there is no more work to be done.
- Output driven:
- Start at the required output and ask what inputs are required to produce it,
- Step back to see what is needed to make these inputs,
- Repeat until we have inputs that already exist and then execute the workflow from this point forward.
An output driven workflow can avoid processing data that is not required for the desired output. This is how Make behaves and it can save a lot of time when you modify and restart a workflow which has previously been run.
Regardless of the type of workflow that you are using there are various caching tricks that can be used to determine if a particular part of the workflow needs to be re-run. Typically this will be based on checking if the inputs or workflow description has changed, and only re-running the parts that have changed and the tasks that depend on them.
How to implement workflows
Despite the up-front designs that we may come up with, a workflow is going to naturally evolve and change as we encounter different problems and adjust our desired outputs. It is very common for people to start a research project by exploring or “playing” with data until interesting features present themselves, which help to develop hypotheses, and so on through to publication. Trying to back track through your notes when writing up a paper can be hard, and reproducing your own work can also be difficult if you haven’t meticulously recorded how each bit of work was done. To get around this, we recommend that you take on a workflow mindset and record (in as much detail as possible) what was done and what decisions were made at each point in your work flow. This record of work may take the form of scripts that transform data, but it could just as reasonably be a recipe for a human to follow. At some point these human centered recipes will become the the slow points for your workflow and you are going to naturally look for ways to automate them. Whilst it is not essential for workflows to be fully-automated, it can certainly save time, and build confidence in results.
As a workflow grows, it often becomes complicated. It can be challenging to do the following:
- Keep the workflow clear, readable and maintainable
- Track errors and respond to failed tasks
- Benchmark tasks to find bottlenecks
- Handle data or software dependencies
- Run the workflow on different systems
- Halt a workflow, update it, and then resume where it left off without having to redo already complete work
To help with the above, it is best your use workflow orchestration software, such as NextFlow, to develop your computer based workflows.
Key Points
Everything is a workflow
Adopt a workflow mindset for your research
NextFlow can help orchestrate your workflows